
Muchas aplicaciones de red consisten en un servidor web que procesa el tráfico en tiempo real y un controlador adicional que se ejecuta en segundo plano de forma asincrónica. Hay muchos consejos excelentes para verificar el estado del tráfico, y la comunidad no deja de desarrollar herramientas como Prometheus que ayudan con la evaluación. Pero los manejadores a veces no son menos, e incluso más, importantes. También necesitan atención y evaluación, pero hay poca orientación sobre cómo hacer esto mientras se evitan las trampas comunes.
Este artículo está dedicado a las trampas que son más comunes en el proceso de evaluación de manejadores asincrónicos, utilizando un ejemplo de un incidente en un entorno de producción donde, incluso con métricas, era imposible determinar exactamente qué estaban haciendo los manejadores. El uso de las métricas ha cambiado tanto el enfoque que las métricas mismas mintieron abiertamente, dicen, sus manejadores al infierno.
Veremos cómo usar las métricas de tal manera que proporcionemos una estimación precisa y, en conclusión, mostraremos la implementación de referencia de prometheus-client-tracer de código abierto, que puede usar en sus aplicaciones.
Incidente
Las alertas llegaron a una velocidad de ametralladora: la cantidad de errores HTTP aumentó considerablemente, y los paneles de control confirmaron que las colas de solicitudes estaban creciendo y que el tiempo de respuesta se estaba agotando. Aproximadamente 2 minutos después, las colas se borraron y todo volvió a la normalidad.
Tras una inspección más cercana, resultó que nuestros servidores API se pusieron de pie, esperando una respuesta de DB, lo que provocó que se detuviera y de repente levantara toda la actividad. Y cuando considera que la carga más pesada cae con mayor frecuencia en el nivel de los procesadores asíncronos, se han convertido en los principales sospechosos. La pregunta lógica era: ¿qué están haciendo allí?
La métrica de Prometheus muestra lo que lleva tiempo el proceso, aquí está:
# HELP job_worked_seconds_total Sum of the time spent processing each job class # TYPE job_worked_seconds_total counter job_worked_seconds_total{job}
Al rastrear el tiempo de ejecución total de cada tarea y la frecuencia con la que cambia la métrica, descubriremos cuánto tiempo de trabajo se ha dedicado. Si por un período de 15 segundos. el número aumentó en 15, esto implica 1 manejador ocupado (un segundo por cada segundo pasado), mientras que un aumento de 30 significa 2 manejadores, etc.
Un horario de trabajo durante el incidente mostrará lo que estamos enfrentando. Los resultados son decepcionantes; la hora del incidente (16: 02-16: 04) está marcada por la alarmante línea roja:

Actividad del manejador durante el incidente: se observa una brecha notable.
Fue doloroso para mí, como persona que estaba depurando después de esta pesadilla, ver que la curva de actividad estaba en el fondo justo durante el incidente. Este es el momento de trabajar con enlaces web, en el que tenemos 20 controladores dedicados. Según los registros, sé que todos estaban en el negocio, y esperaba que la curva fuera de unos 20 segundos, y vi una línea casi recta. Además, ¿ves este gran pico azul a las 16:05? A juzgar por el calendario, 20 procesadores de un solo subproceso pasaron 45 segundos. por cada segundo de actividad, pero ¿es esto posible?
¿Dónde y qué salió mal?
El cronograma del incidente es mentiroso: oculta la actividad laboral y al mismo tiempo muestra lo superfluo, dependiendo de dónde medir. Para saber por qué sucede esto, debe tener en cuenta la implementación del seguimiento de métricas y cómo interactúa con las métricas de recopilación de Prometheus.
Comenzando con la forma en que los manejadores recopilan las métricas, puede esbozar un esquema aproximado de implementación del flujo de trabajo (ver a continuación). Nota: los controladores solo actualizan las métricas al completar una tarea .
class Worker JobWorkedSecondsTotal = Prometheus::Client::Counter.new(...) def work job = acquire_job start = Time.monotonic_now job.run ensure # run after our main method block duration = Time.monotonic_now - start JobWorkedSecondsTotal.increment(by: duration, labels: { job: job.class }) end end
Prometheus (con su filosofía de extracción de métricas) envía una solicitud GET a cada controlador cada 15 segundos, registrando los valores de las métricas en el momento de la solicitud. Los controladores actualizan constantemente las métricas de las tareas completadas, y con el tiempo podemos mostrar gráficamente la dinámica de los cambios en los valores.
