En noviembre de 2018, se creó un departamento de soporte de información en Lituania e invitó a
Andrei Yumashev a dirigir. El año pasado, el departamento ayuda a la empresa a trabajar y desarrollar y mantiene toda la infraestructura bajo control. Pero ese no fue siempre el caso. Antes de comenzar a trabajar, Andrei se enfrentó a ruinas: Nagios medio muerto, Cactus condicionalmente vivo y Puppet en coma, Wiki muerto de 120 páginas, tablas de tareas incoherentes y lista de hierro, arquitectura obsoleta, 340 núcleos inactivos, 2 TB de RAM y 17 TB espacio en disco que por alguna razón no se registró en las tablas de inventario. Planes que no funcionan, plazos que se rompen, entorno de trabajo y herramientas que no existen: todo esto le esperaba a Andrei en un nuevo proyecto.

En
DevOpsConf 2019, Andrei hizo un informe en el que mostró en ejemplos en vivo lo que vale y lo que no debe hacerse cuando ingresa a un proyecto que no ha visto o que conoce mal. Debajo del corte hay una versión actualizada de la historia: cómo analizar adecuadamente el rango de problemas y construir un plan de actividades, cómo calcular los KPI correctamente y cuándo detenerse a tiempo.
Andrey Yumashev es propietario de sus propias empresas de desarrollo en diversos campos (en línea y fuera de línea), consultor en la construcción de procesos y jefe del departamento de soporte de información de LiteRes.
Un poco sobre LiteRes. Este es el mayor proveedor de libros electrónicos y de audio en Rusia, una editorial y un montón de proyectos de asociación. Estos son cientos de miles de líneas de Perl, varios grupos de bases de datos y repositorios. Esto es 2 GB de tráfico saliente por segundo, cientos de miles de solicitudes únicas por día, varios bastidores en diferentes centros de datos y más de 100 servidores. En general, esto no es solo una librería electrónica.
Primeros pasos
Solía trabajar en LiteRes a destajo. La compañía practica el desarrollo de personal con el registro de empleados remotos en el estado.
El sistema de cumplimiento de tareas en litros funciona según el principio de una "subasta". En el rastreador de tareas interno, los gerentes y arquitectos describen tareas para proyectos internos y las evalúan en moneda local. La moneda es "hongos, hierba y árboles".
Luego comienza la "subasta fácil": cualquier desarrollador puede asumir la tarea o negociar. Bien hecho, te pagan. No trabajé en absoluto, no lo entiendes. De una manera lúdica, las personas están interesadas en completar tareas. Para obtener más información sobre este sistema, consulte la
presentación de Dmitry Gribov.
 Trabaja por los champiñones.
Trabaja por los champiñones.El sistema me convenía: apoyé la experiencia de programación de Perl, trabajé cuando era conveniente y no pasé demasiado tiempo en él. En este modo, pasé un par de años hasta noviembre del año pasado y pensé que entendía la estructura del ecosistema.
Estaba equivocado
Me invitaron a la compañía e informé que mis servicios como desarrollador de Perl no eran necesarios, y me ofrecieron dirigir un nuevo departamento. En noviembre de 2018, me convertí en el jefe del departamento de información.
Frente a mí había espacios abiertos: varios bastidores con hierro en varios centros de datos en Moscú, arquitectura obsoleta, recursos extranjeros y la ausencia casi completa de documentación relevante para eso es todo. La introducción sonaba más o menos así: "Ahora este es su patrimonio, mejorar, no romper y apoyar". Había una lista lista de tareas y planes generales para el próximo año. Era necesario comprender todo esto y llevarlo a una forma humana.
Tenía la sensación de que estaba mirando hacia el abismo, y el abismo me estaba mirando.
La experiencia de los últimos años me ayudó mucho cuando desarrollé una posición clara al trabajar con un extraño o incomprensible. En primer lugar, este es un estudio exhaustivo y un plan de acción mínimo. Aquí es donde empecé.
La limpieza es la clave de la salud.
El orden es ante todo.
