A veces sucede así:
- Ven, nos hemos caído. Si no lo subes ahora, se mostrará en la televisión.
Y nos vamos. En la noche Al otro lado del país.
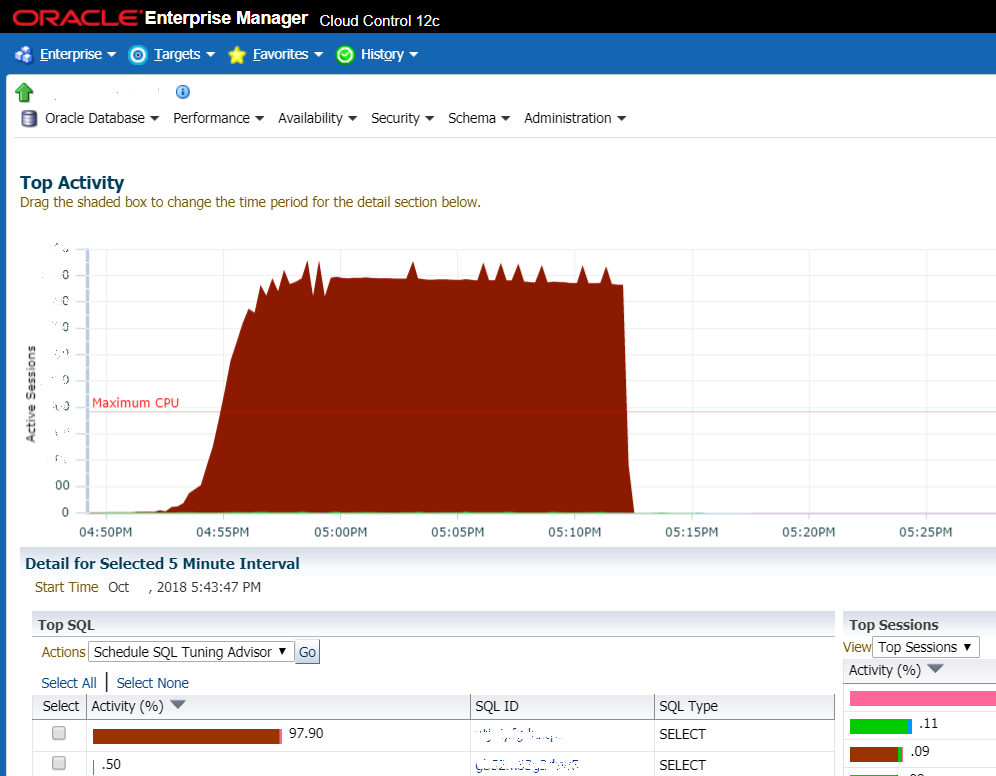 La situación cuando no hay suerte: el gráfico muestra un fuerte aumento de la carga en el DBMS. Muy a menudo, esto es lo primero que miran los administradores del sistema y esta es la primera señal de que ha llegado un asno
La situación cuando no hay suerte: el gráfico muestra un fuerte aumento de la carga en el DBMS. Muy a menudo, esto es lo primero que miran los administradores del sistema y esta es la primera señal de que ha llegado un asnoPero más a menudo estamos hablando de algunas cosas típicas. Por ejemplo, un cliente se enfrenta a un sistema de flujo de trabajo deficiente. Los lunes y martes, el sistema se bloqueó, reiniciaron el servidor y luego todo se encendió. La base de datos se estaba ahogando. Querían comprar equipo (que es largo y costoso), nos llamaron para calcular la estimación. Calculamos sus estimaciones y, al mismo tiempo, ofrecimos averiguar qué es exactamente lo que se ralentiza. En tres o cuatro horas, se localizó la fuente del problema. Descubrimos que estas son consultas lentas de bases de datos y esquemas de indexación subóptimos. Creamos los índices que faltan, hurgamos con el optimizador de consultas en Oracle, algunos problemas requirieron cambiar el código; cambiamos las condiciones de búsqueda (sin cambiar la funcionalidad), reemplazamos algunas de las solicitudes con el uso de vistas precalculadas. Si tuvieran una persona normal en la base de datos, podrían hacer lo mismo ellos mismos. Pero en lugar de una persona normal, la base de datos fue auditada una vez cada seis meses por geniales oracleistas: emitieron recomendaciones generales sobre configuraciones y hardware.
