Hola Habr! Nuestros amigos de Softpoint han preparado un interesante artículo sobre Microsoft SQL Server. Analiza dos ejemplos prácticos del uso de la búsqueda de texto completo:
- Busque en líneas "infinitas" (p. Ej., Comentarios) en lugar de una búsqueda regular a través de LIKE;
- Buscar por números de documento con prefijos. Donde generalmente no se puede usar la búsqueda de texto completo: los prefijos constantes interfieren con ella. Se analizan 2 enfoques: preprocesar el número de documento y agregar su propio separador de palabras de la biblioteca.
Únete ahora!
 Le doy la palabra al autor
Le doy la palabra al autorUna búsqueda efectiva en gigabytes de datos acumulados es una especie de "santo grial" de los sistemas de contabilidad. Todos quieren encontrarlo y obtener la gloria inmortal, pero en el proceso de búsqueda una y otra vez resulta que no hay una solución milagrosa única.
La situación se complica por el hecho de que los usuarios generalmente desean buscar una subcadena; en algún lugar resulta que el número de contrato deseado está "enterrado" en el medio del comentario; en alguna parte, el operador no recuerda exactamente el nombre del cliente, pero recordó que se llamaba "Alexey Evgrafovich"; en algún lugar, solo necesita omitir la forma recurrente de propiedad de BYUBL y buscar de inmediato por el nombre de la organización. Para los DBMS relacionales clásicos, tal búsqueda es una muy mala noticia. Muy a menudo, dicha búsqueda de subcadenas se reduce al desplazamiento metódico de cada fila de la tabla. No es la estrategia más efectiva, especialmente si el tamaño de la tabla crece a varias decenas de gigabytes.
En busca de una alternativa, a menudo recuerdo la "búsqueda de texto completo". La alegría de encontrar una solución generalmente pasa rápidamente después de una revisión superficial de la práctica existente. Resulta rápidamente que, según la opinión popular, la búsqueda de texto completo:
- Difícil de configurar
- Poco a poco actualizado
- Cuelga el sistema al actualizar
- Tiene algún tipo de sintaxis
estúpida e inusual - No encuentra lo que preguntan
El conjunto de mitos puede continuar durante mucho tiempo, pero incluso Platón nos enseñó a ser escépticos y no aceptar ciegamente la opinión de otra persona sobre la fe. ¿A ver si el demonio es tan terrible como está pintado?
Y, aunque no estamos profundamente inmersos en el estudio, acordaremos de
inmediato una condición importante . El motor de búsqueda de texto completo puede hacer mucho más que una búsqueda de cadena normal. Por ejemplo, puede definir un diccionario de sinónimos y usar la palabra "contacto" para buscar "teléfono". O busque palabras sin tener en cuenta la forma y las terminaciones. Estas opciones pueden ser muy útiles para los usuarios, pero en este artículo consideramos la búsqueda de texto completo solo como una alternativa a la búsqueda de línea clásica. Es decir,
solo buscaremos la subcadena que se especificará en la barra de búsqueda , sin tener en cuenta los sinónimos, sin traer palabras a la forma "normal" y otra magia.
Cómo funciona la búsqueda de texto completo de MS SQL
La funcionalidad de búsqueda de texto completo en MS SQL se ha eliminado parcialmente del servicio principal de DBMS (cerca del final del artículo veremos por qué esto puede ser extremadamente útil). Para la búsqueda, se forma un índice especial con su estructura, a diferencia de los árboles equilibrados habituales.
Es importante que para crear un índice de búsqueda de texto completo, sea necesario que exista un índice único en la tabla de claves, que consista en una sola columna; es su búsqueda de texto completo la que se utilizará para identificar las filas de la tabla. A menudo, la tabla ya tiene dicho índice en la Clave primaria, pero a veces tendrá que crearse adicionalmente.
El índice de búsqueda de texto completo se rellena de forma asincrónica y fuera de transacción. Después de cambiar una fila de la tabla, se pone en cola para su procesamiento. El proceso de actualización del índice recibe de la fila de la tabla (fila) todos los valores de cadena, "suscritos" al índice, y los divide en palabras separadas. Después de esto, las palabras se pueden reducir a una cierta forma "estándar" (por ejemplo, sin terminaciones), de modo que sea más fácil buscar por formas de palabras. Se arrojan "palabras de detención" (preposiciones, artículos y otras palabras que no tienen significado). Las coincidencias de enlace de palabra a cadena restantes se escriben en el índice de búsqueda de texto completo.
