- ¿Qué tamaño de clúster necesito?
- Bueno, depende ... (risita enojada)
Elasticsearch es el corazón de Elastic Stack, en el que tiene lugar toda la magia de los documentos: emisión, recepción, procesamiento y almacenamiento. El rendimiento depende del número correcto de nodos y la arquitectura de la solución. Y el precio, por cierto, también, si su suscripción es Gold o Platinum.
Las características principales del hardware son disco (almacenamiento), memoria (memoria), procesadores (cómputo) y red (red). Cada uno de estos componentes es responsable de la acción que Elasticsearch realiza en los documentos, que son, respectivamente, almacenamiento, lectura, computación y recepción / transmisión. Hablemos de los principios generales de dimensionamiento y revelemos el mismo "depende". Y al final del artículo hay enlaces a seminarios web y artículos relacionados. Vamos!
Este artículo se basa en
el dimensionamiento del seminario web y la planificación de capacidad de David Moore . Complementamos su razonamiento con enlaces y comentarios para hacerlo un poco más claro. Al final del artículo, una pista adicional es enlaces a materiales elásticos para aquellos que desean sumergirse mejor en el tema. Si tiene buena experiencia con Elasticsearch, comparta en los comentarios cómo diseñar un clúster. Nosotros y todos los colegas estaríamos interesados en conocer su opinión.
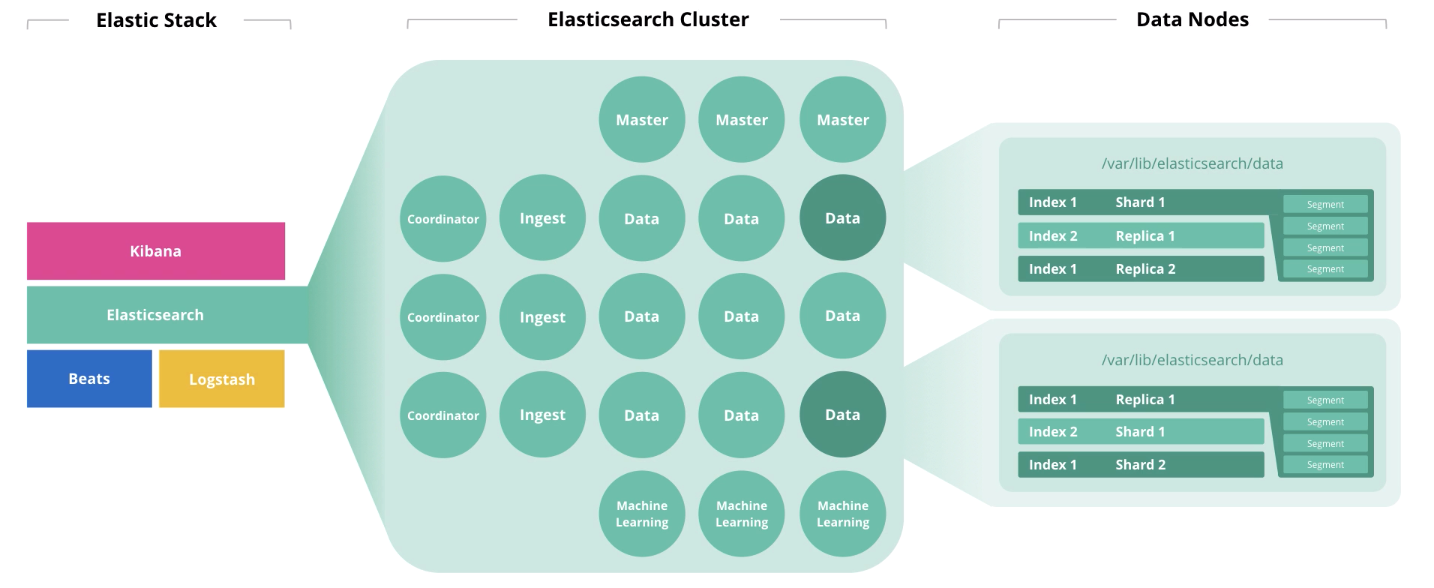
Elasticsearch Arquitectura y Operaciones
Al comienzo del artículo, hablamos sobre 4 componentes que forman el hardware: disco, memoria, procesadores y red. El papel de un nodo afecta la disposición de cada uno de estos componentes. Un nodo puede realizar varios roles a la vez, pero con el crecimiento del clúster, estos roles deben distribuirse entre diferentes nodos.
