La capacidad de trabajar dentro de un sistema de control de versiones es una habilidad que todo programador necesita. A menudo puede parecer que cavar en Git y comprender sus aspectos internos es una pérdida adicional de tiempo y las tareas básicas se pueden resolver a través de un conjunto básico de comandos.
El equipo de AppsCast, por supuesto, quería saber más, y para obtener asesoramiento sobre la aplicación práctica de todas las características de Git, los chicos recurrieron a
Egor Andreyevich de Square.
 Daniil Popov
Daniil Popov : Hola a todos. Hoy, Yegor Andreyevich de Square se unió a nosotros.
Egor Andreyevich : Hola a todos. Vivo en Canadá y trabajo para Square, una compañía de software y hardware para la industria financiera. Comenzamos con terminales para aceptar pagos con tarjetas de crédito, ahora hacemos servicios para dueños de negocios. Estoy trabajando en un producto de la aplicación Cash. Este es un banco móvil que le permite intercambiar dinero con amigos, solicitar una tarjeta de débito para pagar en las tiendas. La compañía tiene muchas oficinas en todo el mundo, y la oficina canadiense tiene unos 60 programadores.
Daniil Popov : En el entorno de los desarrolladores de Android,
Square es conocido por sus proyectos de código abierto que se han convertido en estándares de la industria: OkHttp, Picasso, Retrofit. Es lógico que al desarrollar tales herramientas abiertas para todos, trabajes mucho con Git. Nos gustaría hablar sobre esto.
Que es git
Egor Andreevich : He estado usando Git durante mucho tiempo como herramienta, y en algún momento me resultó interesante aprender más al respecto.
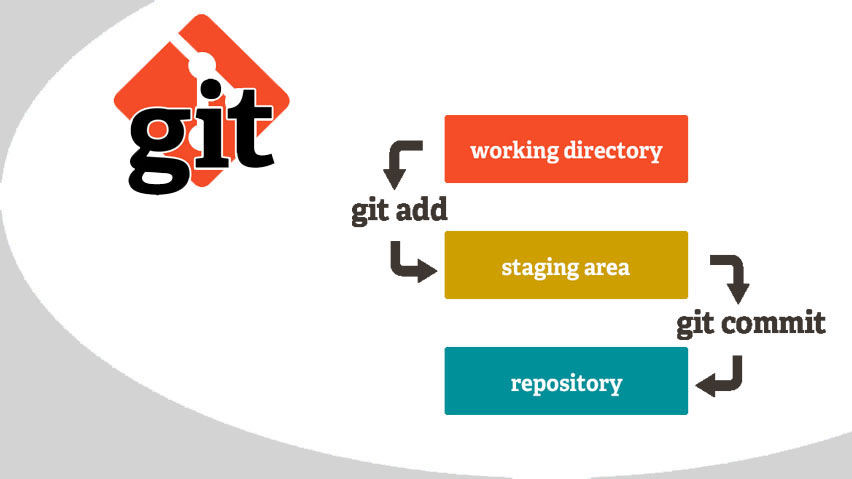
Git es un sistema de archivos simplificado, además de un conjunto de operaciones para trabajar con el control de versiones.
Git te permite guardar archivos en un formato específico. Cada vez que escribe un archivo, Git devuelve la clave a su objeto:
hash .
Daniil Popov : Mucha gente notó que el repositorio tiene un directorio mágico oculto
.git . ¿Por qué es necesario? ¿Puedo eliminarlo o cambiarle el nombre?
Egor Andreevich : Crear un repositorio es posible a través del comando
git init . Crea el directorio
.git que Git usa para controlar los archivos.
.Git almacena todo lo que haces en tu proyecto, solo en formato comprimido. Por lo tanto, puede restaurar el repositorio desde este directorio.
Alexei Kudryavtsev : ¿Resulta que su carpeta de proyecto es una de las versiones de la carpeta Git expandida?
Egor Andreevich : Dependiendo de la rama en la que se encuentre, git restaura un proyecto con el que puede trabajar.
