Zabbix es un sistema de monitoreo. Al igual que cualquier otro sistema, se enfrenta a tres problemas principales de todos los sistemas de monitoreo: recopilación y procesamiento de datos, almacenamiento del historial y su limpieza.
Los pasos para adquirir, procesar y registrar datos llevan tiempo. No mucho, pero para un sistema grande esto puede ocasionar grandes retrasos. El problema de almacenamiento es un problema de acceso a datos. Se utilizan para informes, comprobaciones y disparadores. Los retrasos en el acceso a los datos también afectan el rendimiento. Cuando la base de datos crece, se deben eliminar los datos irrelevantes. La eliminación es una operación difícil que también consume algunos de los recursos.

Los problemas de demoras durante la recolección y el almacenamiento en Zabbix se resuelven mediante el almacenamiento en caché: varios tipos de cachés, almacenamiento en caché en la base de datos. Para resolver el tercer problema, el almacenamiento en caché no es adecuado, por lo tanto, Zabbix usó TimescaleDB.
Andrey Gushchin , ingeniero de soporte técnico en
Zabbix SIA, hablará sobre esto. Andrey ha estado apoyando a Zabbix durante más de 6 años y se enfrenta directamente al rendimiento.
¿Cómo funciona TimescaleDB, qué rendimiento puede ofrecer en comparación con PostgreSQL normal? ¿Qué papel juega Zabbix en TimescaleDB? ¿Cómo ejecutar desde cero y cómo migrar con PostgreSQL y qué rendimiento es mejor? Sobre todo esto bajo el corte.
Retos de rendimiento
Cada sistema de monitoreo enfrenta desafíos de desempeño específicos. Hablaré de tres de ellos: recopilar y procesar datos, almacenar, limpiar el historial.
Rápida recopilación y procesamiento de datos. Un buen sistema de monitoreo debería recibir rápidamente todos los datos y procesarlos de acuerdo con las expresiones de activación, de acuerdo con sus propios criterios. Después del procesamiento, el sistema también debe guardar rápidamente estos datos en la base de datos para usarlos más tarde.
Manteniendo una historia. Un buen sistema de monitoreo debe almacenar el historial en la base de datos y proporcionar un acceso conveniente a las métricas. Se necesita una historia para usarla en informes, gráficos, disparadores, umbrales y elementos de datos calculados para alertas.
Claro historial. A veces llega un día en que no necesita almacenar métricas. ¿Por qué necesita los datos que se recopilaron hace 5 años, un mes o dos: algunos nodos se eliminan, algunos hosts o métricas ya no son necesarios, porque están desactualizados y dejaron de recopilarse. Un buen sistema de monitoreo debe almacenar datos históricos y eliminarlos de vez en cuando para que la base de datos no crezca.
La eliminación de datos obsoletos es un tema candente que tiene un gran impacto en el rendimiento de la base de datos.
Almacenamiento en caché de Zabbix
En Zabbix, la primera y la segunda llamada se resuelven mediante el almacenamiento en caché. RAM se utiliza para la recopilación y el procesamiento de datos. Para almacenamiento: historias en disparadores, gráficos y elementos de datos calculados. En el lado de la base de datos, hay un cierto almacenamiento en caché para las muestras principales, por ejemplo, gráficos.
El almacenamiento en caché en el lado del servidor Zabbix es:
- ConfigurationCache;
- ValueCache;
- HistoryCache;
- TrendsCache.
Consideremos con más detalle.
Caché de configuración
Este es el caché principal en el que almacenamos métricas, hosts, elementos de datos, disparadores: todo lo que se necesita para el preprocesamiento y la recopilación de datos.
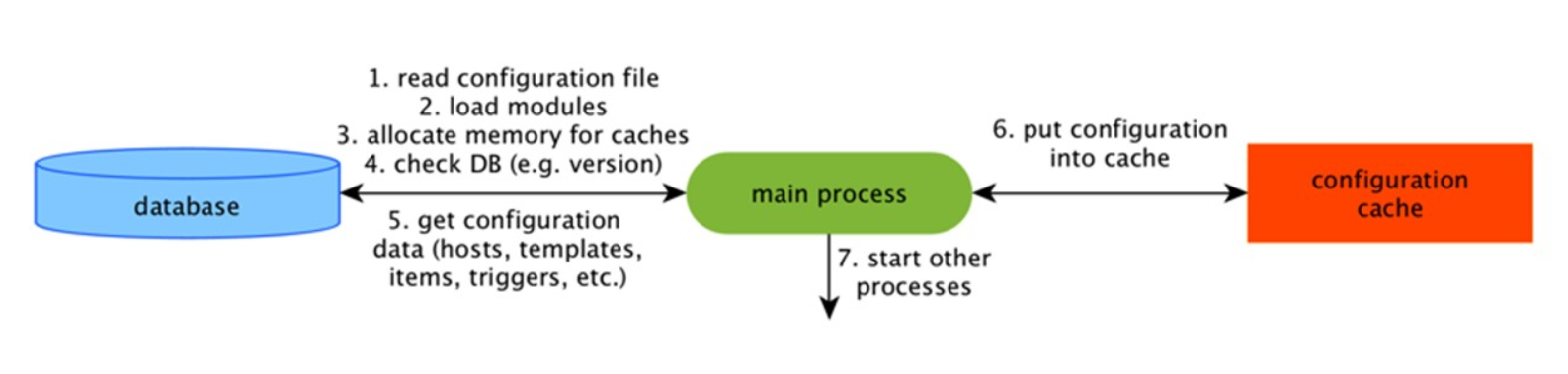
Todo esto se almacena en ConfigurationCache para no crear consultas innecesarias en la base de datos. Después de que se inicia el servidor, actualizamos este caché, creamos y actualizamos periódicamente las configuraciones.
Recogida de datos
El esquema es bastante grande, pero lo principal son los
ensambladores . Estos son los diversos "sondeadores" - procesos de ensamblaje. Son responsables de los diferentes tipos de ensamblaje: recopilan datos a través de SNMP, IPMI y los transfieren a Preprocesamiento.
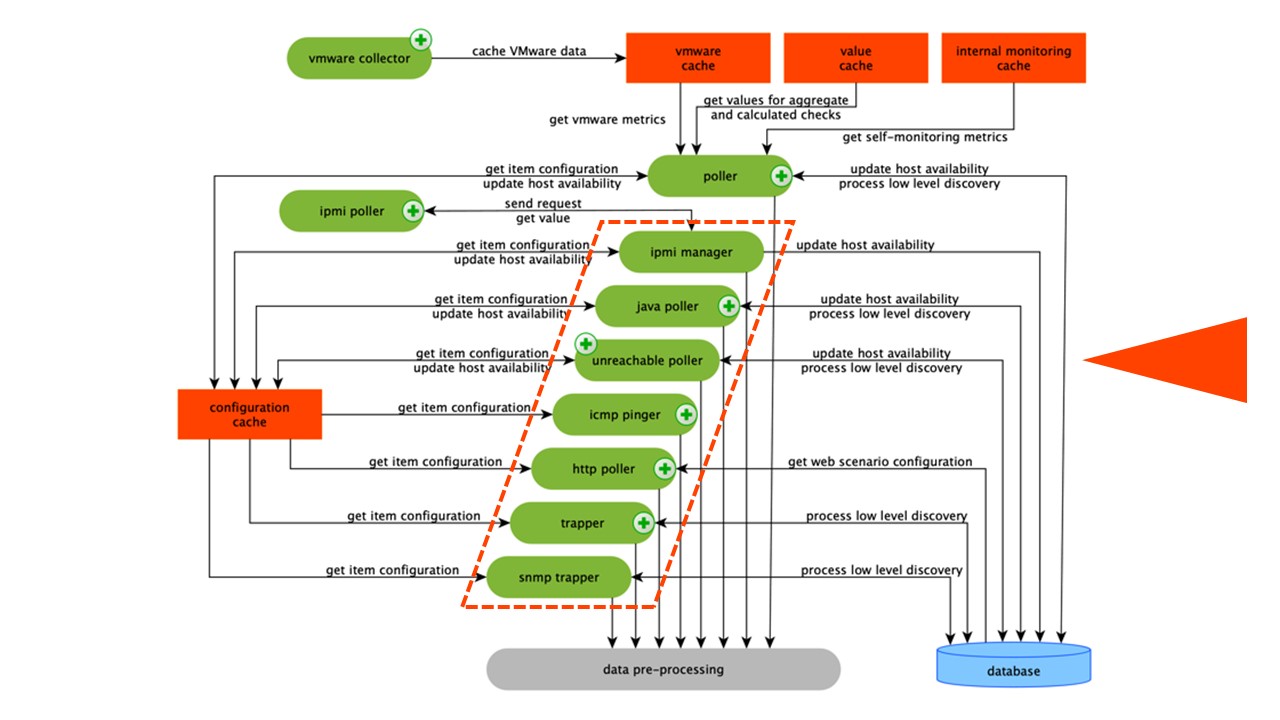 Los coleccionistas están rodeados en naranja.