Los nodos maestros supervisan el estado del clúster en su conjunto. En el trabajo del nodo maestro, se debe observar un quórum, es decir su número debe ser impar (quizás 1, pero mejor 3).
Los nodos de datos realizan funciones de almacenamiento. Para aumentar el rendimiento del clúster, los nodos deben dividirse en
"activo", "activo" y "frío" (congelado) . Los primeros son para el acceso en línea, el segundo para el almacenamiento y el tercero para el archivo. En consecuencia, para "caliente" es razonable usar unidades SSD locales, y para la matriz de HDD "caliente" y "fría" es adecuada localmente o en SAN.
Para determinar la capacidad de almacenamiento de los nodos para el almacenamiento, Elastic recomienda usar la siguiente lógica: "caliente" → 1:30 (30 GB de espacio en disco por gigabyte de memoria), "caliente" → 1: 100, "frío" → 1: 500). Bajo
JVM Heap, no más del 50% de la memoria total y no más de 30 GB para evitar la redada del recolector de basura. La memoria restante se usará como caché del sistema operativo.
Los indicadores de rendimiento de la instancia de Elastisearch, como los
grupos de subprocesos y las colas de subprocesos, se ven más afectados por la
utilización del núcleo del procesador. Los primeros se forman sobre la base de las acciones que realiza el nodo: buscar, analizar, escribir y otros. Los segundos son la cola de las solicitudes correspondientes de varios tipos. El número de procesadores Elasticsearch disponibles para su uso se determina automáticamente, pero puede especificar este valor manualmente en la configuración (puede ser útil cuando tiene 2 o más instancias de Elasticsearch ejecutándose en el mismo host). El número máximo de grupos de subprocesos y colas de subprocesos de cada tipo se puede establecer en la configuración. La métrica de agrupaciones de subprocesos es la métrica de rendimiento principal para Elasticsearch.
Los nodos de ingesta toman información de los recolectores (Logstash, Beats, etc.), realizan conversiones en ellos y escriben en el índice de destino.
Los nodos de aprendizaje automático están destinados al análisis de datos. Como escribimos en el
artículo sobre aprendizaje automático en Elastic Stack , el mecanismo está escrito en C ++ y funciona fuera de la JVM, en la que Elasticsearch está girando, por lo que es razonable realizar tales análisis en un nodo separado.
Los nodos coordinadores aceptan una solicitud de búsqueda y la enrutan. La presencia de este tipo de nodo acelera el procesamiento de consultas de búsqueda.
Si consideramos la carga en los nodos en términos de capacidades de infraestructura, la distribución será algo como esto:
A continuación, presentamos 4 tipos principales de operaciones en Elasticsearch, cada una de las cuales requiere un cierto tipo de recurso.
Índice : procesar y guardar un documento en el índice. El siguiente diagrama muestra los recursos utilizados en cada etapa.
