
Hace dos años, al encender accidentalmente el televisor, vi una historia interesante en el programa Vesti. Se dijo que el Departamento de Tecnología de la Información de Moscú está creando una red neuronal que leerá las lecturas de los medidores de agua de las fotografías. En la historia, el presentador de televisión le pidió a la gente del pueblo que ayudara al proyecto y enviara imágenes de sus medidores al portal mos.ru para entrenar una red neuronal en ellos.
Si usted es un departamento de Moscú, publicar un video en el canal federal y pedirle a la gente que envíe imágenes de medidores no es un gran problema. Pero, ¿qué pasa si eres una pequeña empresa y no puedes hacer un anuncio en un canal de televisión? ¿Cómo obtener 50,000 imágenes de contadores en este caso? Yandex.Toloka viene al rescate!
Yandex.Toloka es una plataforma de crowdsourcing en la que personas de todo el mundo realizan tareas simples, recibiendo dinero por esto. Por ejemplo, los trabajadores de la tolva pueden encontrar peatones en la imagen, capacitar a asistentes de voz y más . Al mismo tiempo, no solo los empleados de Yandex, sino cualquiera que lo desee puede publicar tareas en Toloka.
Declaración del problema.
Entonces, queremos crear una red neuronal, que a partir de la foto determinará las lecturas de los contadores. ¿Dónde comenzar, qué datos necesitamos?
Después de consultar con colegas, concluimos que para crear MVP necesitamos 1000 imágenes de contador. Además, para cada contador queremos saber las lecturas actuales, así como las coordenadas de la ventana con números. 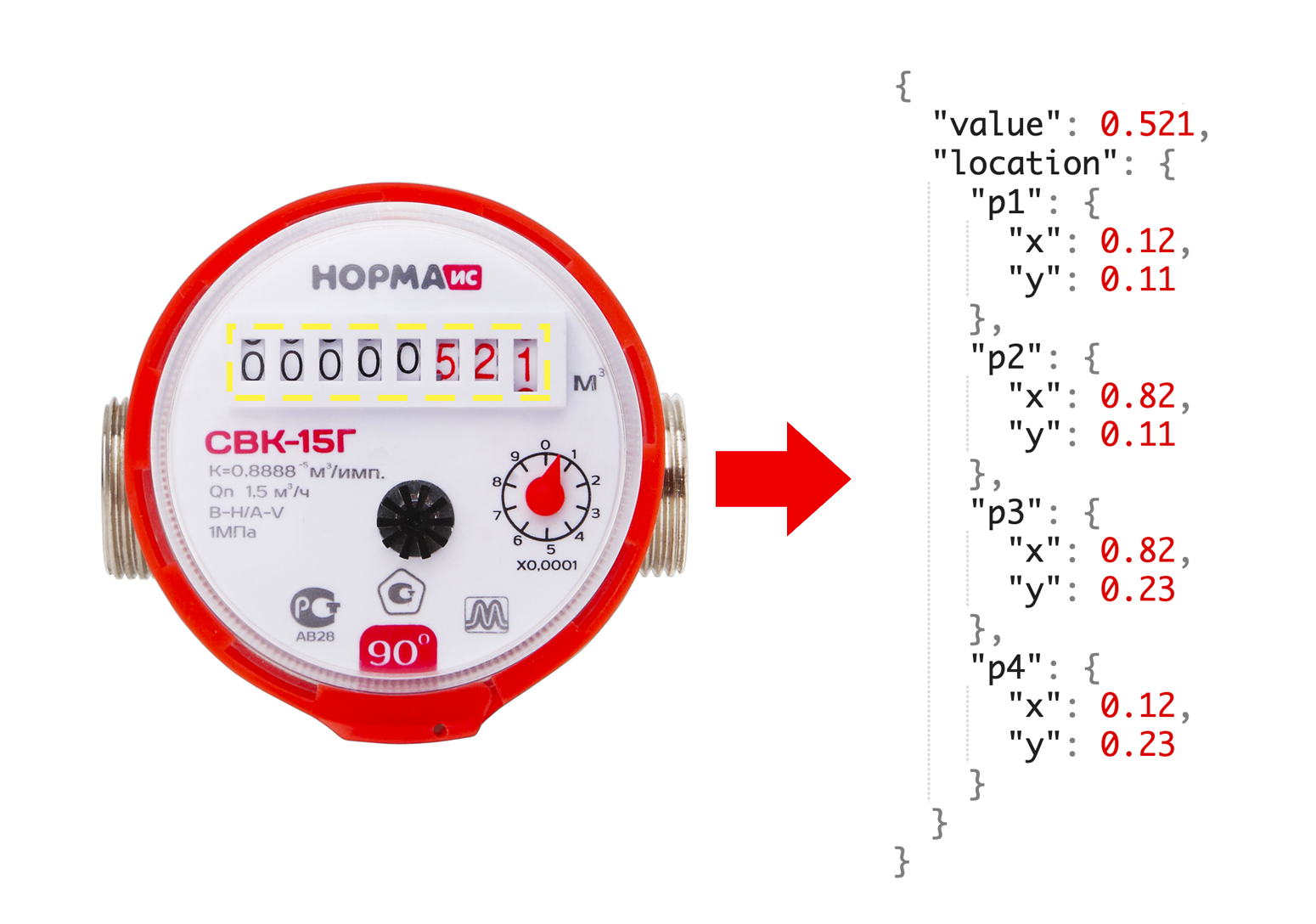
Si nunca ha trabajado con Toloka, le aconsejo que lea el artículo que escribí hace un año. Dado que el artículo actual será técnicamente más complicado, omitiré algunos puntos descritos en detalle en el artículo anterior.
AgradecimientosEl artículo anterior se convirtió en TOP-2 en el ranking de artículos de la comunidad ODS . ¡Gracias por comentar y poner los profesionales!)
