
Hola colegas ¿Cómo destacar los temas principales de 20,000 noticias en 30 segundos? Descripción general del modelado temático que hacemos en TASS, con compañeros y código.
Para empezar, la información presentada en esta nota es parte de un prototipo que se está desarrollando en el Laboratorio Digital ITAR-TASS para apoyar la "digitalización" del negocio. Las soluciones están mejorando constantemente, describiré la sección actual, obviamente, no será la corona de la creación, sino más bien un soporte para futuros desarrollos.
Gran idea
Además de la agenda de noticias, en la que trabajan diariamente las oficinas editoriales de TASS, es bueno comprender qué temas crean más los antecedentes de las noticias en los medios en línea rusos. Con este fin, recopilamos las últimas noticias de los 300 sitios más populares cada pocos minutos, 24/7; luego viene lo más interesante: la elección de métodos de modelado y experimentos.
Cuando termine la sesión mágica, mis colegas, editores y gerentes comenzarán a usar el informe con temas de noticias. Creo que para las personas fuera del área de desarrollo de software y ciencia de datos, el procesamiento automático, el análisis y la visualización de datos de texto se ve un poco mágico. Debido a la alienación de una persona de la alta tecnología, varias imperfecciones en su trabajo pueden llevar a una falta de comprensión de lo que hay dentro y a la decepción. Para minimizar la reacción negativa, trato de hacer que el producto sea más simple y confiable. Y comprender la esencia del modelado temático puede reducirse al hecho de que las noticias relacionadas con un tema y diferentes de las noticias en cualquier otro tema pertenecen a un tema.
He estado experimentando con el modelado temático durante aproximadamente un año. Desafortunadamente, la mayoría de los enfoques que probé me dieron una calidad muy dudosa de llenar temas de noticias. Al mismo tiempo, realicé acciones de acuerdo con la lógica de seleccionar parámetros en métodos de bibliotecas de clústeres populares. Pero no tengo un conjunto de datos etiquetado. Por lo tanto, cada vez que miro una selección de textos que caen en un tema en particular. El caso es bastante triste y no agradecido.
Un picante particular de esta tarea es que varios especialistas, al mirar las noticias incluidas en el tema seleccionado, las encontrarán en un grado u otro inapropiado. Por ejemplo, las noticias con la declaración de Erdogan sobre el inicio de la operación en Siria y las noticias con los primeros informes después del inicio de la operación en Siria pueden entenderse como uno o varios temas. En consecuencia, los medios de comunicación, citando a TASS u otra agencia de noticias, escribirán una serie de textos sobre esto y aquello. Y el resultado de mi algoritmo tenderá a combinarlos o separarlos en función del ... coseno del ángulo entre los vectores de frecuencia de palabras, el número de a priori aceptado o el radio en el método para encontrar los vecinos más cercanos.
En general, esta gran idea es tan frágil como hermosa.
¿Por qué el análisis factorial?
Una mirada más cercana a los métodos de agrupación de textos muestra que cada uno de ellos se basa en una serie de suposiciones. Si las suposiciones no corresponden al problema que se está estudiando, entonces el resultado puede llevar a un lado. Los supuestos del análisis factorial me parecen, y a muchos otros investigadores, cercanos a la tarea de modelar temas.
Creado a principios del siglo XX, este enfoque se basó en la idea de que, además de las variables que caracterizan las observaciones de la muestra, existen factores ocultos que, hablando de manera informal, se correlacionan con algunas variables observadas. Por ejemplo, las respuestas a la pregunta "¿Crees en Dios" y "¿Vas a la iglesia?" Más bien coincidirán que diferirán. Se puede suponer que existe un "factor de religiosidad", que se manifiesta en un conjunto de variables interrelacionadas. Al mismo tiempo, también existe la oportunidad de medir qué tan fuertemente están relacionadas las variables con su factor oculto.
Para los textos, la declaración del problema se convierte en lo siguiente. En las noticias que describen el mismo tema, aparecerán las mismas palabras. Por ejemplo, las palabras "Siria", "Erdogan", "Operación", "Estados Unidos", "Condena" se encontrarán juntas con mayor frecuencia en las noticias que se dedican al despliegue de la intervención militar de Turquía en Siria, y la reacción que acompaña a este asunto desde los Estados Unidos ( como jugador geopolítico en el mismo territorio).