Los coleccionistas están rodeados en naranja.Zabbix ha calculado elementos de datos de agregación que son necesarios para agregar validaciones. Si los tenemos, tomamos los datos directamente de ValueCache.
Historial de preprocesamiento
Todos los recopiladores usan ConfigurationCache para recibir trabajos. Luego los pasan a Preprocesamiento.

El procesamiento previo utiliza ConfigurationCache para recibir los pasos de procesamiento previo. Procesa estos datos de varias maneras.
Después de procesar los datos usando PreProcessing, los guardamos en HistoryCache para procesarlos. Esto finaliza la recopilación de datos y pasamos al proceso principal en Zabbix:
sincerizador de historia , ya que es una arquitectura monolítica.
Nota: El preprocesamiento es una operación bastante difícil. Desde v 4.2, se ha enviado a proxy. Si tiene un Zabbix muy grande con una gran cantidad de elementos de datos y una frecuencia de recopilación, esto facilita enormemente el trabajo.Caché de ValueCache, historial y tendencias
El sincerizador de historia es el proceso principal que procesa atómicamente cada elemento de datos, es decir, cada valor.
El sincronizador de historial toma valores de HistoryCache y verifica en Configuración los activadores para los cálculos. Si lo son, se calcula.
El sincronizador de historial crea un evento, escalada para crear alertas, si la configuración lo requiere, y registros. Si hay desencadenantes para el procesamiento posterior, entonces recuerda este valor en ValueCache para no acceder a la tabla del historial. Entonces ValueCache está lleno de datos que son necesarios para calcular los desencadenantes, los elementos calculados.
History Syncer escribe todos los datos en la base de datos, y se escribe en el disco. El proceso de procesamiento termina aquí.
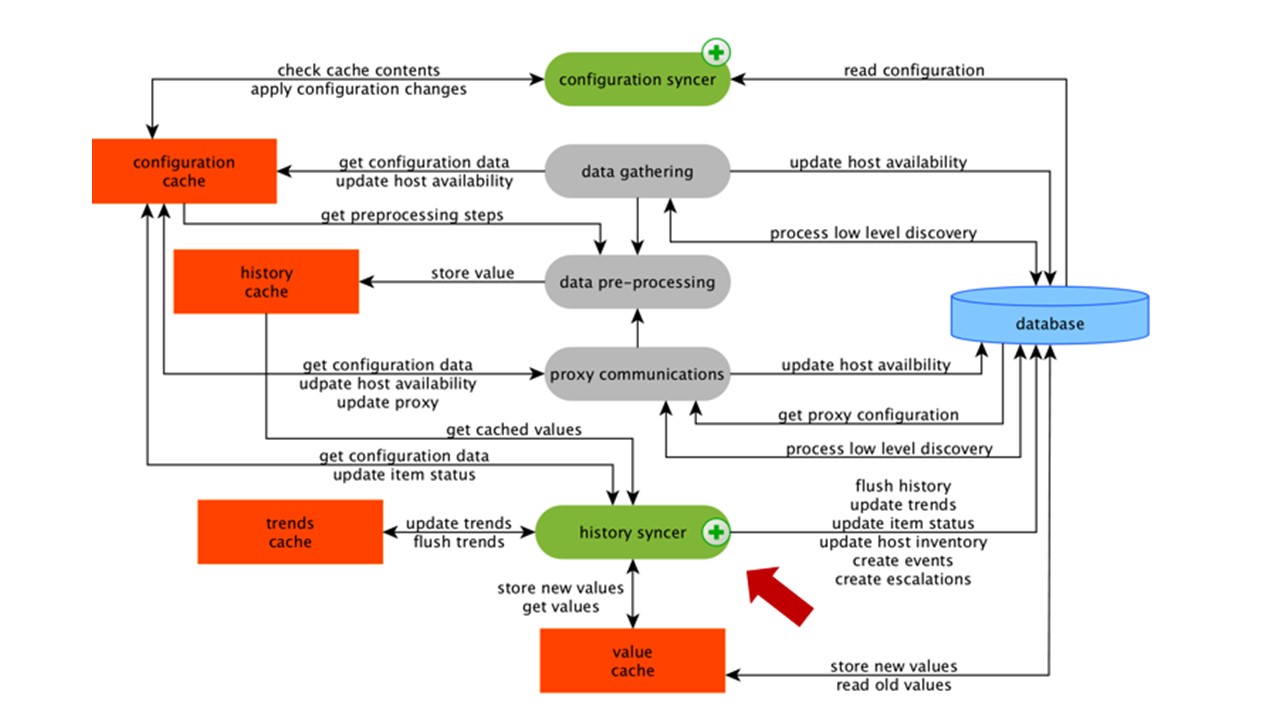
Almacenamiento en caché de DB
En el lado de la base de datos, hay varios cachés cuando desea ver gráficos o informes de eventos:
Innodb_buffer_pool en el lado de MySQL;shared_buffers en el lado de PostgreSQL;effective_cache_size en el lado de Oracle;shared_pool en el lado de DB2.
Hay muchos otros cachés, pero estos son los principales para todas las bases de datos. Le permiten mantener en la memoria los datos que a menudo se necesitan para las consultas. Tienen sus propias tecnologías para esto.
El rendimiento de la base de datos es crítico
El servidor Zabbix recopila constantemente datos y los escribe. Al reiniciar, también lee del historial para completar ValueCache. Los scripts y los informes utilizan la
API de Zabbix , que se basa en la interfaz web. La API de Zabbix se pone en contacto con la base de datos y recibe los datos necesarios para gráficos, informes, listas de eventos y problemas recientes.
Para visualización -
Grafana . Entre nuestros usuarios, esta es una solución popular. Puede enviar solicitudes directamente a través de la API de Zabbix y a la base de datos, y crea una cierta competitividad para recibir datos. Por lo tanto, necesitamos un ajuste más fino y mejor de la base de datos para que se corresponda con la salida rápida de resultados y pruebas.
Ama de llaves
El tercer desafío de rendimiento en Zabbix es limpiar la historia con Housekeeper. Sigue todos los ajustes: los elementos de datos indican cuánto mantener la dinámica de los cambios (tendencias) en días.
Calculamos TrendsCache sobre la marcha. Cuando llegan los datos, los agregamos en una hora y los escribimos en tablas para la dinámica de los cambios de tendencia.
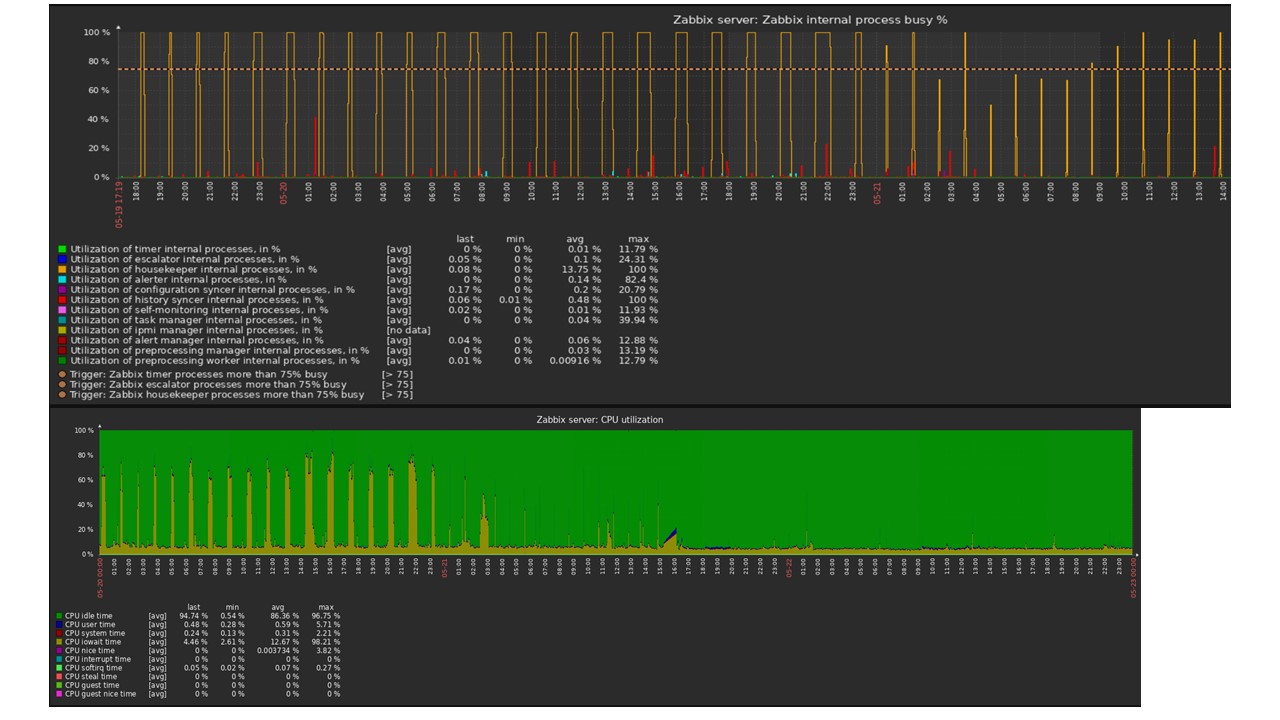
Housekeeper inicia y elimina la información de la base de datos con las "selecciones" habituales. Esto no siempre es efectivo, lo que puede entenderse a partir de los gráficos de rendimiento de los procesos internos.
