El desarrollo ha cambiado mucho en los últimos años. En lugar de aplicaciones monolíticas, llegaron microservicios y funciones. Las bases de datos de monstruos industriales universales se han degenerado en objetivos específicos. Docker cambió de opinión sobre el despliegue. Pero, ¿ha cambiado nuestra idea de los registros?
Uno de los grandes problemas en Yandex.Verticals fueron los registros: 18 TB por día y 250,000 registros por segundo, todo está escrito en archivos. Los registros son heterogéneos porque hay muchos idiomas: Scala, Java, Python, Go. Luego los recoge Fluent Bit, escribe en Kafka, los manipuladores trabajan en una máquina de hierro, ensamblan desde Kafka y escriben todo en el disco. Además, esta es la segunda versión de los registros.

Como resultado, surge un largo problema de búsqueda. Estos registros se buscan utilizando grep. En algunos servicios, grep puede alcanzar horas. Si tiene problemas en la producción, no estará buscando sus registros durante horas. Para resolver el problema, Yandex decidió escribir su propia bicicleta de entrega de registros para la búsqueda. Lo que surgió de esto, le dirá a
Alexei Danilov (
danevge ), el desarrollador del equipo de infraestructura en Yandex. Desarrolla, escribe y respalda proyectos de auto.ru y Yandex.Real Estate.
Descargo de responsabilidad. El artículo habla sobre el desarrollo moderno y es adecuado para la arquitectura de microservicios. Aquí se presentan varios productos: estas son herramientas que se utilizan en Yandex.Verticals. En otras condiciones, los análogos son posibles con mayor éxito, pero realizan casi las mismas funciones. Nota El artículo es una versión extendida del informe de Alexey Danilov "No se necesitan registros" en RIT ++ 2019 DevOps Conf, que se modifica estilísticamente y se complementa con material nuevo. Puede encontrar la grabación de video del discurso de Alexey en el enlace de nuestro canal de YouTube.
El equipo de Yandex.Vertical tiene 300 personas, de las cuales aproximadamente 100 son desarrolladores. En desarrollo, no somos diferentes de la mayoría de las empresas que crean sus propias soluciones de productos. Microservicios, todos viven en Docker, un monolito en PHP está acumulando polvo en un rincón oscuro, implementado a través de Hashicorp Nomad y mantenemos un zoológico de idiomas: Scala, Java, Go, Node.js, Python.
Uno de los grandes problemas de infraestructura en Yandex.Verticals son los registros de aplicaciones. Cuando abordamos seriamente este problema, utilizamos la tercera versión de su recopilación y procesamiento. Simplificado, funcionó así:
- las aplicaciones escribieron en archivos;
- Bit fluido leyó los archivos y los envió línea por línea a Kafka filebeat;
- En una máquina de hierro dedicada había una aplicación que leía el tema de Kafka y escribía en los archivos del disco.
En la temporada de calor, tuvimos 18 TB de registros por día, o 250,000 líneas por segundo. Esta es una cantidad muy grande, lo que complica el trabajo con estos datos. La única forma de analizar esto es grep, ya que todo se almacena en archivos. Para aplicaciones grandes, el análisis puede llevar horas. Para problemas en la producción, no tienes este tiempo.
Las soluciones preparadas no encajaban en precio, recursos o velocidad. No podían manejar aceptablemente nuestro flujo. Incluso es difícil contar la cantidad de intentos de cocinar Elasticsearch. Supongo que no sabemos cómo cocinarlo. Pero esto no es lo que necesitamos, si para usarlo como un depósito de registros, se requieren habilidades especiales (habilidades).
En esta situación, decidimos implementar nuestro propio sistema para recopilar y analizar registros.
Bicicleta
 Nota: Si la próxima bicicleta no es interesante, proceda inmediatamente a la sección "Tipificación".