Queda por descubrir todos los factores importantes de la agenda de noticias durante un período. Estos serán temas de noticias. Pero eso no es todo ...
Un poco de matemática
Para las personas con experiencia en técnicas de modelado de sujetos, puedo hacer tal afirmación. La versión del análisis factorial que probé es una versión altamente simplificada de la
metodología ARTM .
Pero decidí experimentar con métodos donde hay menos grados de libertad, para que se entienda mejor lo que sucede adentro.
(Big) ARTM surgió de pLSA, análisis semántico latente probabilístico, que, a su vez, era una alternativa a LSA basado en una descomposición de matriz singular: SVD.
El análisis del factor de inteligencia va más allá de SVD en que proporciona una "estructura simple" de la relación entre variables y factores, que puede no ser un asunto simple para SVD, pero es limitado porque no está diseñado para calcular con precisión los valores de los factores (puntajes), entonces Hay vectores de valores de factores que pueden reemplazar 2 o más variables observables.
Formalmente, la tarea del análisis del factor de inteligencia es la siguiente:
¿Dónde están las variables observadas?
relacionado linealmente con factores ocultos
Necesito encontrar
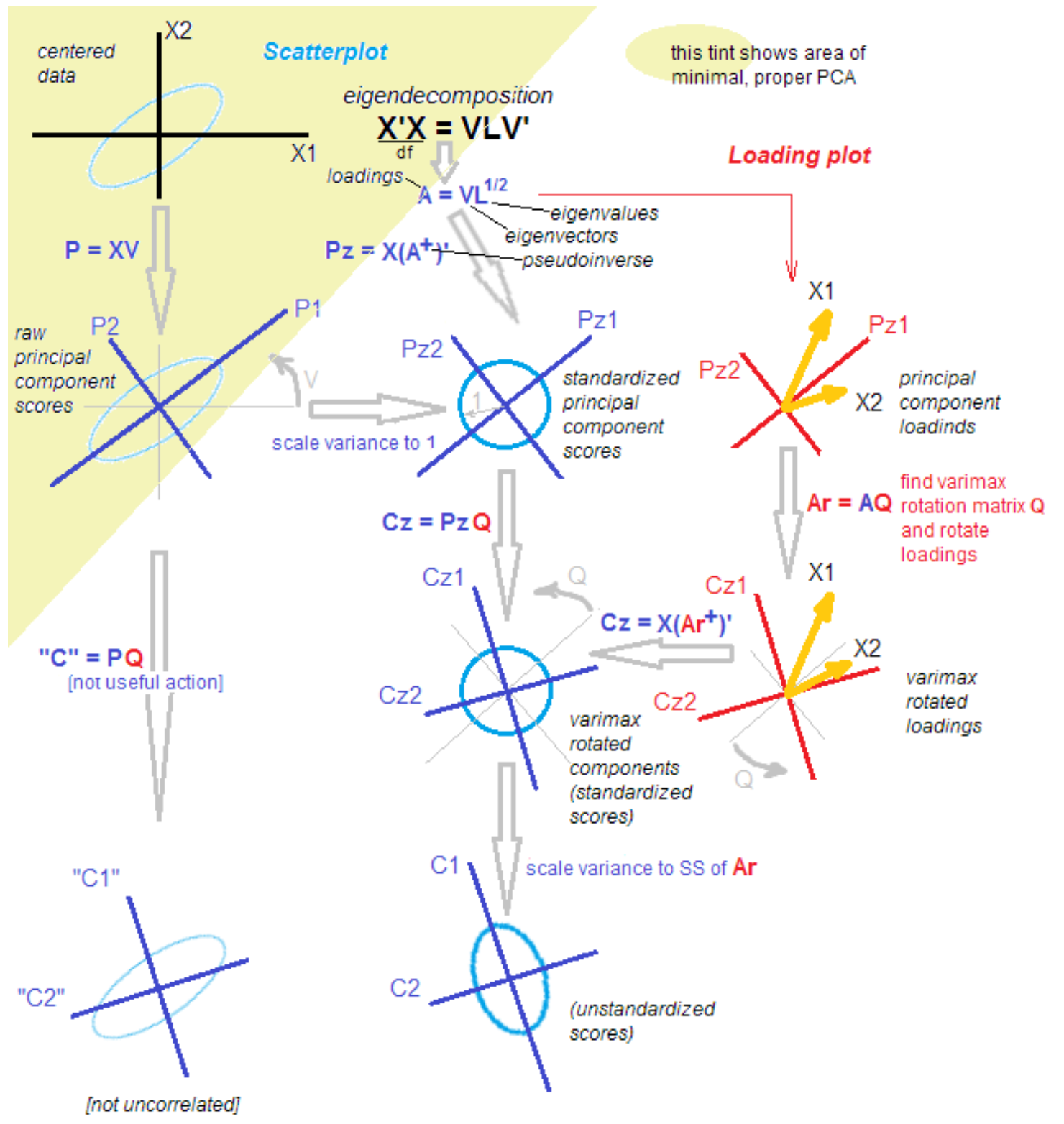
Eso es todo! Estos coeficientes beta se denominan cargas en el mundo del análisis factorial. Considere su importancia un poco más tarde.
Para llegar al resultado del análisis, uno puede moverse de varias maneras. Uno de ellos que utilicé es encontrar los componentes principales en el sentido clásico, que luego rotan para resaltar la "estructura simple". Los componentes principales solo se extienden desde la descomposición singular de la matriz, o mediante la descomposición de la matriz de covarianza variacional en vectores y valores propios. El problema también se resuelve maximizando la función de probabilidad. En general, el análisis factorial es un gran "zoológico" de métodos, al menos 10 que dan resultados diferentes, y se recomienda elegir el método que mejor se adapte a la tarea.
La rotación de la matriz de carga también se puede hacer de diferentes maneras, probé varimax - rotación ortogonal.
