Hace aproximadamente un año, mis colegas y yo tuvimos la tarea de resolver el uso del popular sistema de monitoreo de infraestructura de red: Zabbix. Después de estudiar la documentación, inmediatamente procedimos a las pruebas de carga: queríamos evaluar cuántos parámetros puede trabajar Zabbix sin caídas de rendimiento notables. Solo PostgreSQL se usó como DBMS.
Durante las pruebas, se identificaron algunas características arquitectónicas del diseño de la base de datos y el comportamiento del sistema de monitoreo en sí, que por defecto no permiten que el sistema de monitoreo alcance su máxima potencia. Como resultado, se desarrollaron, realizaron y probaron algunas medidas de optimización principalmente en términos de ajuste de la base de datos.
Quiero compartir los resultados del trabajo realizado en este artículo. Este artículo será útil tanto para los administradores de DBA de Zabbix como para PostgreSQL, así como para todos los que quieran comprender y comprender mejor el popular DBMS de PosgreSQL.
Un pequeño spoiler: en una máquina débil con una carga de 200 mil parámetros por minuto, logramos reducir el iowait de la CPU del 20% al 2%, reducir el tiempo de grabación en porciones a las tablas de datos primarios en 250 veces y a las tablas de datos agregados en 32 veces, reducir el tamaño de los índices 5-10 veces y acelerar la recepción de muestras históricas en algunos casos hasta 18 veces.
Prueba de carga
La prueba de carga se realizó de acuerdo con el esquema: un servidor Zabbix, un proxy Zabbix activo, dos agentes. Cada agente se configuró para dar 50 toneladas de número entero y 50 toneladas de parámetros de cadena por minuto (un total de 200 toneladas de parámetros por minuto o 3333 parámetros por segundo). Para generar los parámetros del agente, utilizamos un
complemento para Zabbix. Para verificar cuántos parámetros puede generar un agente, debe usar un
script especial del mismo autor del complemento zabbix_module_stress . El administrador web de Zabbix tiene dificultades para registrar plantillas grandes, por lo que dividimos los parámetros en 20 plantillas con 5 toneladas de parámetros (2500 numéricos y 2500 cadenas).
Plantilla de generador de scripts para pruebas de carga en pythonimport argparse """ . 20 5000 ( 2500 : echo, ; ping, ) """ TEMP_HEAD = """ <?xml version="1.0" encoding="UTF-8"?> <zabbix_export> <version>2.0</version> <date>2015-08-17T23:15:01Z</date> <groups> <group> <name>Templates</name> </group> </groups> <templates> <template> <template>Template Zabbix Srv Stress {count} passive {char}</template> <name>Template Zabbix Srv Stress {count} passive {char}</name> <description/> <groups> <group> <name>Templates</name> </group> </groups> <applications/> <items> """ TEMP_END = """</items> <discovery_rules/> <macros/> <templates/> <screens/> </template> </templates> </zabbix_export> """ TEMP_ITEM = """<item> <name>{k}</name> <type>0</type> <snmp_community/> <multiplier>0</multiplier> <snmp_oid/> <key>{k}</key> <delay>1m</delay> <history>3</history> <trends>365</trends> <status>0</status> <value_type>{t}</value_type> <allowed_hosts/> <units/> <delta>0</delta> <snmpv3_contextname/> <snmpv3_securityname/> <snmpv3_securitylevel>0</snmpv3_securitylevel> <snmpv3_authprotocol>0</snmpv3_authprotocol> <snmpv3_authpassphrase/> <snmpv3_privprotocol>0</snmpv3_privprotocol> <snmpv3_privpassphrase/> <formula>1</formula> <delay_flex/> <params/> <ipmi_sensor/> <data_type>0</data_type> <authtype>0</authtype> <username/> <password/> <publickey/> <privatekey/> <port/> <description/> <inventory_link>0</inventory_link> <applications/> <valuemap/> <logtimefmt/> </item> """ TMP_FNAME_DEFAULT = "Template_App_Zabbix_Server_Stress_{count}_passive_{char}.xml" chars = "ABCDEFGHIJKLMNOPQRSTUVWXYZ" if __name__ == "__main__": parser = argparse.ArgumentParser( description=' zabbix') parser.add_argument('--items', dest='items', type=int, default=1000, help='- (default: 1000)') parser.add_argument('--templates', dest='templates', type=int, default=1, help=f'- [1-{len(chars)}] (default: 1)') args = parser.parse_args() items_count = args.items tmps_count = args.templates if not (tmps_count >= 1 and tmps_count <= len(chars)): sys.exit(f"Templates must be in range 1 - {len(chars)}") for i in range(tmps_count): fname = TMP_FNAME_DEFAULT.format(count=items_count, char=chars[i]) with open(fname, "w") as output: output.write(TEMP_HEAD.format(count=items_count, char=chars[i])) for k,t in [('stress.ping[{}-I-{:06d}]',3), ('stress.echo[{}-S-{:06d}]',4)]: for j in range(int(items_count/2)): output.write(TEMP_ITEM.format(k=k.format(chars[i],j),t=t)) output.write(TEMP_END)
La métrica del iostat de la CPU es un buen indicador del rendimiento de Zabbix: refleja la fracción de la unidad de tiempo durante la cual el procesador espera el acceso al disco. Cuanto más alto es, más se ocupa el disco con las operaciones de lectura y escritura, lo que afecta indirectamente la degradación del rendimiento del sistema de monitoreo en su conjunto. Es decir Esta es una señal segura de que algo está mal con el monitoreo. Por cierto, en los espacios abiertos de la red, la pregunta más popular es "cómo quitar el activador de iostat en Zabbix", por lo que este es un punto doloroso, porque hay muchas razones para aumentar el valor de la métrica iowait.
