Cuando los clústeres alcanzan cientos, y a veces miles, de máquinas, surge la pregunta de la consistencia de los estados del servidor entre sí. El algoritmo de consenso distribuido en balsa proporciona la garantía de consistencia más estricta posible. En este artículo, consideraremos a Raft desde el punto de vista de un ingeniero e intentaremos responder las preguntas "¿Cómo?" y "¿por qué?" El esta trabajando.

Autor del artículo: Dmitry Pavlushin (desarrollador Dodo Pizza Engineering).
Raft es
un algoritmo de consenso distribuido que se necesita para que varios participantes puedan decidir conjuntamente si un evento ocurrió o no, y qué siguió.
Los datos servidos por el clúster Raft son un registro que consta de registros. Cuando un usuario desea cambiar los datos almacenados en un clúster, intenta agregar un nuevo registro al registro con el comando:
Estos comandos son ejecutados por máquinas de estado distribuidas. Por simplicidad y claridad, en el marco de este artículo, asumiremos que estos registros simplemente se dan cuando se leen a un cliente que, en base a los eventos que han tenido lugar, restaura el estado actual del sistema
(ver Fuente de eventos) .
Para garantizar el consenso en Raft, primero se selecciona un líder, sobre el cual será responsable de administrar el registro distribuido. El líder acepta solicitudes de clientes y las replica en otros servidores del clúster. Si el líder falla, se seleccionará un nuevo líder en el clúster. Esto es si por un rato en tres oraciones. Los detalles seguirán.
Conceptos basicos
- Estados del servidor En el clúster Raft, cada servidor en un momento dado se encuentra en uno de tres estados:
- Líder (líder): procesa todas las solicitudes de los clientes, es la fuente de la verdad de todos los datos en el registro, admite el registro de seguidores.
- Follower (seguidor) es un servidor pasivo que solo "escucha" las nuevas entradas de registro del líder y redirige todas las solicitudes entrantes de los clientes al líder. De hecho, es una réplica en espera del líder.
- Candidato (candidato) es un estado especial del servidor, posible solo durante la selección de un nuevo líder.
Durante el funcionamiento normal en un clúster, solo un servidor es el líder, el resto son sus seguidores.
Sobre el asincronismoVale la pena señalar aquí que la condición es un concepto relativo. Debido al hecho de que los servidores se comunican de forma asíncrona, diferentes servidores pueden observar las transiciones de otros servidores de un estado a otro en diferentes momentos.
- Balsa divide el tiempo en segmentos de longitud arbitraria, llamados plazos . Cada término tiene un número monotónicamente creciente. El término comienza con la elección de un líder cuando uno o más servidores se convierten en candidatos. Si el candidato recibe la mayoría de los votos, se convierte en líder hasta el final de este período. Si los votos se dividen y ninguno de los candidatos puede obtener la mayoría de los votos, se activa un tiempo de espera y este período finaliza. Después de eso, comienza un nuevo período con nuevos candidatos y elecciones. Esta situación se llama voto dividido. Un ejemplo se ilustra con el término número tres en el siguiente diagrama:

El término número sirve como una marca de tiempo lógica en el clúster Raft. Ayuda a los servidores a determinar qué información es más relevante en este momento.
Reglas y términos de interacción del servidor- Cada servidor rastrea el número de su término actual.
- El servidor incluye su número de vencimiento en cada mensaje enviado.
- Si el servidor recibe un mensaje con un número de término menor que el suyo, ignora este mensaje.
- Si el servidor recibe un mensaje con un número de fecha límite más largo que el suyo, entonces actualiza su número de fecha límite para que coincida con el recibido.
- Si un candidato o líder recibe un mensaje con un número de fecha límite más largo que el suyo, entonces comprende que otros servidores ya han iniciado una nueva fecha límite, y su fecha límite ya no es relevante. Por lo tanto, pasa del estado actual al estado "seguidor" además de actualizar su número.
- Comunicación del servidor. Los servidores en Raft interactúan intercambiando solicitudes y respuestas. El algoritmo básico usa solo dos tipos de llamadas:
- RequestVote es utilizado por los candidatos durante las elecciones. La solicitud contiene el número de término y los metadatos del candidato sobre el registro del candidato, que se analizan con más detalle a continuación. La respuesta contiene el número de fecha límite del servidor que responde y el valor "verdadero" si el servidor vota por el candidato; Falso si el servidor vota en contra del candidato.
- AppendEntries es utilizado por el líder para la replicación de registros, así como para el mecanismo de latido. La solicitud contiene el número de término del líder, una colección de entradas que deben agregarse al registro (o una colección vacía en el caso de latidos), algunos metadatos sobre el registro del líder, que también se analizan con más detalle a continuación. La respuesta contiene el número de término del seguidor y el valor "verdadero" si el seguidor agregó entradas exitosamente a su registro; "Falso" si falla la adición de entradas de registro.
Algoritmo de trabajo
1. Elige un líder
Para determinar cuándo es el momento de comenzar una nueva elección, Raft se basa en los latidos del corazón. El seguidor sigue siendo el seguidor hasta que recibe mensajes del líder o candidato actual. El líder envía periódicamente latidos a todos los demás servidores.
Si el seguidor no recibe ningún mensaje por algún tiempo, naturalmente asumirá que el líder está muerto, lo que significa que es hora de tomar la iniciativa en sus manos. En este punto, el antiguo seguidor inicia la elección.
Para iniciar la elección, el seguidor incrementa su número de mandato, cambia al estado "candidato", vota por sí mismo y luego envía la solicitud "RequestVote" a todos los demás servidores. Después de eso, el candidato espera uno de los tres eventos:
- El candidato recibe la mayoría de los votos (incluido el suyo) y gana las elecciones. Cada servidor vota solo una vez en cada período, para que se llegue al primer candidato (con algunas excepciones, discutidas a continuación), por lo tanto, solo un candidato puede obtener la mayoría de los votos en un término específico. El servidor ganador se convierte en el líder, comienza a enviar latidos y atender las solicitudes del cliente al clúster.
- El candidato recibe un mensaje del líder actual del término actual o de cualquier servidor con un término anterior . En este caso, el candidato entiende que las elecciones en las que se dirige ya no son relevantes. No tiene más remedio que reconocer un nuevo líder / nuevo término y entrar en un estado de seguidor.
- Un candidato no recibe la mayoría de los votos por un tiempo de espera determinado. Esto puede suceder cuando varios seguidores se convierten en candidatos, y los votos se dividen entre ellos para que ninguno obtenga la mayoría. En este caso, el período termina sin un líder, y el candidato comienza inmediatamente nuevas elecciones para el próximo período.
2. Repetimos registros
Cuando se selecciona un líder, él es responsable de administrar el registro distribuido. El líder acepta solicitudes de clientes que contienen algunos equipos. El líder coloca en su registro un nuevo registro que contiene el comando y luego envía "AppendEntries" a todos los seguidores para replicar el registro con el nuevo registro.
Cuando el registro se replica con éxito en la mayoría de los servidores, el líder comienza a considerar el registro cerrado y responde al cliente. El líder realiza un seguimiento de qué registro es el último. Envía el número de este registro a AppendEntries (incluidos los latidos) para que los seguidores puedan confirmar el registro para ellos mismos.
En caso de que el líder no pueda alcanzar a algunos seguidores, volverá sobre las entradas de Append al infinito. La siguiente imagen muestra cómo se organizan los registros en el clúster Raft:

Cada cuadro es una entrada en el registro. Cada registro almacena un comando, por ejemplo, x ← 3 asigna el valor 3 a la tecla x. El registro también almacena el número del término en el que se generó. En la imagen, esto se indica mediante un número en la parte superior del cuadrado. La visualización en color de los cuadrados también significa el término número. Cada registro tiene un número de serie (índice de registro).
3. Garantizamos la fiabilidad del algoritmo.
Hasta ahora, de lo que hemos examinado, no está claro cómo Raft puede dar al menos algunas garantías. Sin embargo, el algoritmo proporciona un conjunto de propiedades que juntas garantizan la fiabilidad de su ejecución:
- Seguridad electoral : no se puede seleccionar más de un líder en un solo período. Esta propiedad se desprende del hecho de que cada servidor vota dentro de cada término solo una vez, y para la formación de un líder, se requiere una mayoría de votos
- Líder Anexar-Solo : el líder nunca sobrescribe o borra, no mueve entradas en su registro, solo agrega nuevas entradas. Esta propiedad se deduce directamente de la descripción del algoritmo: la única operación que un líder puede realizar con su registro es agregar entradas al final. Y eso es todo.
- Coincidencia de registros: si los registros de dos servidores contienen una entrada con el mismo índice y número de caducidad, ambos registros son idénticos e incluyen este registro.
Prueba usando inducción matemática e imágenesLa inducción matemática es una forma de probar cuando el primer paso es probar una declaración para un caso simple. En el segundo paso, aceptamos la afirmación verdadera para algún caso X. En base a esto, tratamos de probar la afirmación para algún caso vecino X + 1. Juntos, estos dos pasos ayudan a probar la declaración para todos los casos.
En nuestra situación, un caso simple es registros vacíos. No hay registros, por lo tanto, no hay nada que viole la propiedad.
Ahora intentemos asumir que hay algunas entradas en los registros que corresponden a nuestra propiedad. Raft tiene un mecanismo que evita que la propiedad se rompa cuando cambia un registro. Este mecanismo se llama
comprobación de consistencia . Veamos los ejemplos de inmediato.
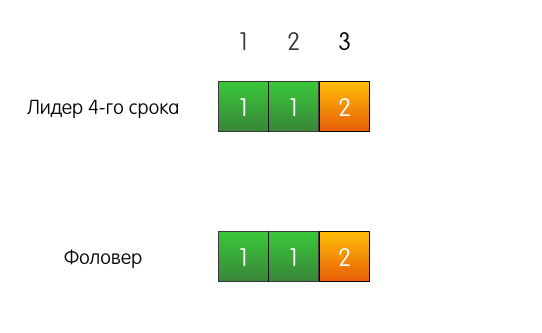
Buen ejemplo Hay un líder, por ejemplo, del cuarto término, hay un seguidor. Ambos tienen registros coincidentes de tres entradas.
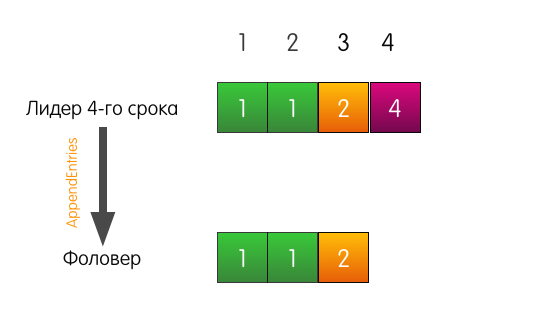
Una solicitud del cliente llega al líder, él agrega una entrada a su registro.

El líder envía AppendEntries al seguidor. Pero, además del registro más agregado, el líder también indica en la solicitud que el registro debe agregarse en el índice 4, y en el índice 3, frente a él, debe haber un registro del término 2.
La entrada de registro en el índice 3 en el registro de seguidor coincide con la especificada en la solicitud, por lo que el seguidor agrega la entrada a su registro y responde con éxito al líder. El final
 También es un buen ejemplo, pero con un comienzo trágico.
También es un buen ejemplo, pero con un comienzo trágico. Ahora el registro del seguidor es diferente del registro del líder actual.

Cuando el líder recibe una solicitud para agregar una entrada al registro, enviará los mismos AppendEntries que en el ejemplo anterior.