Como sucede
Los detalles se modifican un poco a pedido de seguridad. Existe un sistema de gestión de documentos en cientos de instalaciones industriales. A veces se cae y el trabajo sube. Es decir, los objetos pueden funcionar, pero no pasa un solo documento y no está firmado. Y esto, en particular, el envío de materias primas, salarios y pedidos, qué y cuánto producir por turno. Cada caída es un dolor, lágrimas, coñac para el CIO, porque es difícil para él: muchas pérdidas.
El director, por cierto, solo tiene seis meses en este lugar después del pasado. Y el año pasado duró. Y ambos trabajan en un sistema que el director introdujo hace tres generaciones. El segundo desde el final trató de presentar el suyo, pero no tuvo tiempo antes del despido. La situación es muy realista.
A primera vista, no hay suficiente rendimiento. El perfil de carga es bloqueos (Espere clase "Aplicación"). Es decir, competencia por las líneas. Comenzamos a investigar el incidente. Se abre una sesión para cada transacción de usuario. Rápidamente entra en un estado de bloqueo de una orden, de acuerdo con las tareas y las instrucciones de ejecución, ya que el usuario debe poner una visa "Familiar" como mínimo.
El último caso: elaboraron un nuevo estándar sobre la frecuencia con la que los empleados deben someterse a un examen médico. El oficial de personal de nivel superior escribió una orden y la envió a todas las organizaciones. Es decir, cada empleado de cada producción. Decenas de miles de usuarios recibieron transacciones de visa. Comenzaron a abrir órdenes casi simultáneamente, colocar una larga cadena de cerraduras en la base de datos. Debido a que no es el código más óptimo, como resultado se produjo un desbordamiento "pequeño" y todo se ahogó. Cerca de 40 mil usuarios no trabajan. Desde el esquema de respaldo: solo teléfonos y correo. La producción no se detiene, pero la eficiencia cae mucho, lo que causa pérdidas financieras específicas. Y luego las llamadas comienzan personalmente desde cada empresa al director de TI con un discurso. En la práctica, tienen un SLA, pero aún no hay acuerdo. Y la situación adquiere las características finales de la historia puramente rusa.
El problema de solución rápida se resolvió mediante la creación de perfiles, analizando la lógica de bloqueo de objetos, eliminando objetos innecesarios en los que se estableció el bloqueo, aunque no fue necesario porque el objeto no cambió (por ejemplo, directorios, derechos de acceso, etc.). Luego, en un par de meses, se refactorizaron las secciones principales del código.
¿Cómo se buscan estas secciones de código?
Además de las herramientas estándar (volcados de hilos, registros, métricas, AWR, datos de representaciones del sistema, etc.), utilizamos más herramientas civiles, incluidas las comerciales.
Ejemplo 1: registro de transacciones lentasSe han recibido quejas de los usuarios sobre el funcionamiento lento de la revista (un problema conocido y frecuente).
Encontramos la vista del problema, luego buscamos la solicitud en las operaciones para la vista deal_journal_view. Buscamos todas las transacciones donde hay una solicitud dentro.

Para cada una de las operaciones, puede ver sus detalles y encontrar la solicitud en sí con los parámetros de ejecución, lo que le permite analizar el funcionamiento de la solicitud, validar y ajustar el plan. Encontró una solicitud lenta específica.

Ellos mismos analizaron y propusieron opciones de optimización. Y solo entonces, para rastrear este grupo de operaciones comerciales (ver el registro de transacciones), cree un Tipo de transacción y configure alertas.
 Ejemplo 2: encontrar las razones para el trabajo lento del usuario 1
Ejemplo 2: encontrar las razones para el trabajo lento del usuario 1El usuario 1 recibió quejas sobre el funcionamiento lento de la aplicación. Buscamos:

Todas las operaciones del usuario fueron buscadas y ordenadas por duración. A continuación, se analizaron las operaciones más lentas y se detectaron consultas lentas al sistema externo (SAP).

Lo señaló al equipo adyacente, lo arregló.
Ejemplo 3: otro usuario se queja del funcionamiento lento de la aplicaciónNos vemos de la misma manera. Esta vez vemos una gran cantidad de llamadas a un servicio de firma externo. Resultó que, bajo ciertas condiciones, firmaron algunos documentos dos veces. Corregido
 Ejemplo 4: cuando no hay suficientes detalles
Ejemplo 4: cuando no hay suficientes detallesA veces, para analizar partes más complejas del código, recurrimos al uso de perfiladores personalizados, que nos permiten estudiar el comportamiento de la aplicación más profundamente. Por ejemplo, como aquí: mucha lógica incomprensible durante el funcionamiento de la lógica en el sistema. Descubrimos la lógica, agregamos un par de cachés, optimizamos las solicitudes.