Alexei Kudryavtsev : ¿Qué hay dentro de la carpeta?
Egor Andreevich : Git crea carpetas y archivos específicos. La carpeta más importante es .git / objects, donde se almacenan todos los objetos. El objeto más simple es blob, esencialmente el mismo que un archivo, pero en un formato que git entiende. Cuando desea guardar un archivo de texto en el repositorio, Git lo comprime, lo archiva, agrega datos y crea un blob.
Hay directorios, estas son carpetas con subcarpetas, es decir Git tiene un tipo de objeto de
árbol que contiene referencias a blob, a otros árboles.
Básicamente, un árbol es una instantánea que describe el estado de su directorio en cierto punto.
Al crear una confirmación, se fija un enlace al directorio de trabajo: árbol.
Un commit es un enlace a un árbol con información sobre quién lo creó: correo electrónico, nombre, hora de creación, enlace al padre (rama padre) y mensaje. Git también comprime y escribe confirmaciones en el directorio de objetos.
Para ver cómo funciona todo esto, debe enumerar los subdirectorios desde la línea de comandos.
Beneficios de trabajar con Git
Daniil Popov : ¿Cómo funciona Git? ¿Por qué es tan complicado el algoritmo de acción?
Egor Andreevich : Si compara Git con Subversion (SVN), en el primer sistema hay una serie de funciones que debe comprender. Comenzaré con el
área de preparación , que no debe considerarse una limitación de Git, sino más bien características.
Es bien sabido que cuando se trabaja con código, no todo funciona de inmediato: en algún lugar debe cambiar el diseño, en algún lugar para corregir errores. Como resultado, después de una sesión de trabajo, aparecen varios archivos afectados que no están interconectados. Si realiza todos los cambios en una confirmación, será inconveniente, ya que los cambios son de naturaleza diferente. Luego, una serie de confirmaciones llega a la salida, que se puede crear solo gracias al área de preparación. Por ejemplo, todos los cambios en el archivo de diseño se envían a una serie, por ejemplo, reparan pruebas unitarias a otra. Tomamos varios archivos, los movemos al área de preparación y creamos un compromiso solo con su participación. Otros archivos del directorio de trabajo no entran en él. Por lo tanto, divide todo el trabajo realizado en el directorio de trabajo en varias confirmaciones, cada una de las cuales representa un trabajo específico.
Alexei Kudryavtsev : ¿En qué se diferencia Git de otros sistemas de control de versiones?
Egor Andreevich : Personalmente, comencé con SVN e inmediatamente cambié a Git. Es importante destacar que Git es un sistema de control de versiones descentralizado. Todas las copias del repositorio de Git son exactamente iguales. Cada compañía tiene un servidor donde se encuentra la versión principal, pero no es diferente de la que el desarrollador tiene en la computadora.
SVN tiene un repositorio central y copias locales. Esto significa que cualquier desarrollador puede romper el repositorio central solo.
En Git, esto no sucederá. Si el servidor central pierde los datos del repositorio, se puede restaurar desde cualquier copia local. Git está diseñado de manera diferente y ofrece los beneficios de la velocidad.
Daniil Popov : Git es famoso por su ramificación, que funciona notablemente más rápido que SVN. ¿Cómo lo hace él?
Egor Andreevich : en SVN, una rama es una copia completa de la rama anterior. No hay representación física de rama en Git. Este es un enlace a la última confirmación en una línea de desarrollo particular. Cuando Git guarda objetos, al crear una confirmación, crea un archivo con información específica sobre la confirmación. Git crea un archivo simbólico: enlace simbólico con un enlace a otro archivo. Cuando tiene muchas ramas, se refiere a diferentes confirmaciones en el repositorio. Para rastrear el historial de una rama, debe ir desde cada confirmación utilizando el enlace de regreso a la confirmación principal.
Ramas Merjim
Daniil Popov : Hay dos formas de fusionar dos ramas en una: esto es fusionar y rebase. ¿Cómo los usas?
Egor Andreevich : cada método tiene sus propias ventajas y desventajas.
