Hasta ahora, hemos estado discutiendo el tema de cómo aumentar la velocidad del sistema utilizando algunos métodos intensivos. Pero, de hecho, hay métodos extensos. Ahora estamos trabajando a una frecuencia de reloj de 50 MHz, que está asociada con el uso de un componente del conjunto para un programa universitario (y sin él es imposible cronometrar SDRAM, lo que requiere que los pulsos de reloj que van al microcircuito se desplacen en relación con los principales). Cuando introduje este componente en el juego, advertí que esta solución es temporal. Luego arrojé tanta información nueva sobre el lector que cualquier tedio adicional podría llevar a una exclamación: "Bueno, estos FPGA, ¡todo es tan complicado aquí!" Ahora ya estamos construyendo sistemas de procesadores de manera fácil y natural, todas las cosas terribles han quedado atrás. Es hora de descubrir cómo puede hacer su propio componente, lo que le permite aumentar la frecuencia de reloj tanto del procesador como de los periféricos conectados a él.
Artículos anteriores de la serie:
- Desarrollo del "firmware" más simple para FPGAs instalados en Redd, y depuración utilizando la prueba de memoria como ejemplo.
- Desarrollo del "firmware" más simple para FPGAs instalados en Redd. Parte 2. Código del programa.
- Desarrollo de su propio núcleo para incrustar en un sistema de procesador basado en FPGA.
- Desarrollo de programas para el procesador central Redd sobre el ejemplo de acceso a la FPGA.
- Los primeros experimentos utilizando el protocolo de transmisión en el ejemplo de la conexión de la CPU y el procesador en el FPGA del complejo Redd.
- Merry Quartusel, o cómo el procesador ha llegado a tal vida.
- Métodos de optimización de código para Redd. Parte 1: efecto caché.
- Métodos de optimización de código para Redd. Parte 2: memoria no almacenada en caché y operación de bus paralelo.
Un poco de razonamiento teórico.
Calculemos qué frecuencia podemos establecer sin dolor para el reloj de todo nuestro hierro. El chip SDRAM utilizado en el complejo permite una frecuencia límite de 133 MHz. Para conocer las velocidades de reloj del procesador, consulte los
puntos de referencia de rendimiento de Nios II . Allí, para nuestro FPGA Cyclone IV E, la frecuencia de núcleo Nios II / f de 160 MHz está garantizada. No soy partidario de exprimir todos los jugos del sistema, por lo que hablaremos sobre trabajar a una frecuencia de 100 MHz.
Para ser honesto, todavía no me ha inspirado la metodología para calcular el cambio de frecuencia del reloj que figura en la sección
32.7. Consideraciones de reloj, PLL y temporización de la Guía del usuario de IP de periféricos integrados , pero parece que no soy el único. Al menos, una búsqueda larga en la red no me llevó a artículos que contuvieran resultados calculados de la misma manera, pero no a la frecuencia que se da en el documento principal (los mismos 50 MHz).
Hay un artículo interesante al que le daré un enlace directo
www.emb4fun.de/fpga/nutos1/index.html . Uno podría referirse a él y decir "Hagamos como el autor", si no fuera por un "pero": el autor de este artículo usa el bloque PLL (en ruso - PLL, y en el hogar - un convertidor de frecuencia), insertando su propio código en VHDL. Yo, como ya se señaló en el
artículo sobre el divertido Quartusel , me adhiero a la ideología de que el sistema de procesador debe estar en el nivel superior de la jerarquía del proyecto. No se necesitan inserciones en ningún idioma, ya sea VHDL o Verilog. Recientemente, este enfoque mío recibió otra confirmación: tenemos un nuevo empleado, un estudiante que todavía no habla Verilog, pero que tiene un gran código para el complejo Redd, ya que el enfoque elegido lo permite.
Resulta que simplemente tomamos como base que todo funciona para el autor con un desplazamiento de menos 54 grados (qué tipo de grados se describe en el artículo, el enlace al que di el párrafo anterior).
A continuación, preste atención a otro artículo interesante
asral.unimap.edu.my/wp-content/uploads/2019/07/2019_IJEECS_Chan_Implementation-Camera-System.pdf . Todo funciona para los autores con un desplazamiento de menos 65 grados.
Intentemos hacer que nuestro sistema use un valor de este rango. Si durante la prueba diaria de RAM no hay un solo mal funcionamiento, dejaremos este valor como combate. Tenemos el derecho, ya que el "firmware" desarrollado para Redd no irá a los Clientes, sino que se utilizará para necesidades internas y en cantidades por pieza. En todo caso, siempre será posible arreglar todo sin dificultades innecesarias (surgen dificultades cuando es necesario actualizar el "firmware" en miles de dispositivos vendidos, y simplemente de un Cliente remoto).
Nueva pieza de configuración de hardware
Por alguna razón, me parece que el sistema de procesador para este artículo es más fácil de hacer desde cero que rehacer del anterior. Justo cómo demostrar el proceso de "torcer, torcer, querer confundir", refiriéndome constantemente a artículos anteriores, prefiero mostrar todo desde el principio una vez más. Al mismo tiempo, arreglamos el material. Entonces, comencemos.
Al principio, se nos muestra un sistema completamente vacío que contiene solo un reloj y una fuente de señal de reinicio.

Por lo general, no cambio nada allí, pero hoy haré una excepción. No quiero distraerme con el circuito de reinicio, ya que seguiremos trabajando desde debajo del depurador. Por lo tanto, cambiaré la condición de reinicio del nivel a una diferencia negativa, y la pierna misma se anulará posteriormente.
