
Hola a todos! Recientemente, se realizó un seminario web abierto
"Proporcionando almacenamiento tolerante a fallas" . Examinó qué problemas surgen en el diseño de arquitecturas, por qué la falla del servidor no es una excusa para el bloqueo de un servidor y cómo reducir al mínimo el tiempo de inactividad. El seminario web fue organizado por
Ivan Remen , jefe de desarrollo de servidores en Citimobil y profesor en el curso
"Arquitecto de alta carga
" .
¿Por qué molestarse con la capacidad de almacenamiento?
Pensar en la resistencia del almacenamiento escalable y comprender los problemas básicos de almacenamiento en caché debería estar
en la etapa de inicio . Está claro que cuando escribes una startup, al principio creas la versión mínima del producto. Pero cuanto más crezca, más rápido se encontrará con la productividad, lo que puede conducir a una parada completa del negocio. Y si obtiene dinero de los inversores, entonces, por supuesto, también requerirán un crecimiento constante y nuevas características comerciales. Para encontrar el equilibrio adecuado, debe elegir entre velocidad y calidad. Al mismo tiempo, no puedes sacrificar ni a uno ni a otro, y si lo haces, entonces conscientemente y dentro de ciertos límites. Sin embargo, no hay recetas universales aquí, así como soluciones ideales.
Descansamos contra la base para leer
Este es el primer escenario. Imagine que tenemos 1 servidor, cuya carga en el procesador o disco duro es del 99%. En este caso:
- El 90% de las solicitudes son leídas;
- El 10% de las solicitudes son un registro.
La mejor solución en esta situación es pensar en réplicas. Por qué Esta es la solución más barata y fácil.
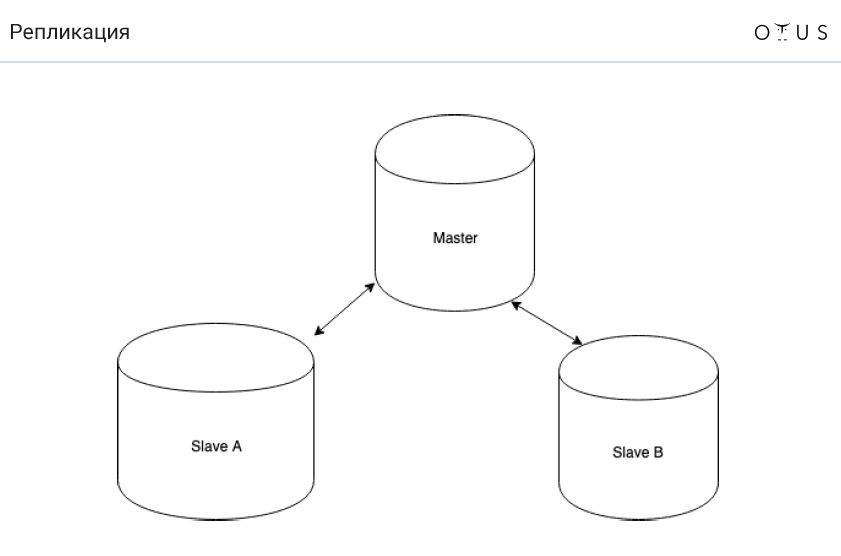
La replicación se clasifica:
1. Por sincronización:
- síncrono
- asincrónico
- semisíncrono
2. Según datos portátiles:
- lógico (basado en filas, basado en sentencias, mixto);
- fisico
3. Por el número de nodos por registro:
- maestro / esclavo;
- maestro / maestro.
4. Por iniciador:
Y ahora la
tarea es sobre un balde de agua . Imagine que tenemos MySQL y replicación asincrónica maestro-esclavo. Se está realizando una limpieza en DC, como resultado de lo cual el limpiador tropieza y vierte un balde de agua en el servidor con la base maestra. La automatización cambia con éxito uno de los últimos esclavos al modo maestro. Y todo sigue funcionando. ¿Dónde está la trampa?
La respuesta es simple: perdemos transacciones que no logramos replicar. En consecuencia, se viola la propiedad D del ACID.
Ahora hablemos sobre cómo funciona la replicación asincrónica (MySQL):
- grabar una transacción en el motor de almacenamiento (InnoDB);
- registrar una transacción en un registro binario;
- finalización de transacciones en el motor de almacenamiento;
- confirmación de devolución al cliente;
- transferir parte del registro a la réplica;
- ejecución de una transacción en una réplica (p. 1-3).
Y ahora la pregunta es, ¿qué hay que cambiar en los párrafos anteriores para que nunca terminemos con la replicación?
Y solo se deben intercambiar dos puntos: 4to y 5to ("transferir parte del registro a la réplica" y "devolver la confirmación al cliente"). Por lo tanto, si el nodo maestro vuela, siempre tendremos un registro de transacciones en algún lugar (punto 2). Y si la transacción se registra en el registro binario, entonces la transacción también ocurrirá en algún momento.
Como resultado, obtenemos la replicación semisíncrona (MySQL), que funciona de la siguiente manera:
- grabar una transacción en el motor de almacenamiento (InnoDB);
- registrar una transacción en un registro binario;
- finalización de transacciones en el motor de almacenamiento;
- transferir parte del registro a la réplica;
- confirmación de devolución al cliente;
- ejecución de una transacción en una réplica (p. 1-3).
