AI en hierro doméstico
Hablamos sobre cómo portamos nuestro marco para redes neuronales y sistema de reconocimiento facial a los procesadores rusos Elbrus.
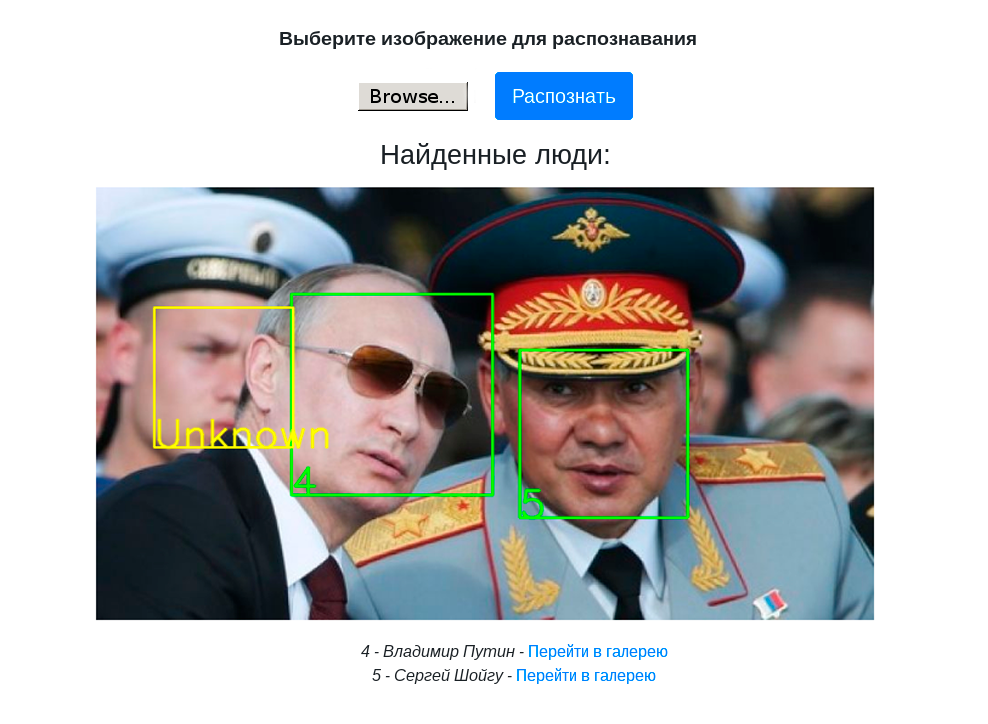
Fue una tarea interesante, en la primavera de 2019 hablamos de ello en la oficina de Yandex en la gran reunión sobre Elbrus, ahora estamos compartiendo con Habr.
Brevemente, ¿qué es Elbrus?
Este es un procesador ruso con su propia arquitectura, desarrollado en el
MCST . Maxim Gorshenin habla bien de él en su canal:
www.youtube.com/watch?v=H8eBgJ58EPYBrevemente: ¿qué es PuzzleLib?
Esta es nuestra plataforma para redes neuronales, que hemos estado desarrollando y utilizando desde 2015. Análogo de Google TensorFlow y Facebook PyTorch. Curiosamente, PuzzleLib no solo admite procesadores NVIDIA e Intel, sino también tarjetas de video AMD.
Aunque tenemos una pequeña biblioteca (TensorFlow tiene aproximadamente 2 millones de líneas, tenemos 100 mil), somos mejores a la velocidad, un poco, pero mejor =)
Todavía no estamos en código abierto, la biblioteca se utiliza para nuestros proyectos. La biblioteca está completa: admite tanto la etapa de entrenamiento como la etapa de inferencia de las redes neuronales. Puede construir redes neuronales recurrentes y convolucionales, también hay una interfaz para crear gráficos arbitrarios de cálculos.
PuzzleLib tiene
- Módulos para ensamblar redes neuronales (Activación (Sigmoid, Tanh, ReLU, ELU, LeakyReLU, SoftMaxPlus), AvgPool (1D, 2D, 3D), BatchNorm (1D, 2D, 3D, ND), Conv (1D, 2D, 3D, ND) , CrossMapLRN, Deconv (1D, 2D, 3D, ND), Dropout (1D, 2D), etc.)
- Optimizadores (AdaDelta, AdaGrad, Adam, Hooks, LBFGS, MomentumSGD, NesterovSGD, RMSProp, etc.)