El problema con la subvaloración y revaluación comienza a aparecer cada vez que el tiempo que lleva completar una tarea excede el tiempo de espera para una solicitud que llega cada 15 segundos. Por ejemplo, una tarea comienza 5 segundos antes de la solicitud y termina 1 segundo después. Total y generalmente, dura 6 segundos, pero este tiempo es visible solo al estimar los costos de tiempo realizados después de la solicitud, mientras que 5 de estos 6 segundos se gastaron antes de la solicitud.
Los indicadores son aún más impíos si las tareas tardan más que el período de informe (15 segundos). Durante la ejecución de la tarea durante 1 minuto, Prometheus tendrá tiempo para enviar 4 solicitudes a los procesadores, pero la métrica se actualizará solo después del cuarto.
Una vez dibujada una línea de tiempo de la actividad laboral, veremos cómo el momento en que se actualiza la métrica afecta lo que ve Prometeo. En el siguiente diagrama, dividimos la línea de tiempo de dos controladores en varios segmentos que muestran tareas de diferentes duraciones. Las etiquetas rojas (15 segundos) y azules (30 segundos) indican 2 muestras de datos Prometheus; Las tareas que sirvieron como fuente de datos para la evaluación se resaltan en consecuencia.
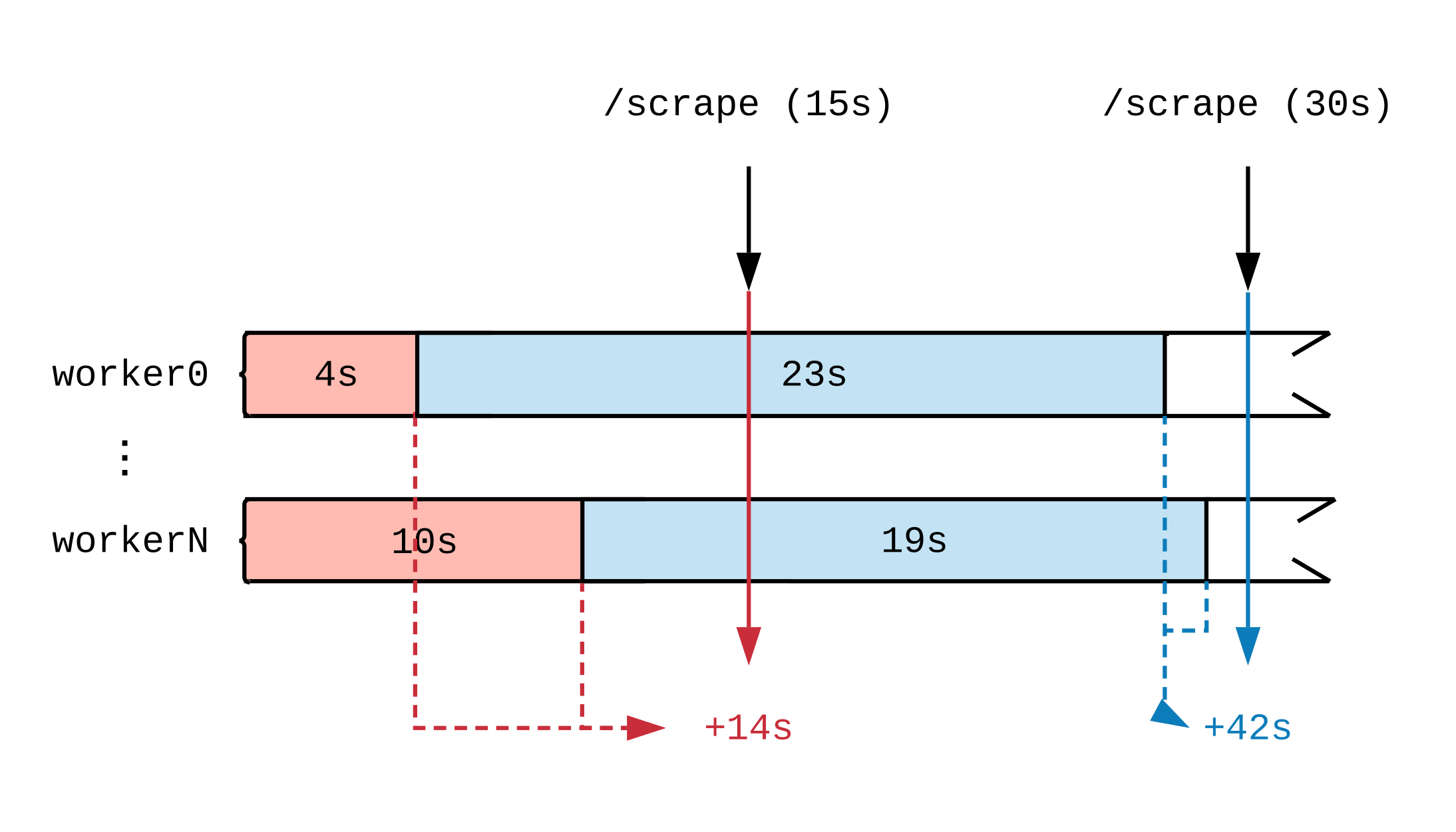
Independientemente de lo que estén haciendo los manejadores a plena carga, harán 30 segundos de trabajo cada intervalo de 15 segundos. Dado que Prometeo no ve el trabajo hasta que se completa, a juzgar por las métricas, se completaron 14 segundos de trabajo en el primer intervalo de tiempo y 42 segundos en el segundo. Si cada controlador realiza una tarea voluminosa, incluso después de unas pocas horas, hasta el final, no veremos informes de que el trabajo está en curso.
Para demostrar este efecto, realicé un experimento con diez manejadores dedicados a tareas cuya longitud es diferente y semi-normal distribuida entre 0.1 segundos y un valor ligeramente mayor (ver tareas aleatorias ). A continuación hay 3 gráficos que representan la actividad laboral; la longitud en el tiempo se muestra en orden creciente.
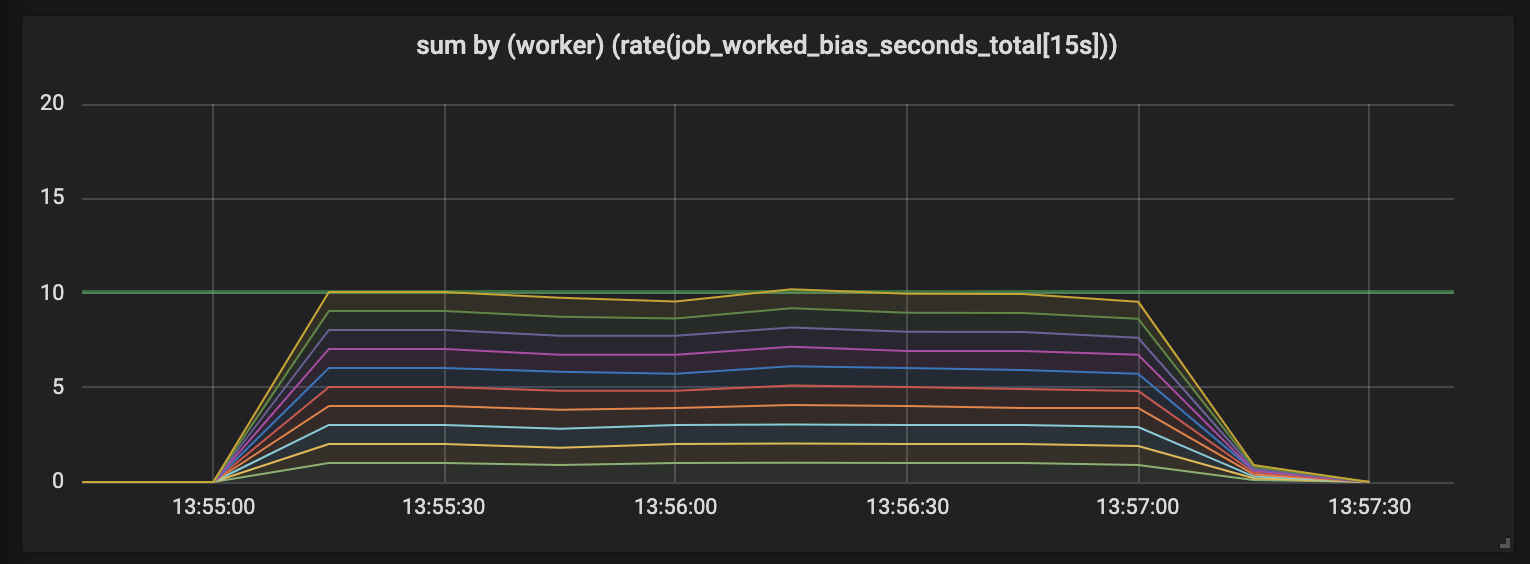
Tareas que duran hasta 1 segundo.
