¿Cómo saber con certeza qué hay dentro del moño?
¿Tal vez lo tragas, y dentro hay un río? © Tanya Zadorozhnaya
Al parecer, hoy es Data Science, no solo los niños, sino también las mascotas lo saben. Pregúntele a cualquier gato, y él dirá: estadísticas, Python, R, BigData, aprendizaje automático, visualización y muchas otras palabras, dependiendo de las calificaciones. Pero no todos los gatos, así como aquellos que quieren convertirse en especialistas en ciencia de datos, saben exactamente cómo está estructurado el proyecto de ciencia de datos, en qué etapas se compone y cómo cada uno de ellos afecta el resultado final, qué tan intensivos son los recursos en cada etapa del proyecto. La metodología generalmente se usa para responder estas preguntas. Sin embargo, la mayoría de los cursos de capacitación dedicados a Data Science no dicen nada acerca de la metodología, sino que simplemente revelan más o menos consistentemente la esencia de las tecnologías mencionadas anteriormente, y cada principiante de Data Scientist conoce la estructura del proyecto desde su propia experiencia (y rastrillo). Pero personalmente, me gusta ir al bosque con un mapa y una brújula, y me gusta imaginar de antemano el plan de la ruta que está moviendo. Después de algunas búsquedas, logré encontrar una buena metodología de IBM, un conocido fabricante de guías y métodos para administrar cualquier cosa.
Entonces, en el proyecto Data Science, hay 3 bloques de 3 etapas en cada uno, un total de 9 etapas. En resumen, el proyecto consiste en trabajar con los requisitos del negocio, los datos y el modelo en sí.
Trabaja con los requisitos del negocio.
En este paso, no sabemos nada sobre qué datos tenemos. Debemos profundizar en el enunciado del problema, entender qué resultado se requiere para obtener del proyecto, aprender todo sobre los participantes y las partes interesadas. Además, de acuerdo con una tarea específica, debemos decidir por qué método se resolverá el problema. El resultado de este paso serán los requisitos de datos: ok, la tarea está clara, el método ha sido elegido, ahora pensaremos en lo que podemos necesitar para una solución exitosa.
Trabajar con datos
En el segundo paso, comenzamos a buscar datos para resolver el problema: descubrimos qué fuentes están disponibles para nosotros y formamos una muestra con la que continuaremos trabajando. Una vez recopilados los datos, es necesario realizar una serie de estudios para comprender mejor cómo está organizada la muestra: investigar la posición central y la variabilidad, identificar correlaciones entre características y construir gráficos de distribución. Después de esta etapa, puede comenzar a preparar los datos. Como regla general, esta etapa es la que requiere más tiempo y puede tomar hasta el 90% del tiempo completo del proyecto, pero el éxito de todo el proyecto depende de qué tan bien se complete.
Desarrollo e implementacion
Finalmente, el tercer paso. Una vez que los datos estén listos, puede continuar con el desarrollo y la implementación reales. Programamos el modelo, lo configuramos en la muestra de capacitación, lo verificamos en la prueba, si el resultado es satisfactorio, luego se lo demostramos al cliente, lo implementamos, reunimos los comentarios y ... puede comenzar de nuevo.
Todo el proceso se presenta en forma de círculo vicioso: en el buen sentido, un proyecto DS nunca puede considerarse finalizado (aproximadamente, como una reparación, que, como saben, no puede completarse, pero solo puede detenerse):
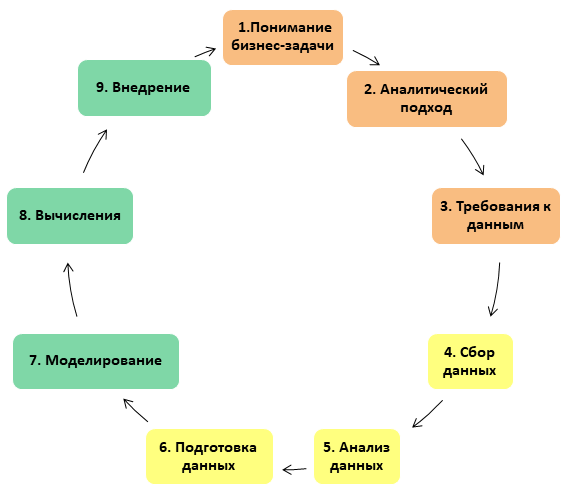
Vamos a entrar en más detalles en cada una de las etapas.
1. Comprender el desafío empresarial
Esta etapa es la base de todo el trabajo posterior: sin ella no se puede construir nada. Es necesario definir claramente el propósito del estudio: ¿cuál es el problema? ¿Por qué debería resolverse el problema? ¿Quién se ve afectado por el problema? Cuales son las alternativas? Y lo más importante: ¿con qué métricas se medirá el éxito del proyecto?
En otras palabras, es necesario identificar claramente el objetivo del cliente. Por ejemplo, el dueño de un negocio pregunta: ¿podemos reducir el costo de una determinada actividad? Necesidad de aclarar: ¿el objetivo es aumentar la efectividad de esta actividad? ¿O aumentar los ingresos del negocio?
Una vez que se define el objetivo, puede continuar con el siguiente paso.
