Trataré de decirle lo fácil que es obtener resultados interesantes simplemente aplicando un enfoque completamente estándar del tutorial del curso de aprendizaje automático a los datos que no se utilizan en Deep Learning. La esencia de mi publicación es que podemos ser cada uno de nosotros, solo necesita mirar la variedad de información que conoce bien. Para hacer esto, de hecho, es mucho más importante simplemente comprender bien sus datos que ser un experto en las últimas estructuras de redes neuronales. Es decir, en mi opinión, estamos en ese punto de oro en el desarrollo de DL, cuando por un lado ya es una herramienta que se puede usar sin la necesidad de ser un doctorado, y por otro todavía hay muchas áreas en las que nadie realmente lo usó, si se mira Un poco más allá de los temas tradicionales.

Al leer artículos y de paso viendo cómo se desarrolla el aprendizaje automático, usted y yo podemos sentir fácilmente que este tren está pasando. De hecho, si toma los cursos más famosos (por ejemplo, Andrew Ng ) o la mayoría de los artículos sobre Habré de la misma excelente comunidad de Open Data Science, rápidamente se dará cuenta de que no hay nada que hacer aquí desde la memoria profunda del conocimiento del instituto en matemáticas superiores, bueno, al menos algunos Los resultados correctos (incluso en ejemplos de " juguetes ") se pueden lograr solo después de varias semanas de estudiar la teoría de Terry y diferentes formas de su implementación. Pero a menudo quiere otro, quiere tener una herramienta que realice su función, que resuelva una cierta clase de problemas, de modo que, al aplicarlo en su campo, obtenga el resultado. De hecho, en otras áreas todo es exactamente así, si usted, por ejemplo, escribe un juego y su tarea es garantizar la transferencia de información del jugador al servidor, entonces no estudia la teoría de los gráficos, no descubre cómo optimizar la conectividad para que sus paquetes lleguen más rápido: toma la herramienta (biblioteca, marco) que hace esto por usted y se enfoca en lo que es exclusivo de una tarea en particular (por ejemplo, qué tipo de información necesita transferir de un lado a otro). ¿Por qué esto no es así para el aprendizaje profundo?
De hecho, ahora estamos al borde del tiempo en que se está volviendo casi así . Y para mí, casi encontré esa herramienta oh - fast.ai. Una biblioteca excelente y un curso aún más pronunciado, cuyo principio completo se construye "de arriba hacia abajo": primero resolver problemas reales, a menudo en el nivel de precisión de la predicción de los modelos de estado del arte, hasta la estructura interna de la biblioteca y la teoría detrás de ella.
Por supuesto, no todo es tan simple.Anticipando las acusaciones de falta de profesionalismo y la superficialidad de mi conocimiento (que, por supuesto, es más cierto que no), quiero hacer una reserva de inmediato. ¿Es necesario estudiar la teoría, ver esas conferencias fundamentales, recordar el cálculo de la matriz, etc.? Por supuesto que lo es. Y cuanto más profundice en el tema, más lo necesitará y tendrá que aferrarse a las fuentes principales. Pero cuanto más consciente sea la inmersión, más fácil será comprender exactamente cómo estos fundamentos afectan el resultado. El punto principal del principio de arriba hacia abajo es precisamente que debe hacerse después. Después de que ya hayas escrito algo tangible que puedes mostrar a tus amigos. Después de que te hayas sumergido lo suficiente en el tema y te haya fascinado. Y la teoría en el conocimiento lo superará, solo se presenta en el momento en que será más fácil para usted correlacionarlo con lo que ya ha hecho. Como una explicación de por qué y cómo funciona realmente.
Estoy más que seguro de que alguien se siente más cómodo con el enfoque tradicional de abajo hacia arriba. Y es bueno que haya dos maneras, lo principal es que nos encontremos en el medio
Con tal conjunto de conocimiento, decidí aplicar DL a un tema que yo mismo había estado interesado durante mucho tiempo y ver a qué puede conducir. Y, por supuesto, lo primero que me vino a la mente fue el fútbol. Y cuando encontré estas maravillosas estadísticas de transferencia en kaggle, la elección se hizo aún más obvia.
