Hola a todos! Mi nombre es Lyudmila, participo en pruebas de carga, quiero compartir cómo realizamos la automatización del análisis comparativo del perfil de regresión del sistema de prueba de carga de la base de datos para Oracle DBMS junto con uno de nuestros clientes.
El propósito del artículo no es descubrir un enfoque "nuevo" para comparar el rendimiento de la base de datos, sino describir nuestra experiencia e intentar automatizar la comparación de los resultados obtenidos y
reducir la cantidad de llamadas a Oracle DBA.
Realizando pruebas de carga de cualquier base de datos, estamos interesados principalmente en:
- ¿Se rompió algo después de instalar un nuevo ensamblaje?
- La dinámica de la base de datos durante la prueba.
La comparación de los informes de AWR por sí sola no es suficiente para lograr sus objetivos.
El almacenamiento centralizado de los volcados de AWR también es una buena práctica. Los volcados de AWR retienen todas las vistas históricas (dba_hist).
Esta práctica ya ha sido aplicada por nuestro cliente.
Después de la próxima sesión de prueba de carga, comparamos los resultados:
- volcado de prueba actual con volcado industrial;
- el volcado de prueba actual con el volcado de prueba anterior.
¿Por qué se necesita esto?
Los objetivos son diferentes:
- A veces, llenar la base en un entorno de prueba es diferente del operativo, lo que significa que habrá diferencias que interfieren con el análisis ("interferencia" para responder a la pregunta principal, "¿hay algo roto?"). Quiero identificar estas diferencias;
- La comparación de la prueba actual con el trabajo de la base industrial ayuda a comprender cuán correctas son las pruebas de estrés actuales (en algún lugar cargamos demasiado, pero nos olvidamos de algo);
- La comparación de la prueba actual con la prueba anterior ayuda a comprender si el comportamiento actual del sistema es normal. ¿Ha cambiado algo en el comportamiento del sistema en comparación con la prueba anterior?
Para lograr todos estos objetivos, a menudo resolvemos el problema de comparar diferentes vertederos entre sí. ¡Las fechas suelen ser muy ajustadas cuando se suponía que debían presentarse ayer! Falta mucho tiempo para verificar completamente cada prueba de regresión. Y si ejecuta la prueba de confiabilidad durante un día, puede pasar mucho tiempo analizando el resultado ...
Por supuesto, puede ver todo en línea en Enterprise Manager (o con solicitudes de gv $ views) durante la prueba: no vaya a fumar, comer y dormir ...

¿Quizás también tenga su propia herramienta personalizada, hecha para usted? Puedes compartir en los comentarios. Y compartiremos lo que usamos para nuestras tareas.
Los informes de AWR tienen mucha información útil:

Aquí hay información útil, por ejemplo: cuánto se ejecuta la consulta, sql_id, módulo y texto abreviado. Aunque el texto está allí, está truncado y la versión completa se puede tomar de la lista completa del párrafo de texto SQL.
En cuanto a las desventajas: en el informe de AWR no está claro cuándo ocurrieron estas solicitudes, en qué momento hubo más y en qué menos ... Después de todo, analizar los resultados de la prueba, comprender lo que sucedió y en qué momento aproximadamente es importante: de manera uniforme para todo prueba o pico / aumento como en un horario. También veremos solo un top limitado aquí. Esto se puede ver más fácilmente consultando tablas históricas.
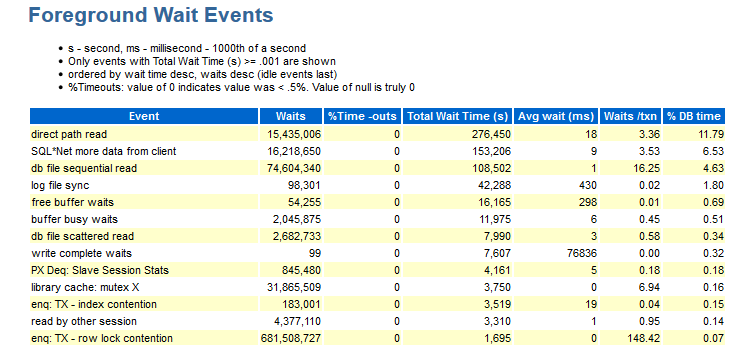
Aquí puede ver qué eventos ocurrieron durante la prueba. Los datos en esta sección están ordenados por tiempo DB.
