Este artículo es mi intento de expresar mi opinión sobre los siguientes aspectos:
- ¿Qué es un factor de velocidad de aprendizaje y cuál es su valor?
- ¿Cómo elegir este coeficiente al entrenar modelos?
- ¿Por qué es necesario cambiar el coeficiente de la velocidad de aprendizaje durante el entrenamiento de modelos?
- ¿Qué hacer con un factor de velocidad de aprendizaje cuando se usa un modelo pre-entrenado?
La mayor parte de esta publicación se basa en materiales preparados por
fast.ai : [1], [2], [5] y [3], que representan una versión concisa de su trabajo destinada a la comprensión más rápida de la esencia del problema. Para familiarizarse con los detalles, se recomienda hacer clic en los enlaces que figuran a continuación.
¿Qué es un factor de velocidad de aprendizaje?
El coeficiente de velocidad de aprendizaje es un hiperparámetro que determina el orden de cómo ajustaremos nuestras escalas teniendo en cuenta la función de pérdida en el descenso de gradiente. Cuanto más bajo es el valor, más lento nos movemos a lo largo de la inclinación. Aunque cuando se utiliza un bajo coeficiente de velocidad de aprendizaje, podemos obtener un efecto positivo en el sentido de que no perdemos un mínimo local, esto también puede significar que tendremos que pasar mucho tiempo en la convergencia, especialmente si estamos en la región de la meseta.
La relación se ilustra con la siguiente fórmula
 Descenso de gradiente con factores de velocidad de aprendizaje pequeños (arriba) y grandes (abajo). Fuente: curso de aprendizaje automático de Andrew Ng en Coursera
Descenso de gradiente con factores de velocidad de aprendizaje pequeños (arriba) y grandes (abajo). Fuente: curso de aprendizaje automático de Andrew Ng en Coursera
Muy a menudo, el factor de velocidad de aprendizaje lo establece el usuario arbitrariamente. En el mejor de los casos, para una comprensión intuitiva de qué valor es el más adecuado para determinar el coeficiente de velocidad de aprendizaje, puede confiar en experimentos previos (u otro tipo de material de capacitación).
Esencialmente, es lo suficientemente difícil elegir el valor correcto. El siguiente diagrama ilustra varios escenarios que pueden surgir cuando el usuario ajusta independientemente la velocidad de aprendizaje.
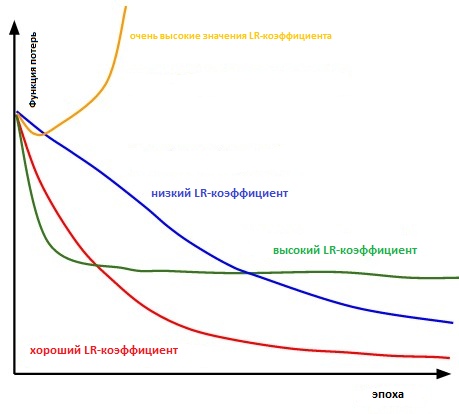 La influencia de varios factores de tasa de aprendizaje en la convergencia. (Crédito Img: cs231n)
La influencia de varios factores de tasa de aprendizaje en la convergencia. (Crédito Img: cs231n)
Además, el factor de velocidad de aprendizaje afecta la rapidez con que nuestro modelo alcanza un mínimo local (también conocido como logrará la mejor precisión). Por lo tanto, la elección correcta desde el principio garantiza menos pérdida de tiempo para entrenar el modelo. Cuanto menos tiempo de entrenamiento, menos dinero se gasta en la potencia informática de la GPU en la nube.
¿Hay alguna forma más conveniente de determinar la tasa de coeficiente de aprendizaje?
En el apartado 3.3. "
Coeficientes de tasa de aprendizaje cíclico para redes neuronales " Leslie Smith defendió lo siguiente: la eficiencia del aprendizaje se puede estimar entrenando un modelo con una velocidad de aprendizaje baja inicialmente establecida, que luego aumenta (lineal o exponencialmente) en cada iteración.
