Esta y las siguientes guías lo guiarán a través del proceso de creación de una solución basada en el proyecto Discovery.js . Nuestro objetivo es crear un inspector para las dependencias de NPM, es decir, una interfaz para examinar la estructura de node_modules .
Nota: Discovery.js se encuentra en una etapa temprana de desarrollo, por lo que con el tiempo, algo se simplificará y se volverá más útil. Si tiene ideas sobre cómo mejorar algo, escríbanos .
Anotación
A continuación encontrará una descripción general de los conceptos clave de Discovery.js. Puede aprender el código manual completo en el repositorio en GitHub , o puede probar cómo funciona en línea .
Condiciones iniciales
En primer lugar, debemos elegir un proyecto para el análisis. Este puede ser un proyecto recién creado o uno existente, lo principal es que contiene node_modules (el objeto de nuestro análisis).
Primero, instale el paquete core discoveryjs y sus herramientas de consola:
npm install @discoveryjs/discovery @discoveryjs/cli
A continuación, inicie el servidor Discovery.js:
> npx discovery No config is used Models are not defined (model free mode is enabled) Init common routes ... OK Server listen on http://localhost:8123
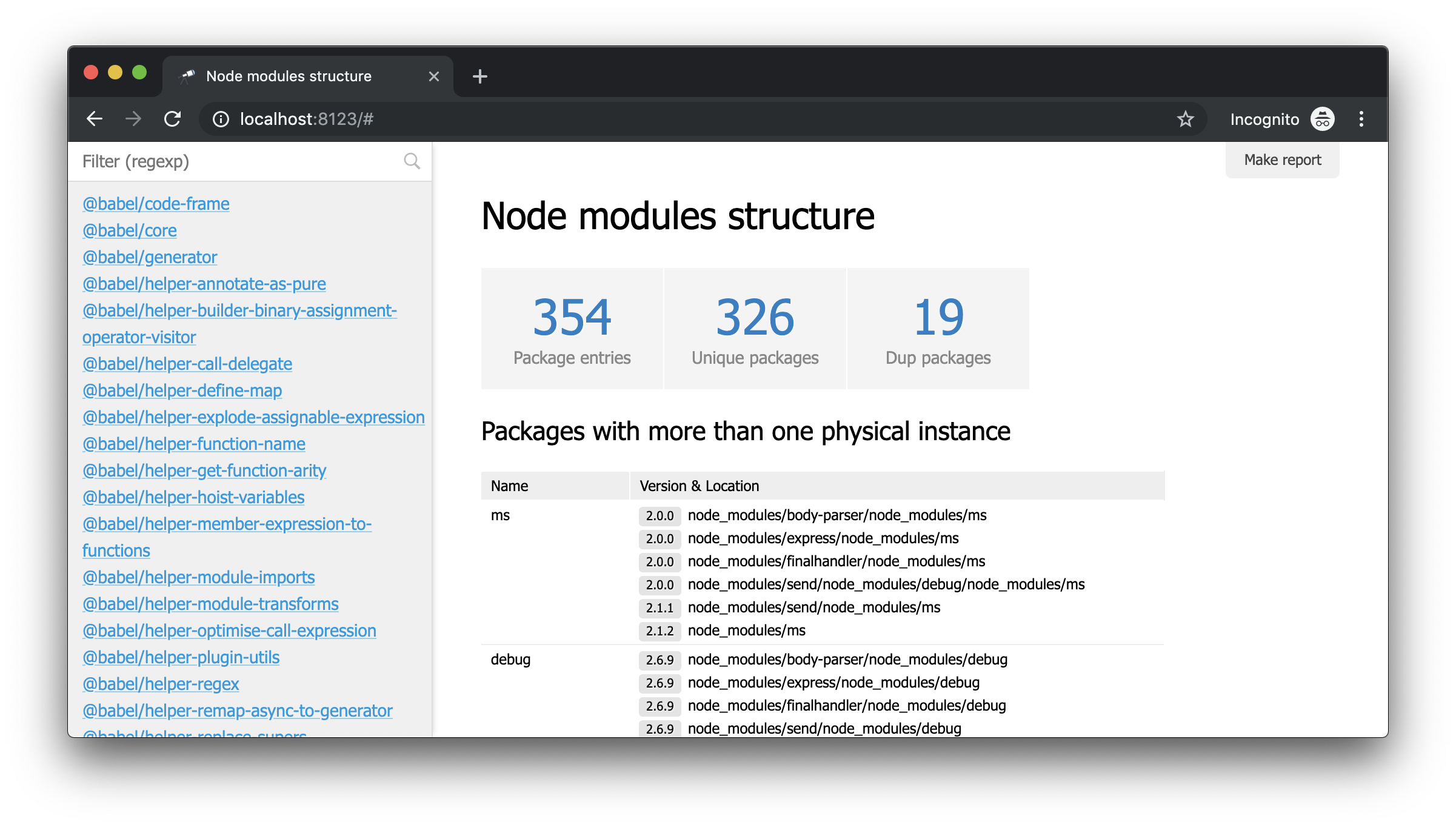
Si abre http://localhost:8123 en el navegador, puede ver lo siguiente:

Este es un modo sin modelo, es decir, un modo cuando no hay nada configurado. Pero ahora, usando el botón "Cargar datos", puede seleccionar cualquier archivo JSON, o simplemente arrastrarlo a la página e iniciar el análisis.
Sin embargo, necesitamos algo específico. En particular, necesitamos obtener una vista de la estructura node_modules . Para hacer esto, agregue la configuración.
Agregar configuración
Como habrá notado, el mensaje No config is used mostró cuando se inició el servidor. .discoveryrc.js un archivo de configuración .discoveryrc.js con el siguiente contenido:
module.exports = { name: 'Node modules structure', data() { return { hello: 'world' }; } };
Nota: si crea un archivo en el directorio de trabajo actual (es decir, en la raíz del proyecto), no se requiere nada más. De lo contrario, debe pasar la ruta al archivo de configuración utilizando la opción --config , o establecer la ruta en package.json :
{ ... "discovery": "path/to/discovery/config.js", ... }
Reinicie el servidor para que se aplique la configuración:
> npx discovery Load config from .discoveryrc.js Init single model default Define default routes ... OK Cache: DISABLED Init common routes ... OK Server listen on http://localhost:8123
Como puede ver, ahora se utiliza el archivo que creamos. Y se aplica el modelo predeterminado descrito por nosotros (Discovery puede funcionar en el modo de muchos modelos, hablaremos sobre esta característica en los siguientes manuales). Veamos qué ha cambiado en el navegador:
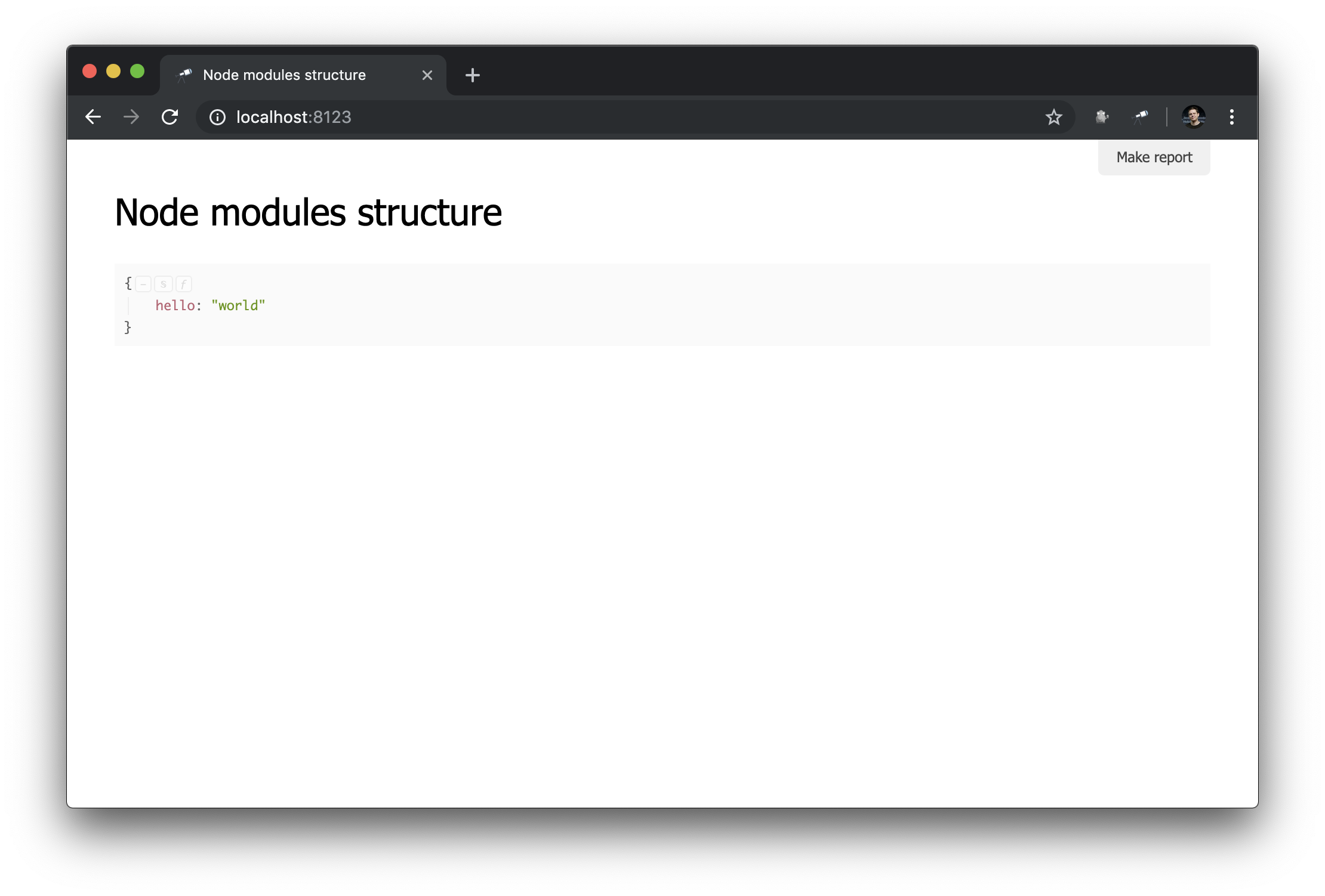
Lo que se puede ver aquí:
name usa como título de la página;- El resultado de llamar al método de
data se muestra como el contenido principal de la página.
Nota: el método de data debe devolver datos o Promesa, que se resuelve en datos.
Se realizan ajustes básicos, puede seguir adelante.