Para mí, en esta sección falta la siguiente información:
- Wait_class (sí, recuerda con experiencia a qué tipo de expectativas pertenece este evento).
- Distribuciones por módulos (si veo, por ejemplo, esperando enq: TX - contención de bloqueo de fila: se necesita información, bajo qué módulo sucedió esto).
Hay trabajos en los que hay números que no llevan una parte semántica, es decir, debe agrupar los mismos módulos y obtener una respuesta para el grupo, por ejemplo: module_A_1, module_A_2, module_A_3 y module_B_1, module_ B_2, module_ B_3. Es decir, había dos módulos semánticos, pero todos tienen nombres diferentes.
- El objeto al que nos estamos refiriendo (CURRENT_OBJ # - si, por ejemplo, ocurre un evento enq: TX - contención del índice, sería bueno saber qué índice tiene la culpa).
- Sql_id: qué solicitud se intentó ejecutar el texto de esta solicitud.
- Información sobre la distribución de cantidades por instantánea (como se describió anteriormente ...).
Para comparar las dos pruebas, puede usar la comparación de informes AWR:
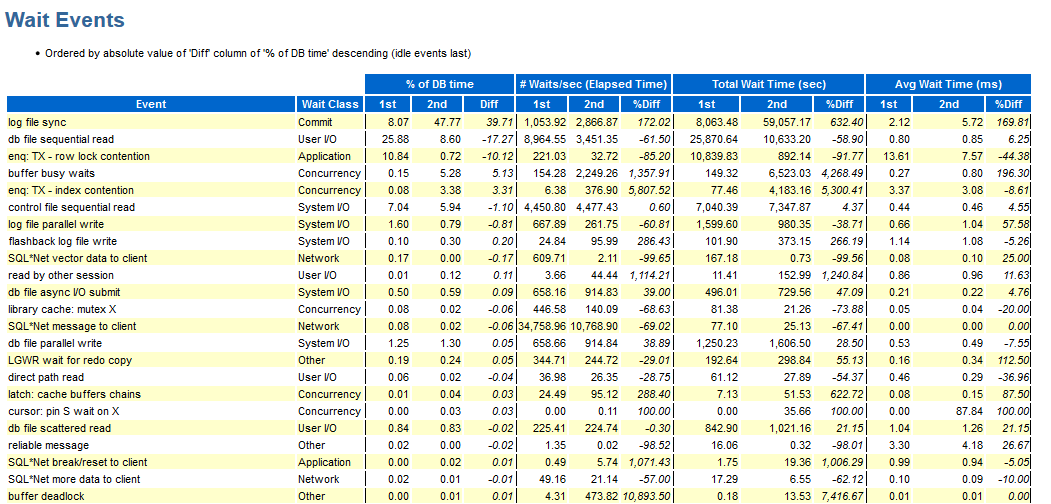
Hurra, aquí tenemos que mostrar wait_class; de lo contrario, las desventajas son las mismas que las descritas anteriormente.
A veces no hay Enterprise Manager en proyectos, y puede, por ejemplo, usar Enterprise Manager Express o ASH Viewer. En Enterprise Manager, muchos usan Top Activity para datos históricos, pero para mí, muchas cosas son más fáciles de ver con las consultas mismas. Todo lo anterior debe compararse con otras pruebas / carga de trabajo. Ya teníamos una comparación personalizada en términos de tiempo de ejecución, pero no teníamos una comparación personalizada, y verificamos manualmente con consultas en tablas históricas.