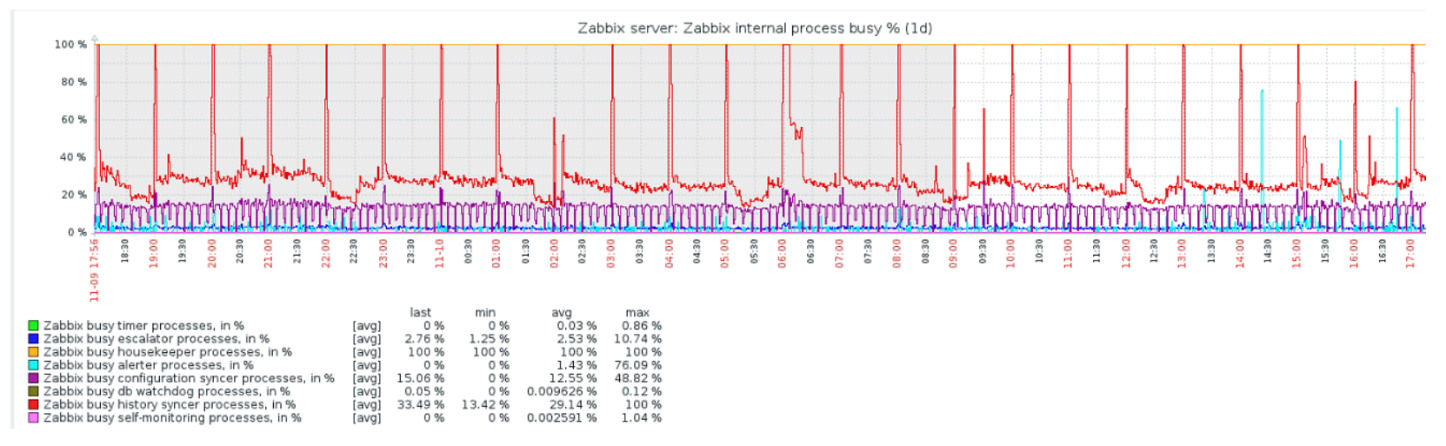
Un gráfico rojo indica que el sincronizador de Historial está constantemente ocupado. El cuadro naranja anterior es Housekeeper, que se ejecuta constantemente. Espera que la base de datos elimine todas las filas que especificó.
¿Cuándo apagar Housekeeper? Por ejemplo, hay un "ID de artículo" y debe eliminar las últimas 5 mil líneas en un momento determinado. Por supuesto, esto sucede por índice. Pero, por lo general, el conjunto de datos es muy grande y la base de datos aún lee del disco y lo eleva al caché. Esta es siempre una operación muy costosa para la base de datos y, dependiendo del tamaño de la base de datos, puede generar problemas de rendimiento.
El ama de llaves es solo una desconexión. En la interfaz web hay una configuración en "Administración general" para Housekeeper. Deshabilite la limpieza interna para el historial de tendencias interno y ya no lo gestiona.
El ama de llaves se apagó, los gráficos se nivelaron: ¿cuál podría ser el problema en este caso y qué puede ayudar a resolver el tercer desafío de rendimiento?
Particionamiento - particionamiento o particionamiento
Por lo general, la partición se configura de manera diferente en cada base de datos relacional que he enumerado. Cada uno tiene su propia tecnología, pero son similares, en general. Crear una nueva partición a menudo conduce a ciertos problemas.
Las particiones generalmente se configuran en función de la "configuración": la cantidad de datos que se crean en un día. Como regla general, la partición se expone en un día, esto es un mínimo. Para conocer las tendencias de la nueva partición, durante 1 mes.
Los valores pueden cambiar en el caso de una "configuración" muy grande. Si la "configuración" pequeña es de hasta 5,000 nvps (nuevos valores por segundo), el promedio es de 5,000 a 25,000, entonces el grande es superior a 25,000 nvps. Estas son instalaciones grandes y muy grandes que requieren una configuración cuidadosa de la base de datos.
En instalaciones muy grandes, una ejecución de un día puede no ser óptima. Vi en particiones MySQL de 40 GB o más por día. Esta es una cantidad muy grande de datos que puede generar problemas y debe reducirse.
¿Qué da el particionamiento?
Tablas de partición . A menudo, estos son archivos separados en el disco. El plan de consulta selecciona de manera más óptima una partición. La partición generalmente se usa en un rango; para Zabbix esto también es cierto. Usamos allí "marca de tiempo" - tiempo desde el comienzo de la era. Tenemos numeros ordinarios. Establece el comienzo y el final del día: esta es una partición.
Eliminación rápida :
DELETE . Se selecciona un único archivo / subtabla, no una selección de filas para eliminar.
Acelera visiblemente la recuperación de datos SELECT : utiliza una o más particiones, no toda la tabla. Si solicita datos hace dos días, se seleccionan de la base de datos más rápido porque necesita cargarlos en la memoria caché y emitir solo un archivo, no una tabla grande.
A menudo, muchas bases de datos también aceleran las inserciones
INSERT en la tabla secundaria.
Timescaledb
Para la versión 4.2, dirigimos nuestra atención a TimescaleDB. Esta es una extensión para PostgreSQL con una interfaz nativa. La extensión funciona eficazmente con datos de series temporales, sin perder los beneficios de las bases de datos relacionales. TimescaleDB también se particiona automáticamente.
TimescaleDB tiene el concepto de
hipertensión que creas. Contiene
trozos - particiones. Los fragmentos son fragmentos controlados automáticamente de un hipertable que no afectan a otros fragmentos. Cada fragmento tiene su propio rango de tiempo.
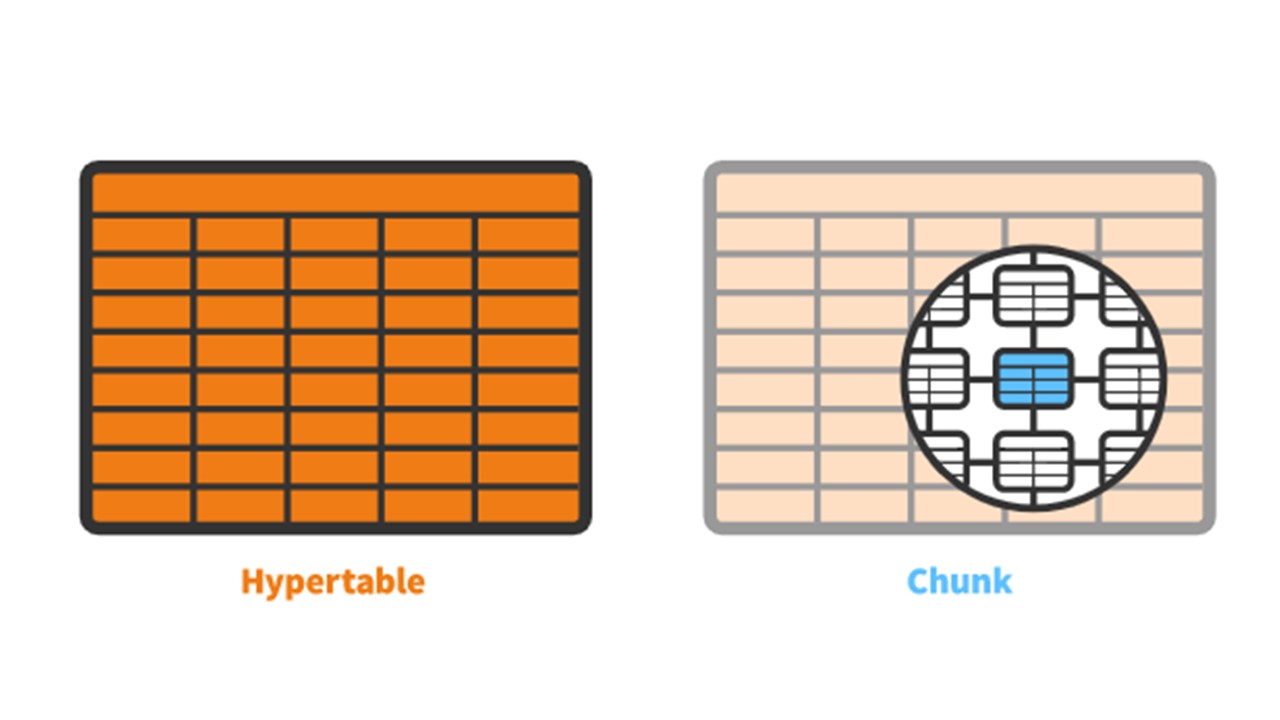
TimescaleDB vs PostgreSQL
TimescaleDB funciona de manera realmente eficiente. Los fabricantes de extensiones afirman que utilizan un algoritmo de procesamiento de solicitudes más correcto, en particular, <code> insertos </code>. Cuando las dimensiones de la inserción del conjunto de datos crecen, el algoritmo mantiene un rendimiento constante.
