Dado que las unidades de estado sólido basadas en flash se están convirtiendo en el principal medio de almacenamiento permanente de información en los centros de datos, es importante darse cuenta de cuán confiables son. Hasta la fecha, se han llevado a cabo una gran cantidad de estudios de laboratorio de chips de memoria flash utilizando pruebas sintéticas, pero no hay suficiente información sobre su comportamiento en el campo. Este artículo está dedicado a los resultados de un estudio de campo a gran escala que abarca millones de días de uso de discos duros, 10 modelos diferentes de unidades de estado sólido, varias tecnologías de memoria flash (MLC, eMLC, SLC) y más de 6 años de uso operativo en centros de datos de Google.
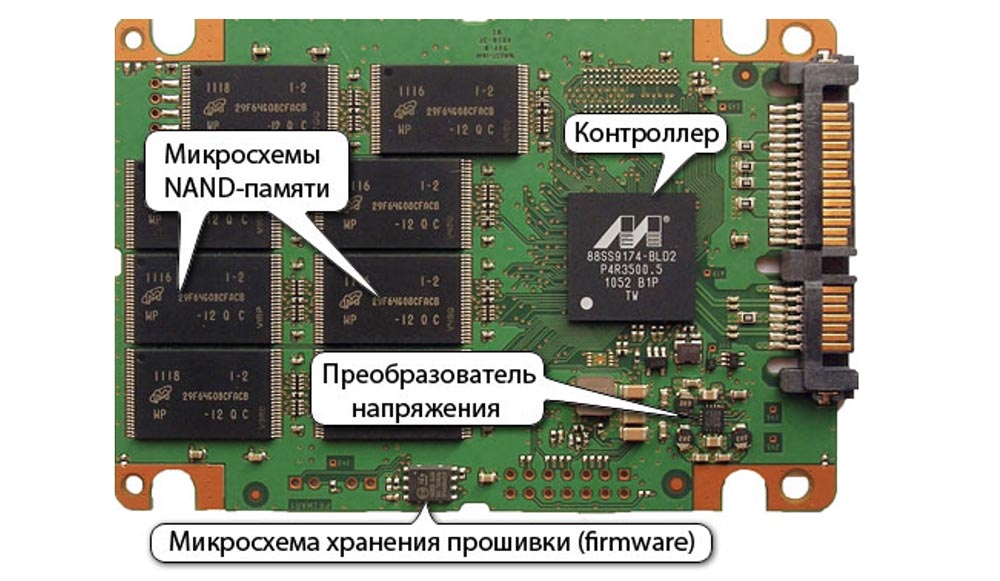
Examinamos una amplia gama de características de confiabilidad de estos dispositivos y llegamos a una serie de conclusiones inesperadas. Por ejemplo, cuando la unidad se desgasta, la tasa de error de bit (RBER) aumenta a una tasa mucho más lenta de lo que sugiere el indicador exponencial y, lo que es más importante, no permite predecir la ocurrencia de errores no corregibles u otros tipos de errores.
La métrica UBER (tasa de error de bit irrecuperable) ampliamente utilizada no es un indicador significativo de confiabilidad, ya que no vimos la relación entre el número de lecturas y el número de errores no corregibles. Tampoco encontramos evidencia de que durante la vida normal de un SSD, las unidades basadas en la arquitectura SLC de un solo nivel sean más confiables que las unidades MLC. En comparación con los discos duros tradicionales, la frecuencia de reemplazo de SSD basados en flash es mucho menor, pero tienen un mayor nivel de corrección de errores.
1. Introducción
La popularidad del uso de unidades flash de estado sólido basadas en tecnología NAND en centros de datos está en constante crecimiento. Cuantos más datos se puedan colocar en dicho disco, mayor será la seguridad y la disponibilidad de información dependiendo de la confiabilidad de la unidad flash. Aunque las ventajas de rendimiento de las SSD en comparación con las HDD son bien conocidas, las características de falla de las unidades flash no se comprenden bien.