2. El enfoque analítico
Ahora debe elegir un enfoque analítico para resolver un problema comercial. La elección del enfoque depende del tipo de respuesta que necesita obtener al final: si la respuesta debe ser sí / no, un ingenuo clasificador de Bayes es adecuado. Si necesita una respuesta en forma de signo numérico, los modelos de regresión son adecuados. Los árboles de decisión pueden tratar con datos numéricos y categóricos. Si la pregunta es determinar las probabilidades de ciertos resultados, es necesario usar un modelo predictivo. Si es necesario identificar los enlaces, se utiliza un enfoque descriptivo.
3. Requisitos de datos
Cuando el propósito del estudio está claramente definido y se elige el enfoque, es decir, entendemos claramente qué tipo de respuesta a la pregunta que estamos buscando, es necesario determinar qué datos nos permitirán dar la respuesta deseada. Debemos preparar los requisitos de datos: contenido, formatos y fuentes que se utilizarán en la próxima etapa del proyecto.
4. Recolección de datos
En esta etapa, recopilamos datos de las fuentes disponibles: nos aseguramos de que las fuentes estén disponibles, sean confiables y puedan usarse para obtener los datos requeridos en la calidad requerida. Una vez completada la recopilación de datos inicial, es necesario comprender si recibimos los datos que queríamos. En esta etapa, puede revisar los requisitos de datos y tomar decisiones sobre la necesidad de datos adicionales (es decir, es probable que tenga que volver a la etapa 3). Las lagunas se pueden identificar en los datos y se puede elaborar un plan sobre cómo cerrarlas o encontrar un reemplazo.
5. Análisis de datos
El análisis de datos incluye todo el trabajo de diseño de muestreo. En esta etapa, es necesario obtener una respuesta a la pregunta: ¿los datos recopilados son representativos de la tarea?
Aquí necesitamos estadísticas descriptivas. Se aplica a todas las variables que se utilizarán en el modelo seleccionado: se examina la posición central (media, mediana, modo), se buscan valores atípicos y se estima la variabilidad (como regla, esta es la magnitud, la varianza y la desviación estándar). También se construyen histogramas de distribución de variables. Los histogramas son una buena herramienta para comprender cómo se distribuyen los valores de los datos y qué tipo de preparación se necesita para que la variable sea más útil al construir un modelo. Otras herramientas de visualización, como cajas de bigote, también pueden ser útiles.
A continuación, se realizan comparaciones por pares: las correlaciones entre las variables se calculan para determinar cuáles de ellas están relacionadas y en qué medida. Si hay correlaciones significativas entre las variables, algunas de ellas pueden descartarse como redundantes.
6. Preparación de datos
Junto con la recopilación y el análisis de datos, la preparación de datos es una de las actividades más intensivas en recursos del proyecto: estas fases pueden tomar el 70, o incluso el 90% del tiempo del proyecto. En esta etapa, procesamos los datos de tal manera que sea conveniente trabajar con ellos: eliminar duplicados, procesar datos faltantes o incorrectos, verificar y, si es necesario, corregir errores de formato.
También en esta etapa estamos construyendo un conjunto de factores con los que trabajará el aprendizaje automático en las siguientes etapas: extraemos y seleccionamos características que potencialmente ayudarán a resolver un problema comercial. Los errores en esta etapa pueden resultar críticos para todo el proyecto, por lo tanto, vale la pena prestarle especial atención: un número excesivo de atributos puede llevar a que el modelo sea reentrenado e insuficiente para que el modelo esté poco capacitado.
7. Construyendo un modelo
La elección del modelo, como puede ver, se lleva a cabo al comienzo del trabajo y depende de la tarea del negocio. Por lo tanto, cuando se determina el tipo de modelo y hay una muestra de capacitación, el analista desarrolla el modelo y verifica cómo funciona en el conjunto de características creadas en el paso 6.
8. Aplicación del modelo.
La aplicación del modelo está estrechamente relacionada con la construcción real del modelo: los cálculos se alternan con la configuración del modelo. En esta etapa, debemos responder a la pregunta de si el modelo construido cumple con la tarea comercial.
El cálculo del modelo tiene dos fases: se llevan a cabo mediciones de diagnóstico que ayudan a comprender si el modelo funciona según lo previsto. Si se usa un modelo predictivo, se puede usar un árbol de decisión para comprender que la salida del modelo coincide con el plan original. En la segunda fase, se verifica la significación estadística de la hipótesis. Es necesario asegurarse de que los datos del modelo se usen e interpreten correctamente y que el resultado obtenido esté más allá del error estadístico.
9. Implementación
Si el modelo nos da una respuesta satisfactoria a la pregunta, esta respuesta debería comenzar a ser beneficiosa. Cuando se desarrolla el modelo y el analista confía en el resultado de su trabajo, es necesario presentarle al cliente la herramienta desarrollada. Tiene sentido atraer no solo al propietario del producto, sino también a otras partes interesadas: marketing, desarrolladores, administradores de sistemas: todos los que de alguna manera pueden influir en el uso posterior de los resultados del proyecto. A continuación, debe pasar a la implementación. La implementación puede ocurrir en etapas, por ejemplo, para un grupo limitado de usuarios o en un entorno de prueba. También es necesario establecer un sistema de retroalimentación para rastrear con qué éxito el modelo desarrollado hace frente a la tarea. Después de algún tiempo, esta retroalimentación será útil para mejorar el modelo. También pueden aparecer nuevas fuentes de datos, nuevas partes interesadas, sin mencionar el hecho de que la tarea comercial en sí misma puede especificarse. Por lo tanto, no hay límite para la perfección: incluso un modelo integrado nunca puede considerarse ideal.