Después de cada prueba de regresión, fue necesario comparar los resultados en tablas históricas con consultas a la base de datos, ver informes de AWR, localizar la expectativa problemática (en qué módulo ocurre, en qué momento, en qué objeto se colgó), de modo que como resultado se podría generar un error para el equipo de desarrollo adecuado.
La base de datos del cliente ha alcanzado 190 TB, se procesan una gran cantidad de solicitudes en el sistema: la cantidad de módulos paralelos es 16237.
Y luego tuve una idea de cómo simplificar el proceso de comparación de los volcados de AWR. Con esta idea, fui a
Fred . Juntos, creamos un portal conveniente.
Al principio, la declaración del problema por mi parte se veía así:

Entonces, sin embargo, decidí sistematizar para empezar qué consultas a las tablas históricas que uso con más frecuencia ... Fred comenzó a fijar esto en el portal y luego comenzó ...
En primer lugar, estaba interesado en una comparación de eventos, ya que ya existía una comparación de la velocidad de ejecución de consultas en alguna forma. El siguiente paso necesitaba información detallada sobre cada evento: por ejemplo, si el evento es una disputa de índice, entonces necesita comprender en qué índice realmente estamos colgados.
Luego me interesó en qué momento de estos eventos fueron más, ya que en la implementación hubo muchas tareas (trabajos) programadas y era necesario entender en qué momento todo se rompía en las costuras.
En general, esto es lo que quería obtener:
- comparación cuantitativa de eventos entre diferentes pruebas (sin sentadillas adicionales);
- toda la información relacionada que necesito para el análisis: sql_id, texto de consulta, distribución durante la prueba, qué objeto se refiere a las sesiones, módulo;
- filtros convenientes para usted para ver qué cambió;
- GUI GUI, todo es tan colorido que es visible de inmediato (puede examinar a las partes interesadas desde el lado del desarrollo)
- agrupación de módulos: como se describió anteriormente, 16237 módulos, pero, desde el punto de vista de las funciones realizadas, muchas veces menos.
Fred y yo hicimos un portal conveniente para nuestro uso para comparar los volcados de AWR de las pruebas de carga, que discutiremos con más detalle a continuación.