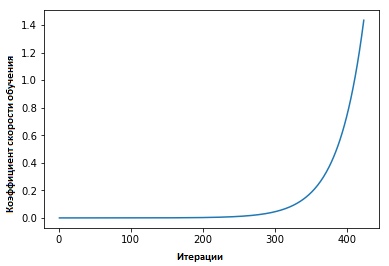 El factor de velocidad de aprendizaje aumenta después de cada mini paquete.
El factor de velocidad de aprendizaje aumenta después de cada mini paquete.
Al fijar los valores de los indicadores en cada iteración, veremos que a medida que aumenta la velocidad de aprendizaje, se alcanza un punto (en el cual) los valores de la función de pérdida dejan de disminuir y comienzan a aumentar. En la práctica, nuestra velocidad de aprendizaje idealmente debería estar en algún lugar a la izquierda del punto inferior del gráfico (como se muestra en el gráfico a continuación). En este caso (el valor será) de 0.001 a 0.01.
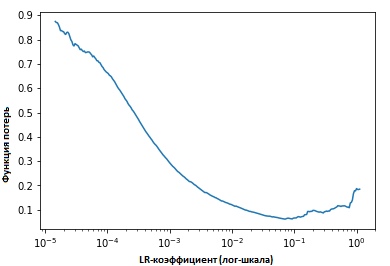
Lo anterior parece útil. ¿Cómo empezar a usarlo?
En este momento hay una función
lista para
usar en el paquete
fast.ia desarrollado por Jeremy Howard, este es un tipo de abstracción / complemento en la parte superior de la biblioteca pytorch (similar a cómo se hace en el caso de Keras y Tensorflow).
Solo es necesario ingresar el siguiente comando para comenzar la búsqueda del coeficiente óptimo de velocidad de aprendizaje antes de (comenzar) entrenar la red neuronal.
learn.lr_find() learn.sched.plot_lr()
Mejorando el modelo
Entonces, hablamos sobre cuál es el coeficiente de velocidad de aprendizaje, cuál es su valor y cómo lograr su valor óptimo antes de comenzar a entrenar el modelo en sí.
Ahora nos centraremos en cómo se puede usar el factor de velocidad de aprendizaje para ajustar modelos.
Sabiduría Convencional
Por lo general, cuando el usuario establece su coeficiente de velocidad de aprendizaje y comienza a entrenar el modelo, debe esperar hasta que el coeficiente de velocidad de aprendizaje comience a caer y el modelo alcance el valor óptimo.
Sin embargo, desde el momento en que el gradiente alcanza una meseta, se hace más difícil mejorar los valores de la función de pérdida cuando se entrena el modelo. En [3], Dauphin expresa la opinión de que la dificultad para minimizar la función de pérdida proviene del punto de silla de montar, y no del mínimo local.
 Un punto de silla de montar en la superficie de los errores. Un punto de silla de montar es un punto del dominio de definición de una función que es estacionaria para una función determinada, pero no es su extremo local
Un punto de silla de montar en la superficie de los errores. Un punto de silla de montar es un punto del dominio de definición de una función que es estacionaria para una función determinada, pero no es su extremo local . (ImgCredit: safaribooksonline)
Entonces, ¿cómo se puede evitar esto?
Propongo considerar varias opciones. Uno de ellos, general, usando la cita de [1],
... en lugar de usar un valor fijo para el coeficiente de velocidad de aprendizaje y disminuirlo con el tiempo, si el entrenamiento ya no suaviza nuestra pérdida, vamos a cambiar el coeficiente de velocidad de aprendizaje en cada iteración de acuerdo con alguna función cíclica f. Cada ciclo tiene, en términos del número de iteraciones, una longitud fija. Este método permite que el coeficiente de velocidad de aprendizaje varíe entre valores límite razonables. Esto realmente ayuda, porque, al quedarnos atascados en los puntos de silla, al aumentar el coeficiente de velocidad de aprendizaje obtenemos una intersección más rápida de la meseta de los puntos de silla.