Resulta que cada columna de la tabla incluida en el índice pasa a través de dicha canalización:
Línea larga -> separador de palabras -> conjunto de partes (palabras) -> stemmer -> palabras normalizadas -> [opcional] excepción de palabra de detención -> escribir en índice
Como se mencionó, el proceso de actualización del índice es asíncrono. De esto se desprende:
- La actualización no bloquea las acciones del usuario
- La actualización espera la finalización de la transacción de cambio de fila y comienza a aplicar los cambios no antes de la confirmación
- Los cambios en el índice de texto completo se aplican con cierto retraso en relación con la transacción principal. Es decir, entre agregar una fila y el momento en que se puede encontrar, habrá un retraso dependiendo de la longitud de la cola de actualización del índice
- La consulta puede monitorear el número de elementos contenidos en el índice:
SELECT cat.name, FULLTEXTCATALOGPROPERTY(cat.name,'ItemCount') AS [ItemCount] FROM sys.fulltext_catalogs AS cat
Pruebas prácticas Busqueda fisica personas por nombre
Llenar la tabla con datos
Para los experimentos, crearemos una nueva base vacía con una tabla donde se almacenarán las "contrapartes". Dentro del campo "descripción" habrá una línea con el nombre del contrato, donde se mencionará el nombre de la contraparte. Algo como esto:
"Contrato con Borovik Demyan Emelyanovich"
Más o menos:
"Perro. con Borovik-Romanov Anatoly Avdeevich "
Sí, quiero dispararme de inmediato a partir de esa "arquitectura", pero, desafortunadamente, esa aplicación de "comentarios" o "descripciones" a menudo se encuentra entre los usuarios de negocios.
Además, agregamos algunos campos "para peso": si solo hay 2 columnas en la tabla, un escaneo simple lo leerá en unos instantes. Necesitamos "inflar" la tabla para que la exploración sea larga. Esto nos acerca a casos comerciales reales: almacenamos no solo la “descripción” en la tabla, sino también mucha otra información útil [del diablo].
create table partners (id bigint identity (1,1) not null, [description] nvarchar(max), [address] nvarchar(256) not null default N'107240, , ., 168', [phone] nvarchar(256) not null default N'+7 (495) 111-222-33', [contact_name] nvarchar(256) not null default N'', [bio] nvarchar(2048) not null default N' . , , . , . , . , , , , . . , , . , , . , , , . , , . . .') -- , ..
La siguiente pregunta es ¿dónde obtener tantos apellidos únicos, nombres y patronímicos? Yo, según un viejo hábito, actuaba como un estudiante ruso normal, es decir. fue a wikipedia:
- Nombres tomados de la página Categoría: nombres masculinos rusos
- Reescribir manualmente los segundos nombres a partir de los nombres, cambiando las terminaciones
- Con los apellidos resultó ser un poco más complicado. Al final, se encontró la categoría "homónimos". Un pequeño chamanismo con Python y en una tabla separada resultó 46.5 mil nombres. (un script para descargar apellidos está disponible aquí)
Por supuesto, hubo variaciones extrañas entre los apellidos, pero para los propósitos del estudio esto fue bastante aceptable.
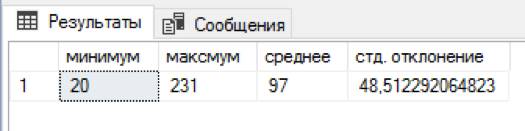
Escribí un script sql que adjunta un número aleatorio de nombres y patronímicos a cada apellido. 5 minutos de espera y en una mesa separada ya había 4.5 millones de combinaciones. No esta mal! Para cada apellido había de 20 a 231 combinaciones del nombre + segundo nombre, en promedio se obtuvieron 97 combinaciones. La distribución por nombre y patronímico resultó estar ligeramente sesgada "a la izquierda", pero pensar en un algoritmo más equilibrado parecía redundante.
Los datos están preparados, podemos comenzar nuestros experimentos.
Configuración de búsqueda de texto completo
Cree un índice de texto completo en el nivel de MS SQL. Primero necesitamos crear un repositorio para este índice: un catálogo de texto completo.
USE [like_vs_fulltext] GO CREATE FULLTEXT CATALOG [basic_ftc] WITH ACCENT_SENSITIVITY = OFF AS DEFAULT AUTHORIZATION [dbo] GO
Hay un catálogo, estamos tratando de agregar un índice de texto completo para nuestra tabla ... y nada funciona.
