Parece que el campo de la publicidad en línea debería ser lo más tecnológico y automatizado posible. De hecho, gigantes y expertos en su campo como Yandex, Mail.Ru, Google y Facebook trabajan allí. Pero, como resultó, no hay límite para la perfección y siempre hay algo para automatizar.
 Fuente
FuenteEl grupo de comunicación
Dentsu Aegis Network Russia es el jugador más grande en el mercado de publicidad digital e invierte activamente en tecnología, tratando de optimizar y automatizar sus procesos comerciales. Uno de los problemas no resueltos del mercado de publicidad en línea fue la tarea de recopilar estadísticas sobre campañas publicitarias de diferentes sitios en línea. La solución a este problema finalmente resultó en la creación del producto
D1.Digital (leído como DiVan), del que queremos hablar sobre el desarrollo.
Por qué
1. En el momento del inicio del proyecto, no había un solo producto terminado en el mercado que resolviera la tarea de automatizar la recopilación de estadísticas sobre campañas publicitarias.
Esto significa que nadie más que nosotros cerrará nuestras necesidades.Servicios como Improvado, Roistat, Supermetrics, SegmentStream, ofrecen integración con sitios, redes sociales y Google Analitycs, y también proporcionan la capacidad de crear paneles analíticos para un análisis y control convenientes de campañas publicitarias. Antes de comenzar a desarrollar nuestro producto, intentamos utilizar algunos de estos sistemas en nuestro trabajo para recopilar datos de sitios, pero, desafortunadamente, no pudieron resolver nuestros problemas.
El principal problema fue que los productos probados fueron repelidos de fuentes de datos, mostrando estadísticas de ubicaciones en secciones por sitios, y no permitieron la agregación de estadísticas en campañas publicitarias. Este enfoque no permitió ver estadísticas de diferentes sitios en un solo lugar y analizar el estado de la campaña en su conjunto.
Otro factor fue que en las etapas iniciales los productos estaban orientados al mercado occidental y no admitían la integración con sitios rusos. Y para aquellos sitios con los que se implementó la integración, no siempre se cargaron todas las métricas necesarias con suficiente detalle, y la integración no siempre fue conveniente y transparente, especialmente cuando era necesario obtener algo que no estaba en la interfaz del sistema.
En general, decidimos no adaptarnos a productos de terceros, pero comenzamos a desarrollar los nuestros ...
2. El mercado de publicidad en línea está creciendo año tras año, y en 2018, tradicionalmente superó al mercado de publicidad televisiva más grande en términos de presupuestos publicitarios.
Entonces hay una escala .
3. A diferencia del mercado de publicidad televisiva, donde la venta de publicidad comercial está monopolizada, la masa de propietarios individuales de equipos publicitarios de varios tamaños con sus oficinas de publicidad trabaja en Internet. Como la campaña publicitaria, por lo general, se ejecuta en varios sitios a la vez, para comprender el estado de la campaña publicitaria, es necesario recopilar informes de todos los sitios y reunirlos en un informe grande que muestre la imagen completa.
Por lo tanto, hay potencial para la optimización.4. Nos pareció que los propietarios de inventario de publicidad en Internet ya tenían una infraestructura para recopilar estadísticas y mostrarlas en las oficinas de publicidad, y podían proporcionar una API para estos datos.
Entonces, hay una viabilidad técnica. Diremos de inmediato que no fue tan simple.
En general, todos los requisitos previos para la implementación del proyecto eran obvios para nosotros, y corrimos para implementar el proyecto ...
Gran plan
Primero, formamos una visión de un sistema ideal:
- Debería cargar automáticamente las campañas publicitarias del sistema corporativo 1C con sus nombres, períodos, presupuestos y ubicaciones en varias plataformas.
- Para cada ubicación dentro de la campaña publicitaria, todas las estadísticas posibles de los sitios en los que la ubicación está en curso deben descargarse automáticamente, como el número de impresiones, clics, vistas, etc.
- Algunas campañas publicitarias son monitoreadas por terceros mediante los llamados sistemas de publicación de anuncios, como Adriver, Weborama, DCM, etc. También hay un medidor de Internet industrial en Rusia: Mediascope. Según nuestra idea, los datos de monitoreo independiente e industrial también deben cargarse automáticamente en las campañas publicitarias correspondientes.
