Me llamo Ivan Bondarenko. He estado trabajando en algoritmos de aprendizaje automático para análisis de texto y lenguaje hablado desde aproximadamente 2005. Ahora trabajo en Moscú PhysTech como desarrollador científico líder del laboratorio de soluciones empresariales sobre la base del Centro de Competencia STI para la Inteligencia Artificial MIPT y en la empresa Data Monsters, que se ocupa del desarrollo práctico de sistemas interactivos para resolver diversos problemas en la industria. También enseño un poco en nuestra universidad. Mi historia estará dedicada a lo que es un bot de chat, cómo se utilizan los algoritmos de aprendizaje automático y otros enfoques para automatizar la comunicación humano-computadora y dónde se puede implementar.
La versión completa de mi discurso en la "Noche de historias científicas" se puede ver en el
video , y daré breves resúmenes en el texto a continuación.

Capacidades de algoritmo
En primer lugar, los algoritmos de interacción humana se utilizan con éxito en los centros de llamadas. El trabajo de un operador de call center es muy difícil y costoso. Además, en muchas situaciones es casi imposible resolver completamente el problema de la comunicación humano-computadora. Una cosa es cuando trabajamos con un banco, que generalmente tiene varios miles de clientes. Puede reclutar al personal del centro de atención telefónica, que atendería a estos clientes y hablaría con ellos. Pero cuando resolvemos tareas más ambiciosas (por ejemplo, producimos teléfonos inteligentes o alguna otra electrónica de consumo), nuestros clientes no son varios miles, sino varias decenas de millones en todo el mundo. Y queremos entender qué problemas tiene la gente con nuestros productos. Los usuarios, como regla, comparten información entre ellos en los foros o escriben al servicio de soporte del fabricante del teléfono inteligente. Los operadores en vivo no podrán hacer frente al trabajo en una gran base de clientes, y aquí los algoritmos vienen al rescate, que pueden funcionar en modo multicanal, sirviendo a una gran cantidad de personas.
Para resolver tales problemas, para construir algoritmos para sistemas de diálogo que puedan interactuar con una persona y extraer significado, información importante de mensajes arbitrarios, existe un área completa en el campo de la lingüística informática: el análisis de textos en lenguaje natural. Un robot debe ser capaz de leer, comprender, escuchar, hablar, etc. Esta área - Procesamiento del lenguaje natural - se divide en varias partes.
Comprensión del texto (Natural Language Understanding, NLU).
Cuando un bot se comunica con una persona y una persona escribe algo al bot, debe comprender lo que está escrito, lo que el usuario quería, lo que mencionó en su discurso. Comprender las intenciones del usuario, la llamada intención, lo que una persona quiere: volver a emitir una tarjeta bancaria o pedir una pizza. Y la asignación de entidades nombradas, es decir, cosas de las que el usuario habla específicamente: si es pizza, entonces "Margarita" o "Hawaiian", si es la tarjeta, entonces qué sistema: MasterCard, World, etc.

Y finalmente, una comprensión de la tonalidad del mensaje, en qué estado emocional se encuentra una persona. El algoritmo debe poder detectar en qué clave está escrito el mensaje, ya sea texto de noticias o este mensaje es de una persona que se comunica con nuestro bot para responder adecuadamente a la clave.
 Generación del texto (Generación del lenguaje natural)
Generación del texto (Generación del lenguaje natural) : una respuesta adecuada a una solicitud humana en el mismo lenguaje humano (natural), y no una placa compleja ni frases formales.
Reconocimiento de voz y síntesis de voz (voz a texto y texto a voz). Si un chatbot no solo se corresponde con una persona, sino que habla y escucha, debe enseñarle a comprender el lenguaje hablado, convertir las vibraciones de sonido en texto, luego analizar este texto con un módulo de comprensión de texto y generar vibraciones de sonido a partir del texto de respuesta. cuál entonces la persona, el suscriptor oirá.
