¿Qué es el reconocimiento de voz End2End y por qué es necesario? ¿Cuál es su diferencia con el enfoque clásico? Y por qué, para entrenar un buen modelo basado en End2End, necesitamos una gran cantidad de datos, en nuestra publicación de hoy.
El enfoque clásico para el reconocimiento de voz.
Antes de hablar sobre el enfoque End2End, primero debe hablar sobre el enfoque clásico para el reconocimiento de voz. ¿Cómo es él?

Extracción de características
De hecho, esta no es una secuencia completamente lineal de bloques de acción. Detengámonos en cada bloque con más detalle. Tenemos algún tipo de discurso de entrada, cae en el primer bloque: extracción de características. Este es un bloqueo que extrae signos del habla. Hay que tener en cuenta que el discurso en sí es algo bastante complicado. Debe poder trabajar con él de alguna manera, por lo que existen métodos estándar para aislar características de la teoría del procesamiento de señales. Por ejemplo, coeficientes Mel-cepstrales (MFCC), etc.
Modelo acústico
El siguiente componente es el modelo acústico. Se puede basar en redes neuronales profundas o en mezclas de distribuciones gaussianas y modelos ocultos de Markov. Su objetivo principal es obtener de una sección de la señal acústica las distribuciones de probabilidad de varios fonemas en esta sección.
Luego viene el decodificador, que busca la ruta más probable en el gráfico en función del resultado del último paso. Restaurar es el toque final en reconocimiento, cuya tarea principal es volver a sopesar las hipótesis y producir el resultado final.
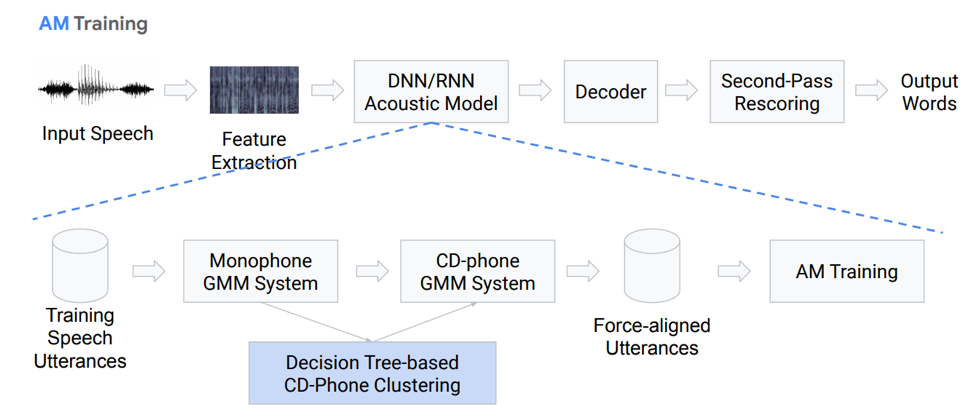
Detengámonos con más detalle en el modelo acústico. Como es ella Tenemos algunas grabaciones de voz que entran en un determinado sistema basado en GMM (mezcla de gausovy monoaural) o HMM. Es decir, tenemos representaciones en forma de fonemas, utilizamos monófonos, es decir, fonemas independientes del contexto. Más allá de esto, hacemos mezclas de distribuciones gaussianas basadas en fonemas sensibles al contexto. Utiliza clustering basado en árboles de decisión.
Luego tratamos de construir la alineación. Tal método completamente no trivial nos permite obtener un modelo acústico. No suena muy simple, de hecho es aún más complicado, hay muchos matices, características. Pero como resultado, un modelo entrenado en cientos de horas es muy capaz de simular acústica.

Decodificador
¿Qué es un decodificador? Este es el módulo que selecciona la ruta de transición más probable de acuerdo con el gráfico HCLG, que consta de 4 partes:
Módulo H basado en HMM
Módulo de dependencia de contexto C
Módulo de pronunciación L
Módulo de modelo de lenguaje G
Construimos un gráfico sobre estos cuatro componentes, en base al cual decodificaremos nuestras características acústicas en ciertas construcciones verbales.
Más o menos, está claro que el enfoque clásico es bastante engorroso y difícil, es difícil de entrenar, ya que consta de una gran cantidad de partes separadas, para cada una de las cuales necesita preparar sus propios datos para el entrenamiento.
II Enfoque End2End
Entonces, ¿qué es el reconocimiento de voz End2End y por qué es necesario? Este es un cierto sistema, que está diseñado para reflejar directamente la secuencia de signos acústicos en la secuencia de grafemas (letras) o palabras. También puede decir que este es un sistema que optimiza los criterios que afectan directamente la métrica final de evaluación de calidad. Por ejemplo, nuestra tarea es específicamente la tasa de error de palabras. Como dije, solo hay una motivación: presentar estos componentes complejos de múltiples etapas como un componente simple que mostrará directamente, generará palabras o grafemas a partir del discurso de entrada.