- Redes neuronales listas para usar (Resnet, Inception, YOLO, U-Net, etc.)
Estos son los bloques familiares, conocidos por todos los involucrados en redes neuronales, para diseñadores de redes neuronales (ya que cualquier marco es constructor que consiste en bloques y algoritmos informáticos típicos).
Tuvimos la idea de lanzar nuestra biblioteca sobre arquitectura Elbrus.
¿Por qué queríamos apoyar a Elbrus?
- Este es el único procesador ruso, quería entender cómo van las cosas con él, lo fácil que es trabajar con él.
- Pensamos que podría ser interesante para las organizaciones estatales que el software ruso que estamos desarrollando funciona en hardware ruso.
- Y, por supuesto, solo estábamos interesados, porque Elbrus es un procesador VLIW , es decir, un procesador con largas instrucciones, y no existen procesadores completos de uso general en el mundo.
Todo comenzó con el hecho de que nos reunimos con el MCST, hablamos y prestamos la computadora
Elbrus 401 para el desarrollo.
Lo que me gustó : Linux se ejecuta en Elbrus, hay Python en este Linux, y no funciona en modo de emulación: es una Python nativa completa, ensamblada para Elbrus. También hay un paquete de bibliotecas python estándar, por ejemplo, numpy, que todos los desarrolladores adoran mucho.
Hubo algunas tareas para las que tuvimos que recopilar adicionalmente bibliotecas: por ejemplo, en PuzzleLib usamos el formato hdf para almacenar los pesos de las redes neuronales, y, en consecuencia, tuvimos que construir las bibliotecas libhdf y h5py usando el compilador lcc. Pero no tuvimos problemas de montaje.
La biblioteca de visión por computadora OpenCV también ya estaba compilada, pero no había ningún enlace para Python; la construimos por separado.
La famosa biblioteca dlib también es bastante fácil de compilar. Solo hubo dificultades menores: algunos archivos de este proyecto de código abierto no tenían un marcador de bom para determinar utf-8, lo que molestó al lcc lexer. En realidad, simplemente había un formato de archivo incorrecto, que tuvo que corregirse en la fuente.
Decidimos comenzar el reconocimiento facial primero. Este es un caso de uso comprensible para muchos, donde se utiliza esta tecnología. PuzzleLib, como otras bibliotecas, tiene una parte de fondo bastante grande, es decir, una base de código específica para diferentes arquitecturas de procesador.
Nuestros backends:- CUDA (NVIDIA)
- Abrir CL + MI Abrir (AMD)
- mlkDNN (Intel)
- CPU (numpy)
En Elbrus, lanzamos un backend numpy, que era muy simple, porque la plataforma requiere un mínimo de todo:
Plataforma -> compilador c90 -> python -> numpyTenemos una biblioteca sin ningún factor de complicación (por ejemplo, sin ningún sistema de ensamblaje especial), además del hecho de que necesitábamos recolectar ciertas carpetas. Realizamos las pruebas, todo funciona, tanto las redes convolucionales como las recurrentes. El reconocimiento facial que lanzamos es bastante simple, basado en Inception-ResNet.
Primeros resultados de trabajoEn el Intel Core i7 7700, el tiempo de procesamiento para una imagen fue de 0.1 segundos, y aquí - 15. Era necesario optimizarlo.
Por supuesto, esperar que Numpy funcione bien sobre la marcha estaría mal.
Cómo optimizamos la informática
Medimos la velocidad de inferencia a través del perfilador de pitón y descubrimos que casi todo el tiempo se dedicaba a multiplicar matrices en numpy. Para la muestra, escribieron la multiplicación manual más simple de la matriz, y ya resultó ser más rápida, aunque no estaba claro por qué.
Parece que numpy.dot debería haberse escrito un poco menos ingenuo que una multiplicación tan simple. Sin embargo, convencimos, comprobamos: resultó más rápido (12 segundos por cuadro en lugar de 15).
A continuación, aprendimos sobre la biblioteca de álgebra lineal EML, que se está desarrollando en ICST, y reemplazamos las llamadas np.dot con cblas_sgemm. Se volvió 10 veces más rápido (1,5 segundos), estuvimos muy contentos.
Esto fue seguido por varias optimizaciones paso a paso. Dado que solo ejecutamos reconocimiento facial, y no datos generalmente arbitrarios, decidimos agudizar nuestras operaciones solo con tensores 4d y hacer Fusion, después de lo cual el tiempo de procesamiento disminuyó 2 veces, a 0,75 segundos.
