
Todos los días, los usuarios de 2GIS nos ayudan a mantener la precisión de los datos: informan sobre nuevas empresas, agregan eventos de tráfico, cargan fotos y escriben reseñas. Anteriormente, solo podíamos agradecerles con palabras o organizar un sorteo. Pero con el tiempo, las palabras se olvidan y no todos reciben regalos. Por lo tanto, decidimos asegurarnos de que todos aquellos que se preocupan por 2GIS vean su contribución al producto y nuestra gratitud por esto.
Así que hubo premios, medallas virtuales que acumulamos para varios tipos de tareas: subir fotos a tarjetas de café, escribir reseñas sobre teatros, especificar las horas de trabajo de las organizaciones, etc. Los usuarios ven las recompensas obtenidas en su perfil personal de 2GIS y en la pestaña "Mi 2GIS" en la aplicación móvil. Allí mostramos cuánto queda hasta el próximo logro.
Para implementar esta función, aprendimos cómo procesar una secuencia de eventos con un volumen de 500 mil registros por hora (en lugares de hasta 50 mil registros por segundo) y analizar datos de varios servicios. Y también: agregaron una pequeña metaprogramación para simplificar la configuración al desarrollar nuevos premios.
Junto con
Rapter , le diremos qué hay
detrás del proceso de adjudicación.
Concepto
Para comprender la complejidad de la función, debe comprender cómo sonó el problema técnico. Luego, considere la idea de implementación y el esquema general de los componentes del sistema. Esto es lo que haremos en esta sección.
Requisitos para resúmenes
Requisitos: algo bastante aburrido, por lo que no pintaremos todos los matices, nos concentraremos en las cosas más importantes:
- los premios se otorgan solo a usuarios autorizados;
- actualizar el progreso de una recompensa debe ser lo más rápido posible;
- recompensa: el resultado de un usuario que realiza un conjunto de acciones en el producto: subir una foto, escribir una reseña, encontrar instrucciones, etc. Hay muchas fuentes de datos.
Idea arquitectónica
La idea de implementación no es muy complicada. Se puede expresar de forma tesis:
- el premio consiste en tareas, cuyos resultados se combinan de acuerdo con la fórmula especificada al configurar el premio;
- la tarea responde a eventos sobre acciones de usuarios que provienen del exterior, los filtra y registra el cambio en progreso en forma de contadores;
- Los “eventos externos” son generados por sistemas maestros (foto, comentarios, servicios de refinamiento, etc.) o servicios auxiliares que transforman o filtran los flujos de eventos ya existentes;
- el procesamiento de eventos ocurre de forma asincrónica y puede detenerse en cualquier momento si es necesario;
- el usuario ve el estado actual de sus premios;
- todo lo demás son los detalles ...
Entidades clave
El siguiente diagrama muestra las principales entidades del área temática y su relación:

Se distinguen dos zonas en el diagrama:
- Esquema: una zona para describir la estructura de los premios y las reglas para su acumulación;
- Datos: área de adjudicación para usuarios específicos y datos relacionados con su estado actual.
Las entidades en el diagrama:
- Lograr: información sobre el premio que se puede obtener. Incluye metainformación y una descripción de cómo combinar los resultados de las tareas: una estrategia.
- Objetivo: una tarea, cuyas condiciones deben cumplirse para avanzar a recibir un premio.
- UserAchieve: el estado actual de la recompensa para un usuario en particular.
- UserObjective: el estado actual del trabajo de recompensa del usuario.
- Usuario: información sobre el usuario, necesaria para las notificaciones y la comprensión de su estado actual (no se necesitan recompensas remotas y prohibidas).
- ProcessingLog: un registro de acumulaciones para tareas. Contiene información sobre cómo una acción específica influyó en el progreso de la tarea.
- Evento: la información mínima necesaria sobre un evento que de alguna manera influyó en el progreso de las tareas del usuario.