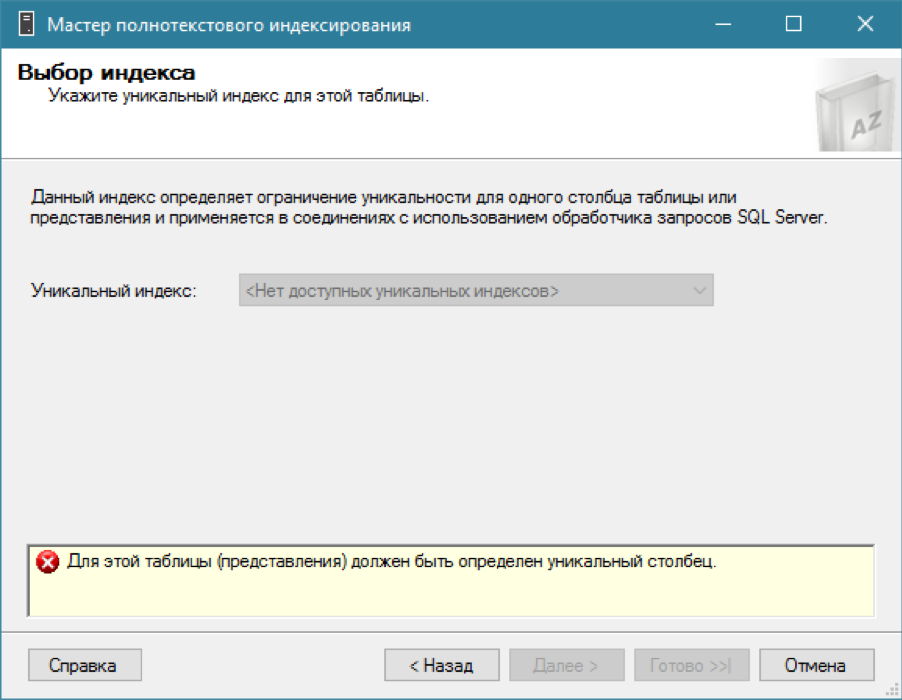
Como dije, para un índice de texto completo necesita un índice regular con una columna única. Recordamos que ya tenemos el campo requerido: un identificador de identificación único. Creemos un índice de clúster único en él (aunque sería suficiente uno no agrupado):
create unique clustered index ndx1 on partners (id)
Después de crear un nuevo índice, finalmente podemos agregar el índice de búsqueda de texto completo. Esperemos unos minutos hasta que el índice esté lleno (recuerde que se actualiza de forma asíncrona). Puedes proceder a las pruebas.
Prueba
Comencemos con el escenario más simple, cerca de la aplicación real de la búsqueda. Simulamos una "vista de lista": una selección de ventana de 45 líneas con selección por máscara de búsqueda. Ejecutamos la solicitud con un nuevo índice de texto completo, notamos el tiempo - 0 segundos - ¡excelente!
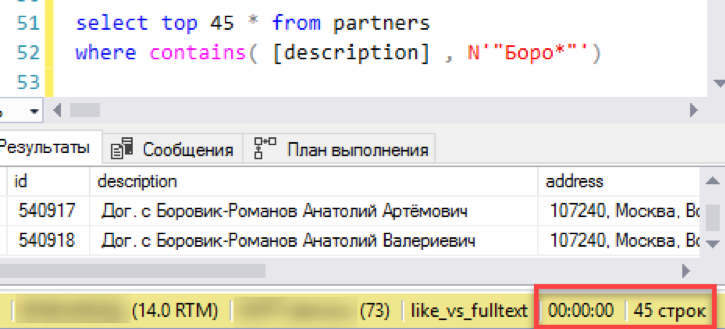
Ahora, una vieja y probada búsqueda a través de "me gusta". Tomó 3 segundos para formar el resultado. No está tan mal, la derrota total no funcionó. Tal vez entonces no tiene sentido configurar una búsqueda de texto completo: ¿funciona todo bien?
