Quienes trabajan con datos son conscientes de que la felicidad no está en la red neuronal, sino en cómo procesar los datos correctamente. Pero para procesarlos, primero debe analizar las correlaciones, seleccionar los datos necesarios, descartar los innecesarios, etc. Para tales fines, a menudo se utiliza la visualización usando la biblioteca matplotlib.

Nos vemos "adentro"!
Personalización
Ejecute el siguiente código para configurar. Sin embargo, los gráficos individuales anulan sus configuraciones ellos mismos.
Correlación
Los gráficos de correlación se utilizan para visualizar la relación entre 2 o más variables. Es decir, cómo cambia una variable en relación con otra.
1. Diagrama de dispersión
Scatteplot es una vista gráfica clásica y fundamental utilizada para examinar la relación entre dos variables. Si tiene varios grupos en sus datos, puede visualizar cada grupo en un color diferente. En matplotlib puedes hacer esto fácilmente usando plt.scatterplot ().

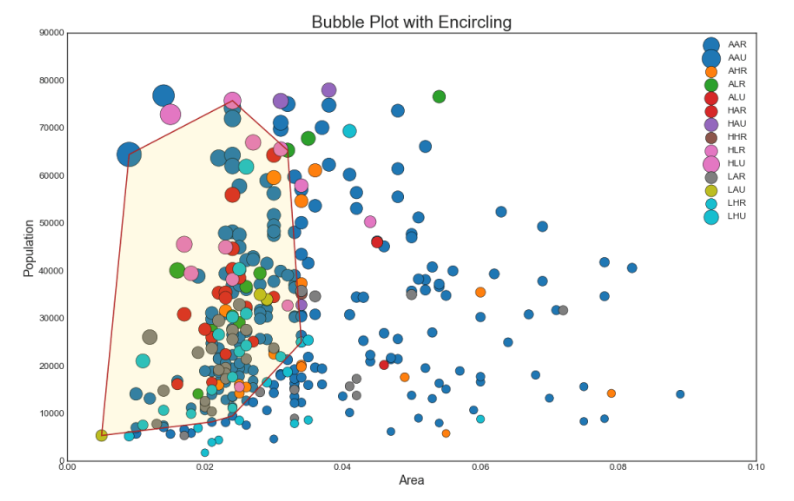
2. Gráfico de burbujas con captura grupal
A veces, desea mostrar un grupo de puntos dentro del borde para enfatizar su importancia. En este ejemplo, obtenemos los registros del marco de datos que deben asignarse, y los pasamos a rodear () descrito en el código a continuación.
Mostrar código from matplotlib import patches from scipy.spatial import ConvexHull import warnings; warnings.simplefilter('ignore') sns.set_style("white")
3. Gráfico de regresión lineal de mejor ajuste
Si desea comprender cómo cambian dos variables en relación entre sí, la mejor línea de ajuste es la mejor. El siguiente gráfico muestra cómo el mejor ajuste difiere entre los diferentes grupos de datos. Para deshabilitar las agrupaciones y simplemente dibujar una línea de mejor ajuste para todo el conjunto de datos, elimine el parámetro hue = 'cyl' de sns.lmplot () a continuación.

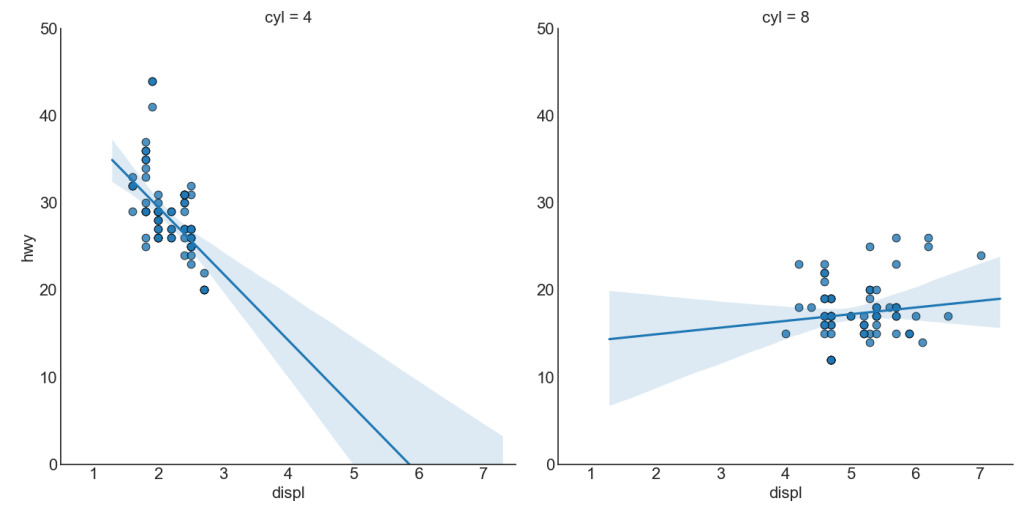
Cada fila de regresión en su propia columna
Además, puede mostrar la línea de mejor ajuste para cada grupo en una columna separada. Desea hacer esto configurando el parámetro col = groupingcolumn dentro de sns.lmplot ().
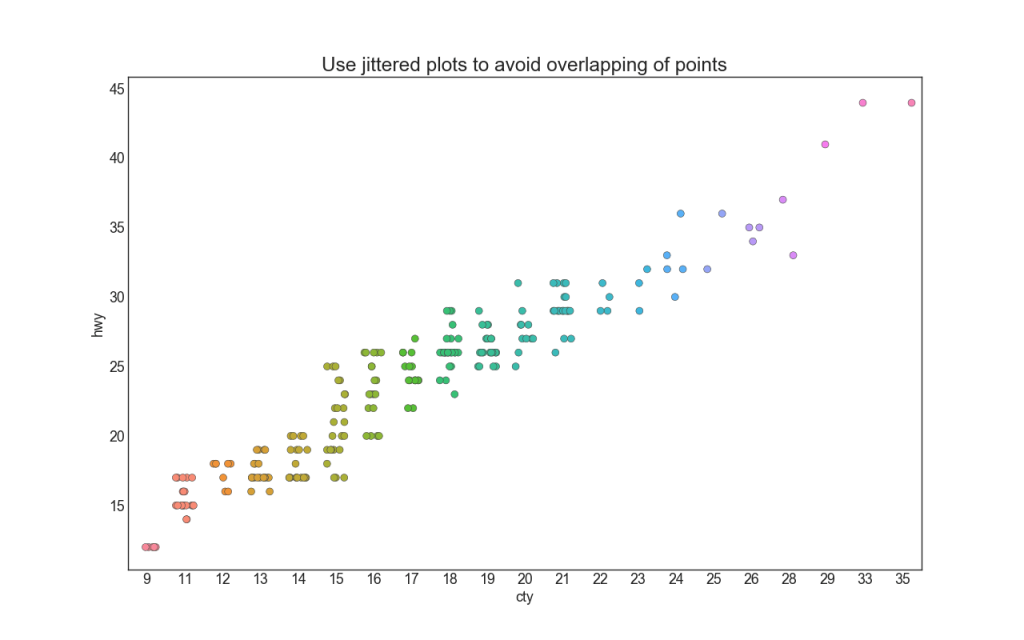
4. Stripplot
A menudo, varios puntos de datos tienen los mismos valores X e Y. Como resultado, varios puntos de datos se trazan uno encima del otro y se ocultan. Para evitar esto, separe los puntos ligeramente para que pueda verlos visualmente. Esto se hace convenientemente usando stripplot ().
5. Contar parcela
Otra opción que evita el problema de la superposición de puntos es aumentar el tamaño del punto, dependiendo de cuántos puntos hay en este lugar. Por lo tanto, cuanto más grande es el punto, mayor es la concentración de puntos a su alrededor.

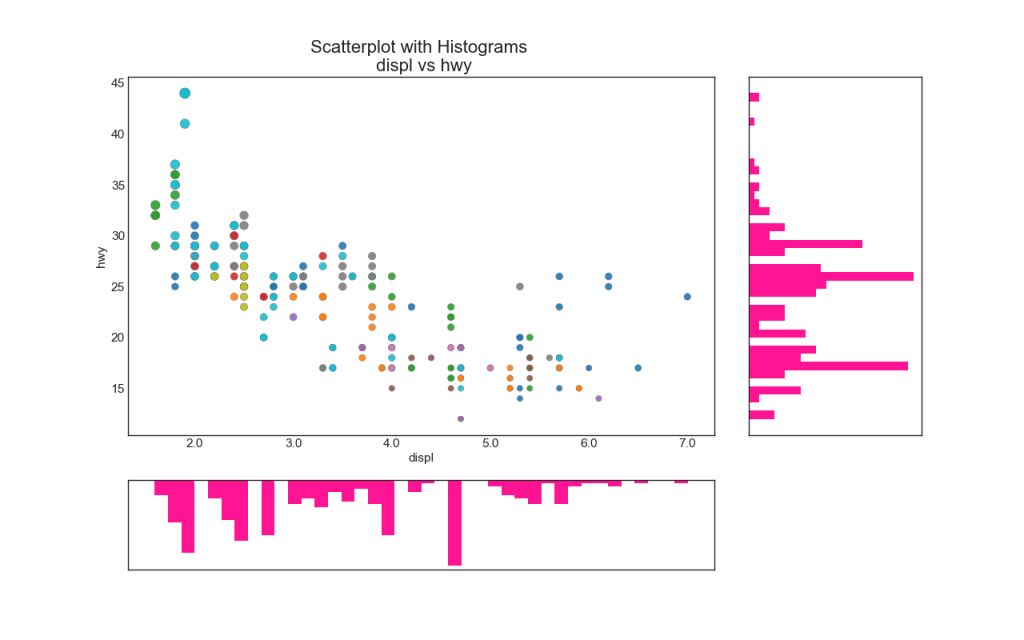
6. Un gráfico de barras
Los histogramas de línea tienen un histograma a lo largo de las variables de los ejes X e Y. Esto se utiliza para visualizar la relación entre X e Y junto con la distribución unidimensional de X e Y individualmente. Este gráfico se usa a menudo en el análisis de datos (EDA).
7. diagrama de caja
Boxplot tiene el mismo propósito que un histograma línea por línea. Sin embargo, este gráfico ayuda a determinar la mediana, los percentiles 25 y 75 de X e Y.
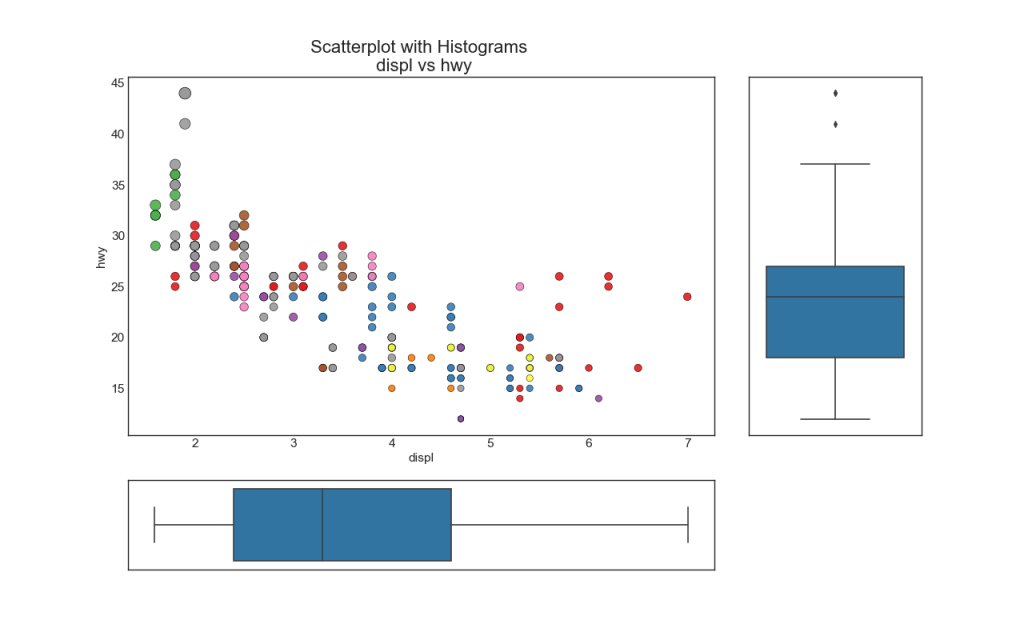
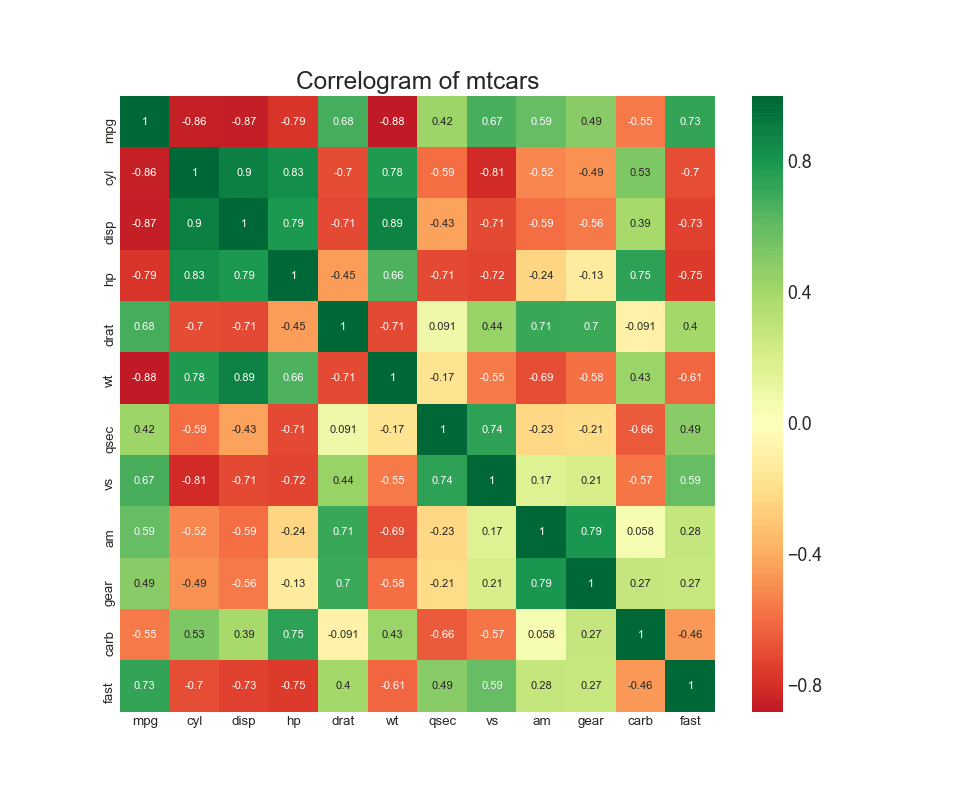
8. El diagrama de correlación
El diagrama de correlación se usa para ver visualmente la métrica de correlación entre todos los pares posibles de variables numéricas en un conjunto de datos dado (o matriz bidimensional).
9. Horario de parejas
A menudo se utiliza en análisis de investigación para comprender la relación entre todos los pares posibles de variables numéricas. Esta es una herramienta obligatoria para el análisis bidimensional.
