El aprendizaje automático moderno le permite hacer cosas increíbles. Las redes neuronales funcionan en beneficio de la sociedad: encuentran delincuentes, reconocen amenazas, ayudan a diagnosticar enfermedades y toman decisiones difíciles. Los algoritmos pueden superar a una persona en creatividad: pintan cuadros, escriben canciones y hacen obras maestras a partir de cuadros comunes. Y aquellos que desarrollan estos algoritmos a menudo se presentan como científicos caricaturizados.
¡No todo es tan aterrador! Cualquiera que esté familiarizado con la programación puede construir una red neuronal a partir de modelos básicos. Y ni siquiera es necesario aprender Python, todo se puede hacer en JavaScript nativo. Es fácil comenzar y por qué el aprendizaje automático es
necesario para los
proveedores de front-end, dijo
Alexey Okhrimenko (
obenjiro ) en FrontendConf, y lo transferimos al texto para que los nombres de la arquitectura y los enlaces útiles estén a la mano.
Spoiler Alerta
Esta historia:
- No para aquellos que ya trabajan con Machine Learning. Algo interesante será, pero es poco probable que bajo el corte esté esperando la apertura.
- No se trata de transferencia de aprendizaje. No hablaremos sobre cómo escribir una red neuronal en Python, y luego trabajaremos con ella desde JavaScript. Sin trampas: escribiremos redes neuronales profundas específicamente en JS.
- No todos los detalles. En general, todos los conceptos no caben en un artículo, pero por supuesto analizaremos lo necesario.
Sobre el orador: Alexei Okhrimenko trabaja en Avito en el departamento de Arquitectura Frontend, y en su tiempo libre dirige el Meetup Angular de Moscú y lanza el "Five Minute Angular". Durante una larga carrera, ha desarrollado el patrón de diseño MALEVICH, el analizador gramatical PEG SimplePEG. El mantenedor de Alexey CSSComb comparte regularmente conocimientos sobre nuevas tecnologías en conferencias y en su
canal de telegramas de aprendizaje automático JS.
El aprendizaje automático es muy popular.
Los asistentes de voz, Siri, el Asistente de Google, Alice, son populares y a menudo se encuentran en nuestras vidas. Muchos productos han pasado del procesamiento de datos algorítmicos convencionales al aprendizaje automático. Un ejemplo sorprendente es Google Translate.
Todas las innovaciones y los chips más geniales en los teléfonos inteligentes se basan en el aprendizaje automático.

Por ejemplo, Google NightSight utiliza el aprendizaje automático. Las fotos geniales que vemos no se obtuvieron con lentes, sensores o estabilización, sino con la ayuda del aprendizaje automático. La máquina finalmente venció a las personas en DOTA2, lo que significa que tenemos pocas posibilidades de derrotar la inteligencia artificial. Por lo tanto, debemos dominar el aprendizaje automático lo más rápido posible.
Comencemos con un simple
¿Cuál es nuestra rutina de programación diaria, cómo solemos escribir funciones?

Tomamos datos y un algoritmo que nosotros mismos inventamos o tomamos de los populares ya preparados, combinamos, hacemos un poco de magia y obtenemos una función que nos da la respuesta correcta en una situación dada.
Estamos acostumbrados a este orden de cosas, pero habría una oportunidad, sin conocer el algoritmo, pero simplemente teniendo los datos y la respuesta, obtener el algoritmo de ellos.

Puedes decir: "Soy un programador, siempre puedo escribir un algoritmo".
Ok, pero por ejemplo, ¿qué algoritmo se necesita aquí?

Supongamos que el gato tiene orejas afiladas y las orejas del perro son opacas, pequeñas, como un pug.

Tratemos de entender quién es quién por los oídos. Pero en algún momento, descubrimos que los perros pueden tener orejas afiladas.

Nuestra hipótesis no es buena, necesitamos otras características. Con el tiempo, aprenderemos más y más detalles, desmotivándonos cada vez más y, en algún momento, querremos abandonar este negocio por completo.
Me imagino una imagen ideal como esta: de antemano hay una respuesta (sabemos qué tipo de imagen es), hay datos (sabemos que el gato está dibujado), queremos obtener un algoritmo que pueda alimentar los datos y obtener respuestas en la salida.
Hay una solución: esto es el aprendizaje automático, es decir, una de sus partes: redes neuronales profundas.
Redes neuronales profundas
El aprendizaje automático es un área enorme. Ofrece una cantidad gigantesca de métodos, y cada uno es bueno a su manera.
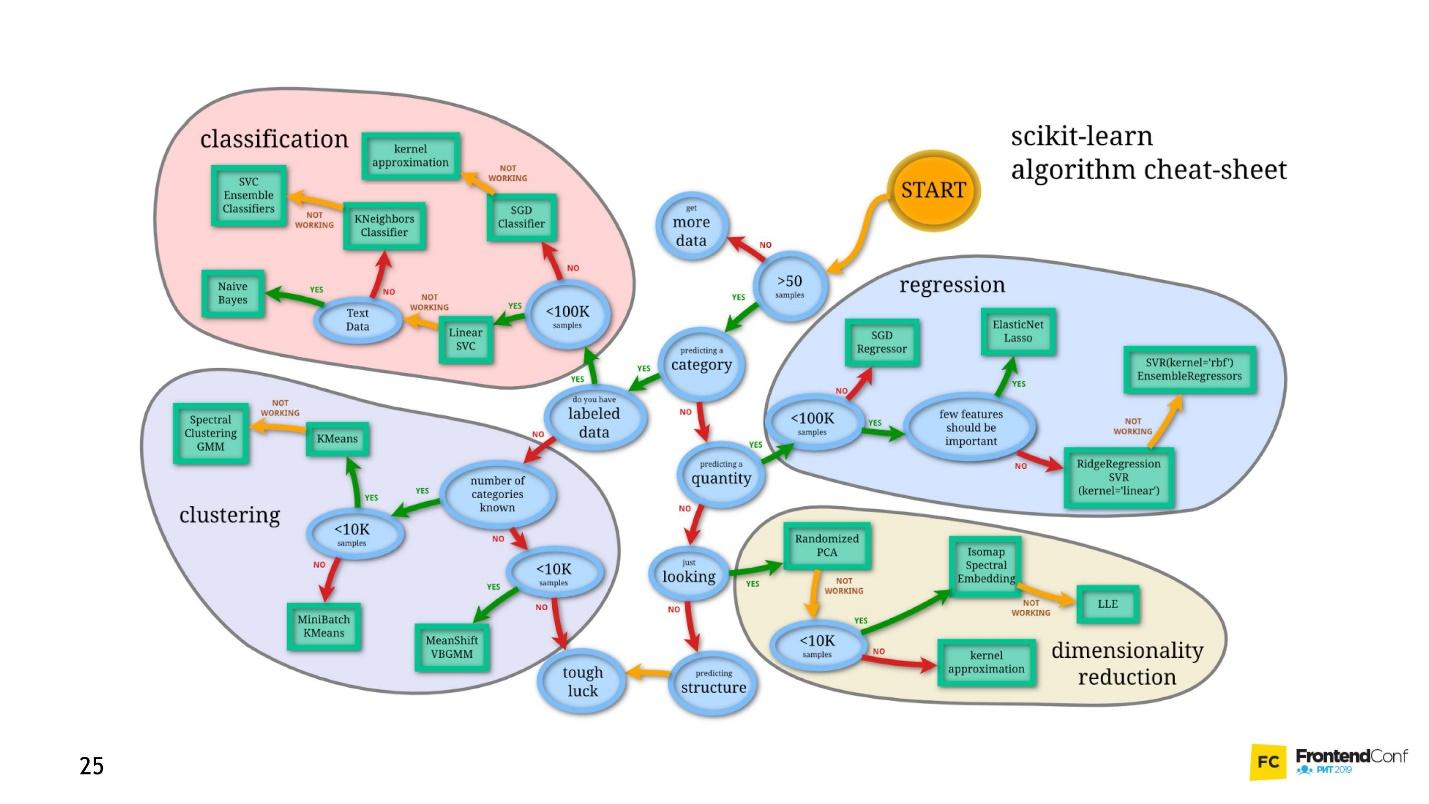
Uno de ellos es Deep Neural Networks. El aprendizaje profundo tiene una ventaja innegable debido a que se ha vuelto popular.
Para comprender esta ventaja, veamos el problema clásico de clasificación usando gatos y perros como ejemplo.
Hay datos: fotos o fotos. Lo primero que debe hacer es incrustar (incrustar), es decir, transformar los datos para que la máquina se sienta cómoda trabajando con ellos. Es inconveniente trabajar con imágenes, el auto necesita algo más simple.
Primero, alinee las imágenes y elimine el color. No importa de qué color sea el perro o el gato, es importante determinar el tipo de animal. Luego convertimos las imágenes en matrices, donde, por ejemplo, 0 es oscuro, 1 es claro.