Tipos de bots de chat
Los chatbots incluyen varias arquitecturas clave.
El chatbot que responde las preguntas más frecuentes (FAQ-chatbot) es la opción más fácil. Siempre podemos formular un conjunto de preguntas modelo que la gente hace. Para un sitio para la entrega de alimentos terminados, por regla general, estas son preguntas: "cuánto costará la entrega", "¿entrega al distrito de Pervomaisky", etc. Puede agruparlos de acuerdo con varias clases, intenciones, intenciones de los usuarios. Y para cada intento, seleccione respuestas típicas.
Bot de chat dirigido (bot orientado a objetivos). Aquí intenté mostrar la arquitectura de tal chatbot, que se implementa en el proyecto iPavlov. iPavlov es un proyecto para crear inteligencia artificial conversacional. En particular, un chatbot enfocado ayuda al usuario a lograr un objetivo (por ejemplo, reservar una mesa en un restaurante o pedir pizza, o aprender algo sobre problemas en el banco). No se trata solo de la respuesta a la pregunta (pregunta-respuesta, sin ningún contexto). El chatbot específico tiene un módulo para comprender el texto, la gestión del diálogo y un módulo para generar respuestas.
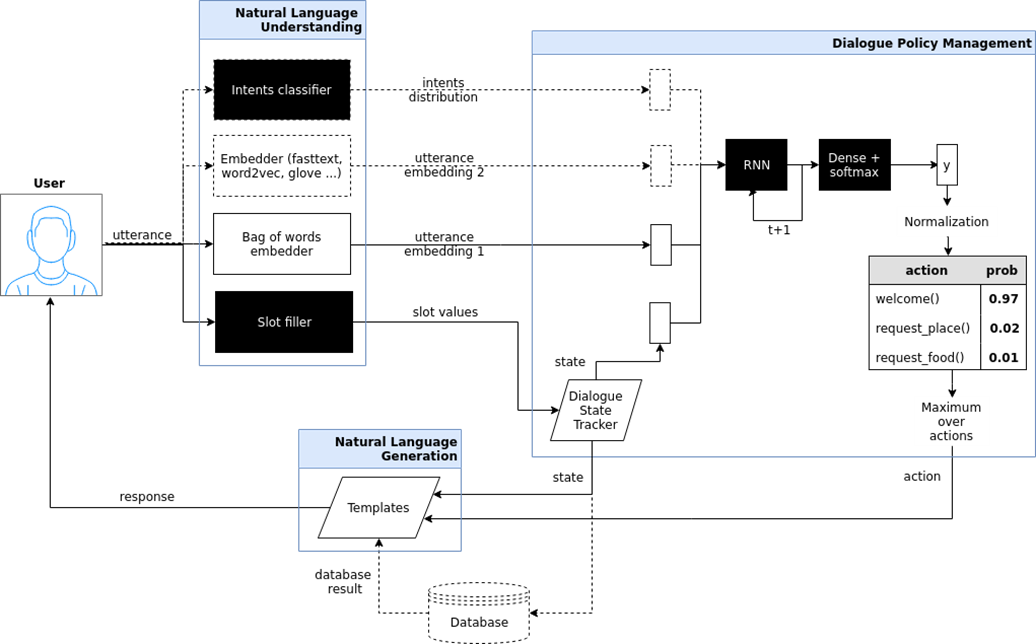 Chat bots del sistema de respuesta de preguntas sistema de respuesta de preguntas y solo "conversadores" (chit chat bot).
