Hola Tenemos más de 15,260 objetos y 38,000 dispositivos de red que deben configurarse, actualizarse y verificarse para que funcionen. Mantener tal flota de equipos es bastante difícil y requiere mucho tiempo, esfuerzo y personas. Por lo tanto, necesitábamos automatizar el trabajo con equipos de red y decidimos adaptar el concepto de Red como Código para administrar la red en nuestra empresa. Debajo del corte, lea nuestro historial de automatización, los errores cometidos y un plan adicional para construir sistemas.
Larga historia corta, queremos automatizar la red
Hola Mi nombre es Alexander Prokhorov y, junto con el equipo de ingenieros de redes de nuestro departamento, estamos
trabajando en una red en
#IT X5 . Nuestro departamento desarrolla infraestructura de red, monitoreo, automatización de red y la dirección moderna de Network as a Code.
Inicialmente, en realidad no creía en ninguna automatización en nuestra red. Quedaban muchos errores heredados y de configuración: no en todas partes había una autorización central, no todo el hardware soportaba SSH, no todo
SNMP estaba configurado. Todo esto minó en gran medida la creencia en la automatización. Por lo tanto, en primer lugar, arreglamos lo que se necesita para iniciar la automatización, a saber: estandarización de la conexión SSH, autorización única (
AAA ) y perfiles SNMP. Toda esta base le permite escribir una herramienta para la entrega masiva de configuraciones a un dispositivo, pero surge la pregunta: ¿puedo obtener más? Entonces llegamos a la necesidad de elaborar un plan para el desarrollo de la automatización y, en particular, el concepto de Red como Código.
El concepto de red como código, según Cisco, significa los siguientes principios:
- Almacene configuraciones de destino en el repositorio, control de origen
- Los cambios de configuración pasan por el repositorio, Fuente única de verdad
- Incrustar configuraciones a través de la API

Los primeros dos puntos le permiten aplicar el enfoque DevOps o NetDevOps para administrar su infraestructura de red. Con el tercer párrafo hay dificultades, por ejemplo, ¿qué hacer si no hay API? ¡Por supuesto, SSH y CLI, somos networkers!
¿Y eso es todo lo que necesitamos?La aplicación de estos principios por sí sola no resuelve todos los problemas de la infraestructura de red, así como su aplicación requiere una cierta base con los datos de la red.
Preguntas que surgieron cuando pensamos en esto:
- OK, guardo la configuración como código, ¿cómo debo aplicarla en un objeto específico?
- Ok, tengo una plantilla de configuración en el repositorio, pero ¿cómo puedo configurar automáticamente una configuración para un objeto basado en él?
- ¿Cómo averiguar qué modelo y qué proveedor debe estar en este objeto? ¿Puedo hacerlo automáticamente?
- ¿Cómo puedo verificar si la configuración actual del objeto coincide con los parámetros en el repositorio?
- ¿Cómo trabajar con cambios en el repositorio y replicarlos en una red productiva?
- ¿Qué conjunto de datos y sistemas necesito para pensar en el aprovisionamiento Zero Touch?
- ¿Qué pasa con las diferencias en los proveedores, e incluso los modelos del mismo proveedor?
- ¿Cómo almacenar subredes para la configuración automática?
En base a todas las preguntas anteriores, quedó claro que necesitamos un conjunto de sistemas que resuelvan varios problemas, trabajen en conjunto y nos brinden información completa sobre la infraestructura de la red.

Además de tratar de aplicar nuevos enfoques para la gestión de la red, queríamos resolver algunos problemas más graves en la infraestructura de la red, como la integridad de los datos, la actualización y, por supuesto, la automatización. Por automatización nos referimos no solo a la entrega masiva de configuraciones a los equipos, sino también a la configuración automática, la recopilación automática de datos de inventario de equipos de red y la integración con los sistemas de monitoreo. Pero lo primero es lo primero.
La funcionalidad a la que apuntamos es:
- Base de datos de equipos de red (+ descubrimiento, + actualización automática)
- Direcciones de red base (IPAM + verificaciones de validación)
- Integración de sistemas de monitoreo con datos de inventario.
- Almacenamiento de estándares de configuración en el sistema de control de versiones.
- Formación automática de configuraciones de destino para un objeto.