Con esta presentación de datos, las redes neuronales ya pueden funcionar.
Vamos a crear dos matrices más y fusionarlas en una cierta "capa". Luego, multiplicamos cada uno de los elementos de la capa y la matriz de datos entre sí utilizando una simple multiplicación de matrices, y dirigimos el resultado a dos funciones de activación (luego analizaremos cuáles son estas funciones). Si la función de activación recibe una cantidad suficiente de valores, entonces se "activa" y producirá el resultado:
- la primera función devolverá 1 si es un gato y 0 si no es un gato.
- la segunda función devolverá 1 si es un perro y 0 si no es un perro.
Este enfoque para codificar una respuesta se denomina
codificación de uno en caliente .

Ya se notan varias características de las redes neuronales profundas:
- Para trabajar con redes neuronales, necesita codificar datos en la entrada y decodificar en la salida.
- La codificación nos permite hacer un resumen de los datos.
- Al cambiar los datos de entrada, podemos generar redes neuronales para diferentes dominios de dominio. Incluso aquellos en los que no somos expertos.
No es necesario saber qué es un gato, qué es un perro. Es suficiente seleccionar los números necesarios para una capa adicional.
Hasta ahora, lo único que no está claro es por qué estas redes se llaman "profundas".
Todo es muy simple: podemos crear otra capa (matrices y sus funciones de activación). Y transfiere el resultado de una capa a otra.
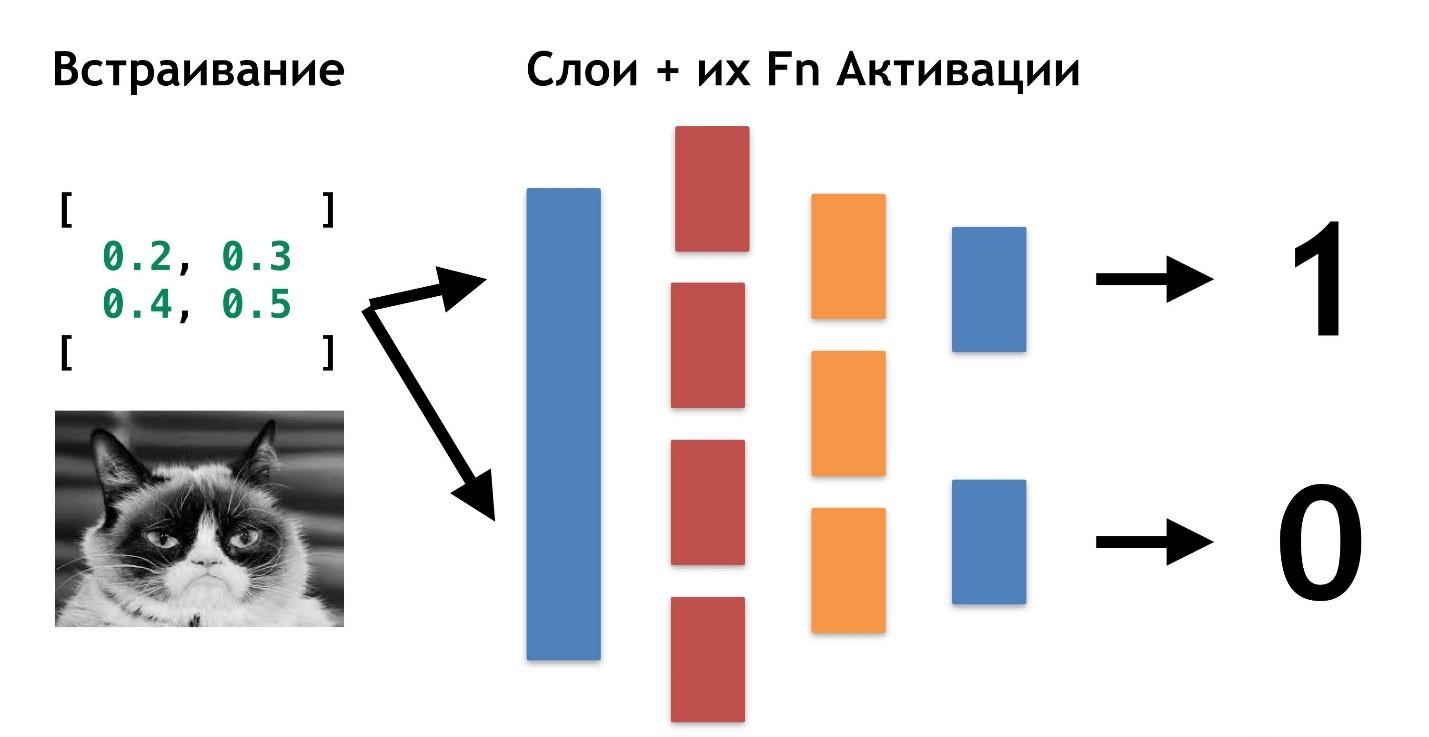
Puede colocar entre sí tantas de estas capas y sus funciones para la activación. Combinando arquitectura en capas, obtenemos una red neuronal profunda. Su profundidad es una multitud de capas. Y colectivamente llamado el
"modelo" .
Ahora veamos cómo se seleccionan los valores para todas estas capas. Hay una
visualización genial que le permite comprender cómo ocurre el proceso de aprendizaje.
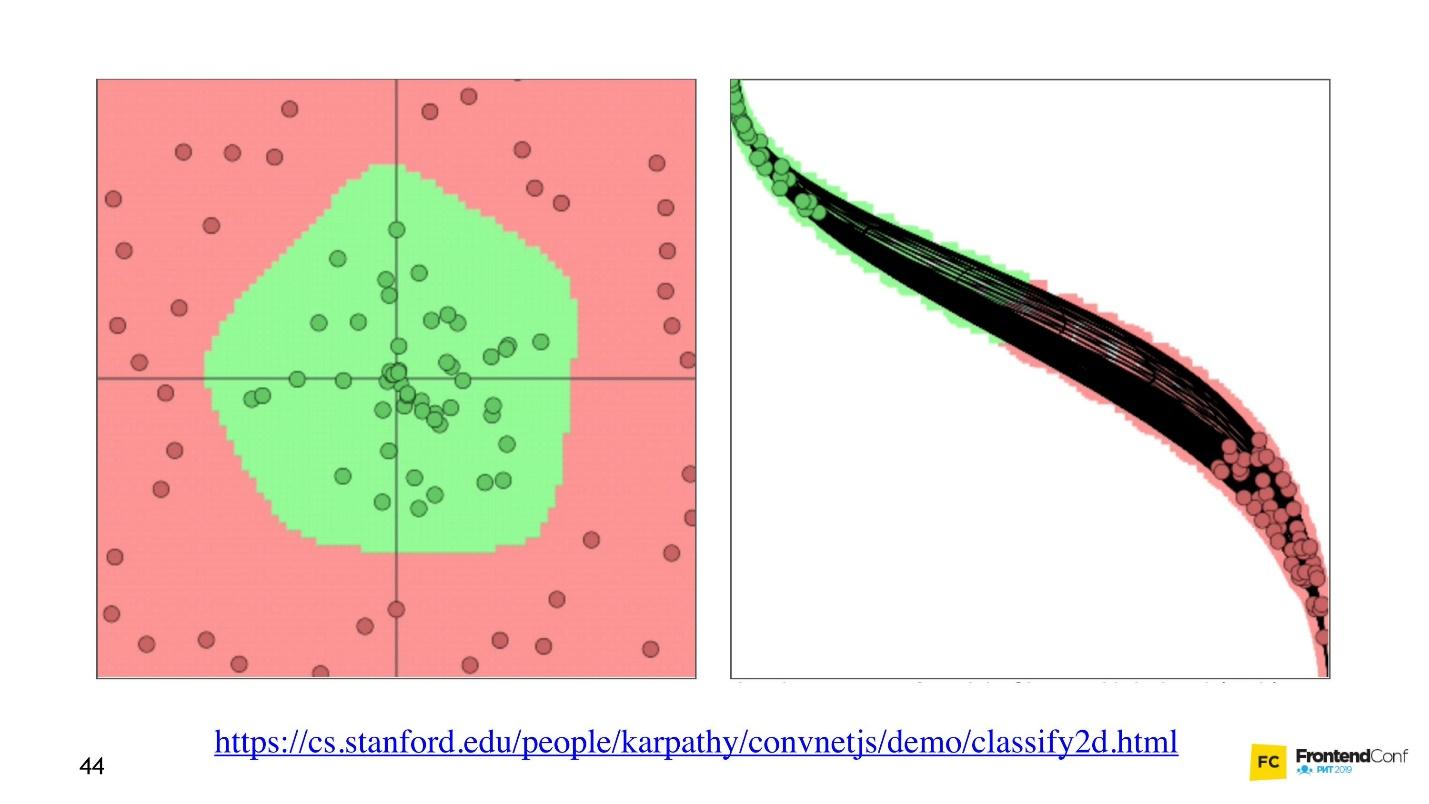
A la izquierda hay datos, y a la derecha está una de las capas. Se puede ver que al cambiar los valores dentro de las matrices de capas, parece que cambiamos el sistema de coordenadas. Adaptándose así a los datos y al aprendizaje. Por lo tanto, el aprendizaje es el proceso de seleccionar los valores correctos para las matrices de capas. Estos valores se llaman pesos o pesos.
El aprendizaje automático es difícil
Quiero molestarte, el aprendizaje automático es difícil. Todo lo anterior es una gran simplificación. En el futuro, encontrará una gran cantidad de álgebra lineal y bastante compleja. Por desgracia, no hay escapatoria de esto.
Por supuesto, hay cursos, pero incluso el entrenamiento más rápido dura varios meses y no es barato. Además, todavía tienes que resolverlo tú mismo. El campo del aprendizaje automático ha crecido tanto que hacer un seguimiento de todo es casi imposible. Por ejemplo, a continuación hay un conjunto de modelos para resolver solo una tarea (detección de objetos):