Un poco sobre estos datos. Contienen información sobre quién y dónde se mudó al fútbol europeo en los últimos 10 años. Hay información sobre clubes, estadísticas de jugadores, ligas en las que participan, entrenadores y agentes, y mucho más (hay más de cien campos diferentes en total). Los datos son muy interesantes, pero ¿es posible determinar cuánto debería costar un jugador?
Si lo piensas bien, el precio de un jugador depende de una gran cantidad de factores. Al mismo tiempo, es genial, y yo (si no la mayoría) su parte es simplemente no formalizable. Cómo entender que el club acaba de vender al jugador a un precio alto, necesita un atacante y está listo para pagar de más; cómo entender que un nuevo entrenador ha venido y requiere actualizar la lista; ¿Cómo entender que el defensor principal del club se dio cuenta del grandioso y comenzó a jugar a medias, exigiendo una transferencia? Todo esto afecta fundamentalmente el monto de una transacción, pero no se presenta en los datos. A partir de eso, mis expectativas iniciales sobre la precisión de tal pronóstico fueron pequeñas.
Soy un programador falsoEn este punto, es hora de insertar el descargo de responsabilidad estándar de que # un # , no gano dinero con esto, por lo que mi código es terrible, y lo más probable es que pueda (y debería) reescribirse mucho mejor, pero dado que la tarea era investigar la idea y (no ?) Confirme la teoría, entonces el código es lo que es :)
Modelo
Comencé excluyendo transferencias más baratas que $ 1 millón, que son demasiado caóticas. Luego reunió todos los datos en una gran tabla con un campo y medio, en el que para cada transferencia había toda la información disponible sobre él (tanto sobre la transferencia en sí, el jugador y sus estadísticas, como sobre los clubes que participan en ella, ligas, etc. )
Veamos los pasos de cómo creé el modelo :
Después de completar todas las importaciones de Python y cargar la tabla de transferencia desnormalizada, lo primero que debemos determinar es cuál de los campos consideraremos numéricos y cuáles son categóricos. Este es un tema muy interesante en sí mismo, puede hablar sobre él en los comentarios, pero para ahorrar tiempo, solo describo la regla que uso: por defecto, considero todos los campos categóricos, excepto aquellos que están representados como números de punto flotante o aquellos donde el número de valores diferentes es lo suficientemente grande.
En este contexto, por ejemplo, considero el año de transferencia categórico, aunque inicialmente es un número, porque el número de valores diferentes es pequeño aquí (10 - de 2008 a 2018). Pero, por ejemplo, el rendimiento del jugador en la última temporada (que está representado por el número promedio de sus goles por partido) es flotante y puede tomar casi cualquier valor, por lo que lo considero numérico.