Aquí está la imagen de la métrica de CPU Iowait que obtuvimos tres días después inicialmente:
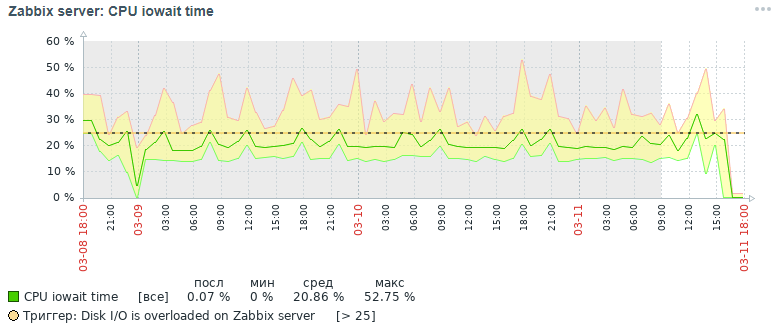
Pero, ¿qué imagen para la misma métrica también obtuvimos dentro de tres días al final después de todas las medidas de optimización que se han hecho, que se discutirán a continuación:
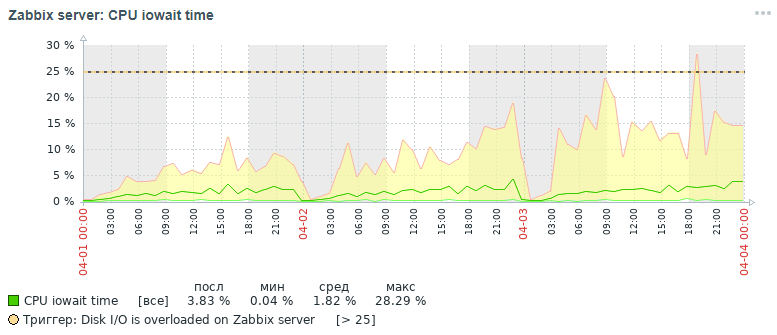
Como se puede ver en los gráficos, el indicador de CPU Iowait cayó de casi 20% a 2%, lo que aceleró indirectamente el tiempo de ejecución de todas las solicitudes para agregar y leer datos. Ahora veamos por qué, con la configuración estándar de la base de datos, el rendimiento general del sistema de monitoreo disminuye y cómo solucionarlo.
Razones para la caída de rendimiento de Zabbix
Con la acumulación de más de 10 millones de valores de parámetros en cada tabla de datos primarios, se notó que el rendimiento del sistema de monitoreo cae bruscamente, debido a las siguientes razones:
- la métrica iowait para la CPU del servidor se incrementa en más del 20%, lo que indica un aumento en el tiempo durante el cual la CPU espera acceder a las operaciones de lectura y escritura del disco
- índices de tablas en los que los datos de monitoreo están muy inflados
- la métrica de utilización aumenta al 100% para un disco con datos de monitoreo, lo que indica la carga completa del disco con operaciones de lectura y escritura
- los valores obsoletos no tienen tiempo para eliminarse de las tablas del historial cuando se limpia de acuerdo con el cronograma del ama de llaves
La situación se agrava al comienzo de cada hora, cuando además de esto, se calculan estadísticas agregadas por hora, mientras se leen y escriben activamente páginas de índice del disco, se eliminan datos obsoletos del historial, lo que conduce al mismo resultado: una caída en el rendimiento de la base de datos y un aumento en el tiempo de ejecución solicitudes (en el límite, se observó una solicitud que duró hasta 5 minutos).
Un poco de ayuda para organizar un almacén de datos de monitoreo en Zabbix. Almacena datos primarios y datos agregados en diferentes tablas, además, con la separación de los tipos de parámetros. Cada tabla almacena un campo itemid (una referencia implícita a un elemento de datos registrado en el sistema), una marca de tiempo para registrar el valor del reloj en formato de marca de tiempo unix (milisegundos en una columna separada) y un valor en una columna separada (la excepción es la tabla de registro, tiene más campos, similar al registro de eventos ):
Actividades de optimización
Para mejorar el rendimiento de la base de datos PostgreSQL, se llevaron a cabo varias medidas de optimización, la principal de las cuales es la partición y el cambio de índices. Sin embargo, vale la pena mencionar algunas palabras sobre algunas medidas importantes y útiles que pueden acelerar el trabajo de cualquier base de datos bajo el sistema de administración de bases de datos PostgreSQL.
Nota importante. En el momento de recopilar el material del artículo, utilizamos Zabbix versión 4.0, aunque la versión 4.2 ya se ha lanzado y la versión 4.4 se está preparando para su lanzamiento. ¿Por qué es importante mencionar esto? Debido a que a partir de la versión 4.2, Zabbix comenzó a admitir una extensión poderosa especial para trabajar con series temporales de TimescaleDB, pero hasta ahora en modo experimental: por todas las ventajas de usar esta extensión, se cree que algunas solicitudes comenzaron a funcionar más lentamente y todavía hay problemas de rendimiento sin resolver ( resuelto en la versión 4.4) -
lea este artículo .
