
Hola lectores de Habr. Con este artículo, abrimos un ciclo que hablará sobre el sistema hiperconvergente AERODISK vAIR que desarrollamos. Inicialmente, queríamos que el primer artículo contara todo sobre todo, pero el sistema es bastante complicado, por lo que comeremos un elefante en partes.
Comencemos la historia con la historia del sistema, profundicemos en el sistema de archivos ARDFS, que es la base de vAIR, y también hablemos un poco sobre el posicionamiento de esta solución en el mercado ruso.
En futuros artículos, hablaremos más sobre los diferentes componentes arquitectónicos (clúster, hipervisor, equilibrador de carga, sistema de monitoreo, etc.), el proceso de configuración, plantearemos problemas de licencia, mostraremos por separado las pruebas de choque y, por supuesto, escribiremos sobre las pruebas de carga y dimensionamiento También dedicaremos un artículo separado a la versión comunitaria de vAIR.
¿Es un disco de aire una historia sobre almacenamiento? ¿O por qué empezamos a hiperconvergir?
Inicialmente, la idea de crear nuestro propio hiperconvergente surgió en algún lugar alrededor del año 2010. Entonces no había Aerodisk, ni soluciones similares (sistemas comerciales hiperconvergentes en caja) en el mercado. Nuestra tarea era la siguiente: desde un conjunto de servidores con discos locales conectados por una interconexión a través de Ethernet, tuvimos que hacer un almacenamiento extendido y ejecutar máquinas virtuales y una red de software en el mismo lugar. Se requería implementar todo esto sin sistemas de almacenamiento (porque simplemente no había dinero para el almacenamiento y su vinculación, pero aún no habíamos inventado nuestro propio sistema de almacenamiento).
Probamos muchas soluciones de código abierto y, sin embargo, resolvimos este problema, pero la solución era muy complicada y difícil de repetir. Además, esta decisión fue de la categoría de "¿Obras? ¡No lo toques! " Por lo tanto, después de resolver ese problema, no desarrollamos más la idea de convertir el resultado de nuestro trabajo en un producto completo.
Después de ese incidente, nos alejamos de esta idea, pero aún teníamos la sensación de que esta tarea era completamente solucionable, y los beneficios de tal solución eran más que obvios. Posteriormente, los productos de HCI de compañías extranjeras que se lanzaron solo confirmaron este sentimiento.
Por lo tanto, a mediados de 2016, volvimos a esta tarea como parte de la creación de un producto completo. Entonces todavía no teníamos ninguna relación con los inversores, por lo que tuvimos que comprar un puesto de desarrollo por nuestro poco dinero. Después de escribir en los servidores y conmutadores Avito BU-shyh, nos pusimos a trabajar.

La tarea inicial principal era crear su propio, aunque simple, pero su propio sistema de archivos, que sería capaz de distribuir datos de forma automática y uniforme en forma de bloques virtuales en el enésimo número de nodos del clúster que están interconectados a través de Ethernet. En este caso, el FS debe escalarse bien y fácilmente e ser independiente de los sistemas adyacentes, es decir. ser enajenado de vAIR en forma de "solo almacenamiento".

VAIR primer concepto

Nos negamos intencionalmente a usar soluciones de código abierto ya preparadas para organizar el almacenamiento extendido (ceph, gluster, lustre y similares) a favor de nuestro desarrollo, ya que ya teníamos mucha experiencia en proyectos con ellos. Por supuesto, estas soluciones en sí mismas son maravillosas, y antes de trabajar en Aerodisk, implementamos más de un proyecto de integración con ellas. Pero una cosa es darse cuenta de la tarea específica de un cliente, capacitar al personal y, posiblemente, comprar soporte para un gran proveedor, y otra cosa es crear un producto fácil de replicar que se utilizará para diversas tareas, que nosotros, como proveedor, incluso podemos conocernos a nosotros mismos. No lo haremos. Para el segundo propósito, los productos de código abierto existentes no nos convenían, así que decidimos ver el sistema de archivos distribuidos nosotros mismos.
Dos años después, varios desarrolladores (que combinaron el trabajo en vAIR con el trabajo en el motor de almacenamiento clásico) lograron un cierto resultado.
