Hoy en día, las palabras "inteligencia artificial" significan muchos sistemas diferentes, desde una red neuronal para el reconocimiento de imágenes hasta un bot para jugar Quake. Wikipedia ofrece una maravillosa definición de IA: esta es "la propiedad de los sistemas inteligentes para realizar funciones creativas que tradicionalmente se consideran prerrogativas del hombre". Es decir, se ve claramente en la definición: si una determinada función se automatizó con éxito, entonces deja de considerarse inteligencia artificial.
Sin embargo, cuando se estableció por primera vez la tarea de "crear inteligencia artificial", AI significaba algo diferente. Este objetivo ahora se llama IA fuerte o IA de propósito general.
Declaración del problema.
Ahora hay dos formulaciones bien conocidas del problema. El primero es la IA fuerte. El segundo es una IA de propósito general (también conocida como Inteligencia General Artificial, abreviada AGI).
Upd. En los comentarios, me dicen que esta diferencia es más probable en el nivel del idioma. En ruso, la palabra "inteligencia" no significa exactamente lo que la palabra "inteligencia" en inglés
Una IA fuerte es una IA hipotética que podría hacer todo lo que una persona podría hacer. Por lo general, se menciona que debe pasar la prueba de Turing en la configuración inicial (hmm, ¿la gente lo pasa?), Ser consciente de sí mismo como una persona separada y ser capaz de lograr sus objetivos.
Es decir, es algo así como una persona artificial. En mi opinión, la utilidad de tal IA es principalmente investigación, porque las definiciones de una IA fuerte no dicen en ninguna parte cuáles serán sus objetivos.
AGI o IA de propósito general es una "máquina de resultados". Ella recibe un determinado objetivo en la entrada y da algunas acciones de control en motores / láseres / tarjeta de red / monitores. Y el objetivo se logra. Al mismo tiempo, AGI inicialmente no tiene conocimiento sobre el medio ambiente, solo sensores, actuadores y el canal a través del cual establece objetivos. El sistema de gestión se considerará un AGI si puede alcanzar cualquier objetivo en cualquier entorno. La llevamos a conducir un automóvil y evitar accidentes, ella lo manejará. La pusimos en control de un reactor nuclear para que haya más energía, pero no explote, ella puede manejarlo. Le daremos un buzón de correo y le indicaremos que venda aspiradoras, también lo veremos. AGI es un solucionador de "problemas inversos". Comprobar cuántas aspiradoras se venden es una cuestión simple. Pero descubrir cómo convencer a una persona para que compre esta aspiradora ya es una tarea para el intelecto.
En este artículo hablaré sobre AGI. Sin pruebas de Turing, sin autoconciencia, sin personalidades artificiales: inteligencia artificial excepcionalmente pragmática y no menos operadores pragmáticos.
Estado actual de las cosas
Ahora existe una clase de sistemas como el aprendizaje reforzado o el aprendizaje reforzado. Esto es algo así como AGI, solo que sin versatilidad. Son capaces de aprender y, debido a esto, alcanzar objetivos en una variedad de entornos. Pero aún están muy lejos de lograr objetivos en cualquier entorno.
En general, ¿cómo se organizan los sistemas de aprendizaje por refuerzo y cuáles son sus problemas?
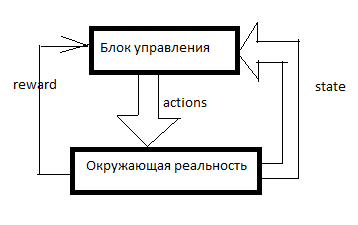
Cualquier RL está organizado de esta manera. Hay un sistema de control, algunas señales sobre la realidad circundante ingresan a través de los sensores (estado) y a través de los cuerpos gobernantes (acciones) que actúan sobre la realidad circundante. La recompensa es una señal de refuerzo. En los sistemas RL, el refuerzo se forma desde el exterior de la unidad de control e indica qué tan bien la IA se las arregla para lograr el objetivo. Cuántas aspiradoras vendidas en el último minuto, por ejemplo.