¿Por qué es todo tan complicado?El hecho es que entre los estadísticos y los solicitantes, la discusión no se detiene sobre las diferencias y similitudes del método de los componentes principales, el análisis factorial y su combinación. La metodología se repone con nuevos conocimientos incluso después de más de 100 años desde el momento del descubrimiento. Un estadístico respetado me trajo la siguiente imagen para facilitar la comprensión con las palabras: "Eso es, resuélvelas".
 fuente
fuente .
¡Todo resuelto!
Es broma). Para comprender los siguientes pasos, es suficiente que después de aislar los componentes principales, los rotamos, pasando de explicar la varianza dentro de las variables a explicar la covarianza de variables y factores.
Además, hago todo esto usando funciones atómicas, y no solo presionando un "gran botón rojo". Este enfoque nos permite comprender la transformación de los datos en etapas intermedias.
¿A dónde fue la LDA?
ActualizaciónDecidí agregar mis pensamientos sobre los arreglos de Dirichlet latentes. Probé este método popular, pero no pude obtener un resultado limpio en poco tiempo. Ejemplos simples de cómo usarlo, y "Dividamos las noticias en política, economía y cultura" realmente funcionan, pero ... En mi caso, tengo que dividir, digamos, la política en 50 temas diurnos, donde Rusia, Putin e Irán estarán y temas tan estrechos como "la liberación de Kokorin y Mamaev". Todo esto, de hecho, 1-2 noticias de agencias de noticias, citadas varias docenas de veces en los medios.
Además, el supuesto sobre la naturaleza de los datos, característico de la hipótesis de que cada texto es una distribución de probabilidad por tema, me parece un poco artificial en el contexto de mi trabajo. Ningún editor está de acuerdo en que la noticia de la "desestimación del caso contra Golunov" es una mezcla de temas. Para nosotros, este es 1 tema. Quizás, eligiendo hiperparámetros es posible lograr tal fragmentación del LDA, dejaré esta pregunta para el futuro.
Código
Me meto de nuevo en el lenguaje R, por lo que este pequeño experimento será ario.