Nota: Si la próxima bicicleta no es interesante, proceda inmediatamente a la sección "Tipificación".Formato
Usamos varios PL y amamos los microservicios. Para trabajar con los registros, formamos uniformemente nuestro propio formato JSON. Cubre la mayoría de las necesidades de trabajo adicional con registros.
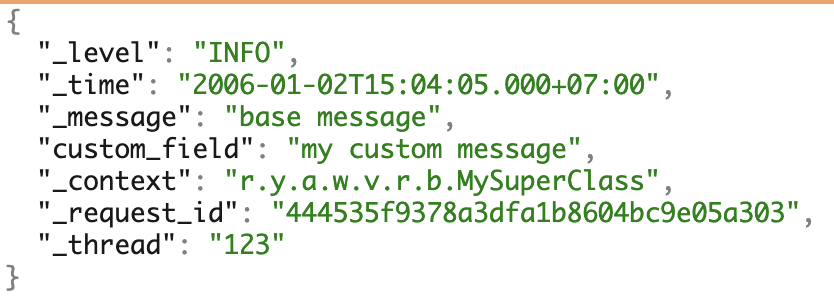 Un ejemplo de registros con todos los campos posibles.
Un ejemplo de registros con todos los campos posibles.Controlador de registro de Docker
Para recopilar los registros, escribimos nuestro propio
controlador de registro de Docker , una aplicación en Go. Se ensambla de una manera especial, entregada por los comandos del complemento Docker, almacenada en el registro y se ejecuta en una sola instancia con Docker.
Dado que cualquier problema con el controlador de registro puede afectar negativamente todo el trabajo, intentamos escribir una implementación mínima. Nuestro controlador escucha la salida estándar del contenedor e inmediatamente pasa los registros a la aplicación que está cerca. Ya se ocupa de la parte más compleja de la entrega.
Los problemas
Mencionaré por separado los problemas de actualización de la versión del controlador de registro de Docker.
 Captura de pantalla de la Grafana interna.
Captura de pantalla de la Grafana interna.A la izquierda está la relación de versiones instaladas a máquinas. Ahora se instalan tres versiones en todo el hardware: no se pierden automóviles en ningún lugar y no hay instalaciones innecesarias. A la derecha está el número de contenedores que usan esta o aquella versión.
El controlador de Docker no puede ir y actualizarse de inmediato. Para hacer esto, tendría que reiniciar todos los contenedores y todos los servicios, lo que podría ocasionar problemas. Por lo tanto, para instalar la nueva versión, solo esperamos que todos los contenedores se actualicen.
Esquema general
Considere el esquema general de un nuevo sistema para recopilar y entregar registros. Otros detalles no son tan interesantes.
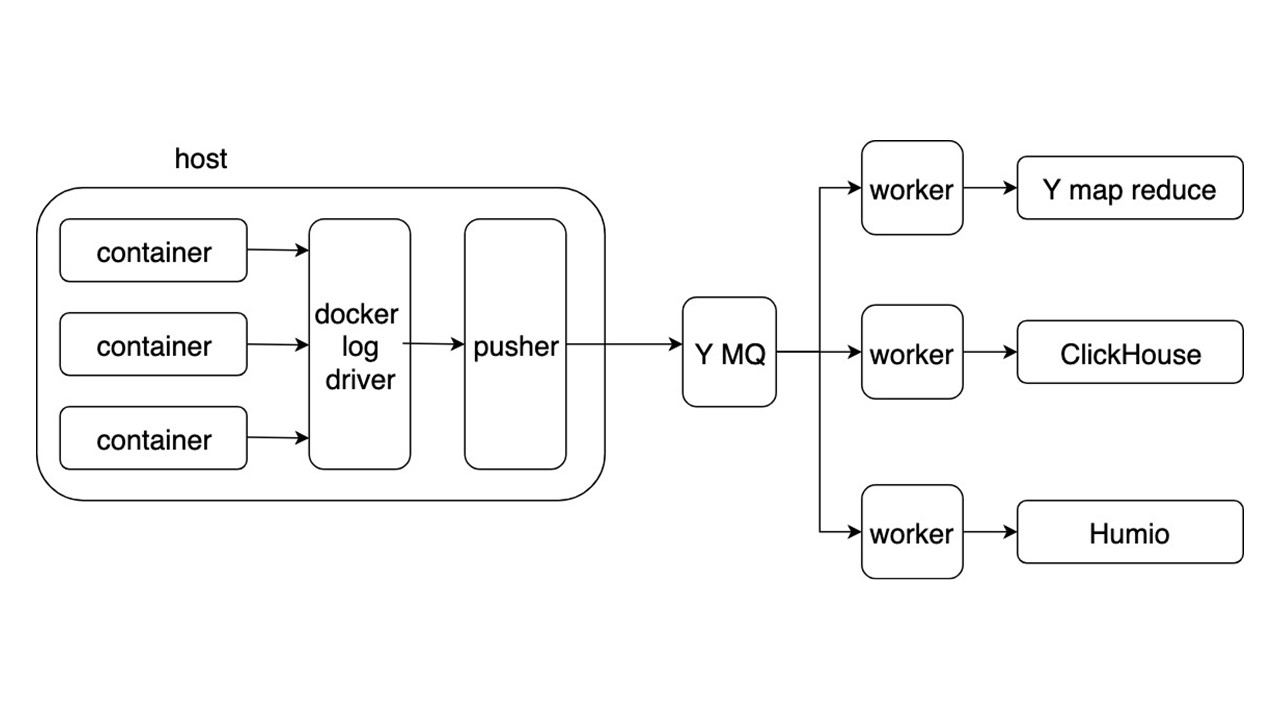