Problema de simulación
Aquí tenemos un problema de inmediato: el discurso sonoro es una secuencia, y en la salida también necesitamos dar una secuencia. Y hasta 2006, no había una forma adecuada de modelar esto. ¿Cuál es el problema del modelado? Era necesario que cada registro creara un marcado complejo, lo que implica en qué segundo pronunciamos un sonido o letra en particular. Este es un diseño complejo muy engorroso y, por lo tanto, no se han realizado una gran cantidad de estudios sobre este tema. En 2006, se publicó un interesante artículo de Alex Graves "Clasificación temporal conexionista" (CTC), en el que este problema se resuelve, en principio. Pero el artículo fue publicado, y no había suficiente potencia informática en ese momento. Y los algoritmos reales de reconocimiento de voz en funcionamiento aparecieron mucho más tarde.
En total, tenemos: el algoritmo CTC fue propuesto por Alex Graves hace trece años, como una herramienta que le permite entrenar / entrenar modelos acústicos sin la necesidad de este marcado complejo: alineación de los cuadros de secuencia de entrada y salida. Con base en este algoritmo, inicialmente apareció un trabajo que no fue completo end2end; como resultado se emitieron fonemas. Vale la pena señalar que los fonemas sensibles al contexto basados en STS logran uno de los mejores resultados en el reconocimiento de la libertad de expresión. Pero también vale la pena señalar que este algoritmo, aplicado directamente a las palabras, se queda atrás en este momento.

¿Qué es STS?
Ahora hablaremos un poco más en detalle sobre qué es el STS y por qué es necesario, qué función realiza. STS es necesario para entrenar el modelo acústico sin la necesidad de una alineación cuadro por cuadro entre el sonido y la transcripción. La alineación cuadro por cuadro es cuando decimos que un cuadro particular de un sonido corresponde a dicho cuadro de la transcripción. Tenemos un codificador convencional que acepta signos acústicos como entrada; proporciona algún tipo de ocultación del estado, en base al cual obtenemos probabilidades condicionales usando softmax. El codificador generalmente consta de varias capas de LSTM u otras variaciones de RNN. Vale la pena señalar que STS funciona además de los caracteres ordinarios con un carácter especial llamado carácter vacío o un símbolo en blanco. Para resolver el problema que surge debido al hecho de que no todos los cuadros acústicos tienen un cuadro en transcripción y viceversa (es decir, tenemos letras o sonidos que suenan mucho más tiempo y hay sonidos cortos, sonidos repetitivos), y allí Este símbolo en blanco.
El STS en sí está destinado a maximizar la probabilidad final de secuencias de caracteres y a generalizar la posible alineación. Dado que queremos usar este algoritmo en redes neuronales, se entiende que debemos entender cómo funcionan sus modos de operación hacia adelante y hacia atrás. No nos detendremos en la justificación matemática y las características del funcionamiento de este algoritmo, de lo contrario, llevará mucho tiempo.
Qué tenemos: el primer ASR basado en el algoritmo STS aparece en 2014. Nuevamente, Alex Graves presentó una publicación basada en el STS carácter por carácter que muestra directamente el discurso de entrada en una secuencia de palabras. Uno de los comentarios que hicieron en este artículo es que usar un modelo de sonido externo es importante para obtener un buen resultado.
5 formas de mejorar el algoritmo
Hay muchas variaciones y mejoras diferentes al algoritmo anterior. Aquí están, por ejemplo, los cinco más populares recientemente.
• El modelo de idioma se incluye en la decodificación durante la primera pasada.
o [Hannun et al., 2014] [Maas et al., 2015]: decodificación directa de primer paso con un LM en lugar de restaurar como en [Graves & Jaitly, 2014]
o [Miao et al., 2015]: marco EESEN para decodificar con WFST, kit de herramientas de código abierto
• Entrenamiento a gran escala en la GPU; Aumento de datos varios idiomas
o [Hannun et al., 2014; DeepSpeech] [Amodei et al., 2015; DeepSpeech2]: entrenamiento de GPU a gran escala; Aumento de datos; Mandarín e inglés
• Uso de unidades largas: palabras en lugar de caracteres.
o [Soltau et al., 2017]: objetivos CTC a nivel de palabra, capacitados en 125,000 horas de discurso. ¡Rendimiento cercano o mejor que un sistema convencional, incluso sin usar un LM!
o [Audhkhasi et al., 2017]: Modelos directos de acústica a palabra en la centralita
Vale la pena prestar atención a la implementación de DeepSpeach como un buen ejemplo de una solución CTC end2end y a una variación que utiliza un nivel verbal. Pero hay una advertencia: para entrenar un modelo de este tipo, necesita 125 mil horas de datos etiquetados, lo que en realidad es bastante en realidades duras.
