pprof es la principal herramienta de creación de perfiles en Go. El generador de perfiles está incluido en la biblioteca estándar Go y se ha escrito mucho sobre él a lo largo de los años. Para conectar pprof a una aplicación existente solo necesita agregar una línea de código:
import _ “net/http/pprof”
En el servidor HTTP predeterminado - net/http.DefaultServeMux - los controladores que envían resultados de generación de perfiles se registrarán a lo largo de la ruta /debug/pprof/ .
curl -o cpu-profile.pb.gz http://<server-addr>/debug/pprof/profile
(para más detalles ver https://godoc.org/net/http/pprof )
Pero por experiencia, no siempre es tan simple y, en la práctica, usar pprof en la batalla, existen dificultades.
Para empezar, no queremos que los controladores del generador de perfiles permanezcan en Internet. La creación de perfiles es barata, en términos de gastos generales, pero no gratuita, y el perfil en sí contiene información sobre la estructura interna de la aplicación, que a menudo no es aconsejable abrir a personas externas. Debe asegurarse de que la ruta /debug no sea accesible para usuarios no autorizados. El acceso se puede limitar en el lado del servidor proxy o el servidor pprof se puede mover a un puerto separado, cuyo acceso estará abierto solo a través del host privilegiado.
Pero, ¿qué sucede si la aplicación no involucra el acceso HTTP en absoluto? Por ejemplo, ¿es un procesador de cola fuera de línea?
Dependiendo del estado de la infraestructura en la empresa, un servidor HTTP "repentino" dentro del proceso de solicitud puede generar preguntas del departamento de operaciones;) El servidor limita adicionalmente las posibilidades de escala horizontal, porque no funcionará solo para ejecutar varias instancias de la aplicación en el mismo host: los procesos entrarán en conflicto al intentar abrir el mismo puerto TCP para el servidor pprof.
Es "simple" resolverlo aislando cada proceso de aplicación en el contenedor (o ejecutando el servidor pprof en un puerto único o socket UNIX). Ya no sorprenderá a nadie con un servicio horizontalmente escalado en cientos de instancias, "distribuido" en varios centros de datos. En una infraestructura muy dinámica, los contenedores con la aplicación pueden aparecer y desaparecer periódicamente. Y aún necesitamos contactarnos de alguna manera con el perfilador. Y esto significa que, independientemente del método de escalado seleccionado, se necesitan mecanismos de búsqueda para una instancia de aplicación específica y el puerto del servidor pprof correspondiente.
Dependiendo de las características de la empresa, la disponibilidad misma de la capacidad de acceder a algo que no está relacionado con la actividad principal de producción del servicio puede generar preguntas por parte del departamento de seguridad;) Trabajé en una empresa donde, por razones objetivas, el acceso a cualquier cosa está de lado. La producción se realizó exclusivamente en el departamento de operaciones. La única forma de ejecutar el generador de perfiles en una aplicación en ejecución era abrir una tarea en el rastreador de errores de operación, con una descripción de qué comando curl, en qué DC, en qué servidor desea ejecutar, qué resultado esperar y qué hacer con él.
O imagine una situación: una mañana de trabajo. Abrió Slack y descubrió que por la noche, en uno de los procesos del servicio de producción, "algo salió mal", "en algún lugar, algo" se apagó "," la memoria comenzó a fluir "," los gráficos de la CPU se arrastraron " la aplicación comenzó a entrar en pánico. Los equipos operativos de servicio (o OOM Killer) no profundizaron y simplemente reiniciaron la aplicación o revertieron la última versión del día anterior.
Después del hecho, no es fácil entender tales situaciones. Es genial si el problema puede reproducirse en un entorno de prueba (o en una parte aislada de la producción a la que tiene acceso). Puede recopilar los datos necesarios con todas las herramientas disponibles y luego averiguar qué componente es el problema.
Pero si no hay una forma obvia de reproducir el problema, ¿solo nos quedan los registros y las métricas de ayer? En tales situaciones, siempre es una lástima que no pueda retroceder el tiempo hasta el momento en que el problema era visible en la producción y recopilar rápidamente todos los perfiles necesarios, de modo que más tarde, en un modo silencioso, realice el análisis.