Combinar es la opción más fácil. Por ejemplo, hay dos ramas: maestra y la función seleccionada de ella.
Para fusionar, puede usar el avance rápido. Esto es posible si desde el momento en que se inició el trabajo en la rama de características, no se realizaron nuevos compromisos en el maestro. Es decir, el primer commit en la función es el último commit en master.
En este caso, el puntero se fija en la rama maestra y se mueve a la confirmación más reciente en la rama característica. De esta forma, la ramificación se elimina conectando la rama de la función al hilo principal principal y eliminando la rama innecesaria. Resulta una historia lineal donde todos los commits se siguen. En la práctica, esta opción ocurre con poca frecuencia, porque constantemente alguien combina commits en master.
Puede ser de otra manera. Git crea un nuevo commit: merge commit, que tiene dos enlaces a los commits primarios: uno en master y otro en feature. Con la nueva confirmación, se conectan dos ramas y la característica se puede eliminar nuevamente.
Después de la confirmación de fusión, puede ver la historia y ver que está bifurcada. Si usa una herramienta que representa gráficamente los commits, visualmente se verá como un árbol de Navidad. Esto no rompe a Git, pero es difícil para un desarrollador ver una historia así.
Otra herramienta es
rebase . Conceptualmente, toma todos los cambios de la rama de características y los voltea sobre la rama maestra. El primer commit de características se convierte en el nuevo commit además del último commit maestro.
Hay una trampa: Git no puede cambiar los commits. Hubo un compromiso en la función y no podemos simplemente envolverlo en maestro, ya que cada compromiso tiene una marca de tiempo.
En el caso de rebase, Git lee todos los commits en la función, los guarda temporalmente y luego los vuelve a crear en el mismo orden en master. Después del rebase, las confirmaciones iniciales desaparecen y aparecen nuevas confirmaciones con el mismo contenido en la parte superior del maestro. Hay problemas Cuando intentas reajustar una rama con la que otras personas trabajan, puedes romper el repositorio. Por ejemplo, si alguien comenzó su rama desde un commit que estaba en función, y usted destruyó y recreó ese commit. Rebase es más adecuado para sucursales locales.
Daniil Popov : si introduce restricciones de que solo una persona trabaja en una rama de características, acepta que no puede ser amigo de una rama de características de otra, entonces este problema no surge. ¿Pero qué enfoque practicas?
Egor Andreevich : No usamos ramas de características en el sentido directo de este término. Cada vez que hacemos un cambio, creamos una nueva rama, trabajamos en ella e inmediatamente la volcamos en master. No hay ramas de larga duración.
Esto resuelve una gran cantidad de problemas con fusión y rebase, especialmente conflictos. Las ramas existen durante una hora y hay una alta probabilidad de usar el avance rápido, ya que nadie ha agregado nada al maestro. Cuando fusionamos en la solicitud de extracción, solo combinamos con la creación de confirmación de fusión
Daniil Popov : ¿Cómo no temes fusionar una característica inactiva maestra, porque descomponer una tarea en intervalos por hora a menudo no es realista?
Egor Andreevich : Utilizamos el enfoque de
banderas de características . Estas son banderas dinámicas, una característica específica con diferentes estados. Por ejemplo, la función de enviar pagos entre sí está activada o desactivada. Tenemos un servicio que entrega dinámicamente este estado a los clientes. Usted del servidor obtiene el valor de la función o no. Puede usar este valor en el código; apague el botón que va a la pantalla. El código en sí está en la aplicación y se puede liberar, pero no hay acceso a esta funcionalidad porque está detrás del indicador de función.
Daniil Popov : A menudo, a los recién llegados a Git se les dice que después de rebase hay que empujar con fuerza. De donde es
Egor Andreevich : cuando simplemente presiona, otro repositorio puede arrojar un error: está intentando iniciar una rama, pero tiene confirmaciones completamente diferentes en esta rama. Git verifica toda la información para que no rompa accidentalmente el repositorio. Cuando diga
git push force , apague este cheque, creyendo que sabe más que él, y exija reescribir la rama.