Parte 1. Adquisición de imágenes
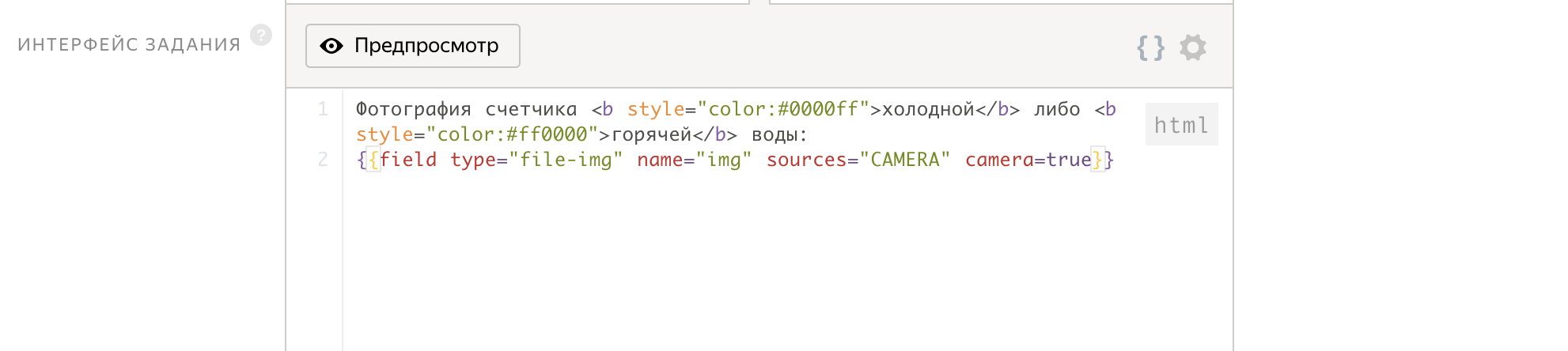
¿Qué podría ser más fácil? Solo necesita pedirle a la persona que abra la aplicación Yandex.Tolok en su teléfono y tome una foto de su contador. Si no hubiera trabajado con Toloka durante varios años, mi instrucción sería: " Debe fotografiar su medidor de agua (caliente o frío) y enviarnos una imagen" .
Desafortunadamente, con tal declaración del problema, no se puede recopilar un buen conjunto de datos. La cuestión es que las personas pueden interpretar este TK de diferentes maneras, ya que las instrucciones no tienen criterios claros para una tarea completada correctamente. Tolockers pueden enviar:
- imágenes borrosas;
- Imágenes que no muestran evidencia
- Imágenes con múltiples contadores.
El blog de Toloka tiene un excelente tutorial sobre cómo escribir instrucciones. Siguiéndolo, recibí estas instrucciones: 
Como parámetros de entrada, pasamos la identificación de la tarea, y en la salida obtenemos el archivo img, que contendrá la imagen del contador.

¡La interfaz de trabajo está escrita en solo 2 líneas!
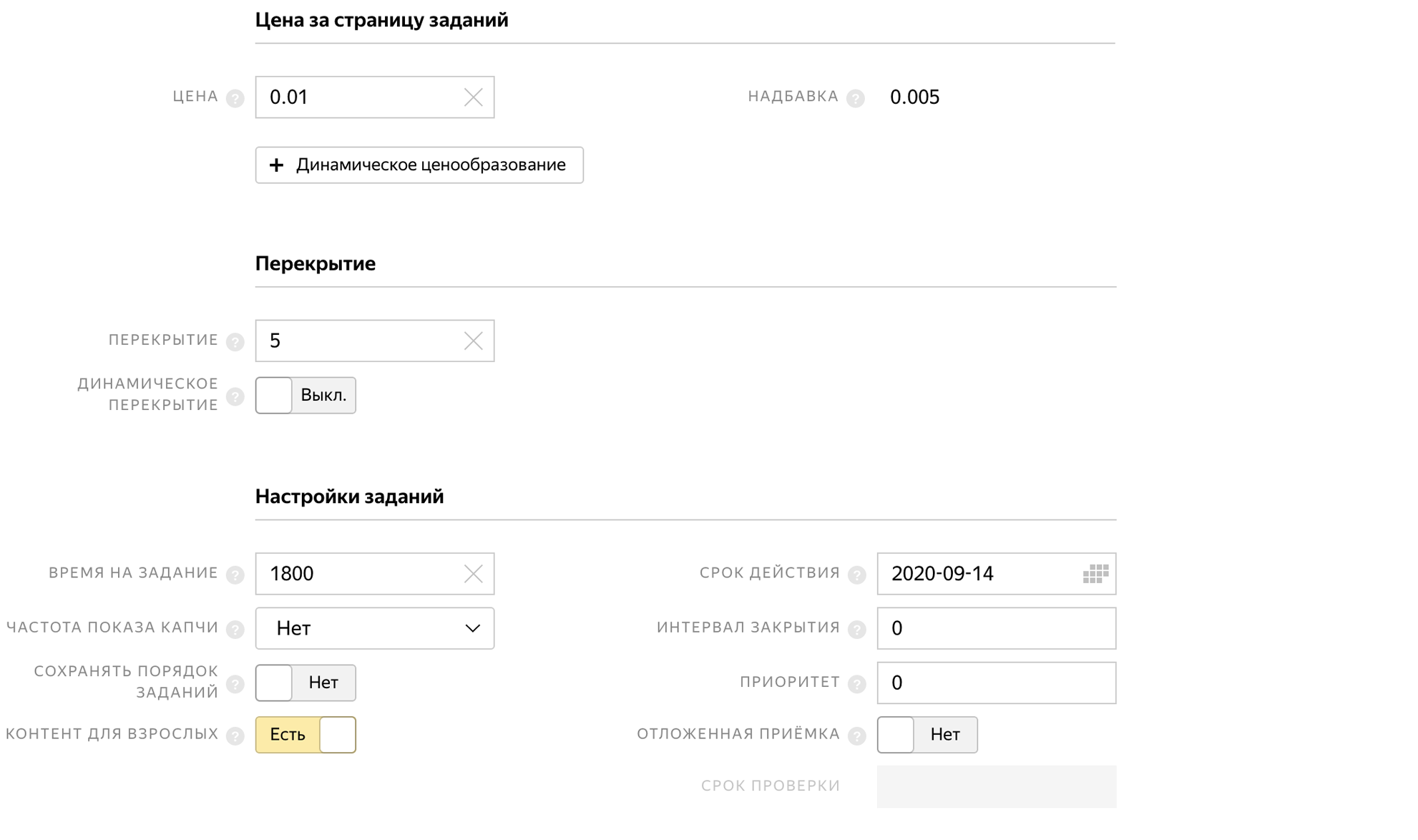
Al crear un grupo, indicamos el tiempo para completar la tarea, la aceptación tardía y el precio de la tarea 0.01 $.