 Ejemplo 5: más frenos
Ejemplo 5: más frenosEl usuario se quejó del trabajo lento con las tarjetas de contrato.

Se analizan las operaciones lentas del usuario (parámetro = 'userlogin = ”...”') durante una semana. La mayoría de los problemas fueron con consultas de búsqueda bajo contratos, pero también se encontraron operaciones con una tarjeta de documento. La mayor parte del tiempo se dedica a crear una gran cantidad de tareas en las tareas. Se encontraron identificadores (la columna Valor del parámetro en la captura de pantalla) de las tareas almacenadas y el tiempo de su guardado.
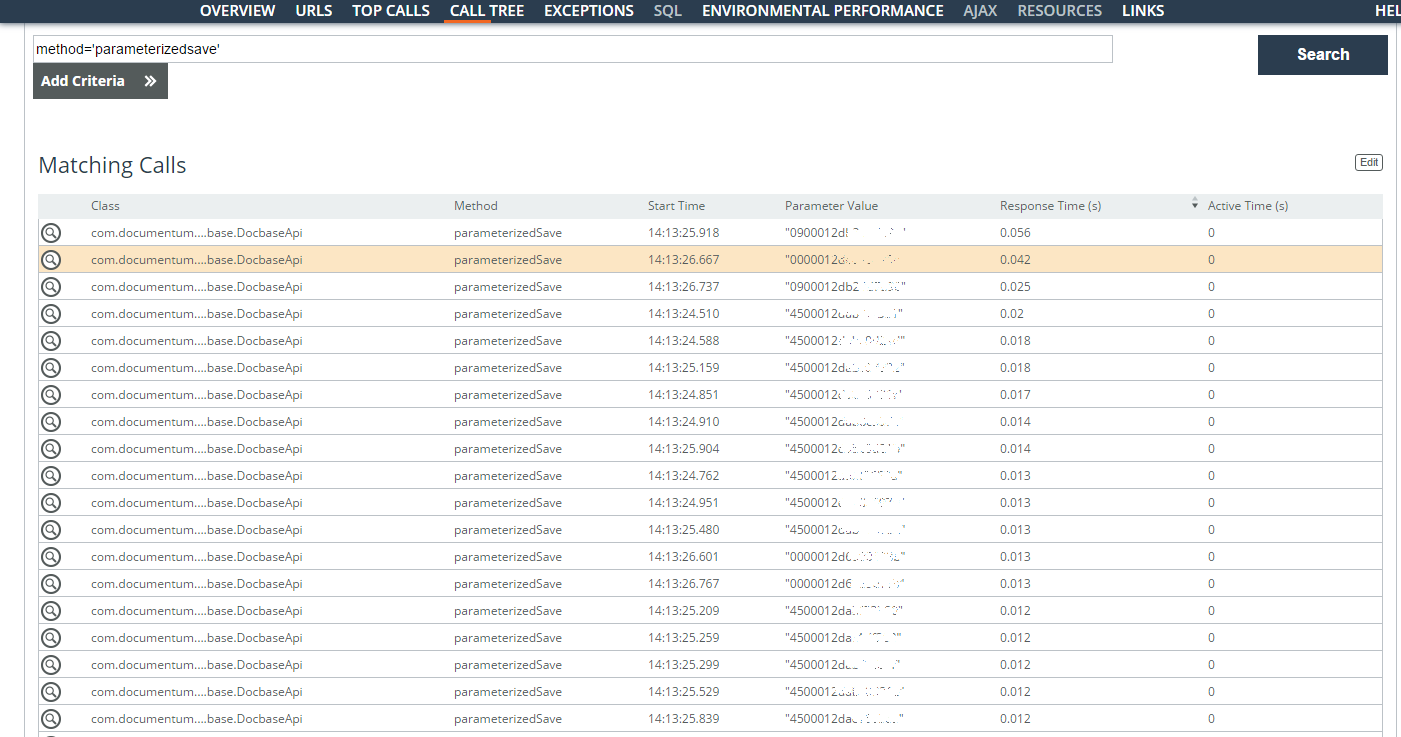
Lógicamente, cuando se pueden crear de forma asincrónica, pero ahora están en cola y requieren bloqueos excepcionales. Aquí ya necesita profundizar en la arquitectura.
Así de simple es: necesita encontrar un cuello de botella, ¿y eso es todo?
No
Y de nuevo, no.
Todo esto es un tratamiento para los síntomas.