Contexto
Veamos la página del informe personalizado (haga clic en Make report ):
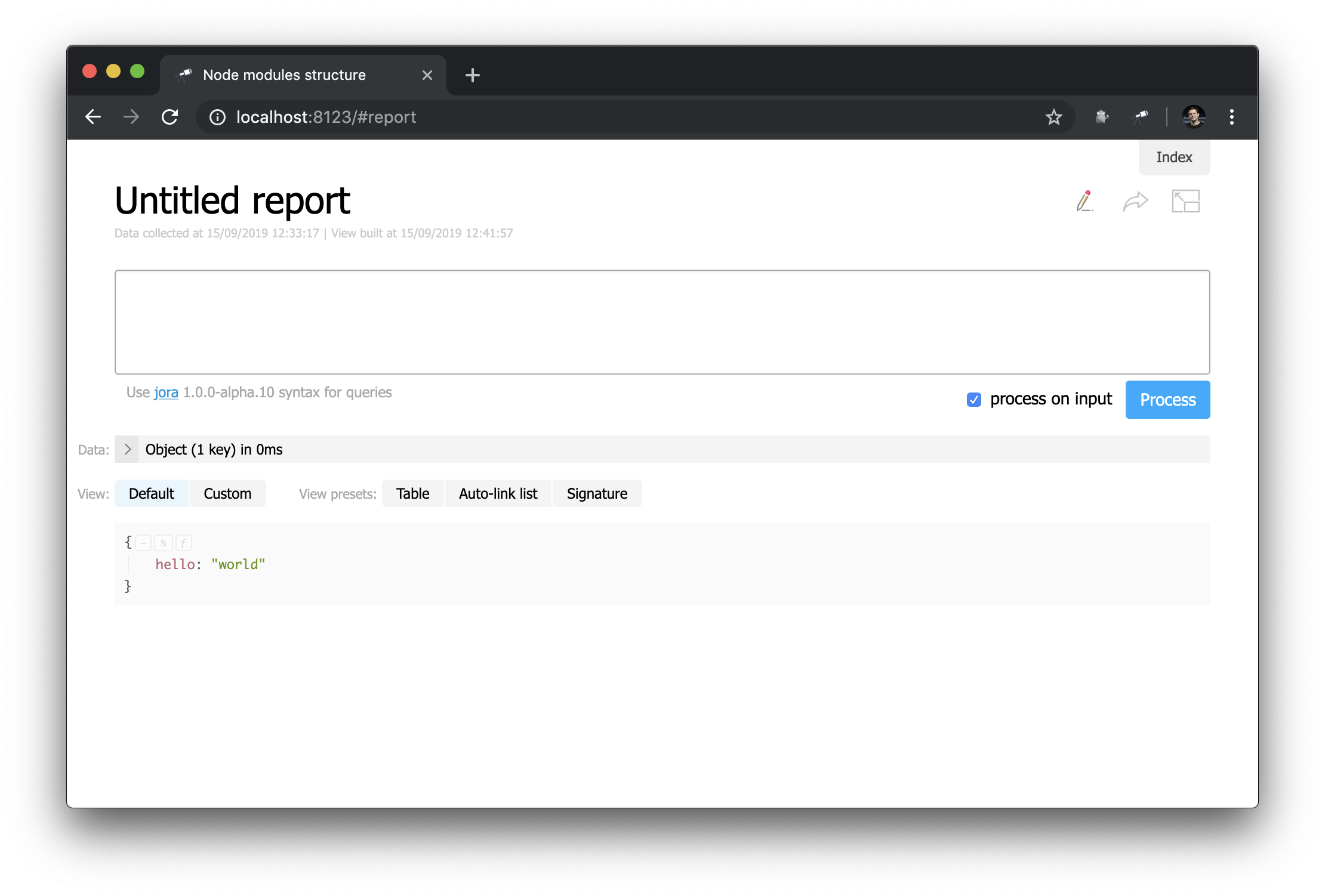
A primera vista, esto no es muy diferente de la página de inicio ... ¡Pero aquí puedes cambiar todo! Por ejemplo, podemos recrear fácilmente la apariencia de la página de inicio:
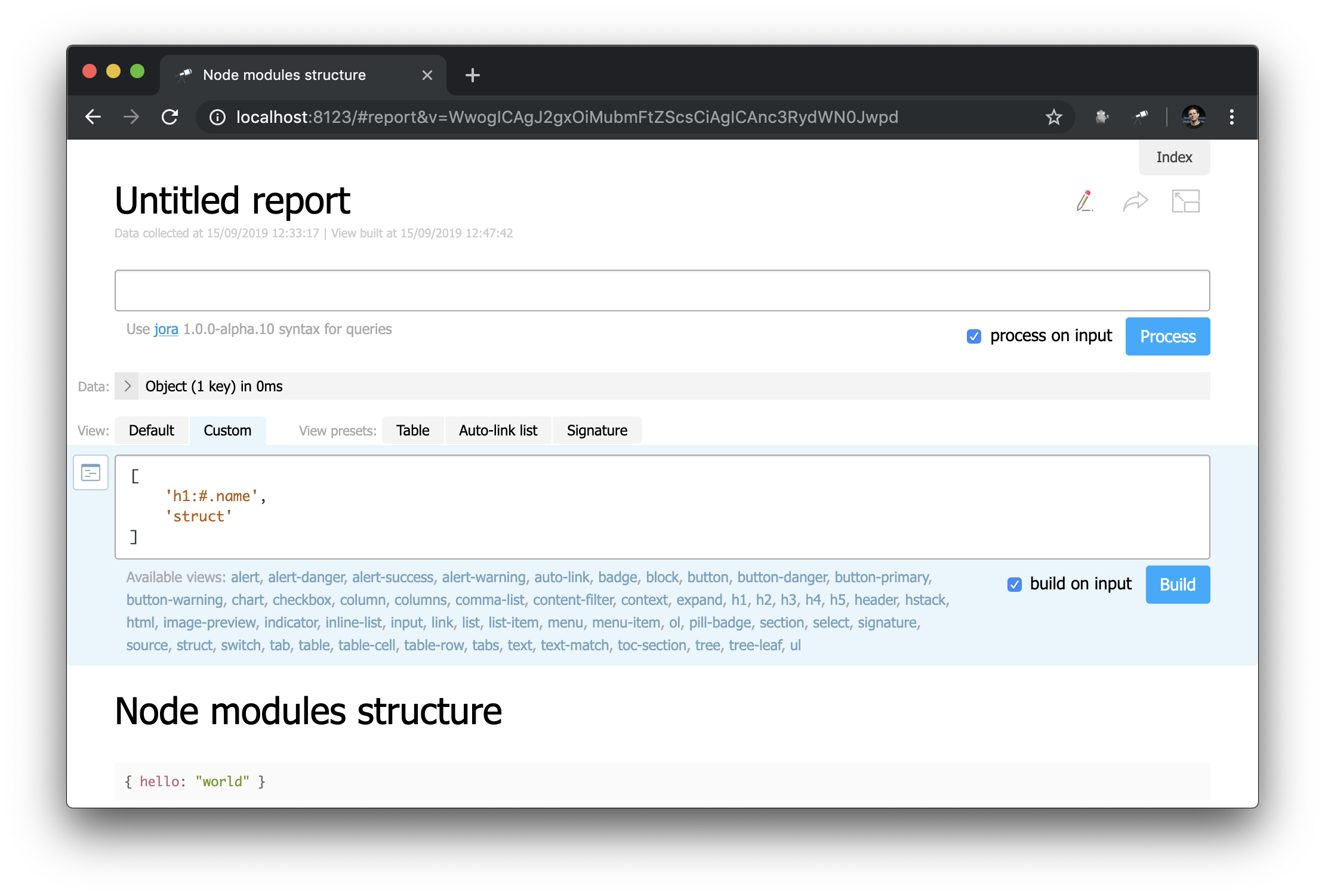
Observe cómo se define el encabezado: "h1:#.name" . Este es el encabezado de primer nivel con el contenido de #.name , que es una solicitud de Jora . # refiere al contexto de la solicitud. Para ver su contenido, simplemente ingrese # en el editor de consultas y use la pantalla predeterminada:
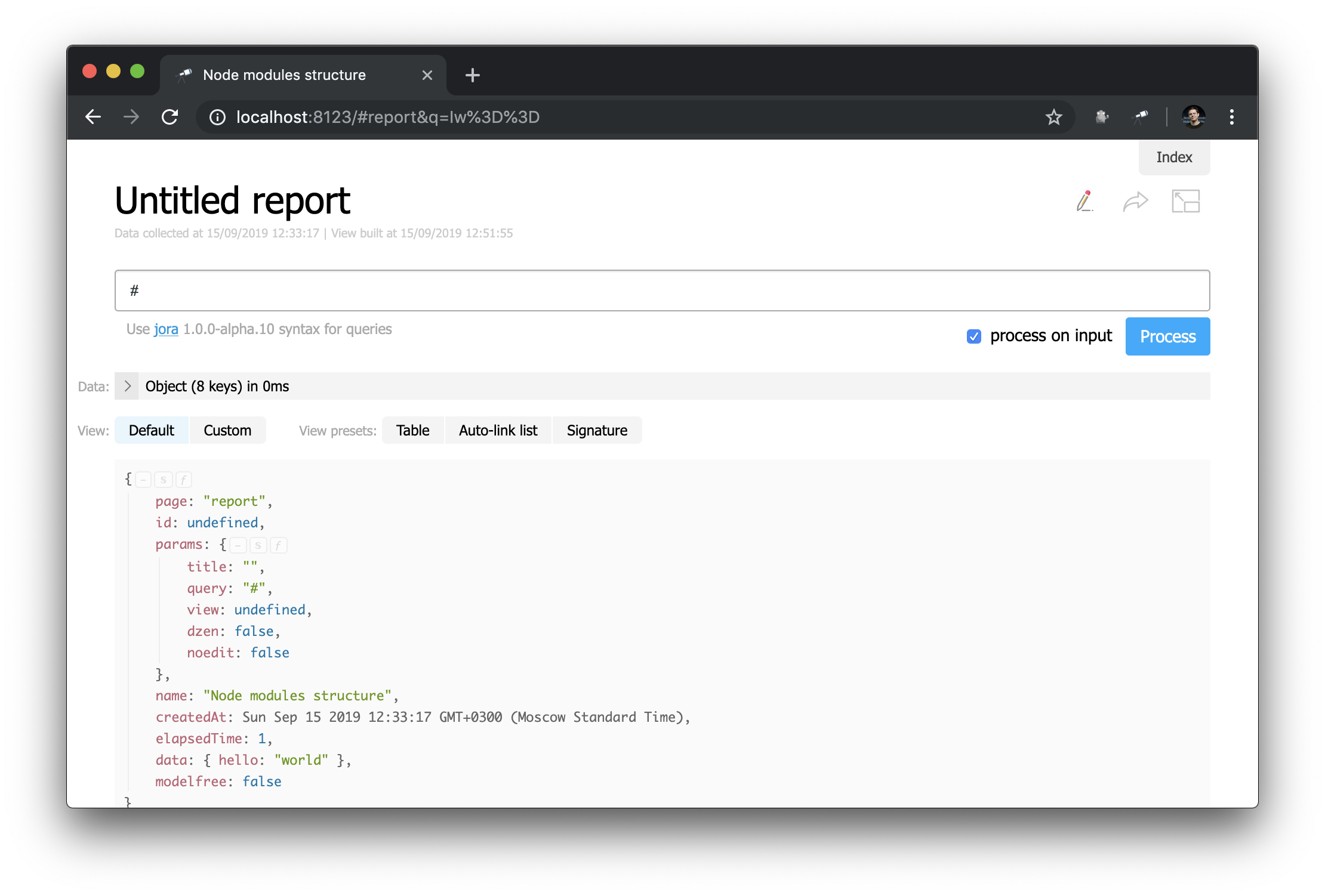
Ahora ya sabe cómo obtener la ID de la página actual, sus parámetros y otros valores útiles.
