Cada día, un número creciente de dispositivos crea más datos. Deben gestionarse en una variedad de puntos, y no en varios centros de datos centralizados en la nube. En otras palabras, el proceso de gestión va más allá de los límites de los centros de datos tradicionales y se traslada al lugar donde se crean los datos, a la periferia de la red, más cerca de los usuarios finales. Aquí, los datos son generados por varios sensores, cámaras, dispositivos y dispositivos de Internet de las cosas (IoT). Cuando los resultados de su trabajo se recopilan y procesan directamente en el límite de la red, se pueden analizar y usar mucho más rápido.

Según los
expertos de Gartner , para 2020, más del 50% de todos los datos generados por las empresas se procesarán fuera de los centros de datos tradicionales o del entorno de la nube (hoy esta cifra es solo del 10%). En esta arquitectura, funcionarán 5.600 millones de dispositivos de Internet de las cosas (IoT). Al mismo tiempo, los volúmenes de datos producidos por los dispositivos se calculan en terabytes y, a menudo, deben interpretarse y analizarse en tiempo real.
Para ayudar a los socios y clientes a explorar esta tendencia, Seagate se asoció con un consorcio de empresas especializadas en computación periférica y lanzó el informe
Data at the Edge . También utilizó los resultados de un
estudio realizado por IDC. El propósito del informe era ilustrar algunos de los problemas de datos que hoy son relevantes para las empresas y mostrar cómo las empresas administran mejor sus recursos de TI.
Computación periférica
“Los jugadores en el mercado de almacenamiento han pasado por varias etapas en el desarrollo de su negocio. Hace un par de décadas, las instalaciones de almacenamiento para sistemas de servidores se consideraban prometedoras, luego los centros de datos locales estaban en el centro de atención. Esto se reflejó en las líneas de productos de los proveedores: comenzaron a producir unidades para este segmento. Luego comenzó el desarrollo del almacenamiento en la nube, la computación en la nube. El siguiente paso es la computación periférica ", dice Alexander Malinin, director de la oficina de representación de Seagate en Rusia y la CEI. - Dado que hay muchos datos, y no solo los generan las personas, sino también las máquinas, enviar todo esto al centro de datos no siempre es óptimo. Tiene sentido hacer parte de los cálculos fuera de los centros de datos y transferir los resultados procesados al centro de datos. De hecho, esta es la creación de otro circuito de cálculos, donde los datos se acumulan, almacenan durante un tiempo, se procesan y transfieren al centro de datos principal para su posterior almacenamiento y acceso ".
A medida que miles de millones de dispositivos continúan conectándose a la red, recolectando y generando zettabytes de datos, los entornos de nube centralizados de hoy requieren soporte para una nueva arquitectura de TI periférica. Y al colocar los recursos informáticos, de red y de almacenamiento cerca de estos dispositivos, puede analizar los datos en el acto.
Debido al hecho de que los datos se someten a un procesamiento primario en el mismo lugar donde se crean, parte de las decisiones de gestión (por ejemplo, para ajustar el modo de funcionamiento de los equipos industriales) se pueden tomar localmente, con un mínimo retraso.
La periferia se puede ubicar en cualquier lugar: desde tiendas de fábricas hasta granjas, en los techos de las casas y en las torres de celdas, en cualquier vehículo en tierra, mar y aire. Al ser el límite externo de una red, a menudo se encuentra a cientos de kilómetros del centro de datos corporativo o en la nube más cercano y muy cerca de la fuente de datos.
Según un estudio de IDC, para 2020, el 45% de todos los datos generados por los dispositivos IoT se almacenarán y procesarán en o cerca de los segmentos fronterizos de la red. Hay muchos casos en los que es mejor mover el proceso informático a la periferia. Entonces, en “ciudades inteligentes”, procesar y analizar datos más cerca de su fuente reduce el tiempo de retraso y permite que varios servicios respondan más rápidamente a la situación.
En los sistemas de transporte inteligentes, la informática periférica le permite procesar información localmente, enviando solo los datos más importantes a la nube. Esta tecnología ya se está utilizando en sistemas de transporte inteligentes. Además, este enfoque mejora la seguridad y la eficiencia del transporte. Los automóviles autónomos deben responder instantáneamente a los datos recibidos, ya que incluso el más mínimo retraso puede ser peligroso.
