
Teníamos 4 cuentas de Amazon, 9 VPC y 30 entornos de desarrollo, etapas y regresiones más potentes, en total más de 1000 instancias EC2 de todos los colores y sombras. Desde que comencé a recopilar soluciones en la nube para empresas, necesito ir a mi hobby hasta el final y pensar en cómo automatizar todo esto.
Hola Mi nombre es Kirill Kazarin, trabajo como ingeniero en DINS. Estamos desarrollando soluciones de comunicaciones empresariales basadas en la nube. En nuestro trabajo, utilizamos activamente Terraform, con el que gestionamos de manera flexible nuestra infraestructura. Compartiré mi experiencia con esta solución.
El artículo es largo, ¡así que abastecerse de té de
palomitas de
maíz y listo!
Y un matiz más: el artículo fue escrito sobre la base de la versión 0.11, en la versión 0.12 mucho ha cambiado, pero las principales prácticas y consejos siguen siendo relevantes. ¡El tema de la migración de 0.11 a 0.12 merece un artículo separado!
¿Qué es Terraform?
Terraform es una herramienta popular de Hashicorp que apareció en 2014.
Esta utilidad le permite administrar su infraestructura de nube en la
infraestructura como un paradigma de
código en un lenguaje declarativo muy amigable y fácil de leer. Su aplicación le proporciona un tipo unificado de recursos y aplicación de prácticas de código para la gestión de la infraestructura, desarrolladas durante mucho tiempo por la comunidad de desarrolladores. Terraform es compatible con todas las plataformas modernas en la nube, le permite cambiar de manera segura y previsible la infraestructura.
Cuando se inicia, Terraform lee el código y, utilizando los complementos proporcionados por los proveedores de servicios en la nube, lleva su infraestructura al estado descrito haciendo las llamadas API necesarias.
Nuestro proyecto está ubicado completamente en Amazon, implementado sobre la base de los servicios de AWS, y por lo tanto escribo sobre el uso de Terraform en esta línea. Por separado, observo que se puede usar no solo para Amazon. Le permite administrar todo lo que tiene una API.
Además, gestionamos la configuración de VPC, las políticas de IAM y los roles. Gestionamos tablas de enrutamiento, certificados, ACL de red. Gestionamos la configuración de nuestro firewall de aplicaciones web, S3-bucket, colas SQS, todo lo que nuestro servicio puede usar en Amazon. Todavía no he visto características con Amazon que Terraform no podría describir en términos de infraestructura.
Resulta una infraestructura bastante grande, con sus manos es fácil de soportar. Pero con Terraform es conveniente y simple.
De qué está hecho Terraform
Los proveedores son complementos para trabajar con la API de un servicio. Los conté
más de 100 . Entre ellos se encuentran proveedores para Amazon, Google, DigitalOcean, VMware Vsphere, Docker. ¡Incluso encontré un proveedor en esta lista oficial que le permite
administrar las reglas para Cisco ASA !
Entre otras cosas, puedes controlar:
Y estos son solo proveedores oficiales, hay aún más proveedores no oficiales. Durante los experimentos, me encontré en GitHub con un tercero, no incluido en el proveedor de la lista oficial, que me
permitió trabajar con DNS de GoDaddy , así como con
recursos de Proxmox .
Dentro de un proyecto de Terraform, puede usar diferentes proveedores y, en consecuencia, los recursos de diferentes proveedores de servicios o tecnologías. Por ejemplo, puede administrar su infraestructura en AWS, con DNS externo de GoDaddy. Y mañana, su empresa compró una startup que estaba alojada en DO o Azure. Y si bien decide migrar esto a AWS o no, ¡también puede admitir esto con la misma herramienta!
Recursos. Estas son entidades de nube que puede crear usando Terraform. Su lista, sintaxis y propiedades dependen del proveedor utilizado, de hecho, de la nube utilizada. O no solo nubes.
Módulos Estas son las entidades con las que Terraform le permite modelar su configuración. Por lo tanto, las plantillas le permiten hacer su código más pequeño, le permiten reutilizarlo. Bueno, ayudan a trabajar cómodamente con él.
Por qué elegimos Terraform
Para nosotros, identificamos 5 razones principales. Quizás desde su punto de vista, no todos parecerán significativos:
- Terraform es una utilidad de soporte de múltiples nubes de
Cloud Agnostic (gracias por el valioso comentario en los comentarios) . Cuando seleccionamos esta herramienta, pensamos: - ¿Qué sucederá si la administración nos llega mañana o dentro de una semana y dice: " Chicos, y pensamos? No solo desplieguemos en Amazon. Tenemos algún tipo de proyecto, donde necesitaremos obtener la infraestructura en Google Cloud. O en Azure, bueno, nunca se sabe ". Decidimos que nos gustaría tener una herramienta que no esté rígidamente vinculada a ningún servicio en la nube. - Código abierto Terraform es una solución de código abierto . El repositorio del proyecto tiene una calificación de más de 16 mil estrellas, esta es una buena confirmación de la reputación del proyecto.
