La información sobre el tema de la arquitectura de aplicaciones de microservicios, que ya ha logrado llenar su ventaja, es suficiente hoy para decidir si se adapta a su producto o no. Y no es un secreto en absoluto que las empresas que han decidido elegir este camino tienen que enfrentar muchos desafíos de ingeniería y culturales. Una de las fuentes de problemas es la sobrecarga que se multiplica en todas partes, y esto se aplica igualmente a la rutina asociada con los procesos de producción.

Fuente de imagen:
Como se puede adivinar, el antiplagio es solo una empresa de este tipo, donde gradualmente se llegó a la comprensión de que estamos con microservicios en el camino. Pero antes de comenzar a comer el cactus, decidimos limpiarlo y cocinarlo. Y dado que las únicas soluciones verdaderas y correctas para cada una son únicas, en lugar de las diapositivas universales de DevOps con hermosas flechas, decidimos compartir nuestra propia experiencia y contar cómo ya hemos cubierto una parte considerable de nuestro camino especial hacia, espero, el éxito.
Si está haciendo un producto verdaderamente único, que consiste en gran medida en conocimientos, casi no hay posibilidad de eludir este camino especial, porque está formado por muchos privados: a partir de la cultura y los datos históricos que se han desarrollado en la empresa, terminando con su propia especificidad y la pila tecnológica utilizada .
Una de las tareas para cualquier empresa y equipo es encontrar el equilibrio óptimo entre las libertades y las reglas, y los microservicios llevan este problema a un nuevo nivel. Esto puede parecer contradecir la idea misma de los microservicios, lo que implica una amplia libertad en la elección de tecnologías, pero si no se enfoca directamente en cuestiones arquitectónicas y tecnológicas, pero mira los problemas de producción en su conjunto, entonces el riesgo de estar en algún lugar de la trama del "Jardín de las Delicias" es bastante tangible. .
Sin embargo, en el libro "Creación de microservicios", Sam Newman ofrece una solución a este problema, donde literalmente desde las primeras páginas habla de la necesidad de limitar la creatividad de los equipos en el marco de acuerdos técnicos. Por lo tanto, una de las claves del éxito, especialmente en el contexto de un recurso limitado de manos libres, es la estandarización de todo lo que solo se puede negociar y que a nadie realmente le gustaría hacer todo el tiempo. Al elaborar acuerdos, creamos reglas claras del juego para todos los participantes en la producción y operación de componentes del sistema. Y conociendo las reglas del juego, debes aceptar que jugarlo debería ser más fácil e incluso más agradable. Sin embargo, seguir estas reglas en sí mismas puede convertirse en una rutina y causar incomodidad a los participantes, lo que conduce directamente a todo tipo de desviaciones de ellos y, como consecuencia, al fracaso de toda la idea. Y la salida más obvia es incluir todos los acuerdos en el código, porque ninguna regulación puede hacer lo que la automatización y las herramientas convenientes pueden usar, cuyo uso es intuitivo y natural.
Moviéndonos en esta dirección, pudimos automatizar más y más, y cuanto más fuerte fue nuestro proceso, se convirtió en un transportador de extremo a extremo para la producción de bibliotecas y micro servicios (o no).
Descargo de responsabilidadEste texto no es un intento de indicar "como debería", no hay soluciones universales, solo una descripción de nuestra posición en el camino evolutivo y la dirección elegida. Todo lo anterior puede no ser adecuado para todos, pero en nuestro caso tiene sentido en gran medida porque:
- El desarrollo en la empresa en el 90% de los casos se realiza en C #;
- No había necesidad de comenzar desde cero, como parte de los estándares, enfoques y tecnologías aceptados: este es el resultado de la experiencia o simplemente un legado histórico;
- Repositorios con proyectos .NET, a diferencia de los equipos, docenas (y habrá más);
- Nos gusta usar una canalización de CI muy simple, evitando el bloqueo de proveedores tanto como sea posible;
- Para un desarrollador ordinario de .NET, las palabras "contenedor", "docker" y "Linux" pueden causar episodios de horror existencial leve, pero no quiero romper a nadie.