Sin embargo, esta vez, dado que el seguidor no coincide con el registro anterior, el seguidor falla.
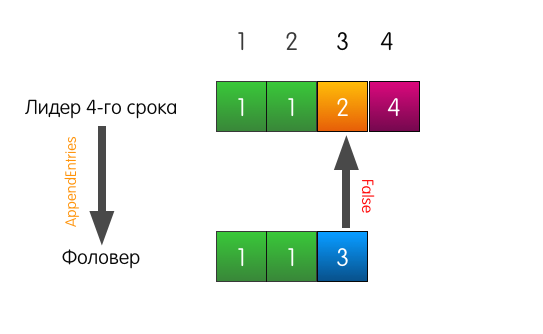
¿Qué hace el líder en este caso? El líder simplemente retrocede un poco e intenta alimentar al seguidor con el registro que él mismo considera estar en el índice 3. También incluye el registro anterior en la solicitud.
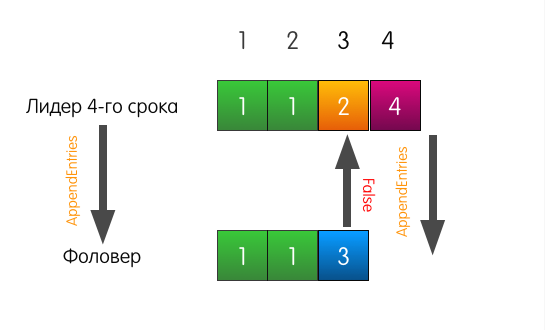
Ahora el seguidor responde con éxito y sobrescribe las entradas en su registro, comenzando desde el índice 3.
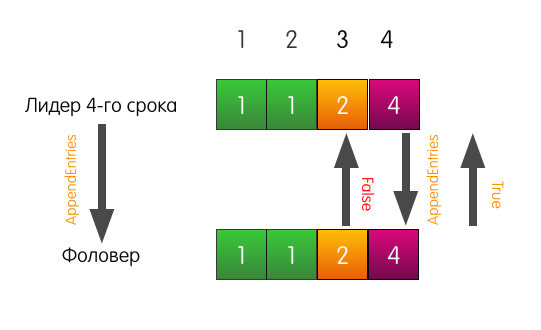
El registro del seguidor puede diferir del registro del líder según lo desee. Puede que no haya suficientes entradas, puede haber entradas adicionales. En cualquier caso, la verificación de consistencia asegura que los registros de seguidores tarde o temprano coincidirán con el registro del líder.
- Integridad del líder : si la entrada del registro se confirma en un momento dado, los registros de los líderes de todos los períodos posteriores incluirán este registro. Esta propiedad nos brinda garantías de durabilidad.
Prueba y fotosConsidere la siguiente situación: tres servidores en un clúster. El servidor S1 es el líder del primer término actual. Todos los servidores tienen tres entradas de registro.