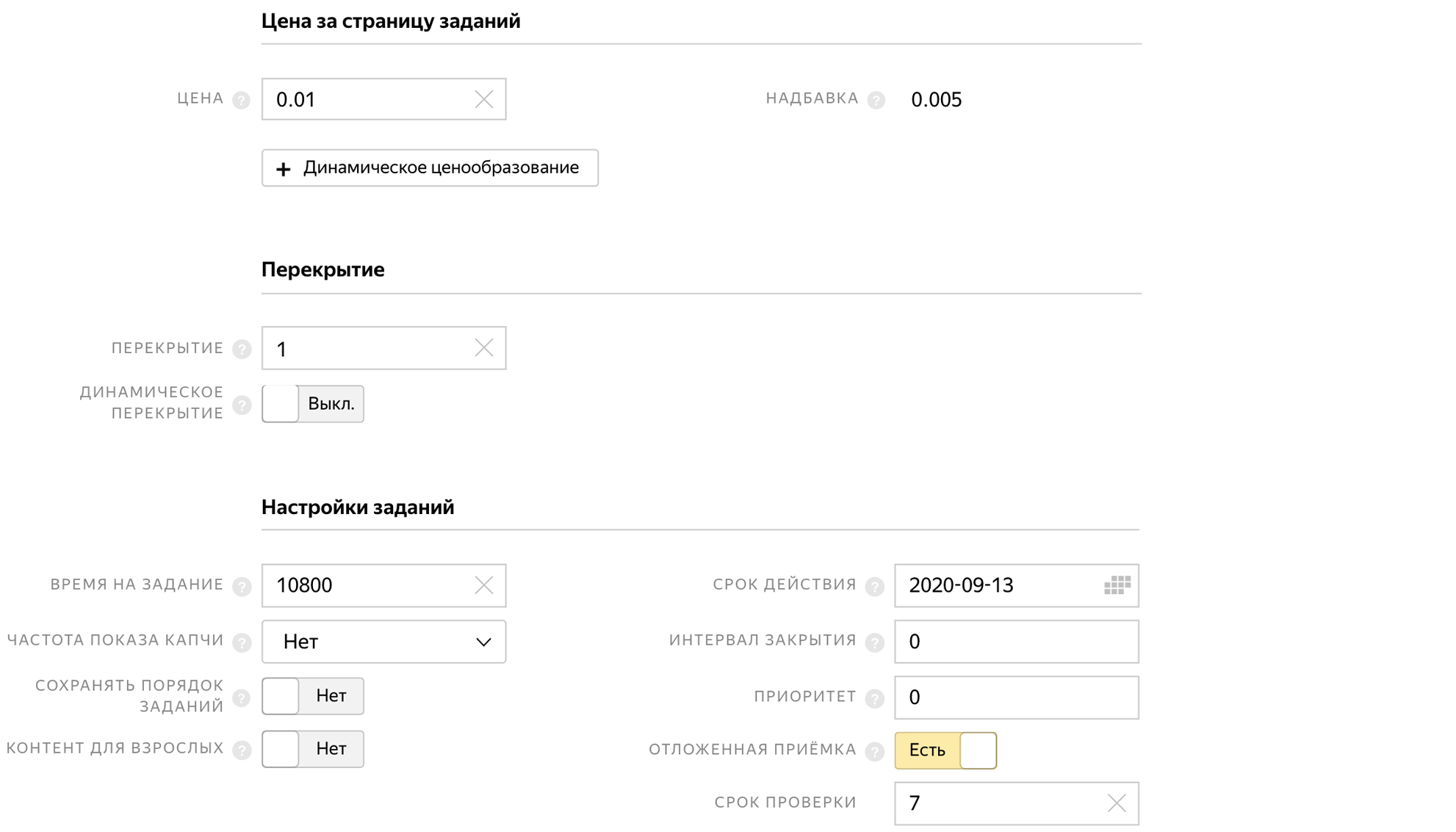
Y para que las personas no completen la tarea varias veces y no envíen las mismas fotos, prohibimos la ejecución repetida de la tarea en el bloque de control de calidad.
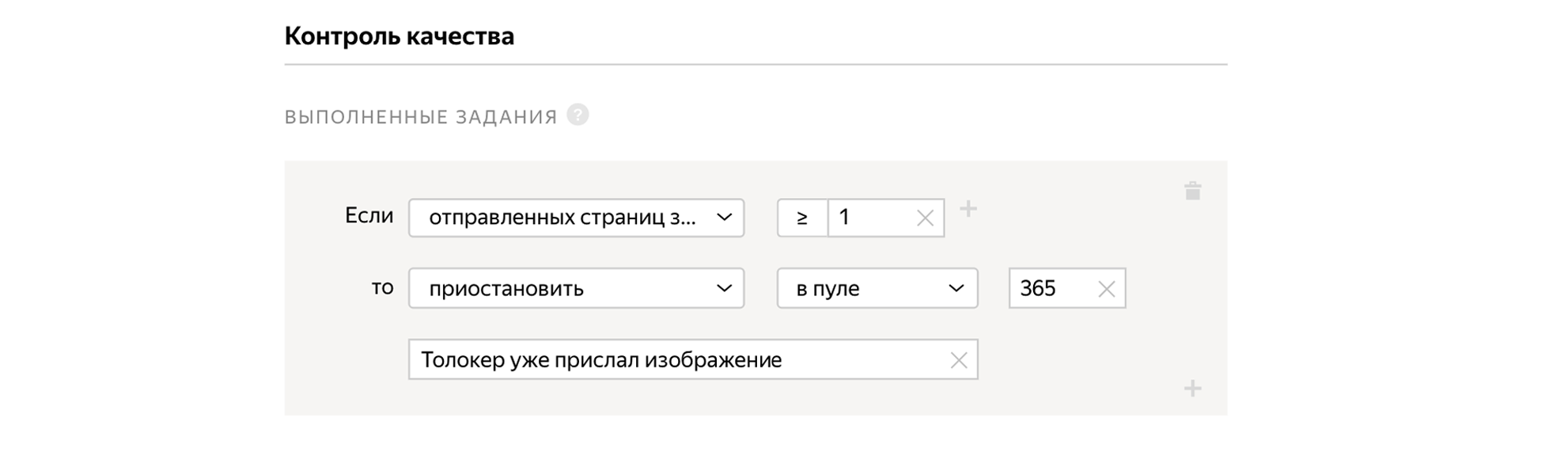
Indicamos que necesitamos usuarios de habla rusa que completen la tarea a través de la aplicación móvil Yandex.Tolok.