Un poco de historia
En la primavera de 2017, Microsoft presentó al mundo una vista previa de .NET Core 2.0, y este año los astrólogos de C # se apresuraron a declarar Linux Year, así que ...

Fuente de imagen:
Durante un tiempo, nosotros, sin confiar en la magia, recopilamos y probamos todo, tanto en Windows como en Linux, publicamos artefactos con algunos scripts SSH, tratamos de configurar viejas canalizaciones de CI / CD en el modo cuchillo suizo. Pero después de un tiempo se dieron cuenta de que estábamos haciendo algo mal. Además, las referencias a microservicios y contenedores sonaban cada vez más a menudo. Así que también decidimos montar la ola de bombo y explorar estas direcciones.
Ya en la etapa de reflexión sobre nuestro posible futuro de microservicio, surgieron una serie de preguntas, ignorando las cuales, arriesgamos en este mismo futuro nuevos problemas que nosotros mismos habríamos creado a cambio de resolverlos.
En primer lugar, al observar el lado operativo del mundo teórico de microservicios sin reglas, nos asustó la posibilidad de un caos con todas las consecuencias resultantes, incluida no solo la calidad impredecible del resultado, sino también conflictos entre equipos o desarrolladores e ingenieros. Y tratar de dar algunas recomendaciones, al no poder garantizar su cumplimiento, inmediatamente parecía una tarea vacía.
En segundo lugar, nadie sabía realmente cómo hacer contenedores y escribir archivos acoplables, que, sin embargo, ya han comenzado a vivir en nuestros repositorios. Además, muchos "leyeron en alguna parte" que no todo es tan simple allí. Entonces, alguien tuvo que profundizar y resolverlo, luego regresar con las mejores prácticas de ensamblaje de contenedores. Pero la perspectiva de asumir el papel de un Docker Packer a tiempo completo, solo con pilas de archivos Docker, por alguna razón no inspiró a nadie en la empresa. Además, como resultó, bucear una vez claramente no es suficiente, e incluso a primera vista parece bueno y correcto, puede resultar incorrecto o simplemente no muy bueno.
Y en tercer lugar, quería estar seguro de que las imágenes obtenidas con los servicios no solo serían correctas desde el punto de vista de las prácticas de contenedores, sino que serían predecibles en su comportamiento y tendrían todas las propiedades y atributos necesarios para simplificar el control de los contenedores lanzados. En otras palabras, quería obtener imágenes con aplicaciones que estuvieran igualmente configuradas y escribir registros, proporcionar una interfaz única para obtener métricas, tener un conjunto coherente de etiquetas y similares. También era importante que el ensamblaje en la computadora del desarrollador arroje el mismo resultado que el ensamblaje en cualquier sistema de CI, incluidas las pruebas aprobadas y la generación de artefactos.
Por lo tanto, nació el entendimiento de que se requeriría algún proceso para administrar y centralizar nuevos conocimientos, prácticas y estándares, y el camino desde el primer compromiso hasta una imagen acoplada completamente lista para la infraestructura del producto debe estar unificado y tan automatizado como sea posible, sin ir más allá de los términos que comienzan con la palabra continua
CLI vs. GUI
El punto de partida para un nuevo componente, ya sea un servicio o una biblioteca, es crear un repositorio. Esta etapa se puede dividir en dos partes: crear y configurar el repositorio en el host del sistema de control de versiones (tenemos Bitbucket) e inicializarlo con la creación de una estructura de archivos. Afortunadamente, ya existían una serie de requisitos para ambos. Por lo tanto, formalizarlos en código era una tarea lógica.
Entonces, ¿cuál debería ser nuestro repositorio?
- Ubicado en uno de los proyectos, en el cual el nombre, los derechos de acceso, las políticas para aceptar solicitudes de extracción, etc.