Luego se forma una tabla de algo como esto (lo llamaré la tabla SAR):

El eje del tiempo se dirige hacia abajo. La tabla muestra todo lo que hizo la IA, todo lo que vio y todas las señales de refuerzo. Por lo general, para que RL haga algo significativo, primero necesita hacer movimientos aleatorios por un tiempo o mirar los movimientos de otra persona. En general, RL comienza cuando ya hay al menos algunas líneas en la tabla SAR.
¿Qué pasa después?
Sarsa
La forma más simple de aprendizaje por refuerzo.
Tomamos algún tipo de modelo de aprendizaje automático y, usando una combinación de S y A (estado y acción), predecimos la R total para los próximos ciclos de reloj. Por ejemplo, veremos que (según la tabla anterior) si le dice a una mujer "¡sea un hombre, compre una aspiradora!", Entonces la recompensa será baja, y si le dice lo mismo a un hombre, entonces alta.
Qué modelos específicos se pueden usar: lo describiré más adelante, por ahora solo diré que no se trata solo de redes neuronales. Puede usar árboles de decisión o incluso definir una función en forma de tabla.
Y luego sucede lo siguiente. AI recibe otro mensaje o enlace a otro cliente. Todos los datos del cliente se ingresan en la IA desde el exterior: consideraremos la base de clientes y el contador de mensajes como parte del sistema de sensores. Es decir, queda asignar algo de A (acción) y esperar refuerzos. AI realiza todas las acciones posibles y, a su vez, predice (utilizando el mismo modelo de Machine Learning): ¿qué sucederá si hago eso? ¿Y si es así? ¿Y cuánto refuerzo habrá para esto? Y luego RL realiza la acción para la cual se espera la recompensa máxima.
Introduje un sistema tan simple y torpe en uno de mis juegos. SARSA contrata unidades en el juego y se adapta en caso de un cambio en las reglas del juego.
Además, en todos los tipos de entrenamiento reforzado, hay un descuento de recompensas y un dilema de exploración / explotación.
Descontar los premios es un enfoque de este tipo cuando RL intenta maximizar no el monto de la recompensa para los próximos N movimientos, sino el monto ponderado según el principio "100 rublos ahora es mejor que 110 en un año". Por ejemplo, si el factor de descuento es 0.9, y el horizonte de planificación es 3, entonces entrenaremos el modelo no en el R total para los próximos 3 ciclos de reloj, sino en R1 * 0.9 + R2 * 0.81 + R3 * 0.729. ¿Por qué es esto necesario? Entonces, esa IA, creando una ganancia en algún lugar allí en el infinito, no la necesitamos. Necesitamos una IA que genere ganancias aquí y ahora.
Explorar / explotar dilema. Si RL hace lo que su modelo considera óptimo, nunca sabrá si hubo mejores estrategias. Exploit es una estrategia en la que RL hace lo que promete recompensas máximas. Explorar es una estrategia en la que RL hace algo para explorar el entorno en busca de mejores estrategias. ¿Cómo implementar una inteligencia efectiva? Por ejemplo, puede realizar una acción aleatoria cada pocas medidas. O puede hacer no un modelo predictivo, sino varios con configuraciones ligeramente diferentes. Producirán resultados diferentes. Cuanto mayor es la diferencia, mayor es el grado de incertidumbre de esta opción. Puede realizar la acción para que tenga el valor máximo: M + k * std, donde M es el pronóstico promedio de todos los modelos, std es la desviación estándar de los pronósticos y k es el coeficiente de curiosidad.
¿Cuáles son las desventajas?Digamos que tenemos opciones. Vaya a la meta (que está a 10 km de nosotros, y el camino es bueno) en automóvil o a pie. Y luego, después de esta elección, tenemos opciones: movernos con cuidado o tratar de chocar contra cada pilar.