- Entrega masiva de configuraciones a equipos de red
- Implemente un proceso de CI / CD para administrar los cambios de configuración de red
- Probar configuraciones de red con CI / CD
- ZTP (Zero Touch Provisioning): configuración automática de equipos para un objeto
Larga historia, intentamos la automatizaciónComenzamos a intentar automatizar el trabajo de configuración de la red hace 2 años. ¿Por qué ahora vuelve a surgir esta pregunta y necesita atención?
Es aburrido y aburrido configurar más de una docena de dispositivos con las manos. A veces la mano del ingeniero se contrae, y él comete errores. Para varias docenas, una secuencia de comandos escrita por un ingeniero suele ser suficiente, lo que transfiere la configuración actualizada al equipo de red.
¿Por qué no parar allí? De hecho, muchos ingenieros de redes ya saben cómo hacer todo tipo de pitones, y aquellos que no saben cómo hacerlo ya podrán hacerlo muy pronto (Natalya Samoilenko, sin embargo, ha publicado
un excelente trabajo en Python , especialmente para los networkers). Cualquiera que tenga la tarea de configurar n + 1 enrutadores puede escribir un script y desplegar la configuración muy rápidamente. Mucho más rápido que entonces capaz de recuperar todo. Según la experiencia de la automatización "cada hombre por sí mismo", se producen errores cuando puede restablecer la comunicación solo con las manos y con un gran sufrimiento de todo el equipo.

Ejemplo
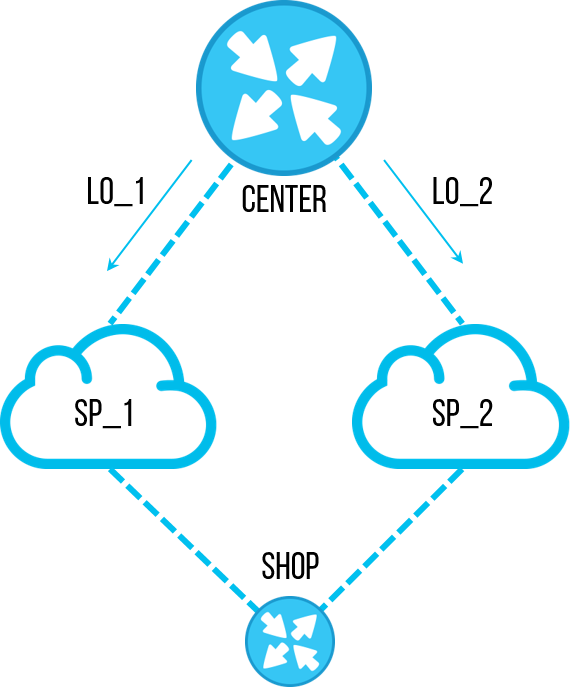
Una vez, uno de los ingenieros decidió realizar una tarea importante: restablecer el orden en las configuraciones de los enrutadores. Como resultado de la auditoría en varios objetos, se encontró una
lista de prefijos obsoleta con subredes específicas, que ya no necesitábamos. Anteriormente, se usaba para filtrar las direcciones de
bucle de
retorno de los sitios centrales para que pasaran por un solo canal, y pudimos probar la conexión en este canal. Pero el mecanismo fue optimizado y dejaron de usar un esquema de prueba de canal. El empleado decidió eliminar esta
lista de prefijos para que no aparezca en la configuración y cause confusión en el futuro. Todos acordaron eliminar la
lista de prefijos no utilizada, la tarea es simple, se olvidaron de inmediato. Pero eliminar la misma
lista de prefijos con tus manos en docenas de objetos es bastante aburrido y requiere mucho tiempo. Y el ingeniero escribió un guión que pasará rápidamente por el equipo, hará
"ninguna lista de prefijos pl-cisco-primer" y guardará solemnemente la configuración.
Algún tiempo después de la discusión, unas pocas horas o un día, no recuerdo, cayó un objeto. Después de un par de minutos, otro similar. El número de objetos inaccesibles continuó creciendo, en media hora a 10, y cada 2-3 minutos se agregó uno nuevo. Todos los ingenieros estaban conectados para el diagnóstico. 40-50 minutos después del inicio del accidente, todos fueron interrogados sobre los cambios y el empleado detuvo el guión. En ese momento, ya había unos 20 objetos con canales rotos. Una restauración completa tomó 7 ingenieros durante varias horas.