Para el año 2018, habíamos escrito el sistema de archivos más simple y lo habíamos complementado con el enlace necesario. El sistema integró discos físicos (locales) de diferentes servidores en un grupo plano a través de una interconexión interna y los "cortó" en bloques virtuales, luego se crearon dispositivos de bloque con diversos grados de tolerancia a fallas a partir de bloques virtuales, en los que se crearon y ejecutaron hipervisores KVM virtuales. carros
No nos molestamos con el nombre del sistema de archivos y lo llamamos sucintamente ARDFS (adivina cómo se desencripta)
Este prototipo se veía bien (no visualmente, por supuesto, no había diseño visual en ese momento) y mostró buenos resultados en rendimiento y escala. Después del primer resultado real, establecimos el rumbo para este proyecto, después de haber organizado un entorno de desarrollo completo y un equipo separado que se dedicaba solo a vAIR.
Justo en ese momento, la arquitectura general de la solución había madurado, que hasta ahora no había sufrido cambios importantes.
Zambullirse en el sistema de archivos ARDFS
ARDFS es la base de vAIR, que proporciona almacenamiento de conmutación por error distribuido de todo el clúster. Una característica distintiva (pero no la única) de ARDFS es que no utiliza ningún servidor dedicado adicional para meta y administración. Originalmente, esto tenía la intención de simplificar la configuración de la solución y por su confiabilidad.
Estructura de almacenamiento
Dentro de todos los nodos del clúster, ARDFS organiza un grupo lógico de todo el espacio disponible en disco. Es importante comprender que un grupo aún no son datos ni espacio formateado, sino simplemente marcado, es decir cualquier nodo con vAIR instalado cuando se agrega al clúster se agrega automáticamente al grupo ARDFS compartido y los recursos del disco se comparten automáticamente en todo el clúster (y están disponibles para el almacenamiento de datos en el futuro). Este enfoque le permite agregar y eliminar nodos sobre la marcha sin ningún impacto grave en un sistema que ya se está ejecutando. Es decir El sistema es muy fácil de escalar con "ladrillos", agregando o eliminando nodos en el clúster si es necesario.
Los discos virtuales (objetos de almacenamiento para máquinas virtuales) se agregan en la parte superior del grupo ARDFS, que se crean a partir de bloques virtuales de 4 megabytes de tamaño. Los discos virtuales almacenan datos directamente. A nivel de disco virtual, también se define un esquema de tolerancia a fallas.
Como habrás adivinado, para la tolerancia a fallas del subsistema de disco, no utilizamos el concepto de RAID (matriz redundante de discos independientes), sino que utilizamos RAIN (matriz redundante de nodos independientes). Es decir La tolerancia a fallos se mide, automatiza y gestiona en función de nodos, no de discos. Los discos, por supuesto, también son un objeto de almacenamiento, ellos, como todo lo demás, son monitoreados, puede realizar todas las operaciones estándar con ellos, incluida la construcción de RAID de hardware local, pero el clúster funciona con nodos.
En una situación en la que realmente desea RAID (por ejemplo, un escenario que admite múltiples fallas en pequeños grupos), nada le impide usar controladores RAID locales y hacer un almacenamiento extendido y una arquitectura RAIN en la parte superior. Este escenario es bastante animado y es compatible con nosotros, por lo que hablaremos de ello en un artículo sobre escenarios típicos para usar vAIR.
Esquemas de conmutación por error de almacenamiento
Puede haber dos esquemas de resistencia de disco virtual vAIR:
1) Factor de replicación o simplemente replicación: este método de tolerancia a fallas es simple "como un palo y una cuerda". Se realiza la replicación síncrona entre nodos con un factor de 2 (2 copias por grupo) o 3 (3 copias, respectivamente). RF-2 permite que un disco virtual resista una falla de un nodo en un clúster, pero "come" la mitad del volumen utilizable, y RF-3 resistirá una falla de 2 nodos en un clúster, pero reservará 2/3 del volumen utilizable para sus necesidades. Este esquema es muy similar al RAID-1, es decir, un disco virtual configurado en RF-2 es resistente a fallas en cualquier nodo del clúster. En este caso, los datos estarán bien e incluso la E / S no se detendrá. Cuando un nodo caído vuelve a funcionar, comenzará la recuperación / sincronización automática de datos.