¿Por qué es necesario esto después de rebase? Rebase vuelve a crear confirmaciones. Resulta que la rama también se llama, pero se compromete con otros hashes, y Git te insulta. En esta situación, es absolutamente normal hacer un esfuerzo forzado, ya que usted tiene el control de la situación.
Daniil Popov : Todavía existe el concepto de
rebase interactivo , y muchos le temen.
Egor Andreevich : No hay nada terrible. Debido al hecho de que Git recrea la historia durante el rebase, la almacena temporalmente antes de lanzarla. Cuando tiene almacenamiento temporal, puede hacer cualquier cosa con commits.
Rebase en modo interactivo asume que Git antes del rebase arroja una ventana de un editor de texto en el que puede especificar lo que debe hacerse con cada confirmación individual. Parece varias líneas de texto, donde cada línea es una de las confirmaciones que están en la rama. Antes de cada confirmación, hay una indicación de la operación que vale la pena realizar. La operación predeterminada más simple es
pick , es decir tomar e incluir en rebase. El más común es el
squash , luego Git tomará los cambios de este commit y lo combinará con los cambios del anterior.
A menudo existe tal escenario. Trabajó localmente en su sucursal y creó commits para guardar. El resultado es una larga historia de confirmaciones, lo cual es interesante para usted, pero de la misma manera no debe verterse en la historia principal. Luego le das squash para cambiarle el nombre al commit general.
La lista de equipos es larga. Puede lanzar el commit -
drop y desaparece, puede cambiar el mensaje de commit, etc.
Alexei Kudryavtsev : Cuando tienes conflictos en rebase interactivo, pasas por todos los círculos del infierno.
Egor Andreevich : Estoy muy lejos de comprender toda la sabiduría del rebase interactivo, pero es una herramienta poderosa y compleja.
Aplicación práctica de Git
Daniil Popov : Pasemos a practicar. En la entrevista, a menudo pregunto: “Tienes mil compromisos. En la primera todo está bien, en la milésima prueba se rompió. ¿Cómo se puede encontrar el cambio que condujo a esto con la ayuda de un gita?
Egor Andreevich : En esta situación, debes usar
bisect , aunque es más fácil echarle la culpa.
Comencemos con el interesante. Git bisect es aplicable a una situación en la que tiene regresión: fue funcional, funcionó, pero de repente se detuvo. Para saber cuándo se ha roto la funcionalidad, teóricamente puede retroceder aleatoriamente a la versión anterior de la aplicación, mirar el código, pero hay una herramienta que le permitirá abordar el problema de forma estructurada.
Git bisect es una herramienta interactiva. Hay un comando incorrecto de git bisect a través del cual informa sobre la presencia de un commit roto y git bisect bueno - para un commit de trabajo. Cada vez que se lanza la aplicación, recordamos el hash del commit desde el que se realizó el lanzamiento. Este hash también se puede usar para indicar confirmaciones malas y buenas. Bisect recibe información sobre el intervalo en el que uno de los commits rompió la funcionalidad e inicia una sesión de
búsqueda binaria , donde gradualmente emite commits para verificar si funcionan o no.
Comenzaste la sesión, Git cambia a una de las confirmaciones en el intervalo, informa esto. En el caso de mil commits, no habrá muchas iteraciones.
La verificación tendrá que hacerse manualmente: a través de pruebas unitarias o ejecute la aplicación y haga clic manualmente. Git bisect es convenientemente programable. Cada vez que emite un commit, le das un script para verificar que el código está funcionando.
La culpa es una herramienta más simple que, según su nombre, le permite encontrar al "culpable" de una falla funcional. Debido a esta definición negativa, a muchos en la comunidad de la culpa no les gusta.
Que esta haciendo el Si le da a git blame un archivo específico, entonces linealmente en este archivo mostrará qué confirmación cambió esta o aquella línea. Nunca he usado git blame desde la línea de comando. Como regla, esto se hace en IDEA o Android Studio: haga clic y vea quién cambió qué línea del archivo y en qué confirmación.