Trabajamos con 3 pares de valores aleatorios correlacionados. Este conjunto contiene 3 factores ocultos, solo por claridad.
set.seed(1) x1 = rnorm(1000) x2 = x1 + rnorm(1000, 0, 0.2) x3 = rnorm(1000) x4 = x3 + rnorm(1000, 0, 0.2) x5 = rnorm(1000) x6 = x5 + rnorm(1000, 0, 0.2) dt <- data.frame(cbind(x1,x2,x3,x4,x5,x6)) M <- as.matrix(dt) sing <- svd(M, nv = 3) loadings <- sing$v rot <- varimax(loadings, normalize = TRUE, eps = 1e-5) r <- rot$loadings loading_1 <- r[,1] loading_2 <- r[,2] loading_3 <- r[,3] plot(loading_1, type = 'l', ylim = c(-1,1), ylab = 'loadings', xlab = 'variables'); lines(loading_2, col = 'red'); lines(loading_3, col = 'blue'); axis(1, at = 1:6, labels = rep('', 6)); axis(1, at = 1:6, labels = paste0('x', 1:6))
Obtenemos la siguiente matriz de carga:
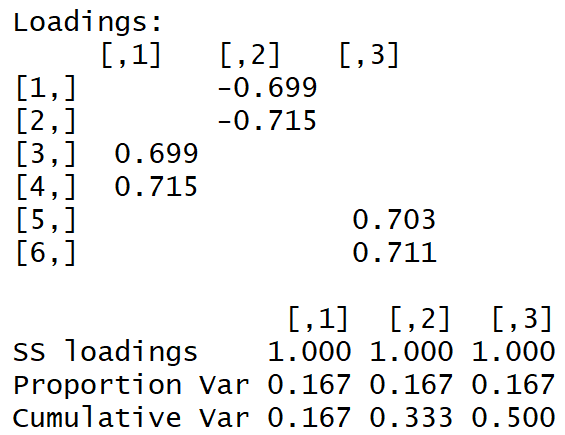
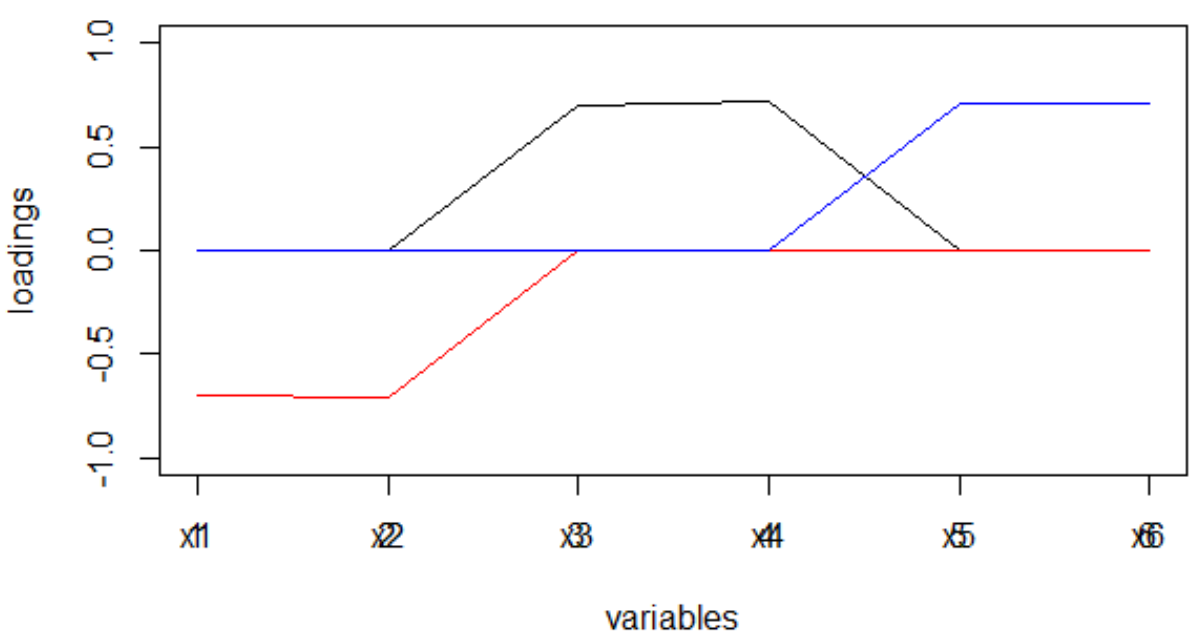
La "estructura simple" es visible a simple vista.