La persona dirá de inmediato que generalmente es mejor conducir un automóvil y comportarse con cuidado.
Pero SARSA ... Verá a lo que llevó la decisión de ir en automóvil antes. Pero llevó a esto. En la etapa del conjunto inicial de estadísticas, la IA condujo imprudentemente y se estrelló en algún lugar en la mitad de los casos. Sí, él puede conducir bien. Pero cuando elige ir en automóvil, no sabe qué elegirá para el próximo movimiento. Tiene estadísticas: luego, en la mitad de los casos, eligió la opción adecuada, y en la mitad, suicida. Por lo tanto, en promedio, es mejor caminar.
SARSA cree que el agente se adherirá a la misma estrategia que se utilizó para completar la tabla. Y actúa sobre esta base. Pero, ¿qué sucede si suponemos lo contrario, que el agente se adherirá a la mejor estrategia en los próximos movimientos?
Q-learning
Este modelo calcula para cada estado la recompensa total máxima alcanzable de él. Y lo escribe en una columna especial Q. Es decir, si del estado S puede obtener 2 puntos o 1, dependiendo del movimiento, Q (S) será igual a 2 (con una profundidad de predicción de 1). ¿Qué recompensa se puede obtener del estado S? Aprendemos del modelo predictivo Y (S, A). (S - estado, A - acción).
Luego creamos un modelo predictivo Q (S, A), es decir, a qué estado irá Q si realizamos la acción A desde S. Y creamos la siguiente columna en la tabla: Q2. Es decir, el Q máximo que se puede obtener del estado S (clasificamos todos los A posibles).
Luego creamos un modelo de regresión Q3 (S, A), es decir, al estado con el que iremos Q2 si realizamos la acción A desde S.
Y así sucesivamente. Por lo tanto, podemos lograr una profundidad ilimitada de pronóstico.
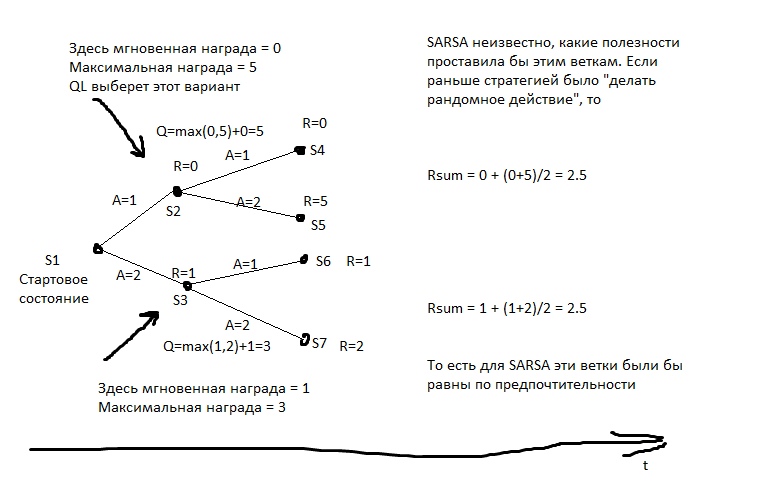
En la imagen, R es el refuerzo.
Y luego, cada movimiento seleccionamos la acción que promete el mayor Qn. Si aplicamos este algoritmo al ajedrez, obtendríamos algo así como un minimax ideal. Algo casi equivalente a calcular mal movimientos a grandes profundidades.
Un ejemplo común de comportamiento de q-learning. El cazador tiene una lanza, y lo acompaña al oso, por iniciativa propia. Él sabe que la gran mayoría de sus movimientos futuros tienen una recompensa negativa muy grande (hay muchas más formas de perder que formas de ganar), él sabe que hay movimientos con una recompensa positiva. El cazador cree que en el futuro hará los mejores movimientos (y no se sabe cuáles como en SARSA), y si hace los mejores movimientos, derrotará al oso. Es decir, para ir al oso, es suficiente para que él pueda hacer todos los elementos necesarios para la caza, pero no es necesario tener una experiencia de éxito inmediato.