La proliferación de la informática periférica requerirá una nueva infraestructura para almacenar y administrar datos. Por ejemplo, una fábrica inteligente creará unos 5 petabytes de video por día, una ciudad inteligente con una población de 1 millón de personas, 200 petabytes de datos diarios, y un automóvil autónomo, 4 terabytes.
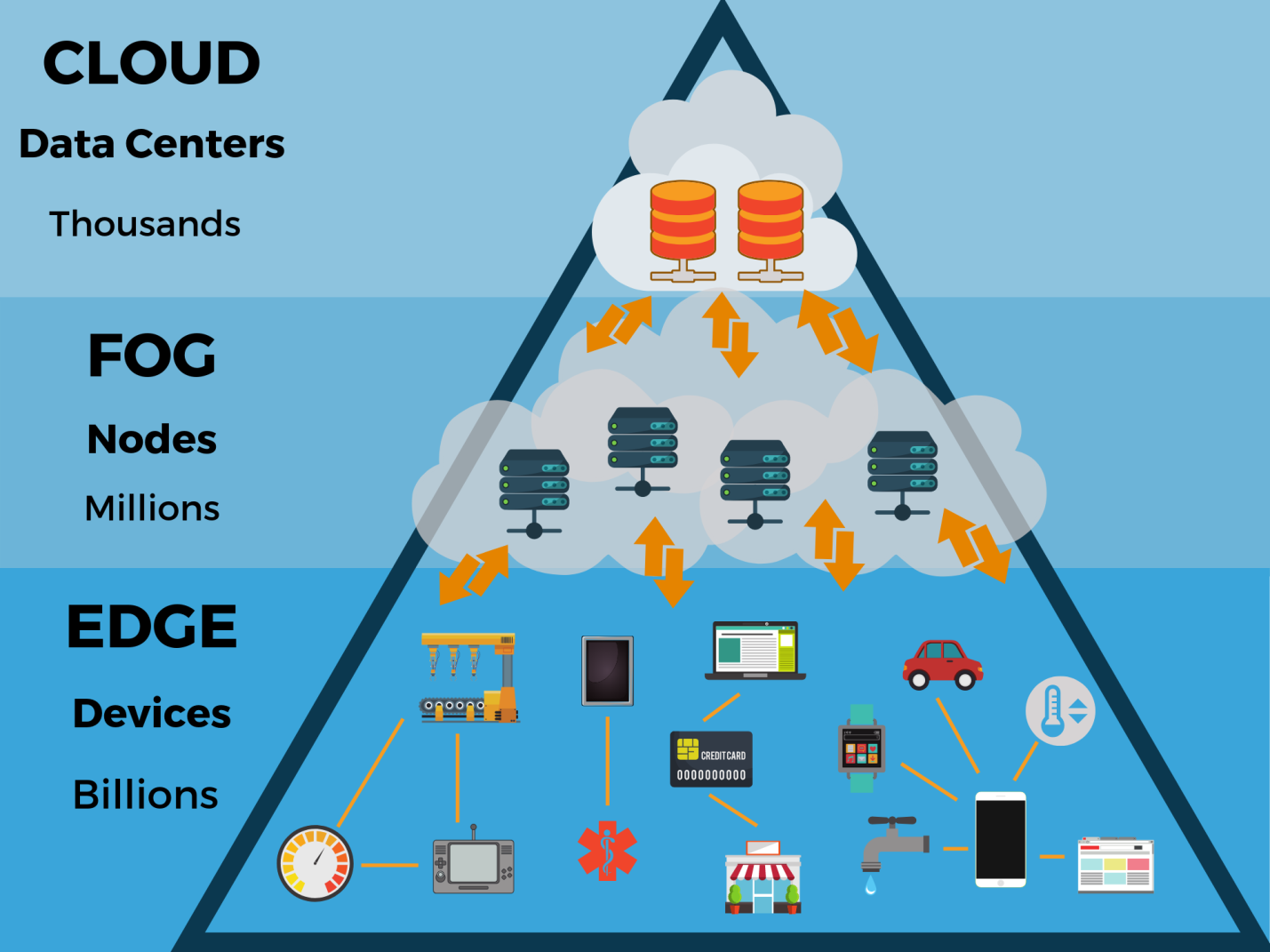
¿Qué significarán estos datos en la frontera? ¿Cómo afectará tal evolución a la estructura y el funcionamiento de los centros de datos existentes y los centros de datos en la nube? ¿Podría la computación en la nube, que prevalece hoy, suplantar a la computación periférica porque es más flexible y escalable en términos de aplicaciones?