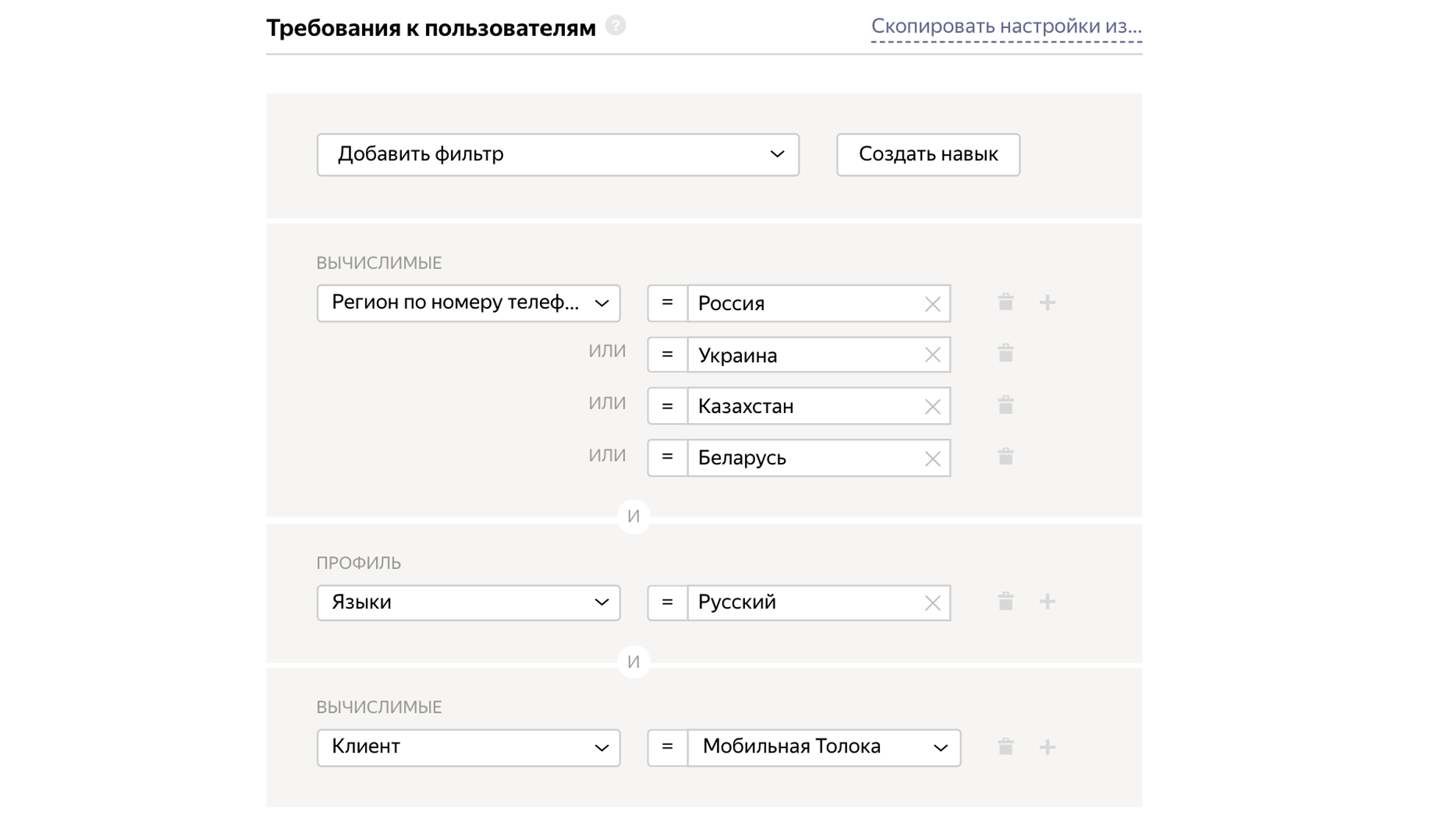
Descarga de tareas al grupo.
¡Comenzamos el grupo, nos alegramos y esperamos las respuestas de los usuarios! Así es como se ve nuestra tarea desde el lado del toloker:
Parte 2. Aceptación de tareas
Después de esperar un par de horas, vemos que los tolkers completaron la tarea. Dado que con la aceptación retrasada, la adjudicación no se paga al contratista de inmediato, sino que se congela en el balance del cliente, ahora debemos verificar todas las imágenes enviadas. Para que los artistas de buena fe acepten tareas, y para los artistas que enviaron imágenes inadecuadas para los criterios, se niegan y escriben el motivo de la negativa.
Si no hubiera muchas imágenes, entonces podríamos ver y verificar todas las imágenes enviadas por nosotros mismos. ¡Pero queremos obtener miles y decenas de miles de imágenes! Verificar este volumen de tareas requerirá una cantidad de tiempo considerable. Además, este proceso requiere nuestra participación directamente.
Toloka viene al rescate otra vez! Podemos crear una nueva tarea "Verificación de imágenes de contador" y pedir a otros trabajadores que respondan si la imagen se ajusta a nuestros criterios o no. Al configurar el proceso una vez, obtenemos una recopilación y validación de datos completamente automática. Al mismo tiempo, la recopilación de datos es fácilmente escalable, y si necesitamos aumentar el tamaño del conjunto de datos varias veces, simplemente haga clic en un par de botones.
Suena increíble y grandioso, ¿no?
¡Entonces es hora de poner en práctica la idea!
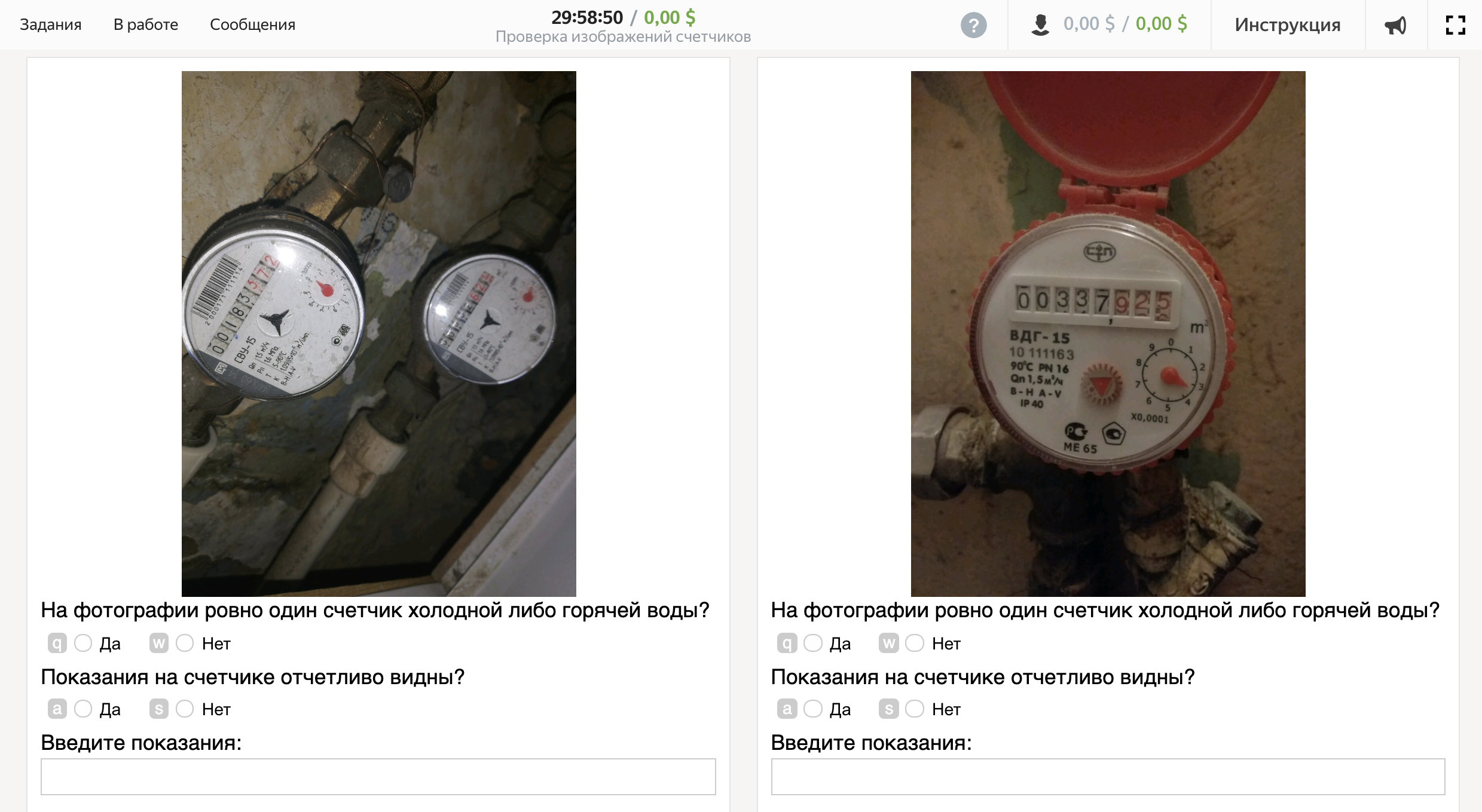
En primer lugar, definiremos los criterios por los cuales consideraremos que la foto es buena.