Lo que es importante tener en cuenta sobre STS
- Problemas u omisiones. Para mayor eficiencia, es importante hacer suposiciones sobre la independencia. Es decir, el STS supone que la salida de la red en diferentes tramas es condicionalmente independiente, lo que en realidad es incorrecto. Pero esta suposición se hace para simplificar, sin ella, todo se vuelve mucho más complicado.
- Para lograr un buen rendimiento del modelo STS, se requiere el uso de un modelo de lenguaje externo, ya que la decodificación codiciosa directa no funciona muy bien.
Atencion
¿Qué alternativa tenemos para este STS? Probablemente no sea ningún secreto para nadie que exista algo como Atención o "Atención", que revolucionó hasta cierto punto y pasó directamente de las tareas de traducción automática. Y ahora, la mayoría de las decisiones de modelado de secuencia de secuencia se basan en este mecanismo. ¿Cómo es él? Tratemos de resolverlo. Por primera vez sobre Atención en tareas de reconocimiento de voz, las publicaciones aparecieron en 2015. Alguien Chen y Cherowski emitieron dos publicaciones similares y diferentes al mismo tiempo.
Detengámonos en el primero: se llama Escuchar, asistir y deletrear. En nuestra simulación clásica, en la secuencia donde tenemos un codificador y decodificador, se agrega otro elemento, que se llama atención. El ecualizador realizará las funciones que el modelo acústico solía realizar. Su tarea es convertir el discurso de entrada en características acústicas de alto nivel. Nuestro decodificador realizará las tareas que previamente realizamos con el modelo de lenguaje y el modelo de pronunciación (léxico), y pronosticará automáticamente cada token de salida, en función de los anteriores. Y la atención misma dirá directamente qué marco de entrada es más relevante / importante para predecir esta salida.
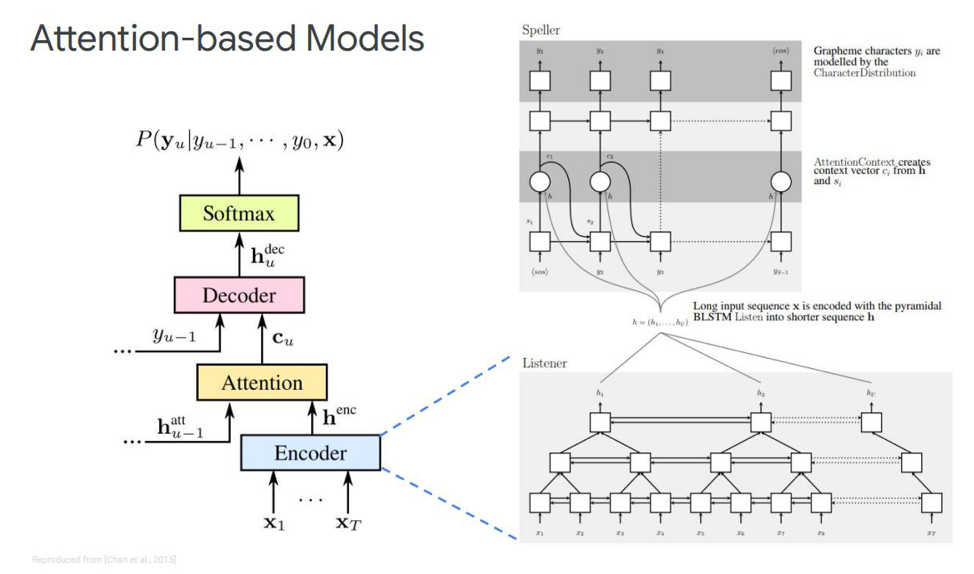
¿Qué son estos bloques? El codificador ecológico del artículo se describe como un oyente, es un RNN bidireccional clásico basado en LSTM u otra cosa. En general, nada nuevo: el sistema simplemente simula la secuencia de entrada en características complejas.
La atención, por otro lado, crea un determinado vector de contexto C a partir de estos vectores, que ayudará a decodificar el decodificador correctamente directamente, el decodificador en sí, que es, por ejemplo, también algunos LSTM que se decodificarán en la secuencia de entrada desde esta capa de atención, que ya ha resaltado los signos de estado más importantes, alguna secuencia de salida de caracteres.