Estructura de servicio
Ahora considere los componentes principales del servicio y sus dependencias:

- Bus de eventos: un bus de eventos que se puede utilizar para completar tareas. Estamos usando Apache Kafka.
- Las bases de datos maestras y esclavas son el almacén de datos principal. En este caso, un clúster PostgreSQL.
- ConsumingWorkers: controladores de eventos de autobuses. La tarea principal es leer eventos de una fuente específica (fotos, reseñas, etc.), aplicarlos a las tareas del usuario y guardar el resultado.
- AchievesWorker: relata el progreso de las recompensas de los usuarios según el estado de las tareas.
- NotificationWorkers: un conjunto de controladores para programar y enviar notificaciones sobre la recepción de premios, anuncios de nuevos logros posibles, etc.
- API pública: una interfaz REST pública para aplicaciones web y móviles.
- API privada: interfaz REST para el panel de administración, que ayuda en la investigación de incidentes y el servicio de soporte. Está disponible para desarrolladores y equipos de soporte.
Cada uno de los componentes está aislado en términos de lógica y áreas de responsabilidad, lo que evita integraciones innecesarias y puntos muertos al modificar los datos. A continuación, consideramos solo una parte del esquema asociado con el procesamiento de eventos y su conversión en recompensas.
Manejo de eventos
Contenido
Las recompensas son principalmente un servicio de agregación de datos. Cada sistema maestro genera varios tipos de eventos. Como regla general, cada tipo de evento está estrechamente relacionado con el estado del contenido, su modelo de estado. Por lo tanto, una foto puede ser moderada, eliminada, bloqueada, oculta o activa. Todos estos son eventos diferentes que son manejados por un trabajador separado que se especializa en una fuente en particular. En este momento, hay una interacción con las siguientes fuentes (sistemas maestros):
- Foto: genera varios eventos relacionados con las operaciones realizadas por los usuarios en las fotografías.
- Revisiones: eventos relacionados con operaciones en revisiones de usuarios.
- Retroalimentación de datos: eventos relacionados con operaciones de refinamiento. La aclaración es un cambio en la información sobre un objeto en un mapa, ya sea una empresa o un monumento.
- Check: eventos relacionados con la aplicación 2GIS Check.
- Los BSS son eventos analíticos que generan aplicaciones 2GIS. Por ejemplo, la apertura de una determinada empresa, viajes en el navegador, etc.

Los eventos generados por el sistema maestro caen en el tema de Kafka en el orden de cambiar sus estados, lo que hace posible avanzar el progreso de la adjudicación para el usuario no solo hacia adelante, sino también para retroceder. Por ejemplo, si la foto estaba en el estado "activo", y luego por alguna razón adquirió el estado de "bloqueado", el progreso de la adjudicación debería cambiar hacia abajo. El progreso del premio es una interpretación de objetos internos llamados contadores de contenido.
Los contadores pueden variar para diferentes datos. Por ejemplo, para eventos sobre la foto, son los siguientes: el número de aprobados, el número de moderación, el número de bloqueados y para eventos de tarjetas de apertura, debe considerar solo el número de tarjetas abiertas por el usuario. En función de los valores actuales de los contadores de contenido, para un usuario en particular, en el marco de un premio específico, se determinan las respuestas a las siguientes preguntas:
- ¿Ha comenzado el premio?
- cual es el progreso
- ¿La recompensa está completa?
Filtros y Reglas
Los contadores de trabajo de un premio en particular se cambian solo si un evento ha llegado con el tipo de contenido deseado, así como con los datos necesarios para recibir el premio.
Para omitir solo el contenido adecuado para el premio, ejecutamos cada evento a través de una serie de filtros y reglas.
Un filtro es una cierta restricción que se impone al contenido. Solo le preocupa responder la pregunta: "¿Un nuevo evento se ajusta a esta condición o no?"
Una regla es un filtro especial, cuyo propósito es decir: "Si un evento se ajusta a la condición, ¿cómo deberían cambiar los contadores?" La regla incluye un algoritmo para cambiar los contadores. Cada premio contiene solo una regla.
