Mi nombre es Azat Razetdinov, llevo 12 años en Yandex, administro el servicio de desarrollo de interfaces en Y. Real Estate. Hoy me gustaría hablar de un monorepository. Si solo tiene un repositorio en el trabajo, felicidades, ya vive en un único repositorio. Ahora sobre por qué otros lo necesitan.
Según Marina Pereskokova, directora del servicio de desarrollo de API Yandex.Map, mi abuelo plantó una monorepa, y una monorepa ha crecido mucho.
- En Yandex probamos diferentes formas de trabajar con varios servicios y nos dimos cuenta: tan pronto como tiene más de un servicio, inevitablemente comienzan a aparecer partes comunes: modelos, utilidades, herramientas, códigos, plantillas, componentes. La pregunta es: ¿dónde poner todo esto? Por supuesto, puedes copiar y pegar, podemos hacerlo, pero lo quiero maravillosamente.
Incluso probamos una entidad como SVN externos para aquellos que recuerdan. Intentamos submódulos git. Intentamos paquetes npm cuando aparecieron. Pero todo esto fue de alguna manera largo, o algo así. Admite cualquier paquete, encuentra un error, realiza correcciones. Luego, necesita lanzar una nueva versión, pasar por los servicios, actualizar a esta versión, verificar que todo funcione, ejecutar las pruebas, encontrar el error, volver al repositorio de la biblioteca, corregir el error, lanzar la nueva versión, pasar por los servicios, actualizar, etc. círculo Simplemente se convirtió en dolor.

Luego pensamos si deberíamos unirnos en un repositorio. Tome todos nuestros servicios y bibliotecas, transfiéralos y desarrolle en un solo repositorio. Hubo muchas ventajas. No estoy diciendo que este enfoque sea ideal, pero desde el punto de vista de la empresa e incluso del departamento de varios grupos, aparecen ventajas significativas.
Para mí personalmente, lo más importante es la atomicidad de los commits, que como desarrollador, puedo arreglar la biblioteca, omitir todos los servicios, hacer cambios, ejecutar pruebas, verificar que todo funcione, empujarlo al maestro y todo esto con un solo cambio. No es necesario reconstruir, publicar, actualizar nada.
Pero si todo está tan bien, ¿por qué no se han mudado todos al repositorio mono todavía? Por supuesto, también hay desventajas en ello.

Según Marina Pereskokova, directora del servicio de desarrollo de API Yandex.Map, mi abuelo plantó una monorepa, y una monorepa ha crecido mucho. Esto es un hecho, no una broma. Si reúne muchos servicios en un solo repositorio, inevitablemente crece. Y si estamos hablando de git, que extrae todos los archivos más su historial completo durante toda la existencia de su código, este es un espacio en disco bastante grande.
El segundo problema es la inyección en el maestro. Usted preparó una solicitud de grupo, realizó una revisión, está listo para fusionarla. Y resulta que alguien logró adelantarse a usted y usted necesita resolver conflictos. Resolvió los conflictos, nuevamente listo para entrar, y nuevamente no tuvo tiempo. Este problema se está resolviendo, hay sistemas de colas de fusión, cuando un robot especial automatiza este trabajo, las solicitudes de grupos de carriles, intenta resolver conflictos, si puede. Si no puede, llama al autor. Sin embargo, tal problema existe. Hay soluciones que lo nivelan, pero debe tenerlo en cuenta.
Estos son puntos técnicos, pero también hay puntos organizativos. Supongamos que tiene varios equipos que hacen varios servicios diferentes. Cuando se trasladan a un único repositorio, su responsabilidad comienza a erosionarse. Debido a que hicieron un lanzamiento, se lanzaron en producción, algo se rompió. Comenzamos el interrogatorio. Resulta que es un desarrollador de otro equipo que ha comprometido algo con el código general, lo sacamos, no lo lanzamos, no lo vimos, todo se rompió. Y no está claro quién es responsable. Es importante comprender y utilizar todos los métodos posibles: pruebas unitarias, pruebas de integración, linter: todo lo que sea posible para reducir este problema de la influencia de un código en todos los demás servicios.
Curiosamente, ¿quién más además de Yandex y otros jugadores usa el mono-repositorio? Mucha gente Estos son React, Jest, Babel, Ember, Meteor, Angular. La gente entiende: es más fácil, más barato, más rápido desarrollar y publicar paquetes npm desde un único repositorio que desde varios repositorios pequeños. Lo más interesante es que, junto con este proceso, comenzaron a desarrollarse herramientas para trabajar con un monorepository. Solo sobre ellos y quiero hablar.
Todo comienza con la creación de un monorepository. La herramienta de front-end más famosa del mundo para esto se llama lerna.