Sobre el portal
Por lo tanto, los volcados de AWR se crean en el sistema, que se vierten en la base de datos y se comparan en el portal.
Utilizamos la siguiente pila:
- Oracle DB: para almacenar volcados AWR
- Python 2+
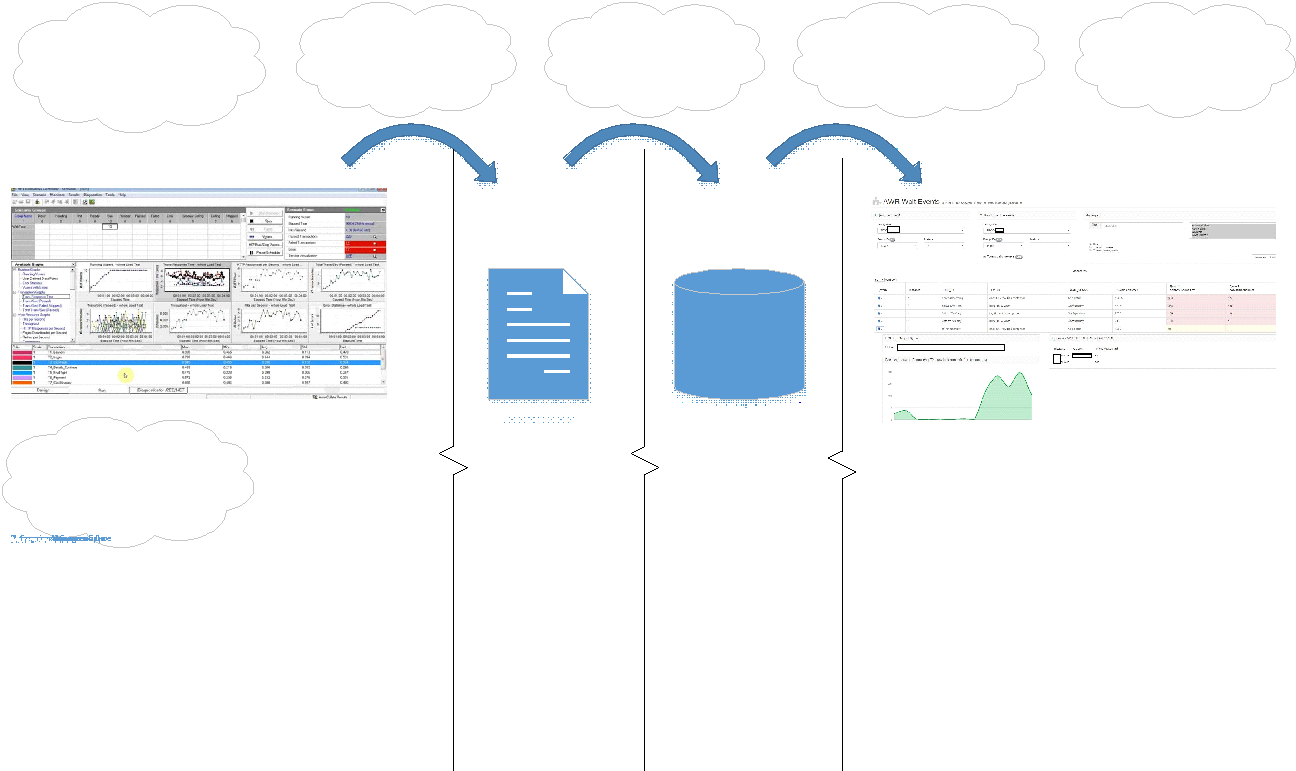
La interfaz del portal se ve así:

En el portal puede elegir los tipos de volcados comparados, prueba de prueba o test-prom.
Cada volcado tiene su propio identificador único: DBID.
También puede filtrar por los siguientes parámetros:
- Instancia (instancia): teníamos una base de datos de clúster;
- Solicitud (Sql_id);
- Tipo de espera (Wait_Class);
- El evento
En la parte superior izquierda, selecciona volcados, y a la derecha puede configurar los filtros necesarios para seleccionar inmediatamente el módulo deseado; esto le permite detectar problemas en la funcionalidad que se ha cambiado / mejorado para que no haya problemas de degradación en la versión anterior.
La tabla en el medio es el resultado de comparar los volcados. Los encabezados de las columnas muestran inmediatamente qué datos se están generando. Las dos columnas de la derecha muestran las diferencias entre los dos volcados:
- los eventos resaltados en rojo son más que en comparación con un volcado comparativo para la instantánea;
- amarillo - nuevos eventos;
- verde: eventos que ya estaban en el volcado original.
Es inmediatamente obvio lo bien que probamos. Si el evento ocurrió con mucha frecuencia, lo más probable es que:
- sobrecargado el sistema;
- o las condiciones para la ejecución de trabajos en segundo plano cambiaron y el evento comenzó a jugar con más frecuencia. Una vez de esta manera, se encontró un error en el código: el evento ocurrió constantemente, y no en la rama de condición deseada.
Si tenemos un nuevo evento, amarillo, entonces esto indica algún tipo de cambio en el sistema, y necesitamos analizar sus consecuencias. Aquí puede ver la distribución de eventos por instantáneas y mostrar información detallada sobre la espera.
Una vez que hubo un caso: se descubrió un nuevo evento que era bastante raro y no se incluía en los eventos principales, pero debido a ello hubo ralentizaciones en la funcionalidad, que tenía SLA críticos. El análisis de solo las principales consultas en el informe de AWR no pudo revelar esto.