Recogida de datos
Ahora usamos un trozo en el proyecto en lugar de datos reales, pero necesitamos datos reales. Para hacer esto, cree un módulo y cambie el valor de los data en la configuración (por cierto, después de estos cambios no es necesario reiniciar el servidor):
module.exports = { name: 'Node modules structure', data: require('./collect-node-modules-data') };
El contenido de collect-node-modules-data.js :
const path = require('path'); const scanFs = require('@discoveryjs/scan-fs'); module.exports = function() { const packages = []; return scanFs({ include: ['node_modules'], rules: [{ test: /\/package.json$/, extract: (file, content) => { const pkg = JSON.parse(content); if (pkg.name && pkg.version) { packages.push({ name: pkg.name, version: pkg.version, path: path.dirname(file.filename), dependencies: pkg.dependencies }); } } }] }).then(() => packages); };
@discoveryjs/scan-fs paquete @discoveryjs/scan-fs , que simplifica el escaneo del sistema de archivos. Un ejemplo de uso del paquete se describe en su archivo Léame, tomé este ejemplo como base y lo finalicé según fue necesario. Ahora tenemos información sobre el contenido de node_modules :
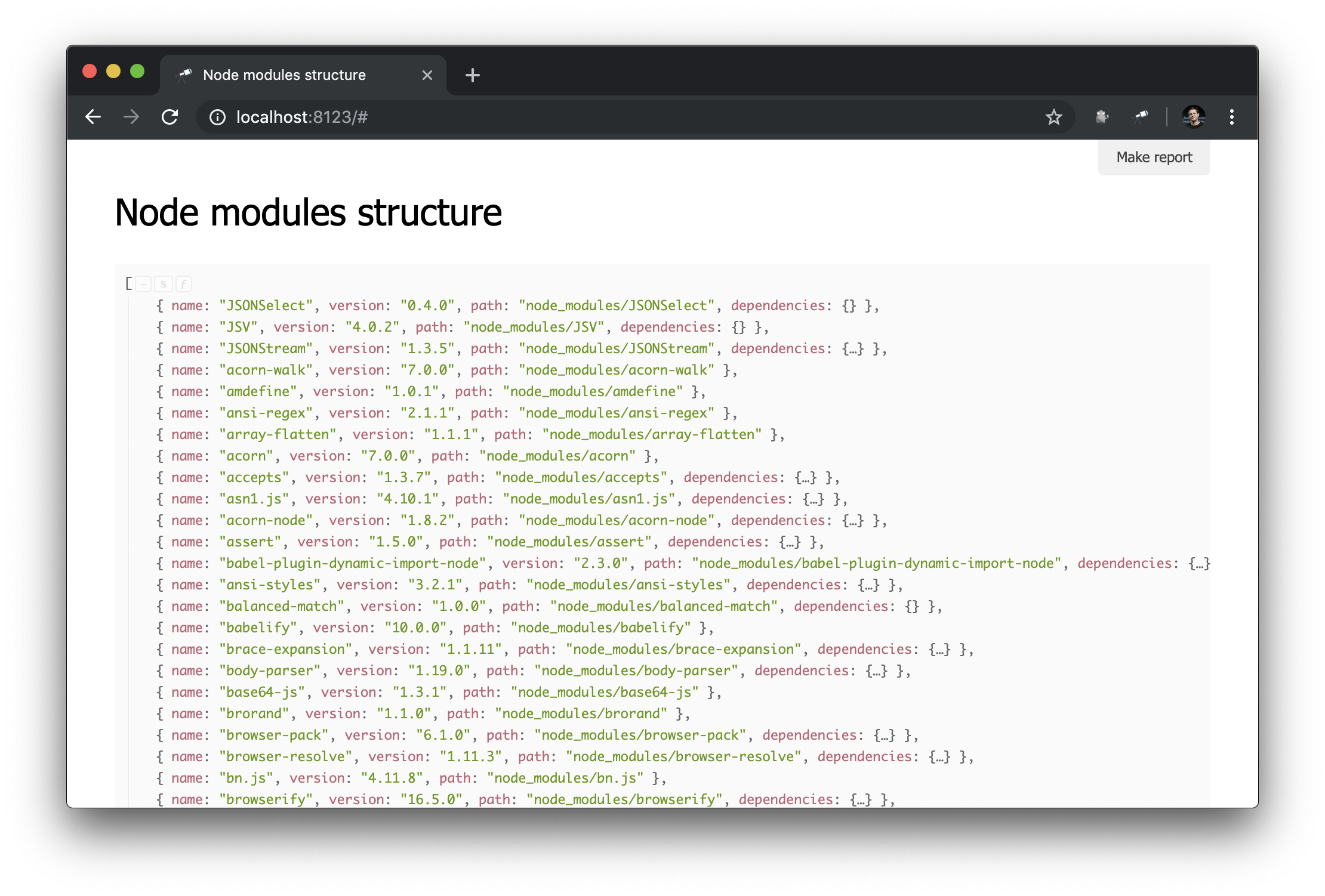
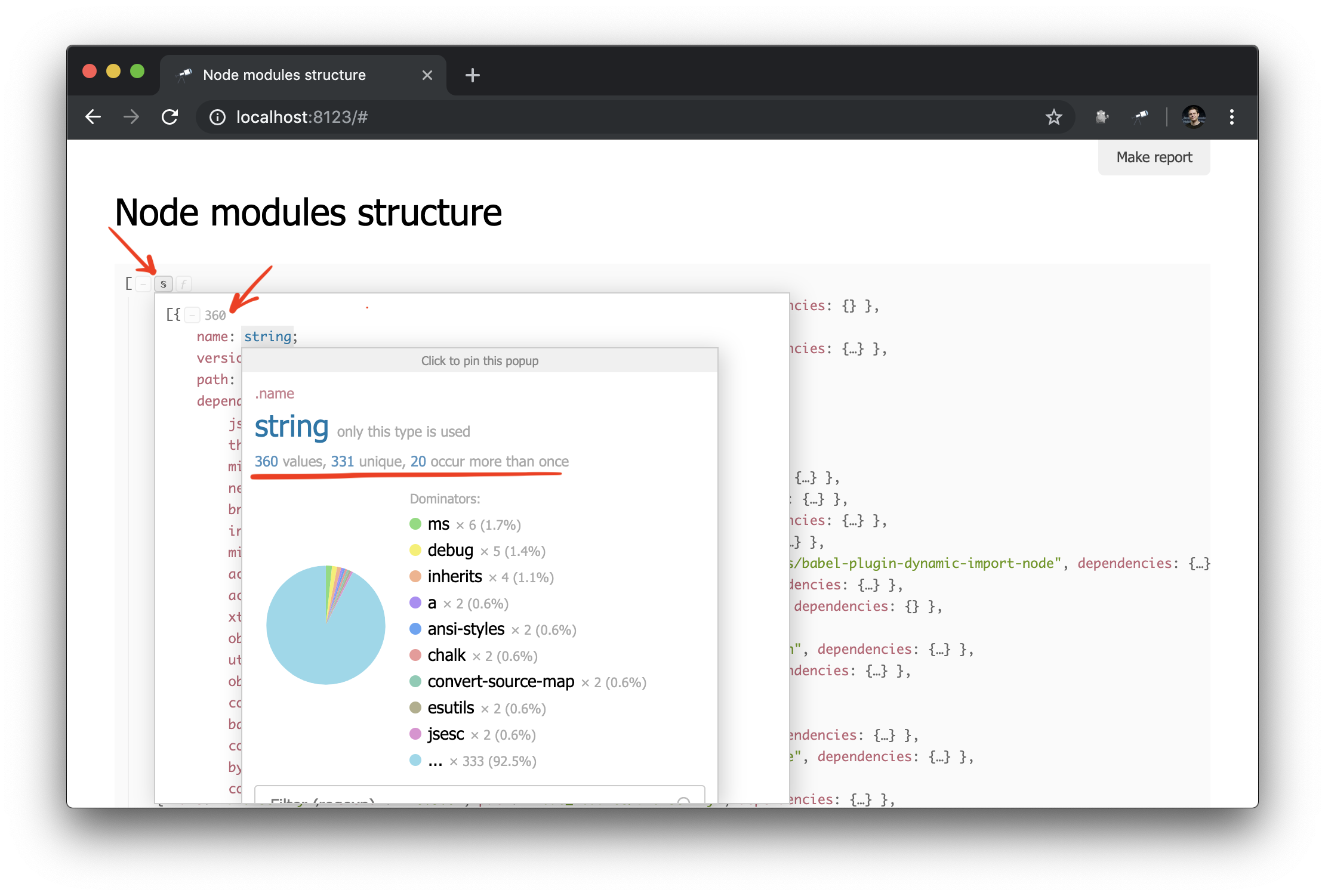
Lo que necesitas! Y a pesar del hecho de que este es JSON ordinario, ya podemos analizarlo y sacar algunas conclusiones. Por ejemplo, utilizando la ventana emergente de la estructura de datos, puede averiguar la cantidad de paquetes y determinar cuántos de ellos tienen más de una instancia física (debido a diferencias de versión o problemas con su deduplicación).