Explicación: Fusion es cuando varias operaciones se combinan en una, por ejemplo, convolución, normalización y activación. En lugar de hacer un pase en tres ciclos, se hace un pase.
Dichas bibliotecas están disponibles en NVIDIA (
TensorRT ). Se carga un gráfico computacional y la biblioteca produce un gráfico optimizado y acelerado, en particular debido al hecho de que puede colapsar las operaciones en uno. Intel también tiene uno similar (nGraph y
OpenVINO ).
Luego vimos que, dado que había muchas convoluciones 1x1 en Inception-ResNet, teníamos que copiar datos adicionales. Decidimos especializarnos en el hecho de que trabajamos en lotes de 1 foto (es decir, no procesamos 100 fotos en lotes, sino que proporcionamos el modo de transmisión); existen casos de uso en los que no necesita trabajar con archivos, sino con una transmisión (por ejemplo, para videovigilancia o ACS). Creamos un pasaje especializado sin
im2col (copias grandes eliminadas): se convirtió en 0,45 segundos.
Luego volvimos a mirar el generador de perfiles, teníamos todo de la misma manera, aunque todas las etapas se redujeron en el tiempo, todavía dedicamos el 80% del tiempo al cálculo de bloques de inferencia convolucionales.
Nos dimos cuenta de que necesitábamos paralelizar
gemm (multiplicación de matriz general). Esa gema, que en EML, resultó ser de un solo hilo. En consecuencia, tuvimos que escribir gemm multihilo nosotros mismos. La idea es esta: una matriz grande se divide en subbloques, y luego hay una multiplicación de estas pequeñas matrices. Escribimos un gemm con OpenMP, pero no funcionó, los errores fallaron. Tomamos un grupo manual de subprocesos, la paralelización dio 0,33 segundos por fotograma.
A continuación, se nos dio acceso remoto a un servidor más potente con
Elbrus 8C , cuya velocidad aumentó a 0.2 segundos por fotograma.
El siguiente video muestra el trabajo del stand de demostración con reconocimiento facial en una computadora Elbrus 401-PC con un procesador Elbrus 4C:
Conclusiones y planes futuros
- Trabajamos no solo el reconocimiento facial, sino en principio un marco de red neuronal, por lo que podemos recopilar cualquier detector, clasificador y ejecutarlo en Elbrus.
- Hemos reunido un stand de demostración con Web-UI para demostrar el reconocimiento facial en PuzzleLib.
- El reconocimiento facial en Elbrus ya es lo suficientemente rápido para tareas prácticas, luego puede acelerarlo si es necesario.
- Puedes trabajar con Elbrus. Solíamos trabajar con procesadores exóticos, por ejemplo, con procesadores rusos tensores que aún se están desarrollando, con tarjetas de video AMD y su software. No todo es tan bueno y simple allí. Es decir, si tomamos la biblioteca MI Open de AMD, esta es una biblioteca muy mal escrita en la que no todas las combinaciones de zancadas, rellenos y tamaños de filtro conducen a cálculos exitosos. La calidad de las herramientas de Elbrus es buena: si tiene un proyecto en Python, C o C ++, ejecutarlo en Elbrus no es nada difícil.
- También vale la pena señalar que el trabajo de optimización paso a paso del que hablamos no son operaciones específicas para trabajar en Elbrus. Estas son operaciones estándar de procesador multinúcleo. En nuestra opinión, esta es una buena señal de que el procesador puede funcionar como un procesador normal de Intel / NVIDIA.
Planes:
- Dado que Elbrus tiene la peculiaridad de ser un procesador VLIW, se pueden realizar algunas optimizaciones específicas para Elbrus.
- Realice la cuantización (trabajando con int8 en lugar de float32), lo que ahorra memoria y aumenta la velocidad. En consecuencia, en este caso, por supuesto, puede haber una reducción en la calidad de los cálculos, pero esto puede no ser así. Hemos notado ambos casos en la práctica.
Planeamos comprender mejor, explorar las capacidades del procesador VLIW. De hecho, por ahora, solo confiamos en el compilador porque si escribimos un buen código, el compilador lo optimiza bien, porque conoce las características de Elbrus.
En general, fue interesante, lo entenderemos más. Esto no llevó mucho tiempo: todas las operaciones de portabilidad tardaron un total de una semana.
En enero de 2020 planeamos poner PuzzleLib en código abierto, escribiremos más sobre esto aquí =)
Gracias por su atencion!