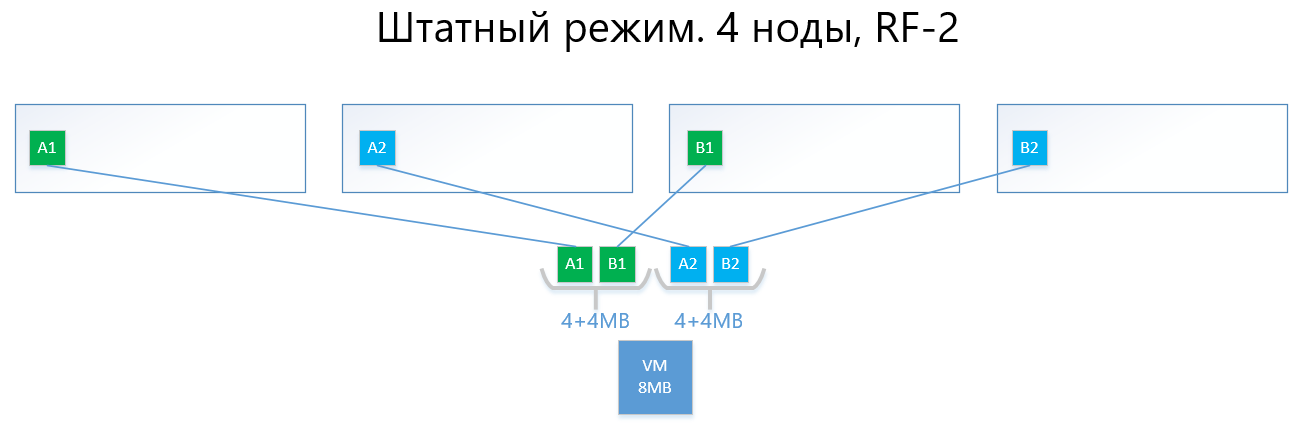
Los siguientes son ejemplos de la distribución de datos RF-2 y RF-3 en modo normal y en una situación de falla.
Tenemos una máquina virtual con una capacidad de 8 MB de datos únicos (útiles) que se ejecutan en 4 nodos vAIR. Está claro que en realidad es poco probable que haya una cantidad tan pequeña, pero para un esquema que refleja la lógica de ARDFS, este ejemplo es más comprensible. AB son bloques virtuales de 4 MB que contienen datos únicos de máquinas virtuales. Con RF-2, se crean dos copias de estos bloques A1 + A2 y B1 + B2, respectivamente. Estos bloques están "dispuestos" por nodos, evitando la intersección de los mismos datos en el mismo nodo, es decir, la copia A1 no estará en la misma nota que la copia A2. Con B1 y B2 es similar.
En caso de falla de uno de los nodos (por ejemplo, el nodo 3, que contiene una copia de B1), esta copia se activa automáticamente en el nodo donde no hay copia de su copia (es decir, copia B2).
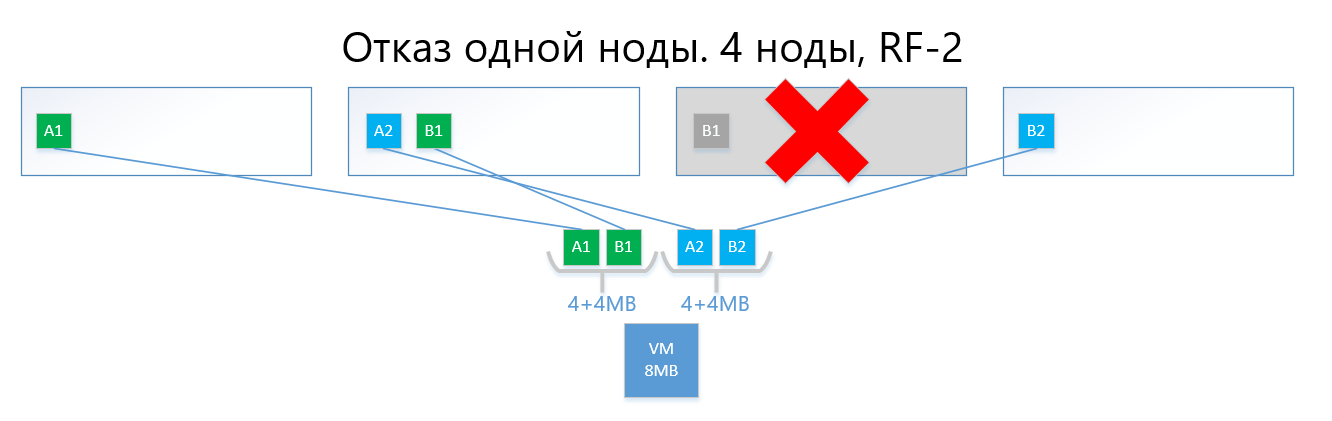
Por lo tanto, el disco virtual (y las máquinas virtuales, respectivamente) sobrevivirán fácilmente a la falla de un nodo en el esquema RF-2.