- La mayoría de las campañas publicitarias en Internet están dirigidas a ciertas acciones específicas (comprar, llamar, grabar para una prueba de manejo, etc.), que se rastrean con Google Analytics, y estadísticas que también son importantes para comprender el estado de la campaña y deben cargarse en nuestra herramienta .
El primer panqueque es grumoso
Teniendo en cuenta nuestro compromiso con los principios flexibles del desarrollo de software (ágil, todas las cosas), decidimos primero desarrollar MVP y luego avanzar hacia el objetivo previsto de forma iterativa.
Decidimos crear MVP sobre la base de nuestro producto
DANBo (Dentsu Aegis Network Board) , que es una aplicación web con información general sobre las campañas publicitarias de nuestros clientes.
Para MVP, el proyecto se simplificó al máximo en términos de implementación. Hemos seleccionado una lista limitada de sitios para la integración. Estas fueron las principales plataformas, como Yandex.Direct, Yandex.Display, RB.Mail, MyTarget, Adwords, DBM, VK, FB y los principales sistemas de servidores de anuncios Adriver y Weborama.
Para acceder a las estadísticas en los sitios a través de la API, utilizamos una sola cuenta. El gerente del grupo de clientes, que quería utilizar la recopilación automática de estadísticas sobre la campaña publicitaria, primero tenía que delegar el acceso a las campañas publicitarias necesarias en los sitios a la cuenta de la plataforma.
Luego, el usuario del sistema
DANBo tuvo que cargar un archivo de cierto formato al sistema Excel, en el que se escribió toda la información sobre la ubicación (campaña publicitaria, sitio, formato, período de ubicación, indicadores planificados, presupuesto, etc.) y los identificadores de las campañas publicitarias correspondientes en los sitios. y contadores en sistemas de servicio de anuncios.
Parecía, francamente, aterrador:

Los datos descargados se almacenaron en la base de datos, y luego los servicios individuales recopilaron identificadores de campaña de los sitios y descargaron estadísticas sobre ellos.
Se escribió un servicio de Windows por separado para cada sitio, que una vez al día estaba bajo una cuenta de servicio en la API del sitio y descargaba estadísticas sobre los identificadores de campaña especificados. Lo mismo sucedió con los sistemas de publicidad.
Los datos descargados se mostraron en la interfaz en forma de un pequeño panel autoescrito:
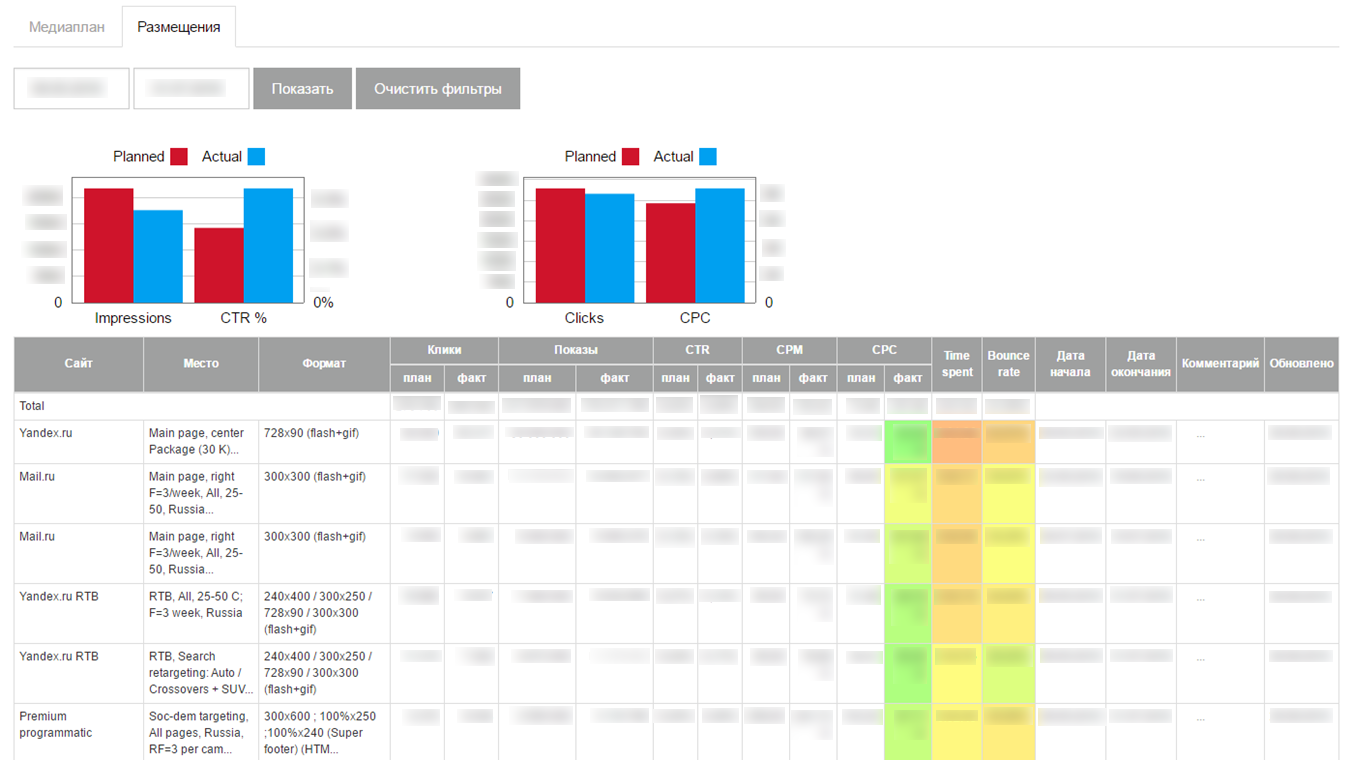
Inesperadamente para nosotros, MVP ganó y comenzó a descargar estadísticas actuales sobre campañas publicitarias en Internet. Implementamos el sistema en varios clientes, pero cuando intentamos escalar, nos encontramos con serios problemas:
- El principal problema era la laboriosidad de preparar los datos para cargarlos en el sistema. Además, los datos de ubicación tuvieron que reducirse a un formato estrictamente fijo antes de la descarga. En el archivo para cargar, era necesario registrar los identificadores de entidades de diferentes sitios. Nos enfrentamos al hecho de que es muy difícil para los usuarios técnicamente inexpertos explicar dónde encontrar estos identificadores en el sitio y dónde colocarlos en el archivo. Teniendo en cuenta el número de empleados en las divisiones que realizan campañas en los sitios y la rotación, esto resultó en una gran cantidad de apoyo de nuestro lado, que categóricamente no nos convenía.
- Otro problema era que no todas las plataformas publicitarias tenían mecanismos para delegar el acceso a campañas publicitarias a otras cuentas. Pero incluso si el mecanismo de delegación estuviera disponible, no todos los anunciantes estaban dispuestos a proporcionar acceso a cuentas de terceros a sus campañas.
- Un factor importante fue la indignación, que causó que los usuarios que todos los indicadores planificados y los detalles de ubicación que ya contribuyen a nuestro sistema de contabilidad 1C se vuelvan a ingresar en DANBo .
Esto nos dio la idea de que la fuente principal de información sobre la ubicación debería ser nuestro sistema 1C, en el que todos los datos se ingresan con precisión y a tiempo (el punto es que, en base a los datos 1C, se forman cuentas, por lo tanto, la entrada correcta de los datos en 1C es para todos en KPI). Entonces apareció un nuevo concepto de sistema ...
Concepto
Lo primero que decidimos hacer fue separar el sistema de recopilación de estadísticas sobre campañas publicitarias en Internet en un producto separado:
D1.Digital .
En el nuevo concepto, decidimos cargar información sobre campañas publicitarias y ubicaciones dentro de ellas desde 1C a
D1.Digital , y luego extraer estadísticas de sitios y de sistemas AdServing a estas ubicaciones. Se suponía que esto simplificaría enormemente la vida de los usuarios (y, como de costumbre, agregaría trabajo a los desarrolladores) y reduciría la cantidad de soporte.