La implementación de filtros y reglas está en el código del proyecto, y la descripción de qué filtros (reglas) pertenecen a un premio en particular está en la base de datos en formato JSON. No tomamos tal decisión de inmediato. Inicialmente, los filtros y las reglas no se podían establecer usando la configuración a través de la base de datos, la adjudicación se describía completamente en el código, solo su identificador se almacenaba en la tabla. Esta decisión dio una serie de inconvenientes significativos:
- El problema de soportar múltiples entornos. Si desea implementar un estado de la lista de premios para el entorno de prueba y enviar otro a la batalla, debe conocer el código del entorno en el código del proyecto o tener un archivo de configuración con la lista de premios. Al mismo tiempo, no es posible utilizar diferentes bases de datos para esta tarea, aunque ya existen para cada entorno.
- Posibilidad de configurar el filtrado solo por el desarrollador. Como todo se describe en el código, solo una persona que conozca el proyecto y el lenguaje de programación podría hacer cambios, me gustaría que fuera posible hacerlo simplemente a través de la API privada o la base de datos.
- La desventaja de ver. Hay muchas recompensas, a veces necesitas ver los filtros que usan. Cada vez, hacer esto mirando el código es bastante tedioso.
Al comienzo de la aplicación, hacemos coincidir el nombre de los filtros cargados desde la base de datos y los colocamos en una recompensa específica. Ejemplo de descripción del filtro:
[ { "name":"SourceFilter", "config":{ "sources":["reviews"] } }, { "name": "ReviewsLengthFilter", "config": { "allowed_length": 100 } } ]
En este caso, tomaremos solo esas revisiones (esto se indica mediante el primer objeto de descripción de la matriz de filtros), cuyo texto contiene más de 100 caracteres (el segundo filtro en la lista).
Descripción de la regla de ejemplo:
{"name": "ReviewUniqueByObjectRule","config":{}}
Esta regla le permitirá cambiar los contadores solo si el usuario escribió una revisión para el objeto, mientras que solo se tendrá en cuenta una revisión para un objeto.
Bss
Detengámonos por separado trabajando con el flujo de eventos BSS. Hay al menos tres razones para esto:
- Los eventos analíticos no se pueden revertir, no hay ningún modelo de estado en ellos, lo que, en general, es lógico, porque no se puede cancelar la conducción a través del navegador o la construcción de una ruta. La acción estaba allí o no.
- Volúmenes Permítame recordarle que la audiencia total de 2GIS es de más de 50 millones de usuarios por mes. Juntos realizan más de 1.500 millones de consultas de búsqueda, así como muchas otras acciones: iniciar la aplicación, ver la tarjeta del objeto, etc. En el pico, el número de eventos puede llegar a 50.000 por segundo. Debemos pasar toda esta información a través de filtros para otorgar una recompensa al usuario.
- Los eventos analíticos tienen características: varios formatos, una amplia variedad de tipos.
Todo esto influyó mucho en el procesamiento de datos del tema BSS, ya que si necesitamos tiempo real, entonces necesitamos un tiempo de procesamiento muy cercano.
Para reducir las diferencias descritas, se ha creado un servicio separado que prepara tales eventos. El servicio puede funcionar con toda la variedad de formatos de mensajes provenientes de análisis. La esencia de su trabajo es la siguiente: se lee toda la secuencia de eventos de BSS, de la cual solo se toman los que se necesitan para los Premios. Tal filtro de servicio reduce significativamente la carga (después de filtrar, la velocidad de flujo es de ≈300 eventos por segundo) de las recompensas del procesador BSS-stream, y también genera eventos en un solo formato, nivelando la desventaja asociada con el historial de análisis interno.
Premios
Entonces, descubrimos cómo manejar eventos y calcular el progreso de las tareas. Ahora es el momento de echar un vistazo al proceso de emisión de recompensas para los usuarios.