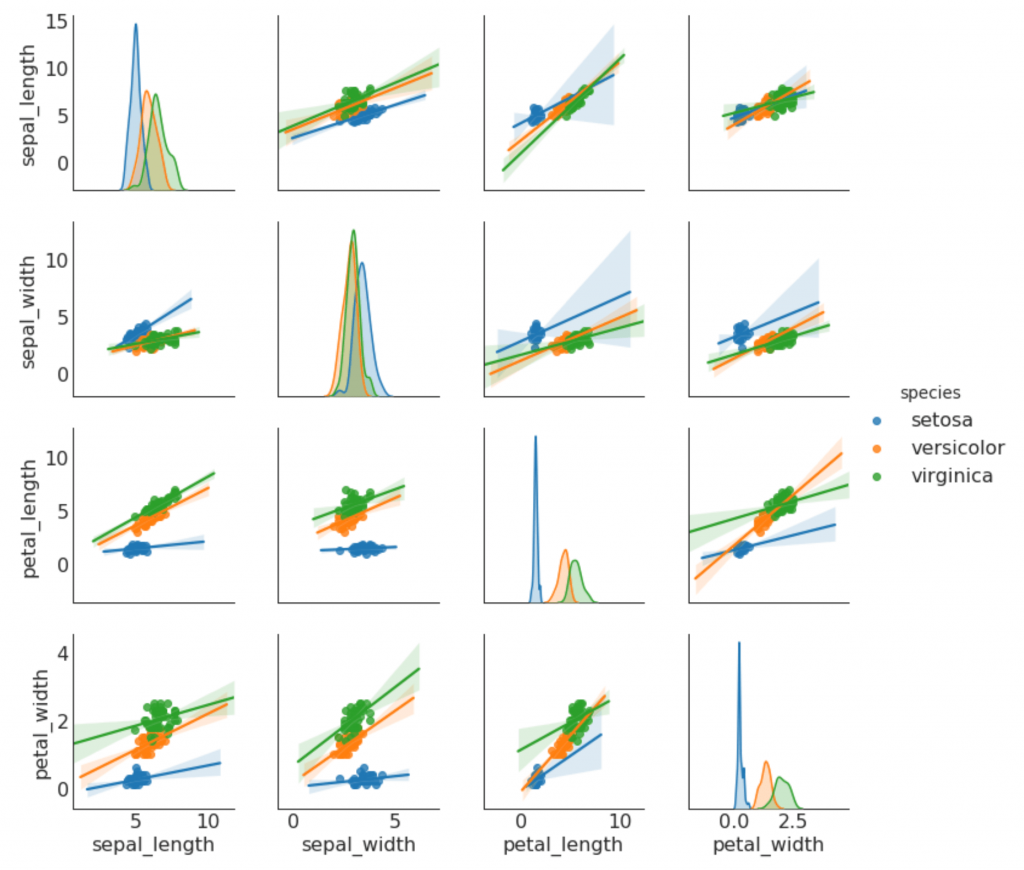
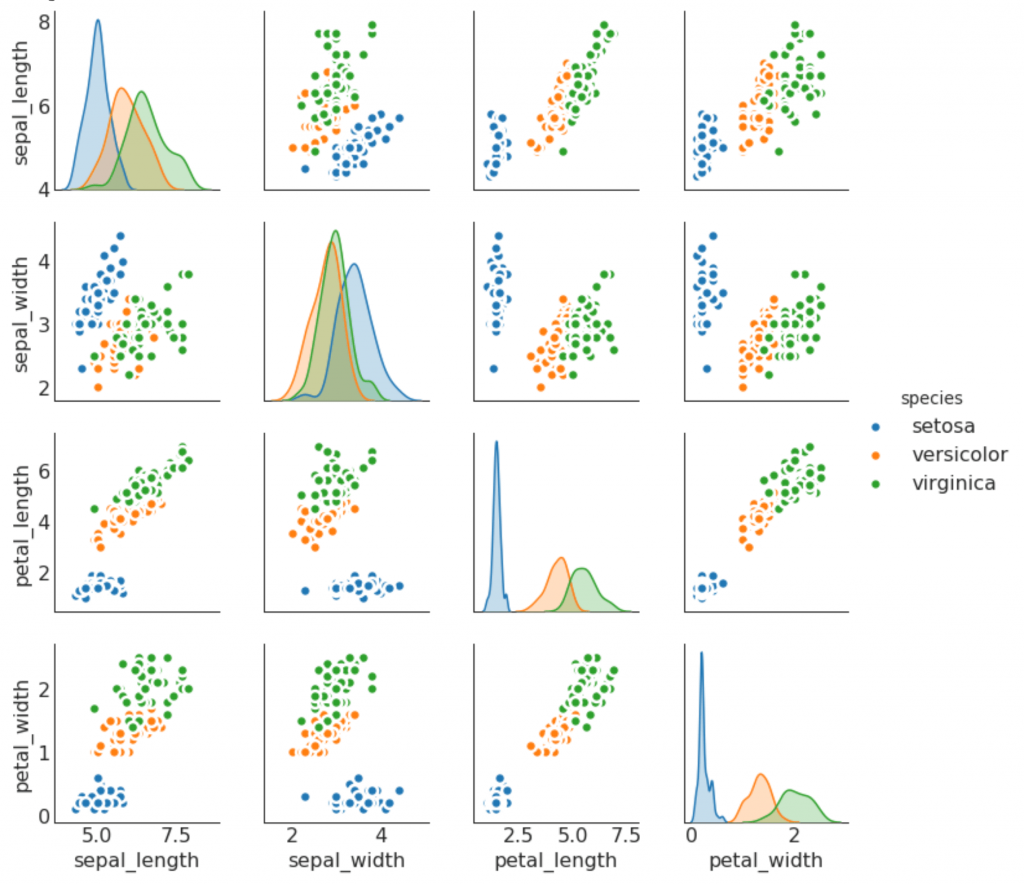
Desviación
10. Columnas divergentes
Si desea ver cómo cambian los elementos según una métrica y visualizar el orden y la magnitud de esta dispersión, las columnas divergentes son una gran herramienta. Ayuda a diferenciar rápidamente el rendimiento de los grupos en sus datos, es bastante intuitivo y transmite instantáneamente significado.

11. Columnas divergentes con texto
- se ven como columnas divergentes, y esto es preferible si desea mostrar la importancia de cada elemento en el gráfico de una manera buena y presentable.
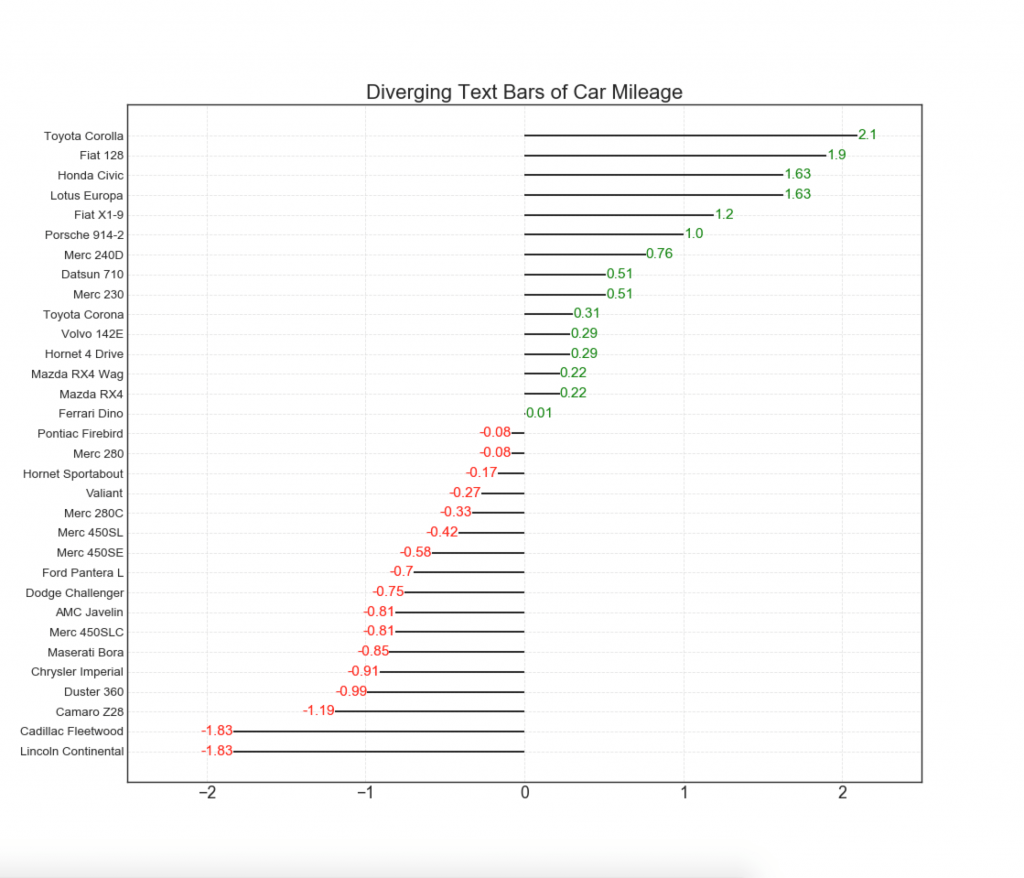
12. Puntos divergentes
El gráfico de puntos divergentes también es similar a las columnas divergentes. Sin embargo, en comparación con las columnas divergentes, la ausencia de columnas reduce el grado de contraste y discrepancia entre los grupos.
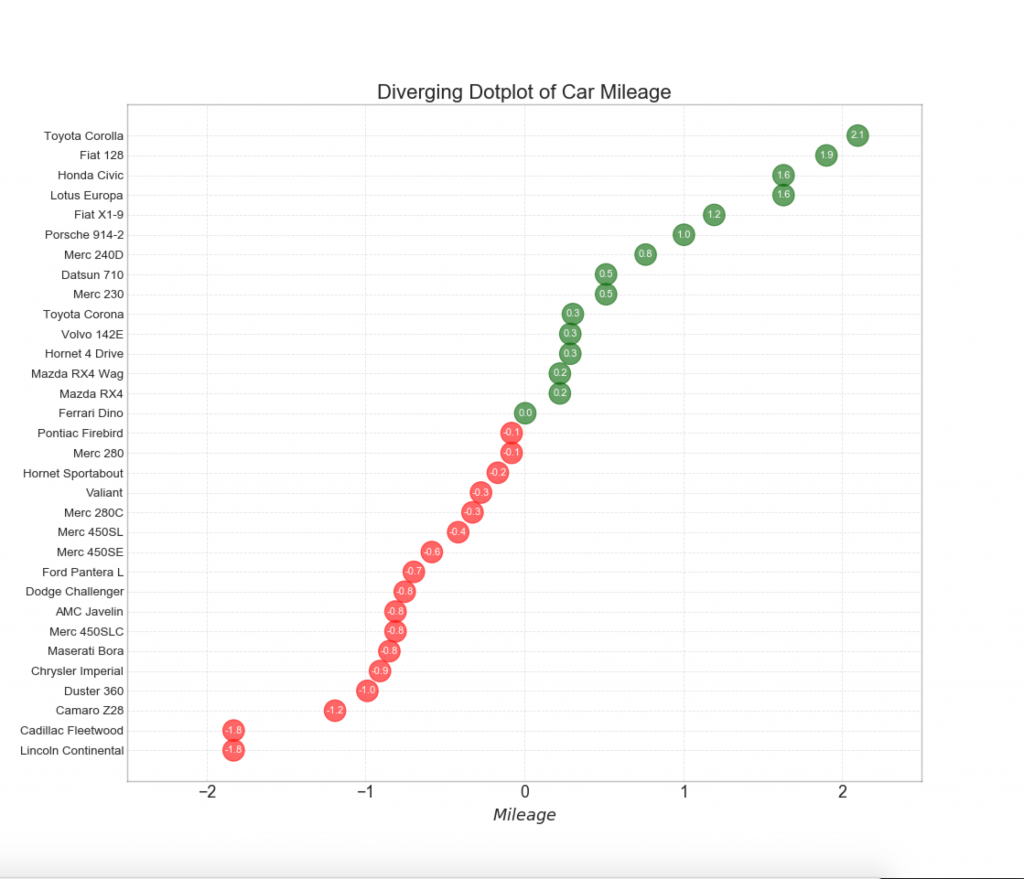
13. Gráfico de Lollipop divergente con marcadores
Lollipop proporciona una forma flexible de visualizar las discrepancias, centrándose en los puntos de datos relevantes a los que desea prestar atención.
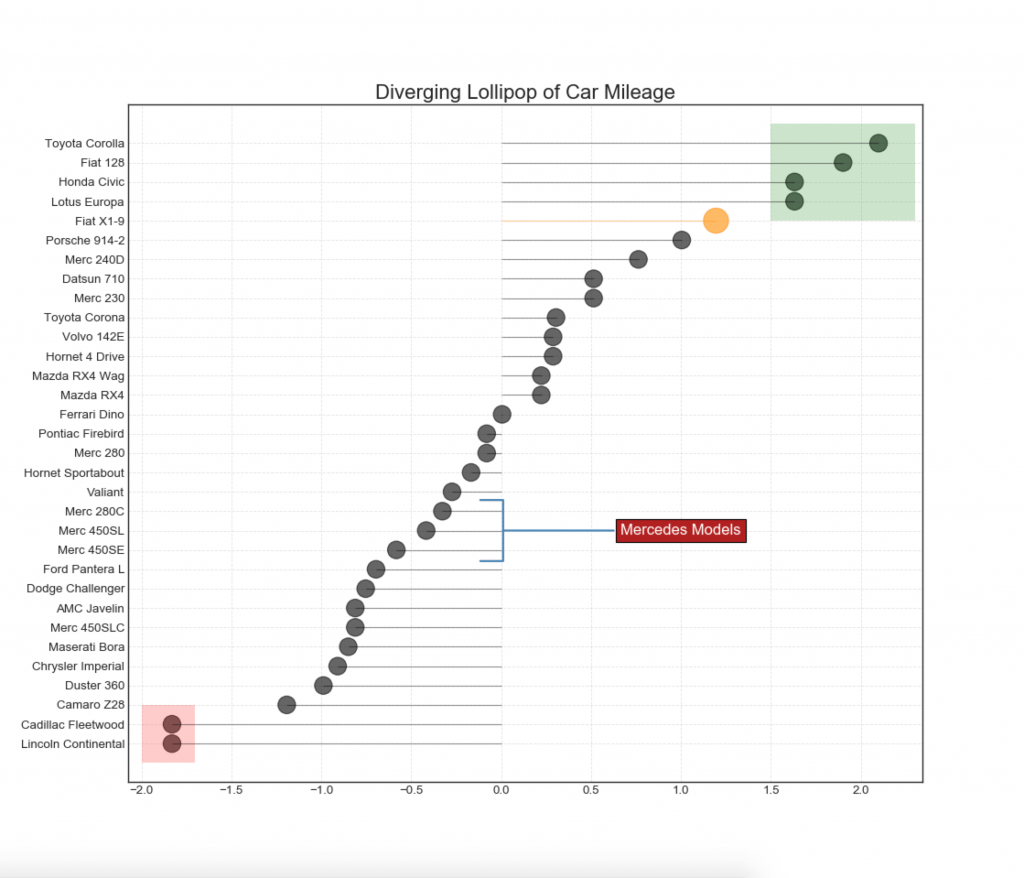
14. Carta del área
Coloreando el área entre el eje y las líneas, el diagrama de área enfatiza picos y valles, pero también en la duración de los altibajos. Cuanto más largos sean los máximos, mayor será el área debajo de la línea.