Hemos encontrado más de una o dos veces el hecho de que en algunas versiones hay errores o un comportamiento no entendible. Tener un repositorio abierto le permite asegurarse de que esto sea realmente un error, y podemos resolver el problema simplemente actualizando el motor o la versión del complemento. O que esto es un error, pero "Chicos, esperen, literalmente dos días después se lanzará una nueva versión y la arreglaremos". O: "Sí, esto es algo incomprensible, extraño, lo solucionan, pero hay una solución". Es muy conveniente. - Control . Terraform como una utilidad está completamente bajo su control. Se puede instalar en una computadora portátil, en un servidor, se puede integrar fácilmente en su tubería, lo que se puede hacer sobre la base de cualquier herramienta. Por ejemplo, lo usamos en GitLab CI.
- Comprobación del estado de la infraestructura . Terraform puede y hace un buen control del estado de su infraestructura.
Suponga que comenzó a usar Terraform en su equipo. Cree una descripción de algún recurso en Amazon, por ejemplo, Grupo de seguridad, aplíquelo: está creado para usted, todo está bien. Y aquí, ¡bam! Su colega, que regresó ayer de vacaciones y aún no sabe que ha organizado todo tan bien aquí, o incluso un colega de otro departamento entra y cambia la configuración de este grupo de seguridad a mano.
Y sin reunirse con él, sin hablar, o sin asumir más adelante cierto problema, nunca lo sabrá en una situación normal. Pero, si usa Terraform, incluso ejecutar un plan inactivo en este recurso le mostrará que hay cambios en el entorno de trabajo.
Cuando Terraform mira su código, simultáneamente llama a la API del proveedor de la nube, recibe el estado de los objetos y compara: "Y ahora hay lo mismo que hice antes, ¿qué recuerdo?" Luego lo compara con el código, mira qué más necesita ser cambiado. Y, por ejemplo, si todo es igual en su historia, en su memoria y en su código, pero hay cambios allí, él lo mostrará y ofrecerá revertirlo. En mi opinión, también es una muy buena propiedad. Por lo tanto, este es otro paso, personalmente para nosotros, para garantizar que tenemos una infraestructura inmutable. - Otra característica muy importante son los módulos que mencioné, y cuenta. Hablaré de esto un poco más tarde. Cuando voy a comparar con las herramientas.
Y también una guinda al pastel: Terraform tiene una
lista bastante grande de funciones integradas . Estas funciones, a pesar del lenguaje declarativo, nos permiten implementar algunas, por no decir programáticas, sino lógicas.
Por ejemplo, algunos cálculos automáticos, líneas divididas, conversión a mayúsculas y minúsculas, eliminación de caracteres de esta línea. Lo estamos usando bastante activamente. Hacen la vida mucho más fácil, especialmente cuando escribes un módulo que luego se reutilizará en diferentes entornos.
Terraform vs CloudFormation
La red a menudo compara Terraform con CloudFormation. También hicimos esta pregunta al elegirla. Y aquí está el resultado de nuestra comparación.
Cómo comenzar con Terraform
En términos generales, comenzar es bastante simple. Aquí están los primeros pasos brevemente:
- En primer lugar, cree un repositorio Git e inmediatamente comience a almacenar todos sus cambios, experimentos y todo.
- Lea la guía de inicio . Es pequeño, simple, bastante detallado y describe bien cómo comenzar con esta utilidad.
- Escriba alguna demostración, código de trabajo. Incluso puedes copiar algún tipo de ejemplo para jugar más tarde.
Nuestra práctica con Terraform
Código fuente
Comenzó su primer proyecto y guardó todo en un gran archivo main.tf.
Aquí hay un ejemplo típico (honestamente tomé el primero que obtuve de GitHub).
No pasa nada, pero el tamaño de la base del código tiende a crecer con el tiempo. Las dependencias entre los recursos también están creciendo. Después de un tiempo, el archivo se vuelve enorme, complejo, ilegible, mal mantenido, y un cambio descuidado en un lugar puede causar problemas.
Lo primero que recomiendo es resaltar el llamado repositorio central, o estado central de su proyecto, su entorno. Tan pronto como comience a crear una infraestructura usando Terraform, o importándola, inmediatamente se dará cuenta de que tiene algunas entidades que, una vez implementadas, configuradas, rara vez cambian. Por ejemplo, estas son configuraciones de VPC, o VPC en sí. Estas son redes, grupos de seguridad básicos y generales, como el acceso SSH: puede compilar una lista bastante grande.
No tiene sentido mantener esto en el mismo repositorio que los servicios que cambia con frecuencia. Selecciónelos en un repositorio separado y conéctelos a través de una función Terraform, como el estado remoto.
- Está reduciendo la base de código de esa parte del proyecto con la que a menudo trabaja directamente.