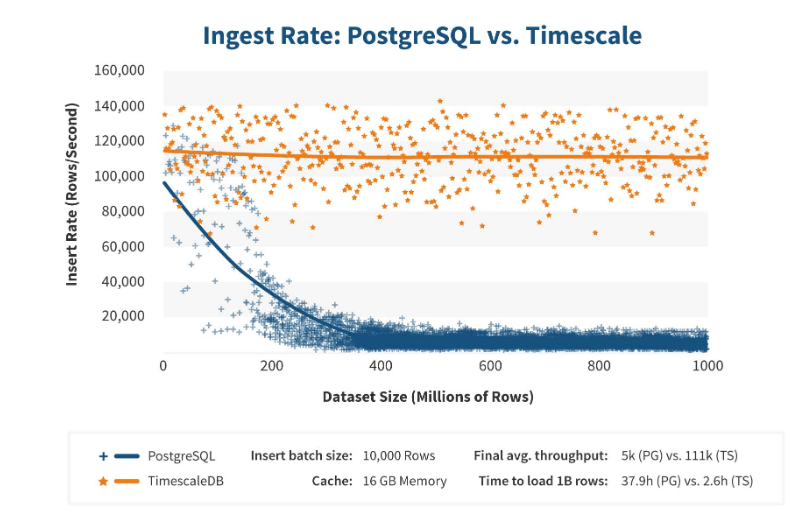
Después de 200 millones de filas, PostgreSQL generalmente comienza a caer mucho y pierde rendimiento hasta 0. TimescaleDB le permite insertar eficientemente "inserciones" para cualquier cantidad de datos.
Instalación
Instalar TimescaleDB es bastante fácil para cualquier paquete. La
documentación describe todo en detalle: depende de los paquetes oficiales de PostgreSQL. TimescaleDB también se puede compilar y compilar manualmente.
Para la base de datos Zabbix, simplemente activamos la extensión:
echo "CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;" | sudo -u postgres psql zabbix
Activa la
extension y la crea para la base de datos Zabbix. El último paso es crear un hipertable.
Migración de tablas de historial a TimescaleDB
Hay una función especial
create_hypertable :
SELECT create_hypertable('history', 'clock', chunk_time_interval => 86400, migrate_data => true); SELECT create_hypertable('history_unit', 'clock', chunk_time_interval => 86400, migrate_data => true); SELECT create_hypertable('history_log', 'clock', chunk_time_interval => 86400, migrate_data => true); SELECT create_hypertable('history_text', 'clock', chunk_time_interval => 86400, migrate_data => true); SELECT create_hypertable('history_str', 'clock', chunk_time_interval => 86400, migrate_data => true); SELECT create_hypertable('trends', 'clock', chunk_time_interval => 86400, migrate_data => true); SELECT create_hypertable('trends_unit', 'clock', chunk_time_interval => 86400, migrate_data => true); UPDATE config SET db_extension='timescaledb', hk_history_global=1, hk_trends_global=1
La función tiene tres parámetros. La primera es una
tabla en la base de
datos para la que necesita crear una hipertable. El segundo es el
campo mediante el cual se crea
chunk_time_interval , el intervalo de los fragmentos de particiones que desea usar. En mi caso, el intervalo es de un día: 86.400.
El tercer parámetro es
migrate_data . Si se establece en
true , todos los datos actuales se transfieren a fragmentos previamente creados. Yo mismo usé
migrate_data . Tenía alrededor de 1 TB, que tardó más de una hora. Incluso en algunos casos, durante las pruebas, eliminé los datos históricos de los tipos de caracteres que eran opcionales para el almacenamiento, a fin de no transferirlos.
El último paso es
UPDATE : configuramos
db_extension en
db_extension para que la base de datos comprenda que existe esta extensión. Zabbix lo activa y usa correctamente la sintaxis y las consultas que ya se encuentran en la base de datos, esas características que son necesarias para TimescaleDB.
Configuración de hierro
Usé dos servidores. El primero es una
máquina VMware . Es lo suficientemente pequeño: 20 procesadores Intel® Xeon® E5-2630 v 4 @ 2.20GHz, 16 GB de RAM y un SSD de 200 GB.
Instalé PostgreSQL 10.8 con Debian 10.8-1.pgdg90 + 1 y el sistema de archivos xfs. Configuré todo mínimamente para usar esta base de datos en particular, menos lo que Zabbix usará.
En la misma máquina había un servidor Zabbix, PostgreSQL y
agentes de carga . Tenía 50 agentes activos que usaban
LoadableModule para generar rápidamente varios resultados: números, cadenas. Atasqué la base de datos con muchos datos.
Inicialmente, la configuración contenía
5.000 elementos de datos por host. Casi todos los elementos contenían un disparador, por lo que era similar a las instalaciones reales. En algunos casos, hubo más de un desencadenante. Hubo
3,000-7,000 disparadores por nodo de red.
El intervalo para actualizar los elementos de datos es de
4 a 7 segundos . Regulé la carga en sí usando no solo 50 agentes, sino también agregando más. Además, con la ayuda de elementos de datos, ajusté dinámicamente la carga y reduje el intervalo de actualización a 4 s.
PostgreSQL 35,000 nvps
La primera ejecución en este hardware la tuve en PostgreSQL puro: 35 mil valores por segundo. Como puede ver, la inserción de datos toma fracciones de segundo: todo está bien y es rápido. Lo único que un SSD de 200 GB se está llenando rápidamente.
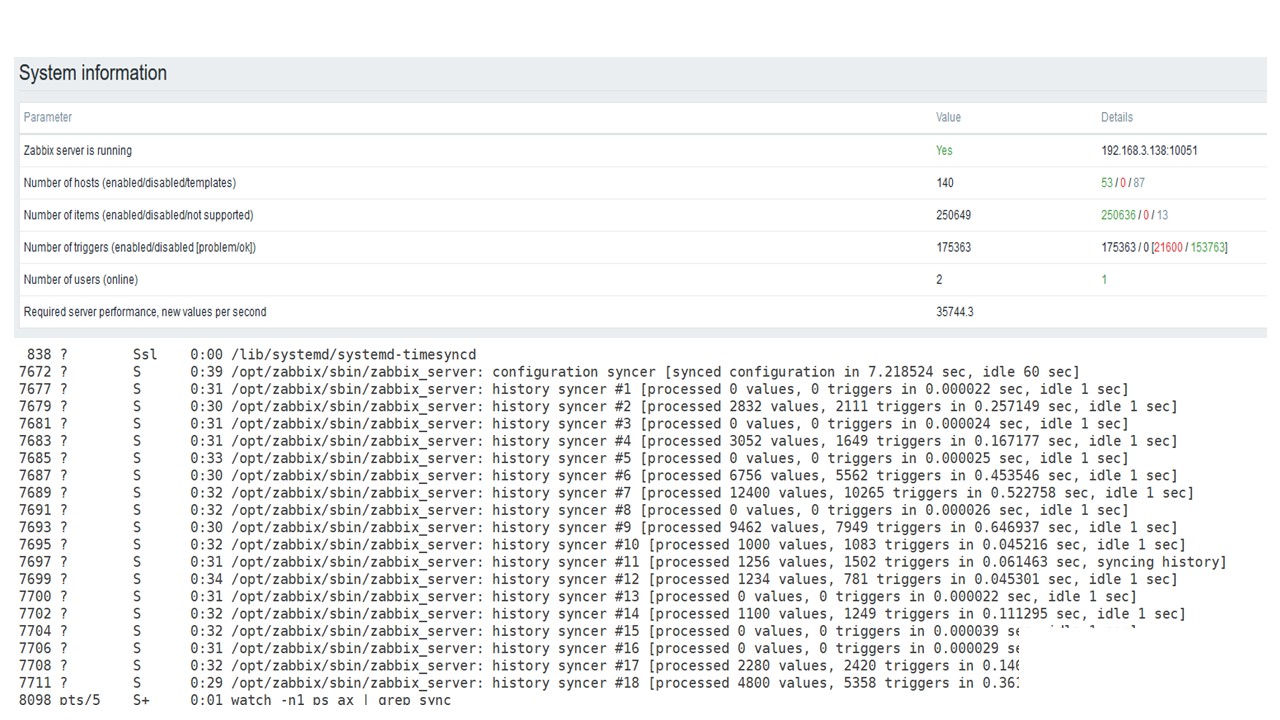
Este es el panel de rendimiento estándar del servidor Zabbix.