En [2], Leslie propone el "método del triángulo", en el cual el coeficiente de velocidad de aprendizaje se revisa después de cada una de varias iteraciones.

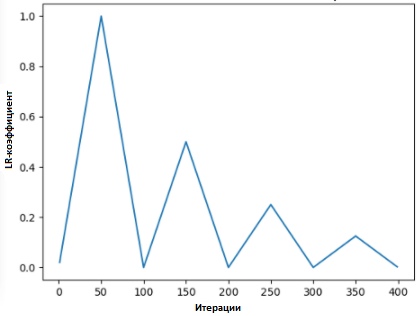 "El método de triángulos" y "método de triángulos-2" son métodos para pruebas cíclicas de coeficientes de velocidad de aprendizaje, propuestos por Leslie N. Smith. En el gráfico superior, el Ir mínimo y máximo se mantienen iguales.
"El método de triángulos" y "método de triángulos-2" son métodos para pruebas cíclicas de coeficientes de velocidad de aprendizaje, propuestos por Leslie N. Smith. En el gráfico superior, el Ir mínimo y máximo se mantienen iguales.Lonchilov & Hutter [6] propuso otro método, que no es menos popular y se llama "descenso de gradiente estocástico con un reinicio en caliente". Este método, que se basa en el uso de la función coseno como una función cíclica, reinicia el coeficiente de la velocidad de aprendizaje en el punto máximo de cada ciclo. La aparición del bit "Caliente" se debe al hecho de que cuando se reinicia el coeficiente de velocidad de aprendizaje, no comienza desde el nivel cero, sino desde los parámetros a los que el modelo ha llegado al paso anterior.
Dado que este método tiene variaciones, el siguiente gráfico muestra uno de los métodos de su aplicación, donde cada ciclo está vinculado al mismo intervalo de tiempo.
 SGDR - gráfico, coeficiente de tasa de aprendizaje vs. iteraciones
SGDR - gráfico, coeficiente de tasa de aprendizaje vs. iteraciones
Por lo tanto, obtenemos una forma de acortar la duración del entrenamiento simplemente saltando sobre los "picos" de vez en cuando (como se muestra a continuación).
 Comparación de coeficientes de tasa de aprendizaje fijo y cíclico
Comparación de coeficientes de tasa de aprendizaje fijo y cíclico (img credit:
arxiv.org/abs/1704.00109Además de ahorrar tiempo, este método, según los estudios, mejora la precisión de la clasificación sin ajustes y con menos iteraciones.
Transferir la tasa de aprendizaje en Transfer Learning
En el curso de
fast.ai, el énfasis está en la gestión de un modelo pre-entrenado para resolver problemas de inteligencia artificial. Por ejemplo, cuando se resuelven problemas de clasificación de imágenes, se les enseña a los estudiantes cómo usar modelos pre-entrenados como VGG y Resnet50 y vincularlos con la muestra de datos de imagen que necesita predecirse.
Para resumir cómo se construye el modelo en el programa
fast.ai (no debe confundirse con el
paquete fast. Ai - el paquete del programa), a continuación se
detallan los pasos que daremos en una situación ordinaria:
- Habilitar aumento de datos y precomputar = True
- Use Ir_find () para encontrar el coeficiente de tasa de aprendizaje más alto, donde la pérdida todavía está mejorando claramente.
- Entrena la última capa de activaciones precalculadas para la era 1-2.
- Entrene la última capa con ganancia de datos (es decir, calcule = falso) durante 1-2 épocas con el ciclo _len 1.
- Descongele todas las capas.
- Coloque las capas anteriores en un factor de velocidad de aprendizaje que sea 3x-10x debajo de la siguiente capa alta
- Reutilizar Ir_find ()
- Entrene una red completa con el ciclo _mult = 2 = 2 hasta que comience a reentrenar.