- Contiene los archivos y directorios necesarios, como:
- archivo con la configuración e información sobre el repositorio
SolutionInfo.props (más sobre eso a continuación); - códigos fuente del proyecto en el directorio
src ; .gitignore , README.md , etc.
- Contiene los submódulos de Git necesarios;
- El proyecto debe derivarse de una de las plantillas.
Dado que la API REST de Bitbucket brinda un control total sobre la configuración de los repositorios, se creó una utilidad especial para interactuar con ella: el generador de repositorios. En el modo de preguntas y respuestas, recibe del usuario todos los datos necesarios y crea un repositorio que cumple todos nuestros requisitos, a saber:
- Define un proyecto en Bitbucket para elegir;
- Valida el nombre de acuerdo con nuestro acuerdo;
- Realiza todas las configuraciones necesarias que no se pueden heredar del proyecto;
- Actualiza la lista de plantillas personalizadas (utilizamos plantillas de dotnet ) para el proyecto y sugiere elegir entre ellas;
- Rellena la información mínima necesaria sobre el repositorio en el archivo de configuración y en los documentos
*.md ; - Conecta submódulos con la configuración de canalización de CI / CD (en nuestro caso, Bamboo Specs ) y scripts de ensamblaje.
En otras palabras, el desarrollador, al iniciar un nuevo proyecto, inicia la utilidad, completa varios campos, selecciona el tipo de proyecto y recibe, por ejemplo, el "¡Hola, mundo!" Completamente terminado. un servicio que ya está conectado al sistema CI, desde donde el servicio puede incluso publicarse si realiza una confirmación que cambia la versión a distinta de cero.
El primer paso ha sido tomado. Sin trabajo manual y errores, buscando documentación, registros y SMS. Ahora pasemos a lo que se generó allí.
Estructura
La estandarización de la estructura del repositorio ha arraigado con nosotros durante mucho tiempo y fue necesaria para simplificar el ensamblaje, la integración con el sistema CI y el entorno de desarrollo. Inicialmente, partimos de la idea de que la canalización en CI debería ser tan simple y, como se podría adivinar, estándar, lo que garantizaría la portabilidad y reproducibilidad del ensamblaje. Es decir, el mismo resultado podría obtenerse fácilmente tanto en cualquier sistema de CI como en el lugar de trabajo del desarrollador. Por lo tanto, todo lo que no se relaciona con las características de un entorno específico de integración continua se envía a un submódulo Git especial y es un sistema de compilación autosuficiente. Más precisamente, el sistema de estandarización de ensamblaje. La tubería en sí, con una aproximación mínima, solo debe ejecutar el script build.sh , recoger un informe sobre las pruebas e iniciar una implementación, si es necesario. Para mayor claridad, veamos qué sucede si genera el repositorio SampleService en un proyecto con el nombre pronunciado Sandbox .
. ├── [bamboo-specs] ├── [devops.build] │ ├── build.sh │ └── ... ├── [docs] ├── [.scripts] ├── [src] │ ├── [CodeAnalysis] │ ├── [Sandbox.SampleService] │ ├── [Sandbox.SampleService.Bootstrap] │ ├── [Sandbox.SampleService.Client] │ ├── [Sandbox.SampleService.Tests] │ ├── Directory.Build.props │ ├── NLog.config │ ├── NuGet.Config │ └── Sandbox.SampleService.sln ├── .gitattributes ├── .gitignore ├── .gitmodules ├── CHANGELOG.md ├── README.md └── SolutionInfo.props
Los primeros dos directorios son submódulos Git. bamboo-specs es "Pipeline as Code" para el sistema Atlassian Bamboo CI (podría haber algún archivo Jenkins en su lugar), devops.build es nuestro sistema de compilación, que analizaré con más detalle a continuación. El directorio .scripts también se .scripts . El proyecto .NET en sí se encuentra en src : NuGet.Config contiene la configuración del repositorio privado NuGet , NLog.config configuración de tiempo de desarrollo de NLog . Como puede suponer, usar NLog en una empresa también es uno de los estándares. Una de las cosas interesantes aquí es el archivo casi mágico Directory.Build.props . Por alguna razón, pocas personas conocen esa posibilidad en los proyectos .NET, como la personalización del ensamblado . En resumen, los archivos con los nombres Directory.Build.props y Directory.Build.targets importan automáticamente a sus proyectos y le permiten configurar propiedades comunes para todos los proyectos en un solo lugar. Por ejemplo, así es como conectamos el analizador StyleCop.Analyzers y su configuración desde el directorio CodeAnalysis a todos los proyectos de estilo de código, establecemos reglas de versiones y algunos atributos comunes para bibliotecas y paquetes ( Compañía , Copyright , etc.), y también nos conectamos a través de <Import> archivo SolutionInfo.props , que es precisamente el mismo archivo de configuración del repositorio, que se discutió anteriormente. Ya contiene la versión actual, información sobre los autores, la URL del repositorio y su descripción, así como varias propiedades que afectan el comportamiento del sistema de ensamblaje y los artefactos resultantes.