Chat bots del sistema de respuesta de preguntas sistema de respuesta de preguntas y solo "conversadores" (chit chat bot). Si los dos tipos anteriores de bots de chat responden las preguntas más frecuentes o guían al usuario a través del cuadro de diálogo, al final, ayudan a reservar un restaurante, descubren lo que el usuario quiere, cocina china o italiana, etc., entonces la pregunta-respuesta un sistema es otro tipo de chat bot. El objetivo de un bot de chat de este tipo no es moverse a lo largo de la columna del diálogo y no solo clasificar las intenciones del usuario, sino proporcionar una búsqueda de información, para encontrar el documento más relevante que coincida con la pregunta de la persona y el lugar en el documento donde está contenida la respuesta. Por ejemplo, los empleados de un gran minorista en lugar de memorizar las instrucciones que rigen el trabajo, o buscar una respuesta donde colocar el trigo sarraceno, hacen una pregunta a dicho chatbot basado en un sistema de preguntas y respuestas.
Tipos de aprendizaje automático
El reconocimiento de intentos, la asignación de entidades nombradas, la búsqueda en documentos y la búsqueda de lugares en un documento que correspondan a la semántica de una pregunta, todo esto sin aprendizaje automático, sin algún tipo de análisis estadístico es imposible de implementar. Por lo tanto, la base de los bots de chat modernos es el aprendizaje automático: métodos de tareas, aproximaciones de algunos patrones ocultos que existen en grandes conjuntos de datos y la identificación de estos patrones. Tiene sentido aplicar este enfoque cuando hay patrones, tareas, pero es imposible encontrar una fórmula simple, formalismo para describir este patrón.
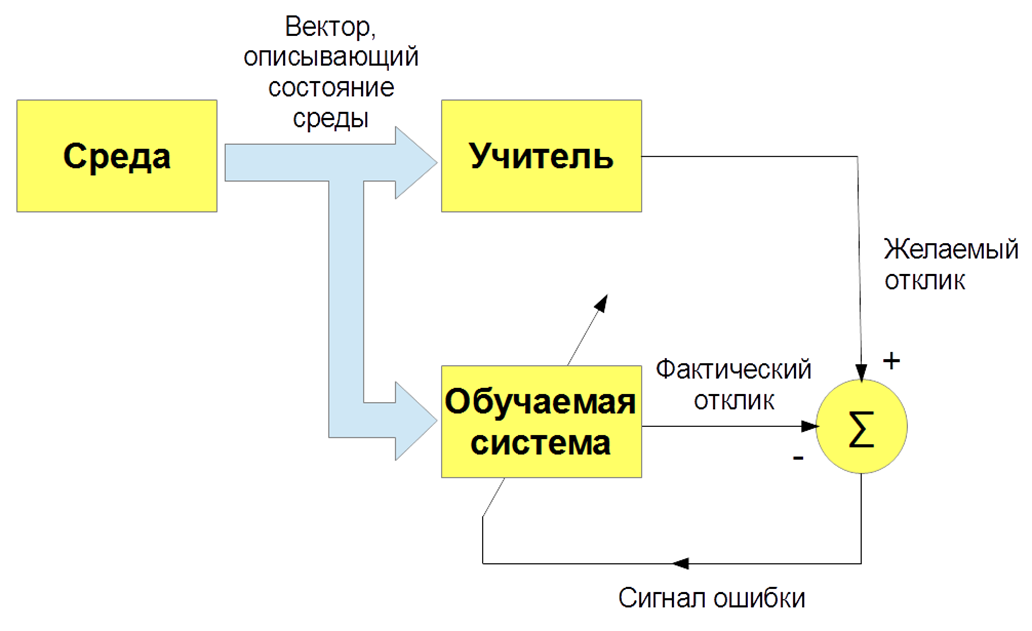
Existen varios tipos de aprendizaje automático: con un maestro (aprendizaje supervisado), sin un maestro (aprendizaje no supervisado), con refuerzo (aprendizaje de refuerzo). Estamos principalmente interesados en la tarea de enseñar con un maestro, cuando hay imágenes de entrada e instrucciones (etiquetas) del maestro y la clasificación de estas imágenes. O ingrese señales de voz y su clasificación. Y enseñamos a nuestro bot, nuestro algoritmo para reproducir el trabajo de un maestro.