Las aplicaciones escriben registros en formato JSON en stdout. Docker escucha la canalización desde el contenedor y la redirige al controlador Docker. El controlador Docker lee y vuelve a fundir asincrónicamente todo en Pusher.
Pusher se encuentra en cada carro de hierro. Prepara, satura, voltea e inserta registros en Yandex Message Queue. La secuencia de registro de MQ es analizada por tres tipos de trabajadores y escrita en los repositorios.
Hay tres repositorios para grabar registros.
- Yandex mapReduce para almacenar y analizar registros durante un largo período de tiempo. Este es un análogo de Hadoop.
- ClickHouse para almacenar registros durante el último día.
- Humio (como experimento) para almacenar registros para el último día.
Ganancia
El formato general le permite escribir y procesar registros de la misma manera. La recopilación de registros es automática, sin usar un disco, y la entrega se realiza en unos segundos. Búsquedas clave de 2 segundos a 5 segundos. Almacenamiento y recuperación durante un largo período de tiempo.
Para volúmenes más pequeños, considere alternativas: Humio, Splunk y Elastic. Los dos últimos tienen controladores Docker oficiales. Si vives en AWS, ese es Amazon CloudWatch.
Amazon Cloudwatch
Amazon CloudWatch maneja métricas, eventos y registros. No busca lo último, no proporciona elementos de súper búsqueda y no los procesa de la forma habitual. Amazon CloudWatch procesa registros, análisis, filtros y pantallas en gráficos.
 Amazon CloudWatch convierte registros en métricas y gráficos.
Amazon CloudWatch convierte registros en métricas y gráficos.¿Qué hacer con los registros?
De vuelta a nuestra bicicleta, ¿satisface todos los casos? No, nuestra solución le permite encontrar los registros, pero requieren mucha mayor heterogeneidad de información y sus tipos. Los registros se utilizan en muchos más casos.
Tan pronto como recopile los registros, la siguiente oración será: "Analicemos algo, procesémoslo de alguna manera, escríbalo en alguna parte y comencemos a mostrarlo en gráficos, en tableros". Este es el camino al infierno. Especialmente si estamos hablando de herramientas comunes.