cat_vars_tpl = ('season','trs_year','trs_month','trs_day','trs_till_deadline', 'contract_left_months', 'contract_left_years','age', 'is_midseason','is_loan','is_end_of_loan', 'nat_national_name','plr_position_main', 'plr_other_positions','plr_nationality_name', 'plr_other_nationality_name','plr_place_of_birth_country_name', 'plr_foot','plr_height','plr_player_agent','from_club_name','from_club_is_first_team', 'from_clb_place','from_clb_qualified_to','from_clb_is_champion','from_clb_is_cup_winner', 'from_clb_is_promoted','from_clb_lg_name','from_clb_lg_country','from_clb_lg_group', 'from_coach_name', 'from_sport_dir_name', 'to_club_name','to_club_is_first_team','to_clb_place', 'to_clb_qualified_to', 'to_clb_is_champion','to_clb_is_cup_winner','to_clb_is_promoted', 'to_clb_lg_name','to_clb_lg_country', 'to_clb_lg_group','to_coach_name', 'to_sport_dir_name', 'plr_position_0','plr_position_1','plr_position_2', 'stats_leag_name_0', 'stats_leag_grp_0', 'stats_leag_name_1', 'stats_leag_grp_1', 'stats_leag_name_2', 'stats_leag_grp_2') cont_vars_tpl = ('nat_months_from_debut','nat_matches_played','nat_goals_scored','from_clb_pts_avg', 'from_clb_goals_diff_avg','to_clb_pts_avg','to_clb_goals_diff_avg','plr_apps_0', 'plr_apps_1','plr_apps_2','stats_made_goals_0','stats_conc_gols_0','stats_cards_0', 'stats_minutes_0','stats_team_points_0','stats_made_goals_1','stats_conc_gols_1', 'stats_cards_1','stats_minutes_1','stats_team_points_1','stats_made_goals_2', 'stats_conc_gols_2','stats_cards_2','stats_minutes_2','stats_team_points_2', 'pop_log1p')
Luego, después de indicar explícitamente lo que predeciremos: la cantidad de transferencia ( fee ), dividimos aleatoriamente nuestros datos en 2 partes de 80% y 20%. En el primero de ellos, enseñaremos a nuestra red neuronal, por el otro, a verificar la precisión de la predicción.
ln = len(df) valid_idx = np.random.choice(ln, int(ln*0.2), replace=False)
En la última etapa preparatoria, debemos elegir cómo mediremos la plausibilidad de nuestras predicciones. Luego elegí no la métrica más estándar en la parte local del universo: la mediana del porcentaje de error ( MdAPE ). O, para decirlo de manera más simple, ¿cuánto porcentaje (el precio absoluto de una transferencia puede diferir en órdenes de magnitud) probablemente cometerá un error en el precio de una transferencia tomada al azar. Me pareció lo más cercano a lo que significa para mí exactamente la frase "precisión del sistema de predicción de transferencia".
Ahora es el momento, de hecho, de comenzar a aprender la red.
data = (TabularList.from_df(df, path=path, cat_names=cat_vars, cont_names=cont_vars, procs=procs) .split_by_idx(valid_idx) .label_from_df(cols=dep_var, label_cls=FloatList, log=True) .databunch(bs=BS)) learn = tabular_learner(data, layers=layers, ps=layers_drop, emb_drop=emb_drop, y_range=y_range, metrics=exp_mmape, loss_func=MAELossFlat(), callback_fns=[CSVLogger]) learn.fit_one_cycle(cyc_len=cycles, max_lr=max_lr, wd=w_decay)
Precisión de la predicción

Validation Error = 0.3492 significa que después de entrenar en un nuevo validation set datos ( validation set , validation set ), el modelo en promedio (mediana) está 34% equivocado en relación con el precio de transferencia real. Y lo obtuvimos solo como resultado de varias líneas de código tomadas del tutorial.
34% de error, ¿es mucho o poco? Todo es relativo La única fuente comparable, cuyos datos pueden tomarse como una " predicción " del monto de la transferencia, es, por supuesto, transfermarkt . Afortunadamente, hay un campo en los datos de kaggle que muestra cómo este sitio calificó a un jugador en el momento de la transferencia, y esto se puede comparar. Cabe señalar aquí que transfermarkt nunca afirmó que su market value sea el precio de transferencia probable. Por el contrario, enfatizaron que es más bien el " valor honesto " de uno u otro jugador. Y cuánto dinero pagará un club en particular en una situación particular es algo muy individual y puede fluctuar en una dirección u otra dentro de límites muy amplios. Pero esto es lo mejor que tenemos, comparemos .

Error de transferencia de marca - 35% , nuestro modelo - 35% . Muy extraño y, para ser sincero, muy sospechoso.