Nubes y periféricos
Los autores del informe "
Datos en el borde " enfatizan que aunque la computación periférica permite un uso más eficiente de los datos, la infraestructura tradicional no perderá su importancia. A medida que se crearán grandes cantidades de datos fuera de los centros tradicionales de procesamiento, la nube se expandirá a la periferia. Es decir, no se trata del escenario "nube contra la periferia", sino más bien de la "nube con la periferia".
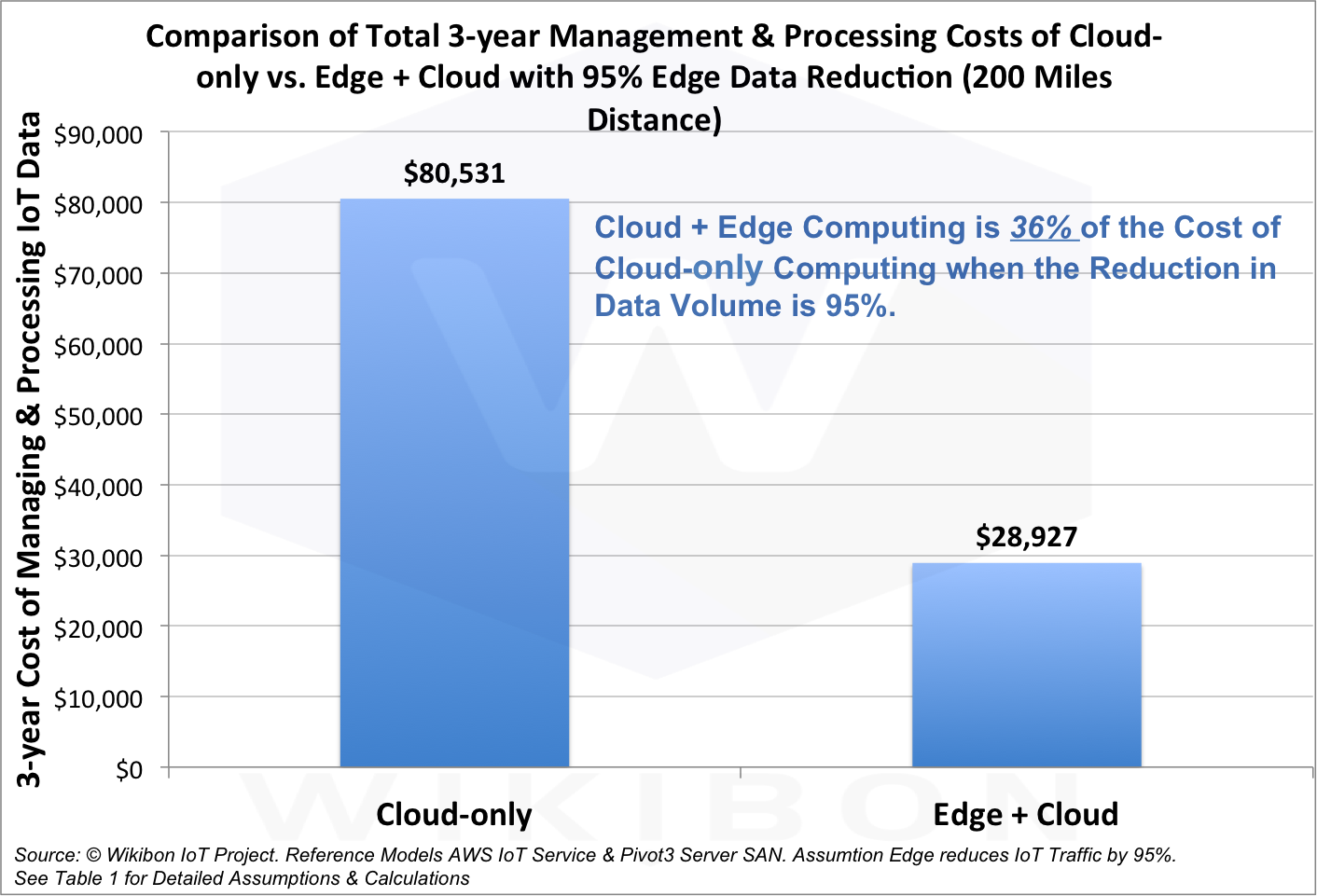
Según los analistas, la combinación de computación en la nube y periférica costará solo el 36% del costo de una versión puramente en la nube, y la cantidad de datos transmitidos se reducirá en un 95%.