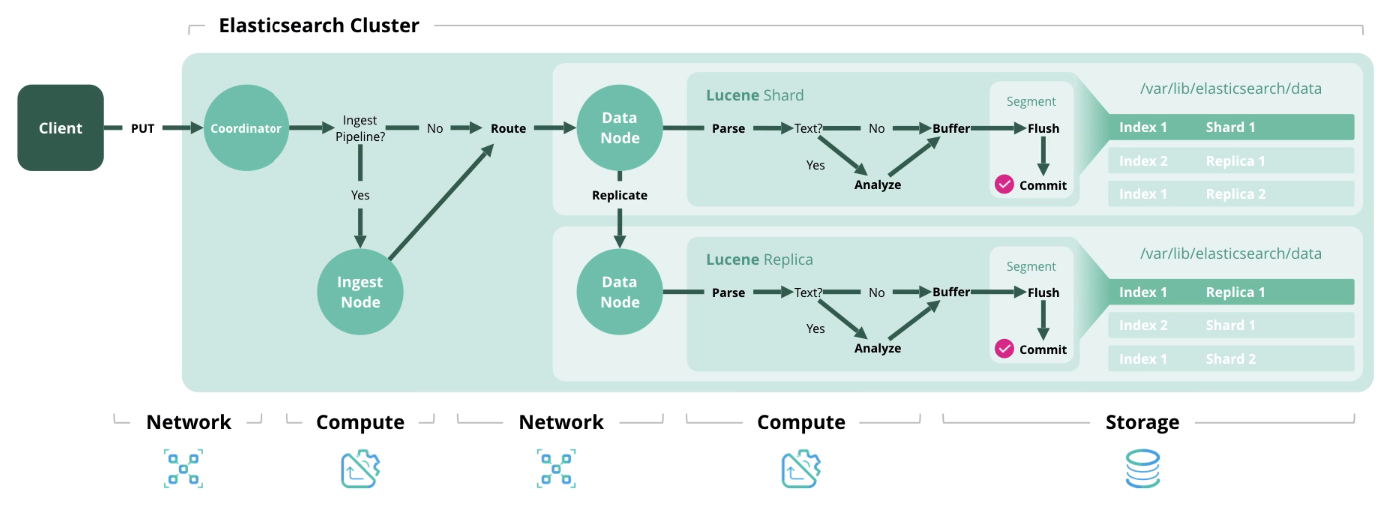 Eliminar
Eliminar : elimina un documento del índice.
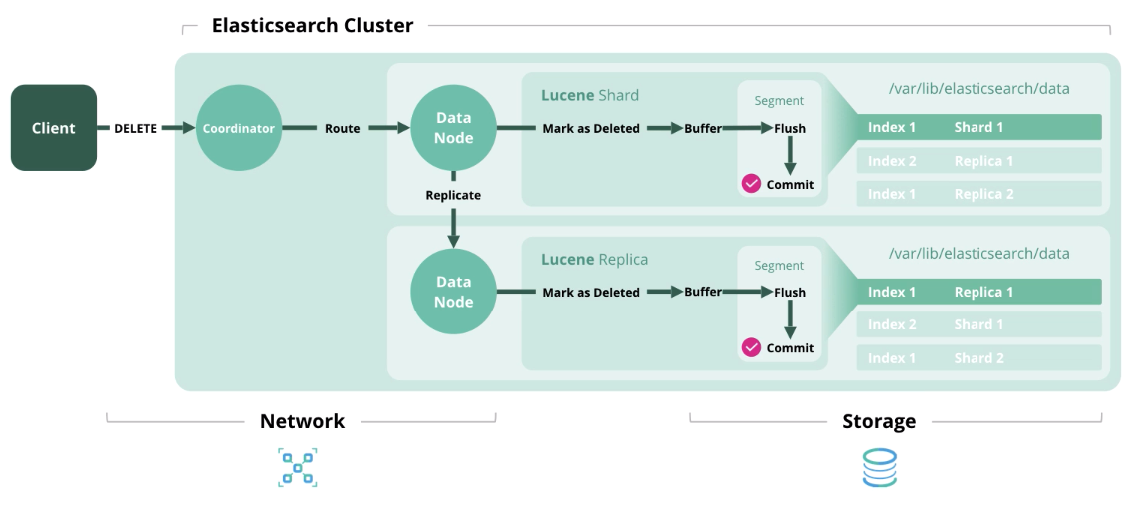 Actualización
Actualización : funciona como Indexar y Eliminar, porque los documentos en Elasticsearch son inmutables.