El primer problema que encontramos fue de naturaleza organizacional y estaba relacionado con el hecho de que no podíamos encontrar una clave o atributo por el cual pudiéramos comparar entidades de diferentes sistemas con campañas y ubicaciones de 1C. El hecho es que el proceso en nuestra compañía está organizado de tal manera que las campañas publicitarias son ingresadas en diferentes sistemas por diferentes personas (reproductores multimedia, compras, etc.).
Para resolver este problema, tuvimos que inventar una clave hash única, DANBoID, que conectaría entidades en diferentes sistemas y que podría identificarse de manera bastante fácil e inequívoca en los conjuntos de datos cargados. Este identificador se genera en el sistema interno 1C para cada ubicación individual y se lanza a campañas, ubicaciones y contadores en todas las plataformas y en todos los sistemas AdServing. La implementación de la práctica de colocar DANBoID en todas las ubicaciones tomó algo de tiempo, pero lo hicimos :)
Luego descubrimos que no todos los sitios tienen una API para la recopilación automática de estadísticas, e incluso aquellos que tienen una API no devuelven todos los datos necesarios.
En esta etapa, decidimos reducir significativamente la lista de sitios para la integración y centrarnos en los sitios principales que participan en la gran mayoría de las campañas publicitarias. Esta lista incluye a todos los jugadores más grandes en el mercado publicitario (Google, Yandex, Mail.ru), redes sociales (VK, Facebook, Twitter), los principales sistemas de análisis y AdServing (DCM, Adriver, Weborama, Google Analytics) y otras plataformas.
La mayor parte de los sitios que seleccionamos tenían una API que nos dio las métricas necesarias. En aquellos casos en que la API no estaba allí, o no tenía los datos necesarios, utilizamos informes que llegaban diariamente por correo comercial para descargar los datos (en algunos sistemas es posible configurar dichos informes, en otros acordaron el desarrollo de dichos informes para nosotros).
Al analizar datos de diferentes sitios, encontramos que la jerarquía de entidades no es la misma en diferentes sistemas. Además, la información de diferentes sistemas debe cargarse con diferentes detalles.
Para resolver este problema, se desarrolló el concepto SubDANBoID. La idea de SubDANBoID es bastante simple, marcamos la esencia principal de la campaña en el sitio con el DANBoID generado, y cargamos todas las entidades anidadas con identificadores únicos del sitio y formamos el SubDANBoID de acuerdo con el principio DANBoID + identificador de la entidad anidada del primer nivel + identificador de la entidad anidada del segundo nivel + ... Este enfoque nos permitió asociarnos campañas publicitarias en diferentes sistemas y subir estadísticas detalladas sobre ellos.
También tuvimos que resolver el problema del acceso a las campañas en diferentes sitios. Como escribimos anteriormente, el mecanismo de delegar el acceso a la campaña a una cuenta técnica separada no siempre es aplicable. Por lo tanto, tuvimos que desarrollar una infraestructura para la autorización automática a través de OAuth usando tokens y mecanismos de actualización para estos tokens.
Más adelante en el artículo intentaremos describir con más detalle la arquitectura de la solución y los detalles técnicos de la implementación.
Arquitectura de soluciones 1.0
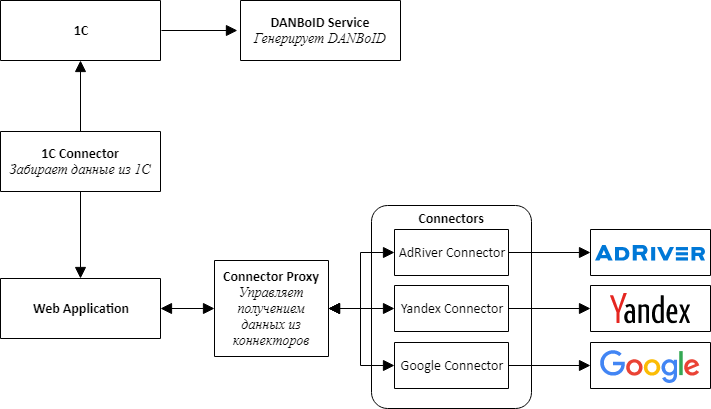
Al comenzar la implementación de un nuevo producto, entendimos que era inmediatamente necesario proporcionar la posibilidad de conectar nuevos sitios, por lo que decidimos seguir el camino de la arquitectura de microservicios.