La primera pregunta que surge es: ¿por qué asignar la salida a un trabajador separado, no se puede volver a contar al procesar cada evento? Respuesta: posible, pero no vale la pena.
Hay varias razones para asignar la extradición a un proceso separado:
- Al transferir el recuento a cada ConsumingWorker, obtenemos la Condición de carrera para la operación de actualizar el progreso por recompensa, porque cada controlador intentará actualizar el progreso en función del estado conocido de las tareas, y otros cambiarán activamente este estado.
- Cada lote de ConsumingWorker procesa eventos de Kafka en una transacción. Al agregar un inserto a la tabla de recompensas del usuario, llamaremos bloqueos adicionales a nivel de la base de datos, lo que inhibirá otros manejadores.
- En el proceso de emisión de premios, existe una lógica para enviar notificaciones que solo ralentizará el procesamiento del flujo de eventos, lo que no es deseable.
Se resolvieron los motivos de la aparición de un AchievesWorker (controlador para la entrega de premios) por separado. Ahora debe lidiar con dos partes importantes del procesamiento:
- Hay un conjunto de misiones en la recompensa. Hay un conjunto de contadores para estas tareas. ¿Cómo entender cuánto se otorga el premio y cómo expresarlo en código?
Ejemplo: necesita escribir 3 reseñas o subir 3 fotos. El usuario tiene 1 comentario y 2 fotos. ¿Cuál es el progreso del premio? Respuesta: 3, porque el usuario definitivamente estará seguro de que necesita 3 en total. - Tenemos un controlador separado para emitir premios. Cada vez, es poco probable que el recuento de varias docenas de premios para cada usuario autorizado, es decir, varias decenas de millones, tenga éxito rápidamente. ¿Cómo puede aprender sobre el progreso de qué usuarios particulares y qué tareas han cambiado desde el último procesamiento?
Consideraremos cada parte por separado.
Flujo de progreso
Para una mejor comprensión de cómo puede describir cómo transformar el progreso de las tareas en progreso por recompensa, dividimos las recompensas en categorías y observamos las transformaciones.