Si el cazador actuara al estilo SARSA, supondría que sus acciones en el futuro serían más o menos las mismas que antes (a pesar de que ahora tiene un bagaje de conocimientos diferente), y solo iría al oso si ya fue a y ganó, por ejemplo, en> 50% de los casos (bueno, o si otros cazadores ganaron en más de la mitad de los casos, si aprende de su experiencia).
¿Cuáles son las desventajas?- El modelo no hace frente a la realidad cambiante. Si toda nuestra vida hemos sido premiados por presionar el botón rojo, y ahora nos están castigando, y no se han producido cambios visibles ... QL dominará este patrón durante mucho tiempo.
- Qn puede ser una función muy compleja. Por ejemplo, para calcularlo, debe desplazarse por un ciclo de N iteraciones, y no funcionará más rápido. Y el modelo predictivo generalmente tiene una complejidad limitada: incluso una red neuronal grande tiene un límite de complejidad, y casi ningún modelo de aprendizaje automático puede rotar los ciclos.
- La realidad generalmente tiene variables ocultas. Por ejemplo, ¿qué hora es ahora? Es fácil saber si miramos el reloj, pero tan pronto como miramos hacia otro lado, ya es una variable oculta. Para tener en cuenta estos valores no observables, es necesario que el modelo tenga en cuenta no solo el estado actual, sino también algún tipo de historia. En QL, puede hacer esto, por ejemplo, para alimentar no solo la S actual, sino también varias anteriores, a la neurona o lo que está allí. Esto se hace en RL, que juega juegos de Atari. Además, puede usar una red neuronal recurrente para el pronóstico: deje que se ejecute secuencialmente en varios cuadros de la historia y calcule Qn.
Sistemas basados en modelos.
Pero, ¿qué sucede si predecimos no solo R o Q, sino en general todos los datos sensoriales? Constantemente tendremos una copia de bolsillo de la realidad y podremos verificar nuestros planes al respecto. En este caso, estamos mucho menos preocupados por la dificultad de calcular la función Q. Sí, requiere muchos relojes para calcular, bueno, de todos modos, para cada plan, ejecutaremos repetidamente el modelo de pronóstico. ¿Planeando 10 movimientos hacia adelante? Lanzamos el modelo 10 veces, y cada vez que alimentamos sus salidas a su entrada.
¿Cuáles son las desventajas?- Intensidad de recursos. Supongamos que necesitamos elegir dos alternativas en cada medida. Luego, durante 10 ciclos de reloj tendremos 2 ^ 10 = 1024 planes posibles. Cada plan tiene 10 lanzamientos de modelos. ¿Si controlamos un avión con docenas de órganos de gobierno? ¿Y simulamos la realidad con un período de 0.1 segundos? ¿Desea tener un horizonte de planificación por al menos un par de minutos? Tendremos que ejecutar el modelo muchas veces, hay muchos ciclos de reloj del procesador para una solución. Incluso si de alguna manera optimizas la enumeración de planes, de todos modos, hay órdenes de magnitud más cálculos que en QL.
- El problema del caos. Algunos sistemas están diseñados para que incluso una pequeña imprecisión de la simulación de entrada provoque un gran error de salida. Para contrarrestar esto, puede ejecutar varias simulaciones de la realidad, un poco diferente. Producirán resultados muy diferentes, y de esto será posible entender que estamos en la zona de tal inestabilidad.
Método de enumeración de estrategia
Si tenemos acceso al entorno de prueba para IA, si lo ejecutamos no en realidad, sino en una simulación, entonces podemos escribir de alguna forma la estrategia del comportamiento de nuestro agente. Y luego elija, con evolución u otra cosa, una estrategia que conduzca al máximo beneficio.