Simplemente abra su repositorio, ejecute npx lerna init, le hará algunas preguntas sugerentes y agregará algunas entidades a su copia de trabajo. La primera entidad es la configuración lerna.json, que indica al menos dos campos: la versión de extremo a extremo de todos sus paquetes y la ubicación de sus paquetes en el sistema de archivos. De forma predeterminada, todos los paquetes se agregan a la carpeta de paquetes, pero puede configurar esto como lo desee, incluso puede agregarlos a la raíz, lerna también puede recogerlo.
El siguiente paso es cómo agregar sus repositorios al repositorio mono, ¿cómo transferirlos?
¿Qué queremos lograr? Lo más probable es que ya tenga algún tipo de repositorio, en este caso A y B.

Estos son dos servicios, cada uno en su propio repositorio, y queremos transferirlos al nuevo mono-repositorio en la carpeta de paquetes, preferiblemente con un historial de confirmaciones, para que pueda culpar a git, git log, etc.

Hay una herramienta de importación de lerna para esto. Simplemente especifique la ubicación de su repositorio, y lerna lo transfiere a su monorepo. Al mismo tiempo, ella, en primer lugar, toma una lista de todas las confirmaciones, modifica cada confirmación, cambia la ruta a los archivos desde la raíz a paquetes / nombre_paquete, y los aplica uno tras otro, los impone en su mono-repositorio. De hecho, cada confirmación se prepara, cambiando las rutas de los archivos. Esencialmente, lerna hace magia para ti. Si lee el código fuente, simplemente los comandos git se ejecutan en una secuencia determinada.
Esta es la primera forma. Tiene un inconveniente: si trabaja en una empresa donde hay procesos de producción, donde la gente ya está escribiendo algún tipo de código y los va a traducir a un monorep, es poco probable que lo haga en un día. Tendrá que averiguar, configurar, verificar que todo comience, las pruebas. Pero las personas no tienen trabajo, continúan haciendo algo.