En el próximo artículo, planeo escribir sobre los resultados de las pruebas de carga que ya usan la extensión TimescaleDB en comparación con este caso de solución. La versión PostgreSQL se usó 10, pero toda la información dada es relevante para las versiones 11 y 12 (¡estamos esperando!).
Por lo tanto, lo primero es lo primero:
- configurar un archivo de configuración usando la utilidad pgtune
- poner la base de datos en un disco físico separado
- particionando tablas de historial con pg_pathman
- cambio de tipos de índice de tablas de historial a brin (reloj) y btree-gin (itemid)
- recopilación y análisis de estadísticas de ejecución de consultas pg_stat_statements
- establecer parámetros de monitoreo de disco físico
- mejora del rendimiento del hardware
- creación de un clúster distribuido (material más allá del alcance de este artículo)
Configurar un archivo de configuración usando la utilidad pgtune
De hecho, PostgreSQL es un DBMS bastante ligero. Su archivo de configuración predeterminado está configurado para que, como dice mi colega, "incluso trabaje en la máquina de café", es decir en un hierro muy modesto Por lo tanto, es necesario configurar PostgreSQL para la configuración del servidor, teniendo en cuenta la cantidad de memoria, la cantidad de procesadores, el tipo de uso previsto de la base de datos, el tipo de disco (HDD o SSD) y la cantidad de conexiones.
Por desgracia, no existe una fórmula única para ajustar todos los DBMS, pero hay ciertas reglas y patrones que son adecuados para la mayoría de las configuraciones (un ajuste más fino ya es el trabajo de un experto). Para simplificar la vida de DBA, se
escribió la utilidad
pgtune , que fue complementada por la
versión web de
le0pard , autor de un libro interesante y útil sobre la administración de PostgreSQL.
Un ejemplo de ejecución de la utilidad en la consola con 100 conexiones (Zabbix tiene un administrador web exigente) para el tipo de aplicación "Almacenes de datos":
pgtune -i postgresql.conf -o new_postgresql.conf -T DW -c 100
Los parámetros de configuración que la utilidad pgtune cambia con una descripción del propósito (los valores se dan como ejemplo) # Versión DB: 11
# Tipo de sistema operativo: linux
# Tipo de base de datos: web
# Memoria total (RAM): 8 GB
# Número de CPU: 1
# Conexiones num .: 100
# Almacenamiento de datos: disco duro
max_connections = 100 # número máximo de conexiones de bases de datos concurrentes
shared_buffers = 2GB # tamaño de memoria para varios buffers (principalmente caché de bloques de tabla y bloques de índice) en memoria compartida
eficaz_caché_tamaño = 6 GB # tamaño máximo de memoria requerida para la ejecución de consultas mediante índices
maintenance_work_mem = 512MB # afecta la velocidad de las operaciones VACÍO, ANALIZAR, CREAR ÍNDICE
checkpoint_completion_target = 0.7 # tiempo objetivo para completar el procedimiento de punto de control
wal_buffers = 16MB # cantidad de memoria utilizada por la memoria compartida para mantener registros de transacciones
default_statistics_target = 100 # cantidad de estadísticas recopiladas por el comando ANALYZE: al aumentar, el optimizador crea consultas más lentamente, pero mejor
random_page_cost = 4 # costo condicional del acceso al índice a páginas de datos - afecta la decisión de usar el índice
efectivos_io_concurrencia = 2 # número de operaciones de E / S asíncronas que el DBMS intentará realizar en una sesión separada
work_mem = 10485kB # la cantidad de memoria utilizada para ordenar y tablas hash antes de usar archivos temporales en el disco
min_wal_size = 1GB # límites por debajo del número de archivos WAL que se reciclarán para uso futuro
max_wal_size = 2GB # limita la cantidad de archivos WAL que se reciclarán para uso futuro
Algunas opciones útiles de configuración postgresql # gestión de manejadores de solicitudes concurrentes
max_worker_processes = 8 # el número máximo de procesos en segundo plano, al menos uno por base de datos
max_parallel_workers_per_gather = 4 # número máximo de procesos paralelos dentro de una sola solicitud
max_parallel_workers = 8 # el número máximo de procesos de trabajo que el sistema puede soportar para operaciones paralelas
# configuración de registro (una manera fácil de conocer el tiempo de ejecución de las solicitudes sin usar la extensión pg_stat_statements)
log_min_duration_statement = 3000 # escribe en los registros la duración de la ejecución de todos los comandos cuyo tiempo de operación> = del valor especificado en ms
log_duration = off # registra la duración de cada comando completado
log_statement = 'none' # qué comandos SQL escribir en el registro, valores: none (deshabilitado), ddl, mod y all (todos los comandos)
debug_print_plan = off # salida del árbol del plan de consulta para su posterior análisis
# exprima el máximo de la base de datos y esté listo para obtenerlo ante cualquier falla (para los más reprimidos, que ignoran la existencia de SSD y un clúster distribuido)
#fsync = off # escritura física en el disco de cambios, deshabilitar fsync proporciona una ganancia de velocidad, pero puede provocar fallas permanentes
#synchronous_commit = off # le permite responder al cliente incluso antes de que la información de la transacción esté en el WAL, una alternativa casi segura para deshabilitar fsync
#full_page_writes = off # shutdown acelera las operaciones normales, pero puede provocar corrupción o corrupción de datos si el sistema falla
Listado de una base de datos en un disco físico separado
Este elemento es opcional y, más bien, es una solución de transición para un clúster distribuido completo, pero será útil saber acerca de esta posibilidad. Para acelerar la base de datos, puede ponerla en un disco separado. Montamos todo el disco en el directorio base, donde se almacenan todas las bases de datos PostgreSQL, pero en general se puede hacer de manera diferente: crear una nueva base de tabla y transferir la base de datos (o incluso solo una parte de ella, las tablas de datos de monitoreo primario y agregado) a esta base de tabla en un disco separado.