Los datos proporcionados por los fabricantes de memoria flash contienen solo vagas garantías, como la cantidad de ciclos de borrado hasta que el dispositivo se haya desgastado por completo. Una comprensión típica del problema se basa en estudios que estudian la confiabilidad de las unidades flash mediante la realización de experimentos de laboratorio controlados (por ejemplo, pruebas de durabilidad aceleradas). Al mismo tiempo, se utiliza una pequeña cantidad de dispositivos seleccionados al azar para probar los efectos de las cargas de trabajo sintéticas. Hay una falta de investigación que establezca un vínculo entre los resultados de las pruebas de laboratorio y las características de confiabilidad de las unidades flash que funcionan en condiciones reales.
Este artículo proporciona resultados detallados de un estudio de campo de la confiabilidad de las unidades flash, basado en los datos recopilados durante 6 años de su funcionamiento en los centros de datos de Google. Estos datos cubren millones de días de funcionamiento del disco (el número exacto de discos y dispositivos que los usan es confidencial por parte de Google, por lo que no podemos proporcionar números exactos. Sin embargo, pudimos verificar la importancia estadística de los datos que nos proporcionaron), diez modelos diferentes de unidades flash, varios flash -tecnologías (MLC, eMLC y SLC) con tecnología de chip de 24 a 50 nm.
Utilizamos estos datos para proporcionar una mejor comprensión de la fiabilidad operativa de la memoria flash. En particular, analizamos tales aspectos de la confiabilidad del dispositivo:
- Varios tipos de errores que ocurren en la memoria flash y la frecuencia de su ocurrencia en el campo (sección 3).
- Tasa de error de bit (RBER), la influencia de factores como el desgaste, la antigüedad del disco y la carga de trabajo, así como la relación de RBER con otros tipos de errores (sección 4).
- Errores irrecuperables, su frecuencia y la influencia de varios factores en ellos (sección 5).
- Características de campo de varios tipos de fallas de equipos, incluidas fallas complejas, fallas de chips y la frecuencia de reparación y reemplazo de unidades (sección 6).
- 5. Comparación de confiabilidad de varias tecnologías flash (discos MLC, eMLC, SLC) (sección 7) y comparación de confiabilidad SSD y HDD (sección 8).
Nos aseguramos de que nuestro análisis revela varios aspectos de la fiabilidad de la memoria flash en el campo, que difieren de las conclusiones hechas en trabajos anteriores. Esperamos que nuestro trabajo sirva como incentivo para futuras investigaciones en esta área.
 Tab. 1. Características de los módulos que participaron en las pruebas de campo.
Tab. 1. Características de los módulos que participaron en las pruebas de campo.2. Información básica sobre datos y sistemas.
2.1. Unidades flash
Nuestra investigación incluyó unidades SSD seriales de alto rendimiento basadas en chips flash industriales, pero utilizamos una interfaz PCIe personalizada, firmware personalizado y un controlador. Nos centramos en 2 generaciones de unidades, donde todas las unidades de la misma generación usan el mismo controlador de dispositivo y el mismo firmware. Esto significa que también usan los mismos códigos de corrección de errores (ECC) para detectar y reparar bits dañados y los mismos algoritmos para determinar el grado de desgaste. La principal diferencia entre los modelos de unidades de la misma generación es el tipo de chip de memoria utilizado.
Nuestro estudio se centró en 10 modelos de unidades, cuyas características principales se muestran en la Tabla 1. Seleccionamos modelos de cuatro fabricantes, cada uno de los cuales trabajó durante varios millones de días, utilizando los tres tipos más comunes de memoria flash (MLC, SLC, eMLC).
2.2. Datos utilizados
Utilizamos datos del monitoreo diario de la operación de unidades flash en el campo durante un período de operación de 6 años. Además, se contaron varios tipos de errores diariamente, se compilaron estadísticas sobre la carga de trabajo, incluida la cantidad de operaciones de escritura y borrado, y se calculó la cantidad de bloques defectuosos que ocurrieron durante el día. El número de operaciones de lectura, escritura y borrado incluyó tanto el número de operaciones del usuario como el número de operaciones internas de "recolección de basura". También se utilizaron grabaciones que registraron casos de fallas en el chip, así como casos de reparación o reemplazo de SSD.