Para una transición más suave al mono-rap, existe una herramienta como git subtree. Esto es algo más sofisticado, pero al mismo tiempo nativo de git, que le permite no solo importar repositorios individuales en un repositorio mono mediante algún tipo de prefijo, sino también intercambiar cambios de un lado a otro. Es decir, el equipo que realiza el servicio puede desarrollarse fácilmente en su propio repositorio, mientras que puede extraer sus cambios a través de git subtree pull, realizar sus propios cambios y hacerlos retroceder a través de git subtree push. Y vive así en el período de transición todo el tiempo que quieras.
Y cuando configuró todo, verificó que todas las pruebas se están ejecutando, la implementación funciona, se configuró todo el CI / CD, puede decir que es hora de seguir adelante. Para el período de transición, una gran solución, lo recomiendo.
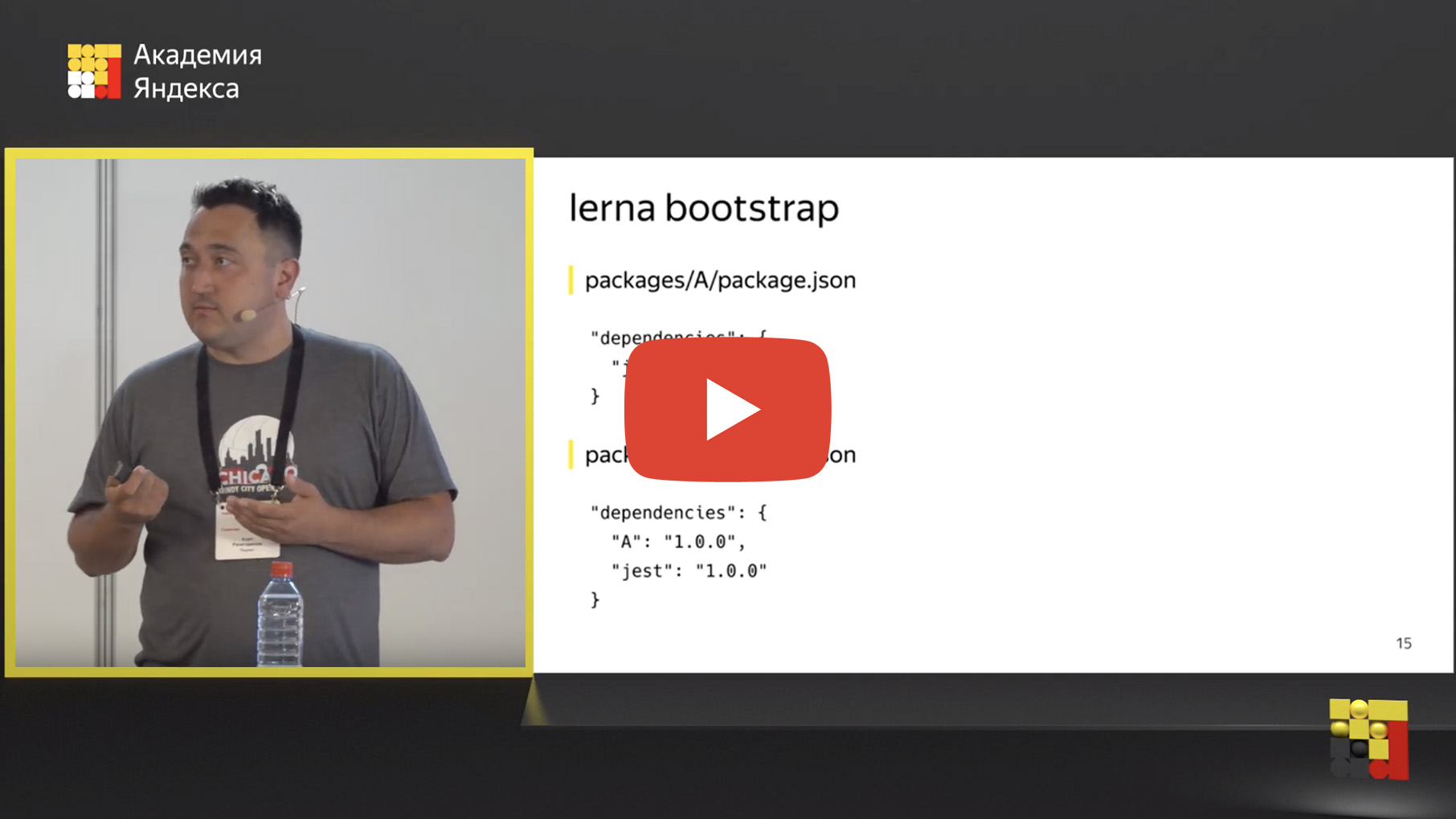
Bueno, trasladamos nuestros repositorios a un mono-repositorio, pero ¿dónde está la magia en alguna parte? Pero queremos resaltar las partes comunes y usarlas de alguna manera. Y para esto hay un mecanismo de "vinculación de dependencia". ¿Qué es el enlace de dependencia? Hay una herramienta de arranque de lerna, un comando que es similar a npm install, solo ejecuta npm install en todos sus paquetes.

Pero eso no es todo. Además, ella está buscando dependencias internas. Puede usar otro en un paquete dentro de su repositorio. Por ejemplo, si tiene el paquete A, que depende de Jest en este caso, existe el paquete B, que depende de Jest y el paquete A. Si el paquete A es una herramienta común, un componente común, entonces el paquete B es un servicio que lo tiene usos.
Lerna define tales dependencias internas y reemplaza físicamente esta dependencia con un enlace simbólico en el sistema de archivos.


Después de ejecutar lerna bootstrap, justo dentro de la carpeta node_modules, en lugar de la carpeta física A, aparece un enlace simbólico que conduce a la carpeta con el paquete A. Esto es muy conveniente porque puede editar el código dentro del paquete A e inmediatamente comprobar el resultado en el paquete B , ejecuta pruebas, integración, unidades, lo que quieras. El desarrollo se simplifica enormemente, ya no necesita volver a ensamblar el paquete A, publicar, conectar el paquete B. Simplemente se soluciona aquí, se verifica allí.
Tenga en cuenta que si mira las carpetas node_modules, y allí y allí es broma, hemos duplicado el módulo instalado. En general, es mucho tiempo cuando inicia lerna bootstrap, espere hasta que todo se detenga, debido al hecho de que hay mucho trabajo repetido, se obtienen dependencias duplicadas en cada paquete.
Para acelerar la instalación de dependencias, se utiliza el mecanismo para aumentar las dependencias. La idea es muy simple: puede llevar las dependencias generales a la raíz node_modules.