Personalmente, estaba muy desmotivado. No podía acercarme a las redes neuronales y comenzar a trabajar con ellas. Pero he encontrado un camino y quiero compartirlo contigo. No es revolucionario, no hay nada de eso en eso, ya estás familiarizado con eso.
Blackbox: un enfoque simple
No es necesario comprender absolutamente todos los aspectos del aprendizaje automático para aprender cómo aplicar redes neuronales a sus tareas comerciales. Mostraré algunos ejemplos que espero te inspiren.
Para muchos, un automóvil también es una caja negra. Pero incluso si no sabe cómo funciona, debe aprender las reglas. Entonces, con el aprendizaje automático, aún necesita conocer algunas reglas:
- Aprenda TensorFlow JS (biblioteca para trabajar con redes neuronales).
- Aprende a elegir modelos.
Nos centramos en estas tareas y comenzamos con el código.
Aprendiendo creando código
La biblioteca TensorFlow está escrita para una gran cantidad de lenguajes: Python, C / C ++, JavaScript, Go, Java, Swift, C #, Haskell, Julia, R, Scala, Rust, OCaml, Crystal. Pero definitivamente elegiremos el mejor: JavaScript.
TensorFlow se puede conectar a nuestra página conectando un script con CDN:
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script>
O use npm:
npm install @tensorflow/tfjs-node - para el proceso de nodo (sitio web);npm install @tensorflow/tfjs-node-gpu (Linux CUDA) - para la GPU, pero solo si la máquina Linux y la tarjeta de video son compatibles con la tecnología CUDA. Asegúrese de asegurarse de que CUDA Compute Capability coincida con su biblioteca para que no resulte que el hardware costoso no es adecuado.npm install @tensorflow/tfjs ( npm install @tensorflow/tfjs / Browser) - para un navegador sin usar Node.js.
Para trabajar con TensorFlow JS, es suficiente importar uno de los módulos anteriores. Verá muchos ejemplos de código donde se importa todo. No es necesario hacer esto, seleccione e importe solo uno.
Tensores
Cuando los datos iniciales están listos, lo primero que debe hacer es
importar TensorFlow . Usaremos tensorflow / tfjs-node-gpu para obtener aceleración debido a la potencia de la tarjeta de video.
Hay una matriz de datos bidimensional, trabajaremos con ella.
Lo siguiente que debe hacer es
crear un tensor . En este caso, se crea un tensor de rango 2, es decir, de hecho, una matriz bidimensional. Transferimos los datos y obtenemos el tensor 2x2.
Tenga en cuenta que el método de
print se llama, no
console.log , porque
b (el tensor que creamos) no es un objeto ordinario, es decir, el tensor. Él tiene sus propios métodos y propiedades.
También puede crear un tensor a partir de una matriz plana y tener en cuenta su forma, digamos. Es decir, declarar una forma, una matriz bidimensional, para transmitir simplemente una matriz plana e indicar directamente la forma. El resultado será el mismo.
Debido al hecho de que los datos y el formulario se pueden almacenar por separado, puede cambiar la forma del tensor. Podemos llamar al método de
reshape y cambiar la forma de 2x2 a 4x1.
El siguiente paso importante es
generar los datos , devolverlos al mundo real.
El código para los tres pasos.El método de
data devuelve promesa. Después de que se resuelve, obtenemos el valor inmediato del valor bruto, pero lo obtenemos de forma asincrónica. Si queremos, podemos obtenerlo sincrónicamente, pero recuerda que aquí puedes perder rendimiento, así que usa métodos asincrónicos siempre que sea posible.
El método
dataSync siempre devuelve datos en un formato de matriz plana. Y si queremos devolver los datos en el formato en que están almacenados en el tensor, debemos llamar a
arraySync .
Operadores
Todos los operadores en TensorFlow son
inmutables por defecto , es decir, en cada operación siempre se devuelve un nuevo tensor. Arriba, simplemente tome nuestra matriz y cuadre todos sus elementos.
¿Por qué tantas dificultades para las operaciones matemáticas simples? Todos los operadores que necesitamos, la suma, la mediana, etc., están ahí. Esto es necesario porque, de hecho, el tensor y este enfoque le permiten crear un gráfico de cálculos y realizar cálculos no inmediatamente, sino en WebGL (en el navegador) o CUDA (Node.js en la máquina). Es decir, el uso real de Aceleración de hardware es invisible para nosotros y, si es necesario, la recuperación de la CPU. Lo bueno es que no necesitamos pensar en nada al respecto. Solo necesitamos aprender la API de tfjs.
Ahora lo más importante es el modelo.
Modelo