3. La prevalencia de varios tipos de errores.
Comencemos con algunas estadísticas básicas sobre la frecuencia de ocurrencia de varios tipos de errores en el campo. Destacamos los errores transparentes que son invisibles para el usuario y los errores opacos que conducen al fracaso de las operaciones del usuario. El controlador de la unidad flash informa los siguientes tipos de errores transparentes:
Error corregible: durante una operación de lectura, el error detectado se corrige mediante la función de corrección de errores ECC incorporada.
- Error de lectura Error de lectura: un error que ocurre durante el proceso de lectura (para la memoria sin corrección de error no ECC), corregido tras la lectura repetida;
- Error de escritura Error de escritura: operación de escritura de error que tiene éxito después de volver a intentarlo.
- Error de borrado Error de borrado: la operación de borrado en el bloque falla.
Los dispositivos también informan los siguientes tipos de errores opacos:
- Error no corregible: durante la operación, se producen más bits dañados de los que puede reparar ECC.
- Error de lectura final Error de lectura final: un error que ocurrió mientras la lectura no se corrige tras intentos repetidos;
- Error de escritura final Error de escritura final: un error que ocurrió mientras se escribía no se corrige tras intentos repetidos;
- Meta-error Meta-error: error al acceder a los metadatos internos del disco.
- Error de tiempo de espera: la operación se cancela después de 3 segundos.
Los errores fatales incluyen los errores que se detectaron durante las operaciones iniciadas por el usuario o las operaciones internas de recolección de basura, mientras que los errores de lectura final incluyen los errores que ocurrieron durante las operaciones del usuario.
Tenga en cuenta que los errores varían en severidad del impacto. Además de la diferencia entre errores transparentes y opacos, la severidad de los errores opacos en sí mismos cambia. En particular, algunos de estos errores (error de lectura final, error fatal, meta error) conducen a la pérdida de datos si el sistema no tiene redundancia en niveles superiores, porque el disco no puede proporcionar al usuario datos que hayan sido aceptados para el almacenamiento.
Solo consideramos los discos que se pusieron en producción hace al menos 4 años (los discos eMLC se lanzaron hace 3 años, ya que este es un tipo más nuevo de unidades flash), y los errores que ocurrieron durante los primeros 4 años de funcionamiento. La Tabla 2 muestra el porcentaje de unidades de cada modelo que están sujetas a diferentes tipos de errores si estos errores ocurrieron al menos 1 vez (mitad superior de la tabla), y el porcentaje de días de operación durante los cuales las unidades estuvieron sujetas a errores de cierto tipo (mitad inferior de la tabla).
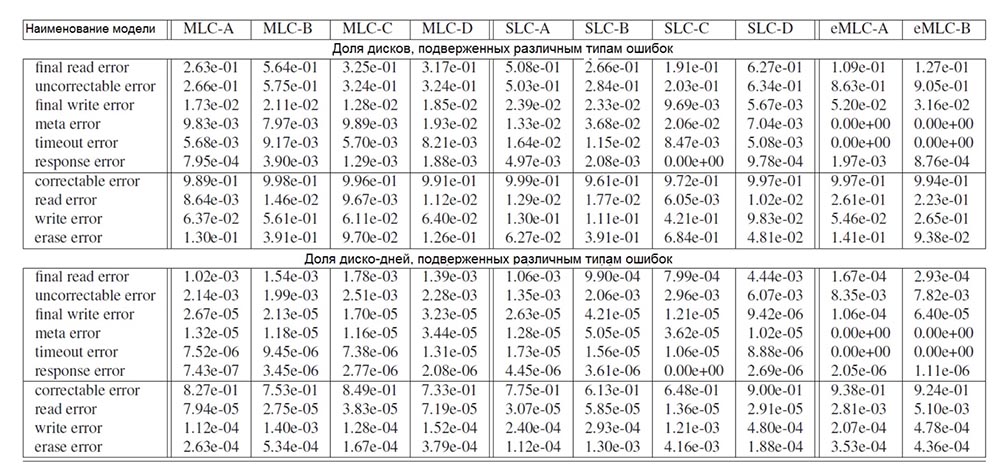 Tab. 2. La prevalencia de varios tipos de errores. La mitad superior de la tabla muestra el porcentaje de discos afectados por errores, y la mitad inferior muestra el porcentaje de días de uso del disco durante los cuales ocurrieron varios tipos de errores.