Ejemplo de montajePrimero debe formatear el disco con el sistema de archivos ext4 y conectarlo al servidor. Monte el disco para la base de datos con la etiqueta noatime:
mount / dev / sdc1 / var / lib / pgsql / 10 / data / base -o noatime
Para el montaje permanente, agregue la línea al archivo / etc / fstab:
# donde UUID es el identificador del disco, puede verlo usando la utilidad blkid
UUID = 121efe29-70bf-410b-bc71-90704568ce3b / var / lib / pgsql / 10 / data / base ext4 por defecto, noatime 0 0
Particionar tablas de historial con pg_pathman
Uno de los problemas que encontramos durante las pruebas de resistencia de Zabbix: PostgreSQL no logra eliminar datos obsoletos de la base de datos. Usando la partición, puede dividir la tabla en sus partes constituyentes, reduciendo así el tamaño de los índices y las partes constituyentes de la supertabla, lo que afecta positivamente la velocidad de la base de datos en su conjunto.
La partición resuelve dos problemas a la vez:
1. acelerar la eliminación de datos obsoletos eliminando tablas enteras
2. división de índices para cada tabla compuesta
Hay cuatro mecanismos para particionar en PostgreSQL:
1. restricción estándar_exclusión
2. extensión pg_partman (
no confunda con pg_pathman )
3. extensión
pg_pathman4. crear y mantener particiones manualmente por nosotros mismos
La solución de particionamiento más conveniente, confiable y optimizada, en nuestra opinión, es la extensión
pg_pathman . Con este método de partición, el planificador de consultas determina de manera flexible en qué particiones buscar datos.
Se rumorea que en la versión 12 de PostgreSQL habrá una excelente partición ya lista para usar.Por lo tanto, comenzamos a escribir datos de monitoreo para cada día en una tabla heredada separada de la supertable y la eliminación de valores de parámetros obsoletos comenzó a ocurrir mediante la eliminación de todas las tablas obsoletas a la vez, lo que es mucho más fácil para un DBMS por los costos laborales. La eliminación se realizó llamando a la función de usuario de la base de datos como un parámetro de monitoreo del servidor Zabbix a las 2 a.m. con una indicación del rango aceptable de almacenamiento de estadísticas.
Instalar y configurar particiones para PostgreSQL 10Instale y configure la extensión
pg_pathman desde el repositorio estándar del sistema operativo (para obtener instrucciones sobre
cómo construir la última versión de la extensión desde las fuentes, busque en el mismo repositorio en github):
yum install pg_pathman10
nano /var/pgsqldb/postgresql.conf
shared_preload_libraries = 'pg_pathman' # importante: aquí escriba pg_pathman último en la lista
Reiniciamos el DBMS, creamos una extensión para la base de datos y configuramos la partición (1 día para los datos de monitoreo primarios y 3 días para los datos de monitoreo agregados; podría hacerse durante 1 día):
systemctl restart postgresql-10.service
psql -d zabbix -U postgres
CREAR EXTENSIÓN pg_pathman;
# configurar un día para las tablas de datos de monitoreo primario
# 1552424400 - cuenta regresiva como marca de tiempo Unix, 86400 - segundos en días
seleccione create_range_partitions ('historial', 'reloj', 1552424400, 86400);
seleccione create_range_partitions ('history_uint', 'clock', 1552424400, 86400);
seleccione create_range_partitions ('history_text', 'clock', 1552424400, 86400);
seleccione create_range_partitions ('history_str', 'clock', 1552424400, 86400);
seleccione create_range_partitions ('history_log', 'clock', 1552424400, 86400);
# configurar durante tres días para tablas de datos de monitoreo agregados
# 1552424400 - cuenta regresiva como marca de tiempo Unix, 259200 - segundos en tres días
seleccione create_range_partitions ('tendencias', 'reloj', 1545771600, 259200);
seleccione create_range_partitions ('trends_uint', 'clock', 1545771600, 259200);
Si todavía no hay datos en ninguna de las tablas, al llamar a la función create_range_partitions, se debe pasar un argumento adicional p_count = 0_.Consultas útiles para monitorear y administrar particiones:
# lista general de tablas particionadas, almacenamiento de configuración principal:
seleccione * de pathman_config;
# representación con todas las secciones existentes, así como sus padres y límites de rango:
seleccione * de pathman_partition_list;
# parámetros adicionales que anulan el comportamiento estándar de pg_pathman:
seleccione * de pathman_config_params;
# copie el contenido nuevamente en la tabla principal y elimine las particiones:
seleccione drop_partitions ('nombre_tabla' :: regclass, falso);
Script útil para ver estadísticas sobre el número y el tamaño de las particiones:
SELECT nspname AS schemaname, relname, relkind, cast (reltuples as int), pg_size_pretty(pg_relation_size(C.oid)) AS "size" FROM pg_class C LEFT JOIN pg_namespace N ON (N.oid = C.relnamespace) WHERE nspname NOT IN ('pg_catalog', 'information_schema') and (relname like 'history%' or relname like 'trends%') and relkind = 'r'
Autoajuste para eliminar particiones obsoletas (ahtung - una gran función SQL)Para configurar la eliminación automática de particiones, debe crear una función en la base de datos