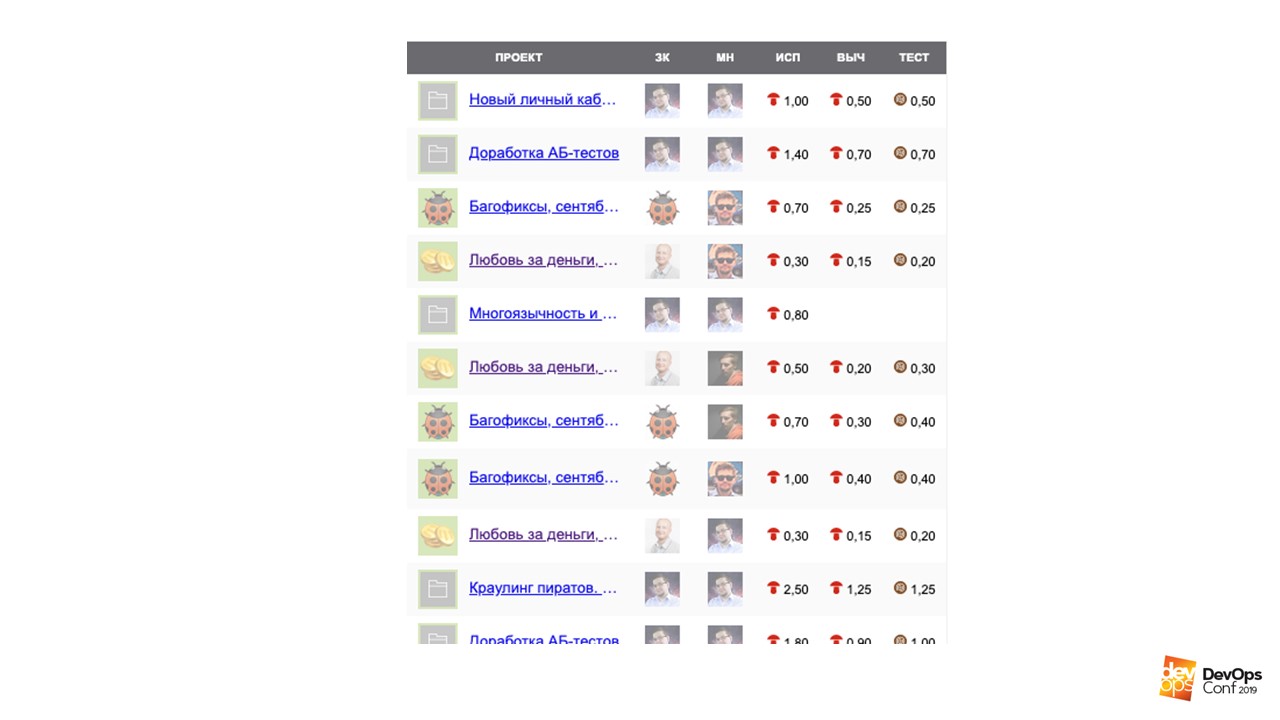
Para el primer mes logró encontrar:
- Hojas de cálculo de Google dispersas con tareas actuales y una pizca de información útil;
- documentos dispersos: Word, textos, fragmentos de antiguas páginas Wiki de 120;
- Nagios, medio muerto;
- monitoreo condicional en vivo de Cactus;
- marioneta muy vieja con signos raros de vida.
Todas estas ruinas también recogieron 400 métricas.
 Las ruinas que encontré en el primer mes.
Las ruinas que encontré en el primer mes.Fui un poco divertido, leí todo con fluidez y me apegué a los procesos de Trello. Le transfirió las tareas actuales de sus colegas y comenzó a soñar: escribir un plan para el trimestre y el año.
Primer error
No hay planes hasta que explore la zona.
El plan brillaba con calor y salud, pero no tenía en cuenta la realidad. Fue hermoso y simple: implementar monitoreo, analizar registros y transferir implementación a CI / CD. En algún momento al final hubo un lánguido "análisis de las debilidades del proyecto". Primeros pasos clásicos.
Me olvidé de lo principal. Mi primera prioridad no es implementar herramientas para la implementación de herramientas, sino garantizar la viabilidad y la estabilidad del servicio en su conjunto.