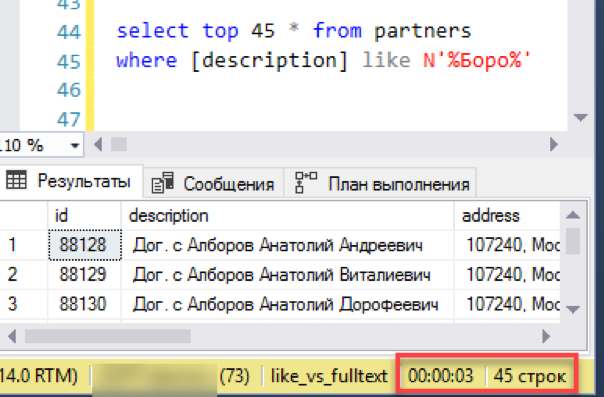
De hecho, nos perdimos un detalle importante: la solicitud se ejecutó sin ordenar. En primer lugar, dicha consulta combinada con "seleccionar los primeros N registros" devuelve un resultado injustificado. Cada inicio puede devolver N registros aleatorios y no hay garantía de que dos inicios consecutivos den el mismo conjunto de datos. En segundo lugar, si estamos hablando de "ver la lista con una ventana deslizante", por lo general, esta misma "ventana" se ordena por cualquier columna, por ejemplo, por nombre. Después de todo, el operador necesita saber qué obtendrá cuando se mueva a la siguiente "ventana".
Corrige el experimento. Agregue clasificación, digamos, por número de teléfono:
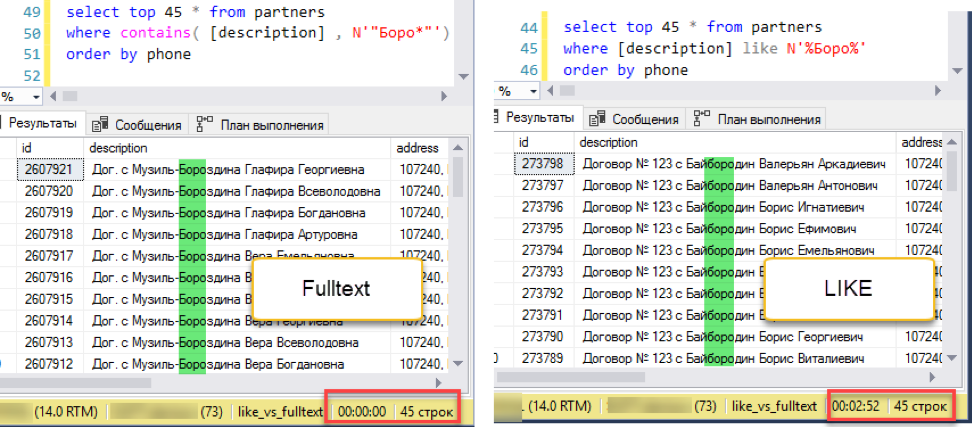 La búsqueda de texto completo gana con una puntuación ensordecedora: ¡0 segundos frente a 172 segundos!
La búsqueda de texto completo gana con una puntuación ensordecedora: ¡0 segundos frente a 172 segundos!Si observa los planes de consulta, queda claro por qué es así. Debido a la adición de pedidos al texto de la consulta, apareció una operación de clasificación durante la ejecución. Esta es la llamada operación de "bloqueo", que no puede completar la solicitud hasta que reciba la cantidad total de datos para ordenar. No podemos recoger los primeros 45 registros que tenemos, tenemos que ordenar todo el conjunto de datos.
Y en la etapa de obtención de datos para la clasificación, se produce una diferencia dramática. Una búsqueda con "me gusta" tiene que navegar a través de toda la tabla disponible. Esto lleva 172 segundos. Pero la búsqueda de texto completo tiene su propia estructura optimizada, que devuelve inmediatamente enlaces a todas las entradas necesarias.
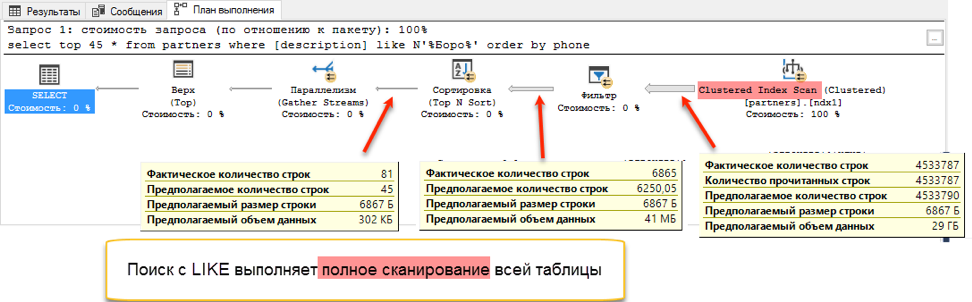
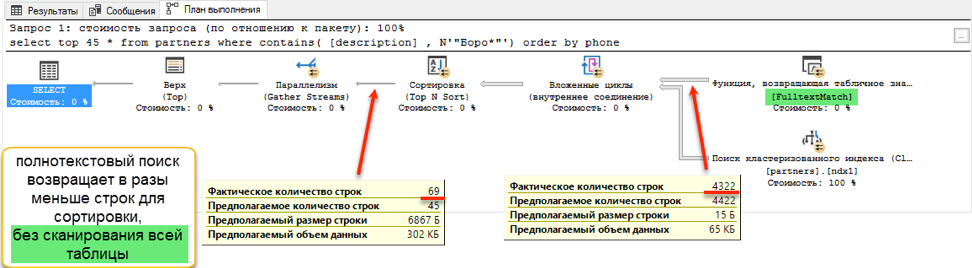
¿Pero debería haber una mosca en la pomada? Hay uno Como se indicó al principio, una búsqueda de texto completo solo puede buscar desde el principio de una palabra. Y si queremos encontrar "Ivan Poddubny" junto a la subcadena "* oak *", una búsqueda de texto completo no mostrará nada útil.