Lado técnico
La lista de prefijos se usó para filtrar
bucles de retroceso : uno se filtró en un canal, el segundo en la copia de seguridad. Esto se usó para probar la comunicación sin cambiar el tráfico productivo entre canales. Por lo tanto, la primera regla de un
mapa de ruta entrante en un vecino
BGP era
NEGAR con
"lista de prefijos de dirección IP de coincidencia" . El resto de las reglas en
el mapa de ruta eran
PERMISO .
Hay varios matices que vale la pena señalar:
- La regla del mapa de ruta en la que no hay coincidencia : omite todo
- Al final de la lista de prefijos está implícitamente negar , pero solo si no está vacía
- Una lista de prefijos vacía es un permiso implícito
Todo lo anterior es cierto para
Cisco IOS . Puede aparecer
una lista de prefijos vacía cuando declara un
mapa de ruta , haga que
"coincida con la lista de prefijos de direcciones IP pl-test-cisco" . Esta
lista de prefijos no se declarará explícitamente en la configuración (además de la línea con
coincidencia ), pero se puede encontrar en
show ip prefix-list .
2901-NOC-4.2(config)#route-map rm-test-in 2901-NOC-4.2(config-route-map)#match ip address prefix-list pl-test-in 2901-NOC-4.2(config-route-map)#do sh run | i prefix match ip address prefix-list pl-test-in 2901-NOC-4.2(config-route-map)#do sh ip prefix ip prefix-list pl-test-in: 0 entries 2901-NOC-4.2(config-route-map)#
Volviendo a lo que sucedió, cuando el script eliminó la
lista de prefijos , quedó vacía, porque todavía estaba en la primera regla
DENY en el
mapa de ruta . Una
lista de prefijos vacía permite todas las subredes, por lo que todo lo que nos pasó un par
BGP cayó en la primera regla
DENY .
¿Por qué el ingeniero no se dio cuenta de inmediato de que había roto la conexión? Aquí jugó el papel de temporizadores
BGP en Cisco.
BGP en sí no intercambia rutas en un horario, y si actualizó la política de enrutamiento de
BGP , debe restablecer la sesión de BGP para aplicar los cambios,
"clear ip bgp <peer-ip>" a Cisco.
Para no restablecer la sesión, hay dos mecanismos:
- Cisco Soft-Reconfiguration
- Actualización de ruta como RFC2918
La reconfiguración suave contiene la información recibida en
ACTUALIZACIÓN del vecino sobre las rutas hasta que las políticas se apliquen en la tabla
adj-RIB-in local. Al actualizar las políticas, es posible emular la
ACTUALIZACIÓN de un vecino.
La actualización de ruta es la "capacidad" de los pares para enviar
ACTUALIZACIÓN a pedido. La disponibilidad de esta oportunidad se acuerda al establecer un vecindario. Pros: no es necesario almacenar una copia de
ACTUALIZACIÓN localmente. Contras: en la práctica, después de una solicitud de
ACTUALIZACIÓN de un vecino, debe esperar hasta que él la envíe. Por cierto, puede deshabilitar la función en Cisco con un comando oculto:
neighbor <peer-ip> dont-capability-negotiate
Hay una característica no documentada de Cisco: un temporizador de 30 segundos, que se activa por un cambio en
las políticas de
BGP . Después de cambiar las políticas, en 30 segundos comenzará el proceso de actualización de rutas utilizando una de las tecnologías anteriores. No pude encontrar una descripción documentada de este temporizador, pero hay una mención de él en
BUG CSCvi91270 . Puede conocer su disponibilidad en la práctica,

después de realizar cambios en el laboratorio y buscar en
depuración las solicitudes de
ACTUALIZACIÓN para el vecino o el
proceso de reconfiguración de software . (Si hay información adicional sobre el tema, puede dejarla en los comentarios)
Para
la reconfiguración suave , el temporizador funciona así:
2901-NOC-4.2(config)#no ip prefix-list pl-test seq 10 permit 10.5.5.0/26 2901-NOC-4.2(config)#do sh clock 16:53:31.117 Tue Sep 24 2019 Sep 24 16:53:59.396: BGP(0): start inbound soft reconfiguration for Sep 24 16:53:59.396: BGP(0): process 10.5.5.0/26, next hop 10.0.0.1, metric 0 from 10.0.0.1 Sep 24 16:53:59.396: BGP(0): Prefix 10.5.5.0/26 rejected by inbound route-map. Sep 24 16:53:59.396: BGP(0): update denied, previous used path deleted Sep 24 16:53:59.396: BGP(0): no valid path for 10.5.5.0/26 Sep 24 16:53:59.396: BGP(0): complete inbound soft reconfiguration, ran for 0ms Sep 24 16:53:59.396: BGP: topo global:IPv4 Unicast:base Remove_fwdroute for 10.5.5.0/26 2901-NOC-4.2(config)#
Para
la actualización de
ruta desde el lado del vecino así:
2801-RTR (config-router)# *Sep 24 20:57:29.847 MSK: BGP: 10.0.0.2 rcv REFRESH_REQ for afi/sfai: 1/1 *Sep 24 20:57:29.847 MSK: BGP: 10.0.0.2 start outbound soft reconfig for afi/safi: 1/1
Si
Route-Refresh no
es compatible con uno de los pares y la
entrada de reconfiguración suave no
está habilitada, entonces la actualización de rutas por la nueva política no se realizará automáticamente.