El primer gráfico muestra que cada controlador realiza aproximadamente 1 segundo de trabajo en cada segundo de tiempo, esto es visible en líneas planas, y la cantidad total de trabajo es igual a nuestras capacidades (10 controladores dan un segundo de trabajo por segundo de tiempo). En realidad, esto, independientemente de la duración de la tarea, esperamos: tanto en tareas cortas como largas, los procesadores con carga constante deberían ceder.
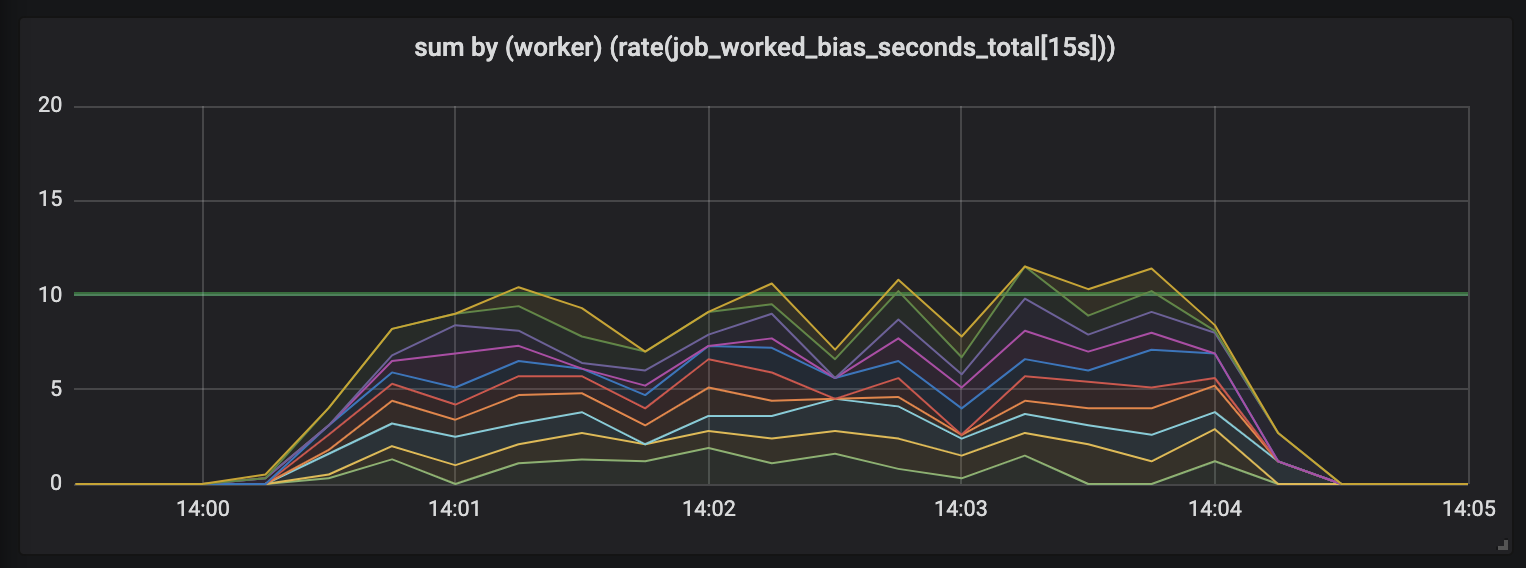
Tareas que duran hasta 15 segundos.
La duración de las tareas aumenta y aparece un desorden en el cronograma: todavía tenemos 10 procesadores, todos ellos están totalmente ocupados, pero la cantidad total de trabajo se salta, ya sea menor o mayor que el límite de capacidad útil (10 segundos).