En este punto, me propongo pensar de nuevo. Un sitio con una gran historia, creado solo para mostrar el 'valor' de los jugadores, que se basa en el poder total del efecto multitud (deriva el valor de las calificaciones tanto de los visitantes ordinarios como de los profesionales del mercado) y el conocimiento de los expertos, por un lado, y el modelo, que no sabe nada sobre fútbol, no ve nada excepto los datos que le dimos (y fuera de estos datos en el mundo real todavía hay muchas cosas que las personas con transferencia tienen en cuenta), por otro lado, muestran el mismo error . Además, nuestro modelo también permite predecir el precio de alquiler del jugador, que el market value , por razones obvias, no muestra (teniendo en cuenta tales transacciones, el resultado de transfermarkt fue aún peor ).
Honestamente, sigo pensando que tengo algún tipo de error aquí, todo es demasiado bueno para ser verdad. Pero, sin embargo, vamos más allá.
Una manera fácil de probarse es tratar de promediar las predicciones de 2 fuentes (modelos y transfermarkt). Si las predicciones son verdaderamente independientes entre sí y no hay un error molesto, entonces el resultado debería mejorar.

De hecho, promediar las previsiones reduce el error de predicción al 32% (!). Esto puede parecer un poco, pero debemos entender que estamos filtrando más información de los datos, que están tan exprimidos al máximo.
Pero lo que haremos a continuación, en mi opinión, es aún más sorprendente e interesante, aunque está más allá del alcance del tutorial fast.ai.
Importancia de la característica
Las redes neuronales, por no decir que es completamente inmerecida, a menudo se consideran una "caja negra". Sabemos qué datos podemos poner allí, podemos obtener las predicciones del modelo, incluso podemos evaluar cuánto son en promedio sus predicciones. Pero no podemos explicar con qué criterios el modelo "tomó" esta o aquella decisión. La estructura interna de la red en sí es tan compleja y, lo que es más importante, no lineal, que es imposible rastrear directamente toda la cadena de toma de decisiones y sacar conclusiones significativas del mundo real a partir de ahí. Pero realmente quiero hacerlo. Me gustaría entender qué es lo que más influye en el monto de la transferencia.
Bueno, no subiremos dentro de la red. Pero, ¿qué significa la importancia de cada campo, llamémosla Importancia de funciones (FI)? Una opción para entender la "importancia" es calcular cuánto empeorarán las cosas si no tuviéramos este campo. Y esto es precisamente lo que podemos medir. Ahora tenemos una herramienta que proporciona predicciones sobre cualquier conjunto de datos. Entonces, si solo calculamos cuánto aumentará el error de predicción cuando sustituimos datos aleatorios en el campo, entonces podemos estimar cuánto afecta (el campo) al resultado final, lo que significa lo importante que es. Para permanecer dentro de la distribución real de los datos, el campo se rellenará no solo con números aleatorios, sino también con valores mezclados al azar (es decir, solo mezclaremos la columna, por ejemplo, 'año de transferencia', en la tabla original). Para fidelidad, este proceso puede llevarse a cabo varias veces para cada campo promediando el resultado. Todo es bastante simple. Ahora veamos qué tan cuerdo da el resultado:
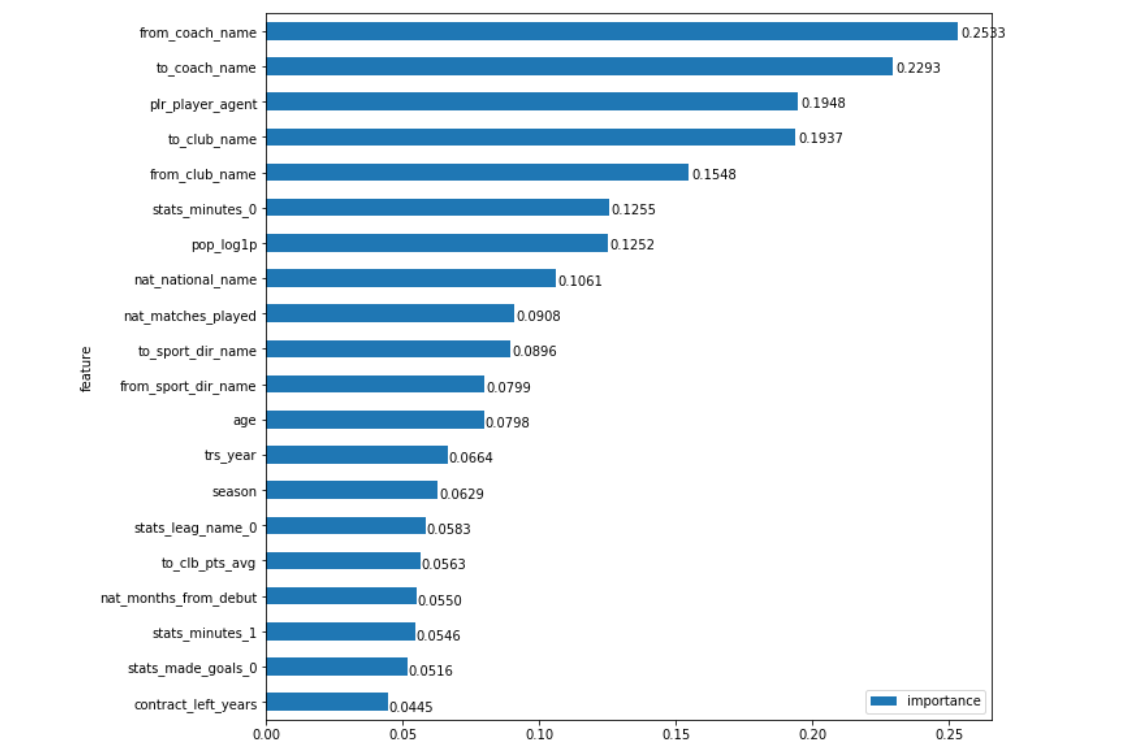
Mi instinto dice: "¡Sí y no!"
Por un lado, los campos que espera ver allí estaban en la parte superior: entrenadores del equipo desde dónde y dónde from_coach_name jugador ( from_coach_name , to_coach_name ), los clubes mismos que participaron en la transferencia ( from_club_name , to_club_name ), el agente del jugador ( plr_player_agent ), su fama en las redes sociales ( pop_log1p ) etc. Pero, por otro lado ... Intuitivamente, no parece que los nombres de los entrenadores tengan más peso en el precio de transferencia que, por ejemplo, los clubes mismos (sabemos bien que el Benfica condicional puede vender a sus jugadores caros). Es la marca de un entrenador más influyente en el precio que la marca del club. ¿La llegada del condicional Mancini obliga al club a pagar de más? ¿Cuál es el caso cuando los datos nos dan información nueva, ligeramente contraintuitiva, o simplemente un error en el modelo?
Vamos a hacerlo bien. Al observar de cerca el gráfico, el ojo se aferra rápidamente a algo extraño. Justo debajo del centro hay 2 campos trs_year y de season trs_year , representan el año de la transferencia y la temporada en la que se realizará la transición (en general, pueden no coincidir, aunque esto no sucede con tanta frecuencia). En primer lugar, parece que deberían ser más altos, sabemos cuánto han subido los precios de los jugadores de fútbol en los últimos años y, en segundo lugar, obviamente significan lo mismo. ¿Qué hacer al respecto? ¿Solo resumir su importancia? ¡No es el hecho de que esto se pueda hacer! Pero lo que definitivamente podemos hacer es aplicar el mismo enfoque (mezclar valores) no por separado a estos dos campos, sino como un grupo. Es decir, mida cómo cambiará el error si hay valores aleatorios en estas 2 columnas a la vez. Bueno, como hemos estado haciendo esto a lo largo de los años, necesitamos ver si tenemos otros campos que estén tan 'conectados'.
Por ejemplo, para un club, tenemos varios parámetros: el propio club ( club_name ), así como un conjunto de información sobre el mismo, de qué liga, país, etc. ( club_is_first_team , clb_lg_name , clb_lg_country , clb_lg_group ). Solo en algunos casos estamos interesados en saber cuánto afecta el precio, por ejemplo, el país al que va el jugador por separado ( clb_lg_country ), lo más frecuente es que comprendamos cuál es el peso total del campo 'club', que ya está en un determinado país, liga, etc. .
