Mikhail Konovalov, Jefe del Departamento de Apoyo a Proyectos de Integración, Dirección de TI del ICDBuen día, Khabrovites!
Propósito
Un enfoque sistemático para gestionar descargas. Queremos decir cómo racionalizar y automatizar el llenado del repositorio con información y, al mismo tiempo, no confundirnos en los flujos de varias fuentes.
Preámbulo
Tarde o temprano, llega un momento en la base de datos corporativa de cualquier empresa cuando crece hasta el tamaño que el ojo del arquitecto deja de captar la incertidumbre (caos) del sistema y se convierte en una masa incontrolable de todo tipo de descargas de diversas fuentes.
Tiene suerte si su sistema se desarrolló desde cero (desde la primera tabla) y fue ejecutado por un arquitecto, un equipo de desarrolladores y analistas. Y además, este arquitecto dirigió de manera competente el modelo de depósito de datos. Pero la vida es multifacética, en la mayoría de los casos DWH crece espontáneamente, al principio había 30 mesas, luego agregamos un poco más según sea necesario, y luego nos gustó y comenzamos a agregar para cada oportunidad, y ahora tenemos más de cinco mil, sí capas, puesta en escena y vitrinas todavía aparecieron. Y toda esta "felicidad" cayó sobre nosotros como resultado de un proceso único pero muy conveniente, que es una relación causal dura:
- la empresa dice: "Necesitamos tal o cual información. Necesita un nuevo informe »
- el analista está mirando
- Desarrollador implementa
- el arquitecto coordina y contribuye al modelo de datos
Pero, como regla, el último punto en la realidad no existe. Y aparece solo en un momento determinado en grandes empresas que han crecido hasta su DWH, donde un arquitecto ordenado gestiona de manera competente la integridad de la información en la base de datos. Dichos repositorios representan una revisión de la estructura anterior, que se volvió a documentar y, a menudo, se reconstruyó, teniendo en cuenta la versión anterior (no documentada).
Entonces, un breve resumen:- no hay DWH que nació de inmediato y anteriormente no era una base de datos normal con un conjunto de tablas;
- todo lo que existe ahora, y es una estructura claramente algoritmizada y documentada, se obtuvo como resultado de una "experiencia amarga" de desarrollos anteriores.
Si usted es el feliz propietario del DWH "correcto", o si forma parte del equipo de este feliz propietario, este artículo "en teoría" puede parecerle interesante. Y si solo tiene que pasar por una revisión o (prohibirle) reconstruir, entonces este artículo puede simplificar enormemente su vida.
Dado que puede haber una cantidad inimaginable de fuentes de información, existe al menos el mismo número de flujos de descarga y sobrecarga de diferentes objetos, y a menudo mucho más, ya que cada objeto de la base de datos puede pasar por más de una transformación antes de que el usuario final pueda usar sus datos para construir Informes comerciales. Pero es para él, para los negocios, y no para su propio placer, que todo este ecosistema fue construido para "transfusiones de vaso en vaso".
Oracle se utiliza como la base de datos de nuestro almacenamiento. Una vez, en la etapa de creación, el núcleo central de nuestra base de datos consistía en un par de cientos de tablas. No pensamos en la puesta en escena y escaparates. Pero, como dicen, "todo fluye, todo cambia", ¡y ahora hemos crecido! El negocio dicta nuevos requisitos, y la integración con varias bases de datos MS SQL, SyBASE, Vertica, Access ya ha aparecido. Desde donde la información no fluye hacia nosotros, incluso aparecieron exóticos como el intercambio de XML y JSON con sistemas de terceros, y el archivo XLS como fuente de información es completamente anacrónico.