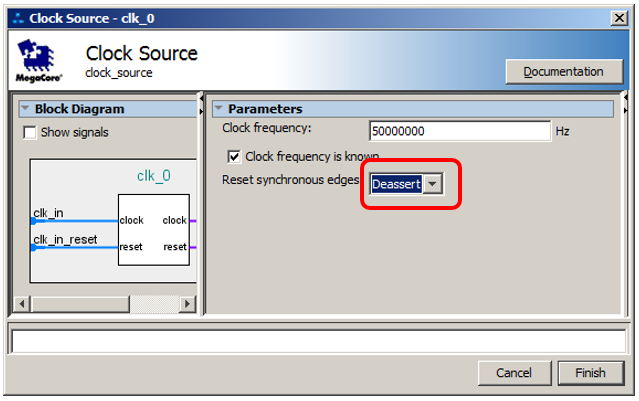
Pero aquí la señal del reloj tiene una frecuencia de 50 MHz (esta frecuencia se establece por las características del generador soldado a la placa). En el primero de los artículos que mencioné anteriormente, se utilizó el bloque PLL agregado al proyecto principal. ¿Dónde lo conseguimos aquí? ¡Y aquí está!
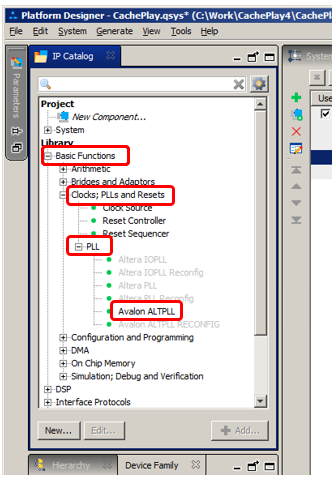
Este es el mismo bloque, pero aquí no tenemos que incrustar ningún código en Verilog o VHDL. ¡Todo ya está insertado para nosotros! Es cierto que la configuración para diferentes tipos de FPGA difiere ligeramente más que por completo. Más precisamente, los parámetros ajustables son más o menos los mismos, pero están ubicados en lugares fundamentalmente diferentes en los cuadros de diálogo de configuración. Dado que el FPGA Cyclone IV E se usa en el complejo Redd, consideraremos la configuración de esta opción.
En la primera pestaña, reemplace la frecuencia de entrada con 50 MHz (por defecto era 100) y vaya a la siguiente pestaña (haga clic en Siguiente, para Cyclone IV E tenemos que hacer esto muchas veces).

Desactive las entradas y salidas adicionales. No los necesitamos:
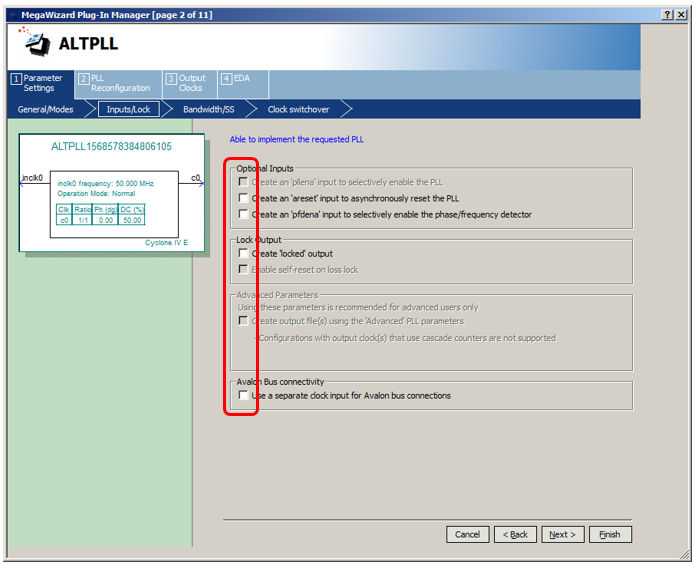
Nos saltamos las siguientes pestañas hasta que podamos configurar la salida C0. Allí cambiamos el botón de opción para establecer la frecuencia e ingresar el valor de 100 MHz:
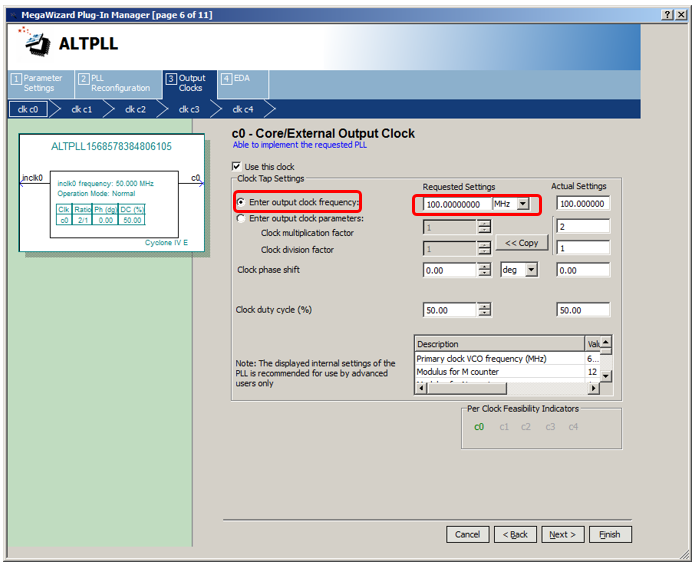
Con C1, las cosas son un poco más complicadas. Primero, seleccione la casilla de verificación que dice que también debe usarse. En segundo lugar, establecemos de manera similar la frecuencia de 100 MHz. Bueno, y en tercer lugar, establecemos el cambio de frecuencia. ¿Cuál preguntar? ¿Menos 58 o menos 65? Por supuesto, probé ambas opciones. Ambos me han ganado. Pero el argumento sobre el tema menos 58 parece un poco menos convincente, por lo que aquí recomendaré ingresar el valor menos 65 grados (mientras que la automatización me dirá que el valor real alcanzado será menos 63 grados).