Para cada solicitud, puede obtener información más detallada:
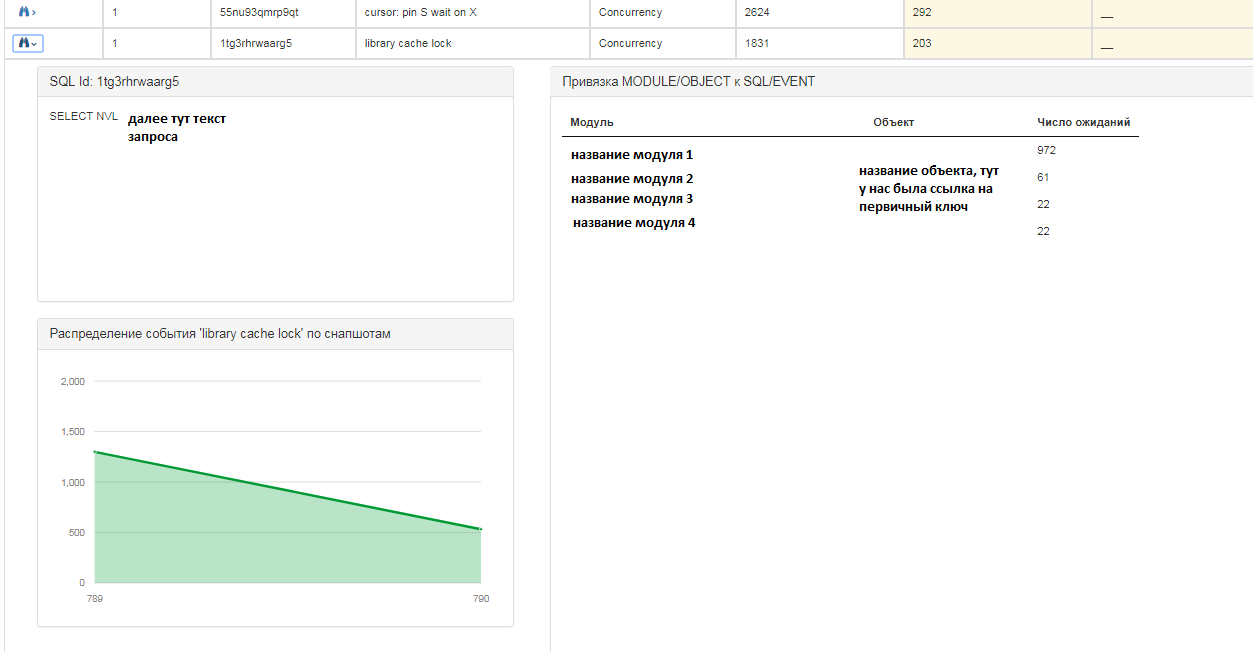
Para cada entrada, también puede ver la siguiente información:
- consulta de texto sql;
- la distribución de eventos en una instantánea en una proporción cuantitativa, es decir en qué momento hubo más / menos eventos;
- en qué módulos y objetos esperan los "colgantes".
Las vistas del sistema de Oracle están involucradas en la comparación de los resultados:
DBA_HIST_ACTIVE_SESS_HISTORY, DBA_HIST_SEG_STAT, DBA_HIST_SNAPSHOT, DBA_HIST_SQLTEXT
+
V_DUMPS_LOADED: su propia tabla de servicios (ya ha sido implementada por el cliente), contiene información sobre los volcados cargados.