La forma más fácil de crear un modelo es secuencial, es decir, un modelo secuencial, cuando los datos de una capa se transfieren a la siguiente capa, y de ella a la siguiente capa. Se usan las capas más simples que se usan aquí.
La capa en sí es solo una abstracción de tensores y operadores. En términos generales, estas son funciones auxiliares que te ocultan una gran cantidad de matemáticas.
Intentemos comprender cómo trabajar con el modelo sin entrar en los detalles de implementación.
Primero, indicamos la forma de datos que cae en la red neuronal:
inputShape es un parámetro requerido. Indicamos
units : el número de matrices multidimensionales y la función de activación.
La función
relu notable porque se encontró por casualidad: se probó, funcionó mejor y, durante mucho tiempo, buscaron una explicación matemática de por qué sucede esto.
Para la última capa, cuando hacemos una categoría, a menudo se usa la función softmax: es muy adecuada para mostrar una respuesta en el formato de codificación One-Hot. Después de crear el modelo, llame a
model.summary() para asegurarse de que el modelo esté ensamblado de la manera correcta. En situaciones particularmente difíciles, puede abordar la creación de un modelo utilizando la programación funcional.
Si necesita crear un modelo particularmente complejo, puede utilizar el enfoque funcional: cada vez que cada capa es una nueva variable. Como ejemplo, tomamos manualmente la siguiente capa y le aplicamos la capa anterior, para que podamos construir arquitecturas más complejas. Más tarde te mostraré dónde puede ser útil.
El siguiente detalle muy importante es que pasamos las capas de entrada y salida al modelo, es decir, las capas que ingresan a la red neuronal y las capas que son capas para la respuesta.
Después de esto, un paso importante es
compilar el modelo . Tratemos de entender qué es la compilación en términos de tfjs.
Recuerde, tratamos de encontrar los valores correctos en nuestra red neuronal. No es necesario recogerlos. Se seleccionan de cierta manera, como dice la función optimizadora.
Código para la descripción de capas secuenciales y compilación.Ilustraré qué es un optimizador y qué es una función de pérdida.
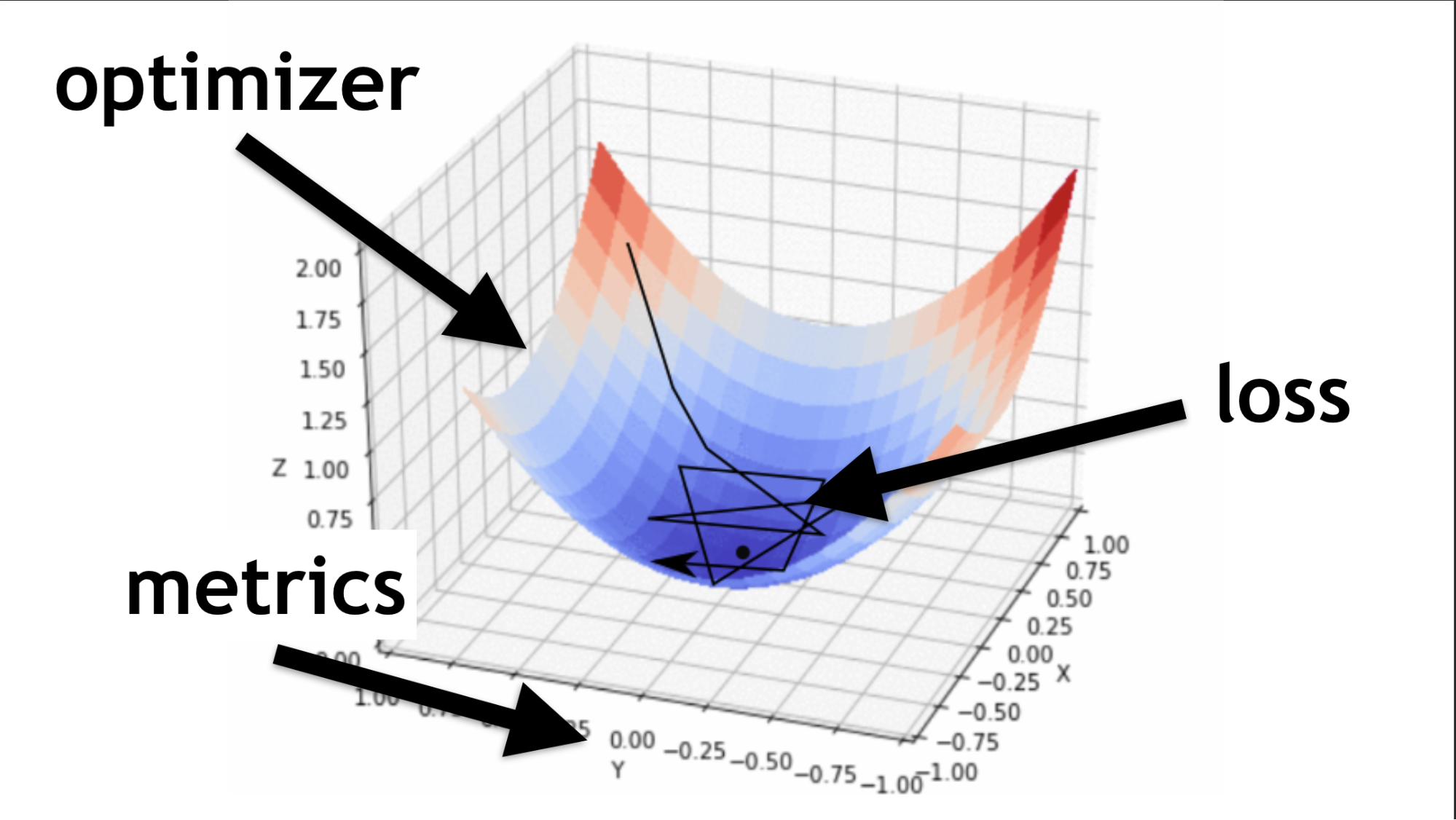
El optimizador es todo el mapa. Le permite no solo correr al azar y buscar valor, sino hacerlo sabiamente, de acuerdo con cierto algoritmo.
La función de pérdida es la forma en que buscamos el valor óptimo (pequeña flecha negra). Ayuda a entender qué valores de gradiente usar para entrenar nuestra red neuronal.
En el futuro, cuando domine las redes neuronales, usted mismo escribirá una función de pérdida. Gran parte del éxito de una red neuronal depende de qué tan bien escrita esté esta función. Pero esta es otra historia. Comencemos simple.
Ejemplo de aprendizaje en red
Generaremos datos aleatorios y respuestas aleatorias (etiquetas). Llamamos al módulo de
fit , pasamos los datos, las respuestas y varios parámetros importantes:
epochs : 5 veces, es decir, aproximadamente, 5 veces llevaremos a cabo un entrenamiento completo;batchSize , que indica cuántos pesos se pueden cambiar a la vez para levantar, cuántos elementos procesar al mismo tiempo. Cuanto mejor sea la tarjeta de video, más memoria tiene, más batchSize se puede configurar.
Código de todos los últimos pasos.Model.fit asincrónico
Model.fit , devuelve promesa. Pero puede usar async / await y esperar la ejecución de esa manera.
El siguiente es el
uso . Entrenamos nuestro modelo, luego tomamos los datos que queremos procesar, y llamamos al método de
predict , decimos: "¿Predecir qué hay realmente allí?", Y gracias a esto obtenemos el resultado.
Estructura estándar
Cada red neuronal tiene tres archivos principales:
- index.js: archivo en el que se almacenan todos los parámetros de la red neuronal;
- model.js: un archivo en el que el modelo y su arquitectura se almacenan directamente;
- data.js: un archivo donde los datos se recopilan, procesan e incrustan en nuestro sistema.
Entonces, hablé sobre cómo aprender TensorFlow.js. Pequeña empresa, queda
por elegir un modelo .
Desafortunadamente, esto no es del todo cierto. De hecho, cada vez que elige un modelo, debe repetir ciertos pasos.
- Prepare datos para ello, es decir, realice la incrustación, ajústelo a la arquitectura.
- Configure los ajustes de Hyper (más adelante le diré lo que esto significa).
- Entrenar / entrenar cada red neuronal (cada modelo puede tener sus propios matices).
- Aplique un modelo neuronal y, de nuevo, puede aplicar de diferentes maneras.
Elige un modelo