Afortunadamente, para buscar por nombre, este no es el escenario más popular.
Buscar un documento por número
Probemos algo más complicado. El segundo caso de uso popular para la búsqueda es encontrar un documento por parte de su número. Además, a menudo el número de documento consta de dos partes: el prefijo de la letra y el número real que contiene ceros a la izquierda.
No hay espacios ni caracteres de servicio entre estas partes. Al mismo tiempo, buscar por el número completo es monstruosamente inconveniente: debe recordar cuántos ceros a la izquierda después del prefijo deben estar antes del comienzo de la parte significativa. Resulta que la búsqueda de texto completo "fuera de la caja" es simplemente inútil en tal escenario. Tratemos de arreglarlo.
Para la prueba, creé una nueva tabla llamada documento, en la que agregué 13.5 millones de registros con números únicos del tipo "ORG". La numeración fue en orden, todos los números comenzaron con "ORG". Puedes empezar.
Pre-dividir un número
La búsqueda de texto completo puede buscar palabras de manera eficiente. Bueno, ayudémoslo y separemos el número "incómodo" en palabras convenientes de antemano. El plan de acción es el siguiente:
- Agregue una columna adicional a la tabla de origen donde se almacenará el número convertido especialmente
- Agregue un disparador, que al cambiar el número lo dividirá en varias partes pequeñas, separadas por un espacio
- La búsqueda de texto completo ya sabe cómo dividir una cadena en partes por espacios, de modo que indexará nuestro número modificado sin problemas
Veamos cómo funcionará esto.
Agregue una columna adicional a la tabla.
alter table document add number_parts nvarchar(128) not null default ''
Un disparador que llena una nueva columna se puede escribir “frente”, ignorando posibles duplicados (¿cuántos triples repetidos hay en el número “0000012”?) Y puede agregar algo de magia XML y registrar solo partes únicas. La primera implementación será más rápida, la segunda dará un resultado más compacto. De hecho, la elección es entre velocidad de escritura y velocidad de lectura, elija lo que es más importante en su situación. Ahora solo revisa un
script que procesa los números existentes.
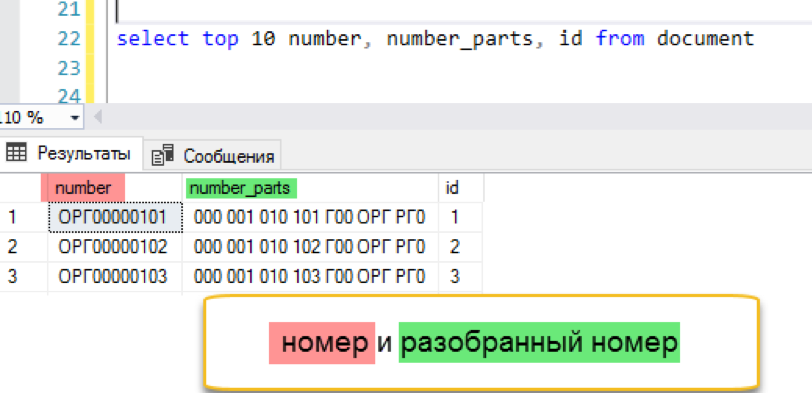
Agregar índice de texto completo
create fulltext index on document (number_parts) key index ndx1 with change_tracking = Auto
Y verifica el resultado. El experimento es el mismo: modelar una selección de "ventana" de una lista de documentos. No repetimos los errores anteriores e inmediatamente ejecutamos la solicitud ordenando, en este caso por fecha.