- En lugar de un gran archivo tfstate que contiene una descripción del estado de su infraestructura, dos archivos más pequeños y, en un momento determinado, está trabajando con uno de ellos.
Cual es el truco Cuando Terraform hace un plan, es decir, calcula, calcula lo que debería cambiar, aplica: relata completamente este estado, verifica el código, verifica el estado en AWS. Cuanto más grande sea su estado, más tiempo llevará el plan.
Llegamos a esta práctica cuando nos llevó 20 minutos elaborar un plan para todo el entorno en producción. Debido al hecho de que incluimos en un núcleo separado todo lo que no estamos sujetos a cambios frecuentes, redujimos el tiempo para construir un plan a la mitad. Tenemos una idea de cómo puede reducirse aún más, desglosándose no solo en núcleo y no núcleo, sino también por subsistemas, porque los tenemos conectados y generalmente cambiamos juntos. Por lo tanto, decimos que convertiremos 10 minutos en 3. Pero todavía estamos en el proceso de implementar tal solución.
Menos código - más fácil de leer
El código pequeño es más fácil de entender y más conveniente para trabajar. Si tiene un equipo grande y tiene personas con diferentes niveles de experiencia, saque lo que rara vez cambia, pero a nivel mundial, en un nabo separado y bríndele un acceso más estrecho.
Supongamos que tiene juniors en su equipo y no les da acceso al repositorio global que describe la configuración de VPC, de esta manera se asegura contra errores. Si un ingeniero comete un error al escribir la instancia, y algo se crea mal, no da miedo. Y si comete un error en las opciones que están instaladas en todas las máquinas, se rompe o hace algo con la configuración de las subredes, con el enrutamiento, esto es mucho más doloroso.
La selección del repositorio principal se realiza en varios pasos.
Etapa 1 Crea un repositorio separado. Almacene todo el código en él, por separado, y describa aquellas entidades que deberían reutilizarse en un repositorio de terceros utilizando esta salida. Supongamos que creamos un recurso de subred de AWS en el que describimos dónde se encuentra, qué zona de disponibilidad, espacio de direcciones.
resource "aws_subnet" "lab_pub1a" { vpc_id = "${aws_vpc.lab.id}" cidr_block = "10.10.10.0/24" Availability_zone = "us-east-1a" ... } output "sn_lab_pub1a-id" { value = "${aws_subnet.lab_pub1a.id}" }
Y luego decimos que enviamos la identificación de este objeto a la salida. Puede hacer la salida para cada parámetro que necesite.
¿Cuál es el truco aquí? Cuando describe un valor, Terraform lo guarda por separado en tfstate core. Y cuando recurras a él, no necesitará sincronizar, contar: podrá darte este asunto inmediatamente desde este estado. Además, en el repositorio, que no es núcleo, usted describe dicha conexión con el estado remoto: tiene un estado remoto tal y tal, se encuentra en el cubo S3 tal y tal, tal y tal clave y región.
Etapa 2 En un proyecto no básico, creamos un enlace al estado del proyecto principal, para que podamos referirnos a los parámetros exportados a través de la salida.
data "terraform_remote_state" "lab_core" { backend = "s3" config { bucket = "lab-core-terraform-state" key = "terraform.tfstate" region = "us-east-1" } }
Etapa 3 Empezando Cuando necesito implementar una nueva interfaz de red para una instancia en una subred específica, digo: aquí está el estado remoto de datos, encuentre el nombre de este estado en él, encuentre este parámetro en él, que, de hecho, coincide con este nombre.
resource "aws_network_interface" "fwl01" { ... subnet_id = "${data.terraform_remote_state.lab_core.sn_lab_pub1a-id}" }
Y cuando construyo un plan de cambios en mi repositorio no central, este valor para Terraform se convertirá en una constante para él. Si desea cambiarlo, debe hacerlo en el repositorio de este, por supuesto, núcleo. Pero como esto rara vez cambia, no te molesta mucho.
Módulos
Permítame recordarle que un módulo es una configuración autónoma que consta de uno o más recursos relacionados. Se gestiona como un grupo:
Un módulo es algo extremadamente conveniente debido al hecho de que rara vez se crea un recurso así, en el vacío, generalmente está lógicamente conectado con algo.
module "AAA" { source = "..." count = "3" count_offset = "0" host_name_prefix = "XXX-YYY-AAA" ami_id = "${data.terraform_remote_state.lab_core.ami-base-ami_XXXX-id}" subnet_ids = ["${data.terraform_remote_state.lab_core.sn_lab_pub1a-id}", "${data.terraform_remote_state.lab_core.sn_lab_pub1b-id}"] instance_type = "t2.large" sgs_ids = [ "${data.terraform_remote_state.lab_core.sg_ssh_lab-id}", "${aws_security_group.XXX_lab.id}" ] boot_device = {volume_size = "50" volume_type = "gp2"} root_device = {device_name = "/dev/sdb" volume_size = "50" volume_type = "gp2" encrypted = "true"} tags = "${var.gas_tags}" }
Por ejemplo: cuando implementamos una nueva instancia de EC2, creamos una interfaz de red y datos adjuntos, a menudo creamos una dirección IP elástica, creamos el registro de la ruta 53 y algo más. Es decir, obtenemos al menos 4 entidades.