Tab. 2. La prevalencia de varios tipos de errores. La mitad superior de la tabla muestra el porcentaje de discos afectados por errores, y la mitad inferior muestra el porcentaje de días de uso del disco durante los cuales ocurrieron varios tipos de errores.3.1. Errores opacos
Creemos que los errores opacos más comunes son los errores de lectura final, es decir, errores que no pueden corregirse mediante una operación de lectura repetida. Dependiendo del modelo de la unidad, al menos 20-63% de los dispositivos tienen dicho error dentro de 2-6 días de 1000 días de operación del disco.
Llegamos a la conclusión de que el número de errores de lectura final está altamente correlacionado con el número de errores no corregibles y que estos errores de lectura final se producen únicamente porque el daño de bits no se puede reparar con ECC. Para todos los modelos de unidades, los errores de lectura final ocurren 2 órdenes de magnitud más a menudo (si se enfoca en la cantidad de días que se usaron las unidades cuando ocurrieron estos errores) que cualquier otro tipo de errores opacos.
A diferencia de los errores de lectura, los errores de escritura rara vez se convierten en errores opacos. Dependiendo del modelo, solo 1.5-2.5% de los discos experimentaron un error de escritura final dentro de 1-4 días de 10,000 días de operación, es decir. operación de escritura fallida que no se corrigió después de repetidos intentos. Esta diferencia en la frecuencia de los errores finales de lectura y escritura probablemente se deba al hecho de que la operación de escritura fallida simplemente se corrigió escribiendo en otro lugar del disco en el área con los bits intactos. Por lo tanto, si la falla de la operación de lectura solo puede ser causada por la presencia de varios bits dañados, el error de escritura final indica un problema de hardware mayor.
Los meta errores ocurren a una frecuencia comparable a la tasa de errores de escritura, pero nuevamente con mucha menos frecuencia que los errores de lectura finales. Esto no es sorprendente, dado que el disco contiene mucho menos metadatos que la cantidad de datos reales, lo que reduce la frecuencia de acceso a los metadatos. Otros errores opacos (errores de tiempo de espera y errores de respuesta) son bastante raros y, como regla, afectan menos del 1% de los discos durante 1 día de cada 100,000 días de funcionamiento del disco.
3.2. Errores transparentes
No es sorprendente que las correcciones de errores sean el tipo más común de error transparente. Casi todas las unidades tienen al menos algunos errores corregibles que ocurren durante la mayoría de los días de funcionamiento del disco (61-90%). Los errores que pueden corregirse con más detalle, incluido el análisis de tasa de error de bit (RBER), se analizan en la Sección 4 de este artículo.
Los siguientes tipos de errores transparentes más comunes son los errores de escritura y borrado. Por lo general, ocurren en el 6-10% de las unidades, pero para algunos modelos los SSD alcanzan hasta el 40-68%. En la mayoría de los casos, tales errores ocurren en menos de 5 días de cada 10,000 días de operación. Según nuestra investigación, los errores de escritura y borrado indican daños en la unidad, este problema se trata en detalle en la sección 6.