Por lo tanto, podemos combinar todos los campos en grupos de acuerdo con el contenido semántico. Esto nos ayudará como un simple conocimiento del área temática y el sentido común, así como la "proximidad" calculada de las características. El último solo muestra cómo los campos se correlacionan entre sí, es decir, cuánto es posible considerarlos como un solo grupo.
Aplicando este enfoque, obtenemos un gráfico aún más intuitivo de la importancia de los campos:
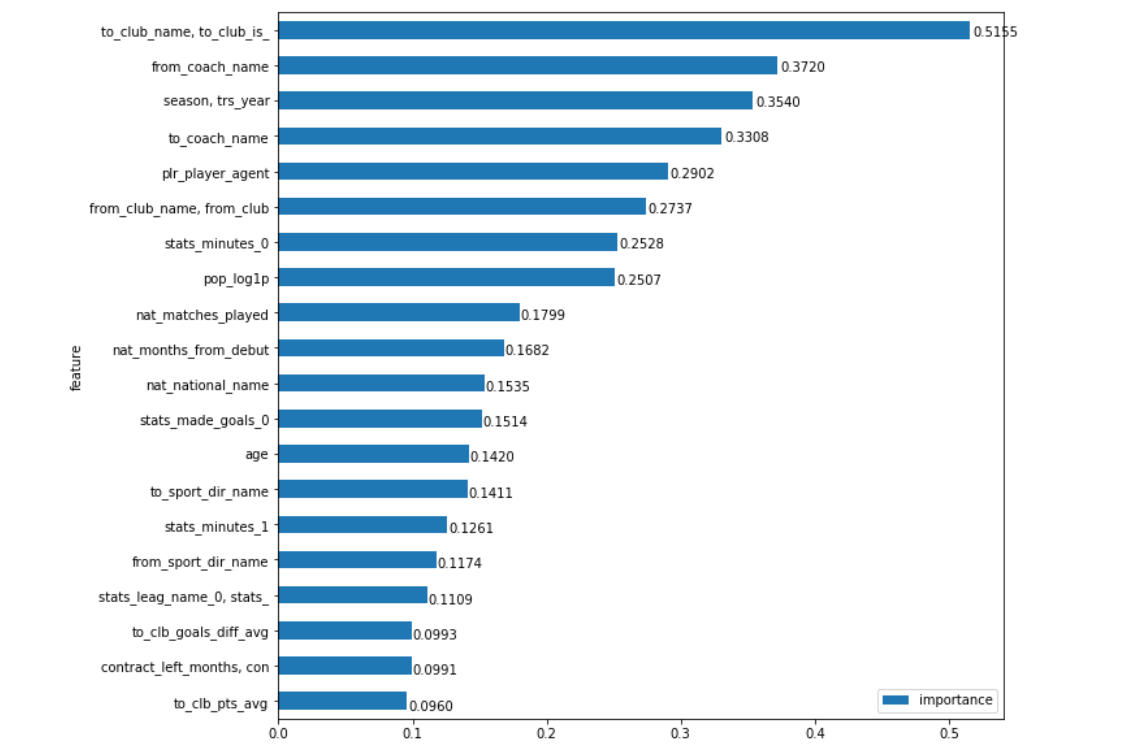
Ahí tienes. Exactamente qué palo compra más el jugador afecta el monto de la transferencia, con un margen muy bueno. Hi Man City, Barcelona, Zenit y, por ejemplo, el mismo Benfica (después de todo, " influye mucho ", también es el hecho de que algunos clubes, por el contrario, pueden comprar jugadores de calidad más baratos que el "mercado"). Me parece que lo más interesante al trabajar con datos es que, cuando se obtienen, las conclusiones son obvias, por un lado (bueno, dudé de que el comprador del club tuviera la influencia más poderosa sobre el monto de la transferencia), y por otro lado, es un poco sorprendente (y los candidatos para el primero el lugar, intuitivamente, podría ser algo, y la separación del segundo no parecía tan significativa)
Todavía hay muchas cosas interesantes por descubrir. Por ejemplo, el nombre del entrenador desde donde se compra al jugador, desde el punto de vista del modelo, es aún más importante que el club ... Deje que la diferencia se reduzca considerablemente. En principio, se puede encontrar una explicación lógica para esto (aunque a veces se puede encontrar para cualquier cosa). Hay entrenadores (Guardiola, Klopp, Benítez, Berdyev) que se adhieren a una determinada ideología del juego en diferentes clubes, lo que revela mejor o viceversa hace que ciertas posiciones en el campo sean menos brillantes, y la visibilidad del jugador afecta en gran medida su precio. Sobre clubes, por así decirlo, casi imposible. Y el hecho de que vemos a entrenadores que no se apartan radicalmente de sus principios del juego con mucha más frecuencia que los clubes que cambian de entrenador, sino que permanecen dentro de la misma filosofía (por ejemplo, de improviso, excepto que Ajax viene a la mente y Barcelona es muy cuestionable), habla de que, tal vez, ciertos gerentes revelan jugadores más estables que los clubes. Aunque aquí no me aferraría fuertemente a mi declaración.