Cada vez, describirlos en cuatro partes de código es inconveniente. Además, son bastante típicos. Suplica: haga una plantilla y luego simplemente refiérase a esta plantilla, pasándole parámetros: algún nombre, en qué cuadrícula para empujar, qué grupo de seguridad colgar en ella. Es muy conveniente.
Terraform tiene una función de conteo, que le permite reducir aún más su estado. Puede describir un gran paquete de instancias con una sola pieza de código. Digamos que necesito implementar 20 máquinas del mismo tipo. No escribiré 20 piezas de código incluso desde una plantilla, escribiré 1 pieza de código, indicaré Count y el número que contiene, cuánto necesito hacer.
Por ejemplo, hay algunos módulos que hacen referencia a una plantilla. Solo paso parámetros específicos: ID de subred; AMI para desplegar con; tipo de instancia; configuración de grupo de seguridad; cualquier otra cosa e indique cuántas de estas cosas me van a hacer. ¡Genial, los tomó y les dio la vuelta!
Mañana, los desarrolladores acuden a mí y me dicen: "Escucha, queremos experimentar con la carga, por favor danos dos más". Lo que necesito hacer: cambio un dígito a 5. La cantidad de código permanece exactamente igual.
Convencionalmente, los módulos se pueden dividir en dos tipos: recursos e infraestructura. Desde el punto de vista del código, no hay diferencia, sino más bien los conceptos de nivel superior que el propio operador introduce.
Los módulos de recursos proporcionan una colección de recursos estandarizada y parametrizada, relacionada lógicamente. El ejemplo anterior es un módulo de recursos típico. Cómo trabajar con ellos:
- Indicamos la ruta al módulo, la fuente de su configuración, a través de la directiva Source.
- Indicamos la versión, sí, y la operación según el principio de "último y mejor" no es la mejor opción aquí. ¿No incluye la última versión de la biblioteca cada vez en su proyecto? Pero más sobre eso más tarde.
- Le pasamos argumentos.
Estamos conectados a la versión del módulo, y solo tomamos el último: la infraestructura debe ser versionada (los recursos no pueden ser versionados, pero el código sí). Se puede crear un recurso eliminado o recreado. Eso es todo! También debemos saber claramente qué versión hemos creado para cada pieza de infraestructura.
Los módulos de infraestructura son bastante simples. Consisten en recursos e incluyen estándares de la compañía (por ejemplo, etiquetas, listas de valores estándar, valores predeterminados aceptados, etc.).
En cuanto a nuestro proyecto y nuestra experiencia, hemos pasado mucho tiempo y firmemente al uso de módulos de recursos para todo lo que es posible con un proceso de revisión y versiones muy estricto. Y ahora estamos introduciendo activamente la práctica de módulos de infraestructura a nivel de laboratorio y puesta en escena.
Recomendaciones para usar módulos
- Si no puede escribir, pero usa los ya hechos, no escriba. Especialmente si eres nuevo en esto. Confíe en los módulos ya preparados, o al menos vea cómo se lo hicieron. Sin embargo, si aún necesita escribir la suya, no use la llamada a los proveedores internamente y tenga cuidado con los proveedores de servicios.
- Compruebe que Terraform Registry no contenga un módulo de recursos listo para usar.
- Si está escribiendo su módulo, oculte los detalles debajo del capó. El usuario final no tiene que preocuparse por qué y cómo implementarlo internamente.
- Realice los parámetros de entrada y los valores de salida de su módulo. Y es mejor si son archivos separados. Muy conveniente
- Si escribe sus módulos, guárdelos en el repositorio y la versión. Mejor un repositorio separado para el módulo.
- No utilice módulos locales, no están versionados ni reutilizados.
- Evite usar descripciones de proveedores en el módulo, porque las credenciales de conexión se pueden configurar y aplicar de manera diferente para diferentes personas. Alguien usa variables de entorno para esto, y alguien implica almacenar sus claves y secretos en archivos con rutas de prescripción para ellos. Esto debe indicarse en un nivel superior.
- Use el aprovisionador local con cuidado. Se ejecuta localmente, en la máquina en la que se ejecuta Terraform, pero el entorno de ejecución para diferentes usuarios puede ser diferente. Hasta que lo incruste en CI, puede encontrar varios artefactos: por ejemplo, ejecutivo local y ejecutando ansible. Y alguien tiene una distribución diferente, otro shell, una versión diferente de ansible, o incluso Windows.
Señales de un buen módulo (aquí hay un
poco más detallado ):
- Los buenos módulos tienen documentación y ejemplos. Si cada uno está diseñado como un repositorio separado, esto es más fácil de hacer.