Entonces,
la lista de prefijos se eliminó, la conexión permaneció, después de 30 segundos desapareció. El script logró cambiar la configuración, verificar la conexión y guardar la configuración. La caída del guión no se conectó de inmediato, en el contexto de una gran cantidad de objetos.
Todo esto podría evitarse fácilmente mediante la prueba, la replicación parcial de la configuración. Se entendió que la automatización debería centralizarse y controlarse.

Los sistemas que necesitamos y sus conexiones.
Una breve conclusión del spoiler: es mejor sistematizar y controlar el proceso de entrega masiva de configuraciones para no llegar a la entrega masiva de errores en las configuraciones.
- DevOps: 50ms 4 - : ", !@#$%"
El esquema al que llegamos consiste en bloques de datos maestros "comerciales", bloques de datos maestros "red", sistemas de monitoreo de infraestructura de red, sistemas de entrega de configuración, sistemas de control de versiones con una unidad de prueba.
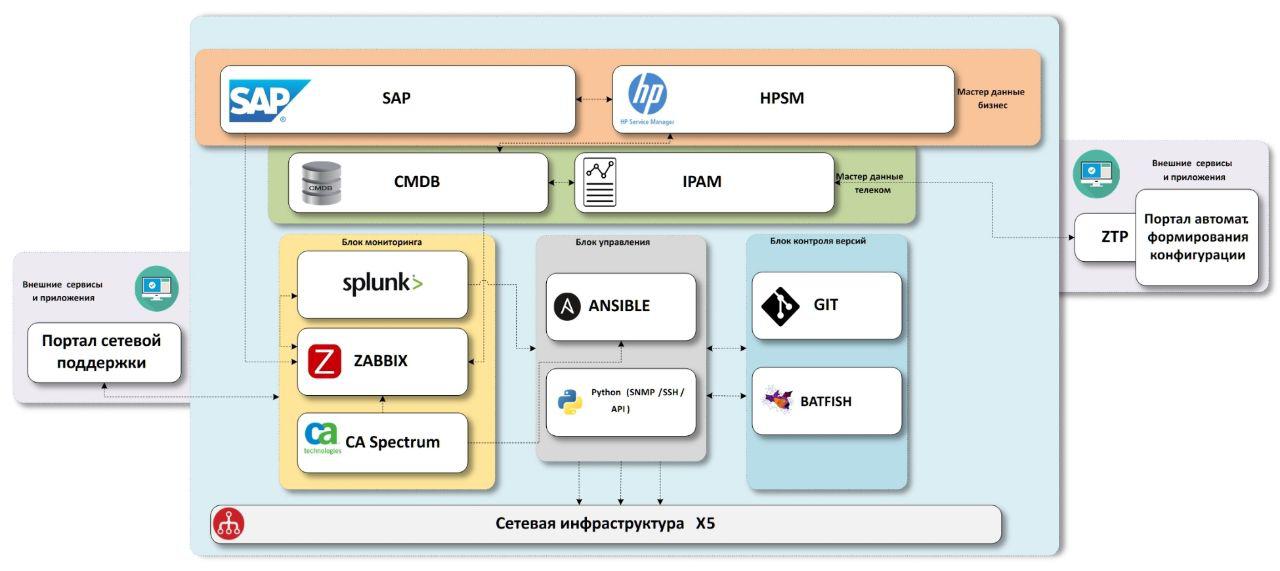
Todo lo que necesitamos son datos
Primero necesitamos saber qué objetos hay en la empresa.