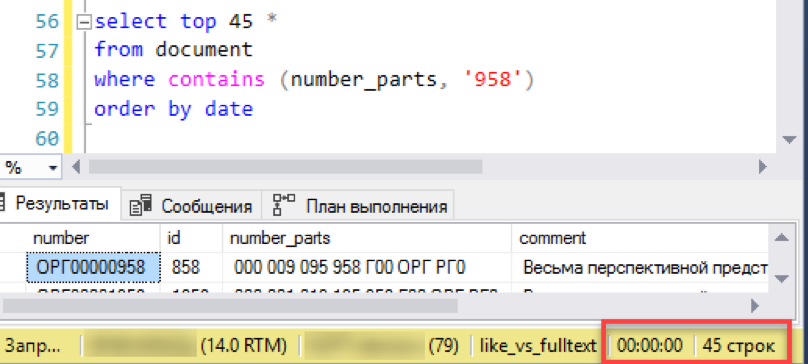
Funciona! Ahora intentemos un número más auténtico:
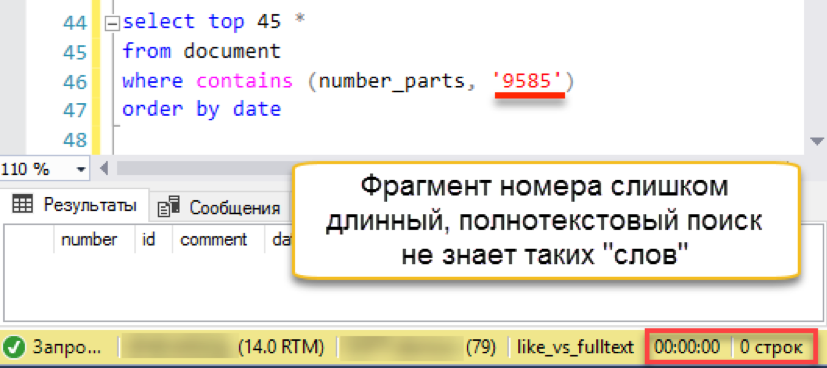
Y luego ocurre un fallo de encendido. La longitud de la cadena de búsqueda es más larga que la longitud de las "palabras" almacenadas. De hecho, la base de datos de búsqueda simplemente no tiene una sola línea de 4 caracteres, por lo que honestamente devuelve un resultado vacío. Tendremos que batir la cadena de búsqueda en partes:
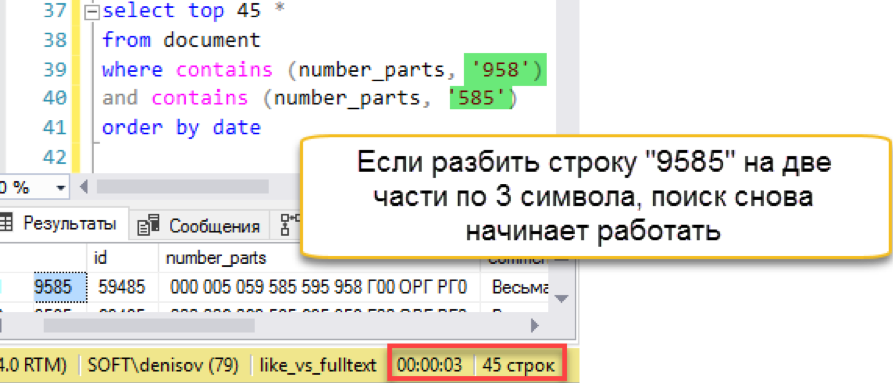
Otra cosa! Nuevamente tenemos una búsqueda rápida. Sí, impone sus gastos generales en mantenimiento, pero el resultado es cientos de veces más rápido que la búsqueda clásica. Notamos que el intento contó, pero intente simplificar el mantenimiento de alguna manera, en la siguiente sección.
¡Lo dividiremos en palabras a nuestra manera!
De hecho, ¿quién dijo que las palabras deberían estar separadas por espacios? ¡Tal vez quiero ceros entre palabras! (y, si es posible, el prefijo para que también se ignore y no interfiera bajo los pies). En general, no hay nada imposible en esto. Recordemos el esquema de operación de búsqueda de texto completo desde el principio del artículo: un componente separado, el separador de palabras, es responsable de dividir en palabras y, afortunadamente, Microsoft le permite implementar su propio "separador de palabras".
Y aquí comienza lo interesante. Wordbreaker es un dll separado que se conecta al motor de búsqueda de texto completo. La
documentación oficial dice que hacer esta biblioteca es muy simple: simplemente implemente la interfaz IWordBreaker. Y aquí hay un par de listados cortos de inicialización en C ++. Con mucho éxito, ¡acabo de encontrar un tutorial adecuado!