Pero si pprof es relativamente barato, ¿por qué no recopilar datos de perfiles automáticamente, en algunos intervalos, y almacenarlos en un lugar separado de la producción, donde puede dar acceso a todos los interesados?
En 2010, Google publicó el documento Perfiles de Google: Una Infraestructura de Perfiles Continuos para Centros de Datos , que describe un enfoque para el perfil continuo de los sistemas de la compañía. Y después de algunos años, la compañía lanzó un servicio de perfilado continuo, Stackdriver Profiler , disponible para todos.
El principio de operación es simple: en lugar de un servidor pprof, un agente de stackdriver está conectado a la aplicación, que, utilizando la API de runtime/pprof directamente, recopila periódicamente diferentes tipos de perfiles de la aplicación y envía perfiles a la nube. Todo lo que el desarrollador necesita, usando el panel de control de Stackdriver, selecciona la instancia de aplicación deseada en la AZ deseada y puedes, después del hecho, analizar la aplicación en cualquier momento en el pasado.
Otros proveedores de SaaS ofrecen una funcionalidad similar. Pero, las reglas de seguridad de su empresa pueden prohibir la exportación de datos más allá de su propia infraestructura. Y no he visto los servicios que le permiten implementar un sistema continuo de creación de perfiles en sus propios servidores.
Todas las dificultades e ideas descritas anteriormente están lejos de ser nuevas y específicas, no solo para Go. Con ellos, de una forma u otra, los desarrolladores se enfrentan en casi todas las empresas donde trabajé.
En algún momento, tenía curiosidad por tratar de construir un análogo del Stackdriver Profiler para un Go-service arbitrario que pudiera resolver los problemas descritos. Como proyecto de hobby, en mi tiempo libre, trabajo en profefe ( https://github.com/profefe/profefe ), un servicio abierto de perfiles continuos. El proyecto aún se encuentra en la etapa de experimentos y discusiones periódicas, pero ya es adecuado para las pruebas.
Las tareas que configuré para el proyecto:
- El servicio se desplegará en la infraestructura interna de la compañía.
- El servicio se utilizará como herramienta interna de la empresa. Puede confiar en los proveedores y consumidores de datos: en las primeras etapas, puede omitir la autorización de solicitudes de escritura / lectura y no tratar de protegerse de antemano del uso malicioso.
- El servicio no debe tener expectativas especiales de la infraestructura de la compañía: todo puede vivir en la nube o en sus propios DC; las aplicaciones perfiladas pueden ejecutarse dentro de contenedores ("todo está controlado por los Kubernetes") o pueden ejecutarse en metal desnudo.
- El servicio debería ser fácil de operar (parece que hasta cierto punto, Prometeo es un buen ejemplo).
- Debe entenderse que la arquitectura seleccionada puede no satisfacer las condiciones en las que se utilizará el servicio. Lo más probable es que necesite la capacidad de expandir / reemplazar componentes del sistema para escalar "en el acto".
- De acuerdo con (4), debemos intentar minimizar las dependencias externas requeridas. Por ejemplo, un servicio debe buscar de alguna manera instancias de aplicaciones perfiladas, pero, al menos en las etapas iniciales, quiero prescindir de un descubrimiento de servicio explícito.
- El servicio almacenará y catalogará los perfiles de las aplicaciones Go. Esperamos que un archivo pprof ocupe entre 100 KB y 2 MB (los perfiles de almacenamiento dinámico suelen ser mucho más grandes que los perfiles de CPU ). Desde una instancia con perfil, no tiene sentido enviar más de N perfiles por minuto (un agente de Stackdriver envía, en promedio, 2 perfiles por minuto). Vale la pena calcular de inmediato que una sola aplicación puede tener desde varios hasta varios cientos de instancias.
- A través del servicio, los usuarios buscarán diferentes tipos de perfiles (cpu, heap, mutex, etc.) de la aplicación o una instancia específica de la aplicación durante un cierto período de tiempo.
- Desde el servicio, el usuario solicitará un perfil pprof separado de los resultados de búsqueda.
Ahora profefe consta de dos componentes:
profefe-collector es un recopilador de servicios con una API RESTful simple.