Comencemos con las opciones básicas que a menudo encontrará.
Sentido profundo
Este es un ejemplo popular de una red neuronal profunda. Todo se hace de manera bastante simple: hay un conjunto de datos disponible públicamente: el conjunto de datos MNIST.
Estas son imágenes etiquetadas con números, en base a las cuales es conveniente entrenar una red neuronal.
De acuerdo con la arquitectura de One-Hot Encoding, codificamos cada una de las últimas capas. Dígitos 10: en consecuencia, habrá 10 últimas capas al final. Simplemente enviamos fotos en blanco y negro a la entrada, todo esto es muy similar a lo que hablamos al principio.
const model = tf.sequential({ layers: [ tf.layers.dense({ inputShape: [784], units: 512, activation: 'relu' }), tf.layers.dense({ units: 256, activation: 'relu' }), tf.layers.dense({ units: 10, activation: 'softmax' }), ] });
Enderezamos la imagen en una matriz unidimensional, obtenemos 784 elementos. En una capa 512 matrices. Función de activación
'relu' .
La siguiente capa de matrices es ligeramente más pequeña (256), la capa de activación también es
'relu' . Redujimos el número de matrices para buscar características más generales. A la red neuronal se le debe indicar cómo aprender y forzarla a tomar una decisión más seria y general, porque ella misma no lo hará.
Al final, hacemos 10 matrices y utilizamos la activación de softmax para la codificación One-Hot: este tipo de activación funciona bien con este tipo de codificación de respuesta.
Las redes profundas le permiten reconocer correctamente el 80-90% de las imágenes; quiero más. Una persona reconoce con una calidad de aproximadamente el 96%. ¿Pueden las redes neuronales atrapar y alcanzar a una persona?
CNN (red neuronal convolucional)
Las redes de convolución funcionan increíblemente simples. Al final, tienen la misma arquitectura que en los ejemplos anteriores. Pero al principio, sucede algo más. Las matrices, en lugar de solo dar algunas soluciones, reducen la imagen. Toman parte de la imagen y la reducen, la contraen a un dígito. Luego se recogen todos juntos y nuevamente se reducen.
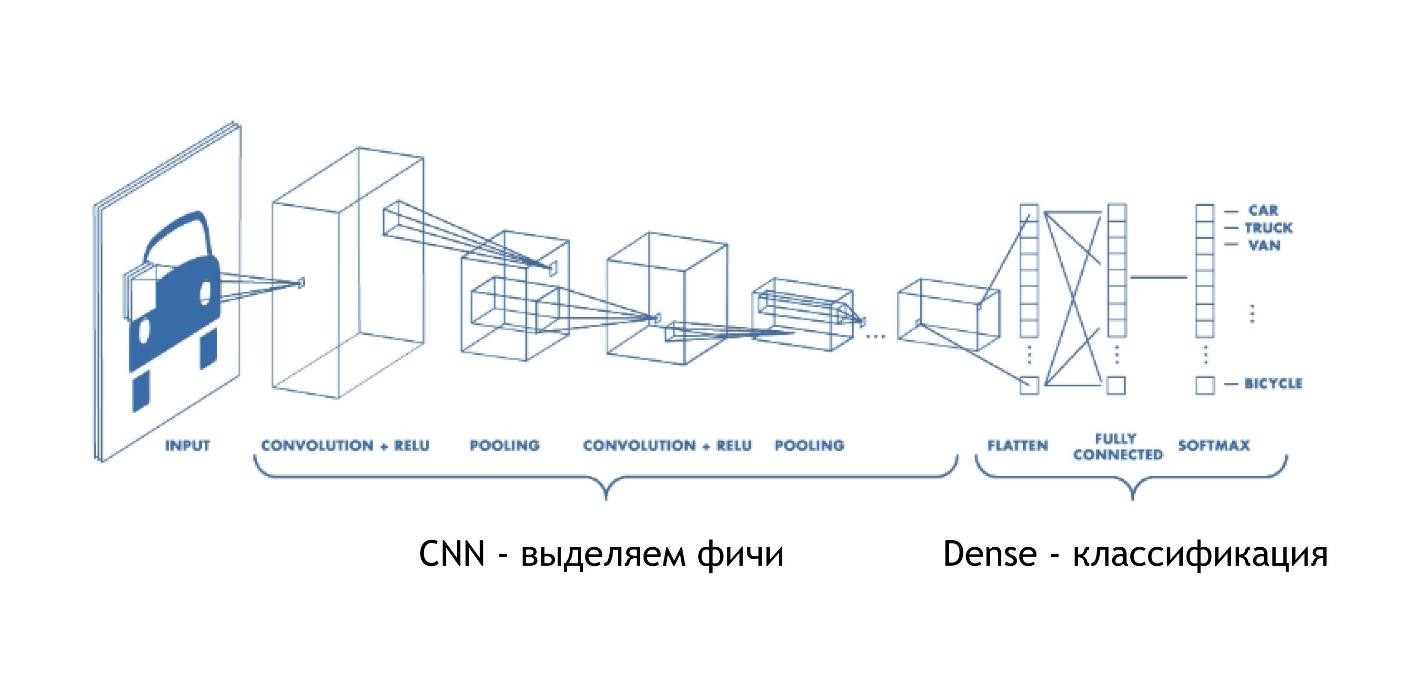
Por lo tanto, el tamaño de la imagen se reduce, pero al mismo tiempo, partes de la imagen se reconocen cada vez mejor. Las redes de convolución funcionan muy bien para el reconocimiento de patrones, incluso mejor que los humanos.
Reconocer imágenes se confía mejor a un automóvil que a una persona. Hubo un estudio especial, y la persona, desafortunadamente, perdió.
Las CNN funcionan de manera muy simple:
const model = tf.sequential({ layers: [ tf.layers.conv2d({ inputShape: [28, 28, 1], filters: 32, kernelSize: 3, activation: 'relu', }), tf.layers.conv2d({ filters: 32, kernelSize: 3, activation: 'relu', }), tf.layers.maxPooling2d({poolSize: [2, 2]}), tf.layers.conv2d({ filters: 64, kernelSize: 3, activation: 'relu', }) tf.layers.flatten(tf.layers.maxPooling2d({ poolSize: [2, 2] })), tf.layers.dense({units: 512, activation: 'relu'}), tf.layers.dense({units: 10, activation: 'softmax'}) ] });
Ingresamos una matriz multidimensional específica: una imagen de 28x28 píxeles, más una dimensión para el brillo, en este caso la imagen es en blanco y negro, por lo que la tercera dimensión es 1.
A continuación, establecemos la cantidad de
filters y
kernelSize : cuántos píxeles se reducirán. Función de activación en todas partes
relu .
Hay otra capa
maxPooling2d , que es necesaria para reducir el tamaño de manera aún más eficiente. Las redes de convolución reducen el tamaño muy gradualmente y, a menudo, no hay necesidad de crear redes de convolución muy profundas.
Explicaré por qué es imposible hacer redes de convolución muy profundas un poco más tarde, pero por ahora, recuerda: a veces necesitan ser un poco más rápidas. Hay una capa maxPooling separada para esto.
Al final hay la misma capa densa. Es decir, utilizando redes neuronales convolucionales, extrajimos varios signos de los datos, después de lo cual usamos el enfoque estándar y categorizamos nuestros resultados, gracias a lo cual reconocemos las imágenes.
U net
Este modelo de arquitectura está asociado con redes de convolución. Con su ayuda, se han realizado muchos descubrimientos en el campo del control del cáncer, por ejemplo, en el reconocimiento de las células cancerosas y el glaucoma. Además, este modelo puede encontrar células malignas no peores que un profesor en esta área.
Un ejemplo simple: entre los datos ruidosos que necesita para encontrar células cancerosas (círculos).

