Las redes neuronales capturan el mundo. Cuentan visitantes, monitorean la calidad, mantienen estadísticas y evalúan la seguridad. Un montón de startups, uso industrial.
Grandes marcos. Qué es PyTorch, cuál es el segundo TensorFlow. Todo se está volviendo más conveniente y conveniente, más simple y más simple ...
Pero hay un lado oscuro. Intentan guardar silencio sobre ella. No hay nada alegre allí, solo oscuridad y desesperación. Cada vez que ves un artículo positivo, suspiras tristemente, porque entiendes que solo una persona no entendió algo. O lo escondió.
Hablemos de la producción en dispositivos integrados.

Cual es el problema
Parecería. Observe el rendimiento del dispositivo, asegúrese de que sea suficiente, ejecútelo y obtenga ganancias.
Pero, como siempre, hay un par de matices. Pongámoslos en los estantes:
- Producción. Si su dispositivo no está hecho en copias individuales, entonces debe asegurarse de que el sistema no se cuelgue, que los dispositivos no se sobrecalienten, que si hay una falla de energía, todo se inicie automáticamente. Y esto es en una gran fiesta. Esto ofrece solo dos opciones: el dispositivo debe estar completamente diseñado teniendo en cuenta todos los posibles problemas. O necesita superar los problemas del dispositivo fuente. Bueno, por ejemplo, estos son ( 1 , 2 ). Que, por supuesto, es estaño. Para resolver los problemas del dispositivo de otra persona en grandes lotes, es necesario gastar una cantidad de energía poco realista.
- Puntos de referencia reales. Muchas estafas y trucos. NVIDIA en la mayoría de los ejemplos sobreestima el rendimiento en un 30-40%. Pero no solo ella se divierte. A continuación, doy muchos ejemplos cuando la productividad puede ser de 4 a 5 veces menos de lo que desea. No se puede echar un polvo "todo funcionó bien en la computadora, aquí será proporcionalmente peor".
- Soporte muy limitado para la arquitectura de redes neuronales. Hay muchas plataformas de hardware integradas que limitan en gran medida las redes que se pueden ejecutar en ellas (Coral, gyrfalcone, snapdragon). Portar a tales plataformas será doloroso.
- Apoyo. Algo no funciona para usted, pero el problema está en el lado del dispositivo ... Este es el destino, no funcionará. Solo para RPi, la comunidad cierra la mayoría de los errores. Y, en parte, por Jetson.
- Precio A muchos les parece que incrustar es barato. Pero, en realidad, con el crecimiento del rendimiento del dispositivo, el precio aumentará casi exponencialmente. RPi-4 es 5 veces más barato que Jetson Nano / Google Coral y 2-3 veces más débil. Jetson Nano es 5 veces más barato que Jetson TX2 / Intel NUC, y 2-3 veces más débil que ellos.
- Lorgus ¿Recuerdas este diseño de Zhelyazny?
Parece que lo configuré como la imagen del título ... " el Logrus es un laberinto tridimensional cambiante que representa las fuerzas del Caos en el multiverso " . Todo esto es una gran cantidad de errores y agujeros, todas estas diversas piezas de hierro, todos los marcos cambiantes ... Es normal cuando la imagen del mercado cambia completamente en 2-3 meses. Durante este año, ha cambiado 3-4 veces. No puedes entrar al mismo río dos veces. Entonces, todos los pensamientos actuales son ciertos para el verano de 2019.
Que es
Vamos a ponerlo en orden, no tiene un sabor dulce ... ¿Qué hay ahora y es adecuado para las neuronas? No hay tantas opciones, a pesar de su variabilidad. Algunas palabras generales para limitar la búsqueda:
- No analizaré las neuronas / inferencias en los teléfonos. Esto en sí mismo es un gran tema. Pero como los teléfonos son plataformas integradas con un ajuste de interferencia, no creo que sea malo.
- Tocaré en Jetson TX1 | TX2. En las condiciones actuales, estas no son las plataformas más óptimas por el precio, pero hay situaciones en las que aún son convenientes de usar.
- No garantizo que la lista incluya todas las plataformas que existen hoy. Tal vez olvidé algo, tal vez no sé sobre algo. Si conoce más plataformas interesantes, ¡escriba!
Entonces Las cosas principales que claramente están incrustando. En el artículo los compararemos con precisión:

- Plataforma Jetson . Hay varios dispositivos para ello:
- Jetson Nano : un juguete barato y bastante moderno (primavera de 2019)
- Jetson Tx1 | Tx2 : bastante costoso pero bueno en plataformas de rendimiento y versatilidad
- Raspberry Pi . En realidad, solo RPi4 tiene el rendimiento para redes neuronales. Pero algunas tareas separadas se pueden hacer en la tercera generación. Incluso comencé cuadrículas muy simples al principio.
- Google Coral Platform. De hecho, para incrustar dispositivos solo hay un chip y dos dispositivos: placa de desarrollo y acelerador USB
- Plataforma Intel Movidius . Si no es una gran empresa, solo estarán disponibles para usted los palos Movidius 1 | Movidius 2.
- Plataforma Gyrfalcone . El milagro de la tecnología china. Ya hay dos generaciones: 2801, 2803
Misceláneos Hablaremos de ellos después de las principales comparaciones:
- Procesadores Intel. En primer lugar, los ensamblajes NUC.
- GPU Nvidia Mobile. Las soluciones preparadas pueden considerarse no integradas. Y si recolectas incrustaciones, entonces resultará decentemente en las finanzas.
- Teléfonos móviles. Android se caracteriza por el hecho de que para usar el máximo rendimiento, es necesario usar exactamente el hardware que tiene un fabricante en particular. O use algo universal, como la luz tensorflow. Para Apple, lo mismo.
- Jetson AGX Xavier es una versión cara de Jetson con más rendimiento.
- GAP8: procesadores de baja potencia para dispositivos súper económicos.
- Mysterious Grove AI HAT
Jetson
Hemos estado trabajando con Jetson durante mucho tiempo. En 2014,
Vasyutka inventó las matemáticas para el entonces
Swift precisamente en Jetson. En 2015, en una reunión con Artec 3D, hablamos sobre qué plataforma es genial, después de lo cual sugirieron que construyamos un prototipo basado en él. Después de un par de meses, el prototipo estaba listo. Solo un par de años de trabajo de toda la compañía, un par de años de maldiciones en la plataforma y en el cielo ... Y nació
Artec Leo , el escáner más genial de su clase. Incluso Nvidia en la presentación de TX2 lo
mostró como uno de los proyectos más interesantes creados en la plataforma.
Desde entonces, TX1 / TX2 / Nano utilizamos en algún lugar en 5-6 proyectos.
Y, probablemente, sabemos todos los problemas que estaban con la plataforma. Vamos a tomarlo en orden.
Jetson tk1
No voy a hablar especialmente de él. La plataforma era muy eficiente en potencia informática en su día. Pero ella no era una tienda de comestibles. NVIDIA vendió los chips
TegraTK1 que apuntalaron a Jetson. Pero estos chips eran imposibles de usar para fabricantes pequeños y medianos. En realidad, solo Google / HTC / Xiaomi / Acer / Google podría hacer algo en ellos además de Nvidia. Todos los demás integrados en el producto ya sea depuran placas o saquearon otros dispositivos.
Jetson TX1 | TX2
Nvidia llegó a las conclusiones correctas, y la próxima generación se hizo increíblemente. TX1 | TX2, ya no son chips, sino un chip en el tablero.