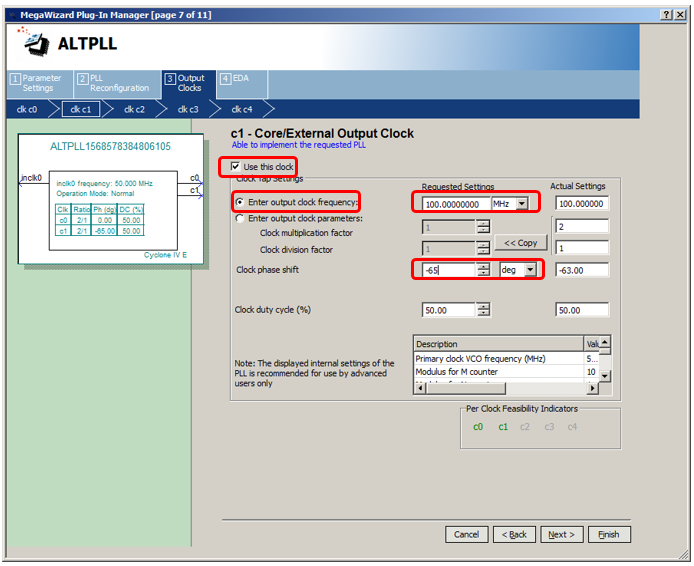
Bueno, eso es todo. Ahora puede pasar por el botón
Siguiente hasta el final, o simplemente hacer clic en
Finalizar . Conectamos las entradas
inclk_interface e
inclk_interface_reset . La salida
c0 se utilizará como reloj para todo el sistema. La salida
c1 se exporta para registrar el chip
sdram . En el futuro, deberá recordar conectar el bus de datos a la entrada
pll_slave . Para el ciclón V, esto no sería necesario.
Otras piezas de ferretería, solo para fijar material
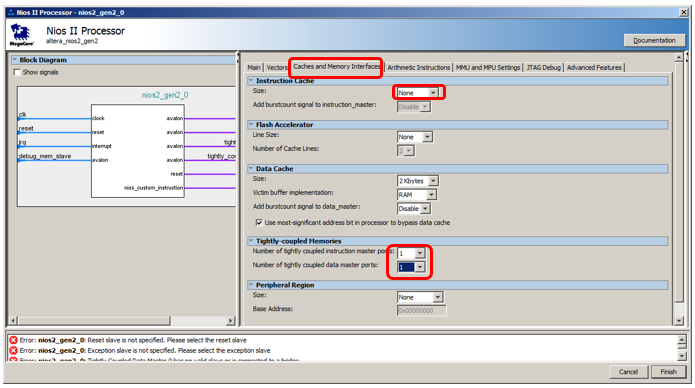
Agregar un núcleo de procesador. Hoy, nuestra SDRAM estará sujeta a pruebas. Por lo tanto, el código no debe ubicarse en él. Y esto, a su vez, significa que todo el código se ubicará en la RAM interna de la FPGA. Es decir, no necesitamos un caché de instrucciones. Apáguelo, ahorrando memoria FPGA. También conectamos un bus altamente conectado de instrucciones y datos. No se requieren configuraciones más interesantes para el núcleo del procesador.
Con el movimiento habitual de la mano, agregue dos bloques de RAM interna FPGA. Uno es un puerto dual con una capacidad de 16 kilobytes y uno es un puerto único con una capacidad de 4 kilobytes. Cómo nombrarlos y cómo conectarse, espero que todos lo recuerden. La última vez que me gustó resaltar los neumáticos con flores, quizás para facilitar la lectura, lo haré en este artículo.
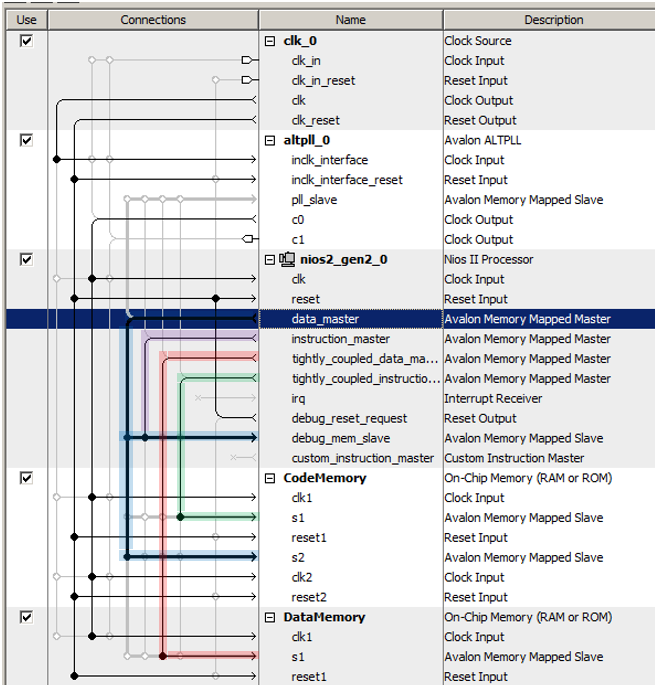
No olvide asignar a estos bloques de memoria direcciones especiales en el rango personal y bloquearlos. Deje que
CodeMemory se asigne a 0x20000000 y
DataMemory a 0x20004000.