De los indicadores puramente estadísticos, la cantidad más alta es simplemente la cantidad de tiempo que un jugador pasó en el campo el año pasado en su competencia principal ( stats_minutes_0 ). Esto es simplemente bastante lógico, porque cuánto este jugador fue el "principal" en su club la temporada pasada parece un indicador estadístico más universal de su éxito que otros, por ejemplo, el número de goles marcados o tarjetas recibidas.
La popularidad del jugador ( pop_log1p ) cierra este grupo de 8 parámetros más importantes. Vale la pena recordar que los datos que hemos presentado durante los últimos 10 años. Creo que la importancia de este campo sería mayor si estuviéramos considerando los últimos 5 años, y para el valor promedio durante la última década, este es un resultado completamente comprensible, especialmente si tenemos en cuenta la brecha del próximo lugar.
Bueno, lo último que me gustaría llamar la atención es la importancia del campo agente ( plr_player_agent ). Dejaré esto sin comentarios, porque si puedes romper los márgenes de las copias en disputas sobre la (falta) necesidad de agentes, entonces no hay duda sobre el grado de su influencia en el mercado moderno de transferencias (aunque el modelo sugiere no sobreestimarlo).

Por cierto, quizás lo más interesante de este método de análisis es su accesibilidad: no es necesario crear un modelo " ideal " para obtener información sobre la importancia de los parámetros. En muchos casos, es suficiente que, al menos, simplemente prediga, es estadísticamente significativamente diferente de lanzar una moneda, y ya obtendrá resultados que a menudo contienen ideas interesantes o le dicen desde qué lado nuevo puede mirar los datos.
Entonces es hora de redondear, para no aumentar el texto tan sobrecargado. Al despedirme, me gustaría instar una vez más a todos los interesados en el tema a que prueben (lo mejor, en mi opinión, para principiantes) el curso de Aprendizaje profundo - fast.ai y apliquen los conocimientos adquiridos en 'su campo de especialización', es probable que sea el primero allí :)
Y si te gusta, trataré de dominar la segunda parte del texto sobre mis experimentos en los que el modelo usando una herramienta igualmente poderosa: la dependencia parcial te dirá: qué cliente de la agencia es mejor para convertirse en jugador de fútbol, qué clubes tienen la política de transferencia más efectiva, qué entrenador aumenta mejor el costo de los jugadores (además de los candidatos obvios, hay muchas 'marcas' no tan promocionadas que claramente merecen una mirada más cercana) y mucho más.
Parte 2 - Modelo de transferencias de fútbol: cavando más profundo