Ejemplo `SolutionInfo.props` <?xml version="1.0"?> <Project xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="devops.build/SolutionInfo.xsd"> <PropertyGroup> <Product>Sandbox.SampleService</Product> <BaseVersion>0.0.0</BaseVersion> <EntryProject>Sandbox.SampleService.Bootstrap</EntryProject> <ExposedPort>4000/tcp</ExposedPort> <GlobalizationInvariant>false</GlobalizationInvariant> <RepositoryUrl>https://bitbucket.contoso.com/projects/SND/repos/sandbox.sampleservice/</RepositoryUrl> <DocumentationUrl>https://bitbucket.contoso.com/projects/SND/repos/sandbox.sampleservice/browse/README.md</DocumentationUrl> <Authors>User Name <username@contoso.com></Authors> <Description>The sample service for demo purposes.</Description> <BambooBlanKey>SMPL</BambooBlanKey> </PropertyGroup> </Project>
Ejemplo `Directory.Build.props` <Project> <Import Condition="Exists('..\SolutionInfo.props')" Project="..\SolutionInfo.props" /> <ItemGroup> <None Include="$(MSBuildThisFileDirectory)/CodeAnalysis/stylecop.json" Link="stylecop.json" CopyToOutputDirectory="Never"/> <PackageReference Include="StyleCop.Analyzers" Version="1.*" PrivateAssets="all" /> </ItemGroup> <PropertyGroup> <CodeAnalysisRuleSet>$(MSBuildThisFileDirectory)/CodeAnalysis/stylecop.ruleset</CodeAnalysisRuleSet> <GenerateDocumentationFile>true</GenerateDocumentationFile> <LangVersion>latest</LangVersion> <BaseVersion Condition="'$(BaseVersion)' == ''">0.0.0</BaseVersion> <BuildNumber Condition="'$(BuildNumber)' == ''">0</BuildNumber> <BuildNumber>$([System.String]::Format('{0:0000}',$(BuildNumber)))</BuildNumber> <VersionSuffix Condition="'$(VersionSuffix)' == ''">local</VersionSuffix> <VersionSuffix Condition="'$(VersionSuffix)' == 'prod'"></VersionSuffix> <VersionPrefix>$(BaseVersion).$(BuildNumber)</VersionPrefix> <IsPackable>false</IsPackable> <PackageProjectUrl>$(RepositoryUrl)</PackageProjectUrl> <Company>Contoso</Company> <Copyright>Copyright $([System.DateTime]::Now.Date.Year) Contoso Ltd</Copyright> </PropertyGroup> </Project>
Asamblea
Vale la pena mencionar de inmediato que tanto yo como mis colegas ya tuvimos una experiencia bastante exitosa en el uso de diferentes sistemas de compilación . Y en lugar de ponderar una herramienta existente con una funcionalidad completamente inusual, se decidió hacer otra, especializada para nuestro nuevo proceso, y dejar la antigua sola para llevar a cabo sus tareas como parte de proyectos heredados. La idea de la solución fue el deseo de obtener una herramienta que convierta el código en una imagen acoplable que cumpla con todos nuestros requisitos, utilizando un único proceso estándar, al tiempo que elimina la necesidad de que los desarrolladores se sumerjan en las complejidades del ensamblaje, pero conservando la posibilidad de alguna personalización.