(
fuente )
En serio, la documentación para crear su propio rompehielos en Internet es muy pequeña. Incluso menos ejemplos y plantillas. Pero todavía encontré el
proyecto de una persona amable que escribió en C ++ una implementación que desglosa las palabras no por separadores, sino simplemente por triples (sí, ¡como en la sección anterior!) Además, la carpeta del proyecto ya contiene un binario cuidadosamente compilado, que solo necesita conectarse al motor de búsqueda
Solo enchufar ... En realidad no es muy fácil. Veamos los pasos:
Necesita copiar la biblioteca a la carpeta con SQL Server:

Registrar un nuevo "idioma" en la búsqueda de texto completo
exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\CLSID\{d225281a-7ca9-4a46-ae7d-c63a9d4815d4}', 'DefaultData', 'REG_SZ', 'sqlngram.dll' exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\CLSID\{0a275611-aa4d-4b39-8290-4baf77703f55}', 'DefaultData', 'REG_SZ', 'sqlngram.dll' exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\Language\ngram', 'Locale', 'REG_DWORD', 1 exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\Language\ngram', 'WBreakerClass', 'REG_SZ', '{d225281a-7ca9-4a46-ae7d-c63a9d4815d4}' exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\Language\ngram', 'StemmerClass', 'REG_SZ', '{0a275611-aa4d-4b39-8290-4baf77703f55}' exec sp_fulltext_service 'verify_signature' , 0; exec sp_fulltext_service 'update_languages'; exec sp_fulltext_service 'restart_all_fdhosts'; exec sp_help_fulltext_system_components 'wordbreaker';
Edite manualmente varias claves en el registro (el autor iba a automatizar el proceso, pero no hay novedades desde 2016. Sin embargo, este fue originalmente un "ejemplo de implementación", gracias por eso)
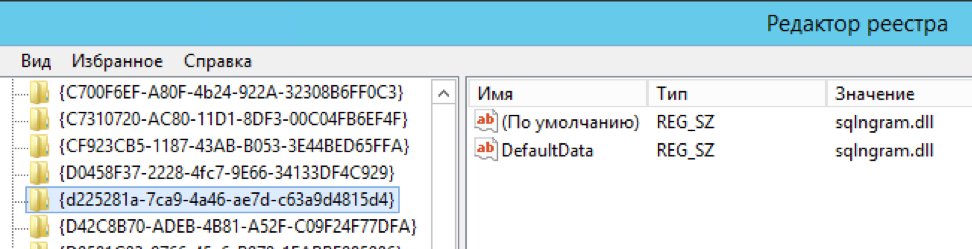
Los pasos se describen en detalle en la página del proyecto.
Listo Eliminemos el índice de texto completo anterior, porque no puede haber dos índices de texto completo para una tabla. Cree uno nuevo e indexe nuestros números de documento. Como columna clave, indicamos los números mismos, no se necesitan más columnas sustitutas previamente divididas. Asegúrese de especificar el "idioma número 1" para usar el rompedor de palabras recién instalado.
drop fulltext index on document go create fulltext index on document (number Language 1) key index ndx1 with change_tracking = Auto
Cheque?
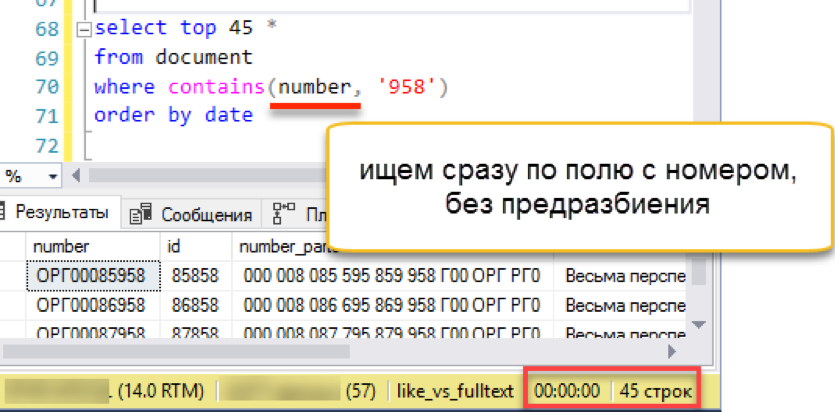
Funciona! Funciona tan rápido como todos los ejemplos discutidos anteriormente.