Bueno, agreguemos un bloque
SDRAM al sistema, configurándolo, así como bloques
JTAG-UART para mostrar mensajes y un
GPIO de un solo bit, en el que mediremos la frecuencia real para asegurarnos de que aumente. Como referencia, aquí hay algunas configuraciones no obvias:
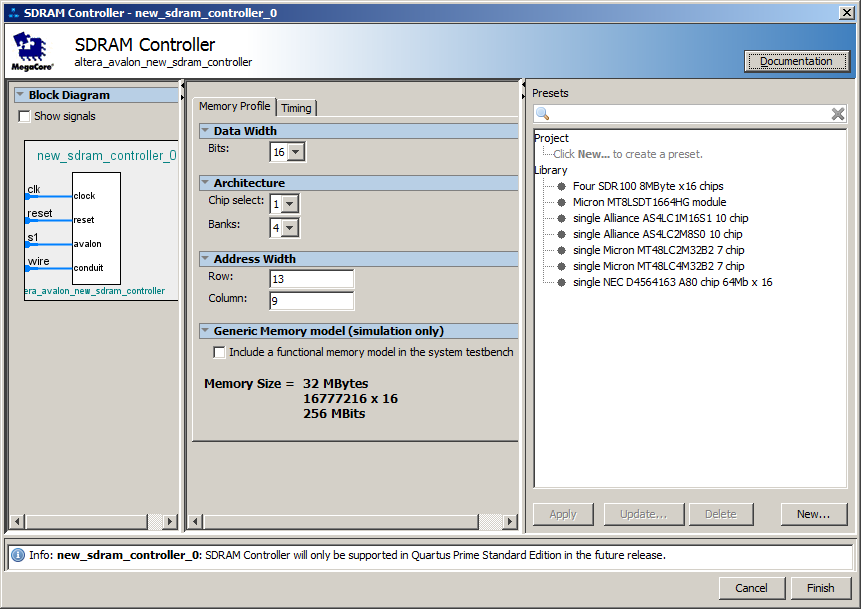
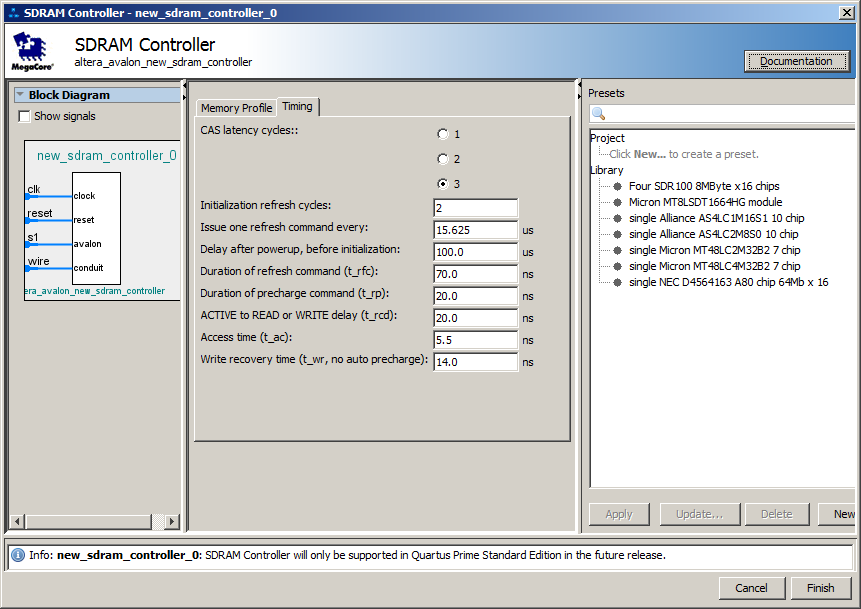

Total, obtenemos un sistema de este tipo (destaqué el bus de datos, ya que escanea todos los dispositivos externos):
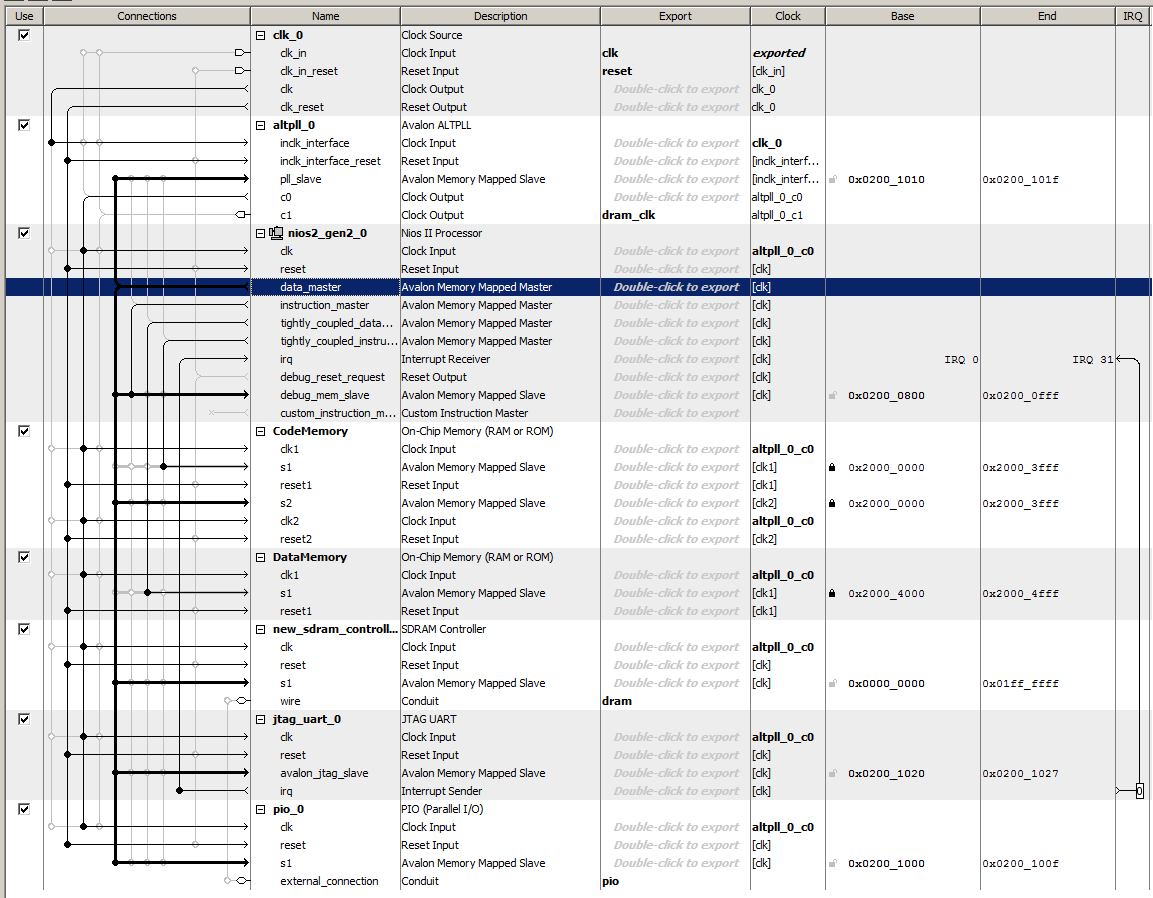
Asignamos vectores al procesador, asignamos direcciones automáticamente, asignamos automáticamente números de interrupción al sistema generador.