Son más caros, pero tienen un nivel de comestibles completo. Una pequeña empresa puede integrarlos en su producto, este producto es predecible y estable. Personalmente, vi cómo se pusieron en producción 3-4 productos, y todo estuvo bien.
Hablaré sobre TX2, porque desde la línea actual es la placa principal.
Pero, por supuesto, no todos agradecen a Dios. Que pasa
- Jetson TX2 es una plataforma costosa. En la mayoría de los productos, usará el módulo principal (según tengo entendido, desde el tamaño del lote, el precio estará en algún lugar entre 200-250 a 350-400 cu cada uno). Necesita una tabla de transporte. No conozco el mercado actual, pero antes era de unos 100-300 pies cúbicos Dependiendo de la configuración. Bueno, y encima de tu kit de cuerpo.
- Jetson TX2 no es la plataforma más rápida. A continuación discutiremos las velocidades comparativas, allí mostraré por qué esta no es la mejor opción.
- Es necesario eliminar mucho calor. Esto probablemente sea cierto para casi todas las plataformas de las que hablaremos. La carcasa debe resolver el problema de la disipación de calor. Aficionados
- Esta es una mala plataforma para fiestas pequeñas. Muchos cientos de dispositivos - aprox. Ordenar placas base, desarrollar diseños y empaques es la norma. ¿Muchos miles de dispositivos? Diseña tu placa base, y elegante. Si necesitas 5-10 - mal. Tendrá que tomar DevBoard muy probablemente. Son grandes, son un poco desagradables al destello. Esta no es una plataforma lista para RPi.
- El pobre soporte técnico de Nvidia. Escuché muchas palabrotas de que las respuestas son respondidas, ya sea información secreta o respuestas mensuales.
- Pobre infraestructura en Rusia. Es difícil de ordenar, lleva mucho tiempo. Pero al mismo tiempo, los distribuidores funcionan bien. Recientemente me encontré con un Jetson nano que se quemó el día del lanzamiento, cambiado sin dudas. Sam recogido por mensajería / trajo uno nuevo. WAH! Además, él mismo vio que la oficina de Moscú aconseja bien. Pero tan pronto como su nivel de conocimiento no permita responder la pregunta y requiera una solicitud a la oficina internacional, tendrán que esperar las respuestas durante mucho tiempo.
Lo que es asombroso:
- Mucha información, una comunidad muy grande.
- Alrededor de Nvidia hay muchas pequeñas empresas que producen accesorios. Están abiertos a negociaciones, puede ajustar su decisión. Y CarierBoard, y firmware, y sistemas de enfriamiento.
- Soporte para todos los frameworks normales (TensorFlow | PyTorch) y soporte completo para todas las redes. La única conversión que puede tener que hacer es transferir el código a TensorRT. Esto ahorrará memoria, posiblemente acelerará. En comparación con lo que habrá en otras plataformas, esto es ridículo.
- No sé cómo criar tablas. Pero de aquellos que hicieron esto por Nvidia, escuché que TX2 es una buena opción. Hay manuales que corresponden a la realidad.
- Buen consumo de energía. Pero de todo eso exactamente "incrustado" estará con nosotros, lo peor :)
- Pinza en Rusia (explicado anteriormente por qué)
- A diferencia de movidius | RPi | Coral | Gyrfalcon es una GPU real. Puede conducir no solo cuadrículas, sino también algoritmos normales
Como resultado, esta es una buena plataforma para usted si tiene dispositivos de pieza, pero por alguna razón no puede entregar una computadora completa. Algo masivo? Biometría: muy probablemente no. El reconocimiento de números está en el borde, dependiendo del flujo. Dispositivos portátiles con un precio de más de 5k dólares - posible. Coches: no, es más fácil poner una plataforma más poderosa un poco más cara.
Me parece que con el lanzamiento de una nueva generación de dispositivos baratos, TX2 morirá con el tiempo.
Las placas base para Jetson TX1 | TX2 | TX2i y otras se parecen a esto:

Y
aquí o
aquí hay más variaciones.
Jetson nano

Jetson Nano es una cosa muy interesante. Para Nvidia, este es un nuevo factor de forma que, en términos de revolución, debería compararse con el TK1. Pero los competidores ya se están acabando. Hay otros dispositivos de los que hablaremos. Es 2 veces más débil que TX2, pero 4 veces más barato. Más precisamente ... las matemáticas son complicadas. Jetson Nano en el tablero de demostración cuesta 100 dólares (en Europa). Pero si compra solo un chip, será más caro. Y tendrás que criarlo (todavía no hay una placa base para él). Y Dios no lo quiera, será 2 veces más barato en una gran fiesta que TX2.
De hecho, Jetson Nano, en su placa base, es un producto publicitario para institutos / revendedores / aficionados, lo que debería estimular el interés y la aplicación comercial. Por ventajas y desventajas (se cruza parcialmente con TX2):
- El diseño es débil y no se depura:
- Se sobrecalienta, con una carga constante que cuelga / vuela periódicamente. Una empresa familiar ha estado tratando de resolver todos los problemas durante 3 meses, no funciona.
- Tengo uno quemado cuando funciona con USB. Escuché que un amigo tenía una salida USB quemada, y el enchufe estaba funcionando. Lo más probable es que haya algunos problemas con la alimentación USB.
- Si empaqueta la placa original, entonces no habrá suficiente radiador de NVIDIA, por ejemplo, se sobrecalentará.
- La velocidad de alguna manera no es suficiente. Casi 2 veces menos que TX2 (en realidad, puede ser 1.5, pero depende de la tarea).
- Muchos dispositivos de 5-10 son generalmente muy buenos. 50-200: es difícil, tendrá que compensar todos los errores del fabricante, colgarlo en sus perros, si necesita agregar algo como POE, dolerá. Fiestas más grandes. Hoy no he oído hablar de proyectos exitosos. Pero me parece que pueden surgir dificultades como con TK1. Para ser honesto, me gustaría esperar que el próximo año se lance Jetson Nano 2, donde se corregirán estas enfermedades infantiles.
- El soporte es malo, igual que TX2
- Infraestructura pobre
Bueno
- Suficiente presupuesto en comparación con los competidores. Especialmente para fiestas pequeñas. Precio / rendimiento favorable
- A diferencia de movidius | RPi | Coral | Gyrfalcon es una GPU real. Puede conducir no solo cuadrículas, sino también algoritmos normales
- Simplemente inicie cualquier red (igual que tx2)
- Consumo de energía (igual que tx2)
- Pinza en Rusia (igual que tx2)
Nano salió a principios de la primavera, en algún lugar de abril / mayo, lo miré activamente. Ya hemos logrado hacer dos proyectos sobre ellos. En general, los problemas identificados anteriormente. Como producto de pasatiempo / producto para lotes pequeños, muy bueno. Pero aún no está claro si es posible arrastrar la producción y cómo hacerlo.
Habla sobre la velocidad de Jetson.
Vamos a comparar con otros dispositivos mucho más tarde. Mientras tanto, solo habla de Jetson y la velocidad. Por qué nos está mintiendo Nvidia. Cómo optimizar tus proyectos.
Debajo de todo está escrito sobre TensorRT-5.1. TensorRT-6.0.1 se lanzó el 17 de septiembre de 2019, todas las declaraciones deben verificarse allí.
Supongamos que creemos en Nvidia. Abramos su
sitio web y veamos el tiempo de inferencia de SSD-mobilenet-v2 a 300 * 300:
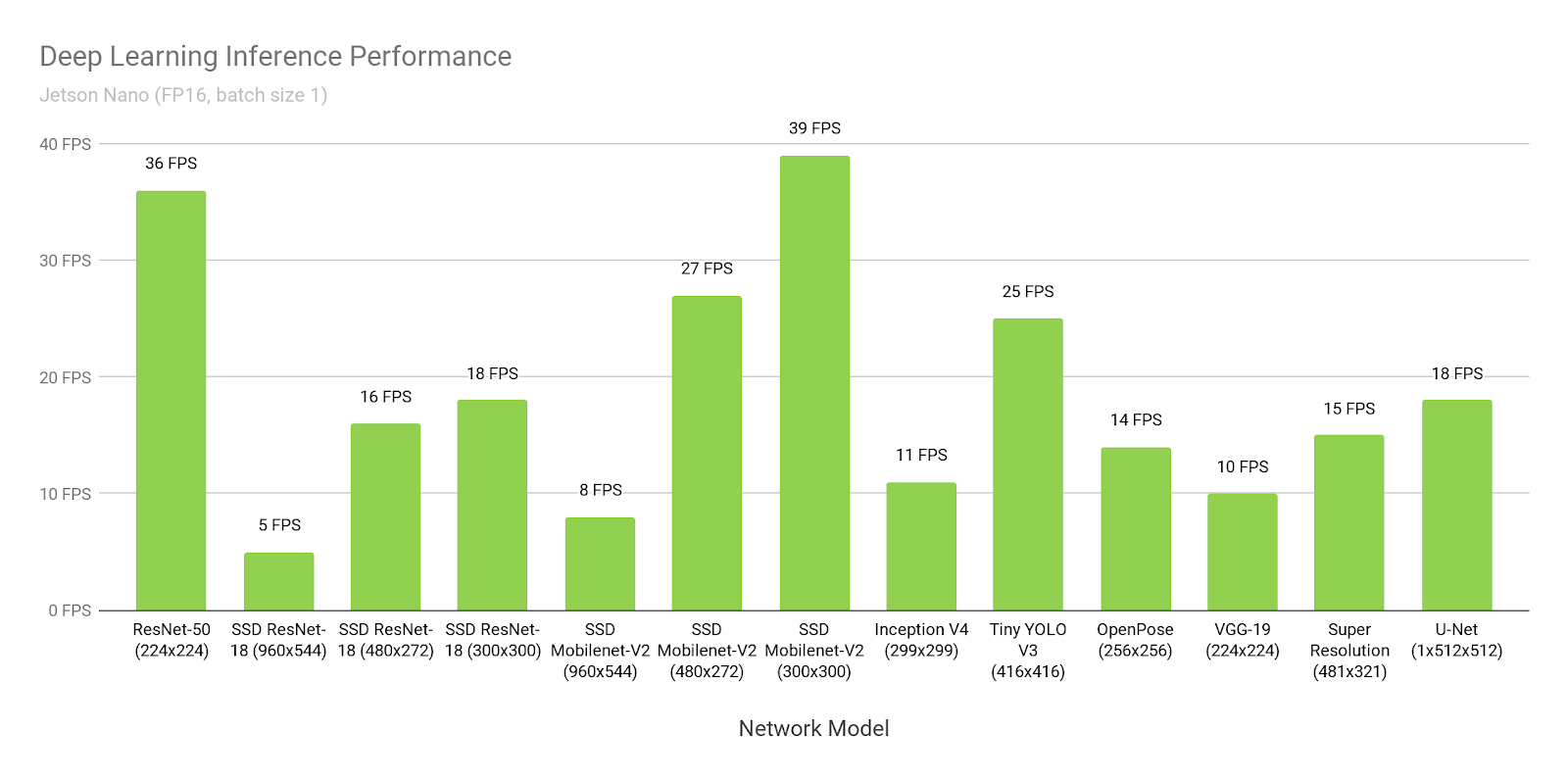
Guau, 39 fps (25 ms). Sí, ¡y se presenta el código fuente!
Hmm ... ¿Pero por qué está escrito
aquí sobre 46ms?
Espera ... Y aquí escriben que 309 ms es nativo, y 72ms está portado ...
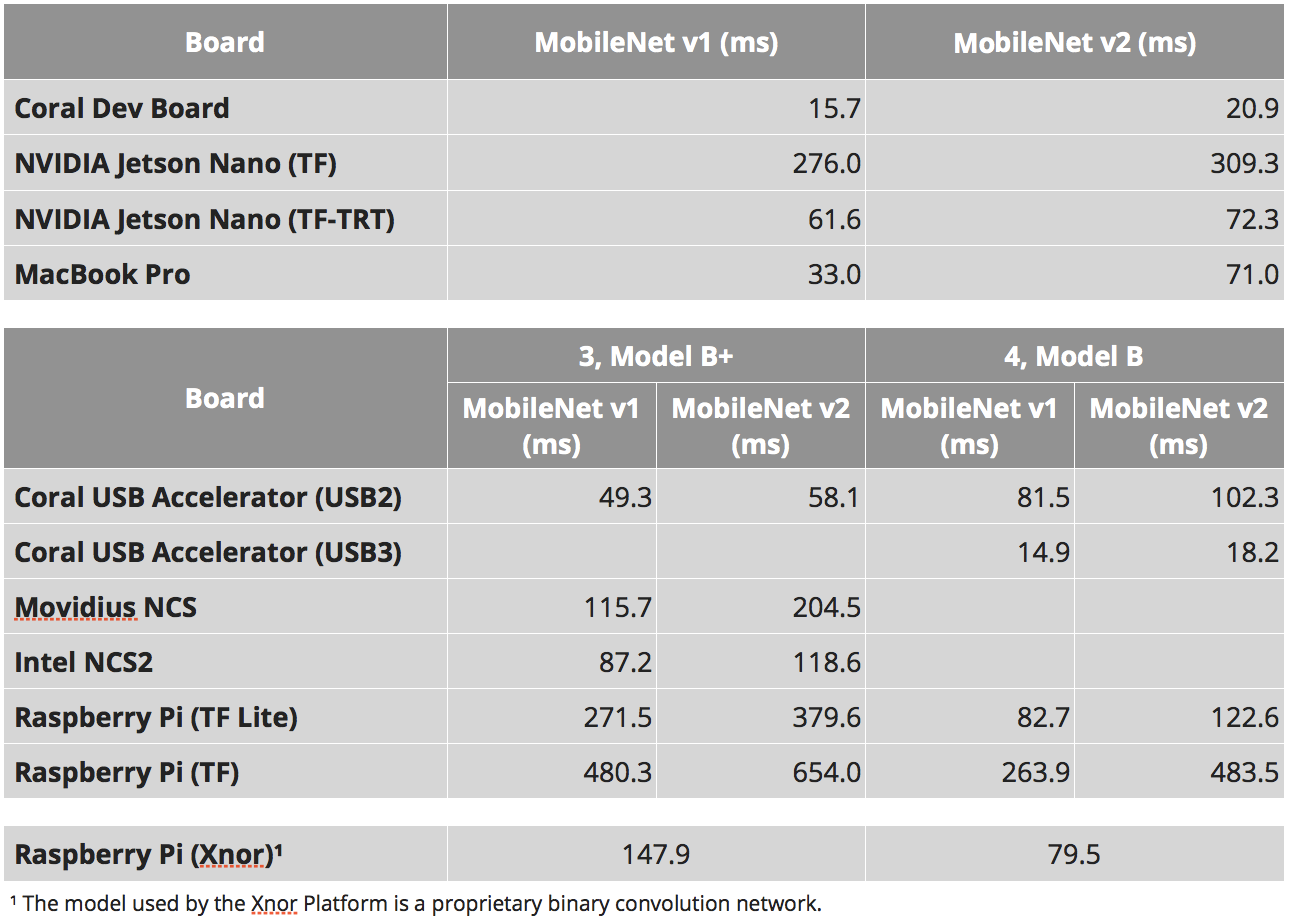
Donde esta la verdad
La verdad es que todos piensan muy diferente:
- SSD consta de dos partes. Una parte es la neurona. La segunda parte es el procesamiento posterior de lo que produce la neurona (supresión no máxima) + el procesamiento previo de lo que se carga en la entrada.
- Como dije antes, bajo Jetson todo debe convertirse a TensorRT. Este es un marco tan nativo de NVIDIA. Sin ella, todo será malo. Solo hay un problema. No todo está portado allí, especialmente desde TensorFlow. A nivel mundial, hay dos enfoques:
- Google, al darse cuenta de que esto es un problema, lanzó para TensorFlow una cosa llamada "tf-trt". De hecho, este es un complemento en tf, que le permite convertir cualquier cuadrícula a tensorrt. Las partes que no son compatibles se infieren en la CPU, el resto en la GPU.
- Reescribe todas las capas / encuentra sus análogos
En los ejemplos anteriores:
- En este enlace, 300 ms de tiempo es el flujo de tensor habitual sin optimización.
- Allí, 72ms es la versión tf-trt. Allí, todos los nms se realizan esencialmente en el proceso.
- Esta es una versión para fanáticos, donde una persona transfirió todos los nms y lo escribió en gpu.
- Y esto ... Este NVIDIA decidió medir todo el rendimiento sin procesamiento posterior, sin mencionarlo explícitamente en ninguna parte.
Debe comprender por sí mismo que si fuera su neurona, que nadie habría convertido antes que usted, entonces, sin problemas, podría lanzarla a una velocidad de 72 ms. Y a una velocidad de 46 ms, sentado sobre los manuales y sorsa día a semana.
En comparación con muchas otras opciones, esto es muy bueno. Pero no olvide que, haga lo que haga, ¡nunca crea los puntos de referencia de NVIDIA!
RaspberryPI 4
¿Producción? ... Y escucho cómo docenas de ingenieros comienzan a reírse de la mención de las palabras "RPI" y "producción" cerca. Pero, debo decir que RPI es aún más estable que Jetson Nano y Google Coral. Pero, por supuesto, TX2 pierde y, aparentemente, la gerifalona.