Veamos la larga línea en la que se tropezó la opción anterior:
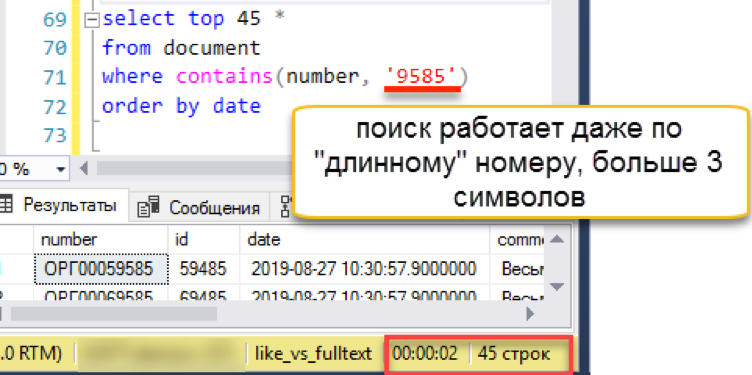
La búsqueda funciona de forma transparente para el usuario y el programador. Wordbreaker rompe independientemente la cadena de búsqueda en pedazos y encuentra el resultado deseado.
Resulta que ahora no necesitamos columnas y disparadores adicionales, es decir, la solución es más simple (léase: más confiable) que nuestro intento anterior. Bueno, en términos de soporte, tal implementación es más simple y más transparente, hay menos posibilidades de errores.
Entonces, para, ¿dije "más confiable"? ¡Acabamos de conectar una biblioteca de terceros a nuestro DBMS! ¿Y qué pasará si ella se cae? ¡Incluso inadvertidamente arrastra todo el servicio de base de datos!
Aquí debe recordar cómo al principio del artículo mencioné el servicio de búsqueda de texto completo, separado del proceso principal de DBMS. Es aquí donde queda claro por qué esto es importante. La biblioteca se conecta al servicio de indexación de texto completo, que puede operar con derechos reducidos. Y, lo que es más importante, si caen componentes de terceros, solo caerá el servicio de indexación. La búsqueda se detendrá por un tiempo (pero ya es asíncrona), y el motor de la base de datos continuará funcionando como si nada hubiera pasado.
Para resumir. Agregar su propio rompecorazones puede ser todo un desafío. Pero cuando se juega "a la larga", estos esfuerzos dan resultado con una mayor flexibilidad y facilidad de mantenimiento. La elección, como siempre, es tuya.
¿Por qué es todo esto necesario?
Un lector curioso probablemente se preguntó más de una vez: "todo esto es genial, pero ¿cómo puedo usar estas funciones si no puedo cambiar las consultas de búsqueda desde mi aplicación?" Pregunta razonable La inclusión de la búsqueda de MS SQL de texto completo requiere cambiar la sintaxis de las consultas, y a menudo esto simplemente no es posible en la arquitectura existente.
Puede intentar engañar a la aplicación "deslizando" una función con valores de tabla del mismo nombre en lugar de una tabla normal, que ya realizará la búsqueda de la manera que deseamos. Puede intentar vincular la búsqueda como una especie de fuente de datos externa. Hay otra solución, Softpoint Data Cluster, un servicio especial que instala un "reenvío" entre la aplicación de origen y el servicio SQL Server, escucha el tráfico y puede cambiar las solicitudes "sobre la marcha" de acuerdo con reglas especiales. Usando estas reglas, podemos encontrar consultas regulares con LIKE y convertirlas a CONTAINS con búsqueda de texto completo.
¿Por qué tantas dificultades? Aún así, la velocidad de búsqueda es cautivadora. En un sistema muy cargado, donde los operadores a menudo buscan registros en millones de tablas, la velocidad de respuesta es crítica. Ahorrar tiempo en la operación más frecuente da como resultado docenas de aplicaciones procesadas adicionales, y esto es dinero real, con lo que cualquier negocio está contento. Al final, unos días o incluso semanas para estudiar e implementar la tecnología dará sus frutos con una mayor eficiencia del operador.
Todos los scripts mencionados en el artículo están disponibles en el repositorio
github.com/frrrost/mssql_fulltextSobre el autor
 Alexander Denisov
Alexander Denisov - Analista de rendimiento de la base de datos MS SQL Server. En los últimos 6 años, como parte del equipo de Softpoint, he estado ayudando a encontrar cuellos de botella en las solicitudes de otras personas y aprovechar al máximo las bases de datos de los clientes.