La tarea del recopilador es obtener el archivo pprof y algunos metadatos y guardarlos en el almacenamiento permanente. La API también permite a los clientes buscar perfiles por metadatos en una ventana de tiempo determinada o leer un perfil específico (o un grupo de perfiles del mismo tipo) de la tienda.
agente: una biblioteca opcional que debe conectarse a la aplicación en lugar del servidor pprof. Dentro de la aplicación, en una rutina diferente, el agente inicia periódicamente el proceso de creación de perfiles (usando runtime/pprof ) y envía los perfiles de pprof recibidos, junto con los metadatos al recopilador.
Los metadatos son un conjunto de valores clave arbitrario que describe una aplicación o su instancia individual. Por ejemplo: nombre del servicio, versión, centro de datos y host donde se ejecuta la aplicación.

Diagrama de interacción del componente Profefe
Mencioné anteriormente que el agente es un componente opcional. Si no es posible conectarlo a una aplicación existente, pero el servidor net/http/pprof ya está conectado en la aplicación, los perfiles se pueden eliminar utilizando herramientas externas y enviar archivos pprof al recopilador a través de la API HTTP.
Por ejemplo, en los hosts, puede configurar una tarea cron que recopilará periódicamente perfiles de instancias en ejecución y las enviará a profefe para su almacenamiento;)
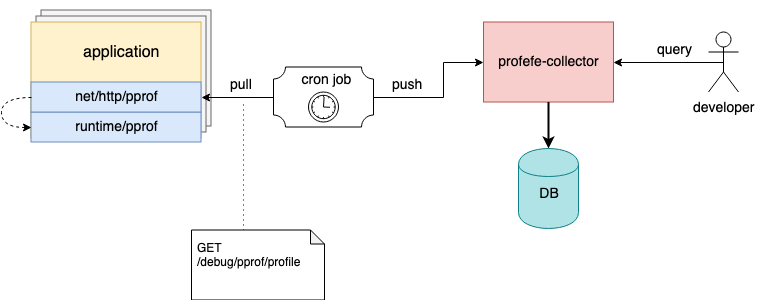
La tarea de Cron recopila y envía perfiles de aplicaciones al colector profefe
Puede leer más sobre profefe API en la documentación en GitHub .
Planes
Hasta ahora, la única forma de interactuar con el profefe collector es la API HTTP. Una de las tareas para el futuro es ensamblar un servicio de interfaz de usuario separado a través del cual será posible mostrar visualmente los datos almacenados: resultados de búsqueda, una descripción general del rendimiento del clúster, etc.
Recopilar y almacenar datos de perfiles no es malo, pero "sin aplicación, los datos son inútiles". El equipo donde trabajo tiene un conjunto de herramientas experimentales para recopilar estadísticas básicas para varios perfiles pprof del servicio. Esto ayuda mucho a analizar las consecuencias de actualizar las dependencias clave de la aplicación o los resultados de una gran refactorización ( desafortunadamente, el rendimiento en la producción no siempre cumple con las expectativas basadas en el lanzamiento de puntos de referencia aislados y la creación de perfiles en un entorno de prueba ). Quiero agregar una funcionalidad similar para comparar y analizar los perfiles almacenados en la API profefe.
A pesar de que el enfoque principal de profefe es el perfil continuo de los servicios de Go, el formato de perfil pprof no está en absoluto vinculado a Go. Para Java, JavaScript, Python, etc., existen bibliotecas que le permiten obtener datos de perfil en este formato. Quizás profefe puede convertirse en un servicio útil para aplicaciones escritas en otros idiomas.
Entre otras cosas, el repositorio tiene una serie de preguntas abiertas descritas en el rastreador de proyectos en GitHub .
Conclusión
En los últimos años, una idea popular se ha arraigado entre los desarrolladores: para lograr la " observabilidad " de un servicio, se necesitan tres componentes: métricas, registros y " tres pilares de observabilidad ". Me parece que la visibilidad es la capacidad de responder efectivamente preguntas sobre el estado del sistema y sus componentes. Las métricas y el seguimiento permiten comprender el sistema en su conjunto. Los registros cubren las partes del sistema descritas deliberadamente. La creación de perfiles es otra señal para lograr visibilidad, lo que le permite comprender el sistema a nivel micro. Los perfiles continuos durante un período de tiempo también ayudan a comprender cómo los componentes individuales y el entorno influyeron y afectaron la operatividad y la productividad de todo el sistema.