La selección de un marco adecuado ha comenzado. Basado en los requisitos de reproducibilidad del resultado tanto en máquinas de compilación con Linux como en máquinas de Windows de cualquier desarrollador, la multiplataforma real y un mínimo de dependencias predefinidas se convirtieron en una condición clave. En diferentes momentos, logré conocer bastante bien algunos de los frameworks de ensamblaje para desarrolladores de .NET: desde MSBuild y sus monstruosas configuraciones XML, que luego se tradujeron a Psake (Powershell), hasta FAKE exótico (F #). Pero esta vez quería algo fresco y ligero. Además, ya se decidió que el ensamblaje y las pruebas deberían llevarse a cabo completamente en un entorno de contenedor aislado, por lo que no planeé ejecutar dentro de otra cosa que no sean los comandos Docker CLI y Git, es decir, la mayor parte del proceso debería haberse descrito en el Dockerfile.
En ese momento, tanto FAKE 5 como Cake for .NET Core aún no estaban listos, por lo que con una plataforma cruzada, estos proyectos estaban más o menos. Pero mi querido y querido PowerShell 6 Core ya ha sido lanzado, y lo usé al máximo. Por lo tanto, decidí recurrir a Psake nuevamente, y mientras lo hacía, me topé con un interesante proyecto Invoke-Build , que es un replanteamiento de Psake y, como señala el propio autor, es lo mismo, solo que mejor y más fácil. Así es No me detendré en detalles en el marco de este artículo, solo notaré que la compacidad me soborna si todas las funciones básicas para esta clase de productos están disponibles:
- La secuencia de acciones se describe mediante un conjunto de tareas interrelacionadas (tareas), que pueden controlarse utilizando sus interdependencias y condiciones adicionales.
- Hay varios ayudantes útiles, por ejemplo, exec {} para manejar correctamente los códigos de salida de la aplicación de consola.
- Cualquier excepción o dejar de usar Ctrl + C se procesará correctamente en un bloque especial de Salir-Construir incorporado. Por ejemplo, allí puede eliminar todos los archivos temporales, un entorno de prueba o dibujar un informe que sea agradable a la vista.
Archivo Docker Genérico
El Dockerfile en sí y el ensamblaje que usa Docker Build proporcionan capacidades de parametrización bastante débiles, y la flexibilidad de estas herramientas es apenas un poco más alta que la de un mango de pala. Además, hay una gran cantidad de formas de hacer que la imagen "incorrecta" sea demasiado grande, demasiado insegura, poco intuitiva o simplemente impredecible. Afortunadamente, la documentación de Microsoft ya ofrece varios ejemplos de Dockerfile , que le permiten comprender rápidamente los conceptos básicos y crear su primer Dockerfile, mejorando gradualmente más adelante. Él ya usa un patrón de etapas múltiples y crea una imagen especial de " Test Runner " para ejecutar pruebas.