A pesar de que ya tenemos algunos datos, necesitamos más detalles. Por ejemplo, sería bueno saber qué instancia física resuelve cada una de las dependencias declaradas de un módulo en particular. Sin embargo, el trabajo para mejorar la extracción de datos está más allá del alcance de esta guía. Por lo tanto, lo reemplazaremos con el paquete @discoveryjs/node-modules (que también se basa en @discoveryjs/scan-fs ) para recuperar los datos y obtener los detalles necesarios sobre los paquetes. Como resultado, collect-node-modules-data.js simplifica enormemente:
const fetchNodeModules = require('@discoveryjs/node-modules'); module.exports = function() { return fetchNodeModules(); };
Ahora la información sobre node_modules ve así:
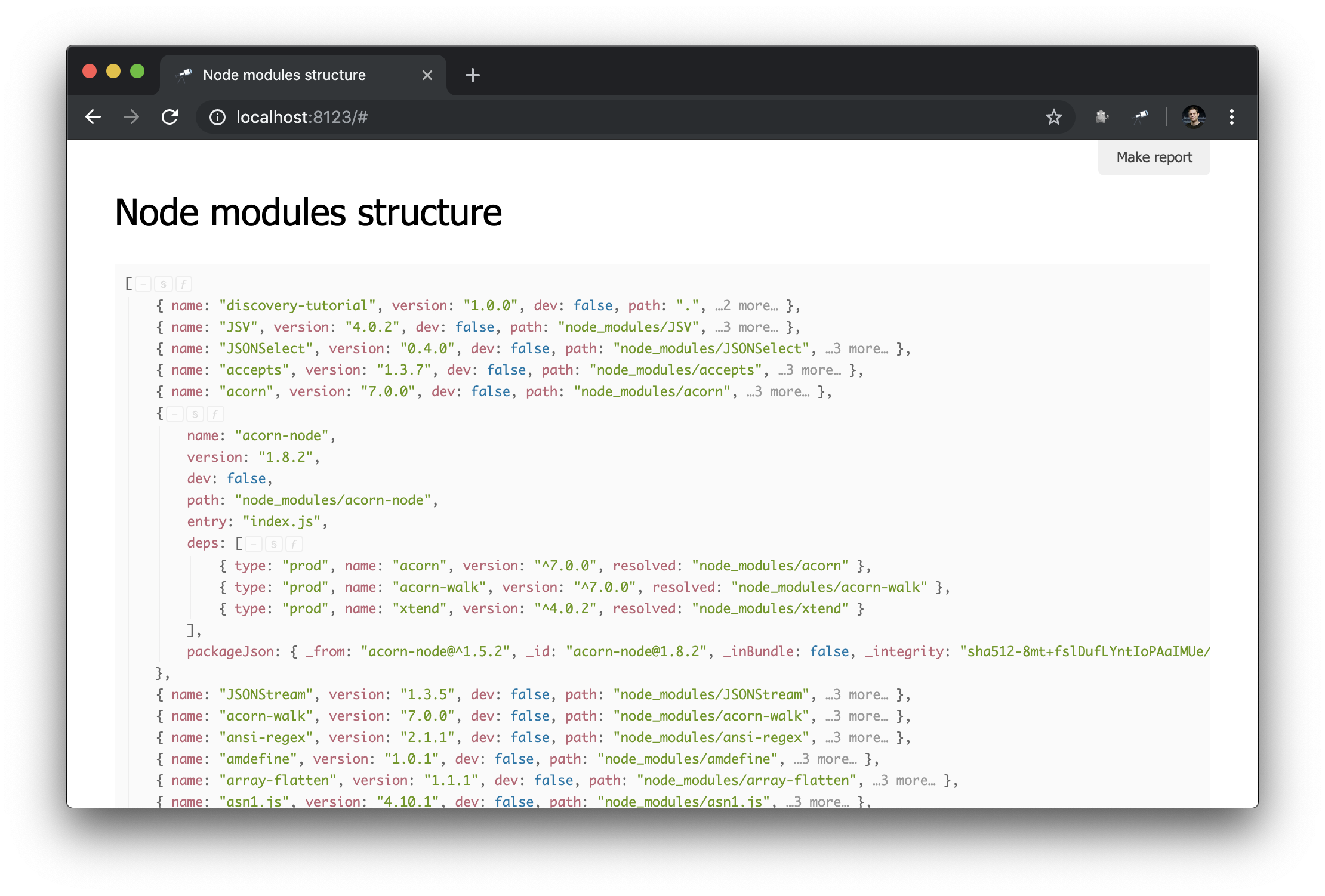
Guion de preparacion
Como habrás notado, algunos objetos que describen paquetes contienen deps , una lista de dependencias. Cada dependencia tiene un campo resolved cuyo valor es una referencia a una instancia física del paquete. Tal enlace es el valor de path de uno de los paquetes, es único. Para resolver el enlace al paquete, debe usar código adicional (por ejemplo, #.data.pick(<path=resolved>) ). Y, por supuesto, sería mucho más conveniente si dichos enlaces ya se resolvieran en referencias a objetos.
Desafortunadamente, en la etapa de recopilación de datos, no podemos resolver los enlaces, ya que esto conducirá a conexiones circulares, lo que creará el problema de transferir dichos datos en forma de JSON. Sin embargo, hay una solución: este es un script de prepare especial. Se define en la configuración y se llama cada vez que se asigna un nuevo dato a la instancia de Discovery. Comencemos con la configuración:
module.exports = { ... prepare: __dirname + '/prepare.js',
Definir prepare.js :
discovery.setPrepare(function(data) {
En este módulo, definimos la función de prepare para la instancia Discovery. Esta función se llama cada vez antes de aplicar datos a la instancia de Discovery. Este es un buen lugar para permitir valores en referencias de objeto:
discovery.setPrepare(function(data) { const packageIndex = data.reduce((map, pkg) => map.set(pkg.path, pkg), new Map()); data.forEach(pkg => pkg.deps.forEach(dep => dep.resolved = packageIndex.get(dep.resolved) ) ); });
Aquí hemos creado un índice de paquete en el que la clave es el valor de la path del paquete (único). Luego revisamos todos los paquetes y sus dependencias, y en las dependencias reemplazamos el valor resolved con una referencia al objeto del paquete. Resultado:
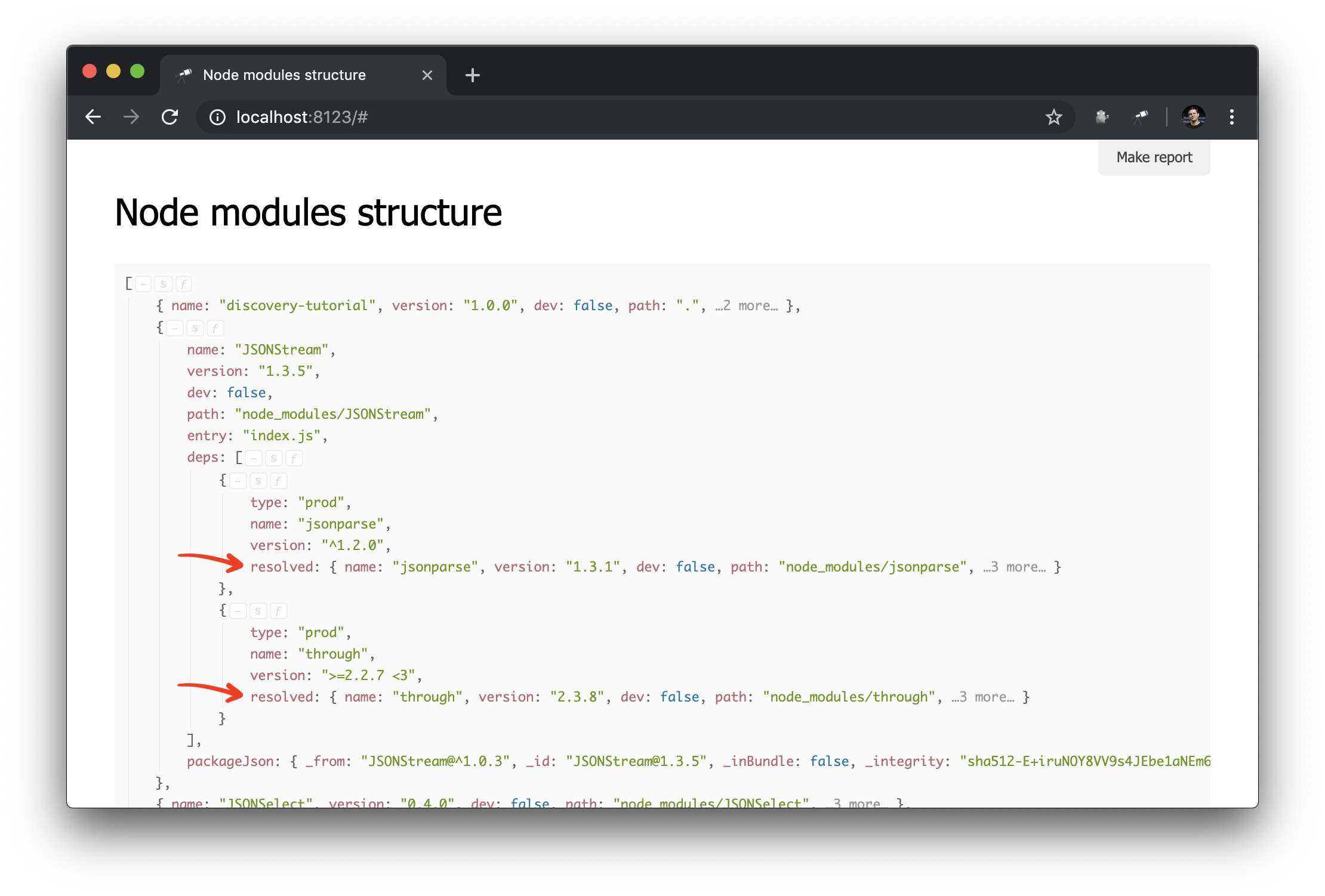
Ahora es mucho más fácil hacer consultas de gráficos de dependencia. Así es como puede obtener un grupo de dependencias (es decir, dependencias, dependencias de dependencia, etc.) para un paquete específico:
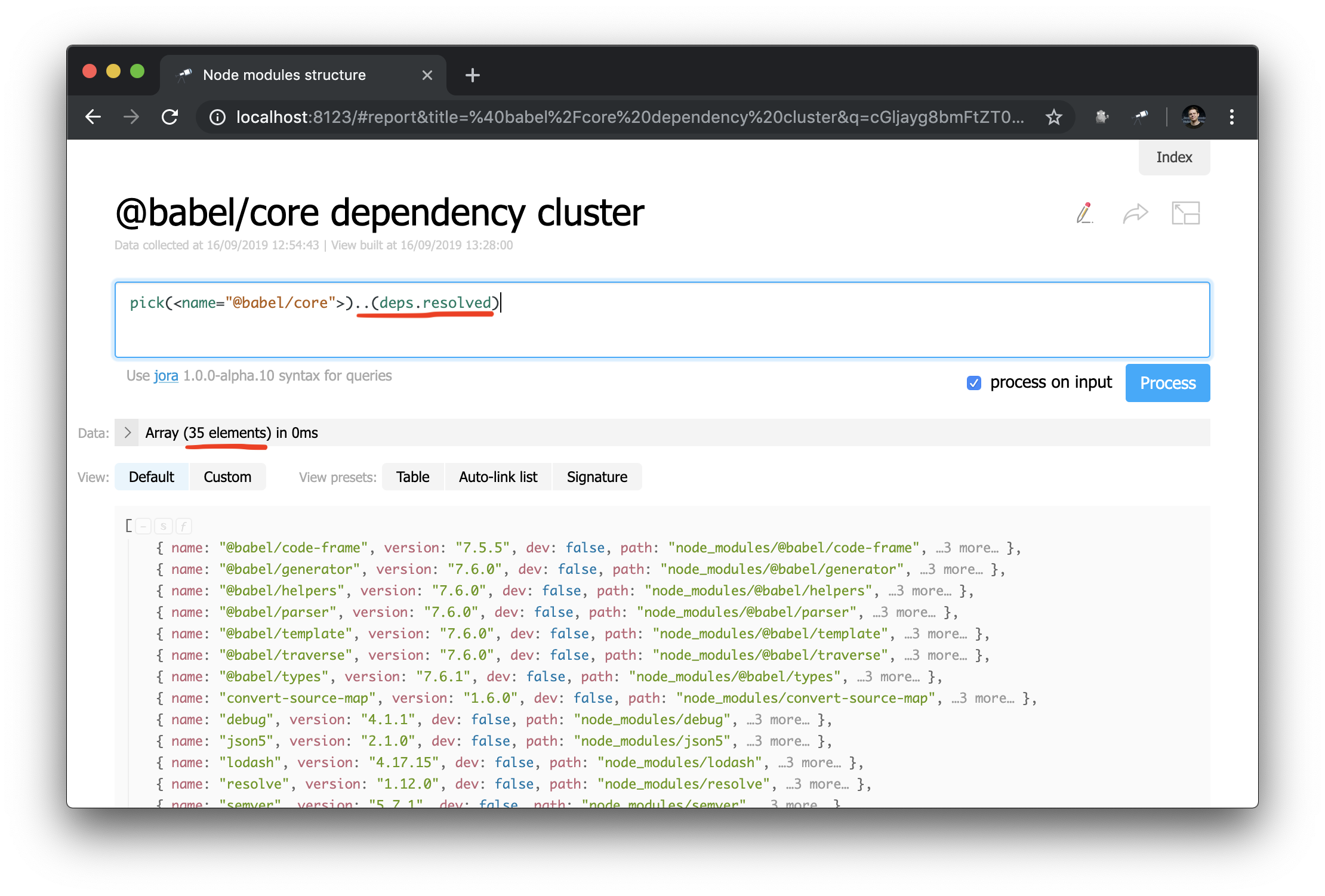
Una historia de éxito inesperada: mientras estudiaba los datos durante la redacción del manual, encontré un problema en @discoveryjs/cli (usando la consulta .[deps.[not resolved]] ), que tenía un error tipográfico en las dependencias de pares. El problema se solucionó de inmediato. El caso es un buen ejemplo de cómo ayudan estas herramientas.