Mientras escribía el plan y atormentado por las preguntas de mis colegas, llegaron los primeros problemas. Uno de los nodos de uno de los grupos de clústeres se quedó sin espacio, y el SSD en su conjunto terminó en el otro nodo del mismo grupo. Compré urgentemente nuevos discos más grandes y nuestro departamento rápidamente ganó experiencia en reemplazar estos discos copiando el sistema de un disco a otro. Después de reemplazar los discos, creamos el clúster desde cero a través de SST. El clúster está construido sobre Percona y Galera, y ese entretenimiento no va a él por nada.
Mientras viajaba entre centros de datos, nacieron los
primeros brotes de dudas sobre el plan.
 Ahhhhhh!
Ahhhhhh!Al mismo tiempo, la intensidad del trabajo negro era tan alta que ni siquiera pensé en recopilar un historial médico completo, sino que simplemente tomé algunas fotos para seguir estudiando.
En paralelo, apareció otra introducción. En litros hay versiones de audio de libros. Para que el oyente no rebobine la grabación cada vez más, tenemos un mecanismo que rastrea el momento de la parada. La próxima vez que escuche, la versión de audio se reproducirá desde la sección deseada. Para esta tarea, llevó alrededor de 500 núcleos más rápido, un terabyte de RAM y un poco de análisis en Java.
Comencé a informar a Azure, Google, DigitalOcean y todo lo demás que proporcionaban las soluciones de gotas. La contenedorización suplica, ¿por qué no implementarla alegremente? Además, en el "gran" plan había un punto separado sobre esto.
Ha pasado un mes en correspondencia y licitación, todo se agregó a las tareas en Trello, de las cuales generé una parte importante, pero el resultado no progresó. Me preguntaba si iría allí. Ante mí, todo funcionó de alguna manera y no se detendrá, sin importar cuánta actividad vacía muestre. Me senté cuidadosamente para estudiar el inventario que pude reunir poco a poco. Luego se levantó y fue a la segunda ronda de centros de datos.
La segunda visita tranquila a los centros de datos puso todo en su lugar. Cuando vi todo esto no en la consola, no en Excel, sino vivo, mi conciencia de la realidad cambió radicalmente. Me di cuenta de que no estoy ocupado con lo que debería. Porque primero necesitas entender con qué estoy trabajando.
Hasta que entienda con qué estoy trabajando, todos los planes son una pérdida de tiempo.
Estudié los bastidores, comparé la realidad con las listas, realicé ediciones y me topé con una semi unidad con 20 cuchillas. De 20, solo 4 funcionaron. Sacudí las cuchillas y me di cuenta de que no necesitábamos gotas para la solución. ¡Porque encontré 340 núcleos inactivos, 2 terabytes de RAM y 17 terabytes de espacio en disco! Estos son viejos backends, viejos nodos de clústeres que simplemente dejaron de usarse y el tiempo ha borrado la memoria de su existencia. Puse a Kubernetes sobre estas cuchillas y me libré de una tarea importante.
Primer error de salida
Analizar y estudiar. Sin un análisis preliminar de la situación, el tren no se mueve.
Gracias a un cuidadoso viaje a los campos, ya tenía en mis manos un plan bastante relevante para el equipo y la arquitectura general del sistema. En el patio era enero. Pasé dos meses en esto, de los cuales la mitad simplemente me lancé de lado a lado. No sabía qué tipo de incendio extinguir primero, qué problema resolver primero: la rutina con apoyo no fue a ninguna parte.
En paralelo, deduje tres reglas. Estas son consecuencias del primer error.
 Tres corolarios.
Tres corolarios.Segundo plan
Descarté tareas secundarias desde el primer plano: análisis de registros e implementación de CI / CD. En una escala de catástrofe general, estas pequeñas cosas no son importantes. Litros ha trabajado durante años y ha desarrollado sus propias lógicas para trabajar con troncos, y ha adquirido un demonio rodante hecho a sí mismo. Metí en el quinto plan lo que funcionó y no requirió intervención.
El segundo plan se parecía a esto.
Tratar con el monitoreo . En su forma actual, no reflejaba al menos un tercio de los problemas, aunque funcionó.
Describa la lógica general de todos los litros . Los nombres de los servidores son excelentes, pero los paquetes clave son un conocimiento crítico: qué, dónde, dónde, por qué y por qué. El error anterior dejó en claro que sin esto de ninguna manera.
Escalado Casi los últimos recursos gratuitos tomaron Kubernetes. Según estimaciones mínimas, se suponía que terminaría todo el grupo de trabajo en seis meses.