Y así es como se veían las cargas justo después de la finalización de la MGK:
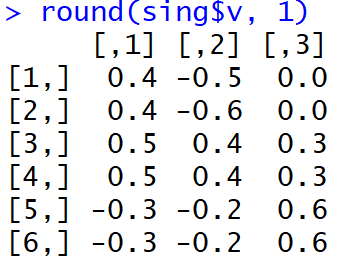
No es muy fácil para las personas comprender qué factores están asociados con qué variables. Además, tales pesos, módulo tomado y en la interpretación de la máquina conducirán a una distribución muy extraña de palabras sobre temas.
Pero, ¡bo !, la proporción de la dispersión explicada en los primeros tres componentes principales (antes de la rotación) alcanzó el 99%.

¿Qué hay de las noticias?
Para las noticias, nuestras variables x1, x2 ... xm se convierten en la frecuencia (o tf-idf) de la aparición del token en el texto. Hay muchas palabras! Por ejemplo, 50,000 palabras únicas por semana es normal. El bi-gramo será aún más grande, comprensiblemente. La complejidad de la descomposición singular es el promedio:
Es decir, es enorme. La descomposición de una matriz de 20,000 * 50,000 valores en una secuencia toma varias horas ...
Para poder leer temas en tiempo real y mostrar Shiny en un tablero, llegué a los siguientes límites dolorosos:
- top-10% de las palabras más comunes
- Selección aleatoria de textos según la fórmula autocumplida:
donde n es todos los textos.
Como resultado, proceso datos semanales en 30 segundos, un día en 5 segundos. No esta mal! Pero debe comprender que las tendencias de noticias son capturadas solo por los más bien alimentados.