(texto ancho, así que tuve que eliminar el resaltado de sintaxis):
CREAR O REEMPLAZAR LA FUNCIÓN public.delete_old_partitions (history_days integer, trends_days integer, str_days integer)
Texto de DEVOLUCIONES
IDIOMA plpgsql
AS $ función $
/ *
La función elimina todas las particiones anteriores al número de días especificado:
history_days: para particiones history_x, history_uint_x
trends_days - para particiones trends_x, trends_uint_x
str_days: para particiones history_str_x, history_text_x, history_log_x
* /
declarar clock_today_start int;
declarar clock_delete_less_history int = 0;
declarar clock_delete_less_trends int = 0;
declarar clock_delete_less_strings int = 0;
clock_delete_less int = 0;
declarar iterador int = 0;
declare result_str text = '';
declarar texto buf_table_size;
declarar texto buf_table_len;
declarar texto de nombre de partición;
declarar texto clock_max;
declarar err_detail text;
declarar t_start timestamp = clock_timestamp ();
declarar t_end marca de tiempo;
comenzar
si $ 1 <= 0, entonces devuelve 'ups, algo mal: el argumento history_days debe ser un valor entero positivo'; terminar si;
si $ 2 <= 0, entonces devuelve 'ups, algo mal: el argumento trends_days debe ser un valor entero positivo'; terminar si;
si $ 3 <= 0, entonces devuelve 'ups, algo mal: el argumento str_days debe ser un valor entero positivo'; terminar si;
clock_today_start = extract (epoch from date_trunc ('day', now ())) :: int;
clock_delete_less_history = extract (época de date_trunc ('día', ahora ()) - ($ 1 :: texto || 'días') :: intervalo) :: int;
clock_delete_less_trends = extract (época de date_trunc ('día', ahora ()) - ($ 2 :: texto || 'días') :: intervalo) :: int;
clock_delete_less_strings = extract (época de date_trunc ('día', ahora ()) - ($ 3 :: texto || 'días') :: intervalo) :: int;
clock_delete_less = least (clock_delete_less_history, clock_delete_less_trends, clock_delete_less_strings);
- aviso de subida 'clock_today_start% (%)', to_timestamp (clock_today_start), clock_today_start;
--seguir aviso 'clock_delete_less_history% (%)% days', to_timestamp (clock_delete_less_history), clock_delete_less_history, $ 1;
- aviso de subida 'clock_delete_less_trends% (%)% days', to_timestamp (clock_delete_less_trends), clock_delete_less_trends, $ 2;
- elevar el aviso 'clock_delete_less_strings% (%)% days', to_timestamp (clock_delete_less_strings), clock_delete_less_strings, $ 3;
para nombre_partición, clock_max en la partición seleccionada, range_max de pathman_partition_list donde
range_max :: int <= greatest (clock_delete_less_history, clock_delete_less_trends, clock_delete_less_strings) y
(partición :: texto como 'historial%' o partición :: texto como 'tendencias%') ordenar por partición asc
bucle
if (nombre_partición ~ 'history_uint_ \ d' y clock_max :: int <= clock_delete_less_history)
o (nombre_partición ~ 'history_ \ d' y clock_max :: int <= clock_delete_less_history)
o (nombre_partición ~ 'trends_ \ d' y clock_max :: int <= clock_delete_less_trends)
o (nombre_partición ~ 'history_log_ \ d' y clock_max :: int <= clock_delete_less_strings)
o (nombre_de_partición ~ 'history_str_ \ d' y clock_max :: int <= clock_delete_less_strings)
o (nombre_partición ~ 'history_text_ \ d' y clock_max :: int <= clock_delete_less_strings)
entonces
iterador = iterador + 1;
elevar el aviso '%', formato ('!!! eliminar% s% s', nombre_partición, reloj_max);
seleccione max (reltuples :: int), pg_size_pretty (sum (pg_relation_size (pg_class.oid)))) como "tamaño" de pg_class donde renombre como partición_nombre || '%' en estricto buf_table_len, buf_table_size;
if result_str! = '' entonces result_str = result_str || ','; terminar si;
result_str = result_str || formato ('% s (dt <% s, len% s,% s)', nombre_partición, to_char (to_timestamp (clock_max :: int), 'YYYY-MM-DD'), buf_table_len, buf_table_size);
ejecutar formato ('eliminar tabla si existe% s', nombre_partición);
terminar si;
bucle final
if iterator = 0 then result_str = format ('no hay particiones para eliminar anteriores, entonces% s date', to_char (to_timestamp (clock_delete_less), 'YYYY-MM-DD'));
de lo contrario result_str = format ('particiones% s eliminadas en% s segundos:', iterador, trunc (extract (segundos de (clock_timestamp () - t_start)) :: numeric, 3)) || result_str;
terminar si;
--avisar aviso '%', result_str;
return result_str;
excepción cuando otros entonces
obtener diagnósticos apilados err_detail = PG_EXCEPTION_CONTEXT;
formato de retorno ('ups, algo mal:% s [código de error% s],% s', sqlerrm, sqlstate, err_detail);
fin
$ función $;
Para llamar automáticamente a la función de partición de limpieza automática, debe crear un elemento de datos para el host del servidor zabbix del tipo "Monitor de base de datos" con la siguiente configuración:
- tipo: monitor de base de datos
- nombre: delete_old_history_partitions
- clave: db.odbc.select [delete_old_history_partitions, zabbix]
- expresión sql: seleccione delete_old_partitions (3, 30, 30);
# aquí, los parámetros de la llamada a la función delete_old_partitions indican el tiempo de almacenamiento en días
# para valores numéricos, valores numéricos agregados y valores de cadena
- tipo de datos: texto