Inventario y estado de los equipos . Como parte del viaje, literalmente borré una red de varios servidores que asustaban con sus etiquetas: "copia de seguridad", "suscripción", "bgp". De nuevo, discos, cayendo discos.
Adaptación de guías a la realidad . La mayoría de las instrucciones están desactualizadas o incompletas.
Los primeros seis meses pasaron desapercibidos en la facturación, compra de equipos y problemas, y finalmente me establecí en el segundo error.
Segundo error
No lo subestimes.
Se subestima cualquier término que se le ocurra . Claro, puede beneficiarse rápidamente del proyecto. Pero para maximizar los retornos, multiplique el tiempo planificado por
al menos dos veces . Especialmente en un proyecto complejo y altamente cargado, que crece constantemente en tráfico en más del 100% por año.
¿Por qué al menos dos veces? Si el proyecto es inestable y no se investiga, prepárese para el hecho de que cualquier actividad dará lugar a otras actividades en lugares vecinos. Parece que reemplazar discos, ¿cuál es más fácil? El procedimiento es simple hasta que encuentre una compra, luego programe el tiempo para nodos específicos de tiempo de inactividad y luego realice el servicio después de reemplazar un disco. Calculé esta simple operación una semana. Al final, tomó dos semanas y media, incluso con un esquema de adquisición simple.
Otro ejemplo es la compra e instalación de nuevos equipos. Comprar y pegar, ¿qué es tan difícil? No tardé más de un mes en hacerlo sin tener en cuenta el tiempo de entrega. De hecho, uno de los tres chasis todavía está parado frente a mi escritorio. Esto se debe a que el equipo simplemente no tenía suficiente espacio: calculamos el lugar en los agujeros entre la instalación actual. Cuando llegamos a uno de los centros de datos con la intención de sacudir el rack, de repente nos dimos cuenta de que los dos servidores eran "intocables". El primero es el host, y simplemente no es seguro tocarlo. El segundo es una canasta de 16 discos, que se cierra con un montón de datos. Las pajillas no se colocaron, el análisis no se llevó a cabo, y es bueno que hayan podido pegar dos de cada tres.
Si parece que todo será simple, pronto tendrá problemas . Esta instalación planteó una nueva pregunta: si todo está tan mal en el lugar, ¿cómo nos expandiremos? Una pequeña tarea ahora generó un sudor gigante. En 2020, según el plan, la transferencia de un centro de datos a otro y la expansión del resto por bastidores. Esto significa la migración dentro del centro de datos entre los módulos. La migración se complementó con la reestructuración de la red y su transferencia a 10G.
No subestimes el tiempo, el umbral de entrada y las consecuencias.
Conceptos basicos
Por supuesto, la esencia de los errores ya se describe en Wiki como conceptos básicos.
Cualquier proceso burocrático dura al menos un mes . Esto se aplica a las adquisiciones, la conclusión de nuevas condiciones con un centro de datos u otros contratistas, a todo. Tómalo como un hecho.
Después de la conclusión del contrato y el pago, cualquier entrega dura al menos una semana y media , desde los discos hasta los procesadores. Aprenda a negociar con los proveedores para las fechas previas a la entrega. Por ejemplo, los discos se envían en pequeños lotes ahora hasta el pago e incluso antes de la aprobación de la aplicación.
Si bien no hay una comprensión clara de la implementación, cualquier plan para implementar algo sigue siendo un plan. Cuanto más cortos sean los pasos, mejor.
Por ejemplo, para cambiar de MySQL a ClickHouse, un paso amplio se ve así: “¡Llenemos un servidor, luego dibujemos un boleto para la reintegración y vuele!”. De hecho, un estudio detallado del problema condujo a nuevos pasos: compra adicional de equipos, por ejemplo, procesadores y discos, tickets detallados para cambiar la lógica del rastreador de comportamiento del usuario, mantener la integración inversa, los servidores de cola y muchos otros.
Cuanto más detallado sea el plan, mejor. Escribir con una pincelada amplia es una garantía de 100% de error en la fecha límite.
Sujete cualquier plan a las máximas críticas y espere el máximo riesgo . Asegúrese de mirar el plan desde el punto de vista comercial: qué beneficio traerá cada paso.