"Completa una tarea por X unidades". Ejemplo: conducir 10 km en el navegador.
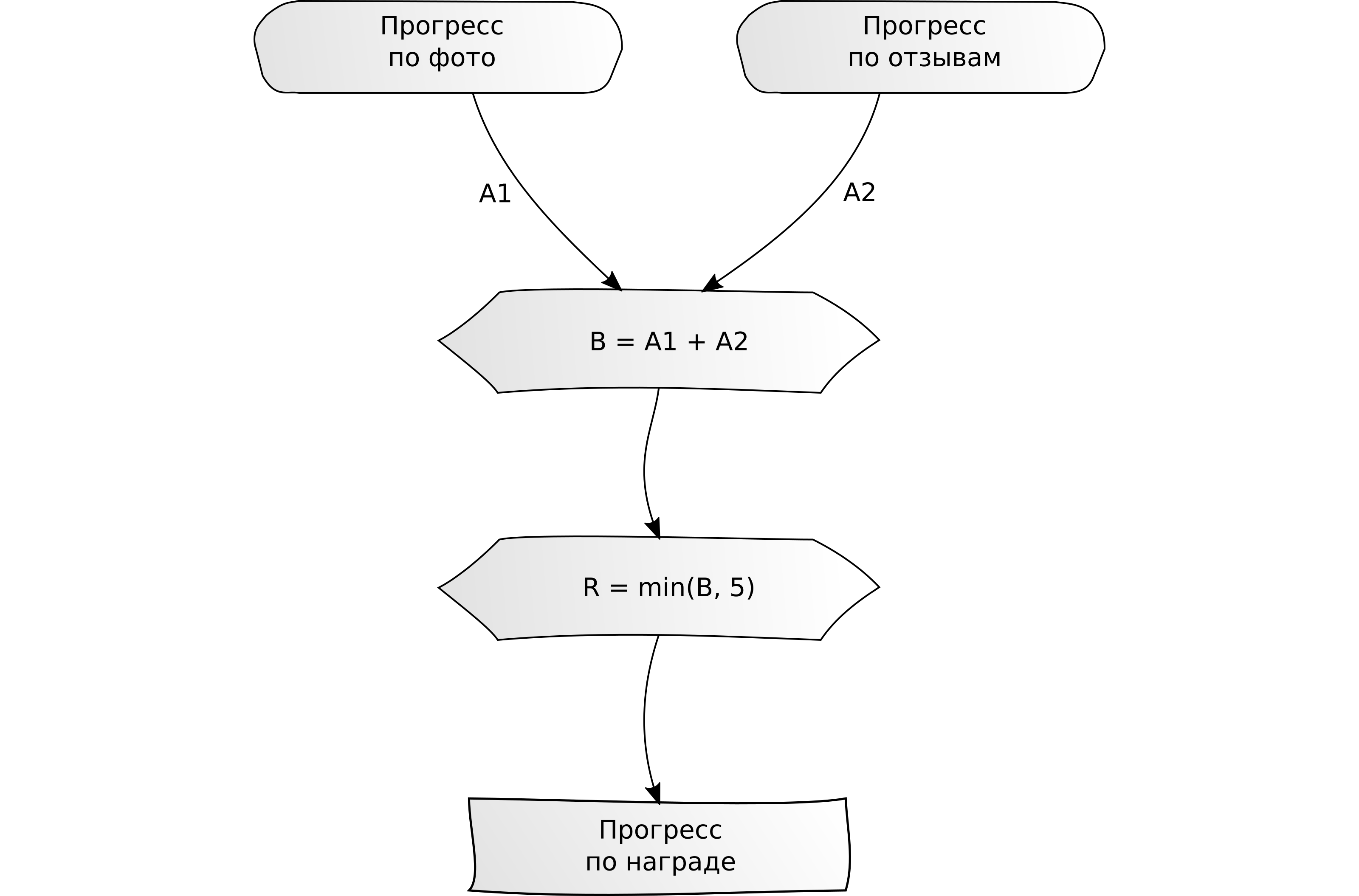
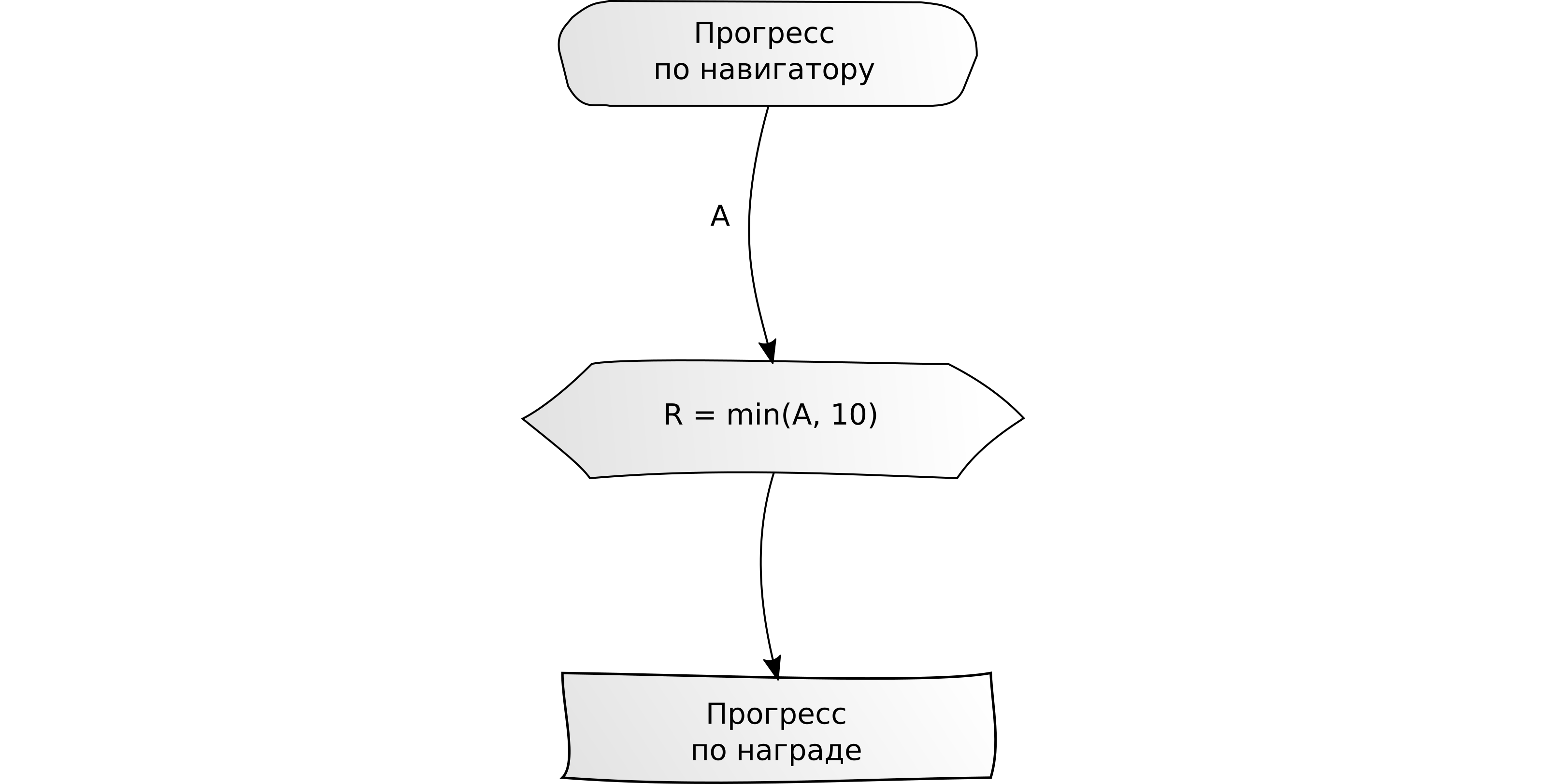 "Completa varias tareas para X unidades cada una".
"Completa varias tareas para X unidades cada una". Ejemplo: suba 5 fotos y escriba 5 reseñas en tarjetas, solo 10 unidades de contenido.
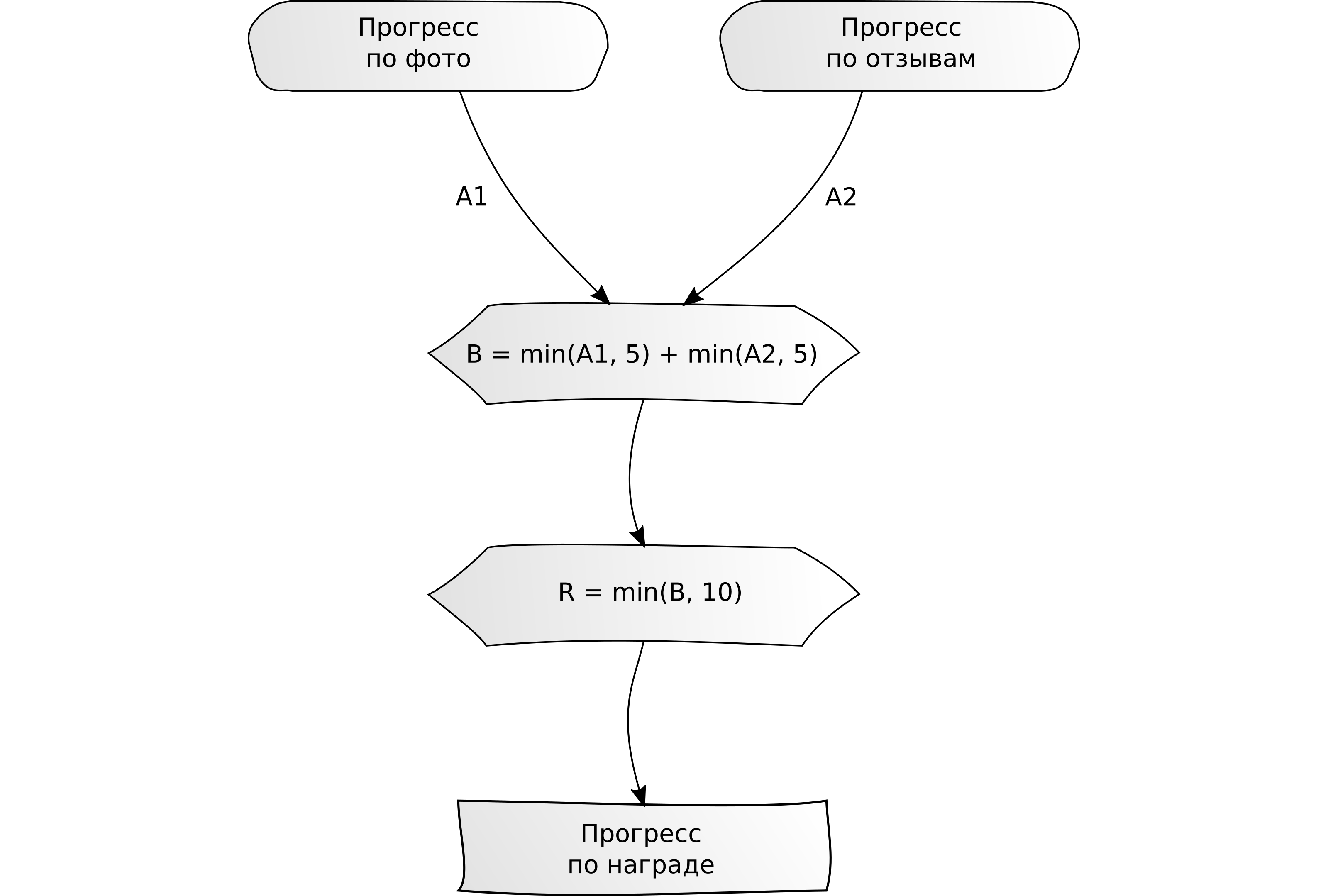 "Completa varias tareas para X unidades en total".
"Completa varias tareas para X unidades en total". Ejemplo: escribe 5 reseñas o sube 5 fotos.
 "Completa varias tareas agrupadas por tipo".
"Completa varias tareas agrupadas por tipo". Ejemplo: cargue 5 unidades de contenido (fotos o reseñas) y conduzca 10 km en el navegador.

Teóricamente, podría haber combinaciones anidadas más complejas. Sin embargo, en condiciones reales, no es posible explicar al usuario en dos o tres oraciones la combinación lógica compleja que debe realizarse para recibir el premio. Por lo tanto, en la mayoría de los casos, estas opciones son suficientes.
Llamamos al método de conversión una estrategia e intentamos hacerlo más o menos universal elaborando una descripción formal en forma de un objeto JSON. Podría, por supuesto, pensar en escribir en forma de una fórmula, pero luego tendría que usar similitudes para evaluar o describir la gramática e implementarla, y esto es claramente una complicación excesiva. Almacenar la estrategia en el código fuente para cada premio no es muy conveniente, porque la descripción del premio (parte de la base de datos y parte del código) se romperá, y tampoco permitirá la recolección de premios de componentes listos en el futuro sin la participación del desarrollo.
La estrategia se presenta en forma de árbol, donde cada nodo:
- Se refiere al progreso actual en la asignación o es un grupo de otros nodos.
- Puede tener una restricción máxima, de hecho, una indicación de la necesidad de usar min ().