- intervalo de actualización: 0
- intervalo de usuario: programado en h2
- período de almacenamiento del historial: 90 días
- grupo de elementos de datos: base de datos
Como resultado, obtendremos estadísticas sobre la limpieza de particiones de aproximadamente este tipo:
2019-09-16 02:00:00, borrado 3 particiones en 0.024 segundos: trends_78 (dt <2019-08-17, len 1, 48 kB), history_193 (dt <2019-09-13, len 85343, 9448 kB ), history_uint_186 (dt <2019-09-13, len 27969, 3480 kB)
Importante! Después de configurar la eliminación automática de particiones a través del elemento de datos y la función del usuario, debe desactivar el historial y la limpieza de tendencias en el programador de tareas de ama de llaves Zabbix: a
través del elemento del menú zabbix, seleccione "Administración" -> "General" -> seleccione "Borrar historial" de la lista en la esquina -> deshabilitar todas las casillas de verificación en las secciones "Historial" y "Dinámica de los cambios". Cambiar los tipos de índice de las tablas de historial a brin (clock) y btree-gin (itemid)
Un agradecimiento especial a
erogov por la
excelente serie de artículos de resumen sobre los índices PostgreSQL .
Y de hecho todo el equipo de PostgresPRO. .
, btree(itemid, clock) — , , «» , — 10 .
, , .Durante la prueba de varios índices, se reveló la combinación más exitosa de índices: el índice brin en el campo del reloj y el índice btree-gin en el campo itemid para todas las tablas de datos de monitoreo.El índice brin es ideal para datos que aumentan monotónicamente, como la marca de tiempo del hecho de un evento, es decir para series de tiempo. Y el índice btree-gin es esencialmente un índice gin sobre los tipos de datos estándar, que generalmente es mucho más rápido que el índice btree clásico porque El índice de ginebra no se reconstruye durante la adición de nuevos valores, sino que solo se complementa con ellos. El índice btree-gin se coloca como una extensión de PostgreSQL.A continuación se ofrece una comparación de la velocidad de muestreo para esta estrategia de indexación y para los índices en la base de datos Zabbix de manera predeterminada. Durante las pruebas de carga, acumulamos datos durante tres días para tres particiones:Para evaluar los resultados, se realizaron tres tipos de consultas:- para un parámetro específico itemid, datos del último mes, de hecho, los últimos tres días (total 1660 registros)
explicar analizar select * from history_uint donde itemid = 313300
y reloj> = extracto (época de '2019-03-09 00:00:00' :: marca de tiempo) :: int
y clock <= extract (época de '2019-04-09 12:00:00' :: marca de tiempo) :: int;
- para datos de un parámetro específico durante 12 horas de un día (649 entradas en total)
explicar analizar seleccionar * del historial_texto donde itemid = 310650
y reloj> = extracto (época de '2019-04-09 00:00:00' :: marca de tiempo) :: int
y clock <= extract (época de '2019-04-09 12:00:00' :: marca de tiempo) :: int;
- para datos de un parámetro específico durante una hora (61 registros en total):
explicar analizar seleccionar recuento (*) de history_text donde itemid = 336540
y reloj> = extracto (época de '2019-04-08 11:00:00' :: marca de tiempo) :: int
y clock <= extract (época de '2019-04-08 12:00:00' :: marca de tiempo) :: int;
Los resultados de la prueba se tabularon a continuación:* el tamaño en MB se indica en total para tres particiones** solicitud de tipo 1 - datos durante 3 días, solicitud de tipo 2 - datos durante 12 horas, solicitud de tipo 3 - datos durante una horaEn la tabla de comparación se puede ver que para tablas de datos grandes con el número de registros más de 100 millones muestran claramente que cambiar el índice compuesto estándar btree a dos índices brin y btree-gin tiene un efecto beneficioso para reducir el tamaño de los índices y acelerar el tiempo de ejecución de consultas.La eficiencia de la indexación y la partición se muestra a continuación en el ejemplo de una solicitud para agregar nuevos registros a las tablas history_uint y trends_uint (las adiciones ocurren en promedio 2000 valores por consulta).Resumiendo los resultados de las pruebas de varias configuraciones de índices para las tablas de datos de monitoreo del sistema zabbix, podemos decir que un cambio similar en el índice estándar para las tablas de datos de monitoreo zabbix afecta positivamente el rendimiento general del sistema, lo que se siente más cuando se acumulan volúmenes de datos de más de 10 millones. debe olvidarse del efecto indirecto de la "hinchazón" del índice btree estándar de forma predeterminada: las reconstrucciones frecuentes del índice de varios gigabytes provocan una gran carga del disco duro (métrica de uso ación), que en última instancia aumenta el tiempo de las operaciones del disco y el tiempo de espera para acceder al disco desde la CPU (métrica iowait).Pero para que el índice btree-gin pueda funcionar con el tipo de datos bigint (in8), que es la columna itemid, debe registrar una familia de operadores bigint para el índice btree-gin.Registrar una familia de operadores bigint para el índice btree-gin/*
gin biginteger integer .