Mostrar código import numpy as np import pandas as pd
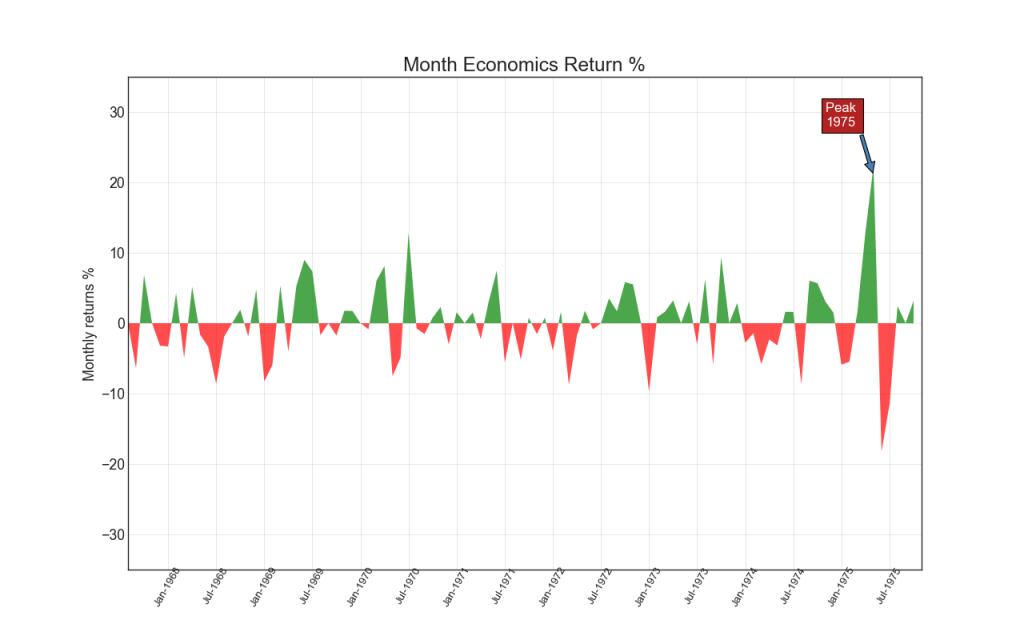
Ranking
15. Histograma ordenado
Un histograma ordenado transmite efectivamente el orden de clasificación de los elementos. Pero al agregar un valor métrico sobre el gráfico, el usuario recibe información precisa del gráfico mismo.
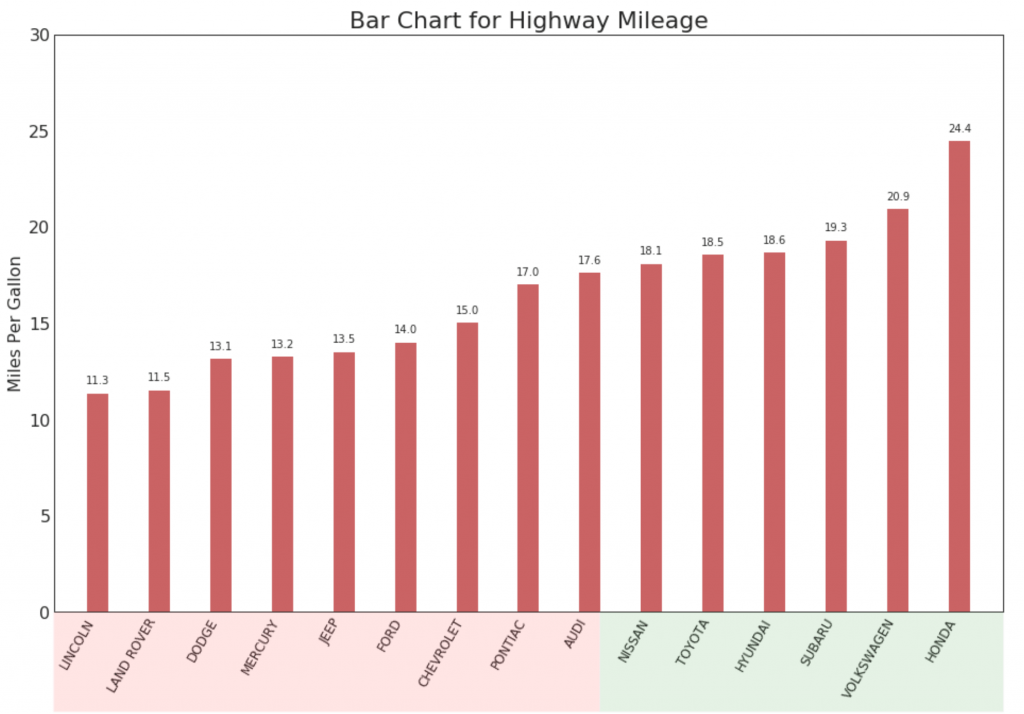
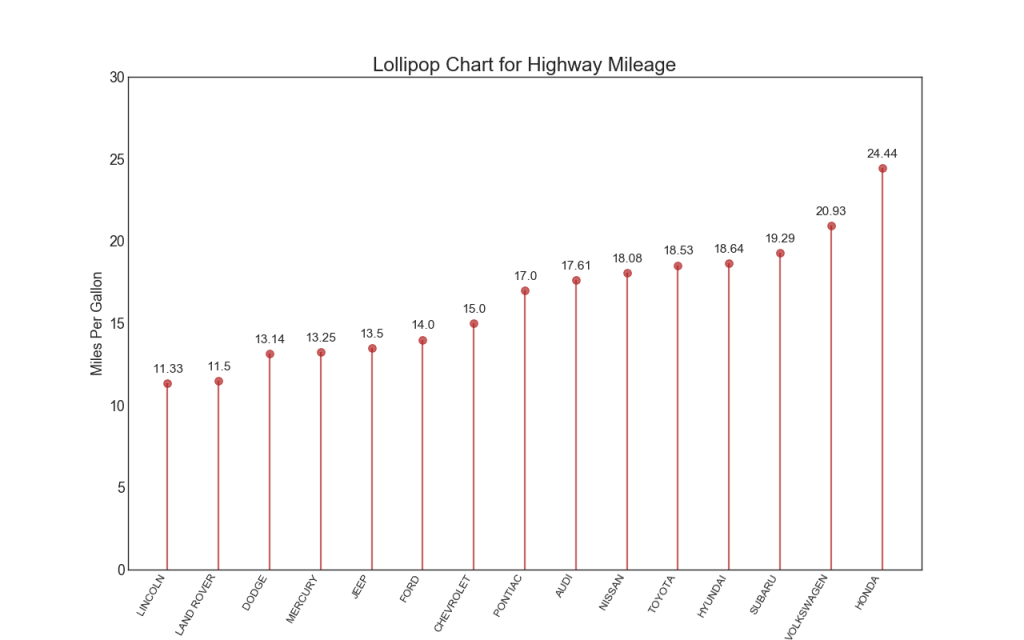
16. tabla de Lollipop
El gráfico de Lollipop tiene un propósito similar al de un histograma ordenado de una manera visualmente agradable.
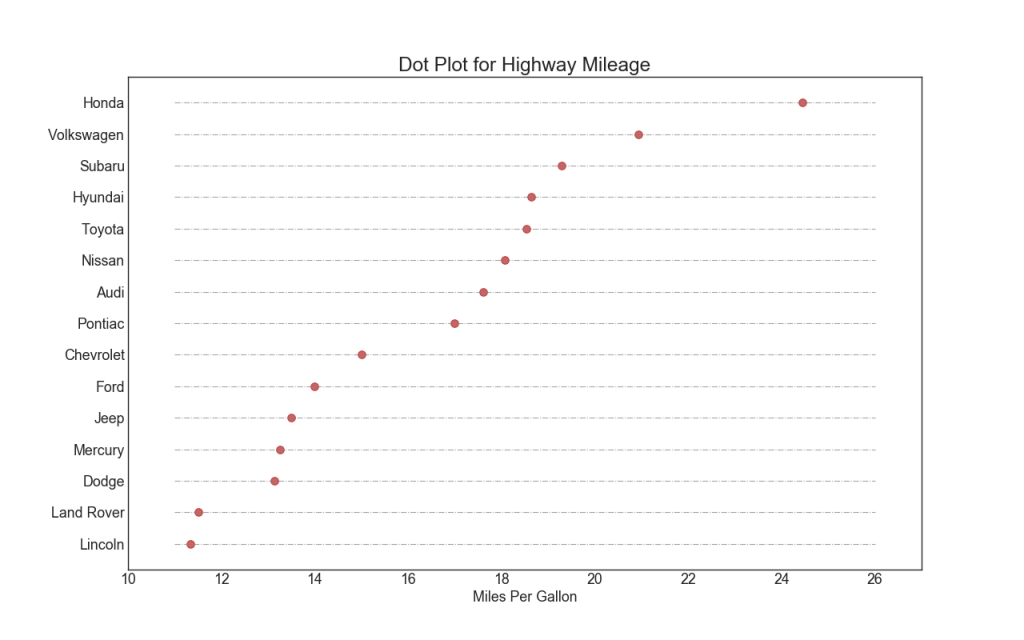
17. Cuadro punteado con firmas
Un diagrama de dispersión transmite la clasificación de los elementos. Y dado que está alineado a lo largo del eje horizontal, puede evaluar visualmente qué tan lejos están los puntos entre sí.
18. Mapa inclinado
El gráfico de pendiente es más adecuado para comparar las posiciones "Antes" y "Después" de una persona / sujeto determinado.
Mostrar código import matplotlib.lines as mlines

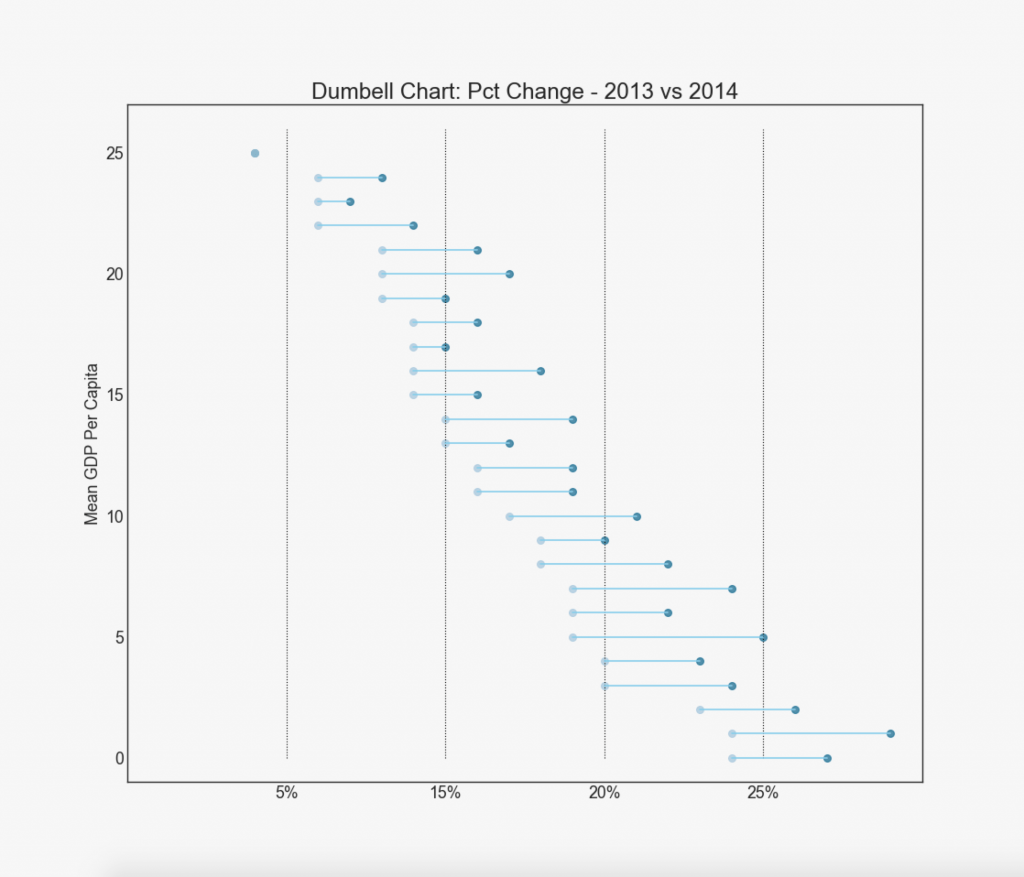
19. "pesas"
El gráfico "Dumbbell" transmite las posiciones "antes" y "después" de diversas influencias, así como el orden de clasificación de los elementos. Esto es muy útil si desea visualizar el efecto de algo en diferentes objetos.
Mostrar código import matplotlib.lines as mlines
Distribución
20. Histograma para una variable continua
El histograma muestra la distribución de frecuencia de esta variable. La siguiente presentación agrupa bandas de frecuencia basadas en una variable categórica.
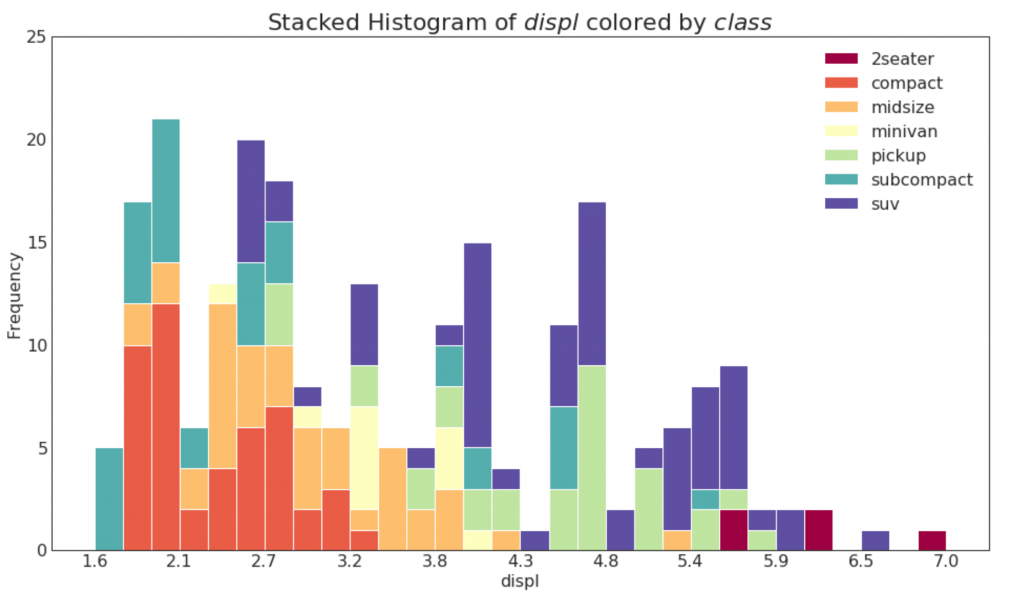
21. Histograma para una variable categórica
El histograma de una variable categórica muestra la distribución de frecuencia de esta variable. Al colorear las columnas, puede visualizar la distribución en relación con otra variable categórica que representa los colores.