Si imagina los registros como un cierto caos o registro de eventos de cualquier dato, entonces no funcionarán.
Esto será un gran desorden de información que no se puede procesar. Un juego comenzará en la formalización de los registros: "¡Escribamos estas líneas en un formato especial para que sea conveniente analizarlas más tarde!" Eso tampoco funciona. Créanos, lo intentamos.
Escribiendo
Si divide los registros en tipos y los procesa por separado, puede encontrar herramientas que facilitarán el trabajo con ellos. Trabajando no más como con los registros, sino como con datos útiles, este trabajo es más transparente y conveniente. Algunos tipos de registros se pueden tirar por completo.
Por si acaso
Este tipo de registros "to be" es mi favorito. Si es imposible responder claramente por qué se necesita esta o aquella línea, entonces lo son. Este tipo también se puede llamar "registros por si acaso".
// validate customer func Validate(customer Customer) { // ??? log.debug(“Validate customer %v”, customer) … log.Error(“Customer not valid %v. Reason: %s”, ...) …. }
Los registros no son comentarios que se puedan eliminar. Esto es parte del código que es más difícil de modificar, mantener y aún más eliminar.
En el mejor de los casos, dicho registro puede convertirse en una depuración o rastreo. Este tipo
abarrota el código . Debido al registro precipitado, puedo ingresar datos personales, contraseñas y cookies de los usuarios.
La forma correcta es
tirarlos y olvidarlos . Pero luego nos enfrentamos a un nuevo problema. ¿Cómo analizar la situación con un error?
Error fatal / crítico
Para empezar, consideramos solo los errores críticos. Estos son errores que sufren los usuarios y desarrolladores. El primero: cuando no pueden completar la operación. El segundo: cuando necesita hacer correcciones a mano.
¿Por qué los registros no encajan?
No hay respuesta rápida . Si el equipo de desarrollo se entera del error de los usuarios a través del soporte o de Twitter, entonces es hora de cambiar algo.
No hay contexto Una línea separada del registro de errores es inútil. Tenemos que recopilar el contexto poco a poco. Aun así, puede que no sea suficiente, ya que este es el contexto del proceso, no el error.
No hay una gran imagen . No hay respuesta a las preguntas:
- con qué frecuencia ocurre tal error;
- ocurrió en las réplicas restantes del servicio;
- fue antes?
Para solucionar estos problemas, use una herramienta adecuada, por ejemplo,
sentry.io . Le permite trabajar con información de error representativa, completa (contextual) con una
alerting rule personalizable.
El sitio web de centinela describe las diferencias en los registros del uso de sentry.io.
Error no crítico
Lanzamos errores fatales y críticos y ahora están escritos en Sentry. Pero hubo errores internos: varias bibliotecas o respuestas de servicios de terceros.
Un buen ejemplo es un reintento exitoso. Supongamos que el servicio A recurrió al servicio B pero, debido a problemas de red, no pudo obtener una respuesta. Después del error, el servicio A volvió al servicio B y recibió una respuesta válida. ¿Es crítico el error en la primera llamada? No En este caso, el proceso se completó con éxito y el usuario pudo usar el servicio.
Si tales errores no son críticos para que el servicio funcione y no afectan al usuario con una repetición rara, entonces estos no son errores en absoluto. Esto es una degradación del servicio, aunque la respuesta al usuario llegó 50 ms después. Este tipo de registro se refiere a advertencias - Advertencia.
Advertencia
Las alertas son información sobre la degradación de un servicio.
Aquí veremos los mismos problemas inherentes a los errores críticos, pero con una reserva. La reacción a un evento individual no es importante: su cantidad a lo largo del tiempo es importante.
Considere un ejemplo en el que un servicio no puede recuperar una entrada de caché y accede al almacenamiento en frío. Si esto sucede una vez por minuto, esto puede tomarse para el funcionamiento normal del servicio.
Las emisiones raras no son importantes .