Sincronización vs semi-sincronización y asíncrona vs semi-sincronización
Por alguna razón, en Rusia, la mayoría de la gente no ha escuchado sobre la replicación semisíncrona. Por cierto, está bien implementado en PostgreSQL y no muy en MySQL. Lea más sobre esto
aquí , pero la tesis se puede formular de la siguiente manera:
- la replicación semisíncrona todavía está detrás (pero no tanto) como asíncrona;
- no perdemos transacciones;
- es suficiente llevar los datos a un solo esclavo.
Por cierto, la replicación semisíncrona se usa en Facebook.
Descansamos contra la base récord
Hablemos de un problema diametralmente opuesto cuando tenemos:
- 90% de las solicitudes - registro;
- 10% de las solicitudes son leídas;
- 1 servidor;
- carga - 99% (procesador o disco duro).
Fragmentos conocidos vienen al rescate aquí. Pero ahora hablemos de otra cosa:

Muy a menudo en tales casos, comienzan a usar master-master. Sin embargo,
no ayuda en esta situación . Por qué Es simple: el registro en el servidor no se reduce. Después de todo, la replicación implica que hay datos en todos los nodos. Con la replicación basada en sentencias, en efecto, SQL se ejecutará en TODOS los nodos. C basado en filas es un poco más fácil, pero sigue siendo costoso. Y también maestro-maestro tiene problemas con los conflictos.
De hecho, tiene sentido usar master-master en las siguientes situaciones:
- tolerancia a fallos de escritura (la idea es que siempre escriba a un solo maestro). Puede implementar usando la dirección IP virtual ;
- sistemas geodistribuidos.
Sin embargo, recuerde que la replicación maestro-maestro siempre es difícil. Y a menudo master-master trae más problemas de los que resuelve.
Sharding
Ya hemos mencionado el fragmentación. En resumen, el fragmentación es una forma segura de escalar un registro. La idea es que distribuyamos datos a través de servidores independientes (pero no siempre). Cada fragmento puede replicarse de forma independiente.
La primera regla de los fragmentos es que los datos que se usan juntos deben estar en el mismo fragmento. La
sharding_key -> shard_id funciona
sharding_key -> shard_id . En consecuencia,
sharding_key para los datos que se usan juntos deben coincidir. La primera dificultad es que si eliges la
sharding_key incorrecta, entonces será muy difícil volver a barajar todo. En segundo lugar, si tiene algún tipo de
sharding_key , algunas solicitudes serán muy difíciles de ejecutar. Por ejemplo, no puede encontrar el valor promedio.
Para demostrar esto, imaginemos que tenemos dos fragmentos con tres valores en cada uno: (1; 2; 3) (0; 0; 500). El valor promedio será igual a (1 + 2 + 3 + 500) / 6 = 84.33333.
Ahora imagine que tenemos dos servidores independientes. Y vuelva a calcular el valor promedio por separado para cada fragmento. En el primero de ellos obtenemos 2, en el segundo - 166.66667. E incluso si luego promediamos estos valores, obtendremos un número que diferirá del correcto: (2 + 166.66667) / 2 = 86.33334.
Es decir, el
promedio de los medios no es igual al promedio de todo: avg(a, b, c, d) != avg(avg(a, b) + (avg(c, d))
Matemáticas simples, pero es importante recordar.
Tarea de fragmentación
Supongamos que tenemos un sistema de diálogo en una red social. Solo puede haber 2 personas en un diálogo. Todos los mensajes están en una tabla, en la que hay:
- ID del mensaje
- ID del remitente
- ID del destinatario
- mensaje de texto;
- fecha en que se envió el mensaje;
- algunas banderas
¿Qué clave de fragmentación se debe elegir en función del hecho de que tenemos la primera regla de fragmentación descrita anteriormente?
Hay varias opciones para resolver este problema clásico:
- crc32 (id_src // id_dst);
- crc32 (1 // 2)! = crc32 (2 // 1);
- crc32 (de + a)% n;
- crc32 (min (de, a). max (de, a))% n.
Cachés
Y algunas palabras sobre cachés. Podemos decir que los
cachés son un antipatrón , aunque uno puede discutir esta afirmación (a muchas personas les gusta usar cachés). Pero en general, los cachés solo son necesarios para aumentar la tasa de respuesta. Y no se pueden configurar para mantener la carga.
La conclusión es simple: debemos vivir en silencio sin cachés. La única razón por la que pueden ser necesarios es exactamente la misma razón por la que se necesitan en el procesador: para aumentar la velocidad de respuesta. Si la base de datos no soporta la carga como resultado de la desaparición de la memoria caché, esto es malo. Este es un patrón arquitectónico extremadamente infructuoso, por lo que no debería serlo. Y cualesquiera que sean los recursos que tenga, algún día su caché seguramente se caerá, haga lo que haga.
Los problemas de caché son tesis:- comenzar con un caché frío;
- problema de invalidación de caché;
- Consistencia de caché.
Si todavía usa cachés, el hashing consistente lo ayudará. Esta es una forma de crear tablas hash distribuidas, en las que la falla de uno o más servidores de almacenamiento no lleva a la necesidad de una reubicación completa de todas las claves y valores almacenados. Sin embargo, puedes leer más sobre esto
aquí .

Bueno, gracias por mirar! Para no perderse nada de la última conferencia, es mejor
ver el seminario web completo .