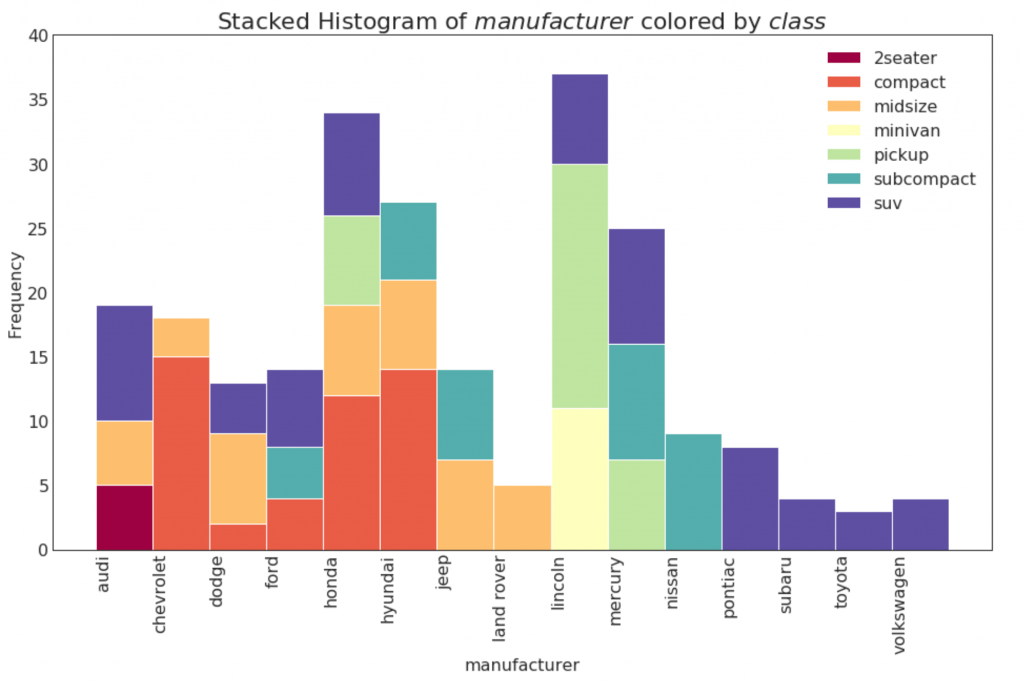
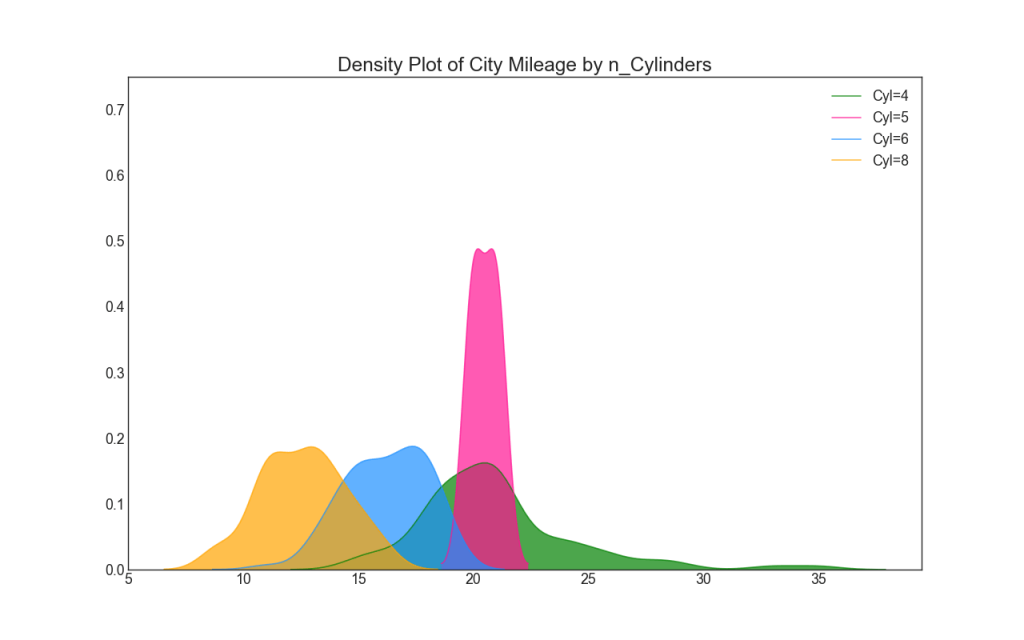
22. Gráfico de densidad
Los gráficos de densidad son una herramienta ampliamente utilizada para visualizar la distribución de una variable continua. Una vez agrupados por la variable "respuesta", puede verificar la relación entre X e Y. El siguiente es un ejemplo si, para mayor claridad, describimos cómo la distribución del kilometraje en la ciudad varía según el número de cilindros.
23. Curvas de densidad con un histograma
La curva de densidad con un histograma combina la información resumida transmitida por los dos gráficos para que pueda ver ambos en un solo lugar.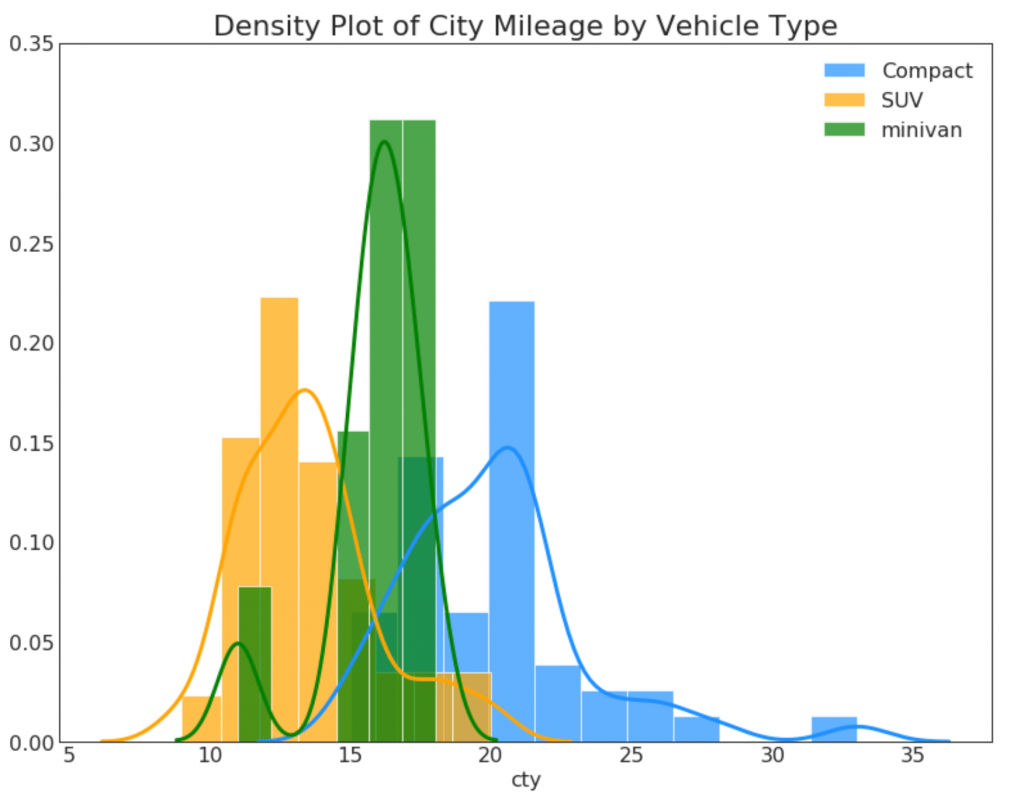
24. Joy chart
El gráfico Joy le permite superponer las curvas de densidad de diferentes grupos, esta es una excelente manera de visualizar la distribución de una gran cantidad de grupos en relación entre sí. Parece agradable a la vista y claramente transmite solo la información correcta.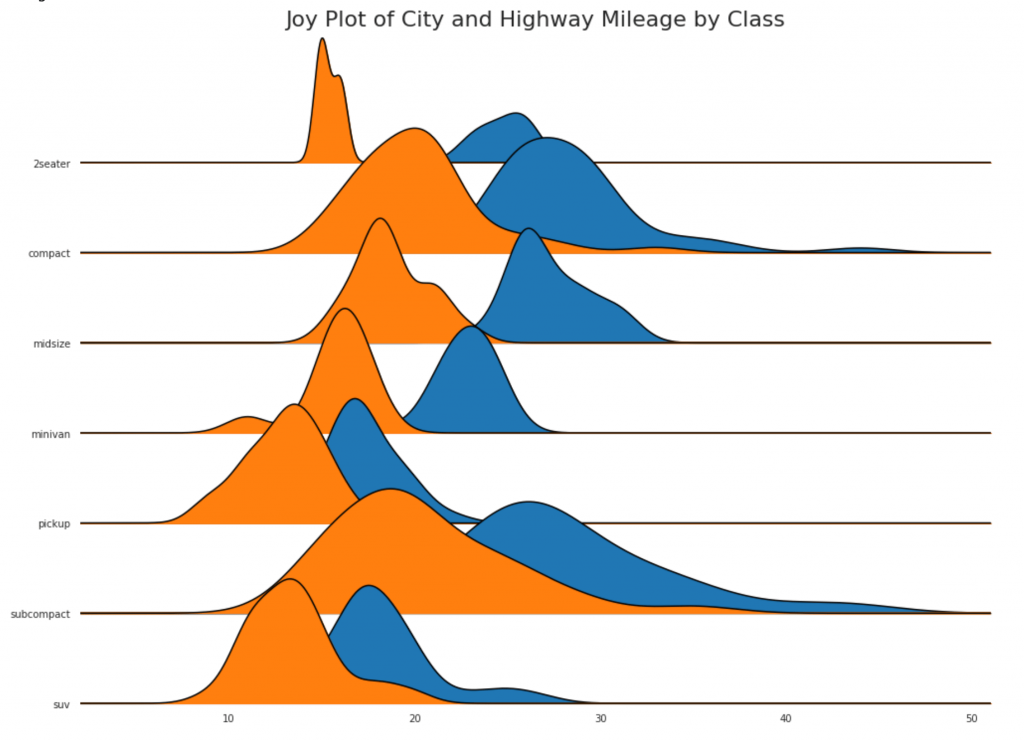
25. Diagrama de dispersión distribuido
El diagrama de dispersión distribuida muestra una distribución unidimensional de puntos segmentados en grupos. Cuanto más oscuros sean los puntos, mayor será la concentración de puntos de datos en esta región. Al colorear la mediana de diferentes maneras, la disposición real de los grupos se hace evidente al instante.Mostrar código import matplotlib.patches as mpatches

26. Gráficos con rectángulos
Tales gráficos son una excelente manera de visualizar la distribución, conociendo la mediana, los cuartiles 25, 75 y los máximos con mínimos. Sin embargo, debe tener cuidado al interpretar el tamaño de los campos, que potencialmente puede distorsionar el número de puntos contenidos en este grupo. Por lo tanto, la indicación manual del número de observaciones en cada celda ayudará a superar este inconveniente.Por ejemplo, los dos primeros rectángulos a la izquierda son del mismo tamaño, aunque tienen 5 y 47 elementos de datos, respectivamente. Por lo tanto, es necesario tener en cuenta el número de observaciones.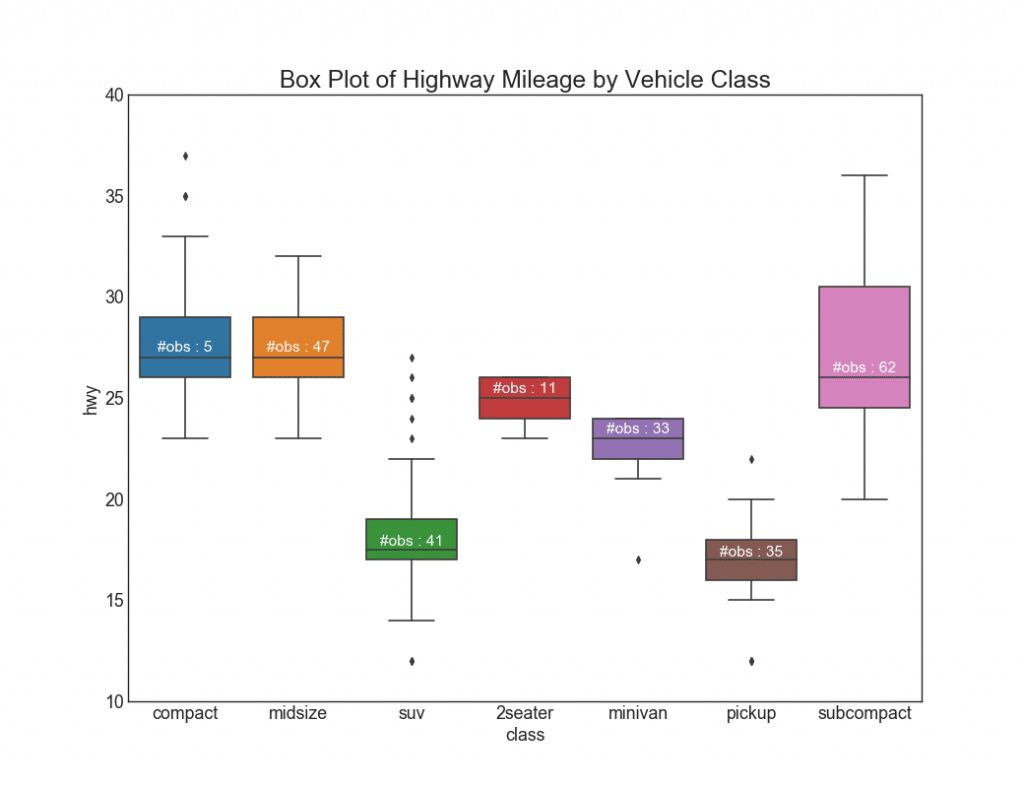
27. Gráficos con rectángulos y puntos