Un circuito con replicación, con su simplicidad y confiabilidad, sufre el mismo dolor que RAID1: hay poco espacio utilizable.
2) La codificación de borrado o codificación de borrado (también conocida como "codificación redundante", "codificación de borrado" o "código de redundancia") simplemente existe para resolver el problema anterior. EC es un esquema de redundancia que proporciona alta disponibilidad de datos con menos sobrecarga de disco en comparación con la replicación. El principio de funcionamiento de este mecanismo es similar al RAID 5, 6, 6P.
Al codificar, el proceso de EC divide el bloque virtual (4 MB por defecto) en varias "piezas de datos" más pequeñas dependiendo del esquema de EC (por ejemplo, un esquema de 2 + 1 divide cada bloque de 4 MB en 2 piezas de 2 MB). Además, este proceso genera "fragmentos de paridad" para "datos" de no más de una de las partes previamente separadas. Al decodificar, el EC genera las piezas faltantes, leyendo los datos "sobrevivientes" en todo el clúster.
Por ejemplo, un disco virtual con un esquema EC 2 + 1, implementado en 4 nodos de un clúster, puede resistir fácilmente una falla de un solo nodo en un clúster de la misma manera que RF-2. Al mismo tiempo, los costos generales serán más bajos, en particular, el factor de capacidad con RF-2 es 2, y con EC 2 + 1 será 1.5.
Si es más sencillo de describir, la conclusión es que el bloque virtual se divide en 2-8 (por qué del 2 al 8, ver más abajo) "piezas", y para estas piezas se calculan las "piezas" de paridad del mismo volumen.
Como resultado, los datos y la paridad se distribuyen uniformemente en todos los nodos del clúster. Al mismo tiempo, al igual que con la replicación, ARDFS distribuye automáticamente los datos entre los nodos de manera que se evite el almacenamiento de los mismos datos (copias de datos y su paridad) en un nodo para eliminar la posibilidad de perder datos debido al hecho de que los datos y sus la paridad terminará repentinamente en el mismo nodo de almacenamiento, lo que fallará.
A continuación se muestra un ejemplo, con la misma máquina virtual con 8 MB y 4 nodos, pero ya con el esquema EC 2 + 1.
Los bloques A y B se dividen en dos partes de 2 MB cada una (dos porque 2 + 1), es decir, A1 + A2 y B1 + B2. A diferencia de la réplica, A1 no es una copia de A2, es un bloque virtual A, dividido en dos partes, también con el bloque B. En total, obtenemos dos conjuntos de 4 MB, cada uno de los cuales contiene dos piezas de dos megabytes. Además, para cada uno de estos conjuntos, la paridad se calcula con un volumen de no más de una pieza (es decir, 2 MB), obtenemos + 2 piezas de paridad adicionales (AP y BP). Total tenemos datos 4x2 + paridad 2x2.
A continuación, los nodos "presentan" las piezas para que los datos no se superpongan con su paridad. Es decir A1 y A2 no estarán en el mismo nodo con AP.

En el caso de una falla de un nodo (por ejemplo, también el tercero), el bloque B1 caído se restaurará automáticamente desde la paridad BP, que está almacenada en el nodo No. 2, y se activará en el nodo donde no hay paridad B, es decir. piezas de BP. En este ejemplo, este es el nodo # 1

Estoy seguro de que el lector tiene una pregunta:
"Todo lo que describió ha sido implementado por los competidores y las soluciones de código abierto, ¿cuál es la diferencia entre su implementación de EC en ARDFS?"