Por lo tanto, el futuro reside en el trabajo conjunto de la periferia y la nube. Esto ayudará a las empresas a tomar decisiones más informadas al instante, aumentar su productividad, eficiencia laboral y satisfacer mejor las necesidades de los clientes.
Negocio basado en datos
Hoy en día, casi cualquier empresa u organización está asociada con el procesamiento y almacenamiento de datos. Las innovaciones en la gestión de la información allanaron el camino para formas más eficientes de usarlo. Esto también se aplica a los datos periféricos.
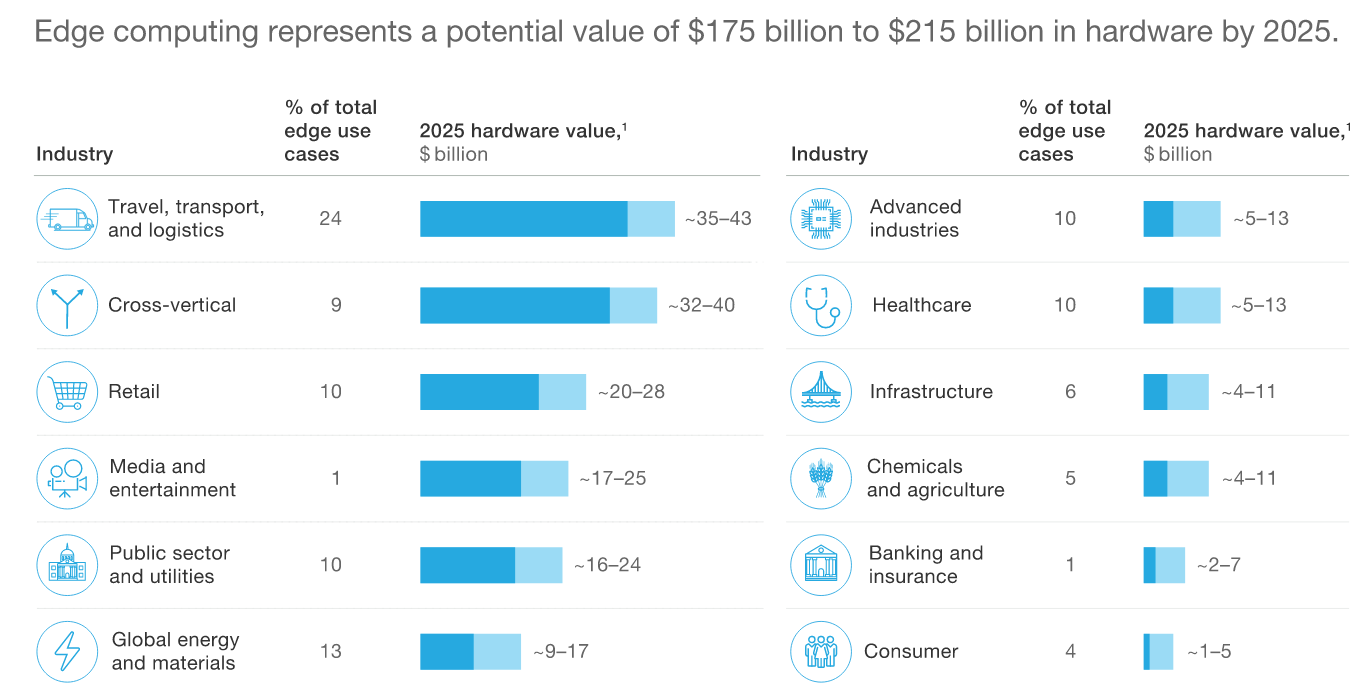
Según
McKinsey , el mercado global de equipos informáticos periféricos llegará a $ 175- $ 215 mil millones para 2025.
Periféricos y vida
¿Qué significa esto para las grandes empresas, ciudades, pequeñas empresas y consumidores individuales, cuáles son los beneficios? ¿Cómo los datos en la periferia nos ayudarán a trabajar mejor, relajarnos, vivir, viajar? ¿Qué oportunidades surgen para el análisis de datos en el borde de la red? Estas son las preguntas que responde el informe Seagate.