Patrón de múltiples etapas y argumentos
El primer paso es dividir las etapas de ensamblaje en otras más pequeñas y agregar otras nuevas. Por lo tanto, vale la pena destacar el lanzamiento de dotnet build como una etapa separada, porque para proyectos que contienen solo bibliotecas, no tiene sentido ejecutar dotnet publish . Ahora, a nuestra discreción, solo podemos ejecutar las etapas de ensamblaje requeridas usando
dotnet build --target <name>
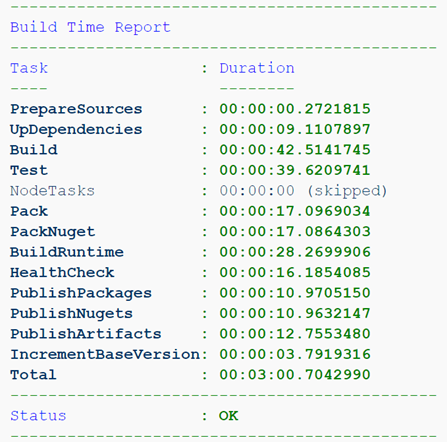
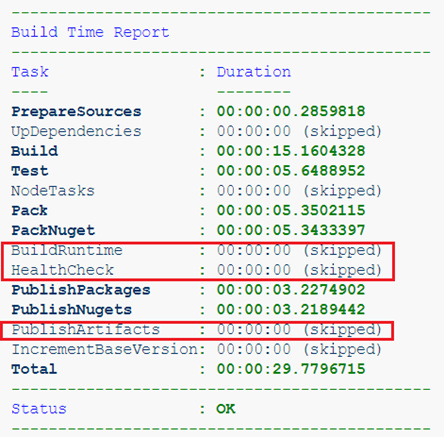
Por ejemplo, aquí estamos recopilando un proyecto que contiene solo bibliotecas. Los artefactos aquí son solo paquetes NuGet, lo que significa que no tiene sentido recopilar una imagen de tiempo de ejecución.
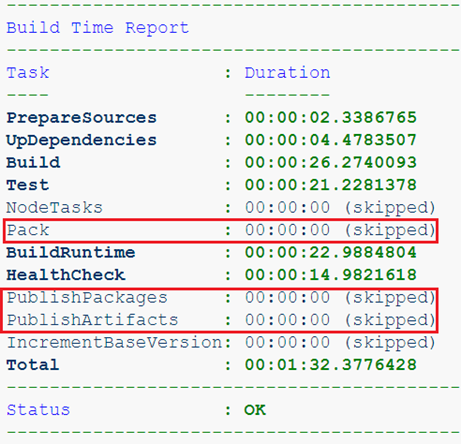
O ya estamos construyendo un servicio, pero desde la rama de características. No necesitamos artefactos de tal ensamblaje en absoluto, solo es importante pasar las pruebas y el control de salud.
Lo siguiente que debe hacer es parametrizar el uso de imágenes básicas. Desde hace algún tiempo, en el Dockerfile, la directiva ARG se puede colocar fuera de las etapas de compilación, y los valores transferidos se pueden usar en el nombre de la imagen base.
ARG DOTNETCORE_VERSION=2.2 ARG ALPINE_VERSION= ARG BUILD_BASE=mcr.microsoft.com/dotnet/core/sdk:${DOTNETCORE_VERSION}-alpine${ALPINE_VERSION} ARG RUNTIME_BASE=mcr.microsoft.com/dotnet/core/runtime:${DOTNETCORE_VERSION}-alpine${ALPINE_VERSION} FROM ${BUILD_BASE} AS restore ... FROM ${RUNTIME_BASE} AS runtime ...
Así que tenemos nuevas y a primera vista, y no oportunidades obvias. En primer lugar, si queremos crear una imagen con una aplicación ASP.NET Core, la imagen en tiempo de ejecución necesitará una diferente: mcr.microsoft.com/dotnet/core/aspnet . El parámetro con una imagen básica no estándar debe guardarse en la configuración del repositorio SolutionInfo.props y pasarlo como argumento durante el ensamblaje. También facilitamos al desarrollador el uso de otras versiones de las imágenes de .NET Core: vistas previas, por ejemplo, o incluso personalizadas (¡nunca se sabe!).