La vida nos hizo revisar y actualizar el modelo de datos, mantenerlo y mantenerlo. Aquí está una de las partes del núcleo principal:
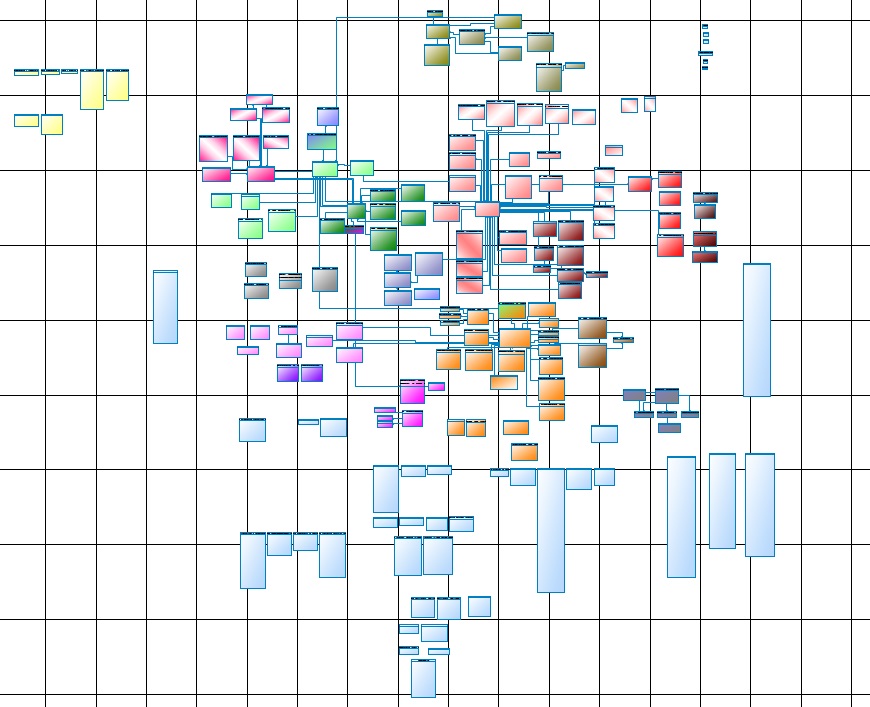 Fig. 1
Fig. 1Para quién es, pero para mí, es legible solo en un papel Whatman, y A0 será un poco pequeño, mejor que 4A0, en la pantalla no cede ante el ojo o la imaginación.
Ahora recuerde que este es solo el núcleo (Core Data Layer), o más bien su parte principal, el núcleo completo consta de varios subsistemas que no son muy inferiores al principal.
La capa de datos primaria y la
capa de Data Mart también se agregan a esto. Además, más, la capa primaria recibe su información de fuentes de datos, y esto, como se mencionó anteriormente, varias bases de datos y archivos. Por otro lado, a la capa de escaparates, el consumidor une varios sistemas de informes.
Al principio, cuando había pocas tablas de bases de datos y algoritmos de carga implementados en PL / SQL, no había dificultades particulares para comprender las actualizaciones de datos. Pero con el auge de DWH, una decisión estratégica fue comprar Informatica PowerCenter. Con toda la comodidad de esta herramienta, tanto en términos de confiabilidad de carga como de visualización del desarrollo, esta herramienta tiene varias desventajas. La siguiente figura muestra un modelo para la secuencia de inicio para cargar un DWH.
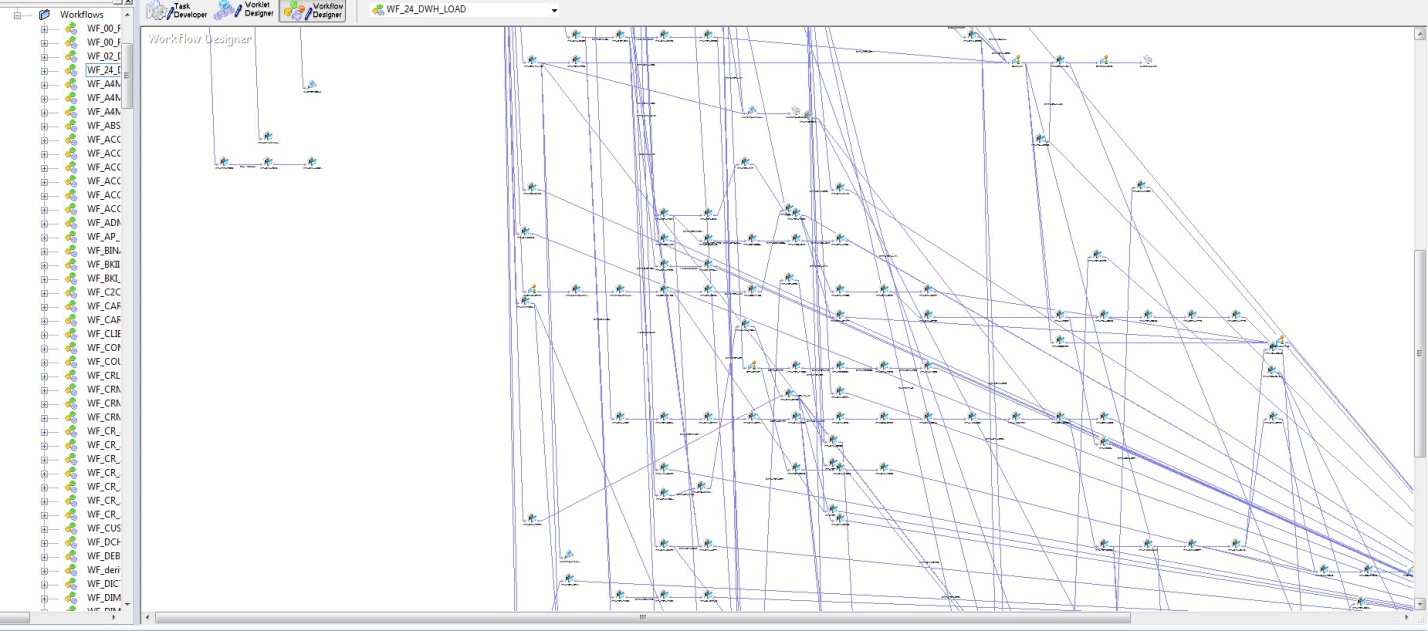 Fig. 2
Fig. 2El inconveniente más importante es la subjetividad, o más bien, solo el arquitecto puede garantizar que las publicaciones no se carguen antes de las facturas. Desafortunadamente, con el crecimiento de DWH, la entropía de la información también aumenta. Teniendo en cuenta el modelo de datos físicos (Fig. 1) y la lógica de cargar estos datos (Fig. 2), la construcción aún se obtiene.