"Elegir una estrategia" significa que primero tenemos que aprender a escribir una estrategia de tal manera que pueda introducirse en el algoritmo de evolución. Es decir, podemos escribir la estrategia con el código del programa, pero en algunos lugares dejamos los coeficientes y dejamos que la evolución los recoja. O podemos escribir una estrategia con una red neuronal y dejar que la evolución recoja el peso de sus conexiones.
Es decir, no hay pronóstico aquí. No hay mesa SAR. Simplemente seleccionamos una estrategia, e inmediatamente da Acciones.
Este es un método poderoso y efectivo, si desea probar RL y no sabe por dónde comenzar, lo recomiendo. Esta es una forma muy barata de "ver un milagro".
¿Cuáles son las desventajas?- Se requiere la capacidad de ejecutar los mismos experimentos muchas veces. Es decir, deberíamos ser capaces de rebobinar la realidad hasta el punto de partida, decenas de miles de veces. Para probar una nueva estrategia.
La vida rara vez brinda tales oportunidades. Por lo general, si tenemos un modelo del proceso que nos interesa, no podemos crear una estrategia astuta: simplemente podemos elaborar un plan, como en un enfoque basado en modelos, incluso con fuerza bruta contundente. - Intolerancia a la experiencia. ¿Tenemos una mesa SAR para años de experiencia? Podemos olvidarlo, no encaja en el concepto.
Un método para enumerar estrategias, pero "en vivo"
La misma enumeración de estrategias, pero sobre la realidad viva. Intentamos 10 medidas de una estrategia. Entonces 10 mide otro. Luego 10 medidas de la tercera. Luego seleccionamos aquel donde había más refuerzo.
Los mejores resultados para caminar humanoides se obtuvieron mediante este método.

Para mí, esto suena algo inesperado: parece que el enfoque basado en el modelo QL + es matemáticamente ideal. Pero nada de eso. Las ventajas del enfoque son aproximadamente las mismas que las anteriores, pero son menos pronunciadas, ya que las estrategias no se prueban por mucho tiempo (bueno, no tenemos milenios en evolución), lo que significa que los resultados son inestables. Además, el número de pruebas tampoco puede elevarse hasta el infinito, lo que significa que la estrategia deberá buscarse en un espacio de opciones no muy complicado. No solo tendrá "plumas" que se pueden "torcer". Bueno, la intolerancia a la experiencia no ha sido cancelada. Y, en comparación con QL o basado en modelos, estos modelos utilizan la experiencia de manera ineficiente. Necesitan muchas más interacciones con la realidad que los enfoques que utilizan el aprendizaje automático.
Como puede ver, cualquier intento de crear un AGI en teoría debería incluir el aprendizaje automático para pronosticar premios, o alguna forma de notación paramétrica de una estrategia, para que pueda elegir esta estrategia con algo como la evolución.
Este es un fuerte ataque hacia las personas que ofrecen crear IA basada en bases de datos, lógica y gráficos conceptuales. Si ustedes, los defensores del enfoque simbólico, leen esto, bienvenidos a los comentarios, estaré encantado de saber qué puede hacer AGI sin la mecánica descrita anteriormente.
Modelos de aprendizaje automático para RL
Casi cualquier modelo de ML se puede utilizar para el aprendizaje reforzado. Las redes neuronales son, por supuesto, buenas. Pero hay, por ejemplo, KNN. Para cada par S y A, buscamos los más similares, pero en el pasado. ¿Y estamos buscando qué será R. Stupid después de eso? Si, pero funciona. Hay árboles decisivos: aquí es mejor dar un paseo por las palabras clave "aumento de gradiente" y "bosque decisivo". ¿Los árboles son pobres para capturar dependencias complejas? Utilice la ingeniería de características. ¿Quieres tu IA más cerca de General? ¡Usa FE automático! Revise un montón de fórmulas diferentes, envíelas como características para su impulso, descarte las fórmulas que aumentan el error y deje las fórmulas que mejoran la precisión. Luego, envíe las mejores fórmulas como argumentos para las nuevas fórmulas, y así sucesivamente, evolucione.