Pero al mismo tiempo, necesita tener una herramienta para ver el panorama general, necesita
un análisis en tiempo real . Para realizar un seguimiento de los cambios durante un largo período de tiempo, sería bueno tener también un
análisis retrospectivo . La degradación por encima de un cierto nivel (umbrales) puede afectar negativamente a los usuarios: necesita una
reacción con degradación severa .
No necesitamos los registros marcados como Advertencia, sino las métricas de degradación.
La herramienta de recopilación de métricas más popular es Prometheus, y puede usar Grafana para la visualización. Si necesita un contexto grande (igual que el error), entonces el mismo Centinela funcionará, pero con las alertas desactivadas. Sin embargo, en la mayoría de los casos habrá suficiente contexto. Se usará para gráficos: etiquetas de Prometheus.
Ejemplos.
Se produjeron tres eventos en el servicio de
user_service condicional. Afectan el funcionamiento del servicio: una solicitud larga a la base de datos, acceso repetido a la API del servicio
service_b y no se encontraron derechos de usuario en la memoria caché. Los gráficos y alertas se configurarán como importantes para los desarrolladores del servicio, gracias al contexto.
Rastreo
Esto es lo primero para comenzar si elegimos la ruta donde necesita analizar los registros. Por sí misma, esta información en los registros es inútil, porque necesita construir cadenas de llamadas, ver datos dentro de las solicitudes, errores en las cadenas de llamadas, tiempos de respuesta, el número de RPS.
Existen excelentes herramientas para el rastreo: Jaeger o Zipkin. Recomiendo usar OpenTracing, que ambos admiten.
Puede recopilar el seguimiento de tres fuentes.
- Si usa equilibradores compartidos, analice los registros de ellos y envíelos a Jaeger.
- Los servicios mismos , si reciben direcciones a través de Service Discovery y van directamente. En este caso, el seguimiento de los servicios se envía directamente a Jaeger.
- Servicio inteligente de malla . Él sabe cómo recopilar y enviar un rastro, por ejemplo, Istio.
Información inicial
Esta información es sobre llamadas de servicio API, lanzamiento de Cron, consultas de bases de datos o llamadas a otros servicios.
{ "_message": "Request: ...; request_id: ...,... ", "_level": "INFO", "_time": "2019-03-08T12:04:05.000+07:00", "_context": "ryawvcHandler", "_tread": "785534" }
Esta información pertenece al bloque "Por si acaso", pero está separada porque es más común. Esta información es necesaria para analizar el error y
puede descartarla .
Si la información sobre las llamadas a métodos internos es de importancia crítica y no puede prescindir de ella, incluso con el contexto recopilado en caso de error, entonces vale la pena instrumentar las llamadas de método como un rastro.
Tiempo de ejecución
Esta información es sobre el tiempo de ejecución de métodos, API, consultas de bases de datos u otros servicios.
{ "_message": "Get customer 12ms", "_level": "INFO", "_time": "2019-03-08T12:04:05.000+07:00", "_context": "ryawvcCustomerRepository", "_tread": "785534" }
No hay ningún valor en los registros, porque necesita analizar esta información, mostrarla en gráficos y configurar umbrales. Este tipo de registros debe reemplazarse con
métricas , por ejemplo, en Prometheus.
Información del negocio
Esta información es necesaria para análisis de negocios, análisis de comportamiento del cliente, cálculos financieros. En este lugar, históricamente utilizamos el enfoque opuesto: los registros analizados. Pero este es un buen ejemplo de lo que los registros de la aplicación pueden degenerar si trabaja con ellos de esta manera.
Para los registros con datos comerciales, se formaron acuerdos con campos fijos en formato TSKV, que son necesarios para el análisis. Las aplicaciones escribieron registros de negocios en un archivo dedicado. Luego, los registros se leyeron y se enviaron línea por línea a MQ, y una aplicación separada los procesó y los escribió en la base de datos. Este es un ejemplo de en lo que se convierte cualquier análisis.