Dot + Box plot transmite información similar, como boxplot, dividida en grupos. Además, los puntos dan una idea del número de elementos de datos en cada grupo.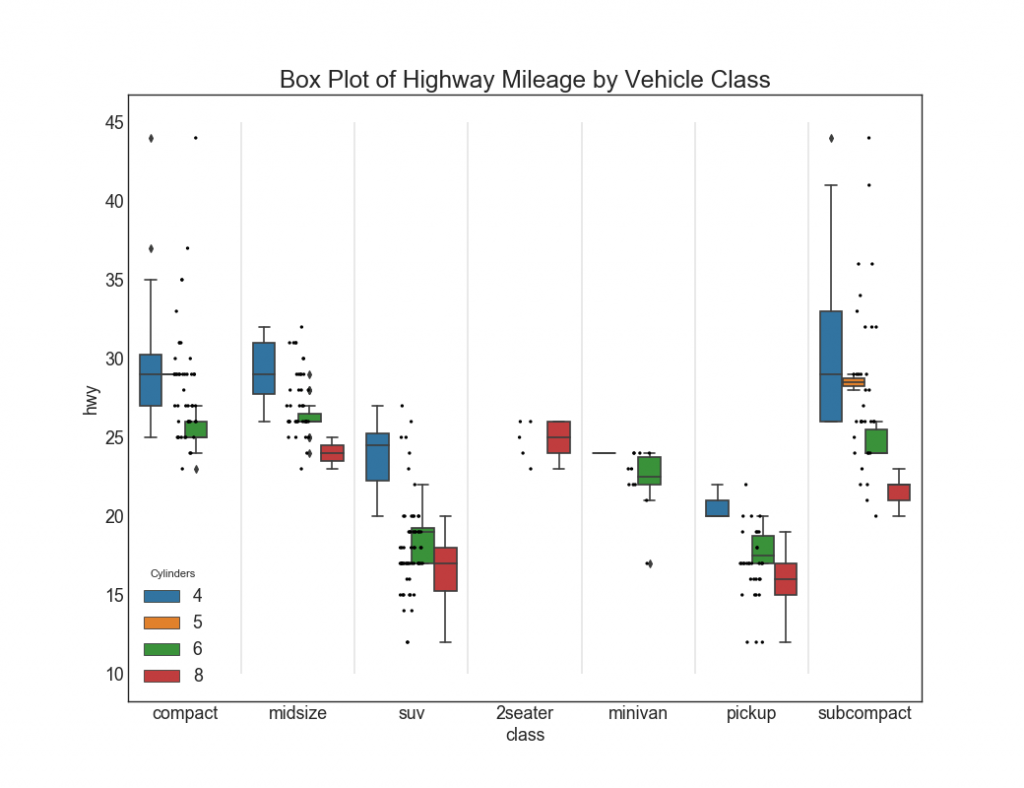
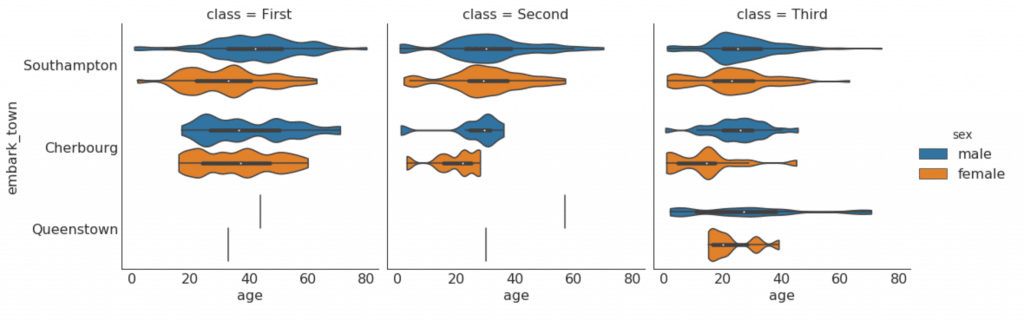
28. Programar "violines"
Tal horario es una alternativa visualmente agradable a boxplot. La forma o área del "violín" depende de la cantidad de datos en este grupo. Sin embargo, estos gráficos pueden ser más difíciles de leer y, por lo general, no se usan en entornos profesionales.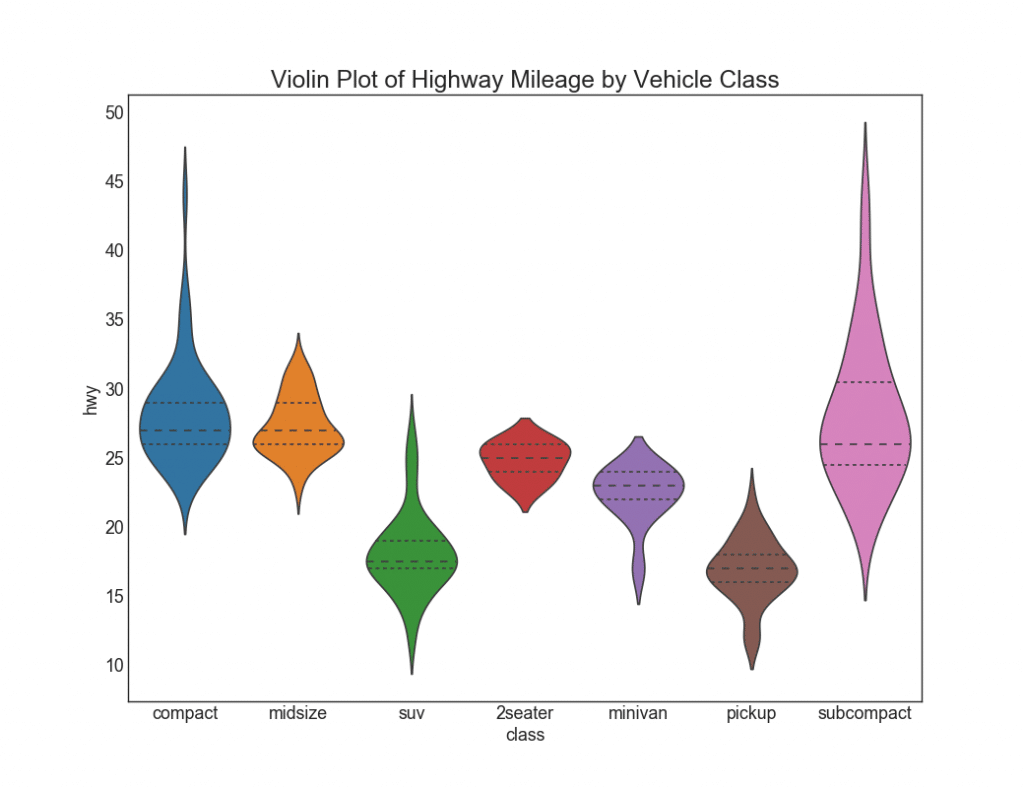
29. Pirámide de población
Se puede usar una pirámide de población para mostrar la distribución de los grupos ordenados por volumen, o para mostrar el filtrado por fases de la población, como se muestra a continuación, para visualizar cuántas personas pasan por cada etapa del embudo de marketing.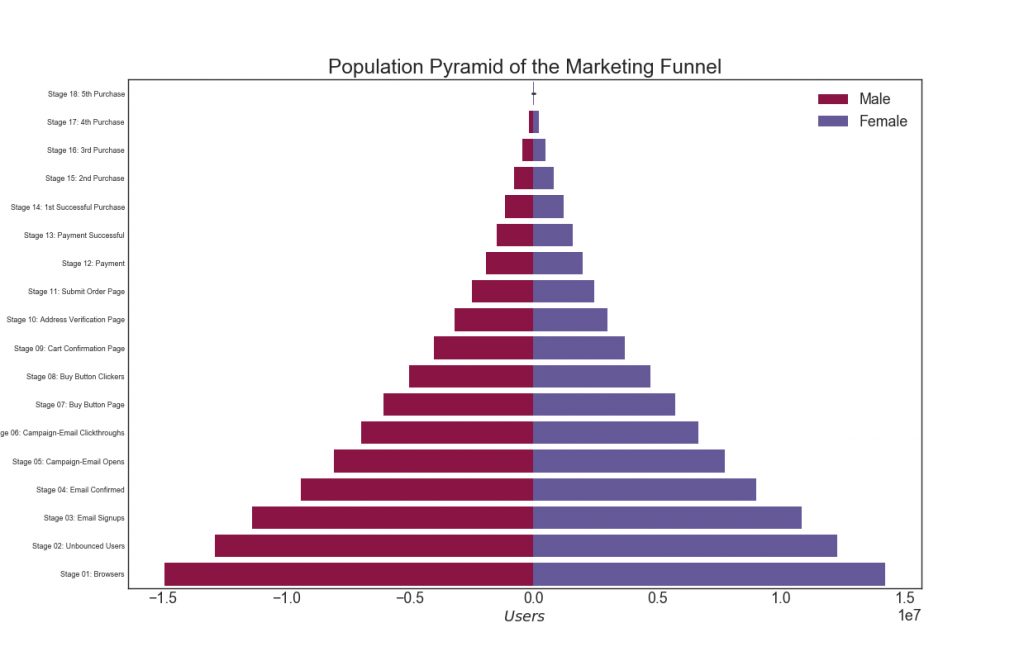
30. Cartas categóricas
Los gráficos categóricos proporcionados por la biblioteca seaborn se pueden usar para visualizar la distribución del número de dos o más variables categóricas entre sí.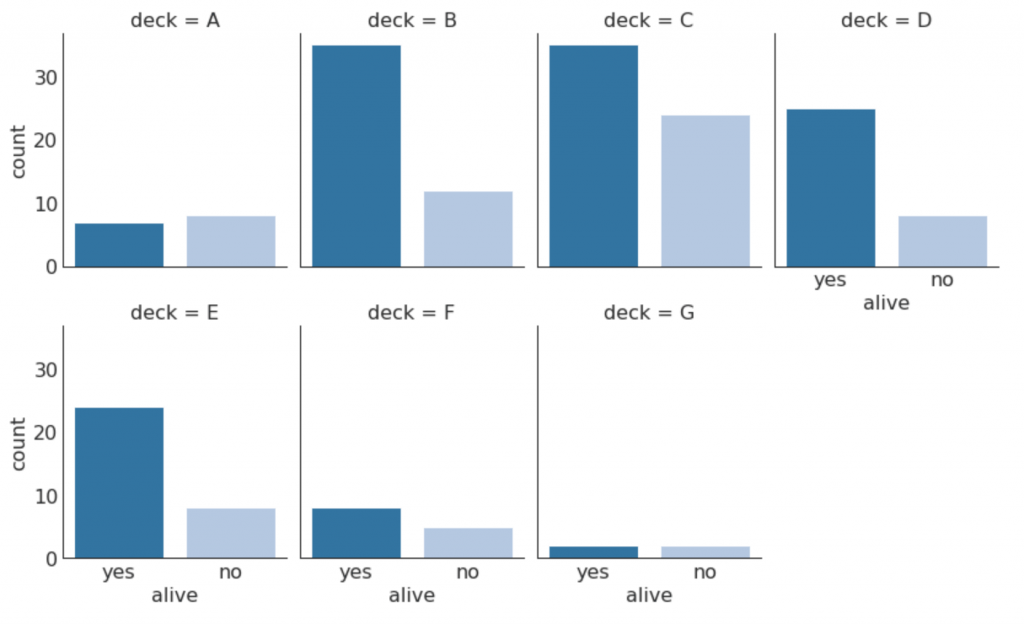
Asamblea, composición
31. Diagrama de gofres
Se puede crear un gráfico de waffle usando el paquete de pywaffle y se usa para mostrar composiciones grupales en la mayoría de la población.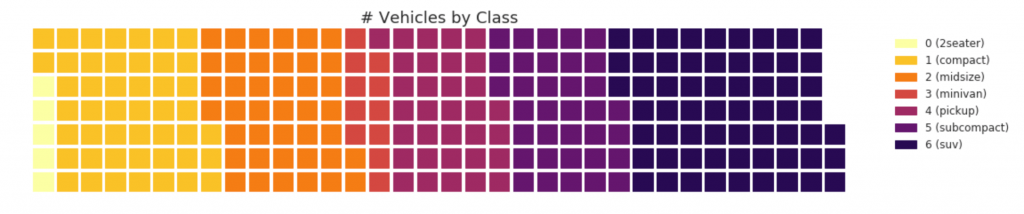
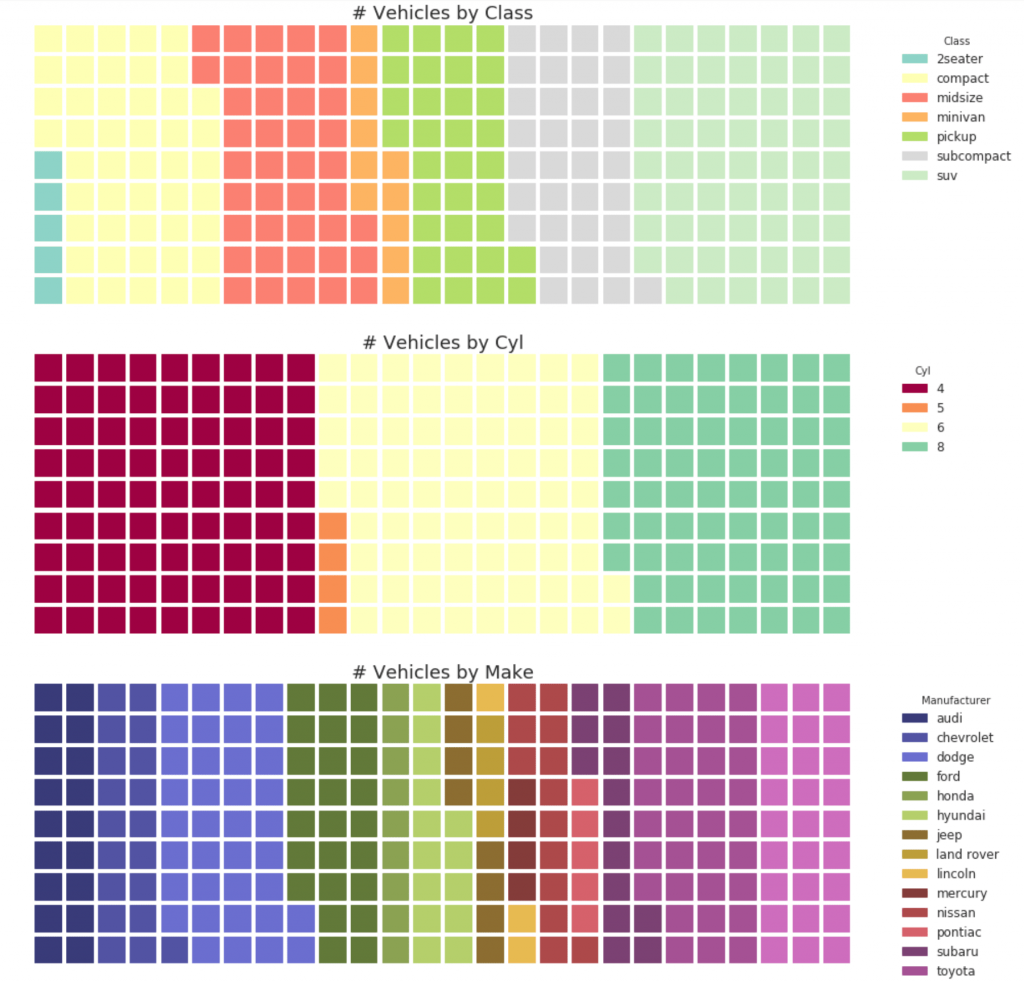
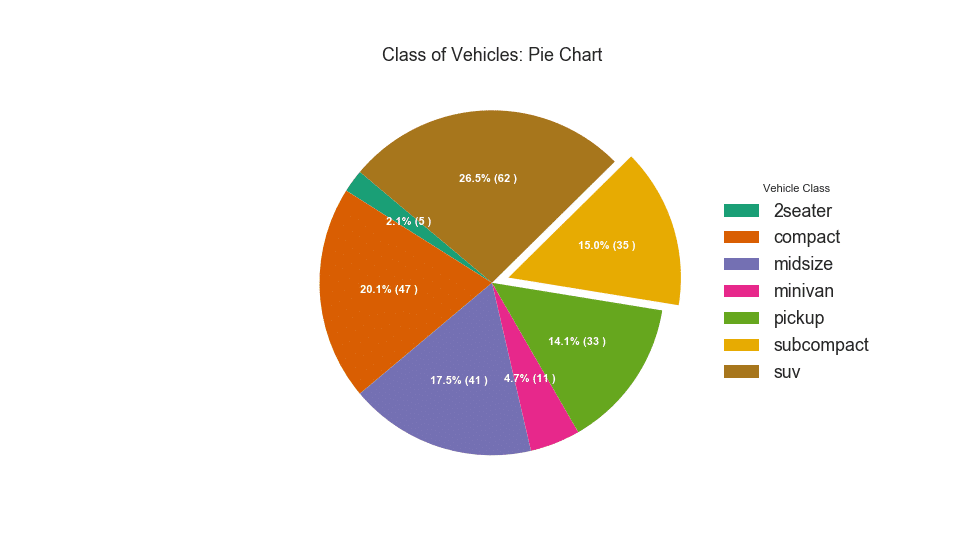
32. Gráfico circular
Un gráfico circular es una forma clásica de mostrar la composición de los grupos. Sin embargo, actualmente no se recomienda usar este gráfico porque el área de los segmentos a veces puede ser engañosa. Por lo tanto, si desea utilizar un gráfico circular, se recomienda que registre explícitamente el porcentaje o número para cada parte del gráfico circular.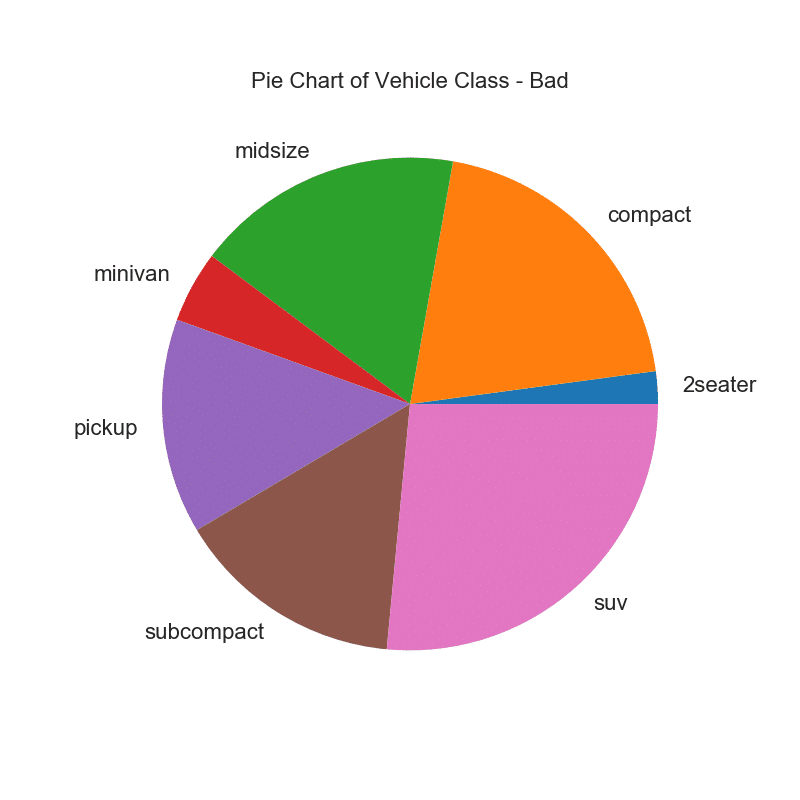
33. Mapa de árboles
El mapa de árbol se ve como un gráfico circular y funciona mejor sin confundir la parte de cada grupo.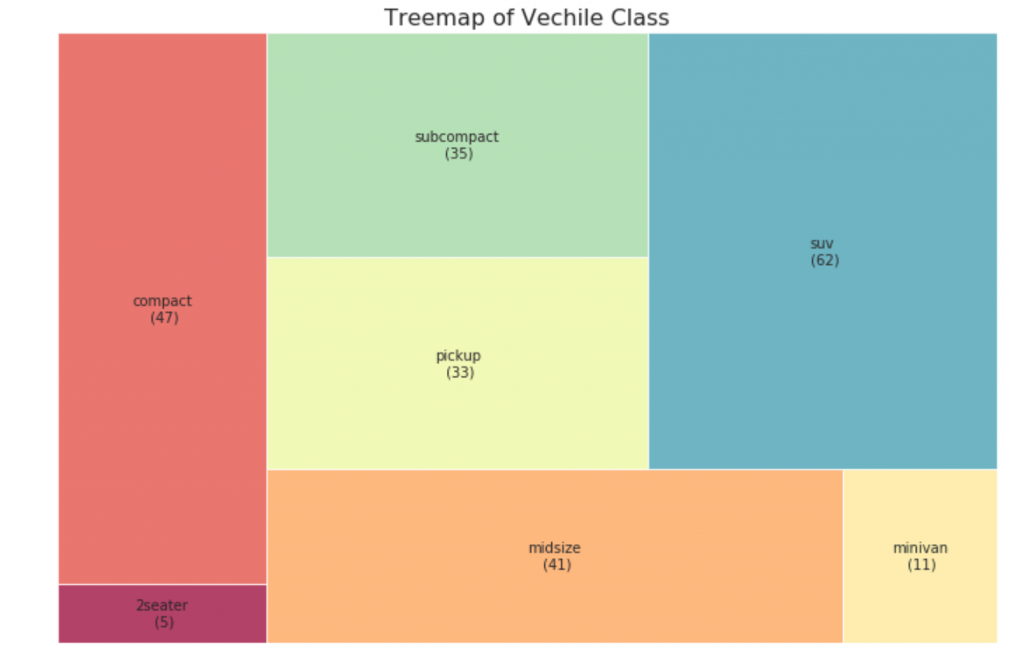
34. histograma