Búsqueda : obtener uno o más documentos o su agregación de uno o más índices.
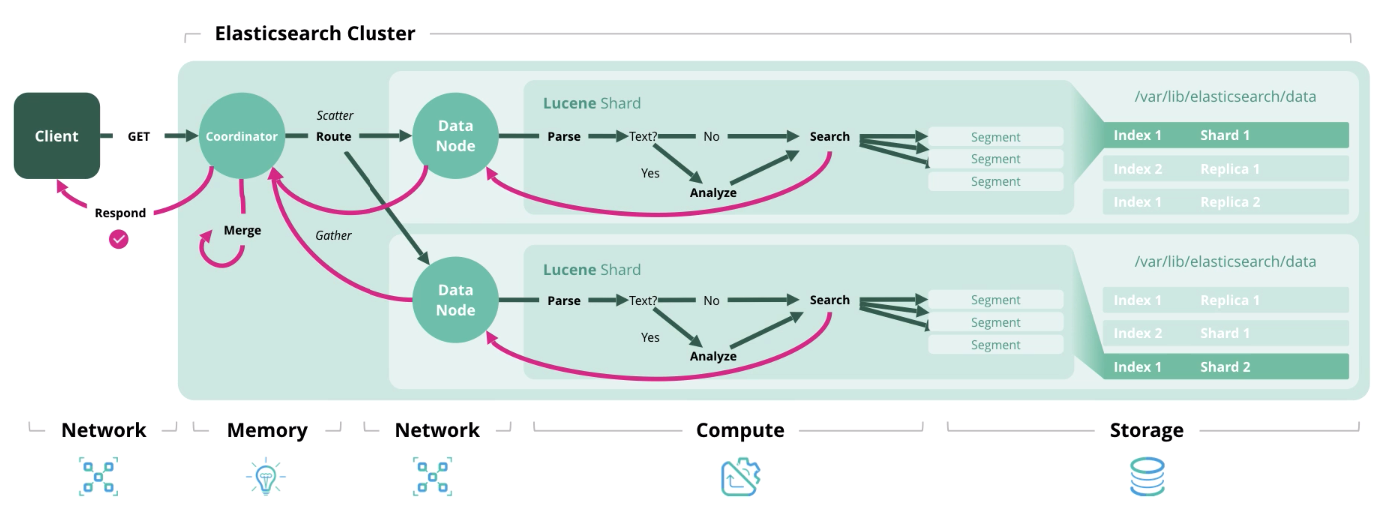
Descubrimos la arquitectura y los tipos de cargas, ahora pasemos a la formación de un modelo de dimensionamiento.
Dimensionar Elasticsearch y preguntas antes de su formación
Elastic recomienda usar dos estrategias de dimensionamiento: orientado al almacenamiento y rendimiento. En el primer caso, los recursos del disco y la memoria son de suma importancia, y en el segundo caso, la memoria, la potencia del procesador y la red.
Tamaño de la arquitectura Elasticsearch basada en el tamaño de almacenamiento
Antes de los cálculos, obtenemos los datos iniciales. Necesita:
- La cantidad de datos sin procesar por día;
- El período de almacenamiento de datos en días;
- Factor de transformación de datos (factor json + factor de indexación + factor de compresión);
- Número de replicación de fragmentos;
- La cantidad de nodos de datos de memoria;
- La relación de memoria a datos (1:30, 1: 100, etc.).
Desafortunadamente, el factor de transformación de datos se calcula solo empíricamente y depende de varias cosas: el formato de los datos sin procesar, el número de campos en los documentos, etc. Para averiguarlo, debe cargar una parte de los datos de prueba en el índice. Sobre el tema de tales pruebas, hay un
video interesante de la conferencia y una
discusión en la comunidad Elastic . En general, puede dejarlo igual a 1.