Una foto es buena si:
- En la foto hay exactamente un contador de agua fría o caliente;
- Las lecturas en el mostrador son claramente visibles.
En otros casos, la foto se considera mala.
Hemos resuelto los criterios, ¡ahora estamos escribiendo una instrucción! 
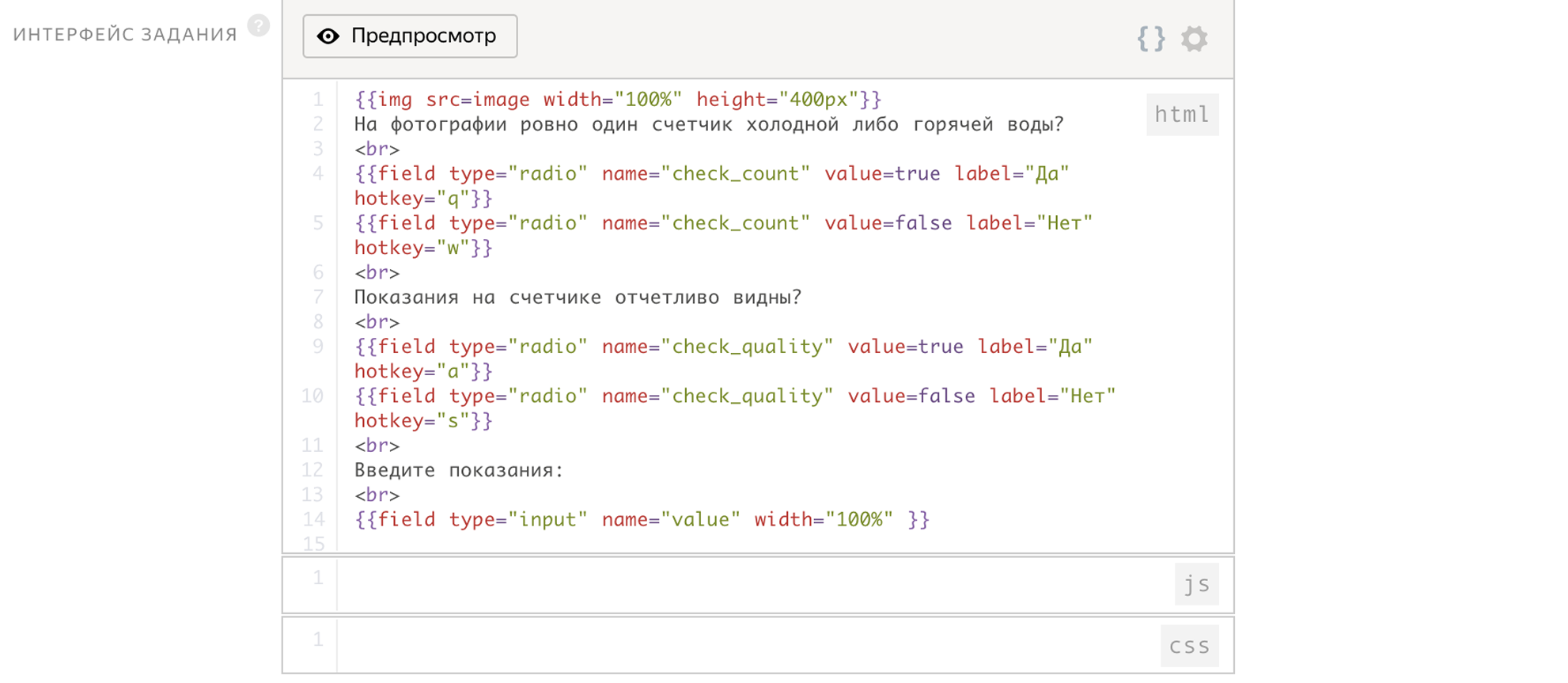
Como parámetros de entrada pasamos el enlace a la imagen. La salida será dos banderas:
- check_count - responde a la primera pregunta
- check_quality - responde a la segunda pregunta
El contador se escribirá en la variable de valor.