También hay diferentes representaciones de esta Atención misma, que es la diferencia entre estas dos publicaciones emitidas por Chen y Charowski. Usan diferente atención. Chen usa la atención de productos de punto, y Charowski usa la atención aditiva.

¿A dónde ir después?
Este es un plus o menos de todos los logros importantes recibidos hasta la fecha en materia de reconocimiento de voz no en línea. ¿Qué mejoras son posibles aquí? ¿A dónde ir después? Lo más obvio es el uso de un modelo en palabras en lugar de usar grafemas directamente. Pueden ser algunos morfemas separados u otra cosa.
¿Cuál es la motivación para usar cortes de palabras? Típicamente, los modelos de lenguaje del nivel verbal tienen mucha menos perplejidad en comparación con el nivel de grafema. Modelar piezas de palabras le permite construir un decodificador más fuerte del modelo de lenguaje. Y modelar elementos más largos puede mejorar la eficiencia de la memoria en un decodificador basado en LSTM. También le permite recordar potencialmente la aparición de palabras de frecuencia. Los elementos más largos permiten la decodificación en menos pasos, lo que acelera directamente la inferencia de este modelo.
Además, el modelo sobre piezas de palabras nos permite resolver el problema de las palabras OOV (fuera del vocabulario) que surgen en el modelo de lenguaje, ya que podemos modelar cualquier palabra usando piezas de palabras. Y vale la pena señalar que tales modelos están entrenados para maximizar la probabilidad de un modelo de lenguaje sobre un conjunto de datos de entrenamiento. Estos modelos dependen de la posición, y podemos usar el algoritmo codicioso para la decodificación.
¿Qué otras mejoras además del modelo de palabras pueden ser? Hay un mecanismo llamado atención de múltiples cabezas. Se describió por primera vez en 2017 para la traducción automática. La atención de múltiples cabezas implica un mecanismo que tiene varias llamadas cabezas que le permiten generar una distribución diferente de esta misma atención, lo que mejora los resultados directamente.
Modelos en línea
Pasamos a la parte más interesante: estos son modelos en línea. Es importante tener en cuenta que LAS no está transmitiendo. Es decir, este modelo no puede funcionar en modo de decodificación en línea. Consideraremos los dos modelos en línea más populares hasta la fecha. Transductor RNN y Transductor Neural.
El transductor RNN fue propuesto por Graves en 2012-2017. La idea principal es complicar un poco nuestro modelo STS con la ayuda de un modelo recursivo.
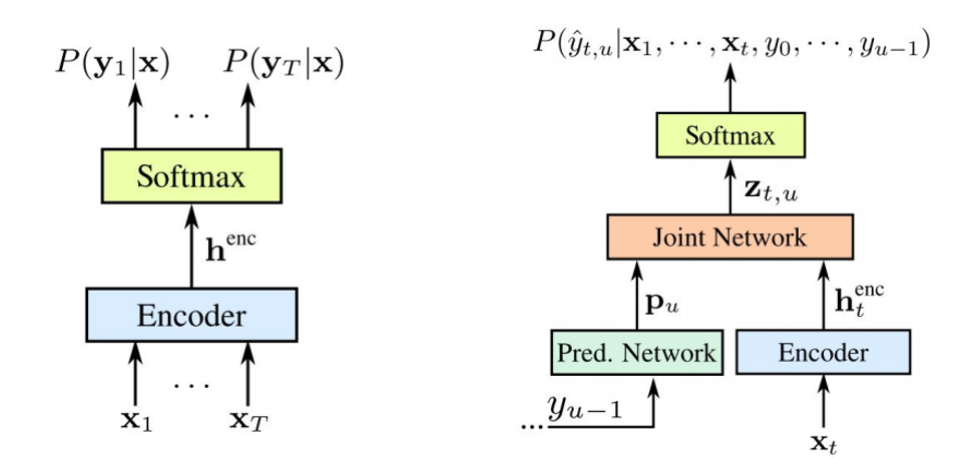
Vale la pena señalar que ambos componentes se entrenan juntos en los datos acústicos disponibles. Al igual que STS, este enfoque no requiere alineación de trama en el conjunto de datos de entrenamiento. Como vemos en la imagen: a la izquierda está nuestro STS clásico, y a la derecha está el Transductor RNN. Y tenemos dos elementos nuevos: la
red prevista y la
red de unión .