(La imagen es
de aquí . Me parece que unir a los fanáticos al RPi4 es una diversión popular por separado).
De la lista completa, este es el único dispositivo que no tenía en mis manos / no probé. Pero él inició neuronas en Rpi, Rpi2, Rpi3 (por ejemplo, me lo dijo
aquí ). En general, Rpi4, según tengo entendido, solo difiere en rendimiento. Me parece que los pros y los contras de RPi lo saben todo, pero aún así. Contras:
- Por mucho que no me gustaría, esta no es una solución de supermercado. Sobrecalentamiento Congelaciones periódicas. Pero debido a la gran comunidad, hay cientos de soluciones para cada problema. Esto no hace que Rpi sea bueno para miles de tiradas de impresión. Pero decenas / cientos - notas wai.
- Velocidad. Este es el dispositivo más lento de todos los principales de los que estamos hablando.
- Casi no hay soporte del fabricante. Este producto está dirigido a entusiastas.
Pros:
- Precio No, por supuesto, si crías el tablero tú mismo, entonces usando la gerifalona puedes hacer que sea más barato en miles. Pero lo más probable es que esto no sea realista. Cuando el rendimiento de RPi sea suficiente, será la solución más barata.
- Popularidad. Cuando salió Caffe2, había una versión para Rpi en la versión base. Tensorflow light? Por supuesto que funciona. I.T.D., I.T.P. Lo que el fabricante no hace es transferir usuarios. Corrí con diferentes RPi y Caffe y Tensorflow y PyTorch, y un montón de cosas más raras.
- Conveniencia para pequeñas fiestas / piezas. Simplemente flashee la unidad flash y corra. Hay WiFi a bordo, a diferencia de JetsonNano. Simplemente puede alimentarlo a través de PoE (parece que necesita comprar un adaptador que se vende activamente).
Hablaremos sobre la velocidad de Rpi al final. Dado que el fabricante no postula que su producto para las neuronas, hay pocos puntos de referencia. Todos entienden que Rpi no es perfecto en velocidad. Pero incluso él es adecuado para algunas tareas.
Tuvimos un par de tareas de semiproductos que implementamos en Rpi. La impresión fue agradable.
Movidio 2