- No tienen configuraciones codificadas (por ejemplo, región de AWS).
- Utilice valores predeterminados razonables, diseñados como valores predeterminados. Por ejemplo, el módulo para la instancia EC2 por defecto no creará una máquina virtual del tipo m5d.24xlarge para usted, utiliza uno de los tipos mínimos t2 o t3 para esto.
- El código es "limpio": estructurado, provisto de comentarios, no confundido innecesariamente, diseñado con el mismo estilo.
- Es altamente deseable que esté equipado con pruebas, aunque es difícil. Desafortunadamente, aún no hemos llegado a esto.
Etiquetado
Las etiquetas son importantes.
Etiquetar es facturar. AWS tiene herramientas que le permiten ver cuánto dinero gasta en su infraestructura. Y nuestra gerencia realmente quería tener una herramienta en la que pudieran verla de manera determinista. Por ejemplo, cuánto dinero consumen tales y tales componentes, o tal y tal subsistema, tal y tal equipo, tal y tal entorno
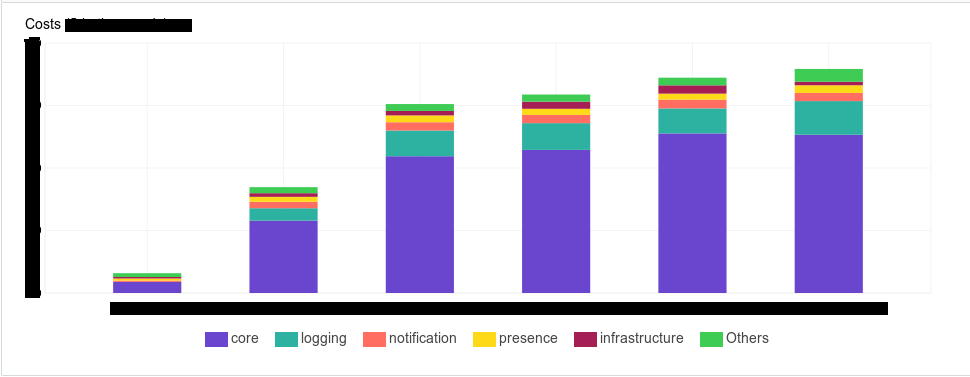
El etiquetado es la documentación de su sistema. Con ella, simplificas tu búsqueda. Incluso solo en la consola de AWS, donde estas etiquetas se muestran claramente en su pantalla, le resulta más fácil comprender a qué se refiere este o aquel tipo de instancia. Si vienen nuevos colegas, es más fácil para usted explicar esto mostrando: "Mira, aquí está". Comenzamos a crear etiquetas de la siguiente manera: creamos una matriz de etiquetas para cada tipo de recurso.
Un ejemplo:
variable "XXX_tags" { description = "The set of XXX tags." type = "map" default = { "TerminationDate" = "03.23.2018", "Environment" = "env_name_here", "Department" = "dev", "Subsystem" = "subsystem_name", "Component" = "XXX", "Type" = "application", "Team" = "team_name" } }
Dio la casualidad de que en nuestra empresa más de uno de nuestros equipos usa AWS, y hay una lista de etiquetas requeridas.
- Equipo: qué equipo usa cuántos recursos.
- Departamento: similar a un departamento.
- Entorno: los recursos funcionan en "entornos", pero usted, por ejemplo, puede reemplazarlo con un proyecto o algo así.
- Subsistema: el subsistema al que pertenece el componente. Los componentes pueden pertenecer a un subsistema. Por ejemplo, queremos ver cuánto tenemos que este subsistema y sus entidades comenzaron a consumir. De repente, por ejemplo, para el mes anterior, ha crecido significativamente. Necesitamos ir a los desarrolladores y decirles: “Chicos, es costoso. El presupuesto ya está cerca el uno del otro, optimicemos la lógica de alguna manera ".
- Tipo: tipo de componente: equilibrador, almacenamiento, aplicación o base de datos.
- Componente: el componente en sí, su nombre en notación interna.
- Fecha de finalización: hora en que debe eliminarse, en formato de fecha. Si no se espera su eliminación, configúrelo como "Permanente". Lo presentamos porque en entornos de desarrollo, e incluso en algunos entornos de etapa, tenemos una etapa de prueba de estrés que aumenta durante las sesiones de estrés, es decir, no mantenemos estas máquinas regularmente. Indicamos la fecha en que el recurso debe ser destruido. Además de esto, puede ajustar la automatización basada en lambda, algunos scripts externos que funcionan a través de la interfaz de línea de comandos de AWS, que destruirá estos recursos automáticamente.
Ahora, cómo etiquetar.
Decidimos que haríamos nuestro propio mapa de etiquetas para cada componente, en el que enumeraríamos todas las etiquetas especificadas: cuándo terminarlo, a qué se refiere. Rápidamente se dieron cuenta de que era inconveniente. Porque la base del código está creciendo, porque tenemos más de 30 componentes, y 30 de esos códigos son inconvenientes. Si necesitas cambiar algo, entonces corres y cambias.