Un histograma es una forma clásica de visualizar elementos basados en la cantidad o cualquier métrica dada. En el siguiente diagrama, utilicé diferentes colores para cada elemento, pero puede elegir un color para todos los elementos si no desea colorearlos en grupos. Los nombres de los colores se almacenan dentro de all_colors en el código a continuación. Puede cambiar el color de las rayas configurando el parámetro de color en .plt.plot ()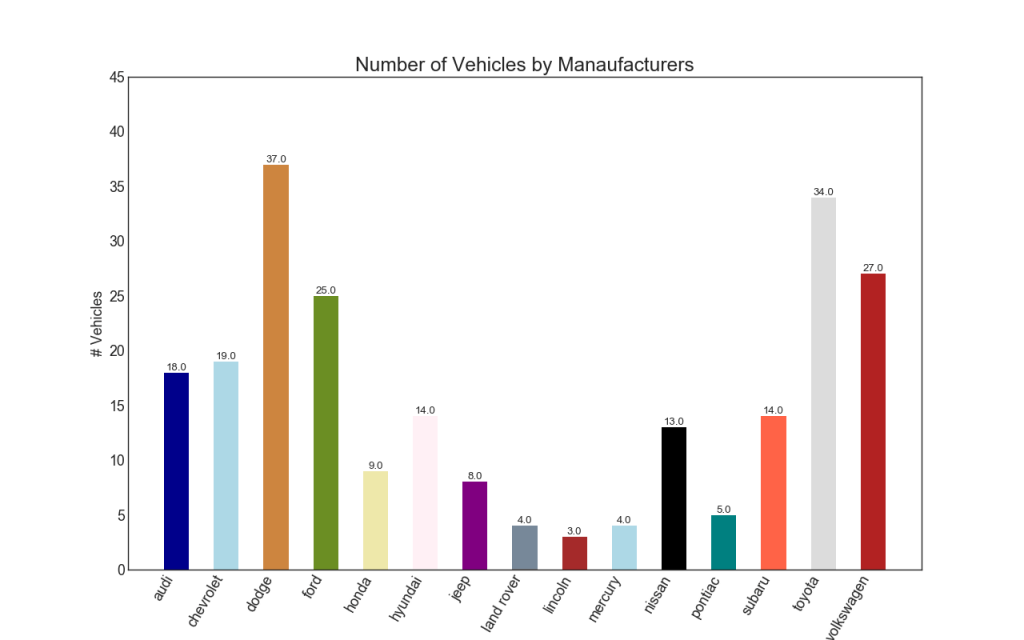
Seguimiento de cambios
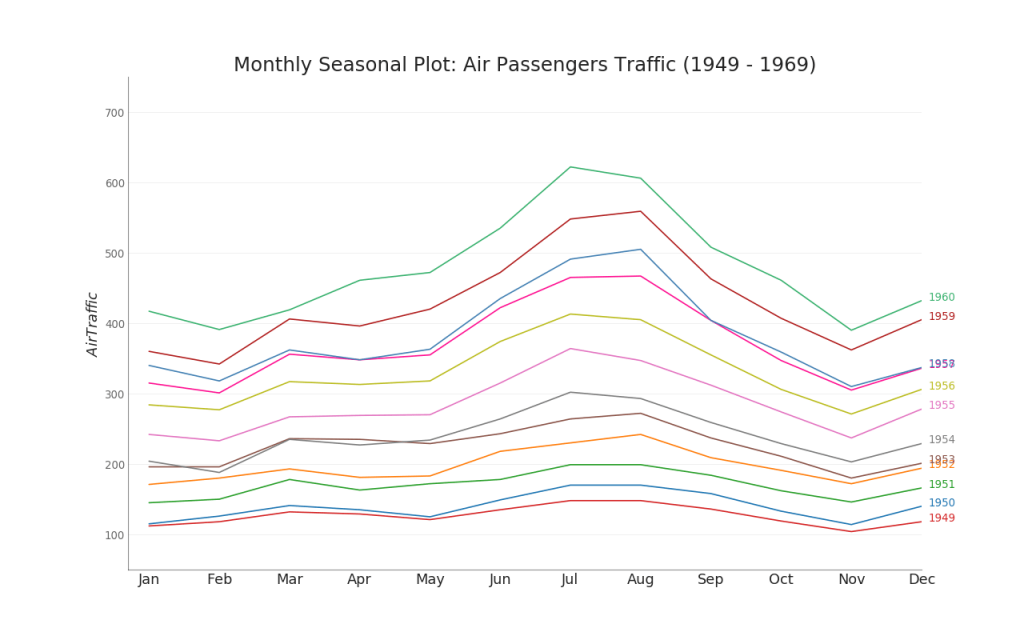
35. Cuadro de series de tiempo
Se utiliza un gráfico de series de tiempo para visualizar cómo cambia un indicador dado con el tiempo. Aquí puede ver cómo ha cambiado el flujo de pasajeros de 1949 a 1969.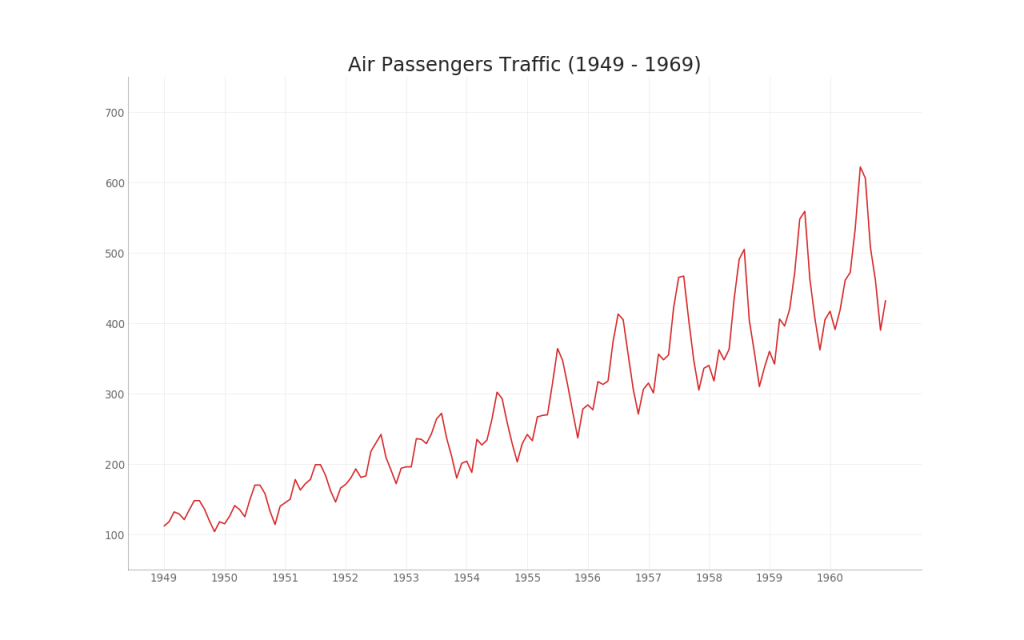
36. Series temporales con picos y valles
La siguiente serie temporal muestra todos los picos y valles y marca la ocurrencia de eventos especiales individuales.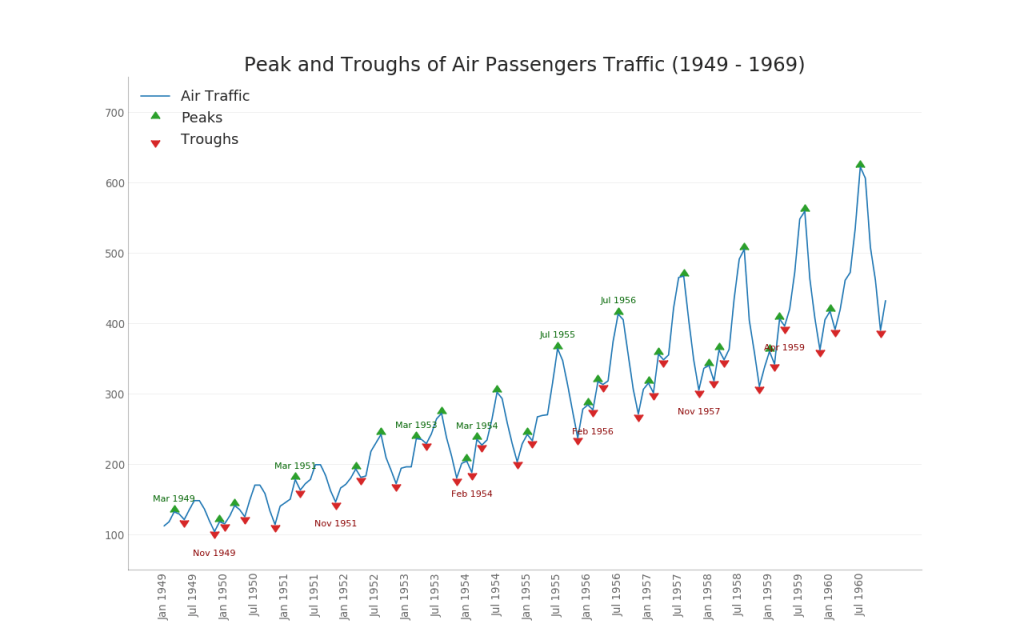
37. (ACF) (PACF)
El gráfico ACF muestra la correlación de una serie de tiempo con su propio tiempo. Cada línea vertical (en el gráfico de autocorrelación) representa una correlación entre la serie y su tiempo, comenzando en el tiempo 0. El área sombreada en azul en el gráfico es un nivel de significancia. Esos momentos que se encuentran por encima de la línea azul son significativos.Entonces, ¿cómo interpretas esto?Para los pasajeros aéreos, vemos que en x = 14, las "piruletas" cruzaron la línea azul y, por lo tanto, son de gran importancia. Esto significa que el tráfico de pasajeros observado hasta hace 14 años tiene un impacto en el tráfico observado hoy.PACF, por otro lado, muestra la autocorrelación de cualquier momento (serie temporal) con la serie actual, pero con la eliminación de influencias entre ellos.Mostrar código from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
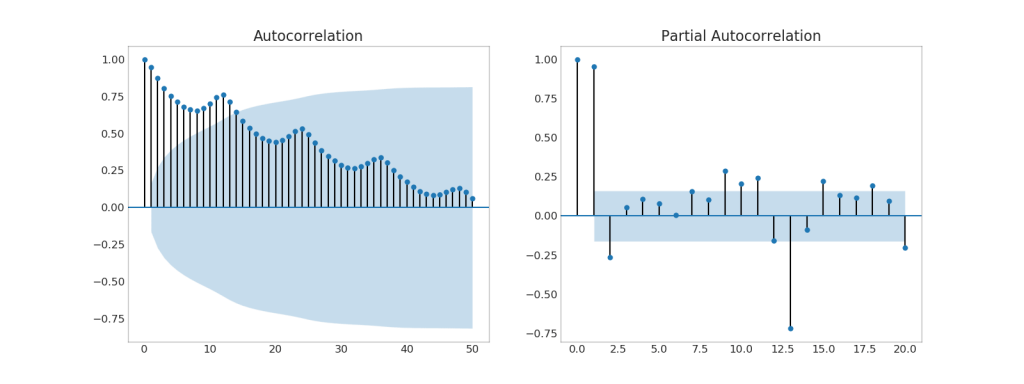
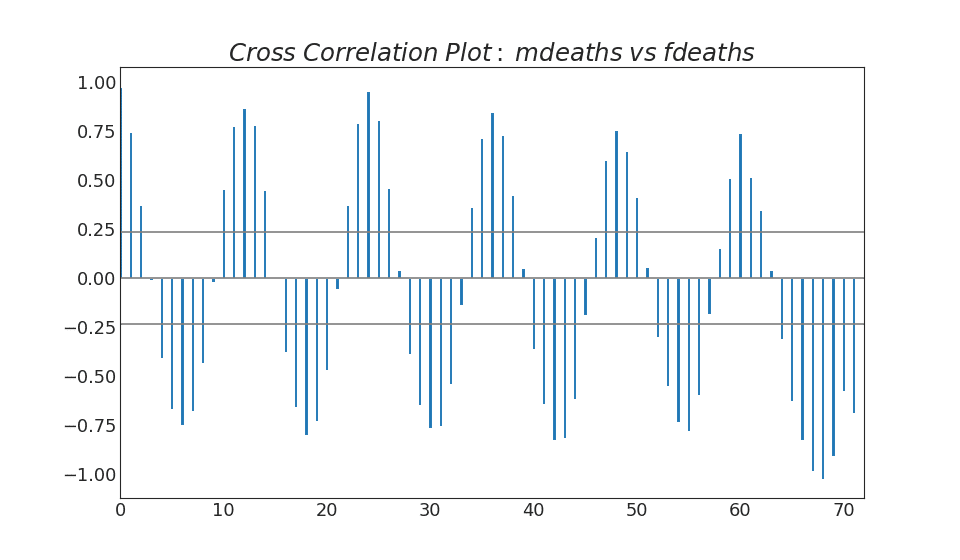
38. Gráfico de correlación cruzada
El gráfico de correlación cruzada muestra los retrasos de dos series de tiempo entre sí.Mostrar código import statsmodels.tsa.stattools as stattools
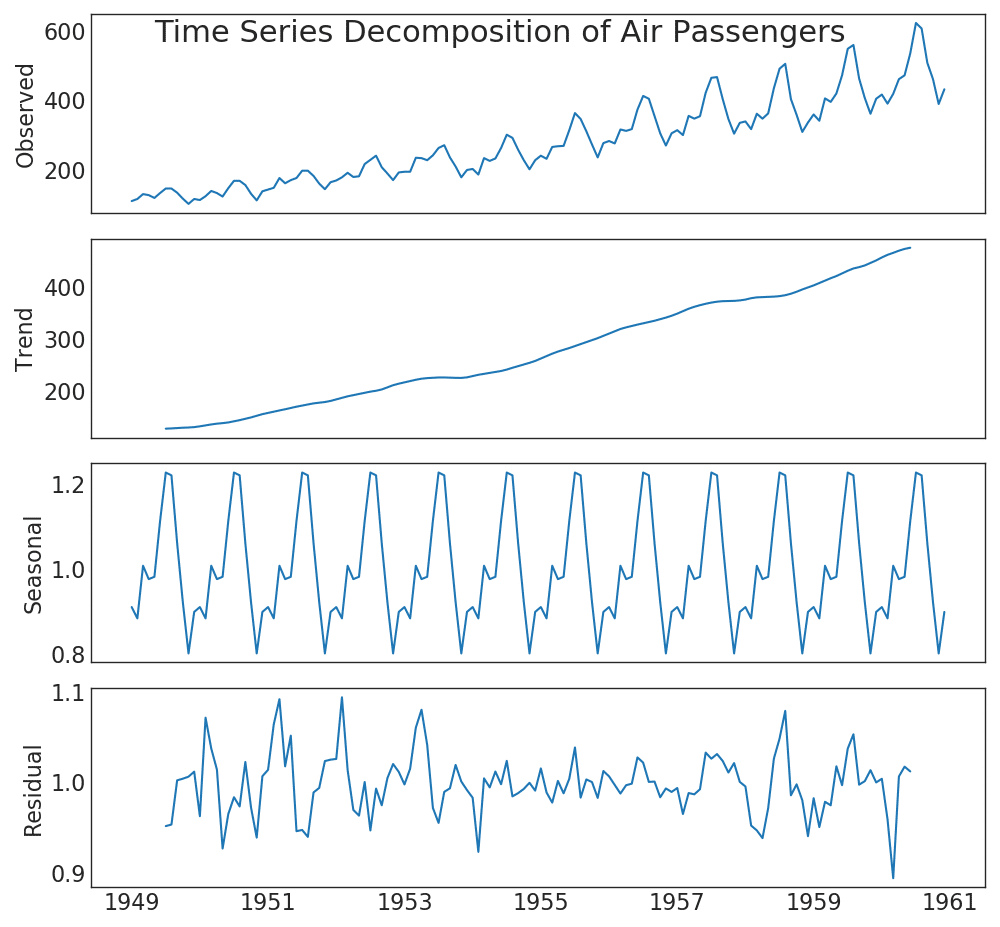
39. Expansión de series temporales
