Hace cinco años, se publicó en Habré un artículo
"Impresión y reproducción de sonido en papel" sobre el sistema para crear y reproducir
espectrogramas . Luego, hace un año y medio,
Meklon publicó una
búsqueda en la que un espectrograma logarítmico en blanco y negro se convirtió en una de las etapas. Según la intención del autor, era necesario imprimirlo en una impresora, escanearlo con un teléfono inteligente con una aplicación de reproductor y utilizar la contraseña "dictada" de esta manera.
En ese momento, no tenía alcance ni para una impresora o un teléfono inteligente, por lo que estaba interesado en dos aspectos de la tarea:
- ¿Cuál es la forma más fácil de decodificar el espectrograma sin dispositivos adicionales y sin software adicional, preferiblemente, directamente en el navegador?
- ¿Es posible descifrarlo sin ningún tipo de software, "a simple vista"?
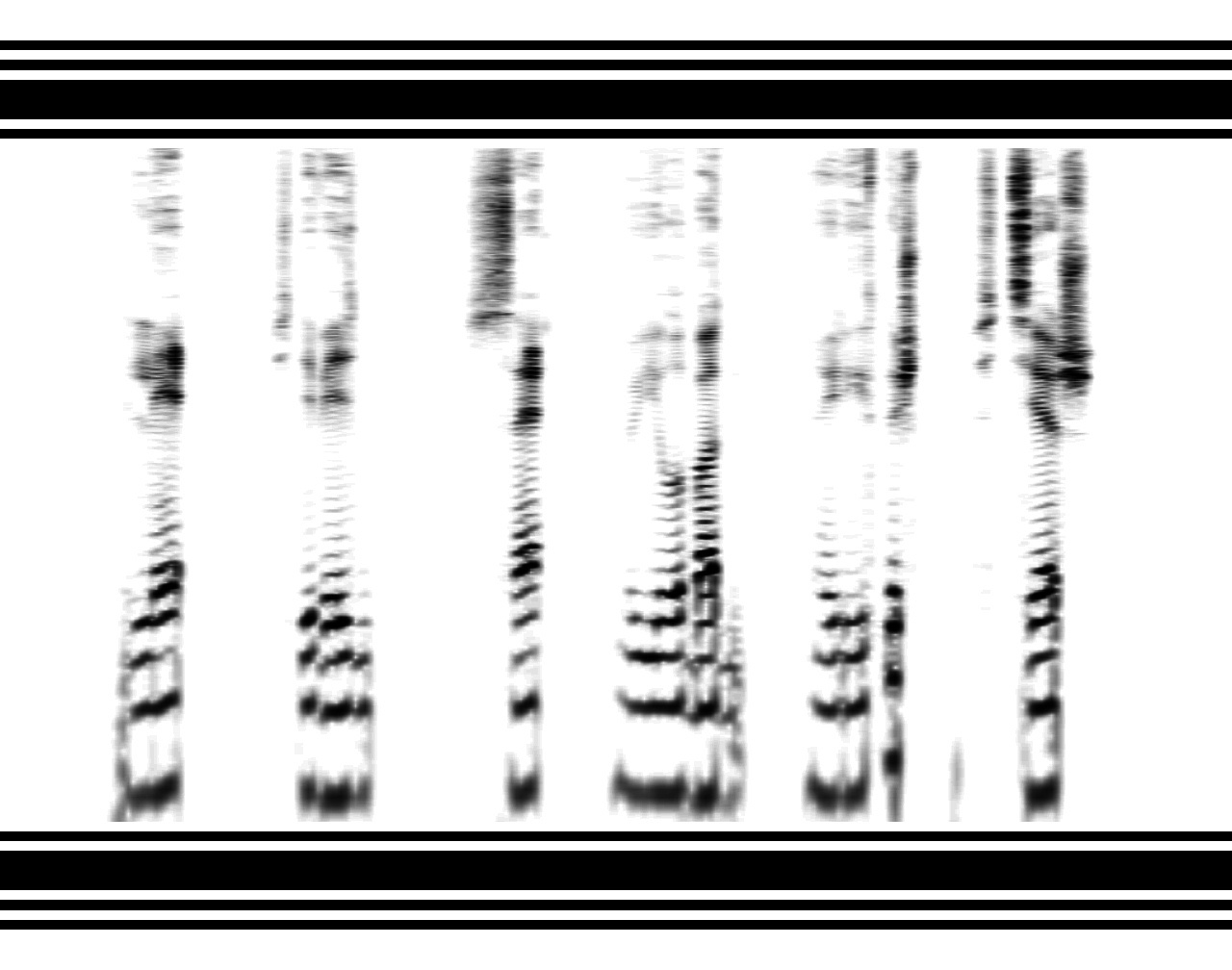
(Para aquellos que ven espectrogramas por primera vez, vale la pena aclarar que este es un gráfico donde el tiempo de reproducción va a lo largo del eje horizontal, la frecuencia del sonido a lo largo del eje vertical (es logarítmico) y el grado de oscuridad del punto indica el poder de esta frecuencia en un momento dado).
No encontré ningún script preparado para reproducir espectrogramas, aunque
es fácil encontrar ejemplos para la conversión inversa, sonido a espectrograma, debido a que la funcionalidad de
AnalyserNode.getByteFrequencyData() está integrada en la API de audio web. Pero para convertir una matriz de frecuencia en una matriz
PCM para la reproducción, no puede hacerlo sin implementar una
transformación inversa de
Fourier (DFT) en un script.
* En el primer ejemplo, como una grabación de audio para análisis espectral, un fragmento de la pista " "de Aphex Twin: como mensaje secreto, el músico insertó una selfie en esta pista, que aparece en un espectrograma logarítmico. Desafortunadamente, en este ejemplo, el espectrograma se muestra linealmente, de modo que la cara se estira en la parte superior y se comprime en la parte inferior.
Con respecto a la implementación de DFT, está claro de inmediato que un "crasher" en JavaScript puro funcionará lenta y tristemente; Afortunadamente, descubrí que el
puerto listo para usar de la biblioteca FFTW ("La transformación de Fourier más rápida en Occidente") en asm.js es una forma de representación de código de bajo nivel, generalmente escrito en C, que los navegadores modernos prometen ejecutar a una velocidad casi como compilada en código máquina. El enlace para FFTW, que convierte una imagen en blanco y negro en un archivo WAV, lo tomé de
ARSS y lo reescribí personalmente en JavaScript. ARSS acepta imágenes invertidas en comparación con PhonoPaper, y no lo cambié.
El resultado se puede admirar en
tyomitch.imtqy.com/#meklon.pngEn la parte inferior, se ven rayas horizontales repetidas:
formantes , por la posición de las cuales se reconocen las vocales. En la parte superior - "ráfagas" verticales correspondientes a
consonantes ruidosas : más ancho - ranurado (fricativo), más estrecho - vocal.
En cuanto a las consonantes
sonoras ([r] y [l]), las "nubes" en las frecuencias medias corresponden.