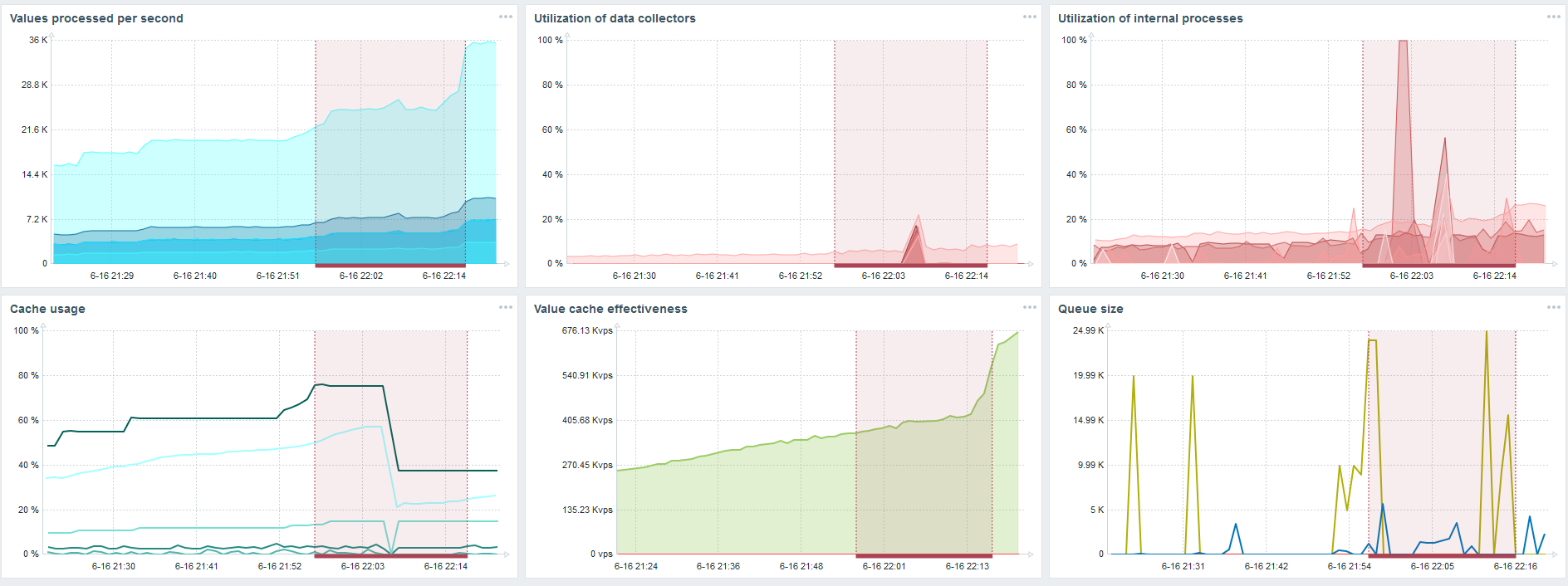
El primer gráfico azul es el número de valores por segundo. El segundo gráfico de la derecha es la carga de los procesos de ensamblaje. El tercero es cargar los procesos internos de ensamblaje: sincerizadores de historia y Housekeeper, que ha estado funcionando durante bastante tiempo aquí.
El cuarto gráfico muestra el uso de HistoryCache. Este es un búfer antes de insertarlo en la base de datos. El quinto gráfico verde muestra el uso de ValueCache, es decir, cuántos hits de ValueCache para los desencadenantes son varios miles de valores por segundo.
PostgreSQL 50,000 nvps
Luego aumenté la carga a 50 mil valores por segundo en el mismo hardware.
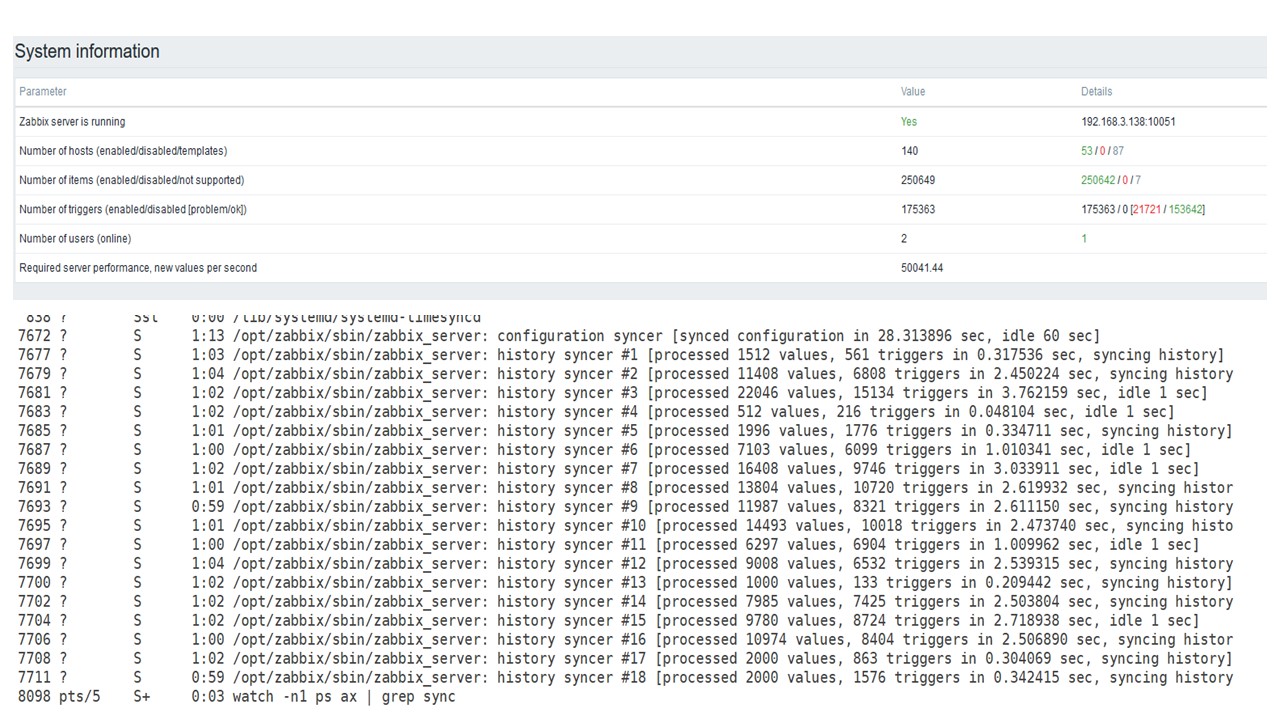
Al cargar desde Housekeeper, se registró una inserción de 10 mil valores durante 2-3 s.
 El ama de llaves ya está comenzando a interferir.
El ama de llaves ya está comenzando a interferir.El tercer gráfico muestra que, en general, la carga de tramperos y sincronizadores de historia todavía está en 60%. En el cuarto gráfico, HistoryCache ya comienza a llenarse de manera bastante activa durante el trabajo de Housekeeper. Está lleno al 20%, es de aproximadamente 0,5 GB.
PostgreSQL 80,000 nvps
Luego aumenté la carga a 80 mil valores por segundo. Estos son aproximadamente 400 mil elementos de datos y 280 mil disparadores.
 La inserción para cargar treinta sincronizadores de historia ya es bastante alta.
La inserción para cargar treinta sincronizadores de historia ya es bastante alta.También aumenté varios parámetros: sincerizadores de historia, cachés.