SAP - Sistema de empresa
ERP . Los datos sobre casi todas las instalaciones están allí, y más precisamente en todas las tiendas y centros de distribución. Además, hay datos sobre equipos que pasaron por un almacén de TI con números de inventario, que también nos serán útiles en el futuro. Solo faltan oficinas, no se inician en el sistema. Estamos tratando de resolver este problema como un proceso separado, comenzando desde el momento de la apertura, necesitamos una conexión en cada objeto y seleccionamos las configuraciones para la comunicación, por lo que en algún momento en este momento necesitamos crear datos maestros. Pero la insuficiencia de datos es un tema separado, es mejor poner esta descripción en un artículo separado si hay interés en esto.
HPSM : un sistema que contiene un
CMDB común para TI, gestión de incidentes, gestión de cambios. Dado que el sistema es común a todas las TI, debe tener todos los equipos de TI, incluidos los equipos de red. Este es el lugar donde agregaremos todos los datos finales a través de la red. Con la gestión de incidentes y cambios, planeamos interactuar desde los sistemas de monitoreo en el futuro.
Sabemos qué objetos tenemos, los enriquecemos con datos a través de la red. Para este propósito, tenemos dos sistemas:
IPAM de
SolarWinds y nuestro propio sistema CMDB.noc.
IPAM es un repositorio de subredes IP, los datos más correctos y correctos sobre la propiedad de las direcciones IP en la empresa deben estar aquí.
CMDB.noc es una base de datos con una interfaz WEB donde se almacenan datos estáticos en equipos de red: enrutadores, conmutadores, puntos de acceso, así como proveedores y sus características. Bajo estático significa que su cambio se lleva a cabo solo con la participación del hombre. En otras palabras, la detección automática no realiza cambios en esta base de datos; necesitamos que comprenda qué "debería" instalarse en el objeto. Su base es necesaria como un amortiguador entre los sistemas productivos con los que trabaja toda la empresa y las herramientas de red internas. Acelera el desarrollo, agregando los campos necesarios, nuevas relaciones, ajustando parámetros, etc. Además, esta solución no solo está en la velocidad de desarrollo, sino también en la presencia de esas relaciones entre los datos que necesitamos, sin compromiso. Como mini-ejemplo, utilizamos varios
exid en la base de datos para la comunicación entre IPAM, SAP y HPSM.
Como resultado, recibimos datos completos de todos los objetos, con equipos de red y direcciones IP conectados. Ahora necesitamos plantillas de configuración o servicios de red que proporcionamos en estos sitios.

Fuente única de verdad
Aquí, acabamos de llegar a la aplicación del primer principio NaaC: almacenar configuraciones de destino en el repositorio. En nuestro caso, este es Gitlab. La elección para nosotros fue simple:
- En primer lugar, ya tenemos esta herramienta en nuestra empresa, no tuvimos que implementarla desde cero
- En segundo lugar, es bastante adecuado para todas nuestras tareas actuales y futuras en infraestructura de red
La principal parte interesante de la automatización sucederá en Gitlab: el proceso de cambiar el estándar de configuración o, más simplemente, la plantilla.
Ejemplo de proceso de cambio estándar
Uno de los tipos de objetos que tenemos es la tienda Pyaterochka. Allí, una topología típica consiste en un enrutador y uno / dos conmutadores. El archivo de configuración de la plantilla se almacena en Gitlab, en esta parte todo es simple. Pero esto no es del todo NaaC.
Ahora digamos que nos llega un nuevo proyecto. Las tareas para el nuevo proyecto de TI son hacer un piloto en un cierto volumen de tiendas. De acuerdo con los resultados del piloto: si tiene éxito, realice una replicación para todos los objetos de este tipo; de lo contrario, colapsar el piloto sin realizar una replicación.
Este proceso encaja muy bien en la lógica de Git:
- Para un nuevo proyecto, creamos una Rama, donde hacemos cambios a las configuraciones.
- En Branch también mantenemos una lista de objetos en los que se está probando este proyecto.
- Si tiene éxito, hacemos una solicitud de fusión en la rama maestra, que deberá replicarse en la red prod
- En caso de falla, deje Branch para el historial o simplemente elimine

En una primera aproximación, incluso sin automatización, es una herramienta muy conveniente para trabajar juntos en una configuración de red. Especialmente si imagina que se presentaron tres o más proyectos al mismo tiempo. Cuando llegue el momento del lanzamiento de proyectos en prod, deberá resolver todos los conflictos de configuración en las solicitudes de fusión y verificar que los cambios en la configuración no sean mutuamente excluyentes. Y esto es muy conveniente de hacer en git.
