Queremos esbozar en términos generales los primeros logros con aprendizaje profundo en animación de personajes para nuestro programa
Cascadeur .
Mientras trabajábamos en
Shadow Fight 3 , acumulamos mucha animación de combate: alrededor de 1100 movimientos con una duración promedio de aproximadamente 4 segundos. Hace mucho tiempo nos pareció que este podría ser un buen conjunto de datos para entrenar algún tipo de red neuronal.
Una vez que nos dimos cuenta de que cuando los animadores hacen los primeros bocetos de ideas en papel, solo necesitan dibujar un hombre literalmente para imaginar la pose del personaje. Pensamos que, dado que un animador experimentado puede establecer una pose bien en un patrón simple, es muy posible que la red neuronal pueda manejarlo. De esta observación, nació una idea simple: tomemos solo 6 puntos clave de cada pose: muñecas, tobillos, pelvis y base del cuello. Si la red neuronal solo conoce las posiciones de estos puntos, ¿puede predecir el resto de la pose, la posición de los 37 puntos restantes del personaje?
Cómo organizar el proceso de aprendizaje, fue claro desde el principio: en la entrada, la red recibe las posiciones de 6 puntos de una pose específica, en la salida da las posiciones de los 37 puntos restantes, y los comparamos con las posiciones que estaban en la posición inicial. En la función de evaluación, puede usar el método de mínimos cuadrados para las distancias entre las posiciones predichas de los puntos y la fuente.
Para el conjunto de datos de entrenamiento, teníamos todos los movimientos de los personajes de Shadow Fight 3. Tomamos poses de cada cuadro y obtuvimos alrededor de 115,000 poses. Pero este conjunto era específico: el personaje casi siempre miraba a lo largo del eje X, y la pierna izquierda siempre estaba al frente al comienzo del movimiento. Para resolver este problema, expandimos artificialmente el conjunto de datos generando posturas espejo y también girando aleatoriamente cada pose en el espacio. También nos permitió aumentar el conjunto de datos a dos millones de poses. Utilizamos el 95% de nuestro conjunto de datos para la capacitación en redes y el 5% para la parametrización y las pruebas.
Tomamos una arquitectura de red neuronal bastante simple: una red de cinco capas totalmente conectada con una función de activación y un método de inicialización de
las Redes Neuronales Autorenormalizadas . En la última capa, no se usa la activación. Teniendo 3 coordenadas para cada nodo, obtenemos una capa de entrada de 6 * 3 elementos y una capa de salida de 37 * 3 elementos. Buscamos la arquitectura óptima para capas ocultas y nos decidimos por una arquitectura de cinco capas con el número de neuronas de 300, 400, 300, 200 en cada capa oculta, sin embargo, las redes con menos capas ocultas también produjeron buenos resultados.
La regularización L2 de los parámetros de red también fue muy útil, hizo que las predicciones fueran más fluidas y continuas.
Una red neuronal con tales parámetros predice la posición de los puntos con un error promedio de 3.5 cm. Este es un error muy alto, pero se deben tener en cuenta los detalles del problema. Para un conjunto de valores de entrada, puede haber muchos valores de salida posibles. Por lo tanto, la red neuronal finalmente aprendió a emitir las predicciones promedio más probables. Sin embargo, cuando el número de puntos de entrada aumentó a 16, el error disminuyó a la mitad, lo que en la práctica arrojó una predicción muy precisa de la pose.
Pero al mismo tiempo, la red neuronal no podía mostrar una postura completamente correcta, preservando la longitud de todos los huesos y las articulaciones articulares correctas. Por lo tanto, también lanzamos un proceso de optimización que alinea todos los cuerpos sólidos y las articulaciones de nuestro modelo físico.
En la práctica, los resultados fueron bastante convincentes: puede verlos en nuestro video. Pero también hay una especificidad debido al hecho de que el conjunto de datos de entrenamiento son animaciones de combate de un juego de lucha con armas. Por ejemplo, un personaje parece suponer que gira con un hombro hacia el enemigo, como en una posición de combate, y en consecuencia gira los pies y la cabeza. Y cuando extiendes tu mano hacia él, el cepillo no gira como si lo estuvieras golpeando con el puño, sino como cuando lo golpeas con una espada.