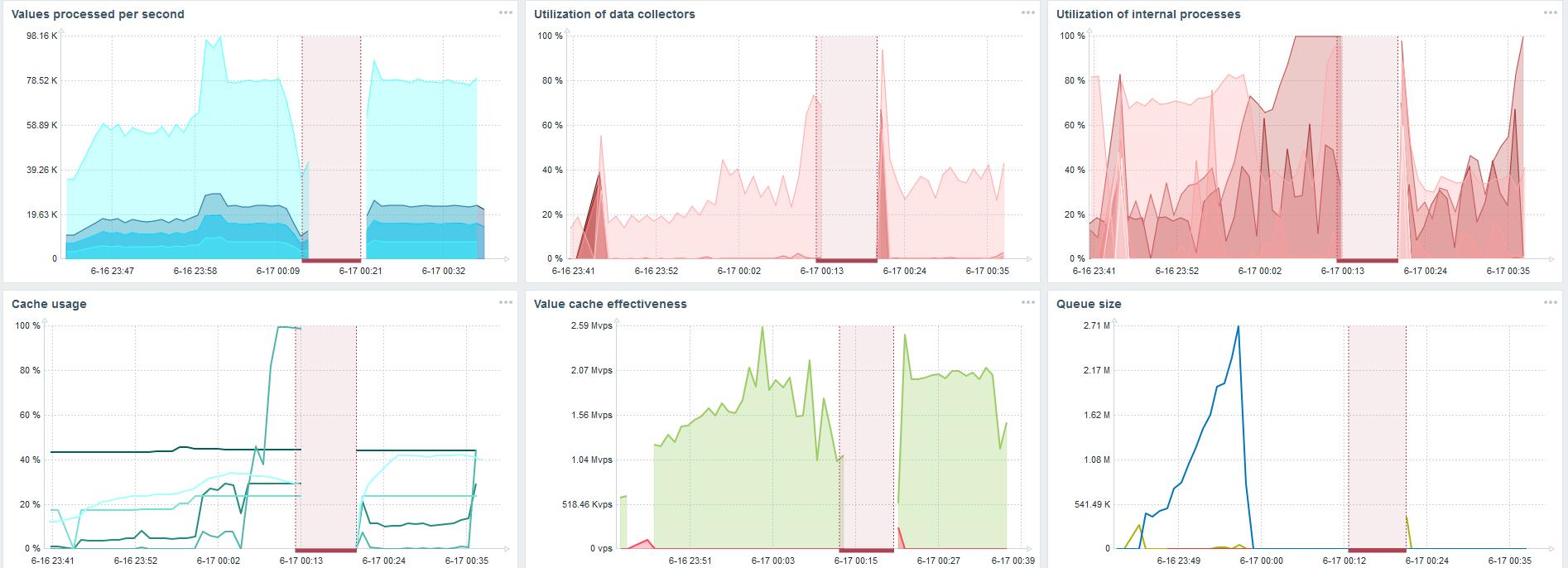
En mi hardware, la carga de sincronizadores de historia aumentó al máximo. HistoryCache se llenó rápidamente de datos: los datos para el procesamiento acumulados en el búfer.
Todo este tiempo observé cómo se usaban el procesador, la RAM y otros parámetros del sistema, y descubrí que la utilización del disco estaba maximizada.
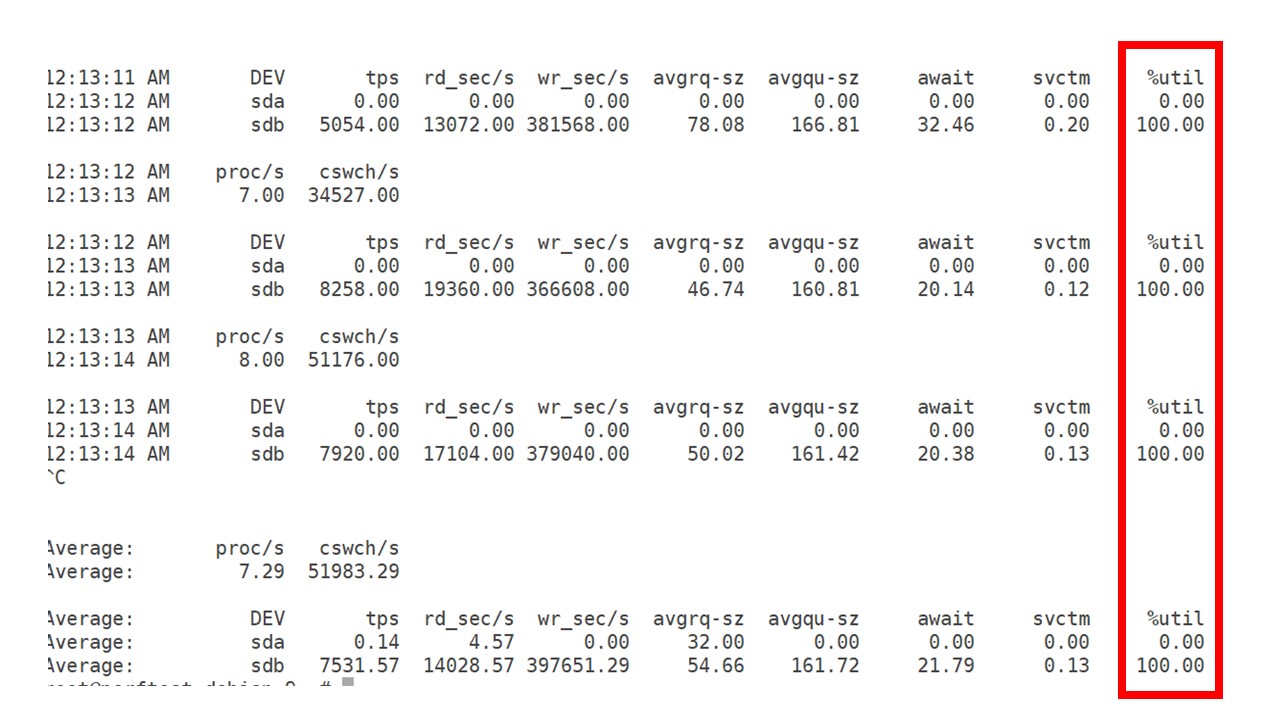
Saqué el
máximo provecho del disco en este hardware y en esta máquina virtual. A esta intensidad, PostgreSQL comenzó a volcar datos de manera bastante activa, y el disco ya no tuvo tiempo de trabajar en escritura y lectura.
Segundo servidor
Tomé otro servidor que ya tenía 48 procesadores y 128 GB de RAM. Ajústelo: configure 60 sincronizadores de historia y logre un rendimiento aceptable.
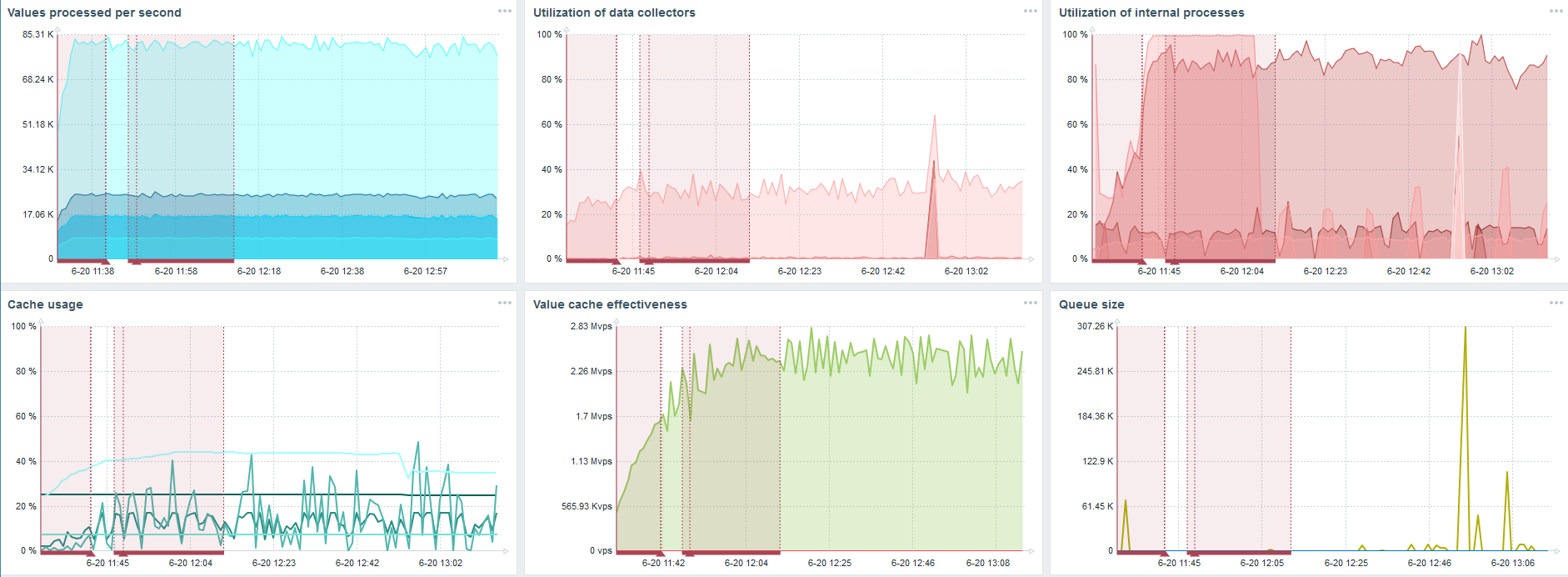
De hecho, esto ya es un límite de rendimiento en el que hay que hacer algo.