- Puede tener un coeficiente de normalización. Necesario para conversiones simples multiplicando el resultado por un número. Fuimos útiles para convertir metros a kilómetros.
Para describir los ejemplos anteriores, una operación es suficiente: suma. La suma es excelente para mostrar claramente el progreso del usuario con un solo número, pero se pueden usar otras operaciones si se desea.
Aquí hay una descripción de estrategia de ejemplo para la última categoría:
{ "goal": 15, "operation": "sum", "strategy": [ { "goal": 5, "operation": "sum", "strategy": [ { "objective_id": "photo" }, { "objective_id": "reviews" } ] }, { "goal": 10, "operation": "sum", "strategy": [ { "objective_id": "navi", "normalization_factor": 0.001 } ] } ] }
Actualizaciones requeridas
Existen varios controladores que analizan sin descanso los eventos de los usuarios y aplican cambios al progreso de las tareas. Una búsqueda regular de todos los usuarios con cada premio llevará a un análisis de varias decenas de millones de premios, lo que no es muy alentador, siempre que las actualizaciones reales se midan en miles. ¿Cómo aprender solo sobre miles y no desperdiciar millones de CPU?
La idea de cómo volver a calcular el progreso solo en aquellos premios que realmente han cambiado, surgió con bastante rapidez. Se basa en el uso de relojes vectoriales.
Antes de la descripción recordaré entidades:
- UserObjective: datos sobre el progreso del usuario al establecer el premio.
- UserAchieve: recompensa los datos de progreso del usuario.
La implementación se ve así:
- Obtenemos el campo de versión para UserObjective y UserAchieve and Sequence en PostgreSQL.
- Cada actualización de la entidad UserObjective cambia su versión. El valor se toma de la secuencia (lo tenemos en común para todos los registros).
- El valor de la versión para UserAchieve se determinará como el máximo de las versiones del UserObjective asociado.
- En cada ciclo de procesamiento, AchievesWorker busca dicho UserObjective para el que no hay UserAchieve o UserAchieve.version <UserObjective.version. El problema se resuelve con una sola consulta a la base de datos.
Vale la pena señalar que la solución tiene limitaciones en el número de entradas en las tablas de premios y tareas, así como en la frecuencia de los cambios en el progreso de las tareas, pero con un par de decenas de millones de premios y el número de actualizaciones de menos de mil por minuto, es bastante posible vivir con una solución de este tipo. De alguna manera, informaremos por separado sobre cómo optimizamos la emisión del concurso "
Agentes 2GIS ".
Conclusiones
A pesar de que el artículo resultó ser bastante voluminoso, quedaron muchos matices detrás de escena, ya que no sería posible hablar brevemente sobre ellos.
¿Qué conclusiones hemos llegado gracias a los Premios?
- El principio de "divide y vencerás" en este caso jugó en nuestras manos. La asignación de controladores de eventos a cada fuente nos ayuda a escalar cuando es necesario. Su trabajo está aislado según los datos y se cruza solo en áreas pequeñas. La lógica de recompensa destacada le permite reducir los gastos generales en los controladores de eventos.
- Si necesita digerir una gran cantidad de datos y el procesamiento es bastante costoso, debe pensar inmediatamente en cómo filtrar lo que definitivamente no es necesario. La experiencia con el filtrado de una secuencia BSS es un ejemplo.
- Una vez más, estábamos convencidos de que la integración de servicios a través de un bus de eventos común es muy conveniente y le permite evitar cargas innecesarias en otros servicios. Si el servicio de Recompensas recibió datos de servicios de Foto, Reseñas, etc. a través de solicitudes http, entonces varios servicios tendrían que estar preparados para una carga adicional.
- Un poco de metaprogramación puede ayudar a mantener la integridad de la configuración de datos y separar entornos de forma arbitraria. El almacenamiento de filtros, reglas y estrategias en la base de datos simplificó el proceso de desarrollo y lanzamiento de nuevos premios.