No funcionará analizar todo el flujo de registros con la esperanza de que los datos converjan.
Están surgiendo convenciones, formatos, reglas y requisitos de confiabilidad. Esto ya se parece un poco a los registros de la aplicación. En este caso, el registro se convierte en la cola de entrega de datos con todos los requisitos resultantes para MQ. Es notable que el middleware en forma de registro es superfluo aquí.
Una buena solución es enviar estos datos directamente a MQ. Ya allí serán procesados, almacenados en el almacenamiento apropiado y utilizados por el equipo de análisis. Por ejemplo, para la visualización usamos Tableau.
Rendimiento
Este tipo de registro rara vez se encuentra en los registros de aplicaciones y se recopila con mayor frecuencia como una métrica. Por separado, agrego que para recopilar las métricas básicas que son específicas del idioma, es suficiente usar la biblioteca Prometheus. Por defecto, recogerá todo lo que alcance. El costo de agregar estas métricas es pequeño.

Resultado de escritura
Después de ordenar los registros por tipo, podemos elegir herramientas más potentes para trabajar con ellos. No hay sistemas complejos o tecnologías espaciales como Amazon, no hay nada que no pueda plantearse mañana. Probablemente ya tenga algunos de estos sistemas o análogos: Sentry está acumulando polvo en alguna parte, Prometheus está trabajando en alguna parte.

El problema no está en la tecnología, sino en una trampa cognitiva cuando confiamos en los registros como un medio de representación confiable del estado de nuestro sistema. Esto no es así, los registros son un conjunto de eventos caóticos.
Hay una excepción: los registros de depuración, que se pueden usar en casos excepcionales.
Registro de depuración
Los registros de depuración deben ser información detallada. No deben duplicar lo que ya se está enviando a los sistemas que describimos anteriormente. Este tipo existe para analizar casos especiales. Por ejemplo, se produce un error incomprensible en la producción, y en este momento no está claro por métricas lo que está sucediendo.
Active los registros de depuración en caliente, sin reiniciar el servicio . Como estamos hablando de varios servicios, no habrá muchos de ellos. No se necesita infraestructura sofisticada. Suficiente pila de ELK sin complicada "preparación". También tiene sentido agregar una alerta a Sentry con todo el contexto necesario.
Los registros de depuración se pueden usar para el desarrollo . Pero se reemplazan perfectamente por depuración.
Para resumir
Escribimos nuestra entrega de registro de bicicleta para la búsqueda . No satisfacemos a los clientes del servicio; todos vienen a analizarlos, recopilarlos y agregarlos en algún lugar. Esto se puede evitar: no se necesitan sistemas complejos de procesamiento de registros.
Los registros sin procesar son inútiles, pero pueden convertirse en métricas útiles.
Es suficiente crear una infraestructura para entregar métricas y datos útiles sobre los servicios. Como resultado, aparecerán métricas útiles que hablan sobre los servicios y muestran de manera transparente todo lo que les sucede.
Los errores deben contener el contexto del error mismo.
Esto ayudará a sobrellevarlo y a solucionarlo de inmediato.
Los errores y la degradación deberían llevar a la acción , de modo que los desarrolladores aprendan instantáneamente sobre los problemas y los solucionen incluso antes de que los usuarios enojados lo soliciten.
Las herramientas adecuadas harán que trabajar con sus servicios sea más agradable y transparente . La depuración tiene un lugar para estar, pero debes ser estricto con ella.
En HighLoad ++ 2019 en noviembre habrá una sección de DevOps: 13 informes sobre cargas en AWS, un sistema de monitoreo en Lamoda, transportadores para entrega de modelos, vida sin Kubernetes y mucho más. Consulte la lista completa de temas y resúmenes en la página separada " Informes ". Y nos reuniremos en DevOpsConf en la primavera: suscríbase al boletín informativo y avísenos cuando determinemos las fechas y la ubicación.