Algunas consultas:
Distribución de eventos en imágenes:
SELECT S.SNAP_ID, COUNT(*) RCOUNT FROM DBA_HIST_ACTIVE_SESS_HISTORY S, V_DUMPS_LOADED V. WHERE V.ID = :1 AND S.DBID = V.DBID AND S.INSTANCE_NUMBER = :2 AND S.SQL_ID = :3 AND S.EVENT_ID = :4 GROUP BY S.SNAP_ID ORDER BY S.SNAP_ID ASC
Agrupación por módulo (los módulos que son un solo grupo lógico se combinan en él), bloqueando el objeto:
SELECT MODULE, OBJECT_NAME, COUNT(*) RCOUNT (SELECT CASE (WHEN INSTR(S.MODULE, ' 1')>0 THEN ' 1' WHEN INSTR(S.MODULE, ' 2')>0 THEN ' 2' … ELSE S.MODULE END) MODULE, O.OBJECT_NAME FROM DBA_HIST_ACTIVE_SESS_HISTORY S, V_DUMPS_LOADED V, DBA_HIST_SEG_STAT O WHERE V.ID = :1 AND S.DBID = V.DBID AND S.INSTANCE_NUMBER = :2 AND S.SQL_ID = :3 AND S.EVENT_ID = :4 AND S.CURRENT_OBJ
¿Qué obtuviste al final?
El portal nos permitió ahorrar tiempo comparando los volcados de AWR. La comparación manual tomó de 4 a 6 horas y ahora pasamos de 2 a 3 horas. Siempre tenemos la oportunidad de comparar rápidamente los resultados de diferentes pruebas entre ellos y con un basurero industrial, así como establecer los filtros que necesitamos ahora. Es decir, podemos comparar convenientemente los datos históricos entre nosotros, y no solo ver el resultado actual en línea.
Anteriormente, después de cada regresión, era necesario comparar los resultados en tablas históricas con consultas a la base de datos, ver informes de AWR, localizar la expectativa problemática (en qué módulo ocurre, qué veces sucedió, qué objeto colgó), de modo que al final podría conducir a un defecto en el equipo de desarrollo correcto. Y ahora solo seleccione los volcados para la comparación, configure los filtros, y los resultados de la comparación estarán listos de inmediato. También puede enviar a los desarrolladores un enlace al portal que indique el DBID del volcado de prueba, y ellos mismos serán filtrados por su módulo.
Solo tomó dos semanas crear el portal, porque una parte del mismo ya estaba lista: cargar los volcados en la base de datos. Por supuesto, tal solución de portal no es necesaria para ningún proyecto con una base de Oracle. Es útil para productos que se dividen en numerosos módulos con diferentes nombres. Para sistemas simples o para sistemas en los que no otorgaron importancia a completar el módulo, el portal será redundante.
Dado que el portal analiza las imágenes que se toman una vez en un período determinado, el portal no está completamente exento del monitoreo en línea de la base de datos, ya que algunos eventos pueden no ser capaces de entrar en la imagen.
Esta es una herramienta conveniente para analizar datos históricos de los resultados de las pruebas, pero puede ser útil en otras situaciones cuando se crean muchas imágenes y se deben verificar grandes volúmenes de datos. Gracias a la combinación de filtros y gráficos, puede ver inmediatamente ráfagas de eventos que en los informes normales de AWR (que no deben confundirse con los volcados) estarán ocultos en la información agrupada. Es suficiente seleccionar volcados para la comparación, establecer filtros, y los resultados de la comparación están listos de inmediato, o puede enviar un enlace a los desarrolladores en el portal que indique el DBID del volcado de prueba, ellos mismos serán filtrados por su módulo.
Si decide desarrollar un portal similar para su proyecto, seleccione el conjunto de filtros adecuado para usted. Si filtra de acuerdo con diferentes condiciones cada vez, será mucho más fácil hacer un filtro apropiado para esto.
La solución resultante todavía se puede finalizar, por ejemplo:
- comparar la duración de la solicitud;
- comparar planes de consulta;
- comparar solicitudes con el mismo plan, pero con texto diferente;
- descarga en informes de prueba (ejecución como documento de Word / Exel).
O, en general, dígale al portal que se conecte a la base de datos probada para que construya imágenes similares en línea utilizando vistas en memoria, y no solo datos históricos. Y guárdelos en su base de datos.
Hemos estado usando el portal por más de un año. Fred, muchas gracias!
Publicado por Lyudmila Matskus,
Jet Infosystems