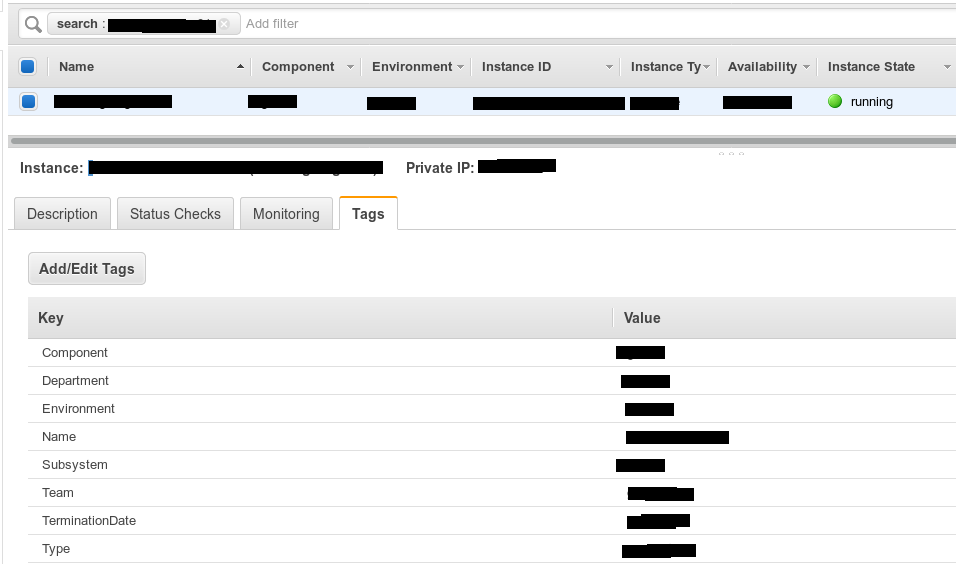
Para etiquetar bien, utilizamos la entidad
Local .
locals { common_tags = {"TerminationDate" = "XX.XX.XXXX", "Environment" = "env_name", "Department" = "dev", "Team" = "team_name"} subsystem_1_tags = "${merge(local.common_tags, map("Subsystem", "subsystem_1_name"))}" subsystem_2_tags = "${merge(local.common_tags, map("Subsystem", "subsystem_2_name"))}" }
En él puede enumerar un subconjunto y luego usarlos entre sí.
Por ejemplo, eliminamos algunas etiquetas comunes en dicha estructura, y luego las específicas por subsistemas. Decimos: "Tome este bloque y agregue, por ejemplo, el subsistema 1. Y para el subsistema 2, agregue el subsistema 2". Decimos: "Etiquetas, por favor, tome las generales y agregue tipo, aplicación, nombre, componente y quién es para ellos". Resulta un cambio muy breve, claro y centralizado, si de repente se requiere.
module "ZZZ02" { count = 1 count_offset = 1 name = "XXX-YYY-ZZZ" ... tags = "${merge(local.core_tags, map("Type", "application", "Component", "XXX"))}" }
Control de versiones
Sus módulos de plantilla, si los usa, deben almacenarse en algún lugar. La forma más sencilla de que todo el mundo comience es el almacenamiento local. Justo en el mismo directorio, solo un subdirectorio en el que describe, por ejemplo, una plantilla para algún tipo de servicio. Esta no es una buena manera. Es conveniente, se puede arreglar y probar rápidamente, pero es difícil reutilizarlo más tarde y controlarlo.
module "ZZZ02" { source = "./modules/srvroles/ZZZ" name = "XXX-YYY-ZZZ" }
Supongamos que los desarrolladores vinieron a usted y le dijeron: "Entonces, necesitamos tal o cual entidad en tal y tal configuración, en nuestra infraestructura". Lo escribiste, lo hiciste en forma de un módulo local en el repositorio de su proyecto. Desplegado - excelente. Lo probaron y dijeron: "¡Lo hará! En producción ". Llegamos al escenario, pruebas de estrés, producción. Cada vez Ctrl-C, Ctrl-V; Ctrl-C, Ctrl-V. Mientras llegamos a la venta, nuestro colega lo tomó, copió el código del entorno del laboratorio, lo transfirió a otro lugar y lo cambió allí. Y obtenemos un estado ya inconsistente. Con el escalado horizontal, cuando tiene tantos entornos de laboratorio como nosotros, es solo una sorpresa.
Por lo tanto, una buena manera es crear un repositorio Git separado para cada uno de sus módulos, y luego simplemente consultarlo. Cambiamos todo en un solo lugar: bueno, conveniente, controlado.
module "ZZZ" { source = "git::ssh://git@GIT_SERVER_FQDN/terraform/modules/general-vm/2-disks.git" host_name_prefix = "XXX-YYY-ZZZ"
Anticipando la pregunta, ¿cómo llega su código a la producción? Para esto, se crea un proyecto separado que reutiliza los módulos preparados y probados.