¿Qué hacer y cómo dirigirlo? Naturalmente: tener un arquitecto brillante que sea capaz de comprender todas las conexiones de estas complejidades. Que supervisará todos los flujos, coordinará nuevos flujos y evitará que la tabla de contabilización se cargue antes que la tabla de cuentas. Por supuesto, todo esto está cosido en los algoritmos y regulado por los límites de las descargas, pero inicialmente solo el arquitecto puede entender y establecer las descargas en una secuencia estricta, y con tal ramificación la probabilidad de errores es muy alta.
Teoría
Ahora intentaré exponer las ideas principales del diccionario del modelo de datos, así como las tareas que resuelve.
Dado que los datos en el almacenamiento están en tablas, y las fuentes de datos son en parte tablas y en parte vistas, estas últimas son tablas. Luego sigue una idea simple: crear una estructura de dependencia
TABLE - TABLE . La forma
3NF es perfecta para esto.
En primer lugar, rellenando los datos de la entidad DWH, lo llamamos
(objetivo) , en el caso más general, puede representarse como
select de diferentes tablas. Ya sea que se trate de tablas de Oracle, SyBase, MSSQL, archivos xls o algo más, no es tan importante, todo esto lo llamamos sus fuentes
(fuente) . Es decir, tenemos una
fuente que fluye hacia el
objetivo .
En segundo lugar, cada entidad DWH tiene referencias entre sí.
En tercer lugar, existe una cronología de las descargas iniciales de varias entidades DWH.
Sigue siendo el caso para los pequeños, para implementar: ¿cómo? Parece que es muy simple, desde la base de su DWH, el arquitecto, cuando aparece la siguiente tabla de la entidad
(objetivo) , tiene que mirar y poner en el diccionario la entidad receptora y todas las entidades que sirven como fuentes. Además, en la segunda tabla del diccionario, especifique los enlaces entre las fuentes de estas entidades en select, así como todas las tablas subordinadas que son referencias vinculadas. A continuación, puede incrustar la carga de esta entidad en la cadena de descarga de almacenamiento. Solo se resuelven dos tablas, y se resuelve la posibilidad de tener en cuenta la secuencia de llenado de datos con el algoritmo en el algoritmo.