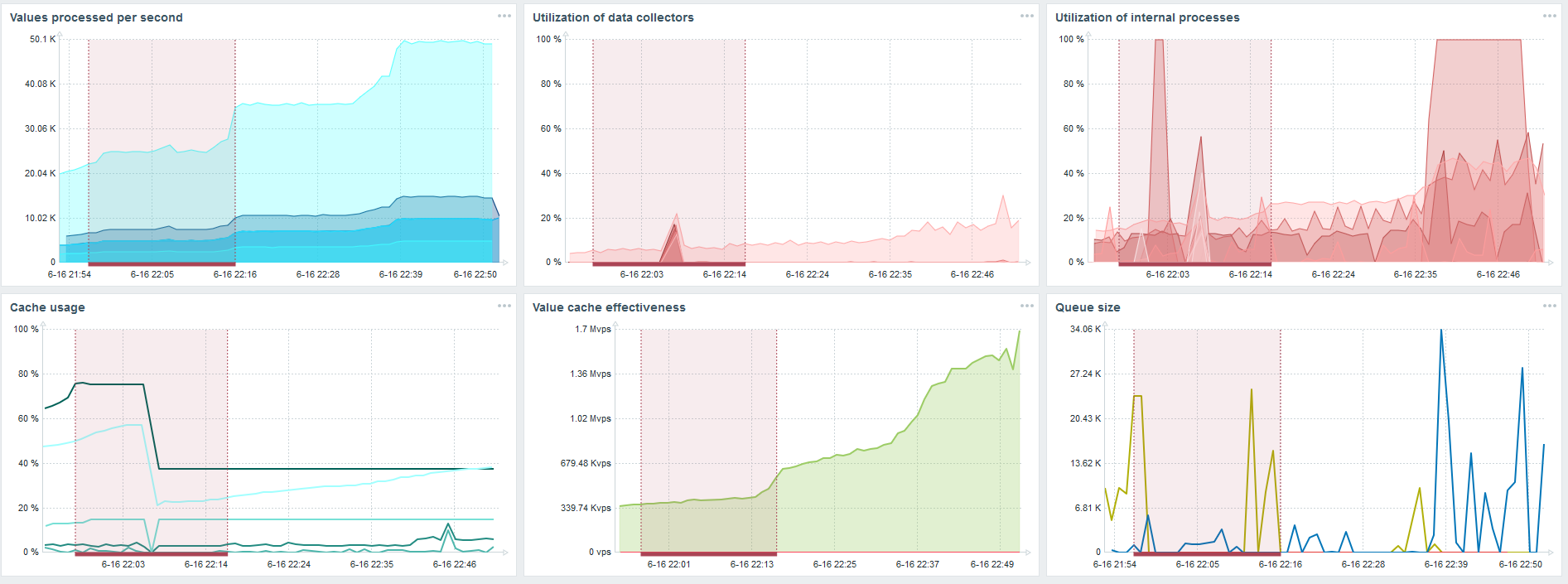
TimescaleDB. 80,000 nvps
Mi tarea principal es probar las capacidades de TimescaleDB desde la carga de Zabbix. 80 mil valores por segundo es mucho, la frecuencia de recopilación de métricas (a excepción de Yandex, por supuesto) y una "configuración" bastante grande.
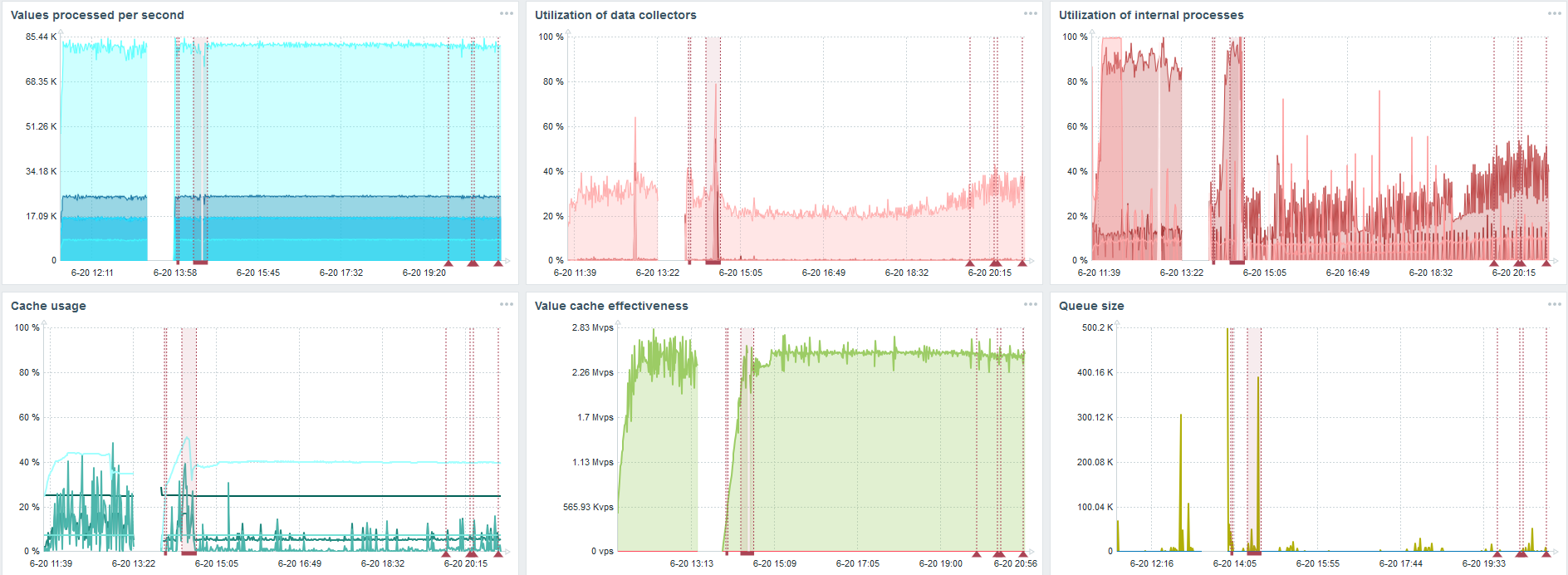
Hay un error en cada gráfico; esto es solo la migración de datos. Después de fallas en el servidor Zabbix, el perfil de inicio del sincronizador de historia ha cambiado mucho, ha caído tres veces.
TimescaleDB le permite insertar datos casi 3 veces más rápido y usar menos HistoryCache.
En consecuencia, los datos se le entregarán de manera oportuna.
