Hola Habr
Este artículo estará en un formato un poco "viernes", hoy trataremos con PNL. No es la PNL sobre los libros que se venden en pasos inferiores, sino la que procesa el lenguaje natural. Como ejemplo de dicho procesamiento, se utilizará la generación de texto usando una red neuronal. Podemos crear textos en cualquier idioma, desde ruso o inglés, hasta C ++. Los resultados son muy interesantes, probablemente puedas adivinar a partir de la imagen.

Para aquellos que estén interesados en lo que sucede, los resultados y el código fuente están por debajo.
Preparación de datos
Para el procesamiento, utilizaremos una clase especial de redes neuronales: las llamadas redes neuronales recurrentes (RNN). Esta red difiere de la habitual en que, además de las celdas habituales, tiene celdas de memoria. Esto nos permite analizar datos de una estructura más compleja y, de hecho, más cercana a la memoria humana, porque tampoco comenzamos cada pensamiento "desde cero". Para escribir código, usaremos redes
LSTM (memoria de corto plazo), ya que Keras ya las admite.
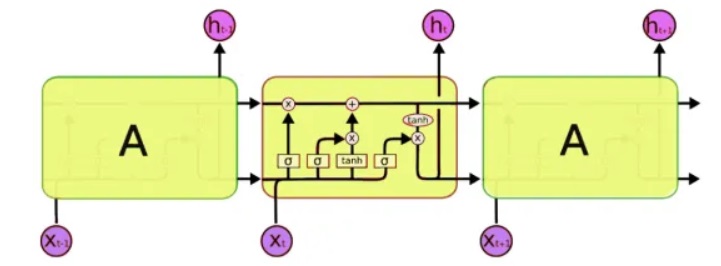
El siguiente problema que debe resolverse es, de hecho, trabajar con texto. Y aquí hay dos enfoques: enviar símbolos o palabras completas a la entrada. El principio del primer enfoque es simple: el texto se divide en bloques cortos, donde las "entradas" son un fragmento del texto y la "salida" es el siguiente carácter. Por ejemplo, para la última frase, 'las entradas son un fragmento de texto':
input: output: ""
input: : output: ""
input: : output:""
input: : output: ""
input: : output: "".
Y así sucesivamente. Por lo tanto, la red neuronal recibe fragmentos de texto en la entrada y en la salida los caracteres que debe formar.
El segundo enfoque es básicamente el mismo, solo se usan palabras enteras en lugar de palabras. Primero, se compila un diccionario de palabras y se ingresan números en lugar de palabras en la entrada de la red.
Esto, por supuesto, es una descripción bastante simplificada. Keras
ya tiene ejemplos de generación de texto, pero en primer lugar, no se describen con tanto detalle y, en segundo lugar, todos los tutoriales en inglés usan textos bastante abstractos como Shakespeare, que son difíciles de entender para el nativo. Bueno, estamos probando una red neuronal en nuestra gran y poderosa, que, por supuesto, será más clara y comprensible.
Entrenamiento de la red
Como texto de entrada, utilicé ... los comentarios de Habr, el tamaño del archivo fuente es de 1 MB (hay realmente más comentarios, por supuesto, pero tuve que usar solo una parte, de lo contrario la red estaría capacitada durante una semana y los lectores no verían este texto el viernes). Permítame recordarle que solo las letras se alimentan a la entrada de una red neuronal, la red "no sabe" nada sobre el idioma o su estructura. Vamos, comience el entrenamiento de la red.
5 minutos de entrenamiento:Hasta ahora, nada está claro, pero ya puedes ver algunas combinaciones reconocibles de letras:
. . . «
15 minutos de entrenamiento:El resultado ya es notablemente mejor:
« » — « » » —Por alguna razón, todos los textos resultaron sin puntos y sin letras mayúsculas, quizás el procesamiento utf-8 no se realizó correctamente. Pero en general, esto es impresionante. Al analizar y recordar solo códigos de símbolos, el programa realmente aprendió palabras rusas de forma "independiente" y puede generar un texto de aspecto bastante creíble.