Habiendo recibido cargas, que, observo, son estimaciones de la covarianza de las variables observadas con los factores, las libero del signo (a través del módulo, no a través del grado), que tiende a cambiar según el método de rotación utilizado.
Recuerde cómo difirió la matriz de carga después de realizar el MHC y después de la rotación con varimax. La escasez de las cargas, así como el hecho de que su dispersión para cada factor se maximizó: hay muy grandes y muy pequeñas, conducirá al hecho de que las palabras se distribuirán entre los factores de manera bastante limpia, lo que, a su vez, conducirá a más y la distribución de factores en el texto de las noticias tendrá un pico pronunciado.
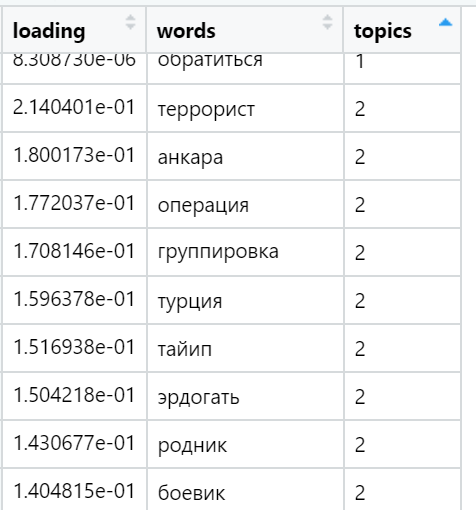
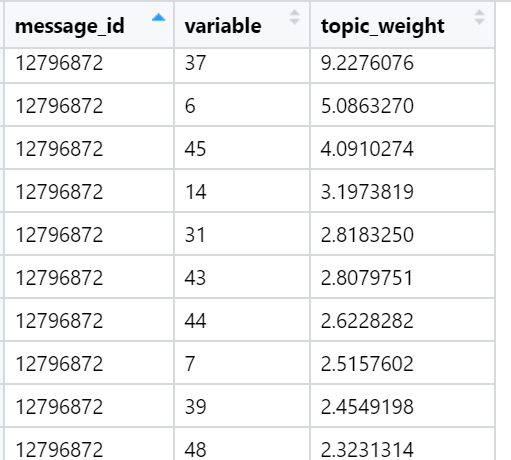
Ejemplos de las palabras más cargadas en varios temas encontrados (seleccionados al azar):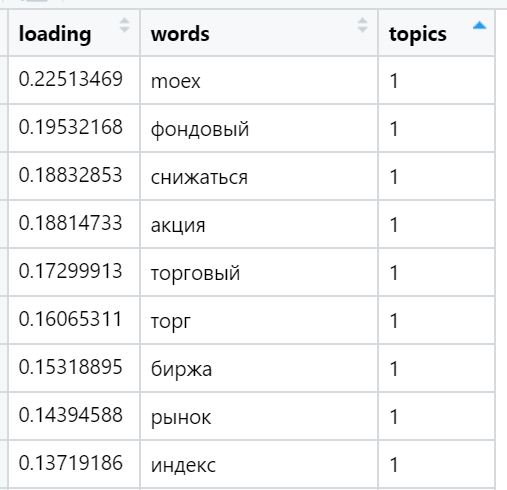

Y finalmente, considero la suma de las cargas en los textos en relación con cada factor. Las ganancias más fuertes: para cada texto, se selecciona un factor cuya suma de cargas se maximiza, teniendo en cuenta la cantidad de palabras incluidas en el documento, que, como hemos proporcionado durante la rotación, tienen una distribución muy desigual entre los factores de carga. En esta iteración, todos los textos (n) ya están involucrados, es decir, la muestra completa.
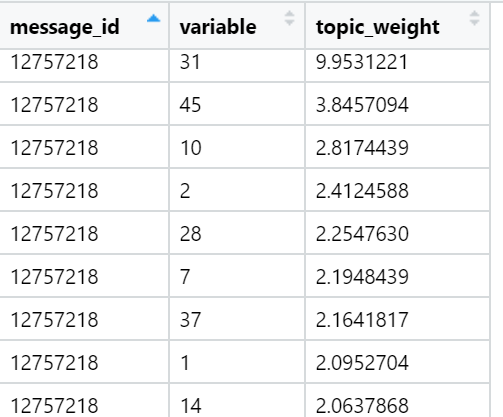
Ejemplos de temas que son superiores en términos de la suma de cargas en textos de noticias específicos (seleccionados al azar):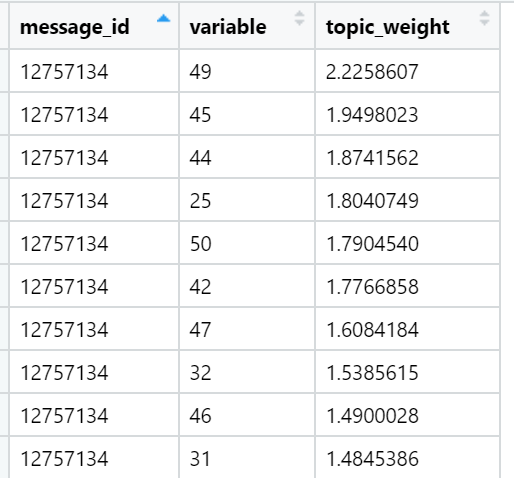
 El resultado de hoy.