Es correcto salvar rápidamente la situación, que ahora está en llamas. Y luego poner los procesos. Es raro que las personas que trabajan con un sistema no entiendan lo que están haciendo. Es solo que necesitan justificar los medios para reducir su deuda técnica (y nadie los cree), o cambiar los procesos a otros más modernos (para los cuales tampoco hay recursos), o hacer algo así.
En general, venimos del nivel superior y vemos dolor en el cliente. Entonces atrapamos el cuello de botella. A veces termina con la introducción de un sistema de monitoreo. Y si el cliente entiende que es necesario cambiar los procesos de desarrollo de software, entonces la etapa comienza "larga, costosa y ni siquiera increíble".
Observamos dos o tres proyectos, seleccionamos todos los documentos, repositorios, entrevistamos a personas. A continuación, preparamos plantillas para nuevos documentos, preparamos procedimientos, observamos herramientas para gestionar requisitos, pruebas. Y ayudamos a implementar. A veces es suficiente dar una opinión sobre qué cambiar, y el CIO alado con papel obtiene un presupuesto. A veces es necesario inyectar directamente sangre y lágrimas.
Cualquier cosa puede resultar dolorosa, desde la elección incorrecta de la arquitectura hasta algunas características del flujo de trabajo.
Estos ejemplos tratan sobre el juego en procesos en diferentes empresas de todo el país.
Con respecto a la optimización de la base de datos, aquí hay un ejemplo típico. Hay un sistema médico (uno de los que cayó). Nos llamaron para mirar. Llegamos cuando ya habían apagado todos los módulos, excepto el flujo de trabajo de los médicos, de modo que al menos de alguna manera los análisis irían y la grabación a través del registro sería. La grabación en línea, en particular, se encontraba entre los módulos deshabilitados. Logré arreglar todo en una semana. Inicialmente, el cliente pensó que los problemas estaban en la capa de la aplicación: hubo fallas de tiempo de espera y se colgaron los hilos. Descubrimos que el problema está en la base de datos. Había una estructura compleja, un montón de secciones por día y mes. Resultó que se olvidaron de un par de índices, los desarrolladores no sabían completamente en qué se convertiría con el tiempo, y aquí está el resultado. Aproximadamente el mismo conjunto de operaciones más restricciones de búsqueda (cuando necesite descargar algo en un rango de fechas, sería bueno buscar entre estas fechas y no en toda la base de datos).
Está claro que dicha optimización no siempre resuelve el problema. Por ejemplo, (por arquitectura) el sector energético: el cliente solicita ver con qué está colgando el sistema. Y allí todo voló al momento de la entrega, pero después de un par de años había muchos más documentos, y todo frenó muy bien. El cliente se sentó con un cronómetro en el lugar de trabajo del operador y dijo: esta operación ahora lleva 31 segundos, queremos 3. Este es de 40 segundos, queremos 2. Y así sucesivamente. Está claro que medir esto no es muy correcto, pero la tarea es bastante específica y puede presentarse fácilmente en forma de criterios objetivos. No hicimos todo, nos llevó unos seis meses "limpiar". En su mayor parte, la lógica se transfirió a la ejecución asincrónica, algunas de las bases de datos se cambiaron a noSQL, se instaló el motor de búsqueda Solar, en una sección fue necesario seleccionar la base de datos más actual y guardarla en la memoria. Como resultado, alrededor del 90% de las necesidades se cerraron, pero en algunos lugares no pudieron reducir los retrasos. Este es el trabajo de las bibliotecas de terceros, las limitaciones físicas de la plataforma, etc. Todo esto fue monitoreado por monitoreo y pudieron probar claramente exactamente dónde y qué se ralentiza.
¿Por qué otra razón podría ser necesaria esa supervisión?
Utilizamos diferentes programas de monitoreo para encontrar rápidamente procesos inhibitorios y optimizarlos. El equipo de TI de uno de los principales clientes analizó cómo lo hacemos y solicitó implementarlo en una de las instalaciones como una herramienta permanente. OK, monitoreé todos los procesos y nodos, personalicé su sistema para tareas, trabajé durante casi cuatro meses, pero creé un conjunto de herramientas para apoyarlos. Y hay 80 mil usuarios, hay la primera y segunda línea dentro y la tercera a menudo, con contratistas o también dentro.