No menos interesante es el hecho de que el programa memoriza bastante bien el estilo del texto. En el siguiente ejemplo, el texto de alguna ley se utilizó como ayuda para la enseñanza. Tiempo de entrenamiento en red 5 minutos.
"" , , , , , , , ,
Y aquí, las anotaciones médicas para medicamentos se usaron como un conjunto de entrada. Tiempo de entrenamiento en red 5 minutos.
, ,
Aquí vemos frases casi enteras. Esto se debe al hecho de que el texto original es corto y la red neuronal "memorizó" algunas frases en su conjunto. Este efecto se llama "reentrenamiento" y debe evitarse. Idealmente, debe probar una red neuronal en grandes conjuntos de datos, pero la capacitación en este caso puede llevar muchas horas, y desafortunadamente no tengo una supercomputadora adicional.
Un ejemplo divertido de usar una red de este tipo es la generación de nombres. Después de cargar una lista de nombres masculinos y femeninos en el archivo, obtuve nuevas opciones bastante interesantes que serían bastante adecuadas para una novela de ciencia ficción: Rlar, Laaa, Aria, Arera, Aelia, Ninran, Air. Algo en ellos siente el estilo de Efremov y la Nebulosa de Andrómeda ...
C ++
Lo interesante es que, en general, una red neuronal es como recordar. El siguiente paso fue verificar cómo el programa maneja el código fuente. Como prueba, tomé diferentes fuentes de C ++ y las combiné en un solo archivo de texto.
Honestamente, el resultado sorprendió aún más que en el caso del idioma ruso.
5 minutos de entrenamientoMaldición, es casi real C ++.
if ( snd_pcm_state_channels = 0 ) { errortext_ = "rtapialsa::probedeviceopen: esror stream_.buffer stream!"; errortext_ = errorstream_.str(); goto unlock; } if ( stream_.mode == input && stream_.mode == output || false; if ( stream_.state == stream_stopped ) { for ( unsigned int i=0; i<stream_.nuserbuffer[i] ) { for (j=0; j<info.channels; } } }
30 minutos de entrenamiento void maxirecorder::stopstream() { for (int i = 0; i < ainchannels; i++ ) { int input=(stream, null; conternallock( pthread_cond_wate);
Como puede ver, el programa ha "aprendido" a escribir funciones completas. Al mismo tiempo, separó completamente "humanamente" las funciones con un comentario con asteriscos, puso comentarios en el código y todo eso. Me gustaría aprender un nuevo lenguaje de programación con tanta velocidad ... Por supuesto, hay errores en el código y, por supuesto, no se compilará. Y, por cierto, no formateé el código, el programa también aprendió a poner paréntesis y sangría "yo mismo".
Por supuesto, estos programas no tienen el
significado principal y, por lo tanto, se ven surrealistas, como si estuvieran escritos en un sueño o no fueron escritos por una persona completamente sana. Sin embargo, los resultados son impresionantes. Y quizás un estudio más profundo de la generación de diferentes textos ayudará a comprender mejor algunas de las enfermedades mentales de pacientes reales. Por cierto, como se sugiere en los comentarios, existe una enfermedad mental en la que una persona habla en un texto gramaticalmente relacionado pero completamente sin sentido (
esquizofasia ).