El gráfico de expansión de series temporales muestra el desglose de series temporales en componentes de tendencia, estacionales y residuales.Mostrar código from statsmodels.tsa.seasonal import seasonal_decompose from dateutil.parser import parse
40. Varias series de tiempo
Puede construir múltiples series de tiempo que miden el mismo valor en un solo gráfico, como se muestra a continuación.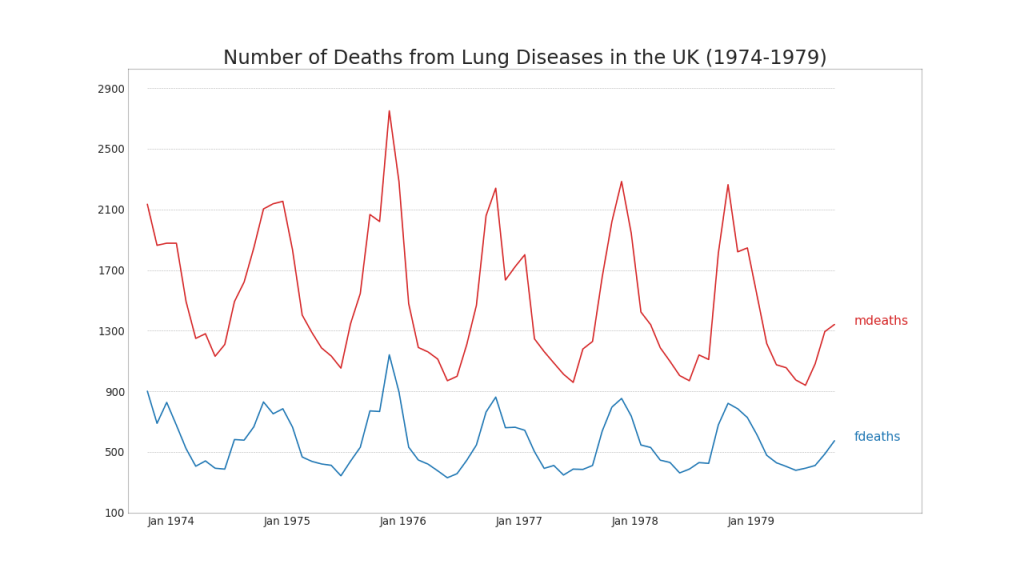
41. Construyendo a diferentes escalas usando el eje secundario Y
Si desea mostrar dos series de tiempo que miden dos valores diferentes al mismo tiempo, puede construir la segunda serie nuevamente en el eje Y secundario a la derecha.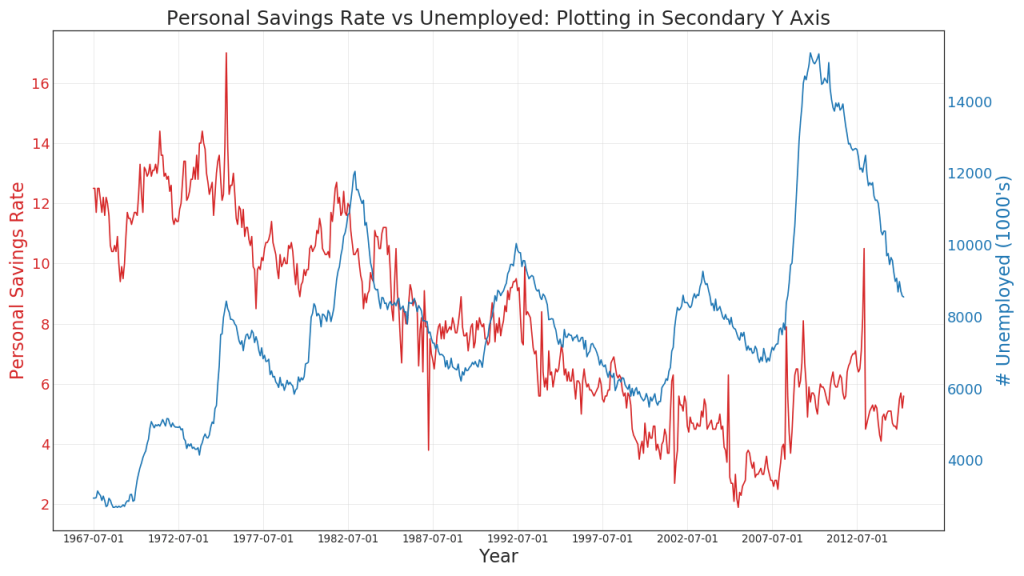
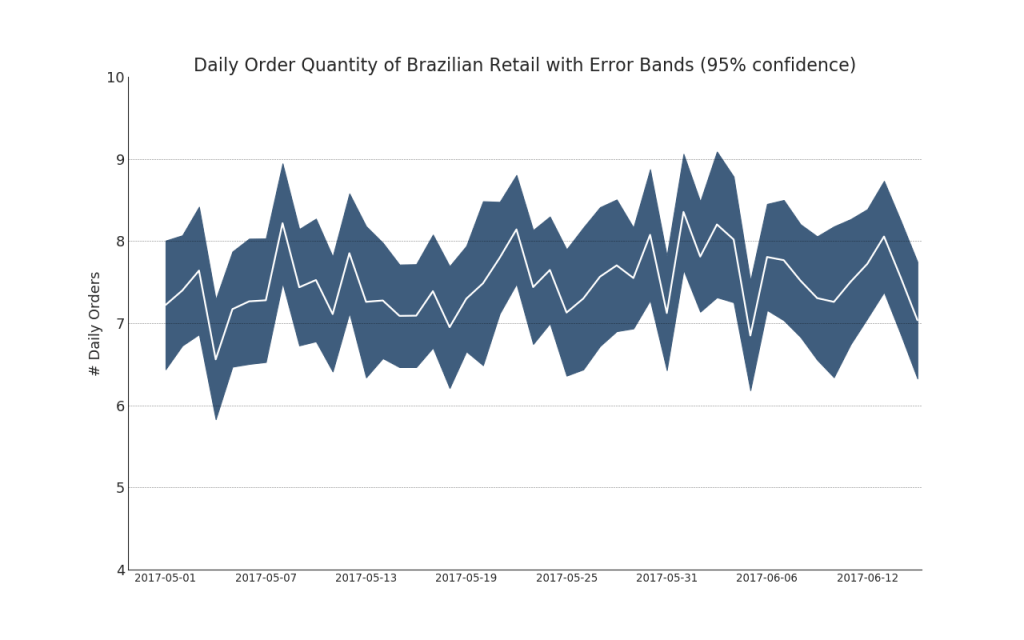
42. Series temporales con barras de error
Se pueden construir series de tiempo con barras de error si tiene un conjunto de datos de series de tiempo con varias observaciones para cada punto de tiempo (sello de fecha / hora). A continuación puede ver algunos ejemplos basados en la recepción de pedidos en diferentes momentos del día. Y otro ejemplo de la cantidad de pedidos recibidos dentro de los 45 días.Con este enfoque, el número promedio de pedidos se indica mediante una línea blanca. Y los intervalos del 95% se calculan y se grafican alrededor del promedio.Mostrar código from scipy.stats import sem
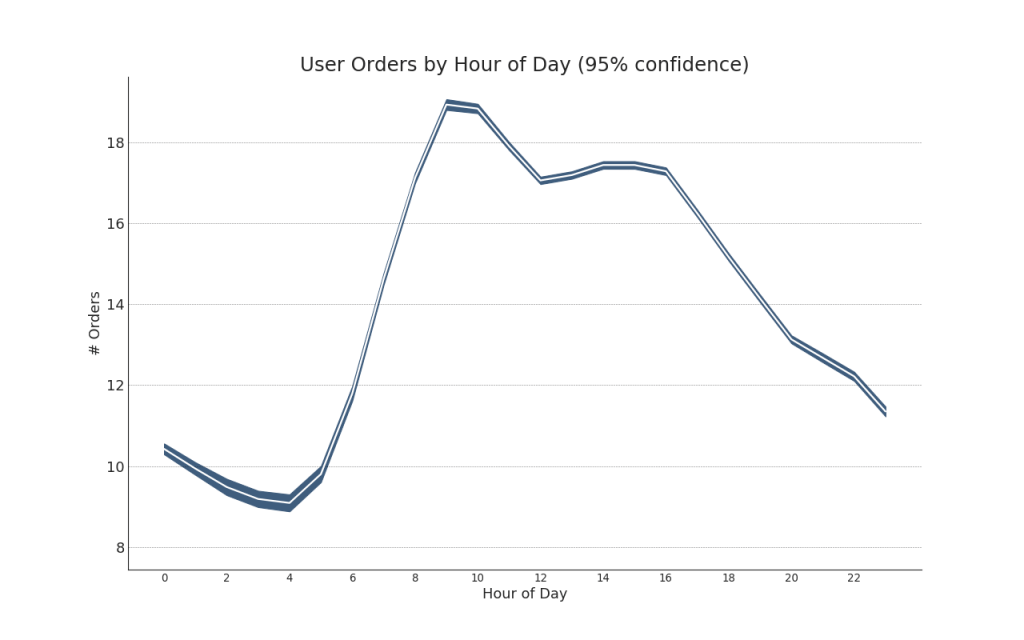
Mostrar código "Data Source: https://www.kaggle.com/olistbr/brazilian-ecommerce#olist_orders_dataset.csv" from dateutil.parser import parse from scipy.stats import sem
43. Gráfico con acumulación
El gráfico de área apilada proporciona una representación visual de la tasa de contribución de múltiples series de tiempo.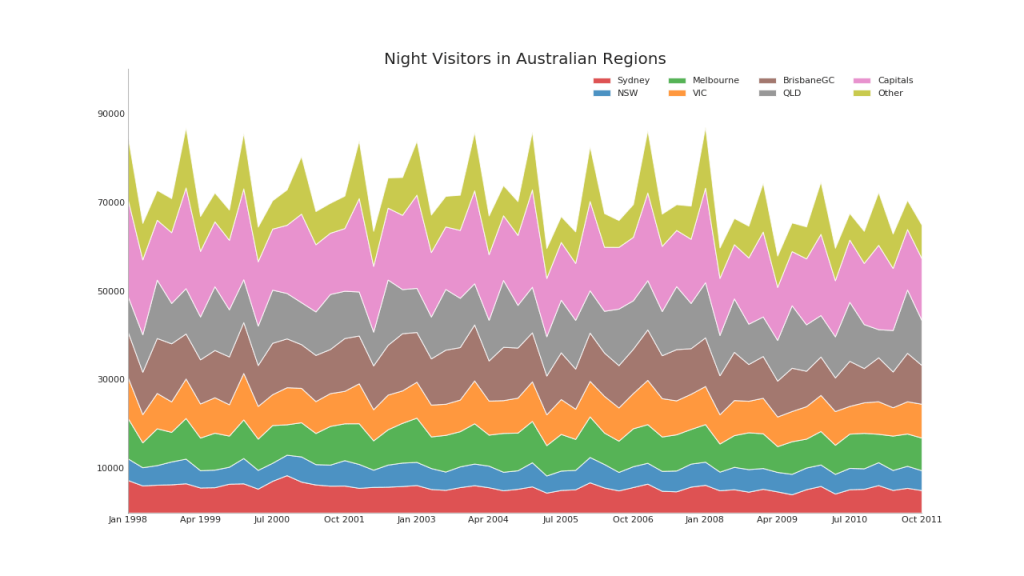
44. Gráfico de área sin apilar
Se utiliza un gráfico de área abierta para visualizar el progreso (subidas y bajadas) de dos o más filas entre sí. En el diagrama a continuación, puede ver claramente cómo la tasa de ahorro personal disminuye con un aumento en la duración promedio del desempleo. Un diagrama con secciones abiertas muestra bien este fenómeno.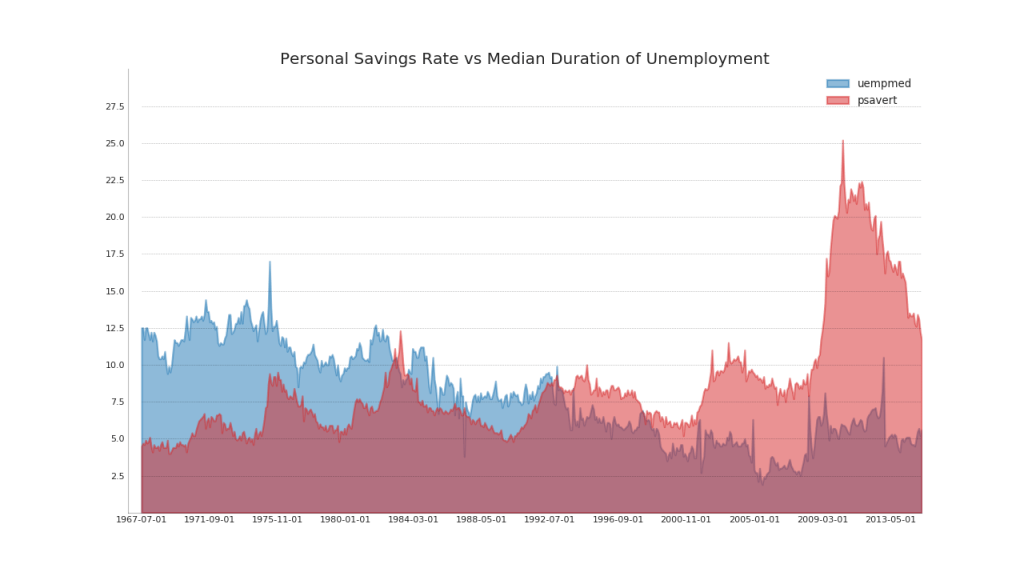
45. Mapa de calor del calendario