Por defecto,
Elasticsearch comprime los datos usando el algoritmo LZ4, pero también existe DEFLATE, que presiona un 15% más. En general, se puede lograr una compresión del 20-30%, pero esto también se calcula empíricamente. Al cambiar al algoritmo DEFLATE, aumenta la carga de potencia informática.
Aún hay recomendaciones adicionales:
- Deposite el 15% para tener una reserva en el espacio en disco;
- Contribuir 5% para necesidades adicionales;
- Establezca 1 equivalente de un nodo de datos para garantizar una migración rápida.
Ahora pasemos a las fórmulas. Aquí no hay nada complicado, y creemos que será interesante para usted verificar que su clúster cumpla con estas recomendaciones.
Cantidad total de datos (GB) = Datos sin procesar por día * Número de días de almacenamiento * Factor de transformación de datos * (número de réplicas - 1)
Almacenamiento total de datos (GB) = Datos totales (GB) * (1 + 0.15 stock + 0.05 necesidades adicionales)
Número total de nodos = OK (Almacenamiento total de datos (GB) / Volumen de memoria por nodo / relación de memoria a datos + 1 equivalente de nodo de datos)
Dimensionamiento de la arquitectura Elasticsearch para determinar la cantidad de fragmentos y nodos de datos según el tamaño de almacenamiento
Antes de los cálculos, obtenemos los datos iniciales. Necesita:
- El número de patrones de índice que creará;
- El número de fragmentos de núcleo y réplicas;
- Después de cuántos días se realizará la rotación del índice, si es que lo hace;
- El número de días para almacenar los índices;
- La cantidad de memoria para cada nodo.
Aún hay recomendaciones adicionales:
- No exceda 20 fragmentos por 1 GB JVM Heap en cada nodo;
- No exceda los 40 GB de espacio en disco de fragmento.
Las fórmulas son las siguientes:
Número de fragmentos = Número de patrones de índice * Número de fragmentos principales * (Número de fragmentos replicados + 1) * Número de días de almacenamiento
Número de nodos de datos = OK (Número de fragmentos / (20 * Memoria para cada nodo))
Tamaño de ancho de banda de Elasticsearch
El caso más común cuando se necesita un gran ancho de banda es frecuente y en grandes números las consultas de búsqueda.
Datos iniciales necesarios para el cálculo:
- Pico de búsquedas por segundo;
- Tiempo de respuesta promedio permitido en milisegundos;
- El número de núcleos y subprocesos por núcleo de procesador en los nodos de datos.
Valor máximo de subprocesos = OK UP (número máximo de consultas de búsqueda por segundo * cantidad de tiempo promedio para responder a una consulta de búsqueda en milisegundos / 1000 milisegundos)
Grupo de subprocesos de volumen = OKRUP ((número de núcleos físicos por nodo * número de subprocesos por núcleo * 3/2) +1)
Número de nodos de datos = OK (valor máximo de subproceso / volumen de grupo de subprocesos)
Quizás no todos los datos iniciales estarán en sus manos cuando diseñe la arquitectura, pero después de mirar el
seminario web o leer este artículo, aparecerá una comprensión que, en principio, afecta la cantidad de recursos de hardware.
Tenga en cuenta que no es necesario adherirse a la arquitectura dada (por ejemplo, crear nodos coord coord y nodos manejadores). Es suficiente saber que existe una arquitectura de referencia de este tipo y puede proporcionar un aumento de rendimiento que no podría lograr por otros medios.
En uno de los siguientes artículos, publicaremos una lista completa de preguntas que deben responderse para determinar el tamaño del clúster.
Para contactarnos, puede usar mensajes personales en Habré o el
formulario de comentarios en el sitio .
Materiales adicionalesSeminario web "Dimensionamiento de Elasticsearch y planificación de capacidad"Seminario web de planificación de capacidad de ElasticsearchDiscurso en ElasticON con el tema "Dimensionamiento cuantitativo de clústeres"Seminario web sobre la utilidad Rally para determinar los indicadores de rendimiento del clústerArtículo de tamaño de ElasticsearchSeminario web de pila elástica