Data at the Edge proporciona varios ejemplos de cómo la informática periférica está transformando los negocios globales en la actualidad y beneficiando a las personas. Por ejemplo, en Chile, un sistema de riego con inteligencia artificial, equipado con sensores, reduce el consumo de agua en un 70%.
Pero lo que sucede en las propias fábricas de Seagate. La compañía produce millones de unidades trimestralmente y miles de millones de sensores anualmente. Esto requiere la introducción de procesos altamente automatizados, y el sistema debe tomar de 20 a 30 decisiones por segundo. A esta velocidad, no hay tiempo para esperar hasta que los datos recopilados en la línea de producción se envíen al centro para su procesamiento, y de allí saldrá una solución.

No podemos detener la línea de producción: debemos mantener el ritmo de producción y garantizar su alta calidad. Por lo tanto, las decisiones deben tomarse en el mismo lugar donde se generan los datos. Para hacer esto, Seagate creó su propia tecnología para detectar anomalías y analizar imágenes en el sitio de la fábrica. Esto reduce la latencia de cientos a menos de 10 milisegundos.
Computación periférica en Rusia
“¿Cuán ampliamente se usa la informática periférica en Rusia? En primer lugar, la introducción de cualquier nueva tecnología lleva tiempo. En segundo lugar, el término "computación periférica" en sí aún no se ha utilizado. Es decir, incluso si la compañía usa este enfoque, lo llama de manera diferente ", explica Alexander Malinin. - Mientras tanto, la informática periférica se usa a menudo, por ejemplo, en geodesia, en la industria del petróleo y el gas. Los datos topográficos se recopilan y procesan en un pequeño centro de datos local, y luego se envían a un repositorio centralizado. La computación periférica también se usa en la industria del petróleo y el gas, donde se recolecta una gran cantidad de datos y no es necesario almacenarlos todos ”.
"Con el desarrollo de las telecomunicaciones, con un aumento en la velocidad de transferencia de datos, la cantidad de centros de datos periféricos solo crecerá", continúa Alexander Malinin. - Sí, y el término "computación periférica" en sí estará más extendido. La industria del almacenamiento de datos tiene algo que ofrecer. Existen diversas tecnologías de almacenamiento que cumplen diferentes tareas, existen algoritmos matemáticos para el análisis de datos. El principal problema ahora está en las tecnologías de telecomunicaciones, en la obtención de datos. Por ejemplo, Internet de las cosas ofrece un uso generalizado de las conexiones inalámbricas. Esto requerirá el despliegue de redes inalámbricas, como 5G. Procesos similares tuvieron lugar con la introducción de la tecnología de big data. Ya comenzaron a usarlo, pero lo llamaron de manera diferente: es una cuestión de terminología ".
Factores de crecimiento
¿Qué impulsa la demanda de una nueva arquitectura informática? Basado en investigaciones y encuestas de ejecutivos de TI en Seagate, se identificaron
cuatro factores clave que determinan la demanda de computación periférica. Esto es latencia de red (latencia); ancho de banda insuficiente de los canales de comunicación para la entrega de grandes cantidades de datos al centro de datos; eficiencia y costo de la solución; soberanía y cumplimiento de datos.
1. Latencia
El factor número uno es la latencia. Debido a las limitaciones físicas de la infraestructura de TI y telecomunicaciones, lleva demasiado tiempo mover los datos desde donde se crearon al sitio central. Por lo tanto, la latencia se convierte en un factor clave: el envío de datos hacia y desde el sitio central puede llevar tanto 100 como 200 milisegundos.
2. Rendimiento
El factor número dos es el problema del ancho de banda. Los volúmenes de datos totales ya no son exabytes, sino zettabytes. Y continúan creciendo, aunque solo sea por la aparición de nuevos sensores, no solo de temperatura, clima, vibración u otros sensores que recopilan relativamente pocos datos, sino también cámaras, radares, lidares y otros dispositivos que generan mucha información. En el futuro, habrá aún más sensores de este tipo. La infraestructura 5G puede soportar millones de dispositivos por kilómetro cuadrado, pero ¿dónde puedo encontrar el ancho de banda para enviar todos los datos a un centro de datos centralizado en la nube?