En segundo lugar, la capacidad de "expandir" el Dockerfile es aún más interesante, ya que ha formado parte de las operaciones en otro ensamblado, cuyo resultado se tomará como base al preparar la imagen en tiempo de ejecución. Por ejemplo, algunos de nuestros servicios usan JavaScript y Vue.js, cuyo código prepararemos en una imagen separada, simplemente agregando un Dockerfile "expansivo" al repositorio:
ARG DOTNETCORE_VERSION=2.2 ARG ALPINE_VERSION= ARG RUNTIME_BASE=mcr.microsoft.com/dotnet/core/aspnet:${DOTNETCORE_VERSION}-alpine${ALPINE_VERSION} FROM node:alpine AS install WORKDIR /build COPY package.json . RUN npm install FROM install AS src COPY [".babelrc", ".eslintrc.js", ".stylelintrc", "./"] COPY ClientApp ./ClientApp FROM src AS publish RUN npm run build-prod FROM ${RUNTIME_BASE} AS appbase COPY --from=publish /build/wwwroot/ /app/wwwroot/
Recopilemos esta imagen con la etiqueta, que pasaremos a la etapa de ensamblar la imagen de tiempo de ejecución del servicio ASP.NET como argumento para RUNTIME_BASE. Por lo tanto, puede expandir el ensamblaje tanto como desee, incluso, puede parametrizar lo que no puede hacer en la docker build . ¿Quiere parametrizar la adición de Volumen? Fácil:
ARG DOTNETCORE_VERSION=2.2 ARG ALPINE_VERSION= ARG RUNTIME_BASE=mcr.microsoft.com/dotnet/core/aspnet:${DOTNETCORE_VERSION}-alpine${ALPINE_VERSION} FROM ${RUNTIME_BASE} AS runtime ARG VOLUME VOLUME ${VOLUME}
Comenzamos el ensamblaje de este Dockerfile tantas veces como queramos agregar directivas VOLUME. Usamos la imagen resultante como base para el servicio.
Ejecutando pruebas
En lugar de ejecutar pruebas directamente en las etapas de ensamblaje, es más correcto y más conveniente hacerlo en un contenedor especial "Test Runner". Transmitiendo brevemente la esencia de este enfoque, observo que le permite:
- Realice todos los lanzamientos programados, incluso si uno de ellos falla;
- Monte el directorio del sistema de archivos del host en el contenedor para recibir un informe de prueba, que es vital al construir en el sistema CI;
- Ejecute las pruebas en un entorno temporal pasando el nombre de su red al
docker run --network <test_network_name> .
El último párrafo significa que ahora podemos ejecutar no solo pruebas unitarias, sino también pruebas de integración. Describimos el entorno, por ejemplo, en docker-compose.yaml , y lo ejecutamos para toda la compilación. Ahora puede verificar la interacción con la base de datos o nuestro otro servicio, y guardar los registros de ellos en caso de que los necesite para su análisis.
Siempre verificamos la imagen de tiempo de ejecución resultante para pasar el chequeo de salud, que también es una especie de prueba. Un entorno de prueba temporal puede ser útil aquí si el servicio que se está probando depende de su entorno.
También noto que el enfoque con los contenedores de corredores ensamblados en el escenario con la dotnet build servirá entonces bien para lanzar dotnet publish , dotnet pack y dotnet nuget push . Esto nos permitirá guardar los artefactos de ensamblaje localmente.
Verificación de salud y dependencias del sistema operativo
Rápidamente se hizo evidente que nuestros servicios estandarizados seguirían siendo únicos a su manera. Pueden tener diferentes requisitos para paquetes preinstalados del sistema operativo dentro de la imagen y diferentes formas de verificar el chequeo de salud. Y si curl es adecuado para verificar el estado de una aplicación web, entonces para un backend gRPC o, además, un servicio sin cabeza, será inútil y también será un paquete adicional en el contenedor.