Los errores que ocurren durante las operaciones de lectura son menos comunes que los errores transparentes, probablemente porque, aparte de corregir errores sobre la marcha utilizando ECC, este problema no se soluciona mediante operaciones repetidas. Los errores de lectura incompletos, es decir, los errores de lectura que pueden corregirse mediante intentos repetidos, ocurren en menos del 2% de las unidades y duran menos de 2 a 8 días de cada 100,000 días de funcionamiento del disco.
Como resultado, además de los errores corregibles que ocurren en una gran cantidad de días de operación del disco, los errores transparentes ocurren con menos frecuencia en comparación con todos los tipos de errores opacos. El tipo más común de errores opacos son los errores no corregibles que ocurren durante 2-6 días de 1000 días de funcionamiento del disco.
4. Tasa de error de bit (RBER)
La métrica estándar para evaluar la confiabilidad de las unidades flash es la tasa de error de bit (RBER) del disco, que se define como la relación entre la cantidad de bits dañados y la cantidad de bits leídos (incluidos los casos de errores corregibles y no corregibles).
La segunda generación de unidades (modelos eMLC-A y eMLC-B) proporciona el número exacto de bits dañados y bits de lectura, lo que nos permite determinar el RBER con alta precisión.
La primera generación de unidades informa el número exacto de bits leídos, pero para cada página que consta de 16 bloques de datos, se proporciona un informe sobre el número de bits dañados del bloque de datos que tuvo el mayor número de bits dañados. Como resultado de esto, en el peor de los casos estadísticos, cuando todos los bloques contienen errores y el número de estos errores es el mismo, el coeficiente RBER puede ser 16 veces mayor que el coeficiente obtenido en base al informe de estado del disco.
Este problema no importa mucho mientras se realiza la comparación entre unidades de la misma generación, pero debe tenerse en cuenta al comparar unidades de diferentes generaciones.
 Tab. 3. Tasa de error de bit agregado RBER para varios modelos SSD.
Tab. 3. Tasa de error de bit agregado RBER para varios modelos SSD.4.1. Revisión de alto nivel de RBER
La Tabla 3 muestra el valor medio de RBER para cada modelo de unidad para todas las unidades de este modelo, así como los percentiles 95 y 99. Decidimos trabajar con medianas y percentiles, porque encontramos que los indicadores promediados están muy sesgados debido a varios valores claramente diferenciados, lo que dificulta la identificación de tendencias.
Observamos grandes diferencias en RBER para diferentes modelos de unidades, que van desde 5.8e-10 a más de 3e-08 para unidades de primera generación. Estas diferencias son aún mayores cuando se considera no el valor medio de RBER, sino el percentil 95 o 99. Por ejemplo, el percentil 99 RBER varía de 2.2e-08 para el modelo SLC-B a 2.7e-05 para el modelo MLC-D. Existen grandes diferencias incluso dentro de la línea de transmisión del mismo modelo: la unidad RBER en el percentil 99 tiende a ser al menos un orden de magnitud mayor que la unidad RBER mediana del mismo modelo.
La diferencia de RBER entre los modelos puede explicarse parcialmente por las diferencias en la tecnología flash subyacente. El valor RBER para los modelos MLC es más alto que para los modelos SLC, por lo que el precio más alto de los modelos SLC tiene en cuenta el valor RBER más bajo. En la sección 5 de este artículo, veremos cómo estas diferencias se traducen en diferencias en errores opacos que son visibles para el usuario.
Los modelos EMLC informan RBER, que es varios órdenes de magnitud más alto que el de otros modelos de unidades. Incluso teniendo en cuenta que las unidades RBER de primera generación pueden ser 16 veces más altas en el peor de los casos, la diferencia existente en los valores de los coeficientes es un orden de magnitud mayor. Suponemos que hay un factor de tamaño, ya que los dos modelos eMLC tienen chips con la litografía microelectrónica más baja en comparación con todos los demás modelos de unidades.
Finalmente, no hay fabricantes cuyos productos tengan ventajas sobre los productos de otros fabricantes. Dentro del grupo de discos SLC y eMLC, el mismo proveedor produce uno de los peores y uno de los mejores modelos del grupo.