U-Net es tan bueno que puede encontrarlos casi a la perfección. La arquitectura es muy simple:
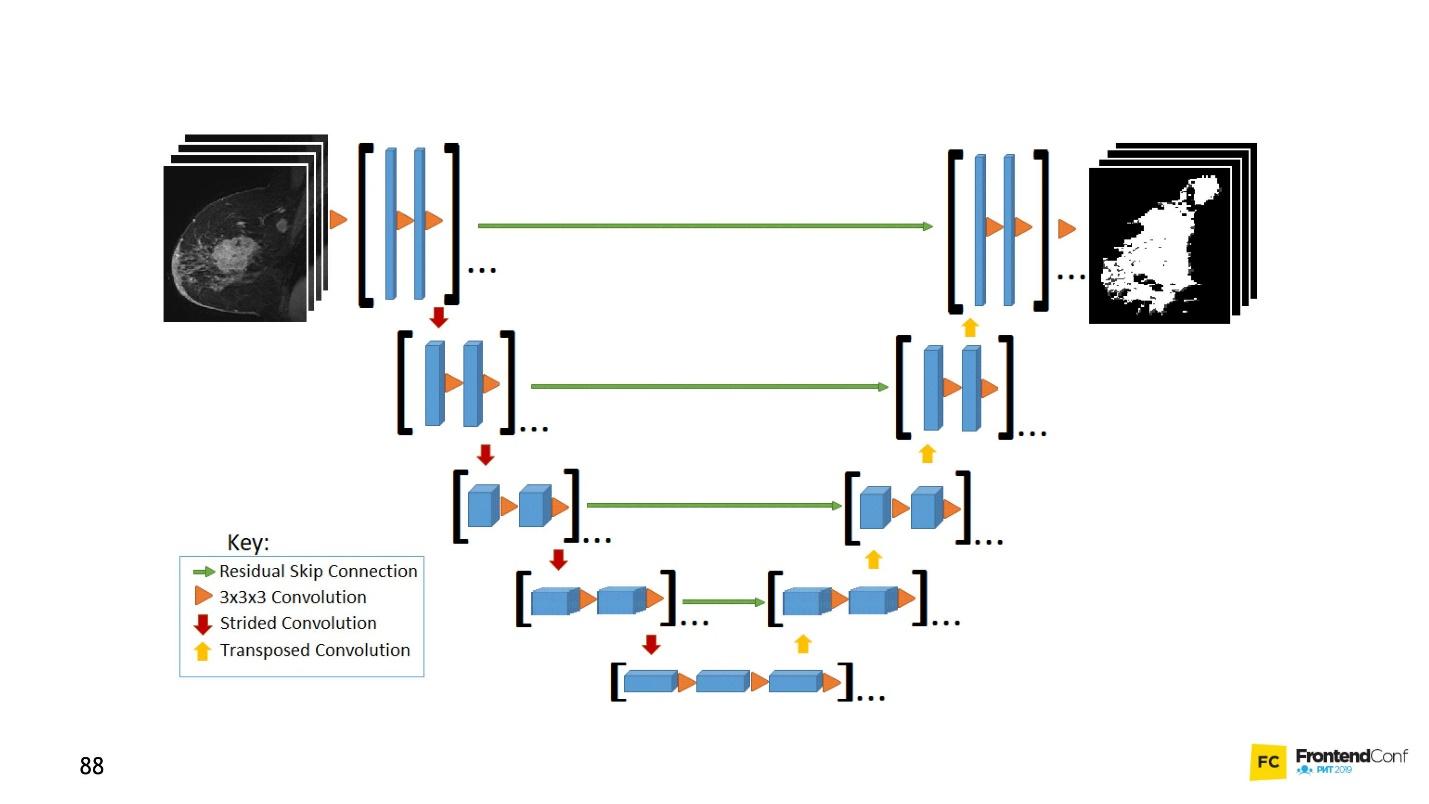
Existen las mismas redes de convolución, al igual que MaxPooling, que reduce el tamaño. La única diferencia: el modelo también utiliza redes de
exploración , la
red deconvolucional .
Además del escaneo de convolución, cada una de las capas de alto nivel se combina entre sí (inicio y salida), debido a lo cual aparecen una gran cantidad de relaciones. Tal U-Net funciona bien incluso en pequeñas cantidades de datos.
Este código es más fácil de aprender en el editor. En general, aquí se crea una gran cantidad de redes de convolución, y luego, para desplegarlas de nuevo,
concatenate y fusionamos varias capas. Esto es solo una visualización de una imagen, solo en forma de código. Todo es bastante simple: copiar y reproducir este modelo es fácil.
LSTM (memoria larga a corto plazo)
Tenga en cuenta que todos los ejemplos considerados tienen una característica: el formato de datos de entrada es fijo. La entrada a la red, los datos deben ser del mismo tamaño y coincidir entre sí. Los modelos LSTM se centran en cómo lidiar con esto.
Por ejemplo, hay un servicio Yandex.Referats, que genera resúmenes.
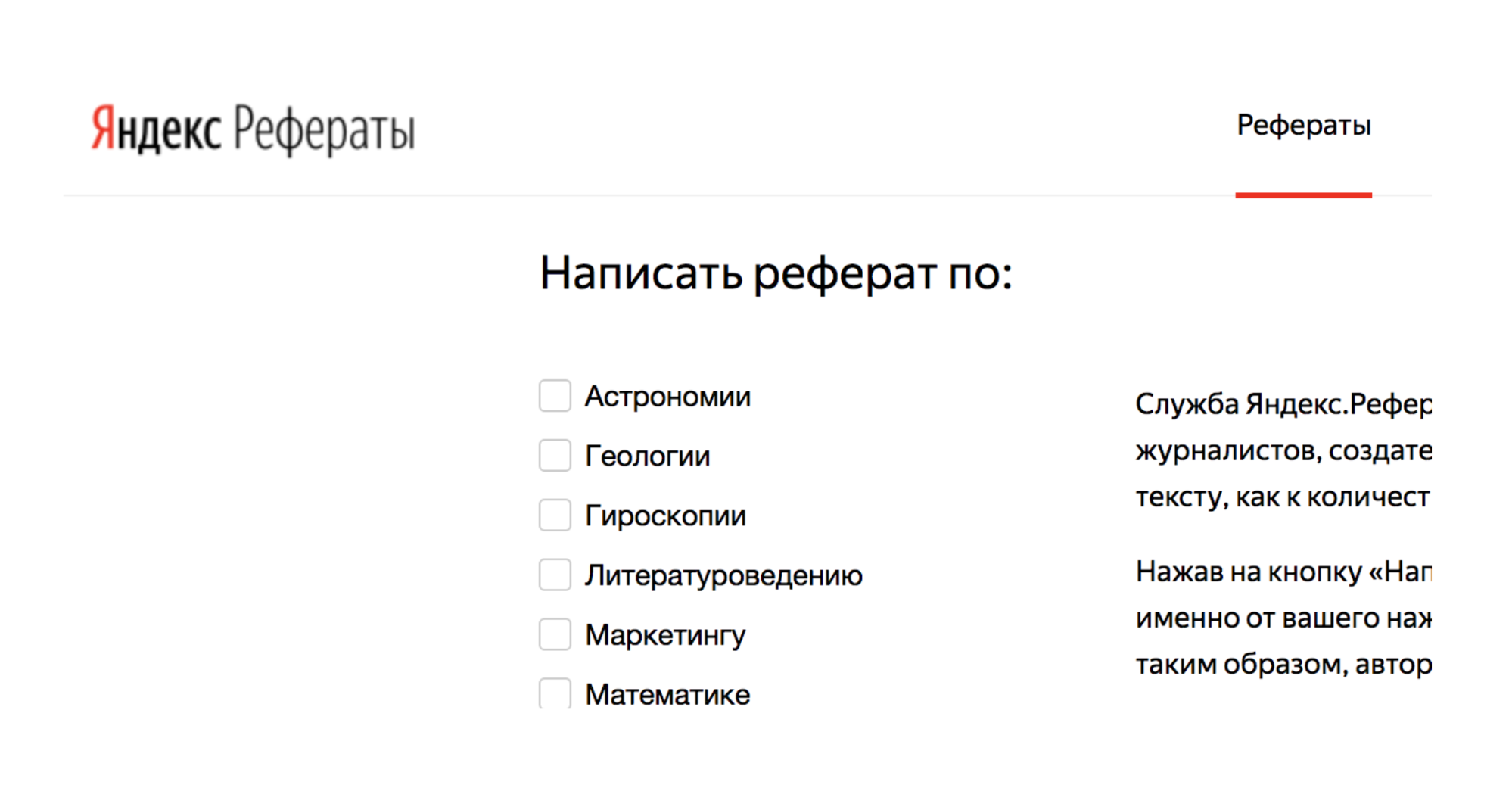
Emite un abracadabra completo, pero al mismo tiempo bastante similar a la verdad:
Resumen en matemáticas sobre el tema: "El binomio de Newton como axioma"
Según lo anterior, la integral de superficie produce una integral curvilínea. La función convexa hacia abajo todavía está en demanda.
De esto se deduce naturalmente que lo normal a la superficie todavía está en demanda. Según lo anterior, la integral de Poisson especifica esencialmente la integral trigonométrica de Poisson.
El servicio se basa en redes neuronales Seq-to-Seq. Su arquitectura es más compleja.