Conclusión
Las redes neuronales recreativas se consideran muy prometedoras, y este es de hecho un gran paso adelante en comparación con las redes "ordinarias" como MLP, que no tienen memoria. De hecho, las capacidades de las redes neuronales para almacenar y procesar estructuras bastante complejas son impresionantes. Fue después de estas pruebas que pensé por primera vez que Ilon Mask probablemente tenía razón en algo cuando escribí que la IA en el futuro podría ser "el mayor riesgo para la humanidad", incluso si una simple red neuronal puede recordar y reproducirse fácilmente patrones bastante complejos, ¿qué puede hacer una red de miles de millones de componentes? Pero, por otro lado, no olvide que nuestra red neuronal no puede
pensar , esencialmente solo recuerda mecánicamente secuencias de caracteres, sin comprender su significado. Este es un punto importante: incluso si entrena una red neuronal en una supercomputadora y un gran conjunto de datos, en el mejor de los casos aprenderá a generar oraciones gramaticalmente 100% correctas, pero completamente sin sentido.
Pero no se eliminará en filosofía, el artículo es aún más para los profesionales. Para aquellos que quieran experimentar por su cuenta, el
código fuente en Python 3.7 está bajo el spoiler. Este código es una compilación de varios proyectos de github, y no es una muestra del mejor código, pero parece realizar su tarea.
El uso del programa no requiere habilidades de programación, es suficiente saber cómo instalar Python. Ejemplos de comenzar desde la línea de comando:
- Creación y formación de modelos y generación de texto:
python. \ keras_textgen.py --text = text_habr.txt --epochs = 10 --out_len = 4000
- Solo generación de texto sin entrenamiento modelo:
python. \ keras_textgen.py --text = text_habr.txt --epochs = 10 --out_len = 4000 --generate
Creo que resultó ser un generador de texto de trabajo muy original,
que es útil para escribir artículos sobre Habr . Particularmente interesante es probar en textos grandes y grandes cantidades de iteraciones de entrenamiento, si alguien tiene acceso a computadoras rápidas, sería interesante ver los resultados.
Si alguien quiere estudiar el tema con más detalle, puede encontrar una buena descripción del uso de RNN con ejemplos detallados en
http://karpathy.imtqy.com/2015/05/21/rnn-effectiveness/ .
PD: Y finalmente, algunos versos;) Es interesante notar que no fui yo quien formateó el texto o incluso agregó estrellas, "soy yo mismo". El siguiente paso es interesante para verificar la posibilidad de hacer dibujos y componer música. Creo que las redes neuronales son bastante prometedoras aquí.
xxx
para algunos, quedar atrapados en las galletas, todo de buena suerte en un patio de pan.
y debajo de la tarde de tamaki
debajo de una vela tomar una montaña.
xxx
pronto hijos mons en petachas en tranvía
la luz invisible huele a alegría
es por eso que toco juntos crece
no te enfermarás de un desconocido.
corazón para arrancar el ogora escalonado
no es tan viejo que el cereal está comiendo,
Guardo el puente a la pelota para robar.
de la misma manera Darina en Doba,
Escucho en mi corazón de nieve en mi mano.
nuestro canto blanco cuántos dumina suave
Le di la espalda a la bestia mineral volot.
xxx
veterinario crucificando inquietos con un hechizo
y se derramó bajo lo olvidado.
y tú, como las ramas de cuba
Brillar en ella.
o diversión en zakoto
con el vuelo de la leche.
oh eres una rosa, luz
luz de nube en mano:
y rodó al amanecer
¿Cómo estás, mi jinete?
él está sirviendo en la noche, no hasta el hueso,
de noche en Tanya la luz azul
como una especie de tristezaY los últimos versos en el aprendizaje por modo de palabra. Aquí la rima desapareció, pero apareció algún significado (?).
y tu, de la llama
las estrellas
habló a individuos distantes.
te preocupa, mañana, mañana.
"Paloma lluvia,
y hogar de los asesinos,
para la niña princesa
su cara
xxx
oh pastor, agita las cámaras
en un bosque en la primavera.
Voy por el corazón de la casa al estanque,
y ratones alegre
Campanas de Nizhny Novgorod.
pero no temas el viento de la mañana
con un camino, con un palo de hierro,
y pensado con la ostra
albergado en un estanque
en rakit empobrecido.