Al diseñar la arquitectura, seleccionamos conectores de servicios separados para todos los sistemas externos: 1C, plataformas publicitarias y sistemas de publicación de anuncios.
La idea principal es que todos los conectores a los sitios tienen la misma API y son adaptadores que traen las API del sitio a nuestra conveniente interfaz.
En el centro de nuestro producto hay una aplicación web, que es un monolito, que está diseñada para que pueda desmontarse fácilmente en los servicios. Esta aplicación es responsable de procesar los datos descargados, comparar estadísticas de diferentes sistemas y presentarlos a los usuarios del sistema.
Para comunicar los conectores con una aplicación web, tuvimos que crear un servicio adicional, al que llamamos Proxy de conector. Realiza las funciones de Service Discovery y Task Scheduler. Este servicio ejecuta tareas de recopilación de datos para cada conector todas las noches. Escribir una capa de servicio fue más fácil que conectar un agente de mensajes, y para nosotros fue importante obtener el resultado lo más rápido posible.
Por simplicidad y velocidad de desarrollo, también decidimos que todos los servicios serían una API web. Esto hizo posible armar rápidamente una prueba de concepto y verificar que todo el diseño funcionara.
Una tarea separada, bastante difícil, fue configurar el acceso para recopilar datos de diferentes gabinetes, que, como decidimos, deberían llevar a cabo los usuarios a través de una interfaz web. Consiste en dos pasos separados: primero, el usuario a través de OAuth agrega un token para acceder a la cuenta y luego configura la recopilación de datos para el cliente desde una cuenta específica. Es necesario obtener un token a través de OAuth porque, como ya escribimos, no siempre es posible delegar el acceso al gabinete deseado en el sitio.
Para crear un mecanismo universal para elegir un gabinete de los sitios, tuvimos que agregar un método a la API de conectores que representa el esquema JSON, que se procesa en el formulario utilizando un componente JSONEditor modificado. Por lo tanto, los usuarios pudieron elegir las cuentas desde las que descargar los datos.
Para cumplir con los límites de solicitud que existen en los sitios, combinamos la solicitud de configuración dentro del mismo token, pero podemos procesar diferentes tokens en paralelo.
Elegimos MongoDB como depósito de datos descargables tanto para una aplicación web como para conectores, lo que nos permitió no preocuparnos mucho por la estructura de datos en las etapas iniciales de desarrollo, cuando el modelo de la aplicación cambia después de un día.
Pronto descubrimos que no todos los datos se ajustan bien en MongoDB y, por ejemplo, las estadísticas diarias son más convenientes para almacenar en una base de datos relacional. Por lo tanto, para los conectores cuya estructura de datos es más adecuada para una base de datos relacional, comenzamos a usar PostgreSQL o MS SQL Server como almacenamiento.
La arquitectura y la tecnología seleccionadas nos permitieron construir y lanzar relativamente rápido el producto D1.Digital. Durante los dos años de desarrollo de productos, desarrollamos 23 conectores de sitio, adquirimos una experiencia invaluable trabajando con API de terceros, aprendimos a sortear las trampas de los diferentes sitios que cada uno tenía el suyo, contribuimos al desarrollo de API al menos en 3 sitios, descargamos información automáticamente en casi 15,000 campañas En más de 80,000 ubicaciones, recopilamos una gran cantidad de comentarios de los usuarios sobre el producto y logramos cambiar el proceso principal del producto varias veces, en base a estos comentarios.
Arquitectura de soluciones 2.0
Han pasado dos años desde el inicio del desarrollo de
D1.Digital . El aumento constante de la carga en el sistema y la aparición de nuevas fuentes de datos revelaron gradualmente problemas en la arquitectura de la solución existente.
El primer problema está relacionado con la cantidad de datos descargados de los sitios. Nos enfrentamos con el hecho de que recopilar y actualizar todos los datos necesarios de los sitios más grandes comenzó a tomar demasiado tiempo. Por ejemplo, la recopilación de datos en el sistema de servicio de anuncios AdRiver, con el que hacemos un seguimiento de las estadísticas para la mayoría de las ubicaciones, lleva aproximadamente 12 horas.