Las capas se organizan en un sistema bastante complejo. Pero no se alarme: no tiene que conducir todas estas flechas usted mismo. Si quieres, puedes, pero no es necesario. Hay un ayudante que hará esto por usted.
Lo principal a entender es que cada una de estas piezas se combina con la anterior. Toma datos no solo de los datos iniciales, sino también de la capa neural anterior. En términos generales, es posible construir algún tipo de memoria: memorizar una secuencia de datos, reproducirla y, debido a este trabajo, "secuencia a secuencia". Además, las secuencias pueden ser de diferentes tamaños tanto en la entrada como en la salida.
Todo se ve hermoso en el código:
tf.sequential({ layers: [ tf.layers.lstm({ units: 512, returnSequences: true, inputShape: [10000, 64] }), tf.layers.lstm({ units: 512, returnSequences: false }), tf.layers.dense({ units: 64, activation: 'softmax' }) ] }) ;
Hay un asistente especial que dice que tenemos 512 objetos (matrices). Luego, devuelva la secuencia y el formulario de entrada (
inputShape: [10000, 64] ). Luego presentamos otra capa, pero no devolvemos la secuencia (
returnSequences: false ), porque al final decimos que ahora necesitamos usar la función de activación para 64 caracteres diferentes (letras minúsculas y mayúsculas). 64 opciones se activan utilizando One-Hot Encoding.
Mas interesante
Ahora, probablemente se esté preguntando: “Esto es todo, por supuesto, bueno, pero ¿por qué lo necesito? "Combatir el cáncer es bueno, pero ¿por qué lo necesito en primera línea?"
Y comienzan los bailes con una pandereta: para descubrir cómo aplicar redes neuronales al diseño, por ejemplo.
Con la ayuda de redes neuronales es posible resolver problemas que antes eran imposibles de resolver. Algunos que ni siquiera se te ocurrieron. Todo depende de ti, tu imaginación y un poco de práctica.
Ahora mostraré ejemplos interesantes en vivo del uso de los modelos que examinamos.
CNN Equipos de audio
Usando redes de convolución, puede reconocer no solo imágenes, sino también comandos de audio, y con un 97% de calidad de reconocimiento, es decir, a nivel de Google Assistant y Yandex-Alice.
Solo en la red, por supuesto, no es posible reconocer el discurso completo, las oraciones, pero puede crear un asistente de voz simple.
Puede encontrar más información sobre Alice en el
informe de Nikita Dubko, y sobre el asistente de Google, cómo trabajar con voz en él y sobre los estándares del navegador,
aquí .
El hecho es que cualquier palabra, cualquier comando puede convertirse en un espectrograma.
Puede convertir cualquier información de audio en dicho espectrograma. Y luego puede codificar el audio en una imagen, aplicar CNN a la imagen y reconocer comandos de voz simples.
U-net. Prueba de captura de pantalla
U-Net es útil no solo para el diagnóstico exitoso del cáncer, sino también, por ejemplo, para probar capturas de pantalla. Para más detalles, vea el
informe de Lyudmila Mzhachikh, y le diré a la base misma.
Para probar con capturas de pantalla, se necesitan dos capturas de pantalla:
- básico (referencia) con el que estamos comparando;
- captura de pantalla para probar.