Quizás ha llegado el momento de mostrar en la página de inicio varios números y paquetes con tomas.
Personalizar página de inicio
Primero, necesitamos crear un módulo de página, por ejemplo, pages/default.js . Usamos el default , porque este es el identificador de la página de inicio, que podemos anular (en Discovery.js, puede anular mucho). Comencemos con algo simple, por ejemplo:
discovery.page.define('default', [ 'h1:#.name', 'text:"Hello world!"' ]);
Ahora en la configuración necesita conectar el módulo de página:
module.exports = { name: 'Node modules structure', data: require('./collect-node-modules-data'), view: { assets: [ 'pages/default.js'
Comprobar en el navegador:
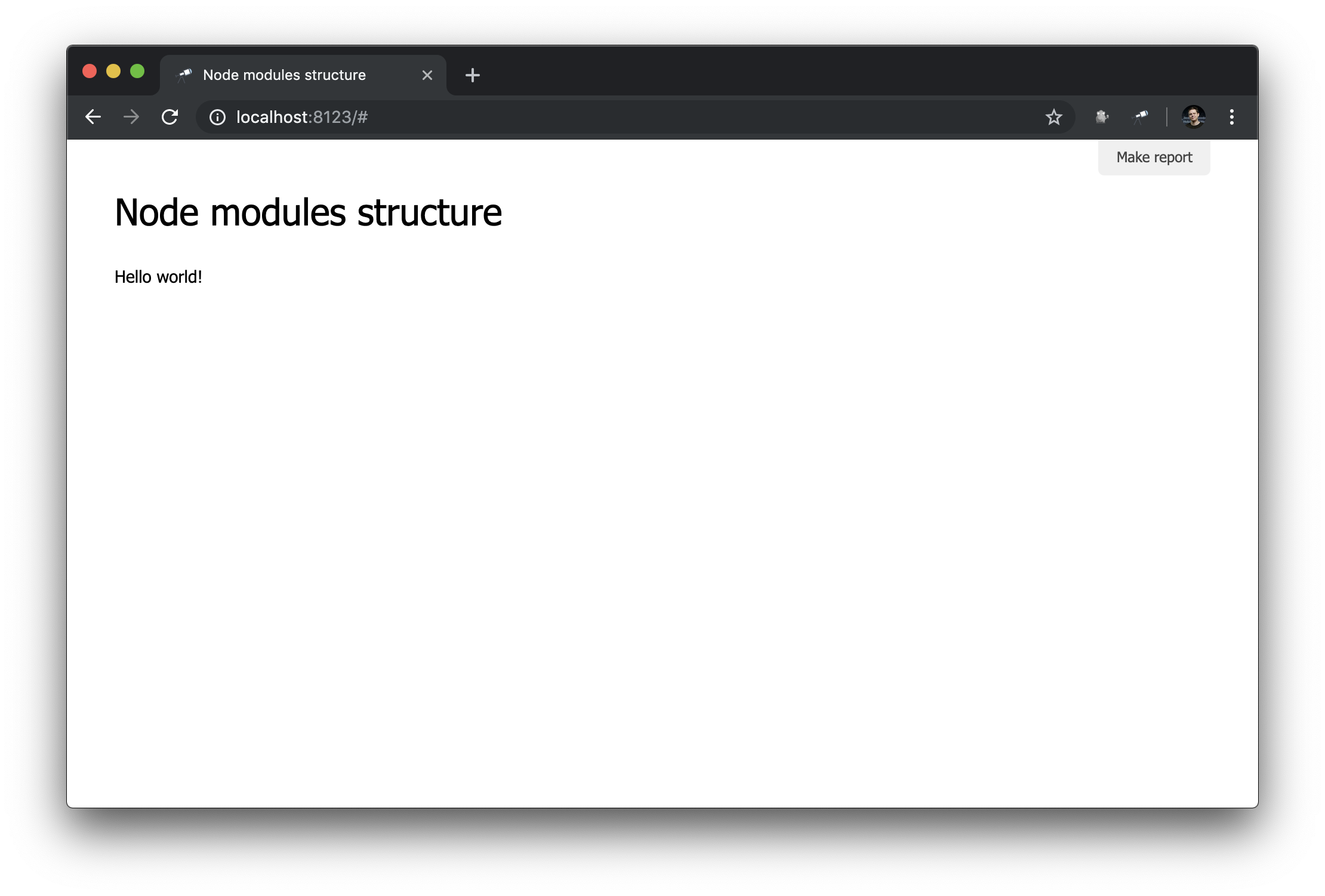
Funciona!
Ahora consigamos algunos contadores. Para hacer esto, realice cambios en pages/default.js :
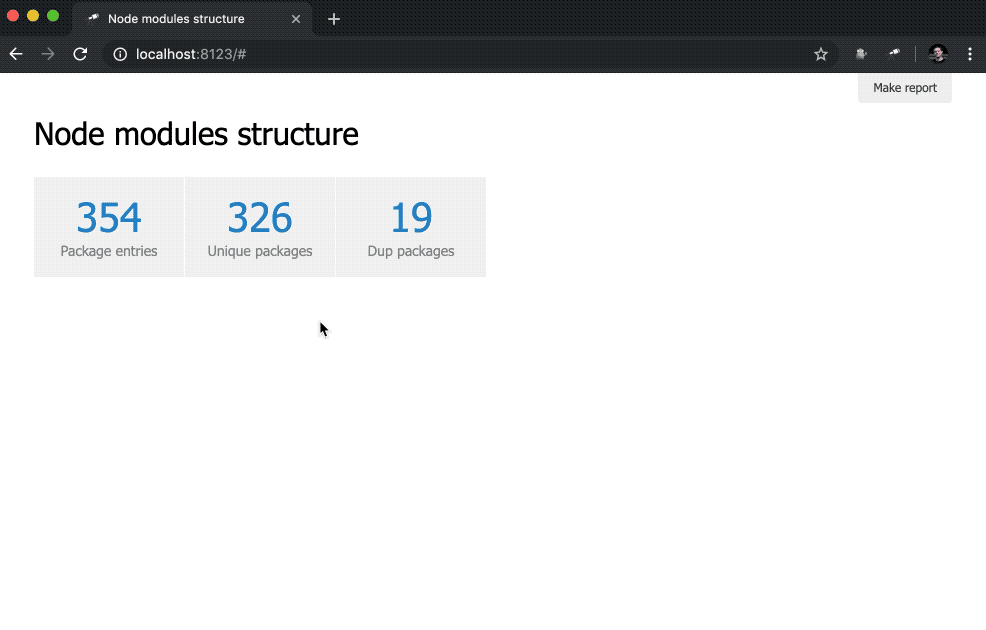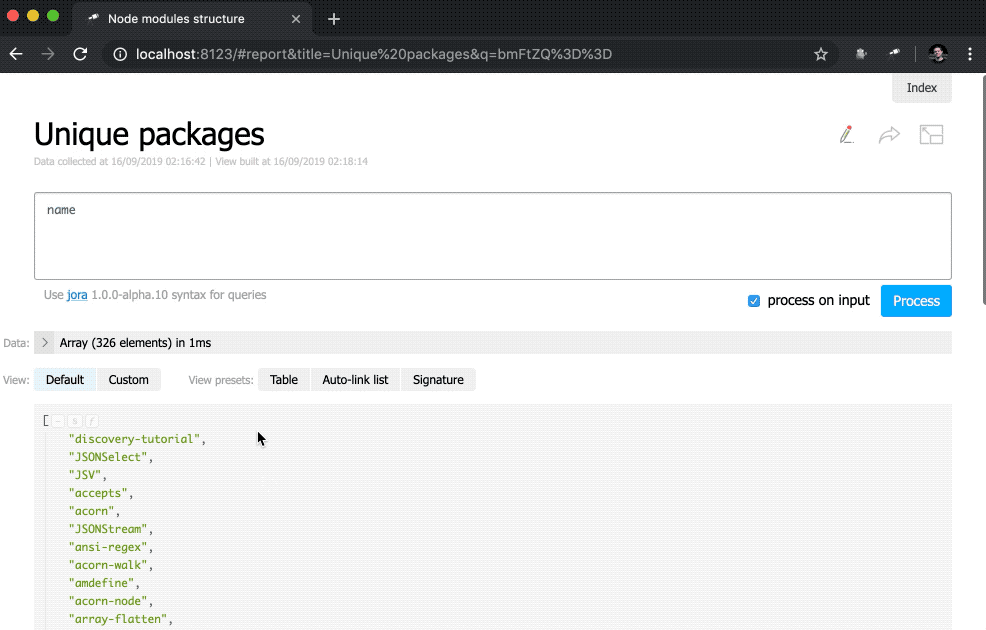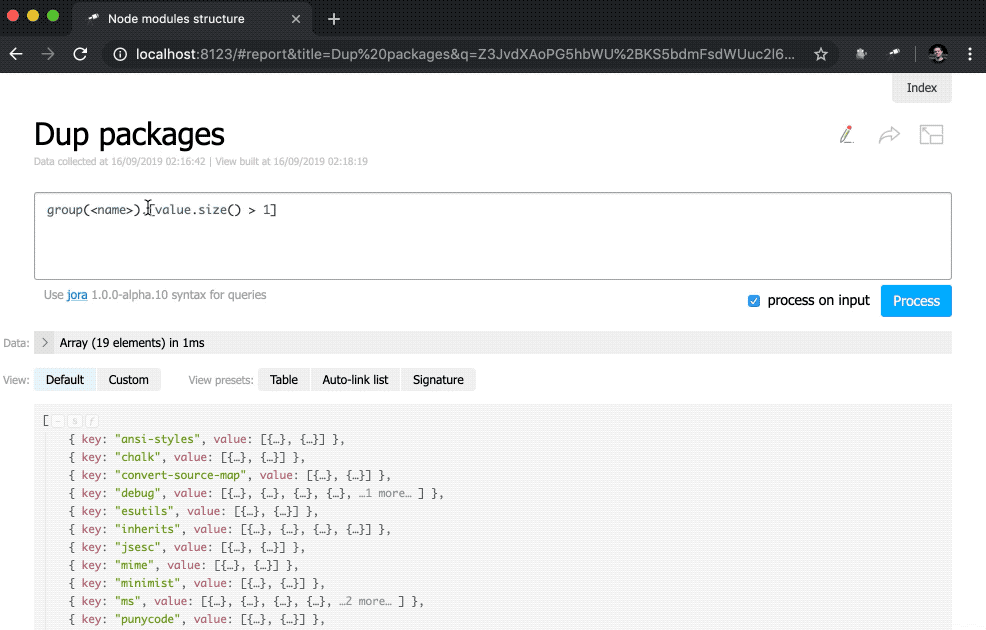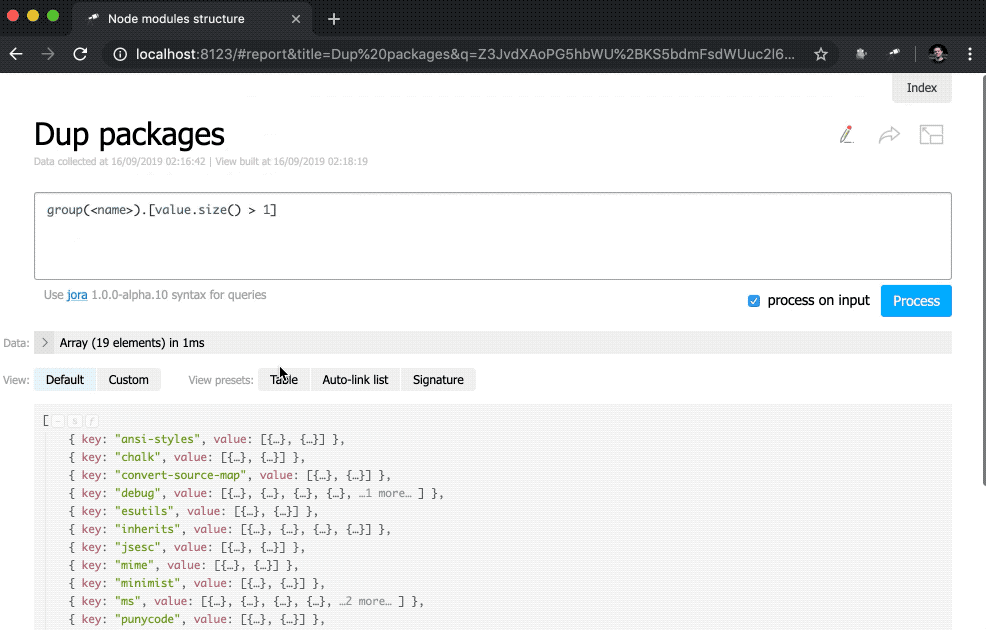
discovery.page.define('default', [ 'h1:#.name', { view: 'inline-list', item: 'indicator', data: `[ { label: 'Package entries', value: size() }, { label: 'Unique packages', value: name.size() }, { label: 'Dup packages', value: group(<name>).[value.size() > 1].size() } ]` } ]);
Aquí definimos una lista en línea de indicadores. El valor de los data es una consulta de Jora que crea una matriz de registros. La lista de paquetes (raíz de datos) se utiliza como base para las consultas, por lo que obtenemos la longitud de la lista ( size() ), la cantidad de nombres de paquetes únicos ( name.size() ) y la cantidad de nombres de paquetes que tienen duplicados ( group(<name>).[value.size() > 1].size() ).
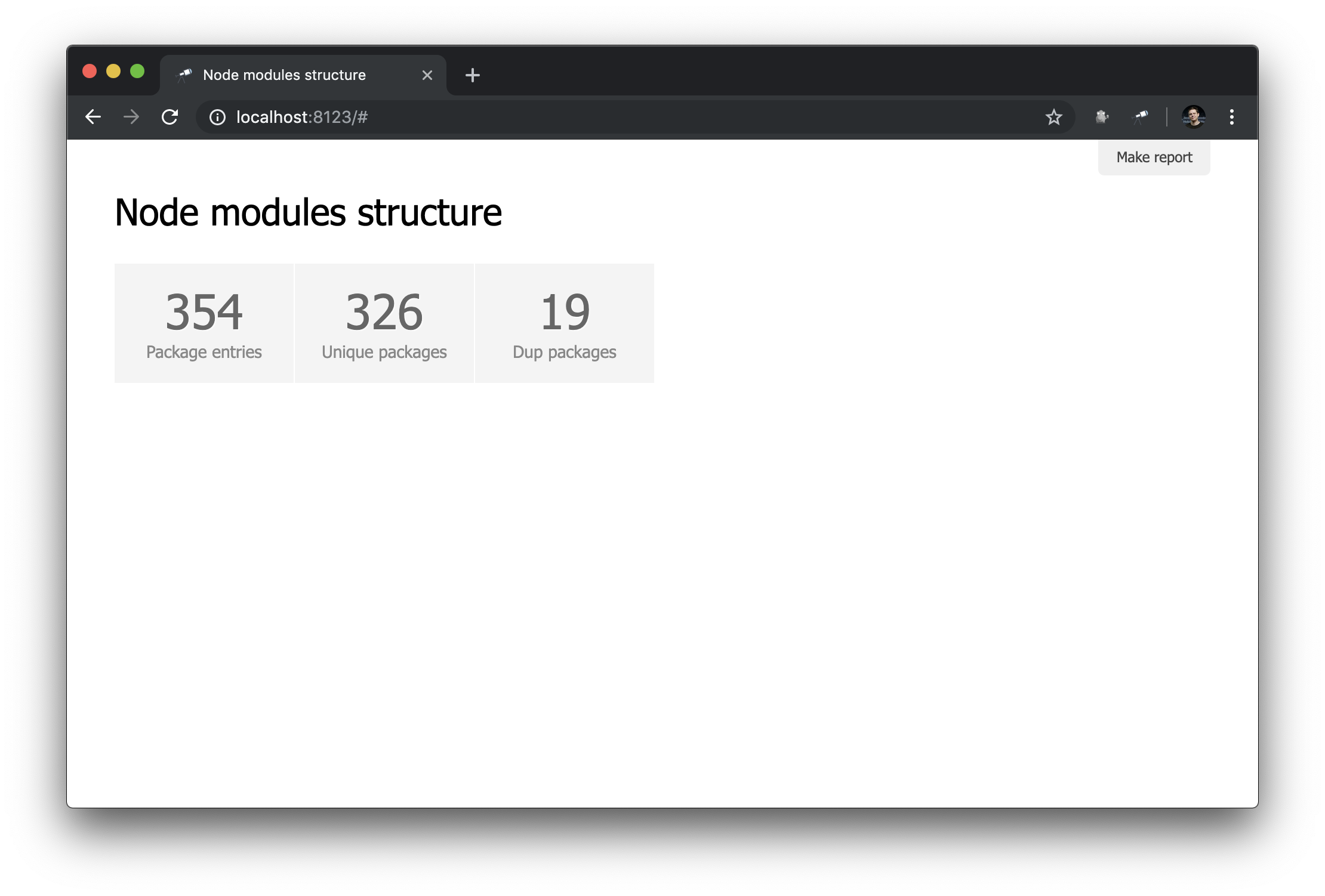