- gin int2, int4, int8,
bigint , bigint (<= 2147483647)
intger_ops, :
create index on tablename using gin(columnname int8_family_ops) with (fastupdate = false);
*/
-- btree_gin
CREATE EXTENSION btree_gin;
CREATE OPERATOR FAMILY integer_ops using gin;
CREATE OPERATOR CLASS int4_family_ops
FOR TYPE int4 USING gin FAMILY integer_ops
AS
OPERATOR 1 <,
OPERATOR 2 <=,
OPERATOR 3 =,
OPERATOR 4 >=,
OPERATOR 5 >,
FUNCTION 1 btint4cmp(int4,int4),
FUNCTION 2 gin_extract_value_int4(int4, internal),
FUNCTION 3 gin_extract_query_int4(int4, internal, int2, internal, internal),
FUNCTION 4 gin_btree_consistent(internal, int2, anyelement, int4, internal, internal),
FUNCTION 5 gin_compare_prefix_int4(int4,int4,int2, internal),
STORAGE int4;
CREATE OPERATOR CLASS int8_family_ops
FOR TYPE int8 USING gin FAMILY integer_ops
AS
OPERATOR 1 <,
OPERATOR 2 <=,
OPERATOR 3 =,
OPERATOR 4 >=,
OPERATOR 5 >,
FUNCTION 1 btint8cmp(int8,int8),
FUNCTION 2 gin_extract_value_int8(int8, internal),
FUNCTION 3 gin_extract_query_int8(int8, internal, int2, internal, internal),
FUNCTION 4 gin_btree_consistent(internal, int2, anyelement, int4, internal, internal),
FUNCTION 5 gin_compare_prefix_int8(int8,int8,int2, internal),
STORAGE int8;
ALTER OPERATOR FAMILY integer_ops USING gin add
OPERATOR 1 <(int4,int8),
OPERATOR 2 <=(int4,int8),
OPERATOR 3 =(int4,int8),
OPERATOR 4 >=(int4,int8),
OPERATOR 5 >(int4,int8);
ALTER OPERATOR FAMILY integer_ops USING gin add
OPERATOR 1 <(int8,int4),
OPERATOR 2 <=(int8,int4),
OPERATOR 3 =(int8,int4),
OPERATOR 4 >=(int8,int4),
OPERATOR 5 >(int8,int4);
Este script redistribuye todos los índices en la base de datos PostgreSQL para Zabbix desde la configuración predeterminada a la configuración óptima descrita anteriormente./*
*/
--
drop index history_1;
drop index history_uint_1;
drop index history_str_1;
drop index history_text_1;
drop index history_log_1;
-- PK
-- ( , )
alter table trends drop constraint trends_pk;
alter table trends_uint drop constraint trends_uint_pk;
-- bree-gin itemid
-- btree-gin bigint
-- https://habr.com/ru/company/postgrespro/blog/340978/#comment_10545932
-- create extension btree_gin;
create index on history using gin(itemid int8_family_ops) with (fastupdate = false);
create index on history_uint using gin(itemid int8_family_ops) with (fastupdate = false);
create index on history_str using gin(itemid int8_family_ops) with (fastupdate = false);
create index on history_text using gin(itemid int8_family_ops) with (fastupdate = false);
create index on history_log using gin(itemid int8_family_ops) with (fastupdate = false);
create index on trends using gin(itemid int8_family_ops) with (fastupdate = false);
create index on trends_uint using gin(itemid int8_family_ops) with (fastupdate = false);
-- bree-gin itemid
-- brin 128 ,
-- ,
-- https://habr.com/ru/company/postgrespro/blog/346460/
create index on history using brin(clock) with (pages_per_range = 128);
create index on history_uint using brin(clock) with (pages_per_range = 128);
create index on history_str using brin(clock) with (pages_per_range = 128);
create index on history_text using brin(clock) with (pages_per_range = 128);
create index on history_log using brin(clock) with (pages_per_range = 128);
create index on trends using brin(clock) with (pages_per_range = 128);
create index on trends_uint using brin(clock) with (pages_per_range = 128);
Para el índice de brin para nuestro volumen de datos a una intensidad de 100 toneladas de parámetros por minuto (100 toneladas en el historial y 100 toneladas en el historial), se notó que el índice funciona en las tablas de datos de monitoreo primario con un tamaño de zona de 512 páginas dos veces más rápido que con el tamaño estándar de 128 páginas, pero esto es individual y depende del tamaño de las tablas y la configuración del servidor. En cualquier caso, el índice brin ocupa muy poco espacio, pero su velocidad puede aumentarse ligeramente ajustando el tamaño de la zona, pero siempre que la velocidad de flujo de datos no cambie mucho.Como resultado, vale la pena señalar que hay una limitación asociada con la arquitectura de Zabbix: en la pestaña "Datos recientes", los últimos dos valores para cada parámetro se recopilan teniendo en cuenta el filtrado. Para cada parámetro, los valores se solicitan en la base de datos por separado. Por lo tanto, cuanto más parámetros se seleccionen, más tiempo se ejecutará la consulta. Se buscan los datos más recientes cuando el índice btree (itemid, clock desc) se establece en las tablas de historial con una ordenación inversa por tiempo, pero el índice en sí mismo "se hincha" en el disco y generalmente disminuye la base de datos indirectamente, lo que causa un problema, descrito anteriormente.Por lo tanto, hay tres salidas:- « » 100 (.. , « » )
- Zabbix , , « »
- deje los índices como están por defecto y limítese a particionar solo para obtener selecciones bastante grandes en la pestaña Datos recientes al mismo tiempo para una variedad de parámetros (sin embargo, se notó que el servidor web Zabbix todavía tiene un límite en la cantidad de valores de parámetros mostrados simultáneamente en la pestaña "Datos recientes", por lo tanto, cuando intento mostrar 5000 valores, la base de datos calculó el resultado, pero el servidor no pudo preparar la página web y mostrar una cantidad de datos tan grande).