3. Eficiencia
Tercero, eficiencia. Incluso si puede enviar todos los datos a un centro de datos centralizado, los costos y la complejidad de la arquitectura para procesar una cantidad de información tan grande serán tan grandes que el sistema estará mal administrado. Con un sistema que procesa datos de manera intensiva en la periferia, más cerca de la fuente, las cosas están mucho mejor.
4. Requisitos reglamentarios y normas corporativas.
Finalmente, el cuarto factor es el requisito de que los datos se procesen de acuerdo con las normas y estándares aceptados por los clientes. Cuando se trata de la seguridad de la información, a menudo no puede enviar datos desde una determinada región o país al extranjero para su procesamiento centralizado. Esto se aplica, por ejemplo, a la información personal.
"La informática periférica requerirá enfoques especiales para regular el almacenamiento de datos, para garantizar la seguridad, incluida la seguridad del acceso físico a los datos", enfatiza Alexander Malinin. "Pero definitivamente veremos un aumento en la informática periférica en los próximos dos o tres años, porque la cantidad de solicitudes de organizaciones para pequeños centros de datos está creciendo, lo que serviría tanto a las industrias individuales como a las grandes empresas nacionales". Es decir, el número de solicitudes para organizar el almacenamiento local de datos está creciendo ".
Nueva arquitectura
¿Qué significa esto para los arquitectos de TI, qué deberían hacer de manera diferente? Para empezar, el diseño de la infraestructura tradicional de un centro de datos o centro de datos en la nube es muy diferente del desarrollo de la arquitectura periférica. Los centros de datos tradicionales incluyen sistemas de refrigeración y aire acondicionado, fuentes de alimentación ininterrumpidas dobles redundantes y sistemas de seguridad física. Son atendidos por todo un equipo de especialistas.
El centro de datos periférico (o más bien, el nodo) del procesamiento de datos puede ubicarse en una torre de telecomunicaciones o en una habitación pequeña. A menudo está expuesto al entorno externo, por lo que su control climático es una tarea difícil.
En lo que respecta a la seguridad física, la arquitectura tendrá que incorporar protección especial de datos en caso de desastres naturales o actos maliciosos. Además, debido a la falta de personal que puede venir y arreglar todo rápidamente, los sistemas periféricos deben ser especialmente confiables. Si sucede algo, el centro de datos periférico debería recuperarse y continuar trabajando.
En otras palabras, si pretendemos procesar datos en la periferia, necesitamos perfeccionar la funcionalidad del centro de datos: refrigeración, seguridad, etc. Los arquitectos de sistemas ya están trabajando para encontrar soluciones. El objetivo es simplificar los centros de datos periféricos y proporcionar suficiente telemetría.
Además, algunos de los datos que se procesarán en la periferia no permanecerán allí. Irán al centro para un análisis posterior o para un almacenamiento más prolongado. Se requiere que un arquitecto de TI piense en este proceso definiendo una estrategia de gestión de datos.
Las organizaciones deberán confiar en su arquitectura de computación en la nube, aprender a procesar y, lo más importante, almacenar de forma segura más datos en el borde.
El
informe de datos periféricos de Seagate y Vapor IO dice que cada organización tiene un valor que ni siquiera sospecha. Esta es su propia información. La forma en que creamos datos y trabajamos con la periferia de la red le da un significado especial. Para seguir creciendo, las empresas deben aprovechar esto.
“Los problemas de implementar la informática periférica ahora se reducen principalmente a las telecomunicaciones, a la velocidad de acceso a los datos. Cuanto más rápido comience la introducción de las tecnologías de telecomunicaciones de próxima generación en Rusia, más rápido se desarrollará la informática periférica ”, dice Alexander Malinin. - Al mismo tiempo, la informática periférica se desarrollará en paralelo con los centros de datos existentes y los complementará. No se requiere una reestructuración radical ".
Gartner predice que para 2021, el 40% de las empresas en el mundo desarrollarán estrategias de computación periférica a gran escala. Por lo tanto, los proveedores ahora tienen prisa por ocupar un nicho prometedor. En los próximos cinco años, el mercado se formará activamente, aparecerán nuevas plataformas y soluciones llave en mano que se centrarán en diversas tareas e industrias. Las empresas que se dedican al desarrollo de la informática periférica podrán convertirse en líderes en nuevas áreas de negocio.