En la segunda línea está solo este conjunto de herramientas. Ahora, en aproximadamente el 50% de los casos, utilizan el monitoreo para diagnosticar, buscar cuellos de botella y causas de congelamiento, para que sus propios desarrolladores puedan ver, comprender y optimizar. Se ahorra mucho tiempo de soporte al identificar rápidamente la causa del problema. Después del piloto escalado por transacción. Eso es lo que tomó cuatro meses: hay una operación comercial para cualquier acción. Abrir una tarjeta de documento es una transacción comercial. Iniciar sesión en un sistema de flujo de trabajo es una transacción comercial. Informe subir o buscar, también. Se describen 1.500 operaciones comerciales en cuatro meses para comprender dónde y qué funciona. El monitoreo antes de esto vio llamadas http y ve los métodos y funciones llamados, ve solicitudes específicas. Antes de esto, solo los desarrolladores entendían que se trataba de un acuerdo o búsqueda. Para que el sistema de monitoreo muestre datos relevantes para diferentes líneas de soporte y para negocios, hemos configurado todos estos paquetes.

El negocio también comenzó a recortar informes sobre su propio desarrollo de TI. Más sobre los registros que nadie elige especialmente.
Por cierto, sobre todo por qué se necesitan los sistemas de clase
APM y cómo elegirlos, hablaremos en un
seminario web el 1 de octubre .
¿Qué más hay "enchufes" desde el lado técnico?
Un par de ejemplos más. Un gran banco extranjero con oficinas de representación en Rusia. Apoyamos Oracle DB y Oracle Weblogic. Se observó una disminución gradual de la productividad en el sistema, las operaciones comerciales fueron más lentas, el trabajo del operador se hizo cada vez menos efectivo, y durante los períodos de importación y sincronización con el NSI todo se congeló por completo. En tales casos, utilizamos herramientas estándar de Java y Oracle para recopilar datos: recopilamos volcados de subprocesos, los analizamos en servicios gratuitos o utilizamos herramientas de análisis autoescritas, observamos AWR, rastreamos la ejecución de consultas SQL, analizamos planes y estadísticas de ejecución. Como resultado, además de las cosas estándar, como la optimización de la composición de los índices y el ajuste de los planes de consulta, propusimos introducir la partición dividiendo los datos. Resultó dos segmentos: histórico (los dejó en el HDD) y operacional, colocado en el SSD. Antes de esto, era bastante difícil entender qué datos se relacionaban con qué, porque los datos históricos aún tenían que descender regularmente, tanto en informes largos como en operaciones ordinarias. Como resultado de la separación correcta, más del 98% de las operaciones principales no entraron en datos históricos lentos. Lo que es importante, no hubo forma de ingresar al código del sistema. Sucede que algunas de nuestras recomendaciones requieren cambios en el código de la aplicación, que no es compatible con nosotros, por lo general, estamos de acuerdo.
El segundo ejemplo: un fabricante internacional en el campo de la industria ligera y el segmento de bienes de consumo en general. El tiempo de inactividad del sitio principal cuesta alrededor de 20 millones de rublos. La carga promedio en la base es de 200 AS (sesiones activas) con picos de hasta 800-1000. No es raro que un optimizador de consultas pierda la cabeza, los planes comienzan a flotar no para mejor y comienza la competencia salvaje por el caché del búfer. Nadie está a salvo de esto, pero puede reducir la probabilidad: durante dos meses monitoreamos el sistema, analizamos el perfil de carga, extinguimos incendios en el camino, ajustamos los esquemas de indexación y partición, lógica de procesamiento de datos desde el lado del código PL / SQL. Aquí debe comprender que en un sistema vivo y en desarrollo, dicha auditoría debe llevarse a cabo regularmente, aunque las pruebas de estrés ayudan, pero no siempre. Y las empresas realizan una auditoría invitando a oracleistas de terceros, pero rara vez alguna de ellas cae al nivel de la lógica empresarial y están listas para profundizar en los datos, interactuando con los desarrolladores. Lo hacemos
Bueno, quiero decir que el problema no siempre es la falta de limpieza regular o el soporte adecuado. A menudo los problemas están en los procesos.
¿Por qué necesitamos tales servicios con sus desarrolladores en vivo?
Porque las empresas aman las decisiones, no los procesos. Esta es la razón principal.
La segunda es que no todos pueden asignar recursos para buscar un cuello de botella en una aplicación, especialmente si se trata de una aplicación de terceros. Y lejos de estar siempre en un equipo, hay personas con las competencias necesarias. En este momento tenemos un ingeniero de sistemas, ingenieros de redes, especialistas en Oracle y 1C, personas capaces de optimizar Java y la interfaz de nuestro equipo.
Bueno, si está interesado en sumergirse en los detalles,
el 1 de octubre habrá nuestro seminario web sobre lo que puede hacer por adelantado, antes de que todo caiga. Y aquí está mi correo para preguntas: sstrelkov@croc.ru.