De acuerdo, todo parece estar bien. ¿Y cómo enseñarle a una computadora a entender textos? El texto es un objeto complejo, y ¿cómo se convierten las letras en números y se obtiene una descripción vectorial del texto? Existe la opción más simple: una "bolsa de palabras". Pedimos al diccionario de todo el sistema, por ejemplo, todas las palabras que están en el idioma ruso, y formulamos vectores muy escasos con frecuencias de palabras. Esta opción es buena para preguntas simples, pero para tareas más complejas no es adecuada.
En 2013, se produjo una especie de revolución en el modelado de palabras y textos. Thomas Mikolov propuso un enfoque especial para la representación vectorial efectiva de palabras basada en la hipótesis de distribución. Si se encuentran diferentes palabras en el mismo contexto, entonces tienen algo en común. Por ejemplo: "Los científicos realizaron un análisis de los algoritmos" y "Los científicos realizaron un estudio de los algoritmos". Entonces, "Análisis" e "investigación" son sinónimos y significan aproximadamente lo mismo. Por lo tanto, puede enseñar una red neuronal especial para predecir una palabra por contexto o contexto por palabra.
Finalmente, ¿cómo entrenamos? Para entrenar al bot para que comprenda intenciones, intenciones verdaderas, debe marcar manualmente un grupo de textos usando programas especiales. Para enseñarle al bot a comprender las entidades nombradas (el nombre de la persona, el nombre de la empresa, la ubicación), también debe colocar textos. En consecuencia, por un lado, el algoritmo de aprendizaje con el maestro es el más efectivo, le permite crear un sistema de reconocimiento efectivo, pero, por otro lado, surge un problema: necesita conjuntos de datos grandes y etiquetados, y esto es costoso y requiere mucho tiempo. En el proceso de marcado de conjuntos de datos, puede haber errores causados por el factor humano.
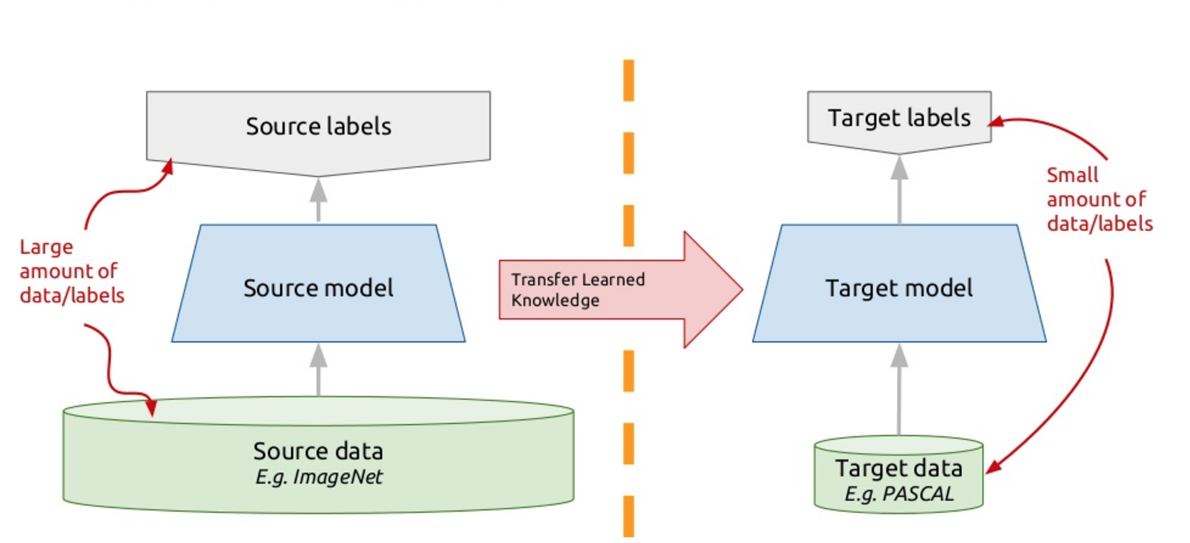
Para resolver este problema, los chatbots modernos utilizan el llamado aprendizaje de transferencia: aprendizaje de transferencia. Aquellos que saben muchos idiomas extranjeros, probablemente notaron tal matiz que es más fácil aprender otro idioma extranjero que el primero. En realidad, cuando estudias alguna tarea nueva, estás tratando de usar tu experiencia pasada para esto. Entonces, el aprendizaje de transferencia se basa en este principio: enseñamos el algoritmo para resolver un problema para el cual tenemos un gran conjunto de datos. Y luego, este algoritmo entrenado (es decir, tomamos el algoritmo no desde cero, sino entrenado para resolver otro problema), entrenamos para resolver nuestro problema. Por lo tanto, obtenemos una solución efectiva utilizando una pequeña variedad de datos.