Para dar a los desarrolladores la oportunidad de personalizar la imagen y expandir su configuración, utilizamos el acuerdo en varios scripts especiales que se pueden redefinir en el repositorio:
.scripts ├── healthcheck.sh ├── run.sh └── runtime-deps.sh
El script healthcheck.sh contiene los comandos necesarios para verificar el estado:
Usando runtime-deps.sh , se instalan las dependencias y, si es necesario, se realizan otras acciones en el sistema operativo base que son necesarias para el funcionamiento normal de la aplicación dentro del contenedor. Ejemplos tipicos:
Para una aplicación web:
Para el servicio gRPC:
Por lo tanto, la forma de administrar las dependencias y verificar el estado está estandarizada, pero hay espacio para cierta flexibilidad. En cuanto a run.sh , entonces es más.
Script de punto de entrada
Estoy seguro de que todos los que al menos una vez escribieron su Dockerfile se preguntaron qué directiva usar: CMD o ENTRYPOINT . Además, estos equipos también tienen dos opciones de sintaxis, que de la manera más dramática afectan el resultado. No explicaré la diferencia en detalle, repitiendo después de aquellos que ya han aclarado todo . Solo recomiendo recordar que en el 99% de las situaciones es correcto usar ENTRYPOINT y la sintaxis ejecutiva:
PUNTO DE ENTRADA ["/ ruta / a / ejecutable"]
De lo contrario, la aplicación iniciada no podrá procesar correctamente los comandos del sistema operativo, como SIGTERM, etc., y también puede tener problemas en forma de procesos zombies y todo lo relacionado con el problema PID 1 . Pero, ¿qué sucede si desea iniciar el contenedor sin iniciar la aplicación? Sí, puede anular el punto de entrada:
docker run --rm -it --entrypoint ash <image_name> <params>
No se ve muy cómodo e intuitivo, ¿verdad? Pero hay buenas noticias: ¡puedes hacerlo mejor! A saber, use un script de punto de entrada . Tal script le permite realizar una inicialización arbitrariamente compleja ( ejemplo ), procesamiento de parámetros y todo lo que desee.
En nuestro caso, por defecto, se utiliza el escenario más simple, pero al mismo tiempo funcional:
Le permite controlar el lanzamiento del contenedor de forma muy intuitiva:
docker run <image> env : solo ejecuta env en la imagen, mostrando las variables de entorno.
docker run <image> -param1 value1 - inicia el servicio con los argumentos especificados.
Por separado, debe prestar atención al comando exec : su presencia antes de llamar a la aplicación ejecutable le proporcionará el codiciado PID 1 en su contenedor.
Que mas
Por supuesto, durante más de un año y medio de uso, el sistema de compilación ha acumulado muchas funcionalidades diferentes. Además de gestionar las condiciones de lanzamiento de varias etapas, trabajando con el almacenamiento de artefactos, versiones y otras características, también se desarrolló nuestro "estándar" del contenedor. Estaba lleno de atributos importantes que lo hacen más predecible y administrativamente conveniente:
- Se instalan todas las etiquetas de imagen necesarias: versiones, números de revisión, enlaces a documentación, autor y otros.
- En el contenedor de tiempo de ejecución, la configuración de NLog se redefine para que, después de la publicación, todos los registros se presenten inmediatamente en forma estructurada utilizando json, cuya versión se versiona.
- Las reglas de análisis estático y cualquier otro estándar se actualizan automáticamente.
Tal herramienta, por supuesto, siempre se puede mejorar y desarrollar. Todo depende de las necesidades y la imaginación. Por ejemplo, además de todo, fue posible empaquetar utilidades cli adicionales en una imagen. El desarrollador puede ponerlos fácilmente en la imagen, especificando en el archivo de configuración solo el nombre de la utilidad requerida y el nombre del proyecto .NET desde el cual debe ensamblarse (por ejemplo, nuestro healthcheck ).
Conclusión
Aquí se describe solo una parte de un enfoque integrado de estandarización. Los servicios en sí, que se crean a partir de nuestras plantillas, permanecieron detrás de escena y, por lo tanto, están bastante unificados por muchos criterios, como un enfoque único de configuración, métodos comunes para acceder a métricas, generación de código, etc. . , .
, Linux , - . , , . , , , Code Style, , .
, ! , « », , . , Docker .