Si especifica la opción --hoist (esta es una actualización del inglés), casi todas las dependencias simplemente se moverán a la raíz node_modules. Y casi siempre funciona. Noda está tan dispuesta que si no ha encontrado las dependencias a su nivel, comienza a buscar un nivel más alto, si no allí, otro nivel más alto, etc. Casi nada cambia. Pero, de hecho, tomamos y deduplicamos nuestras dependencias, transferimos las dependencias a la raíz.
Al mismo tiempo, lerna es lo suficientemente inteligente. Si hay algún conflicto, por ejemplo, si el paquete A usa la versión 1 de Jest y el paquete B usa la versión 2, entonces uno de ellos aparecerá y el segundo permanecerá en su nivel. Esto es aproximadamente lo que npm está haciendo realmente dentro de la carpeta normal node_modules, también trata de deduplicar las dependencias y, al máximo, llevarlas a la raíz.
Desafortunadamente, esta magia no siempre funciona, especialmente con herramientas, con Babel, con Jest. A menudo sucede que comienza, porque Jest tiene su propio sistema para resolver módulos, Noda comienza a retrasarse, arroja un error. Especialmente para tales casos cuando la herramienta no hace frente a las dependencias que se han ido a la raíz, existe la opción de nohoist, que le permite señalar que estos paquetes no se transfieren a la raíz, déjelos en su lugar.

Si especifica --nohoist = jest, todas las dependencias, excepto jest, irán a la raíz y jest permanecerá en el nivel del paquete. No es de extrañar que haya dado ese ejemplo: es una broma que tiene problemas con este comportamiento, y nohoist ayuda con esto.
Otra ventaja de la recuperación de dependencias:

Si antes de eso tenía un paquete-lock.json separado para cada servicio, para cada paquete, entonces, cuando esté listo, todo se mueve hacia arriba y queda el único paquete-lock.json. Esto es conveniente desde el punto de vista de verter en el maestro, resolviendo conflictos. Una vez que todos fueron asesinados, y eso es todo.
¿Pero cómo lerna logra esto? Ella es bastante agresiva con npm. Cuando especifica el polipasto, toma su package.json en la raíz, lo respalda, lo sustituye por otro, agrega todas sus dependencias, ejecuta npm install, casi todo se coloca en la raíz. Entonces este paquete temporal.json elimina, restaura el tuyo. Si después de eso ejecuta algún comando con npm, por ejemplo, npm remove, npm no entenderá lo que sucedió, por qué todas las dependencias aparecieron repentinamente en la raíz. Lerna viola el nivel de abstracción, se mete en la herramienta, que está por debajo de su nivel.
Los chicos de Yarn fueron los primeros en darse cuenta de este problema y dijeron: qué estamos atormentando, déjenos hacer todo por usted de forma nativa, para que todo salga de la caja.

Yarn ya puede hacer lo mismo fuera de la caja: dependencias vinculadas, si ve que el paquete B depende del paquete A, hará un enlace simbólico por usted, de forma gratuita. Él sabe cómo aumentar las dependencias, lo hace por defecto, todo se suma a la raíz. Al igual que lerna, puede dejar el único hilo.lock en la raíz del repositorio. Todos los demás hilados.lock que ya no necesitas.

Está configurado de manera similar. Desafortunadamente, yarn asume que todas las configuraciones se agregan a package.json, sé que hay personas que intentan quitar todas las configuraciones de las herramientas desde allí, dejando solo un mínimo. Desafortunadamente, yarn aún no ha aprendido a especificar esto en otro archivo, solo package.json. Hay dos nuevas opciones, una nueva y otra obligatoria. Dado que se supone que el repositorio raíz nunca se publicará, yarn requiere que private = true se especifique allí.
Pero la configuración de los espacios de trabajo se almacena en la misma clave. La configuración es muy similar a la configuración de lerna, hay un campo de paquetes donde especificas la ubicación de tus paquetes y hay una opción de nohoist, muy similar a la opción de nohoist en lerna. Simplemente especifique estas configuraciones y obtenga la misma estructura que en lerna. Todas las dependencias comunes fueron a la raíz, y las especificadas en la clave nohoist se mantuvieron en su nivel.

La mejor parte es que lerna puede trabajar con hilo y recoger su configuración. Es suficiente especificar dos campos en lerna.json, lerna inmediatamente comprenderá que está utilizando hilo, vaya a package.json, obtenga todos los ajustes desde allí y trabaje con ellos. Estas dos herramientas ya se conocen entre sí y trabajan juntas.

¿Y por qué todavía no se ha brindado soporte en npm si tantas grandes empresas usan un mono-repositorio?

Dicen que todo lo será, pero en la séptima versión. Soporte básico en el séptimo, extendido - en el octavo. Esta publicación se lanzó hace un mes, pero al mismo tiempo, aún se desconoce la fecha en que se lanzará la séptima npm. Estamos esperando que finalmente se ponga al día con el hilo.
Cuando tiene varios servicios en un mono-repositorio, inevitablemente surge la pregunta de cómo administrarlos para no ir a cada carpeta, no ejecutar comandos. Hay operaciones masivas para esto.