Además, este enfoque nos agrega la flexibilidad para usar las herramientas Gitlab CI / CD para probar configuraciones virtualmente, para automatizar la entrega de configuraciones a un banco de pruebas o un grupo piloto de objetos. // E incluso en prod si quieres.
Implementación de la configuración en cualquier entorno.
Inicialmente, el objetivo principal era precisamente la entrega masiva de configuraciones, como una herramienta que claramente le permite ahorrar tiempo a los ingenieros y acelerar la ejecución de las tareas de configuración. Para hacer esto, incluso antes del comienzo de la gran actividad "Red como un código", escribimos una solución de
Python para conectarse al equipo, ya sea para recopilar configuraciones de equipos o para configurarlo. Esto es
netmiko , esto es
pysnmp , esto es
jinja2 , etc.
Pero es hora de que dividamos la configuración masiva en varias subespecies:
Entrega de configuraciones a zonas de prueba y piloto.Este elemento se basa en Gitlab CI, que le permite habilitar la entrega de configuración a las zonas piloto y de prueba en la tubería.
Duplicación de configuraciones en prod- Un elemento separado, la mayoría de las veces, la replicación a dispositivos de 38k se lleva a cabo en varias ondas, aumentando el volumen, para monitorear la situación en producción. Además, el trabajo de esta magnitud requiere la coordinación del trabajo, por lo tanto, es mejor comenzar este proceso a mano. Para esto, es conveniente usar Ansible + -AWX y ajustar la compilación dinámica del inventario de nuestros sistemas de datos maestros.
- Además, esta es una solución conveniente cuando necesita darle a la segunda línea el lanzamiento de libros de jugadas preconfigurados que realizan operaciones complejas e importantes, como cambiar el tráfico entre sitios.
Recogida de datos- Detección automática de dispositivos de red
- Configuraciones de respaldo
- Verificar conectividad
Asignamos esta tarea en un bloque separado, ya que hay momentos en que alguien desmanteló repentinamente un interruptor o instaló un nuevo dispositivo, pero no lo sabíamos de antemano. En consecuencia, este dispositivo no estará en nuestros datos maestros y quedará fuera del proceso de entrega de configuración, monitoreo y, en general, trabajo operativo. Sucede que el equipo se instaló legítimamente, pero la configuración se "vertió" incorrectamente allí y, por alguna razón, las contraseñas
ssh ,
snmp ,
aaa o no estándar para el acceso no funcionan allí. Para hacer esto, tenemos Python para probar todos los métodos de conexión
heredados posibles que podríamos tener en la empresa, hacer fuerza bruta para todas las contraseñas antiguas, y todo para llegar al trozo de hierro y prepararlo para trabajar con
Ansible y monitorear .
Hay una manera simple: hacer varios archivos de
inventario para ansible, donde describir todos los datos posibles para las conexiones (todos los tipos de proveedores con todos los pares posibles de nombre de usuario / contraseña) y ejecutar un
libro de
jugadas para cada variante de
inventario . Esperábamos una mejor solución, pero en la conferencia de RedHat, el arquitecto de Ansible aconsejó lo mismo. En general, se supone que sabe de antemano a qué se está conectando.
Queríamos una solución universal: cuando elimine una copia de seguridad, busque nuevos equipos y, si los encuentra, agréguelos a todos los sistemas necesarios. Por lo tanto, elegimos una solución en python: sepa qué podría ser más hermoso que un programa que puede detectar una pieza de hardware de red para conectarse, independientemente de lo que esté configurado en él (dentro de límites razonables, por supuesto), configurar según sea necesario, eliminar la configuración y, al mismo tiempo, Agregue datos de API a los sistemas requeridos.
Verificación como Monitoreo
Una de las tareas de la automatización es, por supuesto, averiguar qué se cayó de esta automatización. No todos los 38k están configurados perfectamente la primera vez, incluso sucede que alguien configura el equipo con sus manos. Y es necesario rastrear estos cambios y restaurar la
justicia en la configuración de destino.
Existen tres enfoques para verificar el cumplimiento de la configuración con el estándar:
- Haga una verificación una vez por período: descargue el estado actual, verifique el objetivo y corrija las deficiencias identificadas.