Y luego habrá características interesantes del trabajo de ARDFS.
Codificación de borrado con énfasis en flexibilidad
Inicialmente, proporcionamos un esquema EC X + Y bastante flexible, donde X es igual a un número del 2 al 8 e Y es igual a un número del 1 al 8, pero siempre menor o igual que X. Tal esquema se proporciona por flexibilidad. Aumentar la cantidad de datos (X) en los que se divide la unidad virtual permite reducir la sobrecarga, es decir, aumentar el espacio utilizable.
Un aumento en el número de fragmentos de paridad (Y) aumenta la confiabilidad del disco virtual. Cuanto mayor sea el valor Y, más nodos en el clúster pueden fallar. Por supuesto, aumentar la cantidad de paridad reduce la cantidad de capacidad utilizable, pero esto es un cargo por la confiabilidad.
La dependencia del rendimiento en los circuitos EC es casi directa: cuanto más "piezas", menor es el rendimiento, aquí, por supuesto, necesita un aspecto equilibrado.
Este enfoque permite a los administradores la forma más flexible de configurar el almacenamiento extendido. Dentro del grupo ARDFS, puede usar cualquier esquema de tolerancia a fallas y sus combinaciones, lo que también es, en nuestra opinión, muy útil.
La siguiente tabla compara varios (no todos los posibles) circuitos de RF y EC.

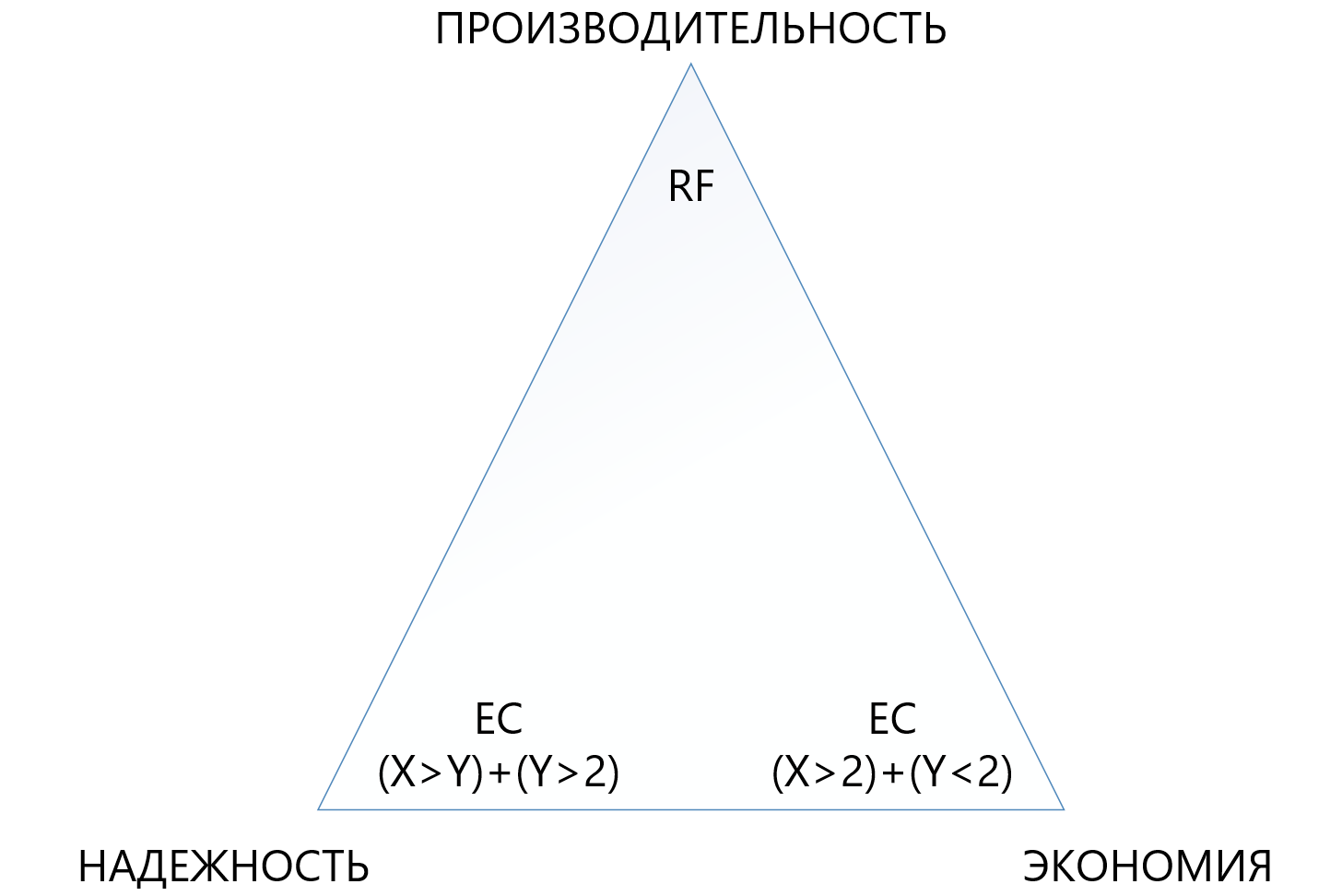
La tabla muestra que incluso la combinación "terry" de EC 8 + 7, que permite perder hasta 7 nodos simultáneamente en un clúster, "come" menos espacio utilizable (1.875 versus 2) que la replicación estándar y protege 7 veces mejor, lo que hace que este mecanismo de protección, aunque sea más complejo, pero mucho más atractivo en situaciones en las que necesita garantizar la máxima fiabilidad en las condiciones de falta de espacio en disco. Al mismo tiempo, debe comprender que cada "más" para X o Y será una sobrecarga adicional para la productividad, por lo que debe elegir con mucho cuidado en el triángulo entre confiabilidad, economía y rendimiento. Por esta razón, dedicaremos un artículo separado a la codificación de eliminación de tamaño.
Fiabilidad y autonomía del sistema de archivos.