A partir de aquí y de abajo, no se utilizarán procesadores completos, sino procesadores diseñados específicamente para redes neuronales. Es como si sus fortalezas y debilidades al mismo tiempo.
Entonces Movidio La compañía fue comprada por Intel en 2016. En el segmento que nos interesa, la compañía lanzó dos productos, Movidius y Movidius 2. El segundo es más rápido, solo hablaremos del segundo.
No, no asi. La conversación no debería comenzar con Movidius, sino con Intel
OpenVino . Yo diría que esto es ideología. Más específicamente, el marco. De hecho, este es un conjunto de neuronas preinformadas e inferencias a ellas, que están optimizadas para productos Intel (procesadores, GPU, computadoras especiales). Integrado con OpenCV, con la Raspberry Pi, con muchos otros silbatos y pedos.
La ventaja de OpenVino es que tiene muchas neuronas. En primer lugar, los detectores más famosos. Neuronas para el reconocimiento de personas, personas, números, letras, poses, etc., etc. (
1 ,
2 ,
3 ). Y están entrenados. No por conjuntos de datos abiertos, sino por conjuntos de datos compilados por el propio Intel. Son mucho más grandes / más diversos y mejor abiertos. Se pueden volver a entrenar de acuerdo con sus casos, luego funcionarán en general bien.
¿Es posible hacerlo mejor? Por supuesto que puedes. Por ejemplo, el reconocimiento de números que hicimos funcionó significativamente mejor. Pero pasamos muchos años desarrollándolo y entendiendo cómo hacerlo perfecto. , .
OpenVino, , . . - — . . GAN . . , , , - , .
, :

, Intel OpenVino . . , . — . 70% OpenVino.
Movidius . . ( , ).
. USB , , !!! USB. . Intel
. - (
1 ,
2 )
. -. - .
?.. :)
, . OpenVino, , , ( Computer Vision ). :
( AI 2.0, OpenVino ).
, . Movidius 2. :
- . Rpi Jetson Nano. — . . Third Party ?
- . . .
- . .
- . USB 3.0
- , . -. . Movidius . .
Pros:
- . . .
- ,
- ,
. — .
, “ 20-30 , , ” — Movidius.
Intel
. , .
 UPD
UPD. . embedded . PCI-e . . — 200 .. . …
Google Coral
Estoy decepcionado No, no hay nada que no pueda predecir. Pero estoy decepcionado de que Google haya decidido lanzar esto. Las pruebas son un milagro al comienzo del verano. Tal vez algo ha cambiado desde entonces, pero describiré mi experiencia de esa época.
Configuración ... Para flashear el Jetson Tk-Tx1-Tx2, tenía que enchufarlo a la computadora host y a la fuente de alimentación. Y eso fue suficiente. Para flashear Jetson Nano y RPi, solo necesita insertar la imagen en la unidad flash USB.
Y para flashear Coral, debe pegar tres cables en el
orden correcto :

¡Y no intentes equivocarte! Por cierto, hay errores / comportamiento indescriptible en la guía. Probablemente no los describiré, ya que desde el comienzo del verano podrían haber arreglado algo. Recuerdo que después de instalar Mendel se perdió cualquier acceso a través de ssh, incluido el descrito por ellos, tuve que editar manualmente algunas configuraciones de Linux.
Me llevó 2-3 horas completar este proceso.
Ok Lanzado ¿Crees que es fácil ejecutar tu grilla en él? Casi nada :)
Aquí hay una lista de lo que puede dejar ir.
Para ser honesto, no llegué a este punto rápidamente. Pasé medio día No realmente No puede descargar el modelo desde
el repositorio TF y ejecutarlo en el dispositivo. O allí es necesario cortar todas las capas. No encontré instrucciones.
Entonces aquí. Es necesario tomar el modelo del repositorio desde arriba. No hay muchos de ellos (se han agregado 3 modelos desde principios de verano). ¿Y cómo entrenarla? Abrir en TensorFlow en una tubería estándar? HAHAHAHAHAHAHAHA. ¡Por supuesto que no!
Tienes un
contenedor Doker especial, y el modelo solo entrenará en él. (Probablemente, también puedes burlarte de tu TF ... Pero hay instrucciones, instrucciones ... que no eran y no parecen ser).
Descargar / Instalar / Lanzar. ¿Qué es ... ¿Por qué la GPU está en cero? ... PORQUE LA FORMACIÓN ESTARÁ EN LA CPU. Docker es solo para él !!! ¿Quieres más diversión? El manual dice "basado en una CPU de 6 núcleos con una estación de trabajo de memoria 64G". Parece que esto es solo un consejo? Tal vez Solo que ahora no tenía suficientes de mis 8 conciertos en ese servidor donde entrenan la mayoría de las modelos. El entrenamiento a la 4ª hora los consumió a todos. Una fuerte sensación de que tenían algo que fluía. Intenté un par de días con diferentes parámetros en diferentes máquinas, el efecto fue uno.
No verifiqué esto dos veces antes de publicar el artículo. Para ser honesto, fue suficiente para mí una vez.
¿Qué más agregar? ¿Que este código no genera un modelo? Para generarlo debes:
- Retraso
- Conviértelo a tflite
- Compilar a Formal Edge TPU. Gracias a Dios ahora esto se hace en una computadora. En la primavera solo se podía hacer en línea. Y allí era necesario marcar "No lo usaré para el mal / No violaré ninguna ley con este modelo". Ahora, gracias a Dios no hay nada de esto.