Un mapa de calendario es una opción alternativa y menos preferida para visualizar datos basados en el tiempo en comparación con una serie de tiempo. Aunque pueden ser visualmente atractivos, los valores numéricos no son del todo obvios.Mostrar código import matplotlib as mpl import calmap

46. Gráfico estacional
El horario estacional se puede utilizar para comparar series de tiempo realizadas el mismo día en la temporada anterior (año / mes / semana, etc.).Mostrar código from dateutil.parser import parse
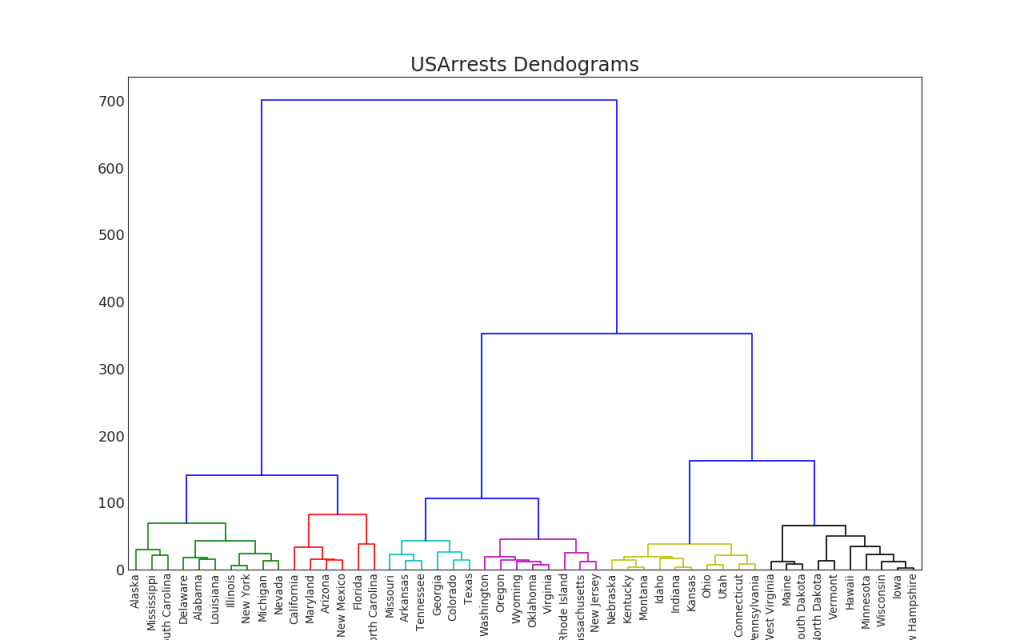
Grupos
47. Dendrograma
El dendrograma agrupa puntos similares sobre la base de una métrica de distancia dada y los organiza en forma de enlaces de árbol basados en la similitud de puntos.Mostrar código import scipy.cluster.hierarchy as shc
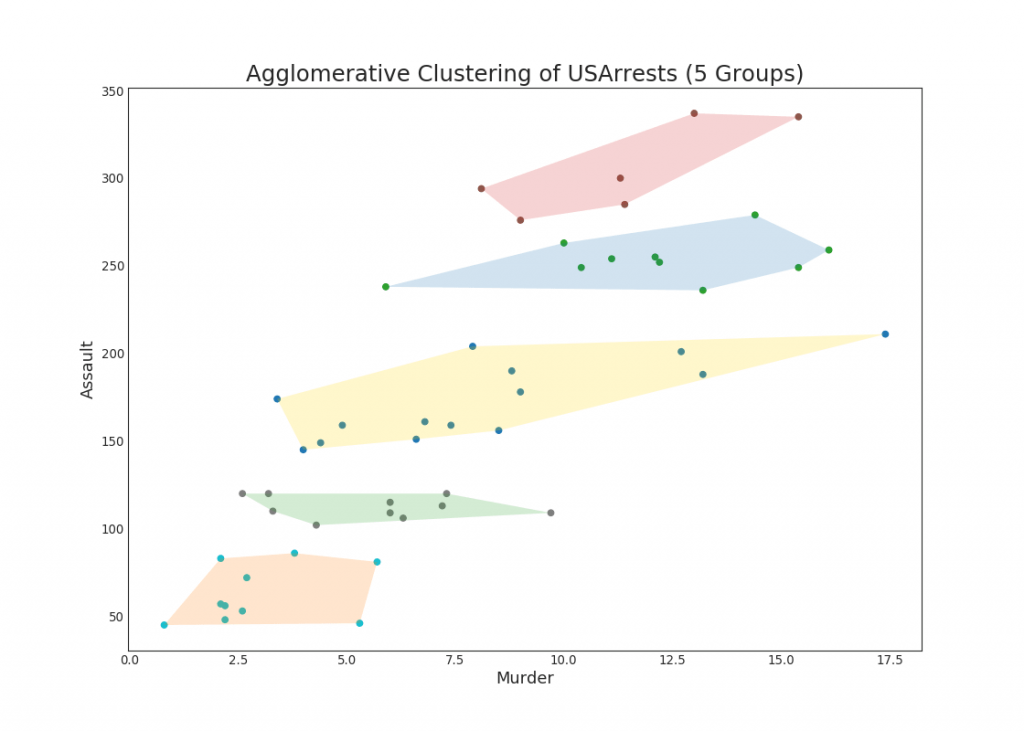
48. Diagrama de clúster
El gráfico de clúster se puede utilizar para distinguir puntos que pertenecen a un clúster. El siguiente es un ejemplo ilustrativo de la agrupación de estados de EE. UU. En 5 grupos según el conjunto de datos de USArrests. Este gráfico de clúster usa las columnas "matar" y "atacar" como ejes X e Y. Alternativamente, puede usar los componentes primero a principal como los ejes X e Y.Mostrar código from sklearn.cluster import AgglomerativeClustering from scipy.spatial import ConvexHull
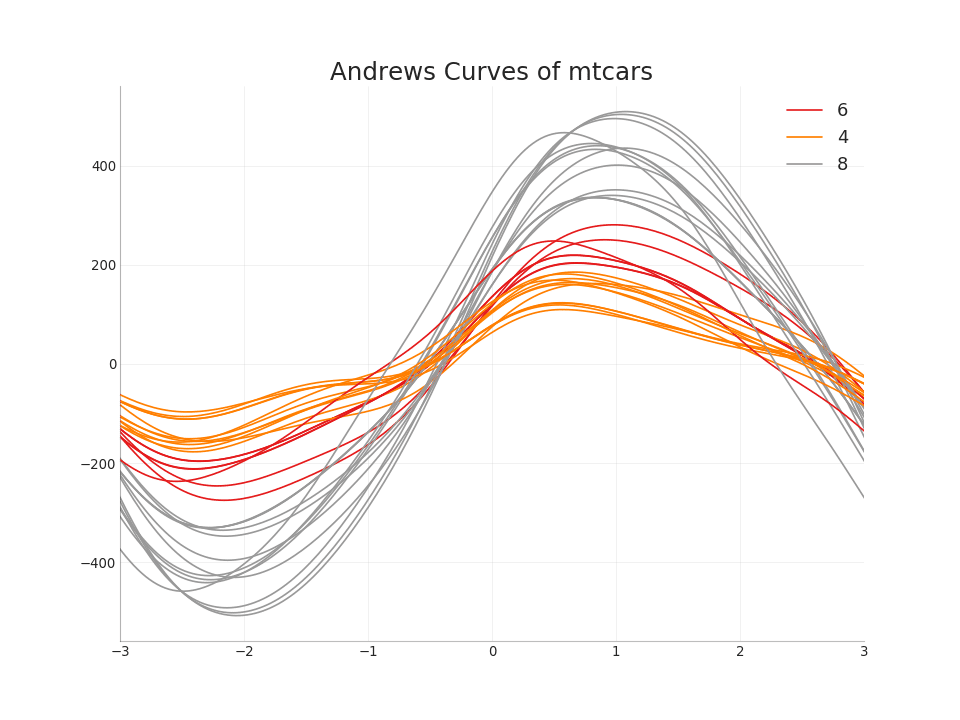
49. Andrews Curve
La curva de Andrews ayuda a visualizar si existen características numéricas inherentes a una agrupación basadas en una agrupación dada. Si los objetos (columnas en el conjunto de datos) no ayudan a distinguir el grupo, entonces las líneas no estarán bien separadas, como se muestra a continuaciónMostrar código from pandas.plotting import andrews_curves
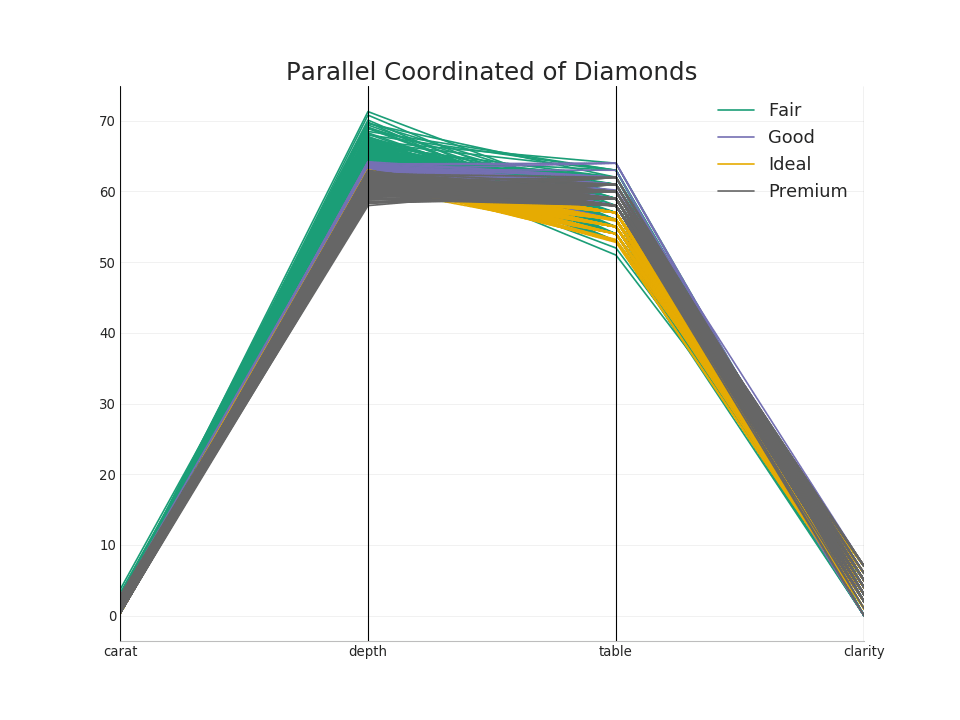
50. Coordenadas paralelas
Las coordenadas paralelas ayudan a visualizar si una función ayuda a separar efectivamente los grupos. Si se produce una segregación, es probable que esta característica sea muy útil para predecir este grupo.Mostrar código from pandas.plotting import parallel_coordinates
 Código de bonificación en Júpiter
Código de bonificación en Júpiter¡Ganso, prometiste vibras!