Uno de estos modelos es ELMo (Incrustaciones de modelos de lenguaje), como ELMo de Sesame Street. Utilizamos redes neuronales recurrentes, tienen memoria y pueden procesar secuencias. Por ejemplo: “Al programador Vasya le encanta la cerveza. Todas las tardes después del trabajo, va al Jonathan y pierde un vaso o dos ". Entonces, ¿quién es él? ¿Es él esta noche, es una cerveza o es un programador Vasya? Una red neuronal que procesa palabras como elementos de una secuencia, dado el contexto, una red neuronal recurrente, puede comprender las relaciones, resolver este problema y resaltar algunas semánticas.
Entrenamos una red neuronal tan profunda para modelar textos. Formalmente, esta es la tarea de aprender con un maestro, pero el maestro es el texto no colocado en sí. La siguiente palabra en el texto es un maestro en relación con todas las anteriores. Por lo tanto, podemos usar gigabytes, docenas de gigabytes de textos, entrenar modelos efectivos que la semántica en estos textos enfatizan. Y luego, cuando usamos las incrustaciones de modelos de lenguaje (ELMo) en modo de salida, damos la palabra según el contexto. No solo un palo, sino que peguemos. Observamos lo que genera la red neuronal en este momento, lo que señala. Catamosamos estas señales y obtenemos una representación vectorial de la palabra en un texto específico, teniendo en cuenta su significado semántico específico.
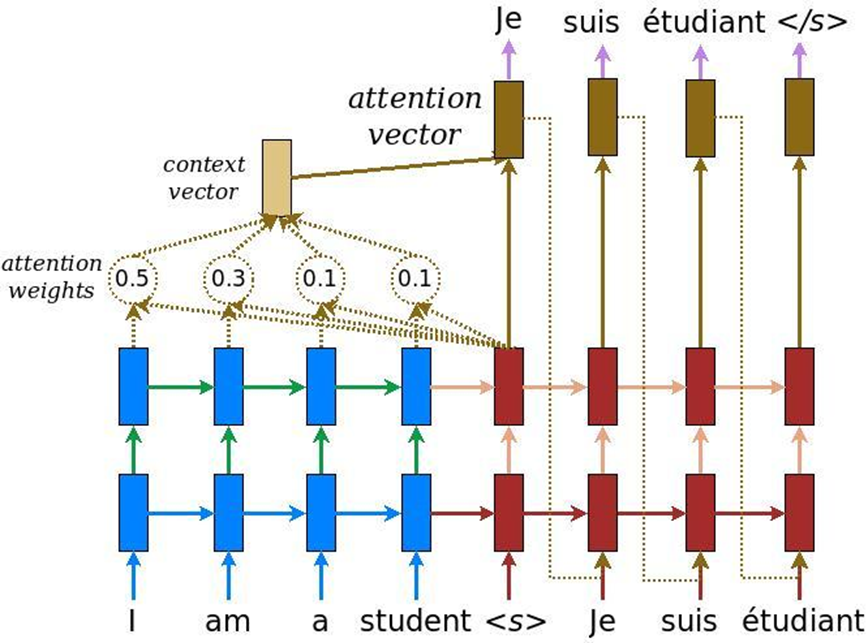
En el análisis de textos hay una característica más: cuando se resuelve la tarea de la traducción automática, se puede transmitir el mismo significado mediante una cantidad de palabras en inglés y otra cantidad de palabras en ruso. En consecuencia, no existe una comparación lineal, y necesitamos un mecanismo que se centre en ciertos textos para traducirlos adecuadamente a otro idioma. Inicialmente, se inventó la atención para la traducción automática: la tarea de convertir un texto en otro con sistemas neuronales recurrentes convencionales. A esto agregamos una capa especial de atención, que en cada momento evalúa qué palabra es importante para nosotros ahora.