Este es el mayor asco que he experimentado en relación con un producto de TI en el último año ...
A nivel mundial, Coral debería tener la misma ideología que OpenVino con Movidius. Solo ahora Intel ha estado en este camino durante varios años. Con excelentes manuales, soporte y buenos productos ... Y Google. Bueno, es solo Google ...
Contras:
- Este tablero no es un supermercado en el nivel AD. No he oído hablar de la venta de chips => la producción no es realista
- El nivel de desarrollo es lo más terrible posible. Todo bazhet. La tubería de desarrollo no se ajusta a los esquemas tradicionales.
- El abanico. En el "chip energéticamente óptimo" lo pusieron. Bien, ya no hablaré sobre producción.
- Costo Más caro que TX2.
- No se pueden guardar dos cuadrículas en la memoria al mismo tiempo. Es necesario realizar la carga y descarga. Lo que ralentiza la inferencia de varias redes.
Pros:
- De todo lo que hablamos, Coral es el más rápido.
- Potencialmente, si se saca el chip, entonces es más productivo que Movidius. Y parece que su arquitectura está más justificada para las neuronas.
Gerifalte

El último año y medio ha estado hablando de esta bestia china. Incluso hace un
año, estaba diciendo algo sobre él. Pero hablar es una cosa, y dar información es otra. Hablé con 3-4 grandes empresas, donde los gerentes / directores de proyecto me dijeron lo genial que era este Girfalkon. Pero no tenían ninguna documentación. Y no lo vieron vivo. El
sitio casi no tiene información.
Descargue del sitio al menos algo que solo puedan asociarse (desarrolladores de hardware). Además, la información en el sitio es muy contradictoria. En un lugar escriben que solo admiten
VGG , en otro que solo tienen sus propias neuronas basadas en GNet (que, según
sus garantías, son muy pequeñas y sin pérdida de precisión). En el tercero se escribe que todo se convierte con TF | Caffe | PyTorch, y en el cuarto se escribe sobre el teléfono móvil y otros encantos.
Comprender la verdad es casi imposible. Una vez que estaba cavando y cavando algunos videos en los que al menos algunos números se deslizan:
Si esto es cierto, significa SSD (¿en dispositivos móviles?). Bajo 224 * 224 en el chip GTI2801 tienen ~ 60ms, lo cual es bastante comparable con movidius.
Parece que tienen un chip 2803 mucho más rápido, pero la información es aún menor:
Este verano tenemos una
placa de firefly en nuestras manos (
este módulo está instalado allí para realizar cálculos).
Había una esperanza de que finalmente lo veríamos vivo. Pero no funcionó. El tablero era visible, pero no funcionó. Al rastrear frases individuales en inglés en la documentación china, casi entendieron cuál era el problema (el sistema moleteado inicial no admitía el módulo neural, era necesario reconstruir y volver a rodar todo por nosotros mismos). Pero simplemente no funcionó, y ya había sospechas de que la placa no encajaría en nuestra tarea (2 GB de RAM es muy pequeña para redes neuronales + sistemas. Además, no había soporte para dos redes al mismo tiempo).
Pero logré ver la documentación original. De ella, se entiende muy poco (chino). Para bien, era necesario probar y mirar la fuente.
El soporte técnico de RockChip nos calificó estúpidamente.
A pesar de este horror, tengo claro que aquí, de todos modos, las jambas de RockChip están aquí en primer lugar. Y tengo la esperanza de que, en una placa normal, Gyrfalcon pueda usarse bastante. Pero debido a la falta de información, es difícil para mí decirlo.
Contras:
- Sin ventas abiertas, solo interactuar con empresas
- Poca información, sin comunidad. La información existente es a menudo en chino. Las características de la plataforma no se pueden predecir de antemano
- Lo más probable es que la inferencia no sea más de una red a la vez.
- Solo los fabricantes de hierro pueden interactuar con el autogiro. El resto necesita buscar algunos intermediarios / fabricantes de tableros.
Pros:
- Según tengo entendido, el precio de un chip girfcon es mucho más barato que el resto. Incluso en forma de unidades flash.
- Ya hay dispositivos de terceros con un chip integrado. Por lo tanto, el desarrollo es algo más fácil que movidius.
- Aseguran que hay muchas redes pre-entrenadas, la transferencia de redes es mucho más simple que Movidius | Coral. Pero no garantizaría esto como la verdad. No tuvimos éxito.
En resumen, la conclusión es la siguiente: muy poca información. No puedes solo ponerte en esta plataforma. Y antes de hacer algo al respecto, debe hacer una gran revisión.
Velocidades
Realmente me gusta cómo el 90% de las comparaciones de dispositivos integrados se reducen a la velocidad de las comparaciones. Como has entendido anteriormente, esta característica es muy arbitraria. Para Jetson Nano, puede ejecutar neuronas como flujo de tensor puro, puede usar tensorflow-tensorrt, o puede usar tensorrt puro. Los dispositivos con arquitectura tensorial especial (movidius | coral | gyrfalcone) pueden ser rápidos, pero en primer lugar solo pueden funcionar con arquitecturas estándar. Incluso para Raspberry Pi, no todo es tan simple. Las neuronas de
xnor.ai dan una aceleración una vez y media. Pero no sé cuán honestos son, y qué se ganó al cambiar a int8 u otros chistes.
Al mismo tiempo, otra cosa interesante es ese momento. Cuanto más compleja es la neurona, más complejo es el dispositivo para la inferencia, más impredecible es la aceleración final que se puede extraer. Toma un poco de OpenPose. Hay una red no trivial, postprocesamiento complejo. Tanto esto como aquello se pueden optimizar debido a:
- Migración de posprocesamiento de GPU
- Optimizar el postprocesamiento
- Optimización de la red neuronal para las características de la plataforma, por ejemplo:
- Usar redes optimizadas para plataforma
- Usando módulos de red para la plataforma
- Portar a int8 | int16 | binarización
- Usando calculadoras múltiples (GPU | CPU | etc.). Recuerdo que en Jetson TX1 una vez aceleramos bien cuando transferimos toda la funcionalidad relacionada con la transmisión de video a los aceleradores incorporados para este propósito. Trillado, pero la red se aceleró. Al equilibrar, aparecen muchas combinaciones interesantes
A veces alguien intenta evaluar algo para todas las combinaciones posibles. Pero realmente, como me parece, esto es inútil. Primero debe decidir sobre la plataforma, y solo luego tratar de sacar por completo todo lo que sea posible.
¿Por qué soy todo esto? Además, la prueba de "
cuánto tiempo MobileNet " es una prueba muy mala. Puede decir que la plataforma X es óptima. Pero cuando intenta desplegar su neurona y postprocesar allí, puede sentirse muy decepcionado.
Pero comparar mobilnet'ov aún da información sobre la plataforma. Para tareas simples. Para situaciones en las que comprende que, de todos modos, la tarea es más fácil de reducir a enfoques estándar. Cuando quieres evaluar la velocidad de la calculadora.
La siguiente tabla está tomada de varios lugares:
- Estos estudios son: 1 , 2 , 3
- Para SSD existe el parámetro "número de clases de salida". Y a partir de este parámetro, la tasa de inferencia puede variar mucho. Traté de elegir estudios con el mismo número de clases. Pero este puede no ser el caso en todas partes.
- Nuestra experiencia con TensorRT. Sabía qué tipos funcionan y cuáles no.
- Para el gerifalte, estos videos se basan en el hecho de que mobilnet v2 está allí + una estimación de cuánto cuesta el cambio de área. Este video dice que 2803 puede ser 3-4 veces más rápido. Pero para 2803 no hay clasificaciones SSD. En general, dudo mucho de las velocidades en este punto.
- Traté de elegir el estudio que daba la velocidad máxima real (no tomé la versión de Nvidia sin NMS, por ejemplo)
- Para Jetson TX2 utilicé estas clasificaciones, pero hay 5 clases, en el mismo número de clases que el resto será más lento. De alguna manera descubrí por la experiencia / comparación con Nano en los núcleos lo que debería estar allí
- No tomé en cuenta los chistes con tasa de bits. No sé en qué bitness trabajaron Movidius y Gyrfalcon.
Como resultado, tenemos:

Comparación de plataforma
Intentaré llevar todo lo que dije arriba a una sola mesa. Destaqué en amarillo aquellos lugares donde mi conocimiento no es suficiente para llegar a una conclusión inequívoca. Y, en realidad 1-6, esta es una evaluación comparativa de las plataformas. Cuanto más cerca de 1, mejor.

Sé que el consumo de energía es crítico para muchos. Pero me parece que todo aquí es algo ambiguo, y lo entiendo muy mal, por lo que no entré. Además, la ideología misma parece ser la misma en todas partes.
Paso lateral
De lo que estábamos hablando es solo un pequeño punto en el vasto espacio de variaciones de su sistema. Probablemente las palabras comunes que pueden caracterizar esta área:
- Bajo consumo de energía
- Tamaño pequeño
- Alta potencia informática
Pero, globalmente, si reduce la importancia de uno de los criterios, puede agregar muchos otros dispositivos a la lista. A continuación, analizaré todos los enfoques que he conocido.
Intel
Como dijimos cuando hablamos de Movidius, Intel tiene una plataforma OpenVino. Permite un procesamiento muy eficiente de las neuronas en los procesadores Intel. Además, la plataforma le permite admitir incluso todo tipo de Intel-GPU en un chip. Ahora tengo miedo de decir exactamente qué tipo de rendimiento hay para qué tareas. Pero, según tengo entendido, una buena piedra con una GPU bastante integrada ⅓ ofrece un rendimiento de 1080. Para algunas tareas, incluso puede ser más rápido.

En este caso, el factor de forma, por ejemplo Intel NUC, es bastante compacto. Buen enfriamiento, embalaje, etc. La velocidad será más rápida que la Jetson TX2. Por disponibilidad / facilidad de compra: mucho más fácil. La estabilidad de la plataforma fuera de la caja es mayor.
Dos contras: consumo de energía y precio. El desarrollo es un poco más complicado.
Jetson agx

Este es otro jetson. Esencialmente la versión más antigua. La velocidad es aproximadamente 2 veces más rápida que Jetson TX2, además hay soporte para cálculos int8, lo que le permite overclockear otras 4 veces. Por cierto, mira esta
foto de Nvidia:
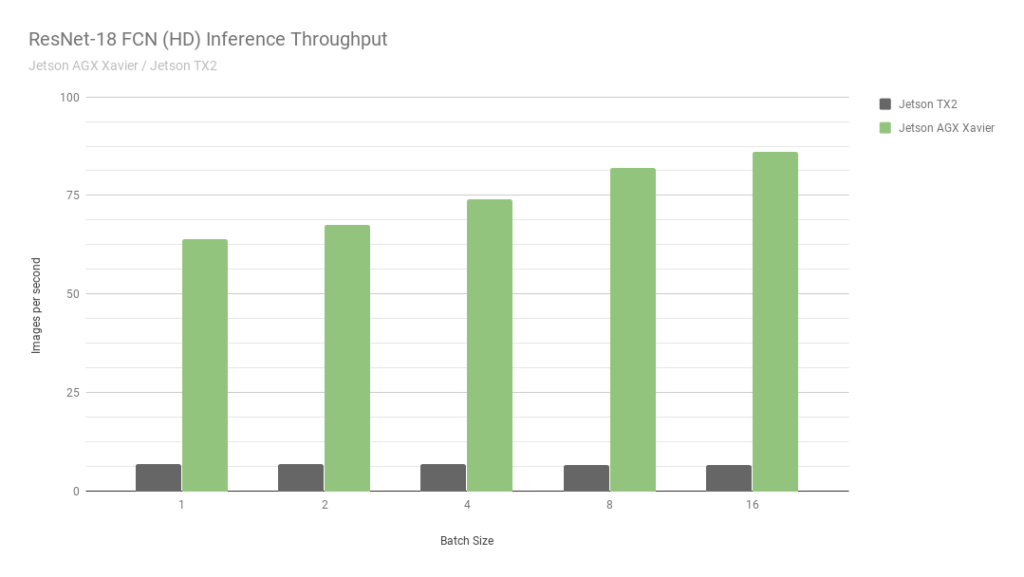
Comparan dos de sus propios Jetson. Uno en int8, el segundo en int32. Ni siquiera sé qué palabras decir aquí ... En resumen: "NUNCA CREER GRÁFICOS NVIDIA".
A pesar de que AGX es bueno, no alcanza las GPU normales de Nvidia en términos de potencia informática. Sin embargo, en términos de eficiencia energética, son muy interesantes. El principal menos el precio.
Nosotros mismos no trabajamos con ellos, por lo que es difícil para mí decir algo más detallado, describir el rango de tareas donde son más óptimas.
Nvidia gpu | versión portátil
Si elimina la restricción estricta sobre el consumo de energía, entonces el Jetson TX2 no se ve óptimo. Como el AGX. Por lo general, las personas tienen miedo de usar la GPU en la producción. Pago por separado, todo eso.
Pero hay millones de empresas que le ofrecen armar una solución personalizada en una placa. Por lo general, estas son placas para computadoras portátiles / minicomputadoras. O, al final, así:

Una de las startups en las que he estado trabajando durante los últimos 2.5 años (
CherryHome ) ha
tomado este mismo camino. Y estamos muy satisfechos.
Menos, como de costumbre, en el consumo de energía, que no fue crítico para nosotros. Bueno, el precio muerde un poco.
Teléfonos móviles
No quiero profundizar en este tema. Para contar todo lo que hay en los teléfonos móviles modernos para neuronas / qué marcos / qué hardware, etc., necesitará más de un artículo con este tamaño. Y teniendo en cuenta el hecho de que empujamos en esta dirección solo 2-3 veces, me considero incompetente para esto. Tan solo un par de observaciones:
- Hay muchos aceleradores de hardware en los que se pueden optimizar las neuronas.
- No hay una solución general que funcione bien en todas partes. Ahora hay algún intento de hacer que Tensorflow Lite sea una solución. Pero, según tengo entendido, aún no se ha convertido en uno.
- Algunos fabricantes tienen sus propios trabajos agrícolas especiales. Ayudamos a optimizar el marco para Snapdragon hace un año. Y fue terrible. La calidad de las neuronas allí es mucho menor que en todo lo que hablé hoy. No hay soporte para el 90% de las capas, incluso las básicas, como "adición".
- Como no hay python, la inferencia de redes es muy extraña, ilógica e inconveniente.
- En términos de rendimiento, sucede que todo está muy bien (por ejemplo, en algunos iphone).
Me parece que para los teléfonos móviles integrados no es la mejor solución (la excepción son algunos sistemas de reconocimiento facial de bajo presupuesto). Pero vi un par de casos cuando se usaron como prototipos iniciales.
Gap8
Estuve recientemente en una conferencia de
Usedata . Y allí uno de los informes fue sobre la inferencia de neuronas en los porcentajes más baratos (GAP8). Y, como dicen, la necesidad de inventos es astuta. En la historia, un ejemplo fue muy descabellado. Pero el autor contó cómo pudieron lograr la inferencia por la cara en aproximadamente un segundo. En una cuadrícula muy simple, esencialmente sin detector. Por optimizaciones locas y largas y ahorros en partidos.
Siempre no me gustan esas tareas. Sin investigación, solo sangre.
Pero, vale la pena reconocer que puedo imaginar acertijos donde los porcentajes de bajo consumo dan un resultado genial. Probablemente no para el reconocimiento facial. Pero en algún lugar donde pueda reconocer la imagen de entrada en 5-10 segundos ...
Grove AI HAT

Mientras preparaba este artículo, me encontré con
esta plataforma integrada. Hay muy poca información al respecto. Según tengo entendido, cero soporte. La productividad también está en cero ... Y ni una sola prueba de velocidad ...
Servidor / Reconocimiento remoto
Cada vez que nos solicitan asesoramiento sobre una plataforma integrada, quiero gritar "¡corre, tontos!". Es necesario evaluar cuidadosamente la necesidad de tal solución. Echa un vistazo a otras opciones. Siempre aconsejo a todos que hagan un prototipo con la arquitectura del servidor. Y durante su funcionamiento, depende de usted decidir si implementará un embebido real. Después de todo, incrustado es:
- Mayor tiempo de desarrollo, a menudo 2-3 veces.
- Soporte sofisticado y depuración en producción. Cualquier desarrollo con ML es una revisión constante, actualización de neuronas, actualizaciones del sistema. Incrustado es aún más difícil. ¿Cómo recargar el firmware? Y si ya tiene acceso a todas las unidades, ¿por qué calcularlas cuando puede calcular en un dispositivo?
- Complejidad del sistema / mayor riesgo. Más puntos de fracaso. Al mismo tiempo, aunque el sistema no funciona como un todo, uno no puede entender: ¿es la plataforma adecuada para esta tarea?
- Aumento de precio. Una cosa es poner una placa simple como nano pi. Y el otro es comprar TX2.
Sí, sé que hay tareas en las que no se pueden tomar decisiones sobre el servidor. Pero, curiosamente, son mucho más pequeños de lo que comúnmente se cree.
Conclusiones
En el artículo, intenté prescindir de conclusiones obvias. Es más bien una historia sobre lo que es ahora. Para sacar conclusiones, es necesario investigar en cada caso. Y no solo plataformas. Pero la tarea en sí. Cualquier tarea puede simplificarse / modificarse / afilarse ligeramente debajo del dispositivo.
El problema con este tema es que el tema está cambiando. Nuevos dispositivos / marcos / enfoques están llegando. Por ejemplo, si NVIDIA activa el soporte int8 para Jetson Nano mañana, la situación cambiará dramáticamente. Cuando escribo este artículo, no puedo estar seguro de que la información no haya cambiado hace dos días. Pero espero que mi breve historia lo ayude a navegar mejor en su próximo proyecto.
Sería genial si tiene información adicional / Me perdí algo / dije algo mal - escriba los detalles aquí.
ps
Incluso cuando terminé de escribir el artículo casi,
snakers4 dejó caer una
publicación reciente de su canal de telegramas Spark en mí, que tiene casi los mismos problemas con Jetson. Pero, como escribí anteriormente, en las condiciones de cualquier consumo de energía, pondría algo como zotacs o IntelNUC. Y como el jetson incrustado no es la peor plataforma.