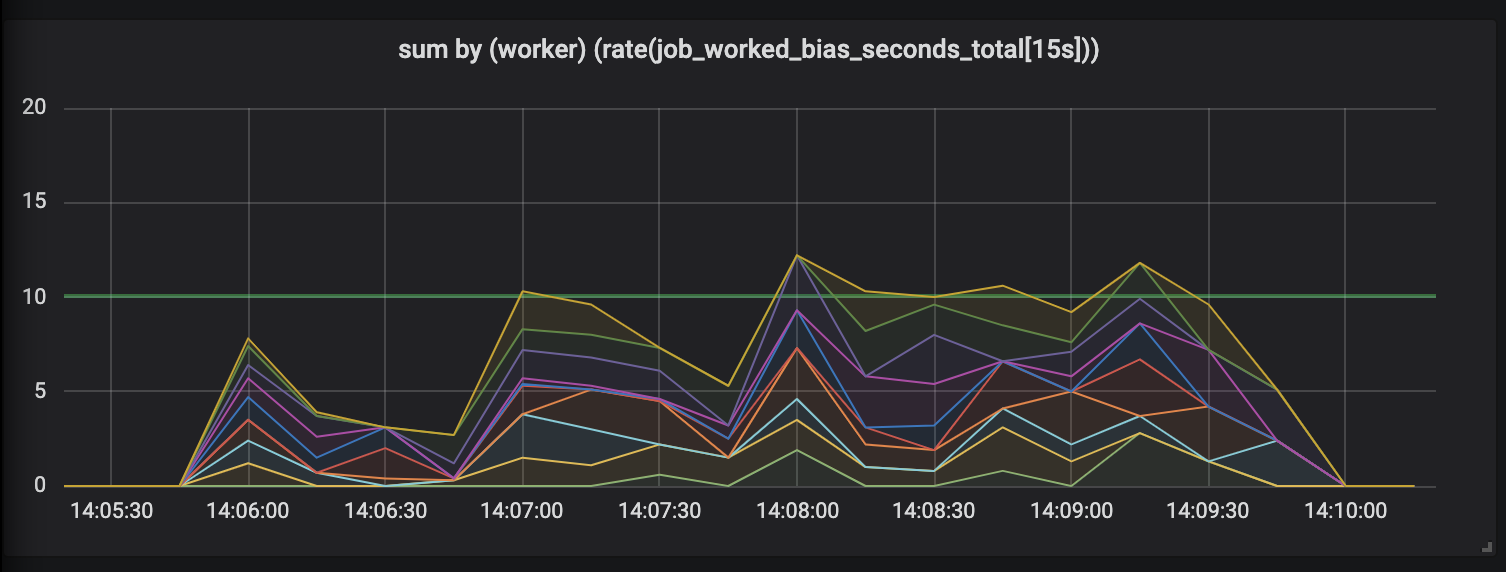
Tareas que duran hasta 30 segundos.
La evaluación de trabajos que duran hasta 30 segundos es simplemente ridícula. Una métrica con límite de tiempo muestra actividad cero para las tareas más largas y, solo cuando se completan las tareas, nos dibuja picos de actividad.
Restaurar la confianza
Esto no fue suficiente para nosotros, por lo que hay otro problema mucho más insidioso con estas tareas a largo plazo que estropean nuestras métricas. Cada vez que se completa una tarea a largo plazo, por ejemplo, si Kubernetes arroja una cápsula de un grupo o cuando un nodo muere, ¿qué sucede con las métricas? Vale la pena actualizarlos inmediatamente después de completar la tarea, ya que muestran que no hicieron el trabajo en absoluto .
Las métricas no deben mentir. La computadora portátil aúlla incrédulamente, causando horror existencial, y las herramientas de vigilancia que distorsionan la imagen del mundo son una trampa y no son adecuadas para el trabajo.
Afortunadamente, el asunto es reparable. La distorsión de datos se produce porque Prometheus toma medidas independientemente de cuándo los procesadores actualizan las métricas. Si pedimos a los controladores que actualicen las métricas cuando Prometheus envía solicitudes, veremos que Prometheus ya no es peculiar y muestra la actividad actual.
Introducing ... Tracer
Una solución al problema de métricas distorsionadas es el Tracer , un diseño abstracto que evalúa la actividad en tareas de larga duración mediante la actualización gradual de las métricas relacionadas con Prometheus.
class Tracer def trace(metric, labels, &block) ... end def collect(traces = @traces) ... end end
Los trazadores proporcionan un método de rastreo que toma las métricas de Prometheus y la tarea a seguir. El comando trace ejecutará el bloque dado (funciones Ruby anónimas) y asegurará que las solicitudes a tracer.collect durante la ejecución actualizarán de manera incremental las métricas relacionadas sin importar cuánto tiempo haya pasado desde la última solicitud de collect .