No esta mal. Sin embargo, sería mejor tener, además de números, enlaces a las muestras correspondientes:
discovery.page.define('default', [ 'h1:#.name', { view: 'inline-list', data: [ { label: 'Package entries', value: '' }, { label: 'Unique packages', value: 'name' }, { label: 'Dup packages', value: 'group(<name>).[value.size() > 1]' } ], item: `indicator:{ label, value: value.query(#.data, #).size(), href: pageLink('report', { query: value, title: label }) }` } ]);
En primer lugar, cambiamos el valor de los data , ahora es una matriz regular con algunos objetos. Además, el método size() se ha eliminado de las solicitudes de valor.
Además, se ha agregado una subconsulta a la vista del indicator . Estos tipos de consultas crean un nuevo objeto para cada elemento en el que se calculan el value y href . Por value , una consulta se ejecuta utilizando el método query() , al que se transfieren datos del contexto, y luego el método size() se aplica al resultado de la consulta. Para href , se utiliza el método pageLink() , que genera un enlace a la página del informe con una solicitud y un encabezado específicos. Después de todos estos cambios, los indicadores se hicieron clic (tenga en cuenta que sus valores se han vuelto azules) y más funcionales.
Para que la página de inicio sea más útil, agregue una tabla con paquetes que tengan duplicados.
discovery.page.define('default', [
La tabla utiliza los mismos datos que el indicador de Dup packages . La lista de paquetes se ordenó por tamaño de grupo en orden inverso. El resto de la configuración está relacionada con las columnas (por cierto, por lo general, no es necesario configurarlas). Para la columna Version & Location , definimos una lista anidada (ordenada por versión), en la que cada elemento es un par del número de versión y la ruta a la instancia.