- Sin verificar nada, una vez al período: despliegue las configuraciones de destino. Es cierto que existe el riesgo de romper algo, tal vez no haya todo en la configuración de destino.
- Un enfoque conveniente es cuando las diferencias de la configuración de destino en Single Source of Truth se consideran alertas y son monitoreadas por el sistema de monitoreo. Esto incluye: un desajuste con el estándar de configuración actual, una diferencia entre el hardware y el especificado en los datos maestros, un desajuste con los datos en IPAM .
En el tercer caso, una opción parece transferir este trabajo a la gestión de incidentes (SO), de modo que las inconsistencias se eliminan en pequeñas porciones durante todo el tiempo que una vez por emergencia.
Zabbix , sobre el que escribí anteriormente en el artículo
"Cómo monitoreamos 14,000 objetos", es nuestro sistema de monitoreo de objetos distribuidos donde podemos hacer cualquier disparador y alerta que podamos pensar. Desde que escribimos el último artículo, hemos actualizado a Zabbix 4.0
LTS .
Basado en
Web Zabbix, realizamos una actualización de nuestro portal de soporte de red, donde ahora puede encontrar toda la información sobre un objeto de todos nuestros sistemas en una pantalla, así como ejecutar scripts para verificar si ocurren problemas frecuentes.
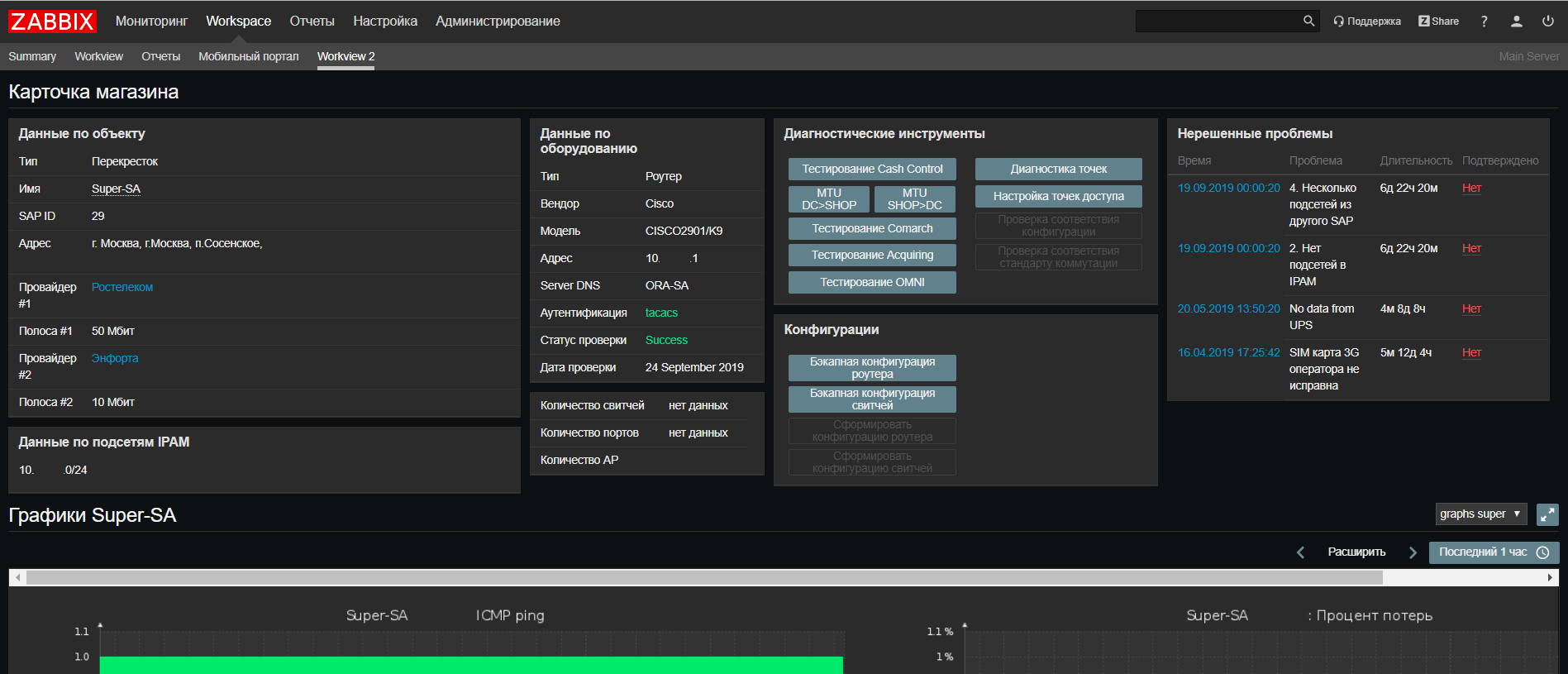
También presentamos una nueva característica: para nosotros, Zabbix se convirtió de alguna manera en un
CRON para el lanzamiento de scripts programados, como scripts de integración de sistemas, scripts de detección automática. Esto es realmente conveniente cuando necesita ver los scripts actuales y cuándo y dónde se ejecutan sin verificar todos los servidores. Es cierto que para los scripts que se ejecutan durante más de 30 segundos, necesitará un
lanzador que los inicie sin esperar el final. Afortunadamente, es simple:
 Splunk
Splunk es una solución que le permite recopilar registros de eventos de equipos de red, y esto también se puede utilizar para monitorear la automatización. Por ejemplo, al recopilar una copia de seguridad de la configuración, un script de
Python genera un mensaje de
REGISTRO CFG-5-BACKUP , un enrutador o conmutador envía un mensaje a Splunk, en el que contamos el número de mensajes de este tipo del equipo de red. Esto nos permite rastrear la cantidad de equipo que el script ha detectado. Y vemos cuántas piezas de hierro pudieron informar esto a
Splunk y verificar que llegaron mensajes de todas las piezas de hierro.
Spectrum es un sistema integral que utilizamos para monitorear objetos críticos, una herramienta bastante poderosa que nos ayuda mucho a resolver incidentes críticos de la red. En automatización, lo usamos solo extrayendo datos de él, no es