Necesitamos conectar el tracer a los manejadores para rastrear la duración de la tarea y el punto final que atiende las solicitudes de métricas de Prometheus. Comenzamos con los manejadores, inicializamos un nuevo trazador y le pedimos que acquire_job.run la ejecución de acquire_job.run .
class Worker def initialize @tracer = Tracer.new(self) end def work @tracer.trace(JobWorkedSecondsTotal, labels) { acquire_job.run } end # Tell the tracer to flush (incremental) trace progress to metrics def collect @tracer.collect end end
En esta etapa, el trazador solo actualizará las métricas en segundos dedicados a la tarea completada, como lo hicimos en la implementación inicial de las métricas. Debemos solicitar al rastreador que actualice nuestras métricas antes de ejecutar una solicitud de Prometheus. Esto se puede hacer configurando el rack de middleware.
# config.ru # https://rack.imtqy.com/ class WorkerCollector def initialize(@app, workers: @workers); end def call(env) workers.each(&:collect) @app.call(env) # call Prometheus::Exporter end end # Rack middleware DSL workers = start_workers # Array[Worker] # Run the collector before serving metrics use WorkerCollector, workers: workers use Prometheus::Middleware::Exporter
Rack es una interfaz para servidores web Ruby que le permite combinar múltiples manejadores de Rack en un único punto final. El comando config.ru determina que la aplicación Rack, cada vez que recibe la solicitud, envía el comando de collect a los controladores primero, y solo luego le dice al cliente Prometheus que dibuje los resultados de la recopilación.
En cuanto a nuestro gráfico, actualizamos las métricas cada vez que se completa la tarea o cuando recibimos una solicitud de métricas. Las tareas que tienen varias consultas envían igualmente datos en todos los segmentos: como lo muestran las tareas cuya duración se dividió en intervalos de 15 segundos.

¿Es mejor?
El uso del rastreador las 24 horas afecta la forma en que se registra la actividad. A diferencia de las mediciones iniciales, que mostraron una "sierra", cuando el número de picos excedía el número de procesadores en ejecución y períodos de silencio sordo, el experimento con diez procesadores proporciona un gráfico que muestra claramente que cada procesador está integrado en el trabajo que se monitorea de manera uniforme.

Métricas basadas en la comparación (izquierda) y controladas por el trazador (derecha), tomadas de un experimento de trabajo.
En comparación con el calendario francamente inexacto y caótico de las mediciones iniciales, las métricas recopiladas por el marcador son suaves y consistentes. Ahora no solo vinculamos con precisión el trabajo a cada solicitud de métrica, sino que tampoco nos preocupamos por la muerte repentina de ninguno de los manejadores: Prometheus registra las métricas hasta que el manejador desaparece, evaluando todo su trabajo.
¿Se puede usar esto?
Si! La interfaz de Tracer ha resultado útil en muchos proyectos, por lo que esta es una gema de Ruby separada, prometheus-client-tracer . Si usa el cliente Prometheus en sus aplicaciones Ruby, simplemente agregue el prometheus-client-tracer a su Gemfile:
require "prometheus/client" require "prometheus/client/tracer" JobWorkedSecondsTotal = Prometheus::Client::Counter.new(...) Prometheus::Client.trace(JobWorkedSecondsTotal) do sleep(long_time) end
Si esto le resulta útil y desea que el cliente oficial de Prometheus Ruby aparezca en Tracer , deje un comentario en client_ruby # 135 .
Y finalmente, algunos pensamientos.
Espero que esto ayude a otros a recolectar métricas de manera más consciente para tareas de larga duración y resolver uno de los problemas comunes. No se equivoque, está asociado no solo con el procesamiento asincrónico: si sus solicitudes HTTP se ralentizan, también se beneficiarán del uso del rastreador al evaluar el tiempo dedicado al procesamiento.
Como de costumbre, cualquier comentario y corrección son bienvenidos: escriba a Twitter o abra PR . Si desea contribuir a la gema del trazador, el código fuente está en prometheus-client-tracer-ruby .