Tuvimos que llevar a cabo implementaciones obligatorias: monitoreo, Ansible, pero no nos olvidamos del componente comercial.
- Al cambiar la arquitectura de la red, podremos aceptar tráfico adicional y resolver muchos problemas actuales.
- Al cambiar el tipo de almacenamiento de contenido, reduciremos la cantidad de errores con la devolución de libros y aumentaremos la velocidad de trabajo con los datos.
- Mueva el back-end a la nube: aumente instantáneamente la carga durante las campañas de marketing.
- Traducir el seguimiento a ClickHouse es una oportunidad para que los analistas comprendan mejor las necesidades de nuestros amados lectores y oyentes.
La mejor manera de lidiar con una situación en la que está poco versado en el tema es solicitar la ayuda de especialistas, no Stack Overflow . El contacto de voz resuelve el problema muchas veces más rápido que la correspondencia larga o la lectura de documentación.
Seis meses despues
A pesar del hecho de que las tareas raíz en las que me enfoqué al principio todavía estaban resbalando, gracias a la investigación y las correcciones, algo bueno apareció en mis manos.
Herramienta autoescrita para el inventario de redes y direcciones. Regularmente hizo tapping en todas nuestras subredes y además verificó los datos con la configuración BIND. Esto facilitó y agilizó la puesta en servicio de nuevos servicios y entendió la carga real de los grupos de redes. Realmente no quería gastar tiempo en esto, pero no pude encontrar una alternativa preparada, y encontrar una dirección para asignar a un nuevo recurso tomó mucho tiempo. Mientras escribía la herramienta, el primer borrador del plan apareció en la red.
La marioneta ya no está tan muerta y confundida . Estaba armado con una conclusión del error número uno y ni siquiera intenté pasar a Ansible, lo cual es más cómodo para mí.
Nagios más o menos amañado . Lo trasladé de la oficina al centro de datos y lo distribuí en tres puntos. Fue mucho más rápido y más barato que implementar Zabbix. Completamos un agujero con alertas que son incorrectas en tiempo y eventos, una simple reconfiguración de las reglas y la introducción de nodos de control adicionales.
Comprender el mantenimiento de los grupos de bases de datos utilizados.
Wiki muy hinchado . Ella "engordó" por los comentarios e instrucciones sobre cómo trabajar con entornos.
Tres chasis HP que compramos para una futura instalación.
Comprender el camino hacia el resto de 2019 en una aproximación más clara.
Ecosistema reciclado para trabajo de departamento.
Todos estos seis meses trabajé casi solo. Los empleados que heredaron eran más administradores del sistema. No estaban realmente ansiosos por profundizar en la esencia de DevOps.
Con gran dificultad, encontré dos especialistas en el equipo: junior y middle. Recopilé la cantidad máxima de conocimiento, apariencias y contraseñas de los administradores actuales y me separé de ellos con gran pesar.
Sistema de trabajo, entorno y herramientas.
Te contaré sobre la importancia de introducir un ecosistema y un entorno de trabajo. Ya mencioné a Trello, pero no dije por qué y por qué lo implementé. No se generará trabajo sin establecer objetivos y datos estructurados. Esto se evidencia parcialmente por el primer error: recoger todo lo que es.
Toma todo, no des nada.
El proceso es el motor del progreso . Por lo tanto, todo este tiempo trabajé en el sistema, a pesar de la obstrucción de la investigación y el flujo de trabajo. Gracias al sistema, seis meses después puse la locomotora de vapor del departamento en rieles estables.
La introducción de herramientas de soporte y un curso corto sobre su uso ahorra mucho tiempo para usted y sus colegas. Especialmente si incluso en la parte superior comprende la administración y es un poco capaz de mantener el orden en el escritorio y en la vida.
No complicamos las herramientas, pasamos de lo simple e introducimos lo necesario . A principios de año, pensé qué rastreador de tareas sería adecuado para nosotros. Inmediatamente despidió a Jira y Redmine, demasiado control. Pasaríamos tiempo completando los formularios, no las tareas. Hojas de cálculo de Google: creo que no vale la pena explicar por qué no.