de código abierto , por lo que las posibilidades son algo limitadas.
La guinda del pastel

Al usar sistemas con datos maestros en el equipo, podemos pensar en crear ZTP o Zero Touch Provisioning. Como un botón de "autoajuste", pero solo sin un botón.
Tenemos todos los datos necesarios de los bloques anteriores: conocemos el objeto, su tipo, qué equipo hay (proveedor y modelo), cuáles son las direcciones (IPAM), cuál es el estándar de configuración actual (Git). Al unirlos todos, al menos podemos preparar una plantilla de configuración para cargarla en el dispositivo, será más como One Touch Provisioning, pero a veces no se requiere más.
True Zero Touch necesita una forma de entregar automáticamente la configuración al hardware no configurado. Además, es deseable independientemente del proveedor. Hay varias opciones de trabajo: un servidor de consola, si todo el equipo pasa por el almacén central, soluciones de consola móvil, si el equipo llega de inmediato. Solo estamos trabajando en estas soluciones, pero tan pronto como haya una opción de trabajo, podemos compartirla.
Conclusión
En total, en nuestro concepto de
Red como Código , hubo 5 hitos principales:
- Datos maestros (comunicación de sistemas y datos entre sí, API de sistemas, suficiencia de datos para soporte y lanzamiento)
- Monitoreo de datos y configuraciones (detección automática de dispositivos de red, verificación de la relevancia de la configuración en la instalación)
- Control de versiones, pruebas y configuraciones piloto (Gitlab CI / CD aplicado a la red, herramientas de prueba de configuración de red)
- Entrega de configuración (Ansible, AWX, scripts de python para conectar)
- Aprovisionamiento Zero Touch (qué datos se necesitan, cómo construir un proceso para que sea así, cómo conectarse a una pieza de hardware no configurada)
No funcionó para encajar todo en un artículo, cada elemento merece una discusión separada, podemos hablar de algo ahora, de algo cuando verificamos las soluciones en la práctica. Si está interesado en alguno de los temas, al final habrá una encuesta en la que podrá votar por el próximo artículo. Si el tema no está incluido en la lista, pero es interesante leerlo, deje un comentario lo antes posible, asegúrese de compartir nuestra experiencia.
Un agradecimiento especial a Virilin Alexander (
xscrew ) y Sibgatulin Marat (
eucariot ) por la visita de referencia en el otoño de 2018 a la nube de yandex y la historia sobre la automatización en la infraestructura de red de la nube. Después de él, obtuvimos inspiración y muchas ideas sobre el uso de la automatización y NetDevOps en la infraestructura del X5 Retail Group.