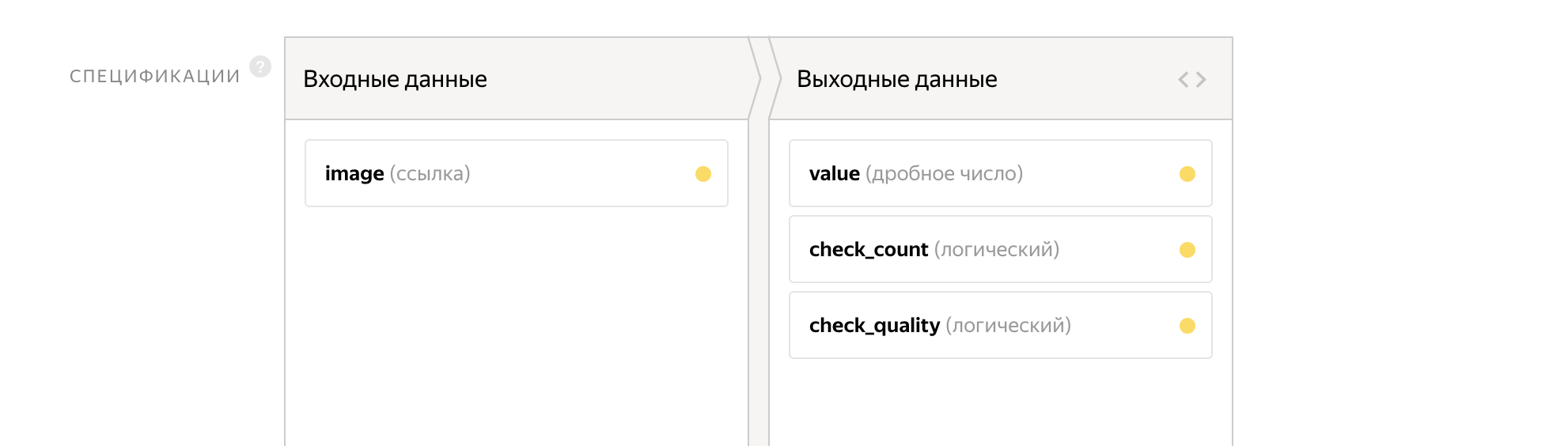
La interfaz de esta tarea ya tiene 14 líneas.
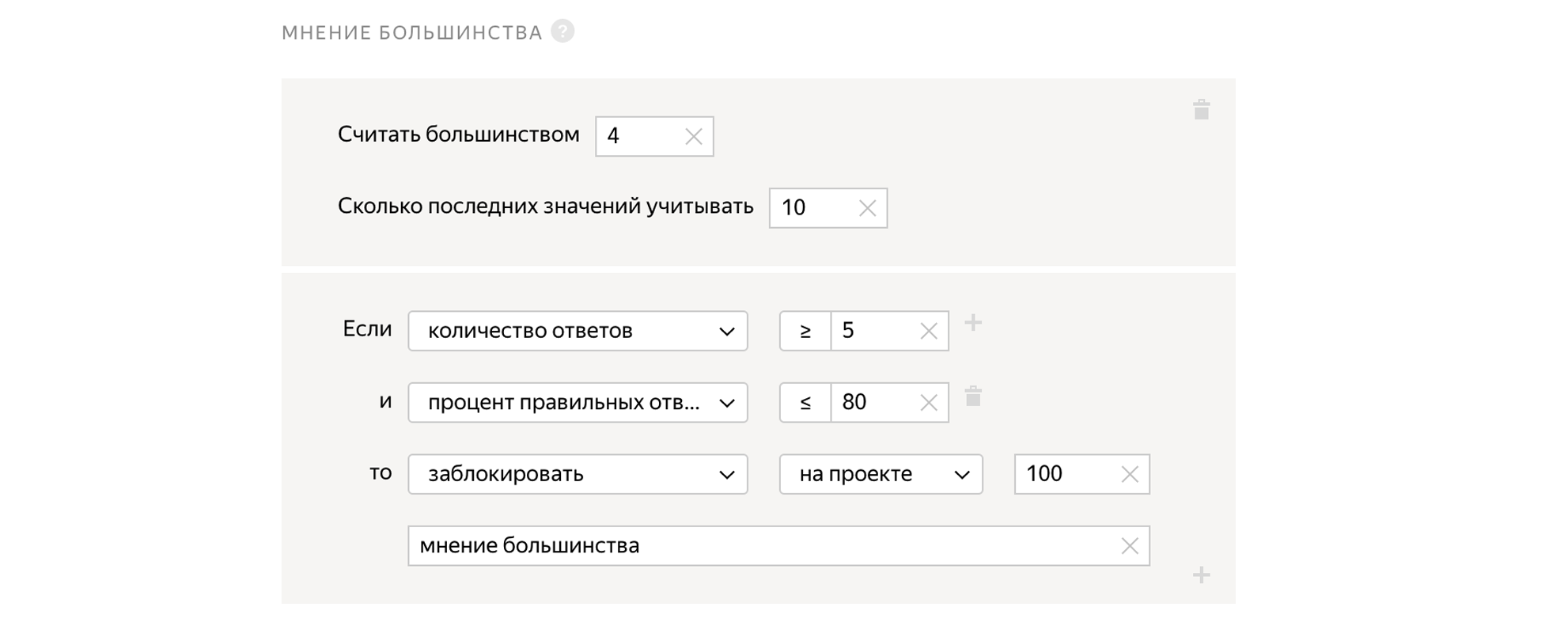
Para aumentar la precisión, 5 imágenes serán verificadas independientemente por 5 tokers, para esto pondremos una superposición de 5. Después de eso, veremos cómo respondieron 5 personas y asumiremos que la respuesta correcta es la que votó la mayoría. Esta tarea ya no tendrá una aceptación retrasada.
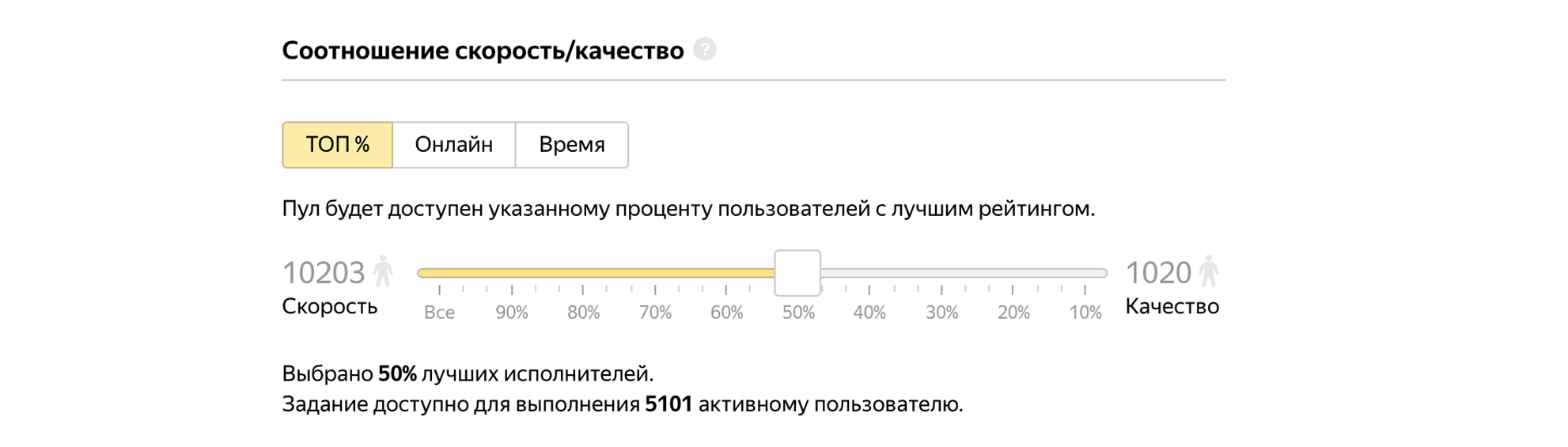
Admitamos el 50% de los mejores artistas a la tarea.