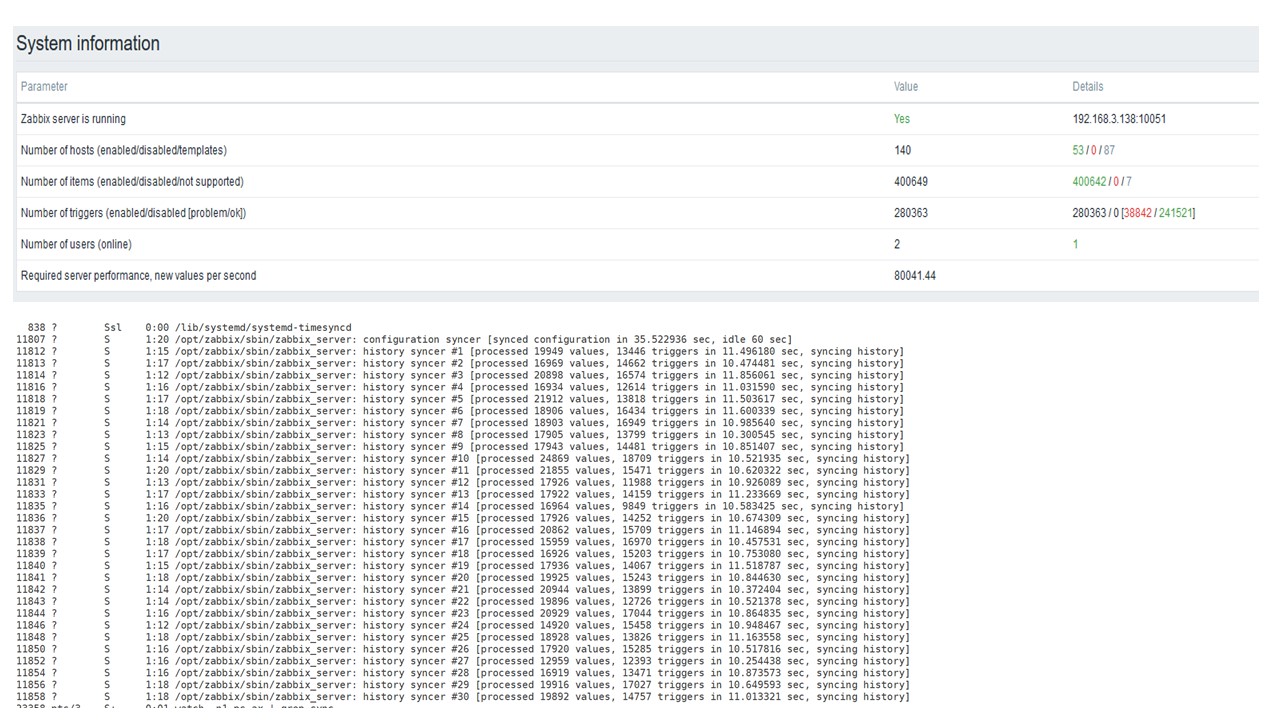
TimescaleDB. 120,000 nvps
Luego aumenté el número de elementos de datos a 500 mil. La tarea principal era verificar las capacidades de TimescaleDB: obtuve el valor calculado de 125 mil valores por segundo.
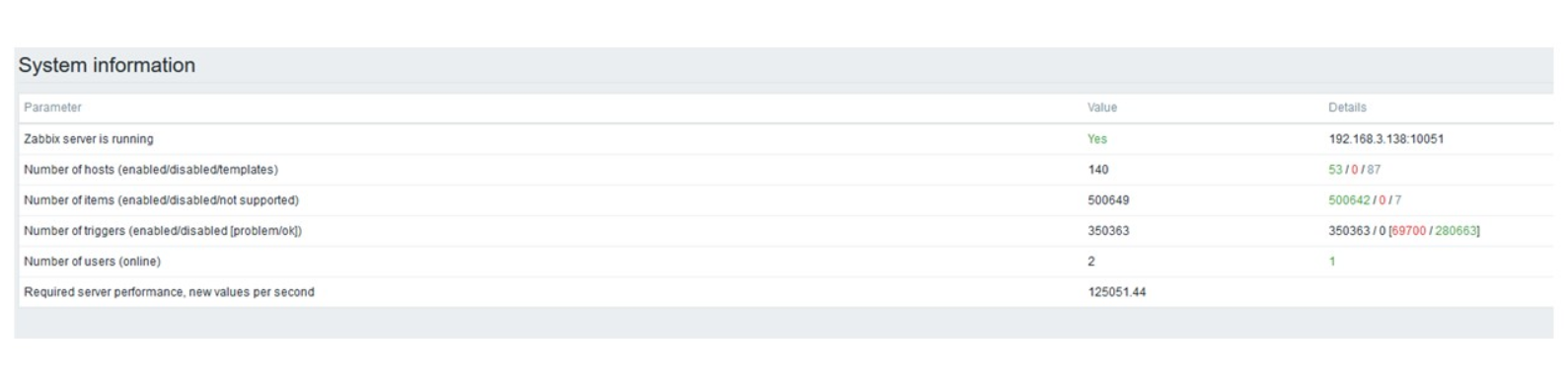
Esta es una "configuración" funcional que puede funcionar durante mucho tiempo. Pero como mi disco tenía solo 1,5 TB, lo llené en un par de días.
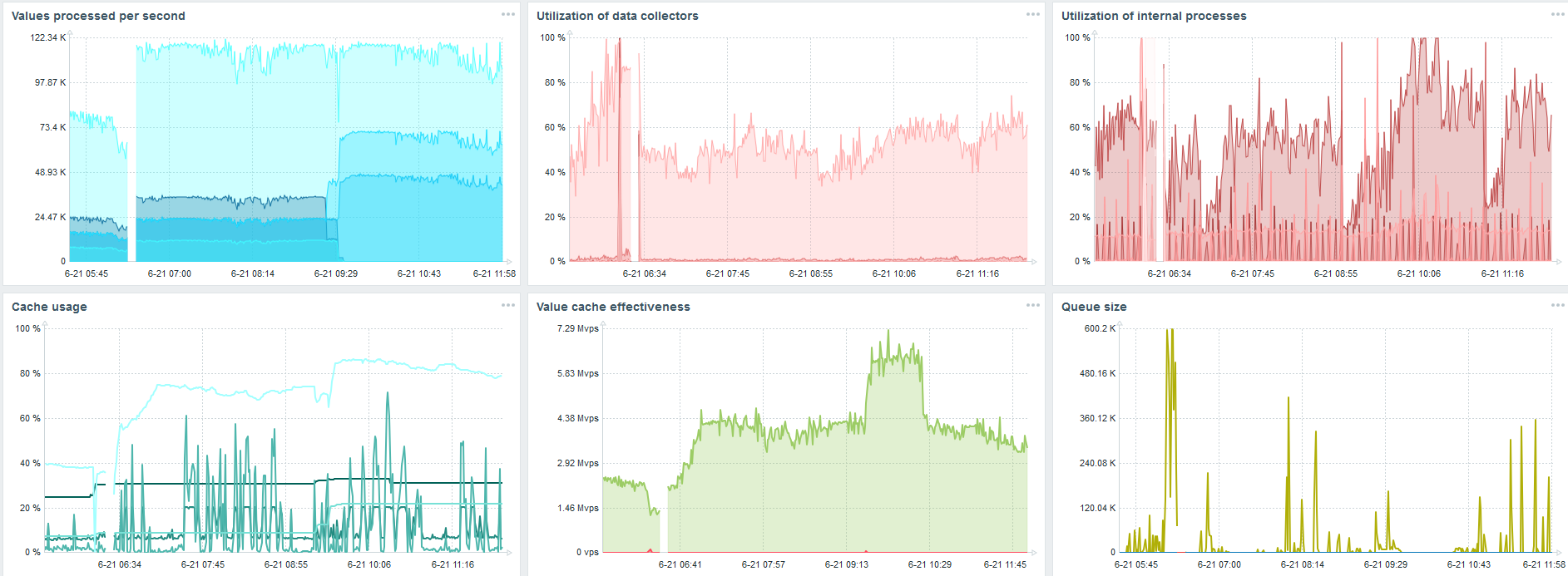
Lo más importante, al mismo tiempo, se crearon nuevas particiones TimescaleDB.
Para el rendimiento, esto es completamente invisible. Cuando se crean particiones en MySQL, por ejemplo, todo es diferente. Por lo general, esto sucede de noche, porque bloquea la inserción general, trabaja con tablas y puede crear degradación del servicio. En el caso de TimescaleDB esto no es.
Por ejemplo, mostraré un gráfico del conjunto en la comunidad. TimescaleDB se incluye en la imagen, debido a esto, la carga sobre el uso de io.weight en el procesador ha disminuido. El uso de elementos de procesos internos también ha disminuido. Y esta es una máquina virtual normal en discos de panqueque ordinarios, no una SSD.
Conclusiones
TimescaleDB es una buena solución para pequeñas "configuraciones" que dependen del rendimiento del disco. Le permitirá continuar trabajando bien hasta que la base de datos se migre a planchar más rápido.
TimescaleDB es fácil de configurar, proporciona un aumento de rendimiento, funciona bien con Zabbix y
tiene ventajas sobre PostgreSQL .
Si usa PostgreSQL y no planea cambiarlo, le recomiendo
usar PostgreSQL con la extensión TimescaleDB junto con Zabbix . Esta solución funciona de manera efectiva para la "configuración" media.
Decimos "alto rendimiento", nos referimos a HighLoad ++ . A la espera de familiarizarse con las tecnologías y prácticas que permiten que los servicios sirvan a millones de usuarios, muy brevemente. Ya hemos compilado una lista de informes para el 7 y 8 de noviembre, pero todavía se pueden ofrecer mitaps .
Suscríbase a nuestro boletín y telegrama , en el que revelaremos los chips de la próxima conferencia, y aprenda cómo aprovecharla al máximo.