Yarn tiene un comando de espacio de trabajo de hilo, seguido del nombre del paquete y el nombre del comando. Dado que yarn from the box, a diferencia de npm, puede hacer las tres cosas: ejecutar sus propios comandos, agregar una dependencia en jest, ejecutar scripts desde package.json, como test, y también puede ejecutar archivos ejecutables desde la carpeta node_modules / .bin. Él te enseñará con la ayuda de la heurística, él comprenderá lo que quieres. Es muy conveniente utilizar el espacio de trabajo de hilo para operaciones puntuales en un paquete.
Hay un comando similar que le permite ejecutar un comando en todos los paquetes que tenga.

Indique solo sus comandos con todos los argumentos.

De los profesionales, es muy conveniente dirigir diferentes equipos. De los inconvenientes, por ejemplo, es imposible ejecutar comandos de shell. Supongamos que quiero eliminar todas las carpetas de módulos de nodo, no puedo ejecutar espacios de trabajo de hilo ejecutar rm.
Es imposible especificar una lista de paquetes, por ejemplo, quiero eliminar la dependencia en solo dos paquetes, solo a su vez o individualmente.
Bueno, se estrella con el primer error. Si quiero eliminar la dependencia de todos los paquetes, y de hecho, solo dos de ellos la tienen, pero no quiero pensar dónde está, pero solo quiero eliminarla, entonces el hilo no lo permitirá, se bloqueará en la primera situación donde este paquete no está en las dependencias. Esto no es muy conveniente, a veces desea ignorar los errores, ejecutar todos los paquetes.

Lerna tiene un kit de herramientas mucho más interesante, hay dos comandos separados de ejecución y ejecución. Run puede ejecutar scripts desde package.json, y a diferencia del hilo, puede filtrar todo por paquete, puede especificar --scope, puede usar asteriscos, globos, todo es bastante universal. Puede ejecutar estas operaciones en paralelo, puede ignorar los errores a través del interruptor --no-bail.

Exec es muy similar. A diferencia de yarn, le permite no solo ejecutar archivos ejecutables desde node_modules.bin, sino también ejecutar cualquier comando de shell arbitrario. Por ejemplo, puede eliminar node_modules o ejecutar alguna marca, lo que quiera. Y la misma opción es compatible.

Herramientas muy convenientes, algunas ventajas. Este es el caso cuando Lerna rasga el hilo, está en el nivel correcto de abstracción. Esto es exactamente lo que lerna necesita: simplificar el trabajo con varios paquetes en monorepe.
Con monoreps hay un menos más. Cuando tiene un CI / CD, no puede optimizarlo. Cuantos más servicios tenga, más tardará todo. Suponga que comienza a probar todos los servicios para cada solicitud de grupo, y cuanto más haya, más tiempo llevará el trabajo. Las operaciones selectivas se pueden utilizar para optimizar este proceso. Voy a nombrar tres formas diferentes. Los dos primeros se pueden usar no solo en monorep, sino también en sus proyectos, si por alguna razón no usa estos métodos.
El primero es lint-stage, que le permite ejecutar linter, pruebas, todo lo que desee, solo a los archivos que han cambiado o serán confirmados en este commit. Ejecute toda la pelusa no en todo su proyecto, sino solo en los archivos que han cambiado.


La configuración es muy simple. Ponga enganchados con pelusa, husky, pre-commit-hooks y diga que al cambiar cualquier archivo js necesita ejecutar eslint. Por lo tanto, la verificación previa a la confirmación se acelera enormemente. Especialmente si tiene muchos servicios, un mono-repositorio muy grande. Luego, ejecutar eslint en todos los archivos es demasiado costoso, y puede optimizar los enlaces de precompromiso en lint de esta manera.

Si escribe pruebas en Jest, también tiene herramientas para ejecutar pruebas selectivamente.

Esta opción le permite darle una lista de archivos de origen y encontrar todas las pruebas que afectan de una forma u otra a estos archivos. ¿Qué se puede usar junto con pelusa puesta en escena? , js-, . js- , . findRelatedTests , .
, . lerna, , . , CI/CD: Travis , .


run exec since, , - . , . , CI/CD -, .
lerna , . , , , lerna . , . , C — , . lerna .
, :
c lerna ,
yarn workspaces
.
, . , . . ? , , , . , , . , - . , Babel. , , . . , .
Quiero agradecer a mis colegas: Misha mishanga Troshev y Gosha Besedin. Pasaron bastante tiempo estudiando las herramientas que revisamos hoy y compartieron su experiencia y conocimiento. Eso es todo, gracias.