Conectamos el sistema al proyecto, hacemos un ensamblaje aproximado, asignamos los números de los
tramos , y esta vez hacemos virtual no solo
CKE , sino también
reset_n (cómo se hace esto, dije en
uno de los artículos anteriores , busque Virtual Pin allí). Hacemos el montaje final, llenamos el equipo en el FPGA. Eso es todo. Hemos terminado el equipo, ve a la parte de software.
Creamos BSP para nuestro entorno.
Para variar, creemos un proyecto basado en una plantilla no de
Hello World Small , sino de
Memory Test Small :
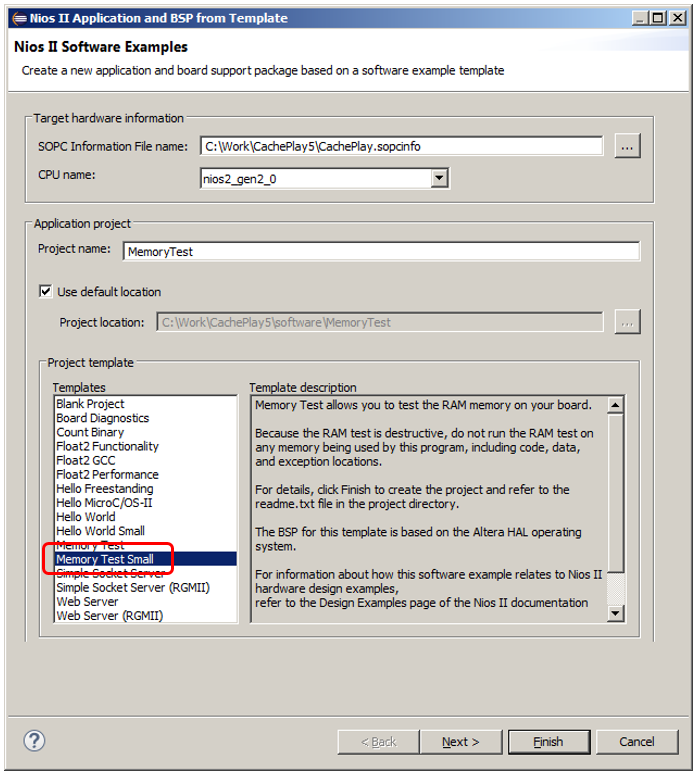
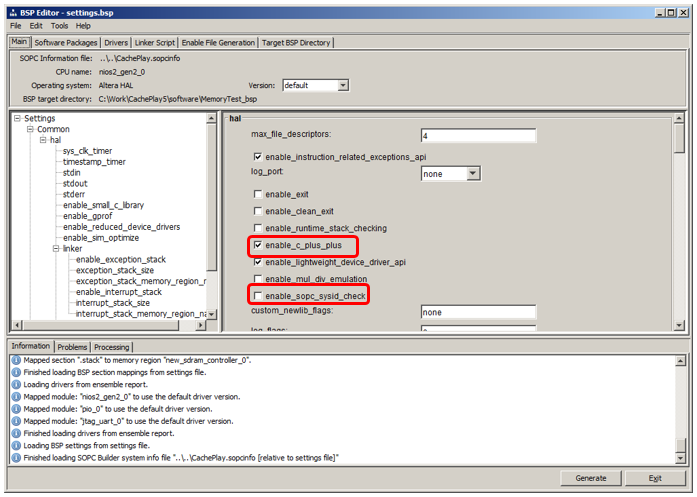
Cuando se creó, vaya al editor BSP. Como de costumbre, lo primero que hacemos es desactivar la verificación SysID y permitir el uso de C ++ (aunque esta vez no cambiaré el tipo de archivo, pero ya es un hábito para mí):
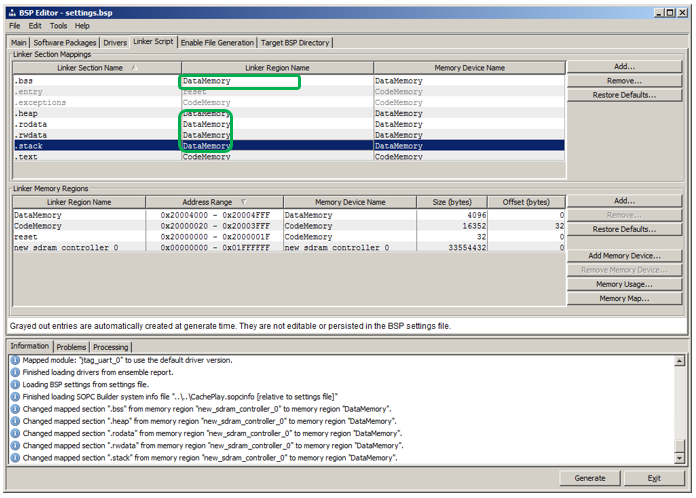
Pero lo más importante que tenemos que arreglar en la pestaña
Linker Script . Automation reconoció que el bus de instrucciones solo va a
CodeMemory , por lo que colocó una sección de código (llamada
.text ) en
CodeMemory . Pero cuidándonos, colocó todo lo demás en la región de datos más grande, que se encuentra en
SDRAM . ¿Cómo sabía ella que borraríamos sin piedad este recuerdo?