ARDFS se ejecuta localmente en todos los nodos del clúster y los sincroniza por sus propios medios a través de interfaces Ethernet dedicadas. Un punto importante es que ARDFS sincroniza independientemente no solo los datos, sino también los metadatos relacionados con el almacenamiento. Mientras trabajábamos en ARDFS, estudiamos simultáneamente una serie de soluciones existentes y descubrimos que muchas realizan la meta sincronización del sistema de archivos usando un DBMS distribuido externo, que también usamos para la sincronización, pero solo configuraciones, no metadatos FS (sobre este y otros subsistemas relacionados) en el proximo articulo).
La sincronización de metadatos de FS usando un DBMS externo es, por supuesto, una solución de trabajo, pero la consistencia de los datos almacenados en ARDFS dependería del DBMS externo y su comportamiento (y ella, francamente, es una mujer caprichosa), lo cual es malo en nuestra opinión. Por qué Si los metadatos de FS están dañados, los datos de FS en sí también se pueden decir "adiós", por lo que decidimos seguir un camino más complicado pero confiable.
Creamos el subsistema de sincronización de metadatos para ARDFS de forma independiente, y vive completamente independiente de los subsistemas adyacentes. Es decir Ningún otro subsistema puede corromper los datos ARDFS. En nuestra opinión, esta es la forma más confiable y correcta, y es realmente así: el tiempo lo dirá. Además, con este enfoque, aparece una ventaja adicional. ARDFS puede usarse independientemente de vAIR, al igual que el almacenamiento extendido, que sin duda utilizaremos en productos futuros.
Como resultado, después de desarrollar ARDFS, obtuvimos un sistema de archivos flexible y confiable que le permite elegir dónde puede ahorrar en capacidad o ceder todo en rendimiento, o hacer que el almacenamiento sea altamente confiable por una tarifa moderada, pero reduciendo los requisitos de rendimiento.
Junto con una política de licencias simple y un modelo de entrega flexible (mirando hacia el futuro, está autorizado por vAIR por nodos y se entrega por software o como PAC), esto le permite adaptar con precisión la solución a los requisitos más diferentes de los clientes y en el futuro es fácil mantener este equilibrio.
¿Quién necesita este milagro?
Por un lado, podemos decir que ya hay jugadores en el mercado que tienen decisiones serias en el campo de la hiperconvergencia y hacia dónde vamos realmente. Esta afirmación parece ser cierta, PERO ...