En general, el RBER varía mucho entre los modelos de disco, así como entre los SDD del mismo modelo. Esto nos motiva a seguir estudiando los factores que influyen en la RBER.
4.2. Qué factores influyen en el valor RBER
En esta sección, examinaremos el efecto en RBER de varios factores:
- desgaste causado por ciclos de Programa / Borrado (PE);
- edad física, es decir, la cantidad de meses durante los cuales el dispositivo fue operado en el campo, independientemente de los ciclos de EP;
- carga de trabajo, medida por la cantidad de operaciones de lectura, escritura y borrado, así como la cantidad de operaciones en la página que podrían dañar las celdas de memoria circundantes;
- La presencia de otros tipos de errores.
Estudiamos el efecto de cada factor en RBER de dos maneras diferentes. Utilizamos datos visuales visuales trazando la influencia de factores en RBER e investigamos indicadores cuantitativos de influencia usando el coeficiente de correlación. Utilizamos el coeficiente de correlación de rango de Spearman, ya que puede cubrir relaciones monotónicas no lineales en métodos no paramétricos, en contraste con, por ejemplo, el coeficiente de correlación de Pearson.
Antes de analizar los factores individuales en detalle, compilamos un gráfico de resumen, como se muestra en la Figura 1.
 Fig. 1. La dependencia del coeficiente de correlación de rango de Spearman entre el valor RBER durante el mes de operación del disco y otros factores.
Fig. 1. La dependencia del coeficiente de correlación de rango de Spearman entre el valor RBER durante el mes de operación del disco y otros factores.Esto muestra la relación entre el coeficiente de correlación de rango de Spearman entre el valor RBER durante el mes de funcionamiento de los discos y factores tales como el número de ciclos PE anteriores, el número de lecturas, escrituras o borrados este mes, el valor RBER en el mes anterior y el número de errores no corregibles (UE) en mes anterior El coeficiente de correlación de rango de Spearman puede variar de -1 (correlación negativa fuerte) a +1 (correlación positiva fuerte).
Cada grupo de etiquetas muestra los coeficientes de correlación entre RBER y un factor particular (ver interpretación en el eje X), y las diferentes etiquetas en cada grupo corresponden a diferentes modelos de accionamiento. Todos los coeficientes de correlación merecen más del 95% de confianza.
Nos aseguramos de que todos los factores, excepto la aparición de errores fatales en el mes anterior, muestren una relación clara con RBER, al menos para algunos modelos. También llamamos la atención sobre el hecho de que algunas de estas dependencias pueden ser falsas, ya que algunos factores pueden correlacionarse entre sí, por lo que examinamos cada factor con más detalle en la siguiente subsección.
4.2.1 RBER y desgaste
Dado que la resistencia de la celda de memoria flash es limitada, el coeficiente RBER aumenta al aumentar los ciclos de Programa / Borrado (PE). Los altos coeficientes de correlación entre los ciclos RBER y PE en la Figura 2 prueban su relación.
 Fig. 2. La dependencia de la mediana y el 95 por ciento de RBER en la cantidad de ciclos de EP.
Fig. 2. La dependencia de la mediana y el 95 por ciento de RBER en la cantidad de ciclos de EP.2 95- RBER . , PE, 95- RBER .
, , RBER PE , 95- RBER. , , . : , , .
, RBER , , RBER PE. , MLC RBER PE, , PE (3,000 MLC), 4- RBER.
, , RBER , (., , MLC-D PE = 3000). , RBER 3- PE, , , PE.
…
, . ? ?
Apóyenos haciendo un pedido o recomendándolo a sus amigos, un
descuento del 30% para los usuarios de Habr en un análogo único de servidores de nivel de entrada que inventamos para usted: toda la verdad sobre VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps de $ 20 o cómo dividir el servidor? ( RAID1 RAID10, 24 40GB DDR4).
Dell R730xd 2 ? 2 Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 $199 ! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — $99! . c Dell R730xd 5-2650 v4 9000 ?