Tendremos que reemplazar manualmente, línea por línea, la región con
DataMemory (las listas de selección aparecerán allí, la selección debe reorganizarse en ellas). Deberíamos obtener esta imagen:
Experimentos del programa
Salimos del editor, generamos el BSP, intentamos ejecutar el programa para la depuración. Recibimos el siguiente texto:
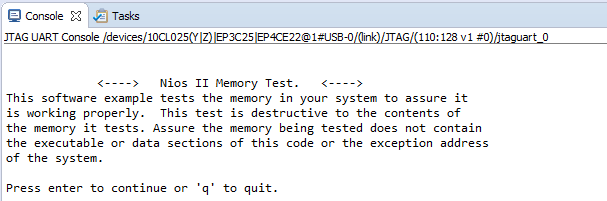
Si presiono Enter, no tuve éxito. Ingresé algo (sí, incluso un espacio) y luego presioné Enter. Entonces me preguntaron:

Hora por hora no es más fácil. ¿Y en qué dirección ingresar? Puede abrir Platform Designer y ver el valor allí. Pero generalmente busco en el archivo de referencia universal system.h (la ruta completa para mi proyecto es C: \ Work \ CachePlay5 \ software \ MemoryTest_bsp \ system.h). Allí nos interesan dos líneas:
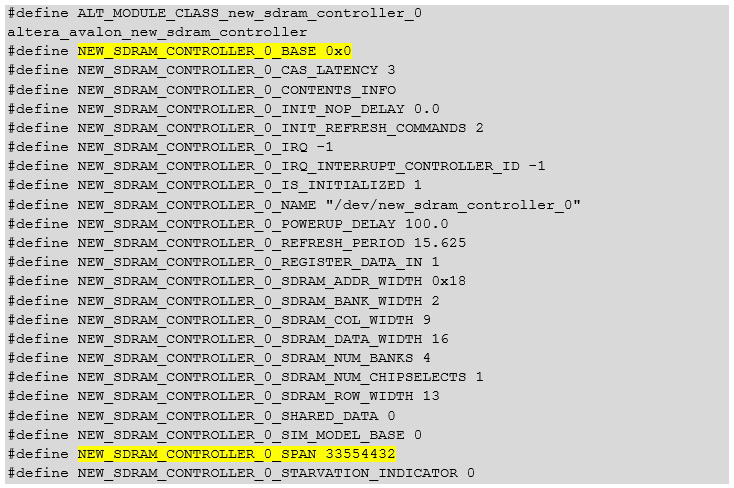
Mismo texto#define ALT_MODULE_CLASS_new_sdram_controller_0 altera_avalon_new_sdram_controller #define NEW_SDRAM_CONTROLLER_0_BASE 0x0 #define NEW_SDRAM_CONTROLLER_0_CAS_LATENCY 3 #define NEW_SDRAM_CONTROLLER_0_CONTENTS_INFO #define NEW_SDRAM_CONTROLLER_0_INIT_NOP_DELAY 0.0 #define NEW_SDRAM_CONTROLLER_0_INIT_REFRESH_COMMANDS 2 #define NEW_SDRAM_CONTROLLER_0_IRQ -1 #define NEW_SDRAM_CONTROLLER_0_IRQ_INTERRUPT_CONTROLLER_ID -1 #define NEW_SDRAM_CONTROLLER_0_IS_INITIALIZED 1 #define NEW_SDRAM_CONTROLLER_0_NAME "/dev/new_sdram_controller_0" #define NEW_SDRAM_CONTROLLER_0_POWERUP_DELAY 100.0 #define NEW_SDRAM_CONTROLLER_0_REFRESH_PERIOD 15.625 #define NEW_SDRAM_CONTROLLER_0_REGISTER_DATA_IN 1 #define NEW_SDRAM_CONTROLLER_0_SDRAM_ADDR_WIDTH 0x18 #define NEW_SDRAM_CONTROLLER_0_SDRAM_BANK_WIDTH 2 #define NEW_SDRAM_CONTROLLER_0_SDRAM_COL_WIDTH 9 #define NEW_SDRAM_CONTROLLER_0_SDRAM_DATA_WIDTH 16 #define NEW_SDRAM_CONTROLLER_0_SDRAM_NUM_BANKS 4 #define NEW_SDRAM_CONTROLLER_0_SDRAM_NUM_CHIPSELECTS 1 #define NEW_SDRAM_CONTROLLER_0_SDRAM_ROW_WIDTH 13 #define NEW_SDRAM_CONTROLLER_0_SHARED_DATA 0 #define NEW_SDRAM_CONTROLLER_0_SIM_MODEL_BASE 0 #define NEW_SDRAM_CONTROLLER_0_SPAN 33554432 #define NEW_SDRAM_CONTROLLER_0_STARVATION_INDICATOR 0
donde el decimal 33554432 es igual a hexadecimal 0x2000000. Por lo tanto, mis respuestas y el resultado del trabajo deberían verse así:
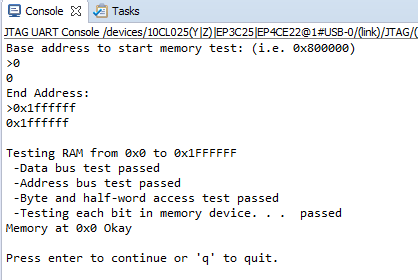
Genial, pero esto no es bueno para una prueba diaria. Reescribí la función
principal de esta manera:
int main(void) { int step = 0; while (1) { if (step++%100 == 0) { alt_printf ("."); } if (MemTestDevice(NEW_SDRAM_CONTROLLER_0_BASE, NEW_SDRAM_CONTROLLER_0_SPAN)!=0) { printf ("*"); } } return (0); }
Los puntos indican que el programa no se "congeló". Si hay un error, se mostrará un asterisco. Para mayor confiabilidad, puede poner un punto de interrupción en su salida, luego simplemente no lo duerma.