Genial, tenemos una fuente de código que cambia centralmente. Tomé, escribí, preparé y me propuse que mañana por la mañana me voy a desplegar en producción. Construí un plan, lo probé, genial, vámonos. En este momento, mi colega, guiado exclusivamente por buenas intenciones, fue y optimizó algo, agregó a este módulo. Y sucedió que estos cambios rompen la compatibilidad con versiones anteriores.
Por ejemplo, agregó los parámetros necesarios, que debe pasar, de lo contrario el módulo no se ensamblará. O cambió los nombres de estos parámetros. Entro en la mañana, tengo un tiempo estrictamente limitado para los cambios, comienzo a construir un plan, y Terraform saca los módulos de estado de Git, comienza a construir un plan y dice: "Vaya, no puedo. No es suficiente para ti, cambiaste de nombre ". Estoy sorprendido: "Pero no lo hice, ¿cómo lidiar con eso?" Y si este es un recurso que se creó hace mucho tiempo, luego de dichos cambios, tendrá que ejecutar todos los entornos, cambiar de alguna manera y dar un vistazo. Esto es inconveniente.
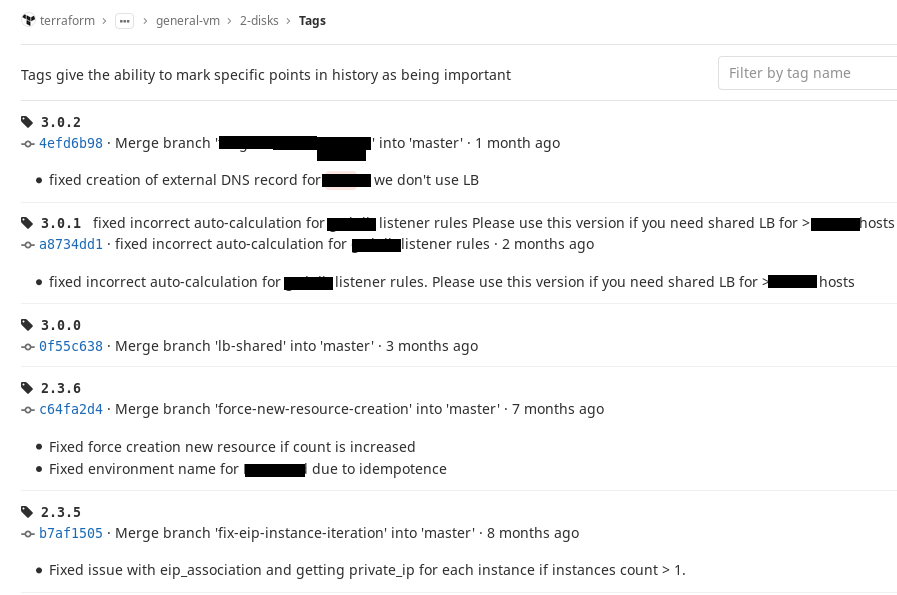
Esto se puede solucionar con etiquetas Git. Decidimos por nosotros mismos que
usaríamos la notación SemVer y
elaboramos una regla simple: tan pronto como la configuración de nuestro módulo alcanza un cierto estado estable, es decir, podemos usarlo, colocamos una etiqueta en este commit. Si hacemos cambios y no rompen la compatibilidad con versiones anteriores, cambiamos el número menor en la etiqueta, si se rompen, cambiamos el número mayor.
Por lo tanto, en la dirección de origen, adjunte a una etiqueta específica y si al menos proporciona algo que tenía antes, siempre se recopilará. Deje que la versión del módulo siga adelante, pero en el momento adecuado iremos, y cuando realmente la necesitemos, la cambiaremos. Y lo que funcionaba antes de eso, al menos no se romperá. Esto es conveniente Así es como se ve en nuestro GitLab.
Ramificación
Usar la ramificación es otra práctica importante. Hemos desarrollado una regla para nosotros que debe hacer cambios solo desde el maestro. Pero para cualquier cambio que desee hacer y probar, haga una rama por separado, juegue con ella, experimente, haga planes y vea cómo va. Y luego haga una solicitud de fusión, y deje que un colega mire el código y le ayude.

Dónde almacenar tfstate
No debe almacenar su estado localmente. No debes almacenar tu estado en Git.
Nos quemamos en esto cuando alguien, cuando despliega las ramas de un no maestro, obtiene su estado, en el que se guarda el estado, luego lo enciende mediante la fusión, alguien agrega el suyo, resulta conflictos de fusión. O resulta que sin ellos, pero un estado inconsistente, porque "él ya lo tiene, todavía no lo tengo", y luego arreglarlo todo es una práctica desagradable. Por lo tanto, decidimos que lo almacenaríamos en un lugar seguro, versionado, pero que estaría fuera de Git.