En tareas sin aceptación tardía, todos reciben el pago, independientemente de si realizan la tarea correctamente o no. Pero queremos que los usuarios lean cuidadosamente las instrucciones, intenten completar la tarea correctamente. ¿Cómo se puede lograr esto?
Hay dos herramientas principales en Tolok que le permiten mantener una buena calidad:
- Entrenamiento Antes de completar la tarea principal, podemos pedirles a los entrenadores que se capaciten. En el grupo de capacitación, a las personas se les asignan tareas para las cuales sabemos de antemano las respuestas correctas. Si una persona respondió incorrectamente, se le muestra un error y se le explica cómo responder. Después de completar la capacitación, vemos qué porcentaje de tareas completó el intérprete y solo podemos permitir que aquellos que hicieron bien al grupo principal de tareas.
- Bloques de control de calidad. Puede haber una situación en la que el grupo de entrenamiento del artista era excelente, se nos permitió hacerlo, pero cinco minutos después se fue a jugar al fútbol, dejando a su hermano de tres años en la computadora. Afortunadamente, hay muchos métodos en Tolok que le permiten realizar un seguimiento de cómo las personas completan las tareas.
Con el grupo de entrenamiento, todo es simple: solo agregue tareas, márquelas en la interfaz Yandex.Tolki y especifique el umbral para pasar, comenzando desde el cual permitimos que las personas realicen la tarea principal.
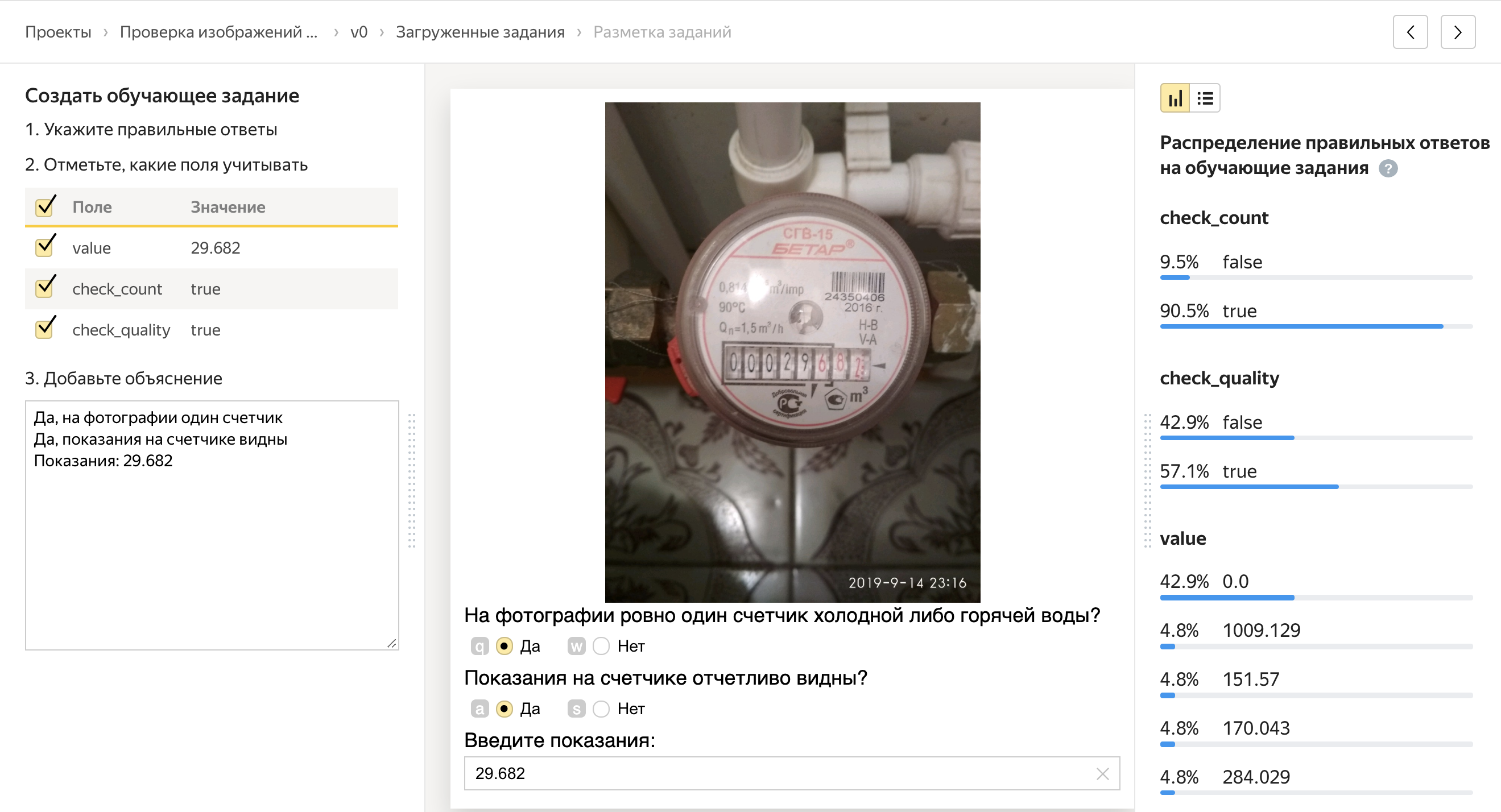
Con las unidades de control de calidad, todo es más interesante: hay bastantes, pero me centraré en las dos más importantes.
Opinión mayoritaria
Damos la tarea a 5 personas independientes. Y si cuatro personas responden "Sí" a la pregunta, y la quinta responde "No", entonces la quinta probablemente cometió un error. Por lo tanto, podemos ver cómo las respuestas de la persona son consistentes con las respuestas de otras personas y bloquear a los usuarios que responden de manera diferente a los demás.