El modelo de datos del diccionario resolverá los siguientes problemas:
- Ver dependencias. Puede ver qué datos, de dónde se extraen. Esto es conveniente para los analistas que siempre están atormentados por preguntas: "dónde, qué miente y de dónde viene todo". Presente esto en la aplicación en forma de árbol, tanto de origen a destino , y viceversa: de destino a origen .
- Ruptura de bucles. Al incorporar la próxima carga en una secuencia compartida que ya funciona, sin tener un diccionario de modelo de datos, es muy posible cometer un error y asignar una hora de inicio para cargar el siguiente destino frente a uno de sus orígenes. Esto crea un bucle. Un diccionario de modelo de datos evitará esto fácilmente.
- Puede escribir un algoritmo para llenar el almacenamiento basado en el diccionario modelo. En este caso, no es necesario incrustar la próxima descarga en ningún lado, solo se refleja en el diccionario y el algoritmo determinará su lugar. Queda por hacer clic en el codiciado botón "Hacer TODO" . El gestor de arranque lanzará descargas tipo avalancha de todas las entidades de almacenamiento, desde simples (independientes) hasta complejas (dependientes).
Implementación
En teoría, todo es siempre simple y hermoso; en la práctica, las cosas son algo diferentes. Lo que está escrito en la sección anterior es una situación ideal cuando DWH se desarrolló desde cero, cuando un arquitecto estaba inseparablemente con él. Si no tiene suerte, ha superado todo esto con seguridad, no hay arquitecto, pero hay un conjunto gigantesco de tablas, entonces, de todos modos, hay una salida.
Ahora, de hecho, te diré cómo nos las arreglamos para ponernos al día, hacer una revisión y reconstruir lo suficientemente barato. Nuestro DWH comenzó a evolucionar con una decisión de liderazgo sobre una necesidad inminente (DWH). Como herramienta, se usó por primera vez PL / SQL. Un poco más tarde se cambió a Informatica. Naturalmente, la prioridad era el momento de la creación. El modelo de datos en PowerDesigner apareció algún tiempo después, cuando se formó claramente la confianza de que nadie podía imaginar claramente una imagen completa y clara de DWH. Vivimos durante algún tiempo con el modelo en la pared, cuando quedó claro que no podíamos hacer frente a la gestión de todo este sistema, comenzamos a buscar una solución que trataré de describir brevemente aquí.
El diccionario del modelo de datos en sí es tan simple como un palo. Pero llenarlo es un problema. N meses de minucioso, y lo más importante, una cuidadosa consideración de las tres partes anteriores:
- en qué fuentes (fuente) consiste cada entidad del repositorio (destino);
- cuáles son las relaciones entre los objetos de almacenamiento (referencias);
- La cronología del inicio de las descargas y el llenado del repositorio.
Afortunadamente, Oracle e Informatica nos ayudaron, y resultó ser muy exitoso que el repositorio de Informatica esté en la base de datos Oracle. Tomando como base que una sesión de Informatica es el átomo de carga de una entidad DWH, cavando un poco en el repositorio, encontramos todo el origen y el destino. Es decir, en el marco de una sesión, para todo su objetivo (como regla, es uno), todas sus fuentes son fuentes. Por lo tanto, podemos completar la primera condición del problema. Pero no se apresure a alegrarse, la fuente se puede presentar en forma de una selección muy inteligente, por lo que tuvo que escribir un analizador que extraiga todas las tablas especificadas en select; no fue del todo difícil. Pero esto no es todo, estas tablas pueden ser representaciones. Usando DBA_VIEWS (o a través de DBA_DEPENDENCIES) este problema también se resolvió. Sacamos la segunda condición de esta trilogía del modelo de datos (Fig. 1) y DBA_CONSTRAINTS. También obtuvimos la tercera condición del repositorio de Informatica basado en (Fig. 2).
¿Qué salió de todo esto?- En primer lugar, desenredamos todos los bucles que logramos enrollar en la evolución de nuestro DWH.
- En segundo lugar, obtuvimos un árbol maravilloso para los analistas:

Fig. 3 - En tercer lugar, nuestro supercargador, presentado en la fig. 2 se convirtió en elegante (lo siento, colegas, pero el desenfoque de la imagen es intencional, ya que se trata de datos que funcionan):
Fig. 4 4
Es posible que tenga muchas más formas de aplicar el diccionario del modelo de datos.
Gracias a todos!