Para resolver este problema, comenzamos a usar todo tipo de informes para descargar datos de los sitios, estamos tratando de desarrollar sus API junto con los sitios para que su velocidad satisfaga nuestras necesidades y paralelizar la carga de datos tanto como sea posible.
Otro problema es el procesamiento de datos descargados. Ahora, con la llegada de nuevas estadísticas sobre la ubicación, se inicia un proceso de varias etapas para volver a calcular las métricas, que incluye cargar datos sin procesar, calcular métricas agregadas para cada sitio, comparar datos de diferentes fuentes entre sí y calcular métricas resumidas para la campaña. Esto provoca una gran carga en la aplicación web, que realiza todos los cálculos. Varias veces, en el proceso de recuento, la aplicación consume toda la memoria del servidor, aproximadamente 10-15 GB, lo que tiene el efecto más perjudicial en el trabajo del usuario con el sistema.
Los problemas identificados y los planes grandiosos para el desarrollo posterior del producto nos llevaron a la necesidad de revisar la arquitectura de la aplicación.
Comenzamos con los conectores.
Notamos que todos los conectores funcionan de acuerdo con el mismo modelo, por lo que construimos un transportador de tubería en el que para crear el conector solo tenía que programar la lógica de los pasos, el resto era universal. Si necesita mejorar algún conector, lo transferiremos inmediatamente a un nuevo marco mientras finalizamos el conector.
Paralelamente, comenzamos a colocar conectores en Docker y Kubernetes.
Planeamos mudarnos a Kubernetes durante un tiempo bastante largo, experimentamos con la configuración de CI / CD, pero comenzamos a movernos solo cuando un conector comenzó a consumir más de 20 GB de memoria en el servidor debido a un error, casi matando el resto de los procesos. Durante la investigación, el conector se reubicó en el clúster de Kubernetes, donde finalmente permaneció, incluso cuando se solucionó el error.
Rápidamente, nos dimos cuenta de que Kubernetes era conveniente, y en seis meses movimos 7 conectores y Conectores Proxy al clúster de producción, que consume la mayoría de los recursos.
Siguiendo los conectores, decidimos cambiar la arquitectura del resto de la aplicación.
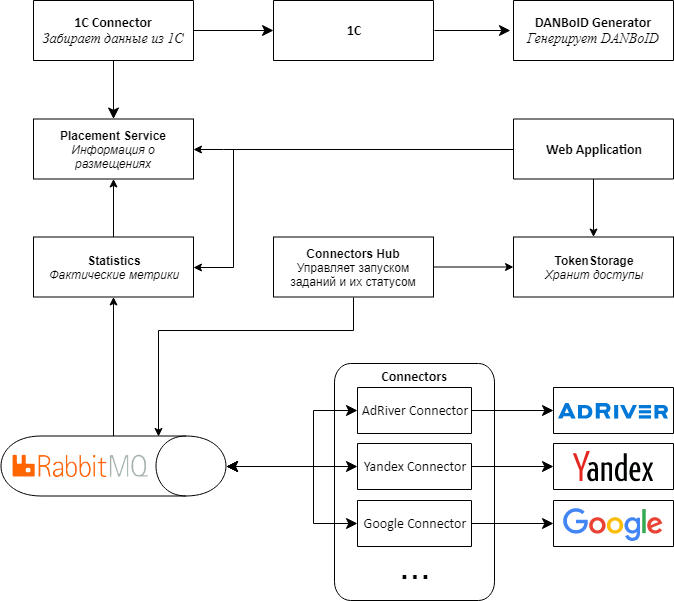
El principal problema fue que los datos provienen de conectores a proxies en paquetes grandes, y luego golpean en DANBoID y se transfieren a una aplicación web central para su procesamiento. Debido a la gran cantidad de recálculos de métricas, se produce una gran carga en la aplicación.
, , web , , , - .
2.0.
, Web API RabbitMQ MassTransit . Connectors Proxy, Connectors Hub. , , .
web , . .
Kubernetes, .
Proof-of-concept 2.0
D1.Digital . — 20 , , , , .
, API, .
, , adserving .
, web , Kubernetes. , , .
, MongoDB. SQL-, , , , .
, , :)
R&D Dentsu Aegis Network Russia: ( shmiigaa ), ( hitexx )