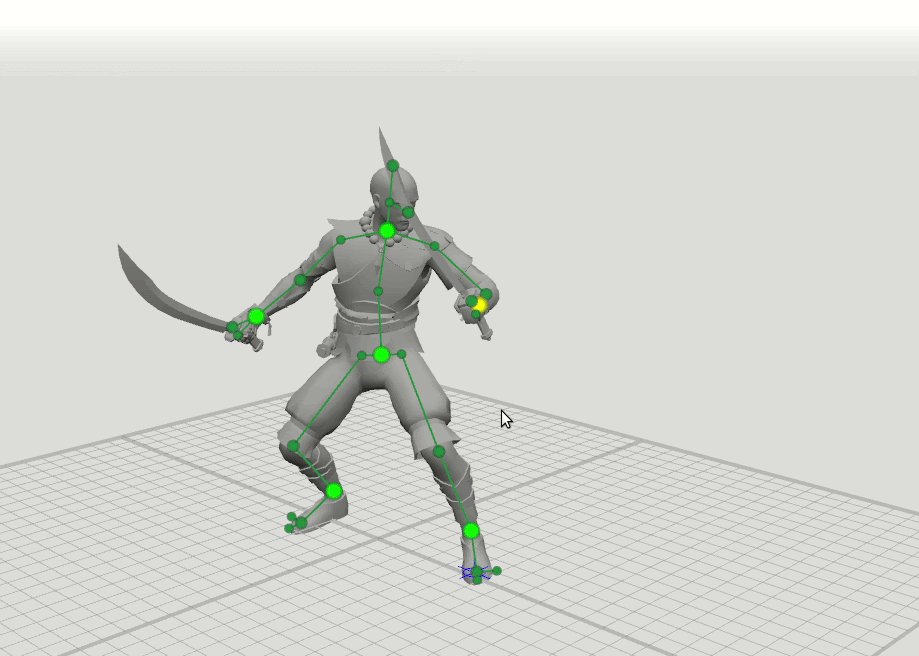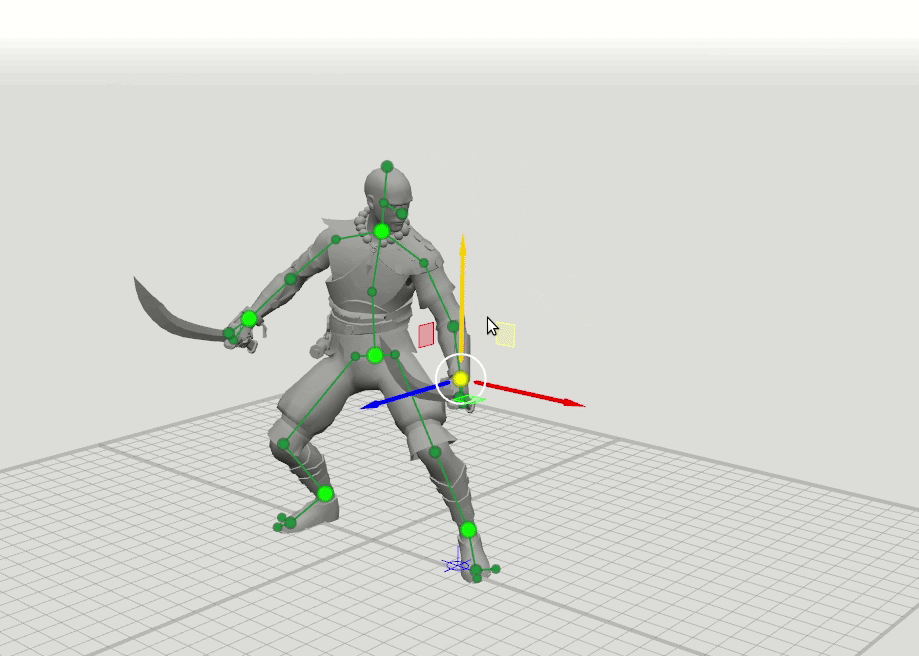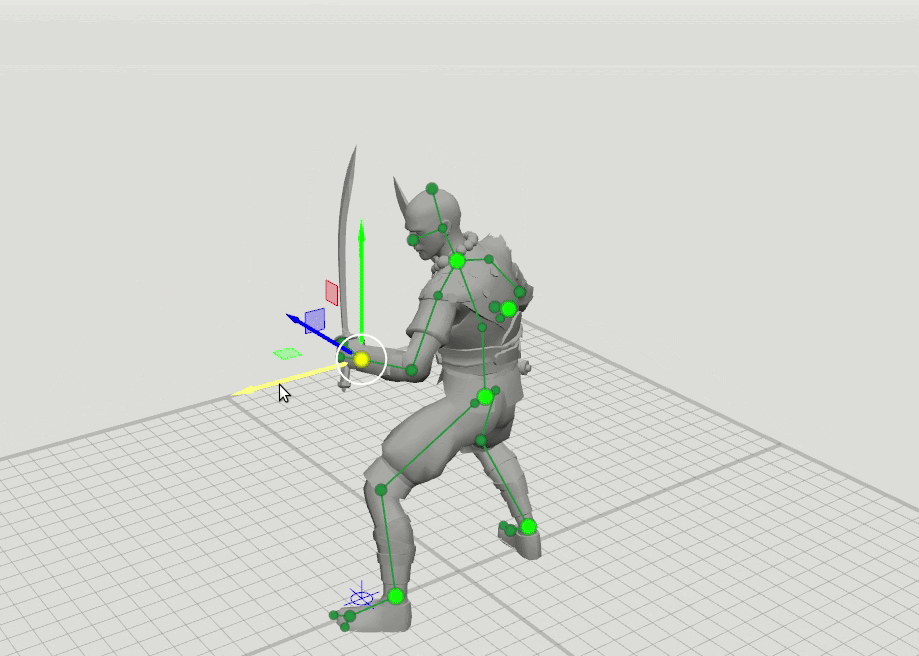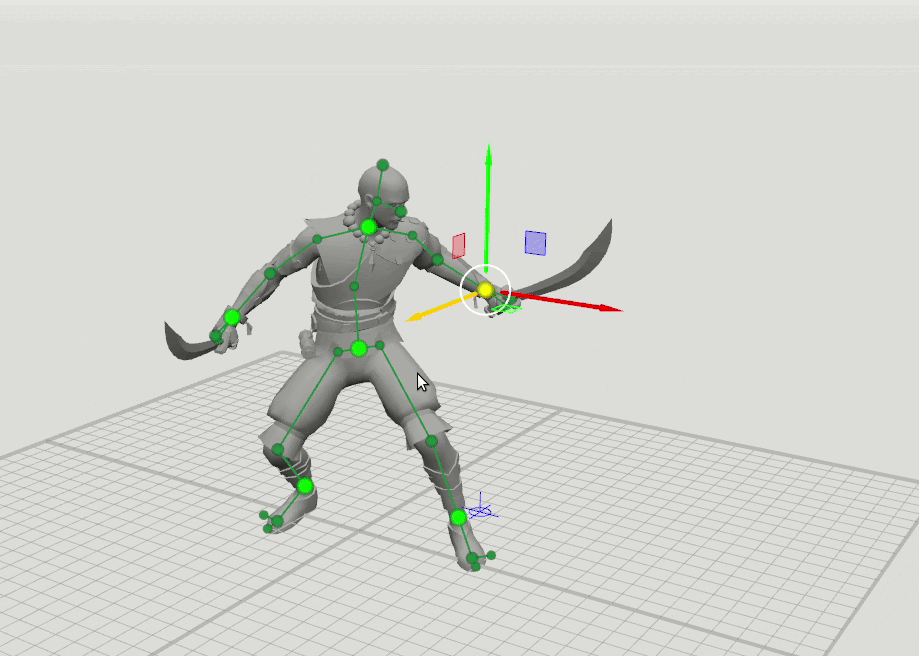
La idea lógica del siguiente paso surgió de esto: entrenar algunas redes más con un conjunto ampliado de puntos que especifican la orientación de las manos, los pies y la cabeza, así como la posición de las rodillas y los codos. Hemos agregado esquemas de 16 puntos y 28 puntos. Resultó que los resultados de estas redes se pueden combinar para que el usuario pueda establecer posiciones en un conjunto arbitrario de puntos. Por ejemplo, el usuario decidió mover el codo izquierdo, pero no tocó el derecho. Luego, la posición del codo derecho y el hombro derecho se predice en un patrón de 6 puntos, y la posición del hombro izquierdo se predice en un patrón de 16 puntos.

Parece que esto resulta ser una herramienta realmente interesante para trabajar con la pose de un personaje. Su potencial aún no se ha revelado hasta el final, y tenemos ideas sobre cómo mejorarlo y aplicarlo no solo para trabajar con una pose. La primera versión de esta herramienta ya está disponible en la versión actual de Cascadeur. Puede probarlo si se registra para una prueba beta cerrada en nuestro sitio web
cascadeur.comEstaremos encantados de conocer su opinión y responder preguntas.
El equipo de Banzai Games requiere un investigador de aprendizaje profundo. Lea más sobre la vacante aquí .