Es cierto que los puntos "izquierdos" subieron desde algún lugar. Resultó que se muestran dentro de la función
MemTestDevice () . Allí borré su conclusión. La prueba fue exitosa. El sistema resultante puede usarse, al menos para necesidades internas (es decir, tales desarrollos se llevan a cabo bajo el complejo Redd).
Comprobación del rendimiento del sistema
Pero ya estoy acostumbrado al hecho de que cuando trabajas con equipos no puedes confiar en nada. Todo debe ser revisado cuidadosamente. Asegurémonos de que trabajamos con una frecuencia duplicada en comparación con los artículos anteriores. Agregue la conocida función MagicFunction1 ().
Déjame recordarte cómo se ve. void MagicFunction1() { IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); }
Lo llamaremos desde
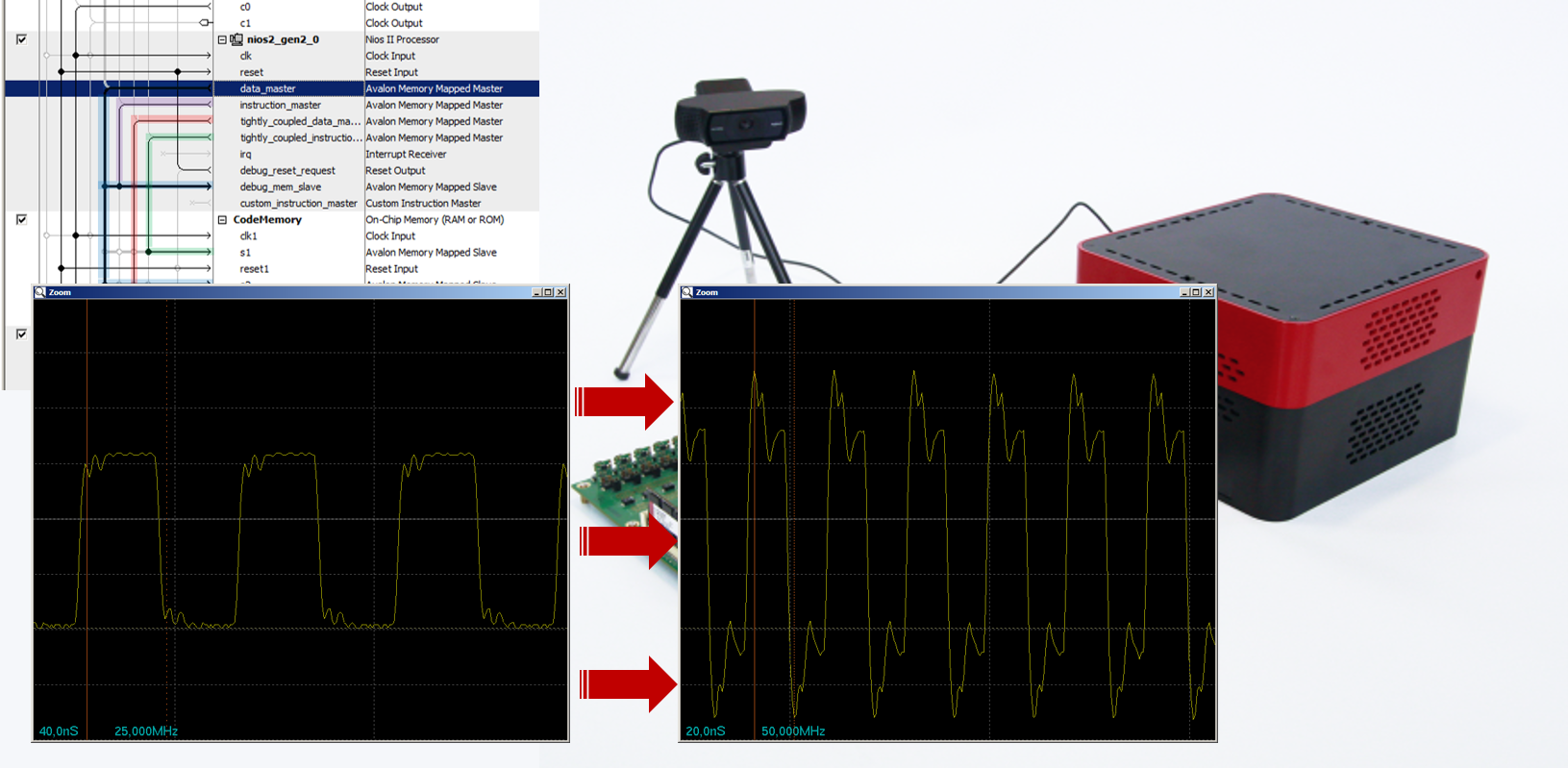
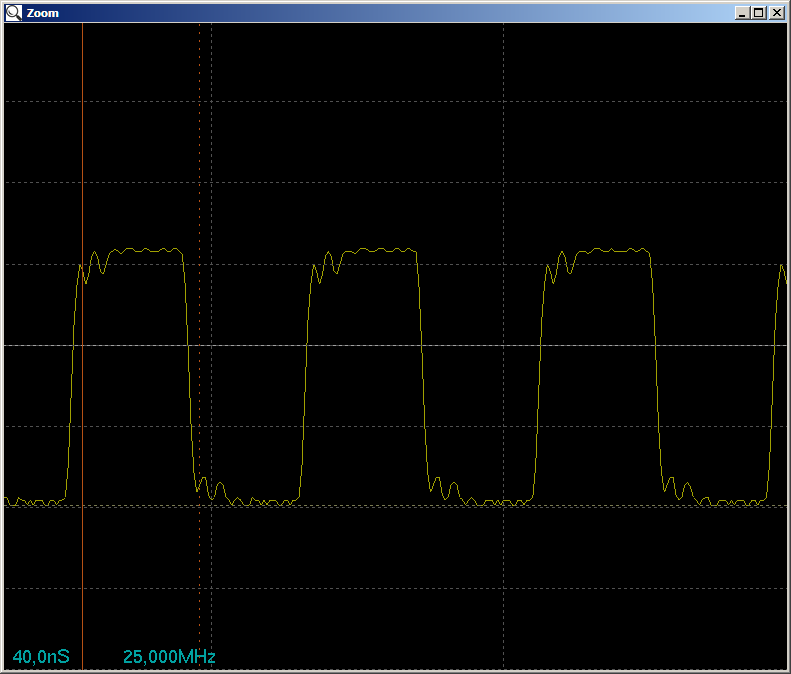
main () , captaremos los pulsos en el osciloscopio, pero esta vez prestaremos atención no solo a su belleza, sino también a la frecuencia (permítame recordarle que cada caída, incluso arriba, abajo, es un comando, por lo que puede medir la distancia entre las gotas )
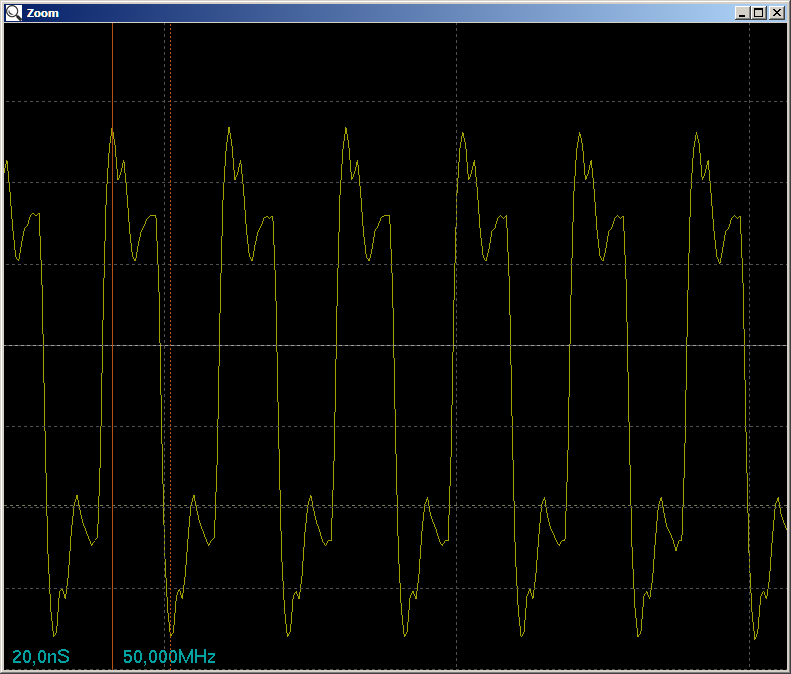