Tareas de control
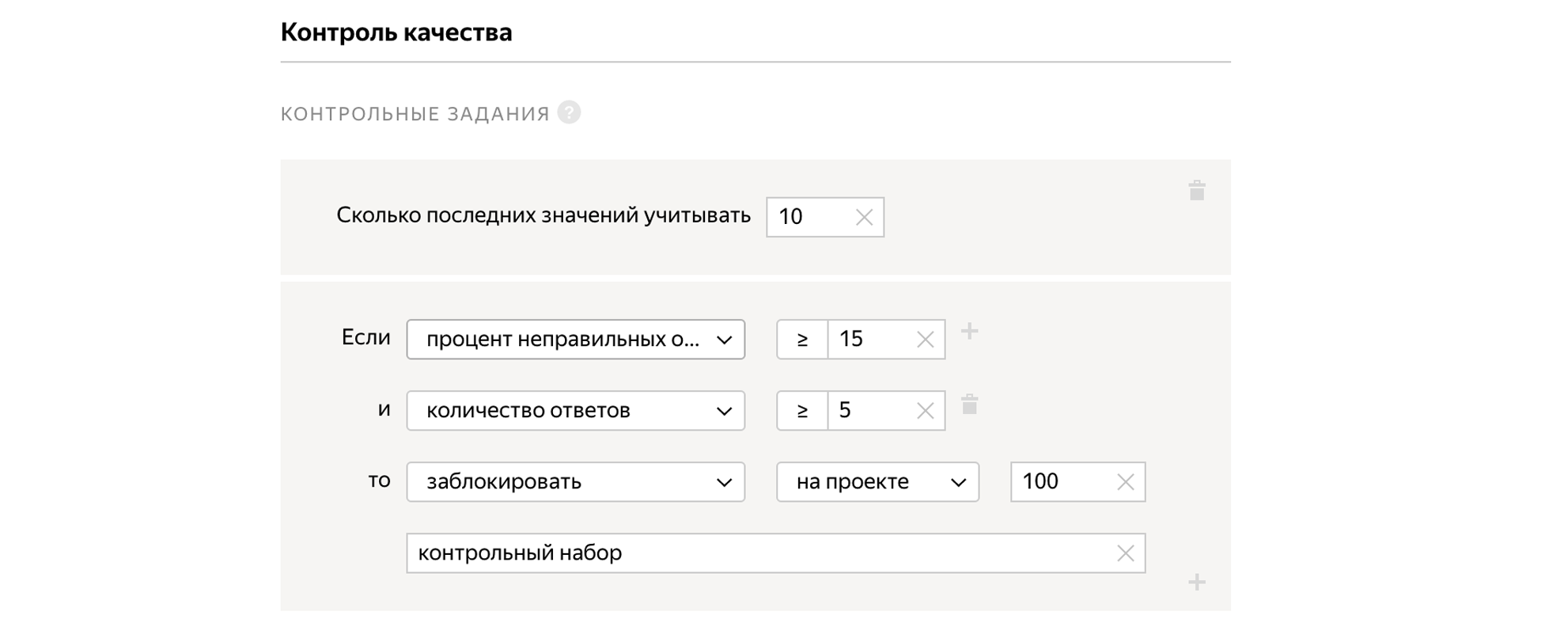
Podemos mezclar tareas en el grupo, para lo cual sabemos de antemano la respuesta correcta. Al mismo tiempo, las tareas de control de calidad tienen el mismo aspecto que las tareas normales. Sobre la base de si una persona responde las tareas de control correctamente, podemos extrapolar y asumir, correctamente o no, que resuelve todas las demás tareas para las que no conocemos las respuestas. Si una persona responde mal a las tareas de control, podemos bloquearla y, si es buena, otorgar una bonificación.
¡Hurra, tarea creada! Así es como se ve la interfaz del ejecutor:
Parte 3. Unirse a empleos
¡Genial, las tareas están listas! Pero surge la pregunta, ¿cómo conectar las tareas entre sí? ¿Cómo hacer la segunda carrera después de la primera tarea?
Por supuesto, puedes jugar con una pandereta y hacerlo manualmente a través de la interfaz de Toloka, ¡pero hay una forma más simple y rápida! Yandex.Tolok tiene una API , ¡úsala y escribe un script de python!
Sé que a muchos de ustedes no les gusta leer código, así que lo escondí debajo de un spoilerimport pandas as pd import numpy as np import requests import boto3
Ejecutamos el código y aquí está el resultado tan esperado: el conjunto de datos de 871 imágenes de contador está listo.

Precio
Vamos a evaluar el componente económico del proyecto.
Para la imagen enviada en la primera tarea, ofrecemos $ 0.01.
Desafortunadamente, si le pagamos al artista $ 0.01, tendremos que pagar $ 0.018.
¿Cómo se hace esto?
- La comisión de Yandex es min (0.005.20%). Para una tarea con un precio de 0.01 $, la comisión será del 50%;
- El IVA es del 20%.
Para verificar 10 imágenes de contadores, pagamos $ 0.01. En este caso, una imagen es verificada 5 veces por personas independientes. En total, damos para verificar una imagen: (0.01 x 5/10) x 1.2 x 1.5 = $ 0.009.
De los 1000 envíos enviados, se recibieron 871 imágenes y se rechazaron 129. Entonces, para obtener un conjunto de datos de 871 imágenes, pagamos:
0.018 $ x 871 + 0.009 $ x 1000 = $ 25 y necesita 92,000 rublos para obtener un conjunto de datos de 50,000 imágenes. ¡Esto es definitivamente más barato que ordenar anuncios en el canal federal!
Pero esta cifra en realidad se puede reducir varias veces. Usted puede:
- Sugiera en la primera tarea tomar no una foto, sino varias. Al mismo tiempo, aumente el precio, entonces la comisión de Yandex no será del 50%, sino del 20%;
- Utilice la superposición dinámica en la segunda tarea. Si 4 de cada 5 personas dieron la misma respuesta, entonces no tiene sentido darle la tarea a la quinta persona;
- Trabajar con Toloka como entidad legal extranjera. En este caso, no paga el IVA.
Como había tanto material, decidí dividir el artículo en dos partes. La próxima vez hablaremos con usted sobre cómo seleccionar objetos en imágenes usando Toloka y crear conjuntos de datos para tareas en Computer Vision. ¡Y para no perderte, suscríbete y dale me gusta!
PS
Después de leer el artículo, puede parecerle que este es un anuncio oculto de Yandex.Tolki, pero no, no lo es. Yandex no me pagó nada, y lo más probable es que no me pague. Solo quería mostrar en un ejemplo ficticio, pero relevante e interesante, cómo usar este servicio puede armar un conjunto de datos de manera rápida y económica para cualquier tarea, ya sea la tarea de reconocer gatos o entrenar vehículos no tripulados.