Pero luego, los chicos de Google pensaron: ¿por qué no utilizar el mecanismo de atención sin redes neuronales recurrentes? Solo atención. Y se les ocurrió una arquitectura llamada transformador (BERT (Representaciones de codificador bidireccional de transformadores)).
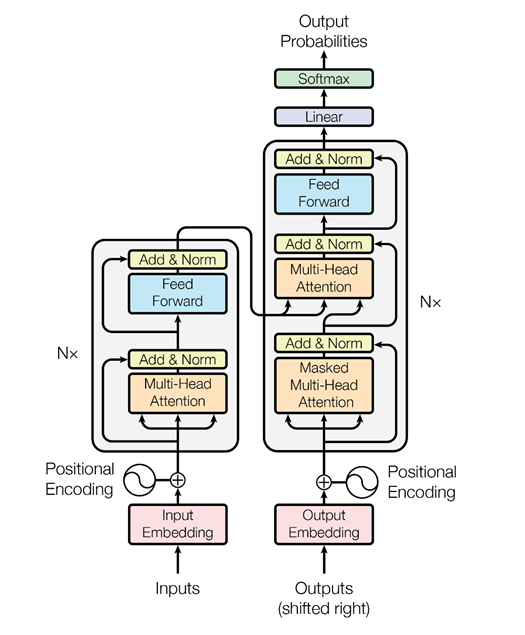
Sobre la base de dicha arquitectura, cuando solo hay atención de múltiples cabezas, se inventaron algoritmos especiales que también pueden analizar la relación de las palabras en los textos, la relación de los textos entre sí, como lo hace ELMo, solo de manera más astuta. En primer lugar, es una red más fresca y compleja. En segundo lugar, resolvemos dos problemas simultáneamente, y no uno, como en el caso de ELMo: modelado de lenguaje, pronóstico. Estamos tratando de restaurar palabras ocultas en el texto y restaurar enlaces entre textos. Es decir, digamos: “Al programador Vasya le encanta la cerveza. Todas las noches va al bar. Dos textos están interconectados. “El programador Vasya ama la cerveza. Las grullas vuelan hacia el sur en el otoño ”. Estos son dos textos no relacionados. Nuevamente, esta información se puede extraer de textos no asignados, BERT capacitado y obtener resultados muy interesantes.
Esto se publicó en noviembre pasado en el artículo "Atención es todo lo que necesitas", que recomiendo leer. Por el momento, este es el mejor resultado en el campo del análisis de texto para resolver varios problemas: para la clasificación de texto (reconocimiento de tonalidad, intenciones del usuario); para sistemas de preguntas y respuestas; para reconocer entidades con nombre, etc. Los sistemas de diálogo modernos utilizan BERT, incrustaciones contextuales pre-entrenadas (ELMo o BERT) para comprender lo que el usuario quiere. Pero el módulo de gestión del diálogo todavía se diseña a menudo basado en reglas, porque un diálogo particular puede depender mucho del tema o incluso de la tarea.