El resultado de hoy. Información adicional
Información adicional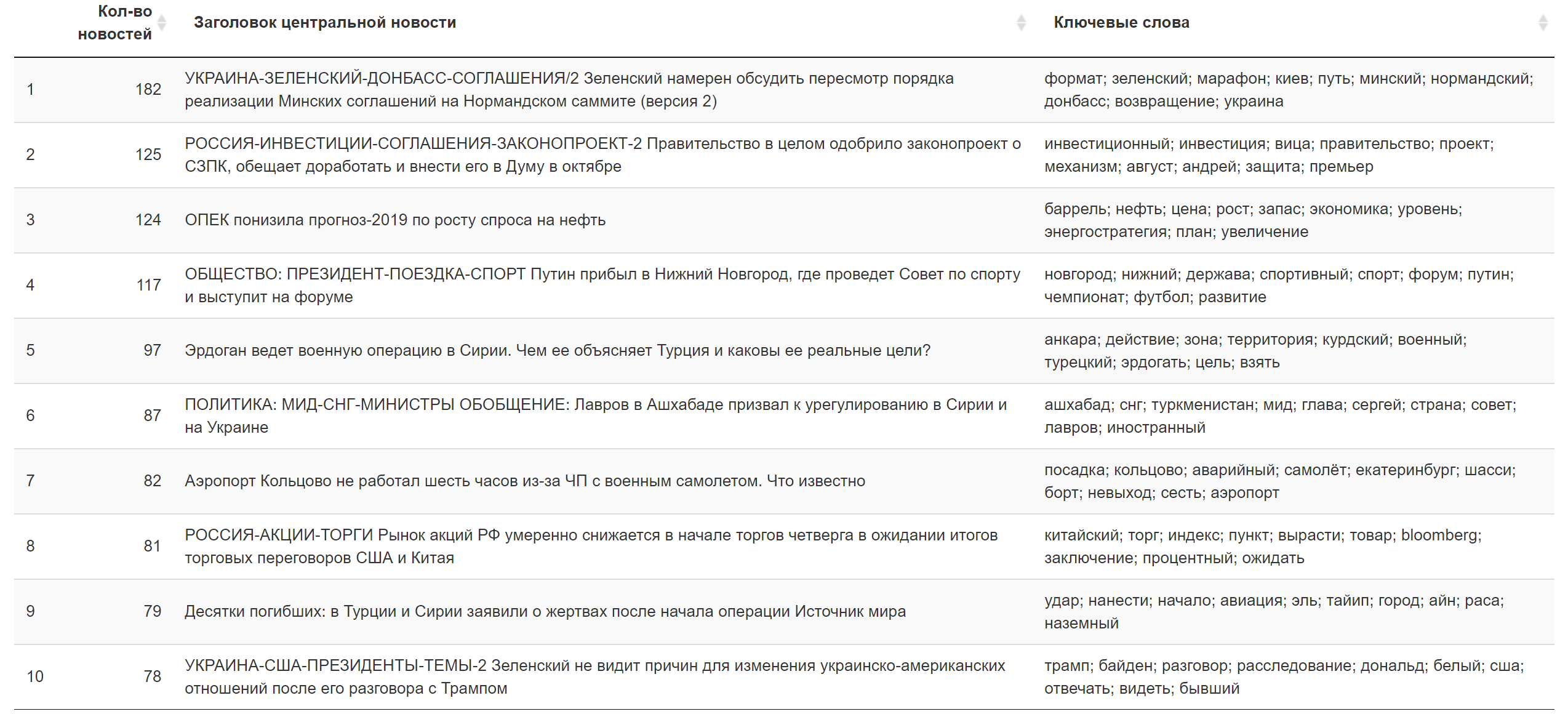
Que hacer
Aquí, lo primero que haré cuando ... En general, cuando llegue la inspiración, intentaré configurar el trabajo para el entrenamiento por hora de una red neuronal con un cuello estrecho, lo que me dará una aproximación no lineal de factores, componentes principales distorsionados, en forma de neuronas de capa oculta. En teoría, el aprendizaje se puede hacer rápidamente utilizando la mayor velocidad de aprendizaje. Después de esto, los pesos de la capa oculta (de alguna manera normalizada) desempeñarán el papel de cargas de tokens. Ya se pueden cargar rápidamente en el entorno de procesamiento final a una velocidad aceptable. Quizás este truco pueda llevar al hecho de que la semana se procesará en todos los textos en 10 segundos: el tiempo normal para un caso tan difícil.
Con todo, eso es todo lo que quería cubrir. Espero que esta breve excursión al método de modelado de temas le permita comprender mejor lo que se está haciendo bajo el "gran botón rojo", reducir la alienación de la tecnología y brindar satisfacción. Si ya lo sabía, me complacerá escuchar las opiniones de un sentido técnico o de producto. ¡Nuestro experimento está evolucionando y cambiando todo el tiempo!