Solo 50 megahercios. ¿La frecuencia realmente no ha aumentado? Compare con la frecuencia del código desarrollado al escribir el último artículo, y entendemos que todo está en orden. Es solo que la unidad pio normal requiere 2 ciclos de reloj por salida al puerto (en una casera obtuve 1 reloj, pero aquí es suficiente para asegurarnos de que el rendimiento del sistema se duplique).
Conclusión
En lugar de usar un oscilador de frecuencia fija, aprendimos a usar una unidad PLL personalizada. Es cierto que las constantes detectadas están destinadas a una frecuencia de 100 MHz, pero todos pueden ajustarlas a cualquier otra frecuencia ya sea utilizando cálculos bien conocidos o por prueba y error. También fortalecimos las habilidades de crear un sistema de procesador óptimo y nos aseguramos de que la memoria a una frecuencia más alta funcione de manera estable, y la frecuencia realmente aumentó.
En general, ya podemos producir cualquier cosa informática, incluso podemos intercambiar con el procesador central, pero el procesador central del complejo se encargará de los cálculos triviales de manera más eficiente. FPGA se agrega a Redd para implementar cualquier interfaz de alta velocidad o capturar (bien o reproducir) flujos de información. Ya hemos dominado los conceptos básicos del diseño, hemos aprendido a proporcionar un rendimiento más o menos alto. Es hora de seguir trabajando con interfaces, que es lo que haremos en el próximo artículo. Más precisamente, un conjunto de artículos, conscientes de la regla "un artículo, una cosa".