Puede usar regresiones simbólicas para pronosticar, es decir, simplemente ordenar fórmulas en un intento de obtener algo que se aproxime a Q o R. Es posible intentar ordenar algoritmos; luego se obtiene una cosa llamada inducción de Solomonov, que es teóricamente óptima, pero casi muy difícil de entrenar aproximaciones de funciones.
Pero las redes neuronales suelen ser un compromiso entre la expresividad y la complejidad del aprendizaje. La regresión algorítmica idealmente recoge cualquier dependencia, durante cientos de años. El árbol de decisión funcionará muy rápidamente, pero no podrá extrapolar y = a + b. Una red neuronal es algo intermedio.
Perspectivas de desarrollo.
¿Cuáles son las formas de hacer exactamente AGI ahora? Al menos teóricamente.
Evolución
Podemos crear muchos entornos de prueba diferentes y comenzar la evolución de algunas redes neuronales.
Las configuraciones que obtengan más puntos en total para todas las pruebas se multiplicarán.La red neuronal debe tener memoria y sería deseable tener al menos parte de la memoria en forma de cinta, como una máquina de Turing o como en un disco duro.El problema es que, con la ayuda de la evolución, puede crecer algo como RL, por supuesto. Pero, ¿cómo debería ser el lenguaje en el que RL parece compacto, para que la evolución lo encuentre, y al mismo tiempo que la evolución no encuentra soluciones como "pero crearé una neurona para ciento cincuenta capas para que todos se vuelvan locos mientras lo enseño!" . La evolución es como una multitud de usuarios analfabetos: encontrará fallas en el código y abandonará todo el sistema.Aixi
Puede hacer un sistema basado en modelos basado en un paquete de muchas regresiones algorítmicas. Se garantiza que el algoritmo estará completo en Turing, lo que significa que no habrá patrones que no se puedan recoger. El algoritmo está escrito en código, lo que significa que su complejidad se puede calcular fácilmente. Esto significa que es posible refinar matemáticamente correctamente sus hipótesis sobre el dispositivo de complejidad del mundo. Con las redes neuronales, por ejemplo, este truco no funcionará; allí la penalización por la complejidad es muy indirecta y heurística.Solo queda aprender a entrenar rápidamente regresiones algorítmicas. Hasta ahora, lo mejor que hay para esto es la evolución, y es imperdonablemente largo.AI de semillas
Sería genial crear una IA que se mejore a sí misma. Mejora tu capacidad para resolver problemas. Esto puede parecer una idea extraña, pero este problema ya se ha resuelto para sistemas de optimización estática, como la evolución . Si logras darte cuenta de esto ... ¿Lo sabe todo sobre el expositor? Obtendremos una IA muy poderosa en muy poco tiempo.Como hacerloPuede intentar arreglar que en RL algunas de las acciones afecten la configuración de RL.O proporcione al sistema RL alguna herramienta para crear nuevos procesadores de datos previos y posteriores. Deje que RL sea tonto, pero podrá crear calculadoras, computadoras portátiles y computadoras por sí mismo.Otra opción es crear algún tipo de IA utilizando la evolución, en la que parte de las acciones afectarán a su dispositivo a nivel de código.Pero por el momento no he visto opciones viables para Seed AI, aunque muy limitadas. ¿Se están escondiendo los desarrolladores? ¿O son estas opciones tan débiles que no merecían atención general y me pasaron por alto?Sin embargo, ahora tanto Google como DeepMind trabajan principalmente con arquitecturas de redes neuronales. Aparentemente, no quieren involucrarse en la enumeración combinatoria y tratar de hacer que cualquiera de sus ideas sea adecuada para el método de propagación del error.Espero que este artículo de revisión haya resultado útil =) ¡Los comentarios son bienvenidos, especialmente comentarios como "Sé cómo mejorar AGI"!