Para jugar con el espectrograma, adjunté un dibujo primitivo, casi completamente copiado del
tutorial de dibujo en lienzo. El botón "Copiar" le permite transferir la imagen al canal rojo (el sintetizador lo ignora) y tratar de "rodear" los sonidos.
Wikipedia escribe:
"Se cree que la asignación de cuatro formantes es suficiente para caracterizar los sonidos del habla" . Hacemos un círculo alrededor de los formantes F
2 -F
4 (por alguna razón F
1 es ignorado por el sintetizador), y nos
aseguramos de que las vocales sean completamente reconocidas:

Luego rodeamos las ruidosas consonantes: el
africano [h] es [t], convirtiéndose suavemente en [w]; y expresado [d] de sordo [t] se distingue por la presencia de formantes de frecuencia media. Ahora
puede distinguir entre los números "seis" y "de'it":
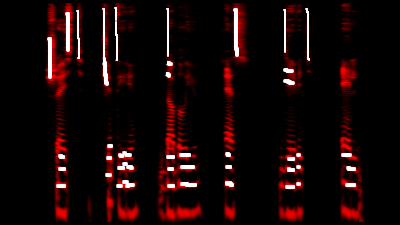
Agregue consonantes sonoras de color gris oscuro: al mismo tiempo, tenga en cuenta que [p] "eleva" ligeramente los formantes vocales y [l], por el contrario, omite.

Solo las consonantes labiales [b] y [c] permanecieron mal entendidas, pero incluso sin ellas la contraseña es
más o menos clara .
¿Es posible extraer sonido desde cero sin rastrear el espectrograma de la grabación de audio? Francamente, no tuve éxito. ¿Quizás quieras probarlo tú mismo?