Recopilación y análisis de estadísticas de ejecución de consultas pg_stat_statements
Pg_stat_statements es una extensión para recopilar estadísticas sobre el rendimiento de las consultas en todo el servidor. La ventaja de esta extensión es que no necesita recopilar y analizar registros de PostgreSQL.Uso de la extensión pg_stat_statementspsql:
CREATE EXTENSION pg_stat_statements;
postgresql.conf:
shared_preload_libraries = 'pg_stat_statements'
pg_stat_statements.max = 10000 # sql , ( );
pg_stat_statements.track = all # all - ( ), top - /, none -
pg_stat_statements.save = true #
:
SELECT pg_stat_statements_reset();
:
select substring(query from '[^(]*') as query_sub, sum(calls) as calls, avg(mean_time) as mean_time from pg_stat_statements where query ~ 'insert into' or query ~ 'update trends' group by substring(query from '[^(]*') order by calls desc
Para monitorear los discos duros en Zabbix, solo se proporcionan los parámetros vfs.dev.read y vfs.dev.write listos para usar. Estas opciones no proporcionan información sobre la utilización del disco. Los criterios útiles para encontrar problemas con el rendimiento de sus discos duros son el factor de utilización, el tiempo de espera y la carga de la cola de carga del disco.Como regla general, una alta carga de disco se correlaciona con un alto iowait de CPU en sí y con un aumento en el tiempo de ejecución de consultas sql, que se encontró durante la prueba de esfuerzo de un servidor zabbix con una configuración estándar sin particiones y sin configurar índices alternativos. Puede agregar estos parámetros para monitorear los discos duros usando los siguientes pasos, que se vieron en un artículo de un amigolesovsky y mejorado: ahora los parámetros de iostat se recopilan por separado para cada disco en el parámetro de tiempo json, desde donde, de acuerdo con la configuración de procesamiento posterior, ya se descomponen en los parámetros de monitoreo final.Mientras la solicitud de extracción está pendiente, puede intentar expandir la supervisión de los parámetros del disco de acuerdo con las instrucciones detalladas a través de mi tenedor .Después de todos los pasos descritos, puede agregar un gráfico personalizado con CPU iowait y parámetros de utilización para el disco del sistema y el disco de la base de datos (si son diferentes) al panel de monitoreo del servidor Zabbix principal. El resultado puede verse así (sda es el disco principal, sdc es el disco con la base de datos):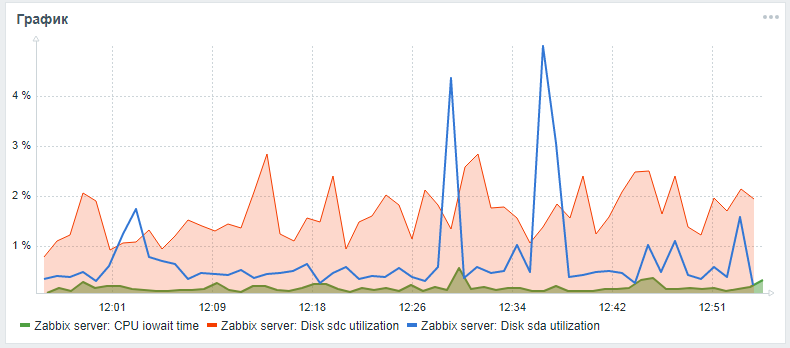
Mejora de rendimiento de hardware
Después de configurar el DBMS, la indexación y la partición, puede continuar con el escalado vertical para mejorar las características de hardware del servidor: agregue RAM, cambie las unidades a estado sólido y agregue núcleos de procesador. Este es un aumento de rendimiento garantizado, pero es mejor hacerlo solo después de la optimización del software.Crear un clúster distribuido
Después de una escala vertical moderada, debe comenzar horizontalmente: crear un clúster distribuido: fragmente o replique el esclavo maestro. Pero este es un tema separado y material de un artículo separado (cómo moldear un grupo de mierda y palos) , así como una comparación de la técnica de optimización de la base de datos Zabbix descrita anteriormente usando pg_pathman e indexando con el método de aplicación de la extensión TimescaleDB.Mientras tanto, ¡uno solo puede esperar que el material de este artículo sea útil e informativo!