Desafortunadamente, en las pruebas de captura de pantalla, a menudo hay muchas caídas negativas (falsos positivos). Pero esto se puede evitar aplicando tecnologías avanzadas de control del cáncer en el front-end.
Recuerde, marcamos la imagen en el área donde hay cáncer y no. Lo mismo se puede hacer aquí.
Si vemos una imagen con un buen diseño, no la marcamos y marcamos imágenes con un diseño deficiente. Por lo tanto, puede probar el diseño con una sola imagen. , , , . U-Net .
, , . , U-Net, . , .
LSTM. Twitter — 2000
, , , .
, LSTM . 40 - , :
« — » .
, :

- , ?
— . - :


, «» , , (, ).
:
« » « » .
— .
« ».
:

EPOCS 250
, .
- , , , . , Overfitting — .
, — . , , . , , , .
, , .
, .

, , , . ( , ), . .
— . .
overfitting. , helper-: Dropout; BatchNormalization.
LSTM. Prettier
, — Prettier . , .
const a = 1 . :
[]c co on ns st , , :
[][] []c co on ns st , .
, , .
, , . , , 0 — , - , - . .
, . .
En lugar de conclusiones
, , . . , , Deep Neural Network.
. , . . . .
JS, , . , . , JavaScript, . TensorFlow.js.
, . telegram- JS.FrontendConf , 13 . 32 .
, , . Saint AppsConf, . , , , .