Daniil Popov : Por cierto, en Android Studio se llamaba Annotate. La connotación negativa de culpa ha sido eliminada.
Alexei Kudryavtsev : Exactamente, en xCode lo renombraron Autores.
Egor Andreevich : También leí que hay un gran elogio de utilidad: encontrar al que escribió este excelente código.
Daniil Popov : Cabe señalar que por culpa de las sugerencias de los revisores sobre el trabajo de solicitud de extracción. Él mira quién tocó un archivo en particular sobre todo, y sugiere que esta persona podrá revisar bien su código.
En el caso del ejemplo, alrededor de mil commits, la culpa en el 99% de los casos mostrará lo que salió mal. Bisect ya es el último recurso.
Egor Andreevich : Sí, recurro a la bisección extremadamente rara, pero uso anotar regularmente. Aunque a veces es imposible entender por qué no se verifica desde la línea de código, está claro a lo largo de la confirmación lo que el autor quería hacer.
¿Cómo trabajar con PR apiladas?
Daniil Popov : Escuché que Square usa solicitudes de extracción apiladas (PR).
Egor Andreevich : Al menos en nuestro equipo de Android a menudo los usamos.
Dedicamos mucho tiempo a hacer que cada solicitud de extracción sea fácil de revisar. A veces existe la tentación de alimentar, alimentar rápidamente y dejar que los revisores lo entiendan. Intentamos crear pequeñas solicitudes de extracción y una breve descripción: el código debe hablar por sí mismo. Cuando las solicitudes de extracción son pequeñas, es fácil y rápido gritar.
Aquí es donde surge el problema. Está trabajando en una función que requerirá una gran cantidad de cambios en la base del código. Que puedes hacer Puede ponerlo en una solicitud de extracción, pero luego será enorme. Puede trabajar creando gradualmente una solicitud de extracción, pero el problema será que creó una rama, agregó algunos cambios y envió una solicitud de extracción, regresó al maestro y el código que tenía en la solicitud de extracción no está disponible en el maestro hasta la fusión no sucederá. Si depende de los cambios en estos archivos, es difícil continuar trabajando porque no existe dicho código.
¿Cómo lo solucionamos? Después de crear la primera solicitud de extracción, seguimos trabajando, creando una nueva rama a partir de la rama existente, que utilizamos antes de la solicitud de extracción. Cada rama no proviene del maestro, sino de la rama anterior. Cuando terminemos de trabajar en esta pieza de funcionalidad, envíe otra solicitud de extracción e indique nuevamente que con la fusión no se fusiona en el maestro, sino en la rama anterior. Resulta una cadena de solicitudes de extracción: prs apiladas. Cuando una persona revisa, ve los cambios realizados solo por esta función, pero no por la anterior.
La tarea es hacer que cada solicitud de extracción sea lo más pequeña y clara posible para que no sea necesario cambiarla. Porque si tiene que cambiar el código en las ramas que están en el medio de apiladas, todo en la parte superior se romperá, ya que debe hacer un rebase. Si las solicitudes de extracción son pequeñas, intentamos congelarlas lo antes posible, y luego todas las combinaciones apiladas se convierten en maestras paso a paso.
Daniil Popov : Entiendo correctamente que al final habrá una última solicitud de extracción que contiene todas las solicitudes de extracción pequeñas. ¿Vienes este hilo sin mirar?
Egor Andreevich : Merge proviene de la fuente apilada: primero, la primera solicitud de extracción se fusiona en master, en la siguiente, la base cambia de la rama a master y, en consecuencia, Git calcula que ya hay algunos cambios en master, menos instantánea.
: , , , master?
: , . pull request, , , , bitbucket, merge.
: CI, ?
: . CI , pull request base. , .
: master develop? , ?
: develop, master. . , - - master, . tags — - . - — -, , . , Git , .
: Git, ?
: Git
. , , . , . StackOverflow . .
Saint AppsConf Git . Introductory, . Avito : , 2019 .
AppsCast , , SoundCloud , .