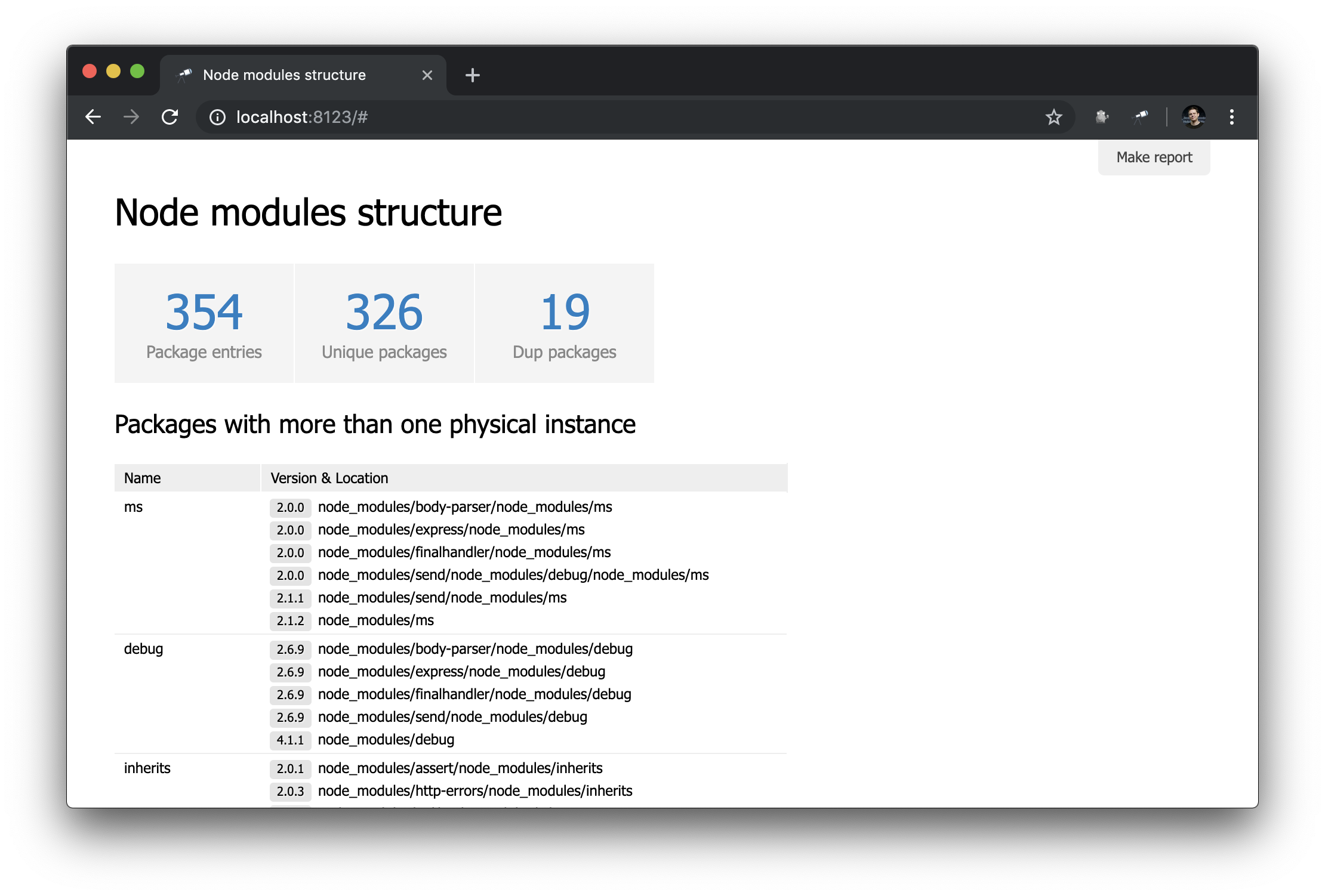
Página del paquete
Ahora solo tenemos una descripción general de los paquetes. Pero sería útil tener una página con detalles sobre un paquete en particular. Para hacer esto, cree un nuevo módulo de pages/package.js y defina una nueva página:
discovery.page.define('package', { view: 'context', data: `{ name: #.id, instances: .[name = #.id] }`, content: [ 'h1:name', 'table:instances' ] });
En este módulo, definimos la página con el package identificador. El componente de context se utilizó como representación inicial. Este es un componente no visual que le ayuda a definir datos para asignaciones anidadas. Tenga en cuenta que utilizamos #.id para obtener el nombre del paquete, que se recupera de una URL como esta http://localhost:8123/#package:{id} .
No olvide incluir el nuevo módulo en la configuración:
module.exports = { ... view: { assets: [ 'pages/default.js', 'pages/package.js'
Resultado en el navegador:
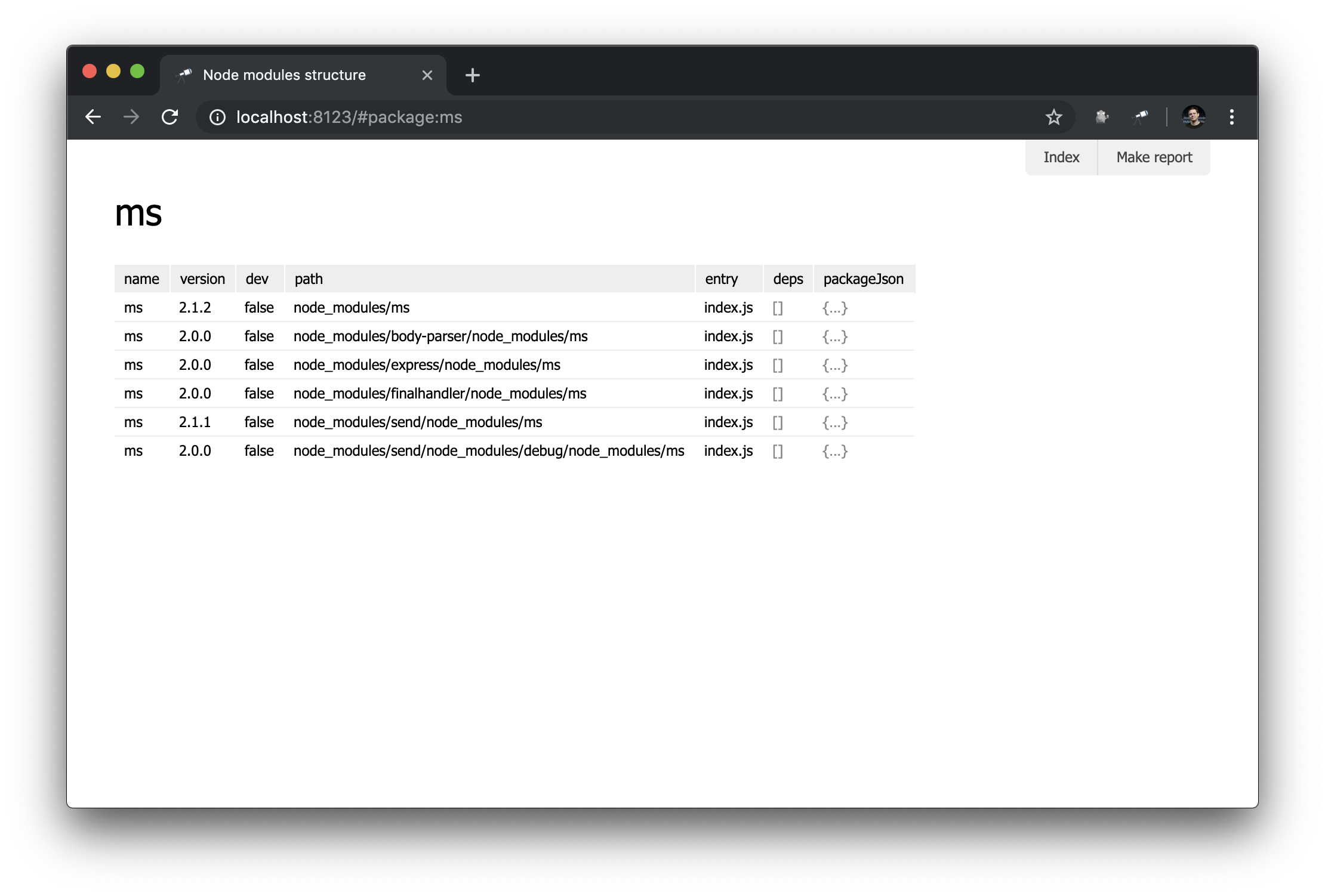
No es demasiado impresionante, pero por ahora. Crearemos mapeos más complejos en manuales posteriores.
Panel lateral
Como ya tenemos una página de paquetes, sería bueno tener una lista de todos los paquetes. Para hacer esto, puede definir una vista especial: sidebar , que se muestra si está definida (no está definida de manera predeterminada). Cree un nuevo módulo views/sidebar.js :
discovery.view.define('sidebar', { view: 'list', data: 'name.sort()', item: 'link:{ text: $, href: pageLink("package") }' });
Ahora tenemos una lista de todos los paquetes:
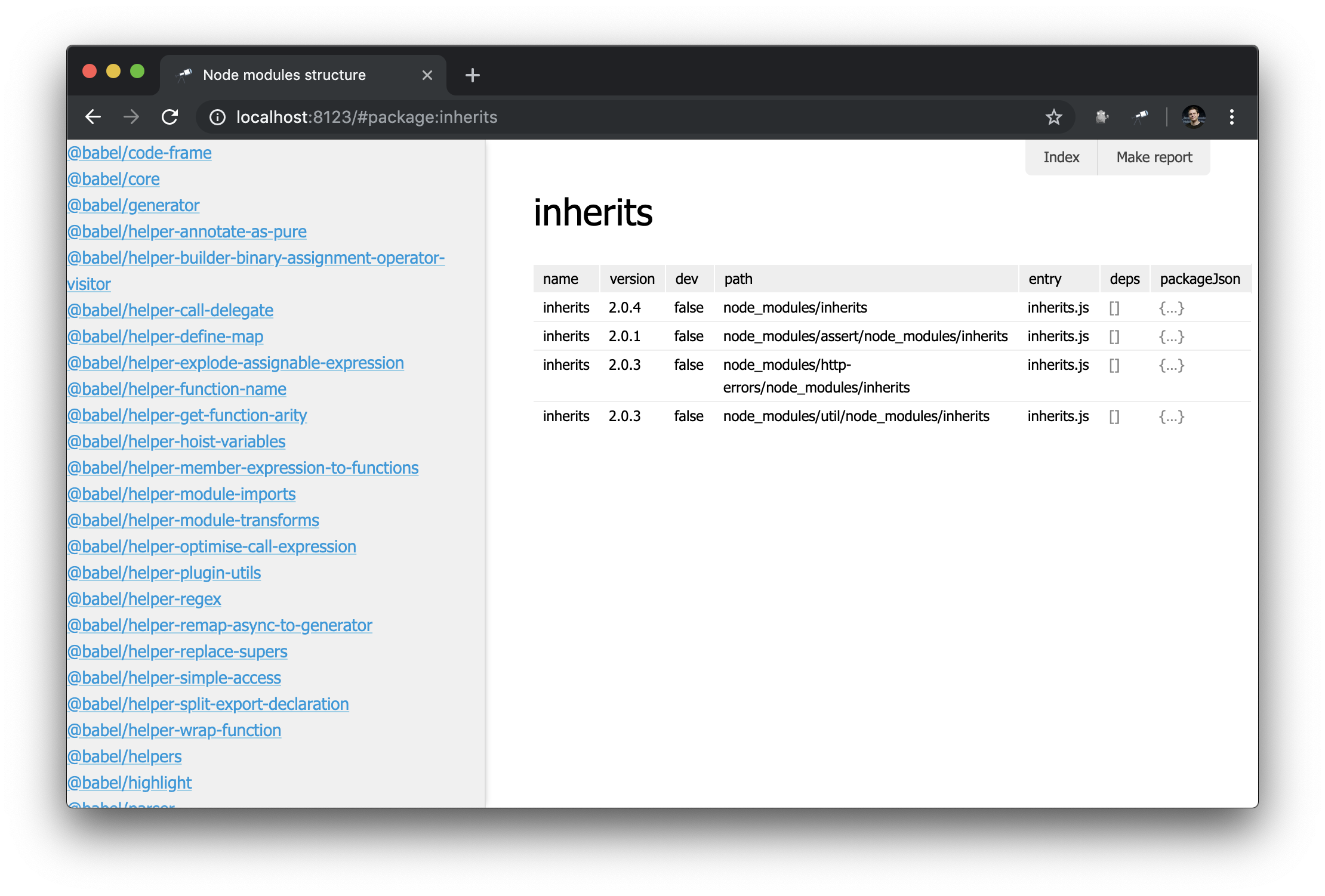
Se ve bien Pero con un filtro sería aún mejor. Ampliamos la definición de sidebar :
discovery.view.define('sidebar', { view: 'content-filter', content: { view: 'list', data: 'name.[no #.filter or $~=#.filter].sort()', item: { view: 'link', data: '{ text: $, href: pageLink("package"), match: #.filter }', content: 'text-match' } } });
Aquí ajustamos la lista en un componente de content-filter que convierte el valor de entrada en el campo de entrada a expresiones regulares (o null si el campo está vacío) y lo guarda como un valor de filter en el contexto (el nombre se puede cambiar con la opción de name ). Además, para filtrar los datos de la lista, utilizamos #.filter . Finalmente, aplicamos mapeo de enlaces para resaltar partes coincidentes con text-match Resultado:

En caso de que no le guste el diseño predeterminado, puede personalizar los estilos como desee. Supongamos que desea cambiar el ancho de la barra lateral, para esto necesita crear un archivo de estilo (por ejemplo, views/sidebar.css ):
.discovery-sidebar { width: 300px; }
Y agregue un enlace a este archivo en la configuración, así como a los módulos de JavaScript:
module.exports = { ... view: { assets: [ ... 'views/sidebar.css',
Enlaces automáticos
El capítulo final de esta guía está dedicado a los enlaces. Anteriormente, utilizando el método pageLink() , hicimos un enlace a la página del paquete. Pero además del enlace, también debe establecer el texto del enlace. ¿Pero cómo lo haríamos más fácil?