Trello fue perfecto . Algunas columnas simples: "Backlog": donde se suman todos los errores o tareas notados para el futuro, "A la finalización": las principales tareas a realizar y "Finish". Un poco más tarde, había cinco columnas: "Backlog", "Pause", "Sprint", "Finish" y "Study".
En la "Pausa" se llevaron cosas que han perdido relevancia en el proceso de sprint. En "Aprendizaje": tareas que requieren investigación y que no deben perderse hasta el momento de comprender y transferir el conocimiento al Wiki. Sprint se ha convertido en evidencia de que hemos cambiado al sistema de sprint. Experimentamos y elegimos el momento óptimo: 2 semanas. Usamos este segmento ahora, pero otro le conviene.
El tiempo de sprint es individual para cada empresa .
Las reuniones semanales obligatorias son la próxima innovación después de Trello. Prácticamente no trabajamos en la oficina. El tiempo que podemos pasar en el camino, lo dedicamos al trabajo. Pero una vez a la semana, todo el departamento se reúne en la oficina durante 2-3 horas de manera intermitente y discute el curso del sprint y las tareas que surgieron. En consecuencia, además de una vez cada dos semanas, planeamos el próximo sprint.
Luego fue a implementar las herramientas mínimas necesarias. Todos los repositorios de servicios con configuraciones (Puppet, Nagios, DNS) se sacaron de SVN a GitLab nuevo. Engancharon a Jenkins a él. Ahora las configuraciones de DNS se actualizaron automáticamente, y las ediciones de los colegas de Puppet se podían leer a través de solicitudes de combinación de manera más fácil y conveniente. Anteriormente, las contraseñas se transmitían de persona a persona, ahora se recogen perfectamente en 1Password. Ahora esta es la única solución paga en la infraestructura.
Las herramientas fáciles de implementar y configurar generaron el proceso, y es más fácil de controlar.
Los problemas
En litros, el tráfico creció y se agregó trabajo: grupos defectuosos, piezas rotas de hierro, componentes. Se acercaba la segunda mitad del año, para lo cual se planificó el desarrollo de la escala.
En este momento, aparecieron dos bestsellers: un nuevo libro de un autor popular y un decreto del presidente de un país amigo sobre el bloqueo de litros. Vertió masivamente quejas sobre la inaccesibilidad del sitio. El decreto se emitió hace mucho tiempo, pero lo descubrimos solo cuando realmente comenzaron a bloquearnos en todo el amplio conjunto de direcciones. Afortunadamente, el decreto se refería a un solo nombre de dominio: "litres.ru".
El aumento del tráfico (todos querían un éxito de ventas) a través de servidores proxy, confundimos con un ataque DDoS y lo pagamos con divisas. Recuerdo cómo pagamos las facturas de una compañía que nos prometió protección contra DDoS. Inmediatamente después del pago, cambié el DNS a sus direcciones, y después de 10 minutos recordé el primer error y volví el DNS frenéticamente. No había tráfico de basura, pero había un precio de caballo para el tráfico que pasaba por ellos: libros, audio, portadas. No diré cuánto nos costó 20 minutos de vida en las direcciones de otras personas.
Esa noche llamé a Cloudflare y hablé sobre nuestros problemas. Anti-DDoS . , Cloudflare . . , DDoS' , .
. KPI.
KPI
. . , , .
KPI. — .
- . — .
- Downtime. — .
- . , --, , . , .
KPI, — . , , KPI, .
. 90%. , . — , . . , .
-Nagios -Puppet Zabbix Grafana Ansible. « ».
Prometheus , Zabbix. Zabbix, Prometheus — . — . .
, , .
. ,
, . — . , .
. - -, - . , . . . . .
, .
2 . 3 « », — . .
. : , , , Ansible, .
. , . . .
.
— , , . .
. — , .
. , . . 2019. , , , — . .
. .
.
, - , . .
- , , .
- , .
- , , — .
- , , , — , .
. , - . , , , .
.
— , , . , , .

, — - . , .
« , ». , — , , , .
, , .
—
Ansible? , , Puppet ? — .

CI/CD? , . CI/CD , — .
., , . - ? , KPI? , -.
- — , , .
.
:DevOpsConf . — , , . DevOps- HighLoad++ 2019 . DevOps 13 AWS, Lamoda, , Kubernetes, Kubernetes, Kubernetes . « » . HighLoad++ — , -. . — .