El codificador STS es exactamente el mismo: este es el nivel de entrada RNN, que determina la distribución en todas las alineaciones con todas las secuencias de salida que no exceden la longitud de la secuencia de entrada; esto fue descrito por Graves en 2006. Sin embargo, la tarea de tales conversiones de texto a voz también se excluye, donde la secuencia de entrada más larga que la secuencia de entrada del STS no modela la relación entre las salidas. El transductor expande este mismo STS, determinando la distribución de las secuencias de salida de todas las longitudes y modelando conjuntamente la dependencia de la entrada-salida y la salida-salida.
Resulta que nuestro modelo es capaz de manejar las dependencias de la salida de la entrada y la salida de la salida del último paso.
Entonces, ¿qué es una
red pronosticada o una red predictiva? Ella trata de simular cada elemento teniendo en cuenta los anteriores, por lo tanto, es similar al RNN estándar con el pronóstico del siguiente paso. Solo con la capacidad adicional de hacer hipótesis nulas.
Como vemos en la imagen, tenemos una red pronosticada, que recibe el valor anterior de la salida, y hay un codificador, que recibe el valor actual de la entrada. Y a la salida nuevamente, tal tiene el valor actual
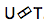
.
Transductor Neural . Esta es una complicación del enfoque clásico seq-2seq. El codificador procesa la secuencia acústica de entrada para crear vectores de estado ocultos en cada paso de tiempo. Todo parece ser como siempre. Pero hay un elemento Transductor adicional que recibe un bloque de entrada en cada paso y genera hasta tokens de salida M utilizando el modelo basado en seq-2seq sobre esta entrada. El transductor mantiene su estado en bloques mediante el uso de conexiones periódicas con los pasos de tiempo anteriores.
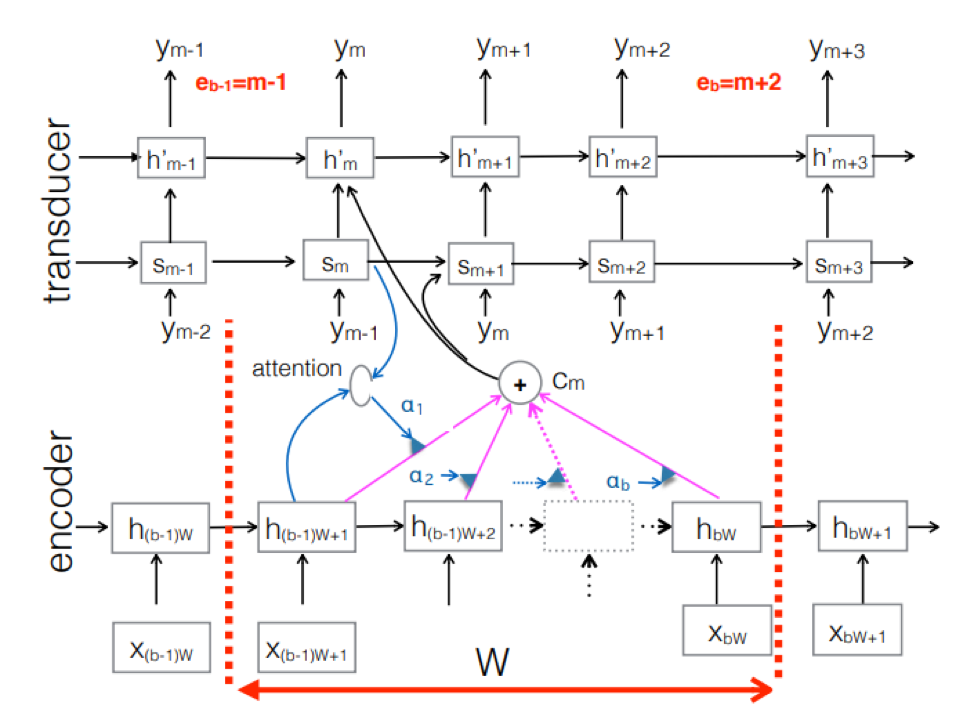 La figura muestra el Transductor, produciendo tokens para el bloque para la secuencia utilizada en el bloque del Ym correspondiente.
La figura muestra el Transductor, produciendo tokens para el bloque para la secuencia utilizada en el bloque del Ym correspondiente.Entonces, examinamos el estado actual del reconocimiento de voz basado en el enfoque End2End. Vale la pena decir que, desafortunadamente, estos enfoques requieren hoy una gran cantidad de datos. Y los resultados reales que se logran con el enfoque clásico, que requieren de 200 a 500 horas de grabaciones de sonido marcadas para entrenar un buen modelo basado en End2End, requerirán varios, o tal vez decenas de veces más datos. Ahora este es el mayor problema con estos enfoques. Pero quizás pronto todo cambie.
Desarrollador líder del centro AI MTS Nikita Semenov.