Puede notar que los pasos dos, cinco y siete (de los anteriores) están relacionados con la tasa de factor de aprendizaje. En una parte anterior de nuestra publicación, destacamos el punto de los segundos pasos mencionados, donde mencionamos cómo obtener el mejor coeficiente de velocidad de aprendizaje antes de comenzar a entrenar el modelo.
En el siguiente párrafo, hablamos sobre cómo puede reducir el tiempo de entrenamiento utilizando SGDR y reiniciando periódicamente el factor de velocidad de aprendizaje, mejorar la precisión para que pueda evitar áreas donde el gradiente es cercano a cero.
En la última sección, tocaremos el concepto de aprendizaje diferenciado y explicaremos cómo se utiliza para determinar el coeficiente de velocidad de aprendizaje cuando un modelo entrenado se asocia con un pre-entrenado ...
¿Qué es el aprendizaje diferencial?
Este es un método en el que varios factores de velocidad de entrenamiento se establecen en la red durante el entrenamiento. Proporciona una alternativa a la forma en que los usuarios suelen ajustar los factores de velocidad de aprendizaje, es decir, usar el mismo factor de velocidad de aprendizaje a través de la red durante el entrenamiento.
 La razón por la que amo Twitter es una respuesta directa de la persona misma.
La razón por la que amo Twitter es una respuesta directa de la persona misma.
(Al momento de escribir esta publicación, Jeremy publicó un artículo con Sebastian Ruder, quien se sumergió aún más en este tema. Entonces, creo, el coeficiente diferencial de velocidad de aprendizaje ahora tiene otro nombre: ajuste exacto discriminatorio :)
Para demostrar el concepto más claramente, podemos referirnos al diagrama a continuación, en el que el modelo previamente entrenado se "divide" en 3 grupos, donde cada uno se ajusta con un valor creciente del coeficiente de velocidad de aprendizaje.
 Ejemplo de CNN con coeficiente de tasa de aprendizaje diferenciado
Ejemplo de CNN con coeficiente de tasa de aprendizaje diferenciado . Crédito de imagen de [3]
Este método de configuración comprende lo siguiente: las primeras capas generalmente contienen detalles muy pequeños de los datos, como líneas y ángulos, desde los cuales no intentaremos cambiar mucho e intentar guardar la información contenida en ellos. En general, no hay una necesidad seria de cambiar su peso a un gran número.
Por el contrario, para las capas posteriores, como las de la imagen pintadas de verde, donde obtenemos signos detallados de los datos, como el blanco de los ojos, la boca o la nariz, la necesidad de salvarlos desaparece.
¿Cómo se compara esto con otros métodos de ajuste fino?
En [9], se demostró que ajustar el modelo completo sería demasiado costoso, ya que los usuarios pueden obtener más de 100 capas. Muy a menudo, las personas recurren a la optimización del modelo capa por capa.
Sin embargo, esta es la razón de una serie de requisitos, los llamados interferencia concurrente, y requiere múltiples entradas a través de un conjunto de datos, lo que lleva a un entrenamiento excesivo de conjuntos pequeños.
También demostramos que los métodos presentados en [9] son capaces de mejorar la precisión y reducir el número de errores en diversas tareas relacionadas con la clasificación de NRL.
 Resultados tomados de la fuente [9]
Resultados tomados de la fuente [9]Referencias
[1] Mejorando la forma en que trabajamos con la tasa de aprendizaje.
[2] La técnica del índice de aprendizaje cíclico.
[3] Transferir el aprendizaje utilizando tasas de aprendizaje diferenciales.
[4] Leslie N. Smith. Tasas de aprendizaje cíclico para la formación de redes neuronales.
[5] Estimación de una tasa de aprendizaje óptima para una red neuronal profunda
[6] Descenso de gradiente estocástico con reinicios cálidos
[7] Optimización para Deep Learning Highlights en 2017
[8] Cuaderno de la Lección 1, fast.ai Parte 1 V2
[9] Modelos lingüísticos ajustados para la clasificación de texto