S3 encaja perfectamente debajo de esto: está disponible, tiene HA, por lo que recuerdo
exactamente cuatro nueves, tal vez cinco . Da versiones fuera de la caja, incluso si rompe su estado, siempre puede retroceder. Y también da una cosa muy importante en combinación con DynamoDB, que, en mi opinión, ha aprendido este Terraform desde la versión 0.8. En DynamoDB, tiene una placa de identificación en la que Terraform registra que está bloqueando el estado.
Es decir, supongamos que quiero hacer algunos cambios. Estoy comenzando a construir un plan o comenzando a aplicarlo, Terraform va a DynamoDB y dice que en esta placa se informa que este estado está bloqueado; usuario, computadora, tiempo. En este momento, mi colega, que trabaja de forma remota o tal vez en un par de mesas de mí, pero se centró en el trabajo y no ve lo que estoy haciendo, también decidió que hay que cambiar algo. Él hace un plan, pero lo lanza un poco más tarde.
Terraform entra en la dinámica, ve: Lock, se interrumpe y le dice al usuario: "Lo siento, el estado está bloqueado por algo". Un colega ve que estoy trabajando ahora, puede acercarse a mí y decirme: "Escucha, mi cambiador es más importante, entrégate a mí, por favor". Digo: "Bien", cancelo el plan, elimino el bloque, más bien, incluso se elimina automáticamente si lo hace correctamente, sin interrumpir Ctrl-C. Un colega va y lo hace. Por lo tanto, nos aseguramos contra una situación en la que ustedes dos están cambiando algo.
Solicitud de fusión
Usamos ramificaciones en Git. Asignamos nuestras solicitudes de fusión a colegas. Además, en Gitlab usamos casi todas las herramientas disponibles para que trabajemos juntos, para solicitudes de fusión o incluso solo algunos grupos: discutir su código, revisarlo, establecer un progreso o problema, algo más como eso. Es muy útil, ayuda en el trabajo.
Además, en este caso, la reversión también es más fácil, puede volver a la confirmación anterior, o si, por ejemplo, decide que no solo aplicaría los cambios desde el asistente, simplemente puede cambiar a una rama estable. Por ejemplo, hizo una rama de características y decidió que primero haría los cambios desde la rama de características. Y luego los cambios, después de que todo funcionó bien, le hacen al maestro. Usted aplicó los cambios en su rama, se dio cuenta de que algo andaba mal, cambió al maestro, sin cambios, dijo aplicar, regresó.
Tuberías
Decidimos que necesitábamos usar el proceso de CI para aplicar nuestros cambios. Para hacer esto, basado en Gitlab CI, estamos escribiendo una tubería que automatiza la aplicación de cambios. Hasta ahora, tenemos dos tipos de ellos:
- Tubería para la rama maestra (tubería maestra)
- Tubería para todas las otras ramas (tubería de rama)
¿Qué hace la tubería de brunch? ( , ). . , merge-request, — , . . .
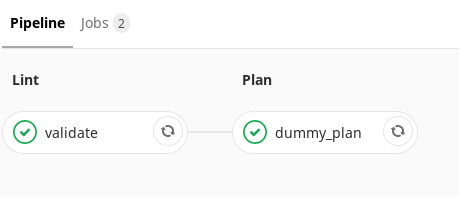
. , , . Terraform- , , . , merge-request . . . , , , .
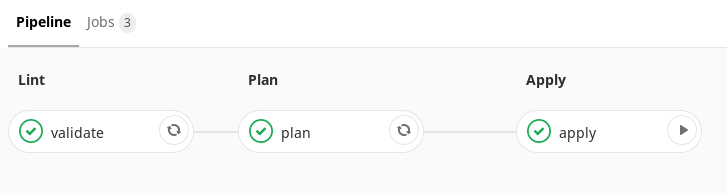
, . .
Terraform
. Terraform , , .
, «» — , .
, , count — , , , , availability-. , , , . . , AZ . , count .
, 4 AZ 5 , AZ — 4, , . : « ». ! , . Terraform .
. —
. . - - If Else. , — , .
. , , , , Terraform- , CI.
CI . , , , — merge, . .
, . . , , Terraform , , tfstate Terraform : «, , ». , , .
CI, , pipeline — , .
, . , . , target , . , : «Terraform apply target instance», -. - (, - ), .
, . . CI — , Terraform , . , - . , , , . .
Terraform —
:
- Terraform , . , , . , , , . , , , .
, — Tfstate, , . . « , » — .
, -, , - — . , . , — . - Terraform , . Terraform . Por qué , . . , , AZ - -. , North Virginia, 6 . . , , : «, ». — . — , , Terraform .
- Terraform . , — 200 , 198 , 5. . , API . Por desgracia
- , . , S3 bucket. , — , - . Terraform – , , : «, - ». . - , .
, Terraform — , . , .