Para simplificar el trabajo de los enlaces, necesitamos definir una regla para generar enlaces. Esto se hace mejor en el script de prepare :
discovery.setPrepare(function(data) { ... const packageIndex = data.reduce( (map, item) => map .set(item, item)
Agregamos un nuevo mapa (índice) de paquetes y lo usamos para resolver entidades. El solucionador de entidades intenta, si es posible, convertir el valor que se le pasa en un descriptor de entidad. El descriptor contiene:
type - tipo de entidadid : una referencia única a una instancia de entidad utilizada en enlaces como IDname : se usa como texto de enlace
Finalmente, debe asignar este tipo a una página específica (el enlace debe llevar a alguna parte, ¿verdad?).
discovery.page.define('package', { ... }, { resolveLink: 'package'
La primera consecuencia de estos cambios es que algunos valores en la vista de struct ahora están marcados con un enlace a la página del paquete:
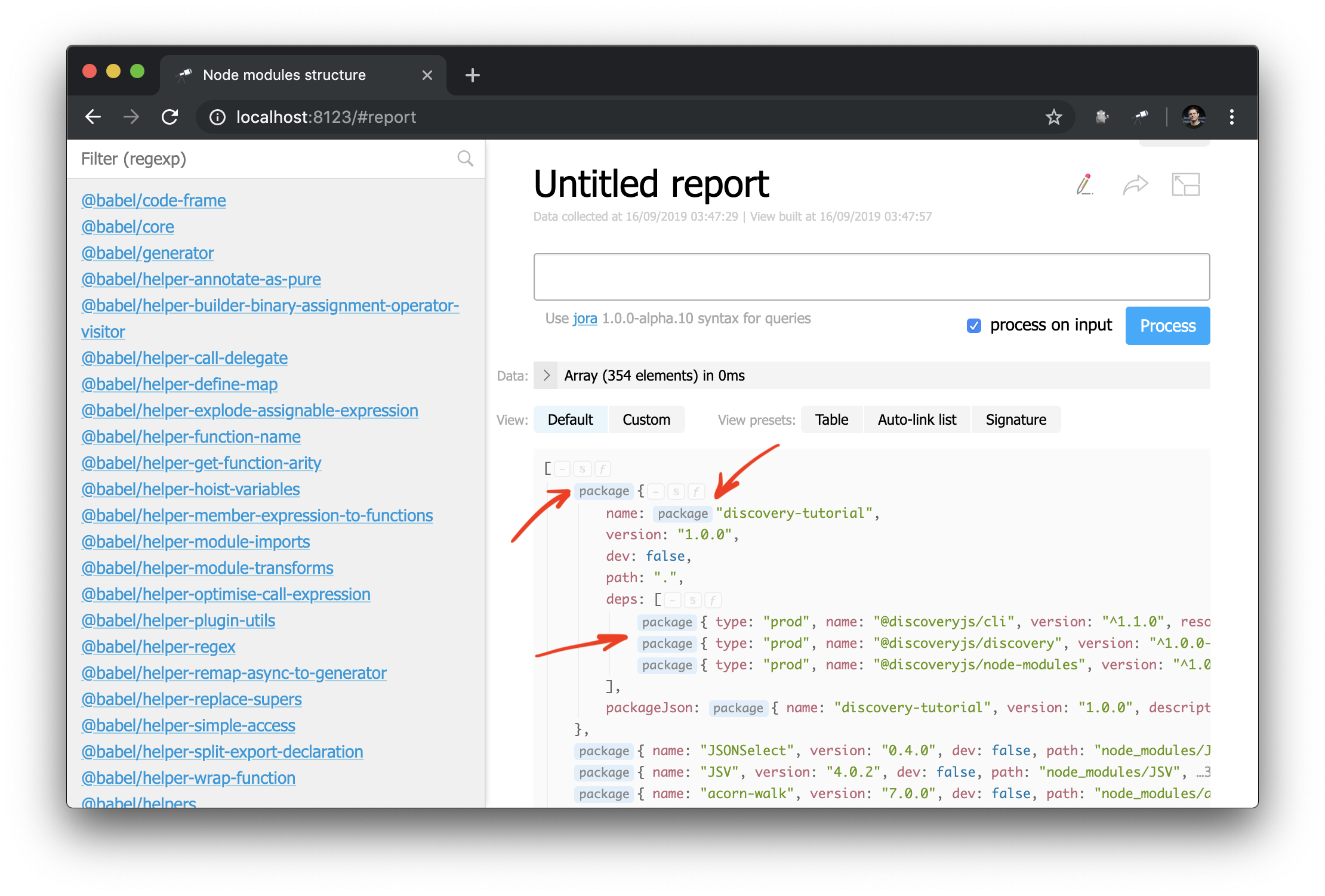
Y ahora también puede aplicar el componente de auto-link a un objeto o nombre de paquete:
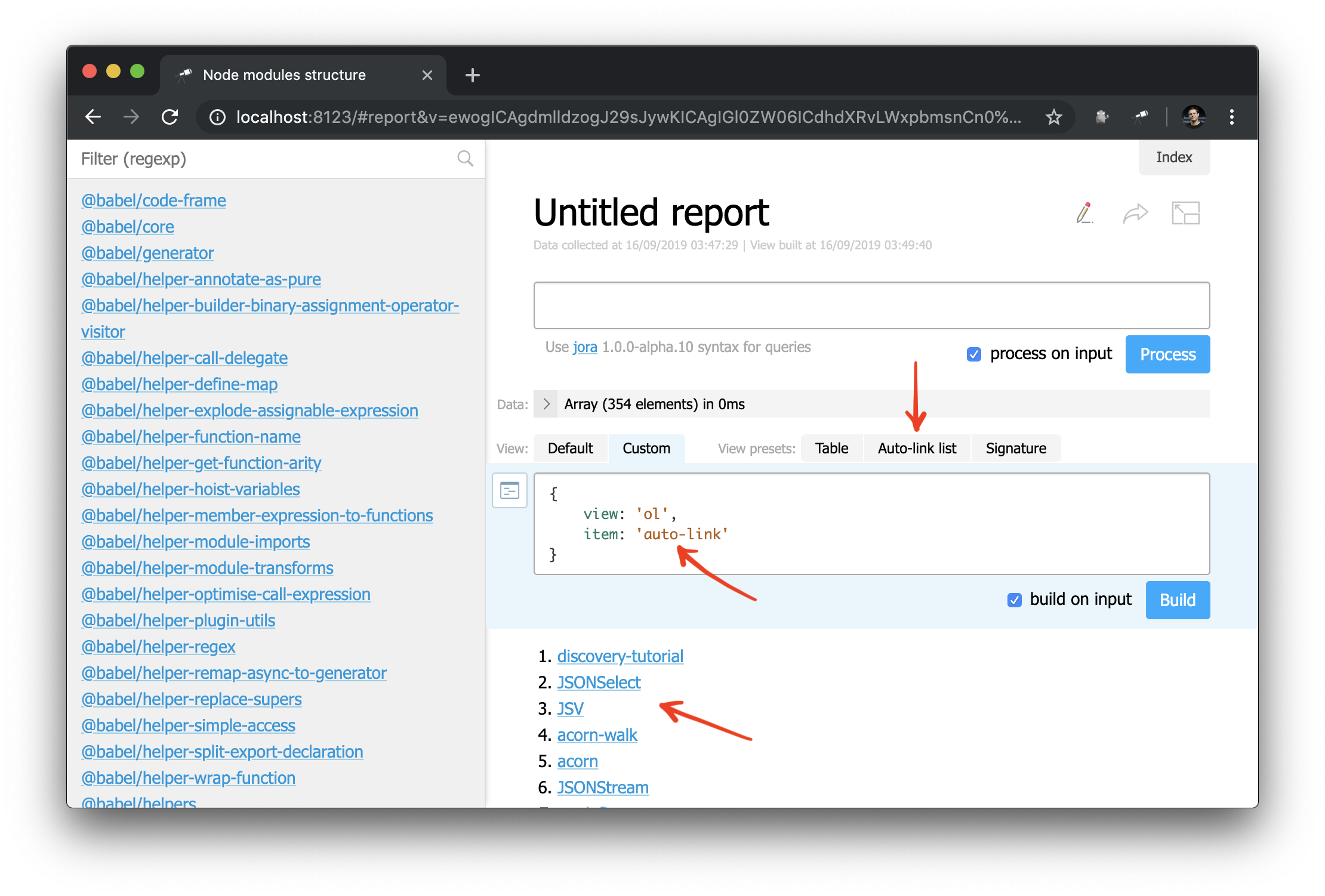
Y, como ejemplo, puede modificar ligeramente la barra lateral:
Conclusión
Ahora tiene una comprensión básica de los conceptos clave de Discovery.js . En las siguientes guías, veremos más de cerca los temas tratados.
Puede ver el código fuente completo de la guía en el repositorio en GitHub o probar cómo funciona en línea .
¡Sigue a @js_discovery en Twitter para estar al día de las últimas noticias!