El líder S1 recibe una solicitud del cliente y agrega un nuevo registro a su registro, envía AppendEntries a otros servidores S2 y S3.
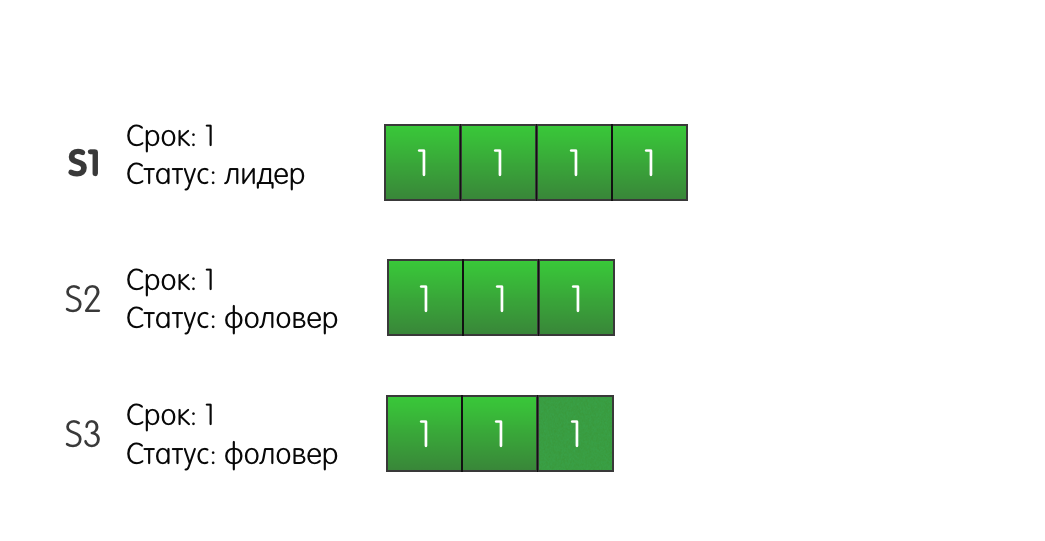
El registro llega con éxito a S2, pero la red entre S1 y S3 parpadea y se pierde la solicitud. Como S1 sabe que el registro está presente en dos de los tres servidores, puede determinar que el registro está confirmado y responder con éxito al cliente.
S1 también volverá a intentar agregar una entrada a S3 hasta que tenga éxito. Pero, ¿qué sucede si S1 falla y se apaga? Además, ¿qué sucederá si S3 es el primero en cansarse de esperar y se convierte en candidato? S2 votará a favor, S3 se convertirá en el líder del segundo mandato y, en la próxima solicitud para agregar un registro, ¿S3 sobrescribirá nuestro registro grabado?
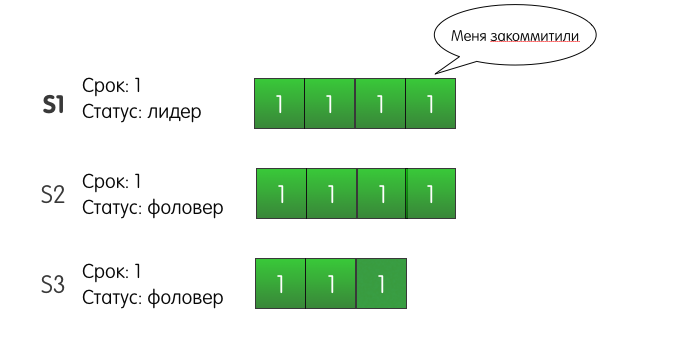
De hecho, esta situación no puede suceder en el grupo Raft. El problema aquí es que S2 no votaría por S3. Por qué Porque el registro del servidor S3 en el momento de la votación es menos relevante que el registro del servidor S2. Este mecanismo se llama
restricción de elección : el servidor votará por otro servidor solo si el registro del candidato no es menos relevante que el registro del votante.
Raft compara la relevancia de los registros de dos maneras:
- Último número de fecha de registro
- Longitud del registro
Los candidatos incluyen estos dos parámetros en la solicitud RequestVote para que los seguidores puedan comparar la relevancia de su registro con el registro del candidato.
"Lo más importante" es el registro en el que el último registro es más antiguo.

Si los números del término de las últimas entradas coinciden, entonces el "principal" es el registro que es más largo.

Si ambos coinciden, los registros son igualmente relevantes y, como se desprende de la propiedad anterior, son absolutamente idénticos.
Resulta que el registro del servidor en el que hay un registro seguro siempre será más relevante que el registro en el que no lo está. Y un servidor que tiene un registro seguro no votará por un servidor que no lo tenga. Y dado que hay un registro registrado en la mayoría de los servidores, un candidato sin este registro no podrá obtener la mayoría de los votos y convertirse en un líder para eliminar este registro de otros servidores.
- State Machine Safety : esta propiedad se describe en el original en términos de máquinas de estado distribuidas, en términos de nuestro artículo, esta propiedad se puede describir de la siguiente manera: cuando un servidor confirma un registro con cierto índice, ningún otro servidor confirma otro registro para este índice.
Esta propiedad se sigue del pasado. Si el seguidor confirma algún registro en el índice N, entonces su registro es idéntico al registro del líder hasta e incluyendo N. La propiedad de integridad de Líder garantiza que todos los líderes posteriores también contendrán este registro asegurado en el índice N, lo que significa que los seguidores que cometan un registro en el índice N en períodos posteriores cometerán el mismo valor.
Enlaces a materiales para estudios posteriores