No hay necesidad de representar específicamente la base FIAS:

Puede descargarlo haciendo clic en el
enlace , esta base de datos está abierta y contiene todas las direcciones de objetos en Rusia (registro de direcciones). El interés en esta base de datos se debe al hecho de que los archivos que contiene son bastante voluminosos. Entonces, por ejemplo, el más pequeño es 2.9 GB. Se propone detenerse en él y ver si los pandas pueden manejarlo si trabaja en una máquina con solo 8 GB de RAM. Y si no puede hacer frente, ¿cuáles son las opciones para alimentar a los pandas con este archivo?
Mano a corazón, nunca he encontrado esta base y este es un obstáculo adicional, porque El formato de los datos presentados en él es completamente confuso.
Después de descargar el archivo fias_xml.rar con la base, obtenemos el archivo de él: AS_ADDROBJ_20190915_9b13b2a6-b3bd-4866-bd1c-7ab966fafcf0.XML. El archivo está en formato xml.
Para un trabajo más conveniente en pandas, se recomienda convertir xml a csv o json.
Sin embargo, todos los intentos de convertir programas de terceros y Python en sí mismo conducen a un error o congelación "MemoryError".
Hm. ¿Qué pasa si corto el archivo y lo convierto en partes? Una buena idea, pero todos los "cortadores" también intentan leer todo el archivo en la memoria y se cuelgan, el propio Python, que sigue el camino de los "cortadores", no lo corta. ¿8 GB obviamente no es suficiente? Bueno, veamos.
Programa Vedit
Deberá utilizar un programa vedit de terceros.
Este programa le permite leer un archivo xml de 2.9 GB y trabajar con él.
También te permite dividirlo. Pero hay un pequeño truco.
Como puede ver al leer un archivo, tiene, entre otras cosas, una etiqueta de apertura de AddressObjects:

Por lo tanto, al crear partes de este archivo grande, no debe olvidar cerrarlo (etiqueta).
Es decir, el comienzo de cada archivo xml será así:
<?xml version="1.0" encoding="utf-8"?><AddressObjects>
y terminando:
</AddressObjects>
Ahora corte la primera parte del archivo (para las partes restantes, los pasos son los mismos).
En el programa vedit:
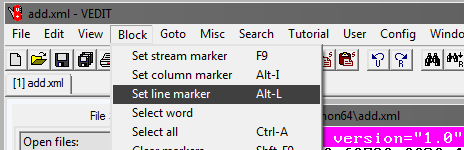
Luego, seleccione Ir a y Línea #. En la ventana que se abre, escriba el número de línea, por ejemplo, 1,000,000:

A continuación, debe ajustar el bloque seleccionado para que capture hasta el final el objeto en la base de datos antes de la etiqueta de cierre:
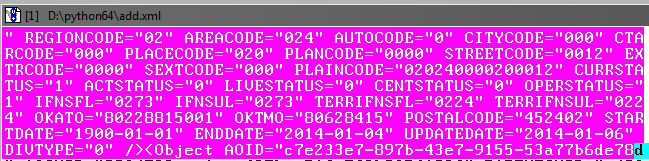
Está bien si hay una ligera superposición en el objeto posterior.
A continuación, en el programa vedit, guarde el fragmento seleccionado: Archivo, Guardar como.
De la misma manera, creamos las partes restantes del archivo, marcando el comienzo del bloque de selección y el final en incrementos de 1 millón de líneas.
Como resultado, debe obtener el cuarto archivo xml con un tamaño de aproximadamente 610 MB.
Finalizamos las partes xml
Ahora debe agregar etiquetas en los archivos xml recién creados para que se lean como xml.
Abra los archivos en vedit uno por uno y agregue al principio de cada archivo:
<?xml version="1.0" encoding="utf-8"?><AddressObjects>
y al final:
</AddressObjects>
Por lo tanto, ahora tenemos 4 partes xml del archivo fuente dividido.
Xml a csv
Ahora traduzca xml a csv escribiendo un programa python.
Código del programa
.
Con el programa, debe convertir los 4 archivos a csv.
El tamaño del archivo disminuirá, cada uno será de 236 MB (en comparación con 610 MB en xml).
En principio, ahora ya puede trabajar con ellos, a través de Excel o Notepad ++.
Sin embargo, los archivos siguen siendo 4º en lugar de uno, y no hemos alcanzado el objetivo: procesar el archivo en pandas.
Pegar archivos en uno
En Windows, esto puede resultar una tarea difícil, por lo que utilizaremos la utilidad de consola en Python llamada csvkit. Instalado como un módulo de Python:
pip install csvkit
* En realidad, este es un conjunto completo de utilidades, pero se necesitará una a partir de ahí.
Habiendo ingresado a la carpeta con archivos para pegar en la consola, realizaremos el pegado en un archivo. Como todos los archivos no tienen encabezados, asignaremos los nombres de columna estándar al pegar: a, b, c, etc .:
csvstack -H fias-0-10.csv fias-10-20.csv fias-20-30.csv fias-30-40.csv > joined2.csv
El resultado es un archivo csv terminado.
Trabajemos en pandas para optimizar el uso de memoria
Si carga inmediatamente el archivo a pandas
import pandas as pd import numpy as np gl = pd.read_csv('joined2.csv',encoding='ANSI',index_col='a') print (gl.info(memory_usage='deep'))
y verifique cuánta memoria tomará, el resultado puede sorprender desagradablemente:

3 GB! Y esto a pesar del hecho de que al leer los datos, la primera columna "fue" como una columna de índice *, por lo que el volumen sería aún mayor.
* Por defecto, pandas establece su propio índice de columna.
Realizaremos la optimización utilizando los métodos de la
publicación y el
artículo anteriores :
- objeto en la categoría;
- int64 en uint8;
- float64 en float32.
Para hacer esto, al leer el archivo, agregue dtypes y leer las columnas en el código se verá así:
gl = pd.read_csv('joined2.csv',encoding='ANSI',index_col='a', dtype ={ 'b':'category', 'c':'category','d':'category','e':'category', 'f':'category','g':'category', 'h':'uint8','i':'uint8','j':'uint8', 'k':'uint8','l':'uint8','m':'uint8','n':'uint16', 'o':'uint8','p':'uint8','q':'uint8','t':'uint8', 'u':'uint8','v':'uint8','w':'uint8','x':'uint8', 'r':'float32','s':'float32', 'y':'float32','z':'float32','aa':'float32','bb':'float32', 'cc':'float32' })
Ahora, al abrir el archivo pandas, el uso de memoria sería prudente:

Queda por agregar al archivo csv, si lo desea, los nombres de columna de fila real para que los datos tengan sentido:
AOID,AOGUID,PARENTGUID,PREVID,FORMALNAME,OFFNAME,SHORTNAME,AOLEVEL,REGIONCODE,AREACODE,AUTOCODE,CITYCODE,CTARCODE,PLACECODE,STREETCODE,EXTRCODE,SEXTCODE,PLAINCODE,CODE,CURRSTATUS,ACTSTATUS,LIVESTATUS,CENTSTATUS,OPERSTATUS,IFNSFL,IFNSUL,OKATO,OKTMO,POSTALCODE
* Puede reemplazar los nombres de columna con esta línea, pero luego debe cambiar el código.
Guarde las primeras líneas del archivo de pandas
gl.head().to_csv('out.csv', encoding='ANSI',index_label='a')
y mira lo que pasó en excel:

Código de programa para la apertura optimizada de un archivo csv con una base de datos:
codigo import os import time import pandas as pd import numpy as np # : object-category, float64-float32, int64-int gl = pd.read_csv('joined2.csv',encoding='ANSI',index_col='a', dtype ={ 'b':'category', 'c':'category','d':'category','e':'category', 'f':'category','g':'category', 'h':'uint8','i':'uint8','j':'uint8', 'k':'uint8','l':'uint8','m':'uint8','n':'uint16', 'o':'uint8','p':'uint8','q':'uint8','t':'uint8', 'u':'uint8','v':'uint8','w':'uint8','x':'uint8', 'r':'float32','s':'float32', 'y':'float32','z':'float32','aa':'float32','bb':'float32', 'cc':'float32' }) pd.set_option('display.notebook_repr_html', False) pd.set_option('display.max_columns', 8) pd.set_option('display.max_rows', 10) pd.set_option('display.width', 80) #print (gl.head()) print (gl.info(memory_usage='deep')) # def mem_usage(pandas_obj): if isinstance(pandas_obj,pd.DataFrame): usage_b = pandas_obj.memory_usage(deep=True).sum() else: # , , usage_b = pandas_obj.memory_usage(deep=True) usage_mb = usage_b / 1024 ** 2 # return "{:03.2f} " .format(usage_mb)
En conclusión, veamos el tamaño del conjunto de datos:
gl.shape
(3348644, 28)
3,3 millones de filas, 28 columnas.
En pocas palabras: con un tamaño de archivo csv inicial de 890 MB, "optimizado" para trabajar con pandas, ocupa 1,2 GB de memoria.
Por lo tanto, con un cálculo aproximado, se puede suponer que un archivo de 7,69 GB de tamaño se puede abrir en pandas, habiéndolo "optimizado" previamente.