Por otro lado, al salir al campo y comunicarnos con los clientes, nosotros y nuestros socios vemos que este no es el caso. Hay muchas tareas para el hiperconvergente, en algún lugar la gente simplemente no sabía que existían tales soluciones, en algún lugar parecía costoso, en algún lugar había pruebas fallidas de soluciones alternativas, pero en algún lugar generalmente prohibían comprar, debido a las sanciones. En general, el campo no estaba arado, así que fuimos a criar las tierras vírgenes))).
¿Cuándo es mejor el almacenamiento que GCS?
En el curso de trabajar con el mercado, a menudo se nos pregunta cuándo es mejor usar el esquema clásico con sistemas de almacenamiento y cuándo es hiperconvergente. Muchas empresas, fabricantes de GCS (especialmente aquellas que no tienen almacenamiento en su cartera) dicen: "¡El almacenamiento ha sobrevivido, solo hiperconvergente!" Esta es una declaración audaz, pero no refleja la realidad.
En verdad, el mercado de almacenamiento, de hecho, nada hacia soluciones hiperconvergentes y similares, pero siempre hay un "pero".
En primer lugar, los centros de datos y las infraestructuras de TI construidas de acuerdo con el esquema clásico con sistemas de almacenamiento no se pueden reconstruir fácilmente de esta manera, por lo que la modernización y finalización de tales infraestructuras sigue siendo un legado de 5-7 años.
En segundo lugar, las infraestructuras que se están construyendo ahora en su mayor parte (es decir, la Federación de Rusia) se están construyendo de acuerdo con el esquema clásico utilizando sistemas de almacenamiento y no porque las personas no conozcan el hiperconvergente, sino porque el mercado hiperconvergente es nuevo, aún no se han establecido soluciones y estándares , Los empleados de TI aún no han recibido capacitación, hay poca experiencia y necesitamos construir centros de datos aquí y ahora. Y esta tendencia es por otros 3-5 años (y luego otro legado, ver párrafo 1).
En tercer lugar, una limitación puramente técnica en pequeños retrasos adicionales de 2 milisegundos por escritura (excluyendo el caché local, por supuesto), que son tarifas por almacenamiento distribuido.
Bueno, no nos olvidemos de usar servidores físicos grandes que aman la escala vertical del subsistema de disco.
Hay muchas tareas necesarias y populares en las que el sistema de almacenamiento se comporta mejor que el GCS. Aquí, por supuesto, aquellos fabricantes que no tienen sistemas de almacenamiento en su cartera de productos estarán en desacuerdo con nosotros, pero estamos listos para discutir razonablemente. Por supuesto, nosotros, como desarrolladores de ambos productos en una de las futuras publicaciones, definitivamente haremos una comparación de los sistemas de almacenamiento y GCS, donde demostraremos claramente qué es mejor en qué condiciones.
¿Y dónde funcionarán mejor las soluciones hiperconvergentes que los sistemas de almacenamiento?
Basado en las tesis anteriores, hay tres conclusiones obvias:
- Cuando otros 2 milisegundos de demoras de grabación que se producen de manera estable en cualquier producto (ahora no estamos hablando de sintéticos, puede mostrar nanosegundos en sintéticos) no son críticos, el hiperconvergente funcionará.
- Donde la carga de grandes servidores físicos puede convertirse en muchos servidores virtuales pequeños y distribuirse por nodos, el hiperconvergente también funcionará bien allí.
- Donde la escala horizontal es más importante que la escala vertical, GCS también funcionará bien allí.
¿Cuáles son estas soluciones?
- Todos los servicios de infraestructura estándar (servicio de directorio, correo, EDS, servidores de archivos, sistemas ERP y BI pequeños o medianos, etc.). Llamamos a esto "computación general".
- La infraestructura de los proveedores de la nube, donde es necesario expandir y estandarizar rápidamente horizontalmente y "cortar" fácilmente una gran cantidad de máquinas virtuales para los clientes.
- Infraestructura de escritorios virtuales (VDI), donde muchos usuarios pequeños virtuala se lanzan y "flotan" silenciosamente dentro de un clúster uniforme.
- , , , 15-20 .
- (big data-, ). , «», «».
- , , , .
AERODISK vAIR ( ). , , .. .
…
, .
, .