Nota perev. : El ingeniero líder de Zalando, Henning Jacobs, ha notado repetidamente problemas con los usuarios de Kubernetes para comprender el propósito de las sondas de vida (y preparación) y su aplicación correcta. Por lo tanto, reunió sus pensamientos en este artículo espacioso, que con el tiempo se convertirá en parte de la documentación del K8.
Los controles de salud, conocidos en Kubernetes como
sondas de vida (es decir, literalmente, "pruebas de viabilidad" - aprox. Transl.) , Pueden ser bastante peligrosos. Recomiendo evitarlos siempre que sea posible: las únicas excepciones son los casos en que son realmente necesarios y usted es plenamente consciente de los detalles y las consecuencias de su uso. Esta publicación se centrará en los controles de vida y preparación, y también explicará en qué casos
vale la pena y no vale la pena usarlos.
Mi colega Sandor recientemente compartió en Twitter los errores más comunes que encuentra, incluidos los relacionados con el uso de sondas de preparación / vitalidad:
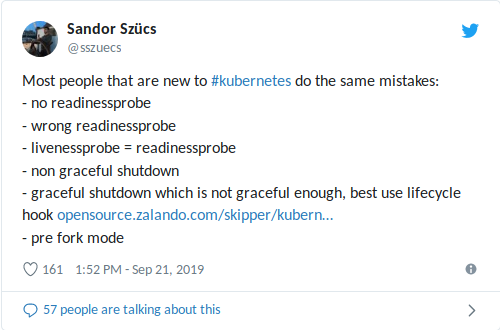
Un livenessProbe configurado incorrectamente puede agravar situaciones con una carga alta (apagado de avalancha + lanzamiento potencialmente prolongado del contenedor / aplicación) y provocar otras consecuencias negativas, como una caída en las dependencias
(consulte también mi artículo reciente sobre la limitación del número de solicitudes en el paquete K3s + ACME) . Peor aún, cuando una sonda de vida se combina con un control de estado, que actúa como una base de datos externa: ¡la
única falla de la base de datos reiniciará todos sus contenedores !
El mensaje general
"No utilizar sondas de vida" en este caso ayuda un poco, por lo tanto, consideraremos para qué sirven los controles de disponibilidad y vida.
Nota: La mayoría de las pruebas a continuación se incluyeron originalmente en la documentación interna para los desarrolladores de Zalando.Verificaciones de preparación y vida
Kubernetes proporciona dos mecanismos importantes llamados
sondas de vida y sondas de preparación . Periódicamente realizan alguna acción, por ejemplo, enviar una solicitud HTTP, abrir una conexión TCP o ejecutar un comando en un contenedor, para confirmar que la aplicación funciona correctamente.
Kubernetes utiliza
sondas de preparación para comprender cuándo un contenedor está listo para recibir tráfico. Una cápsula se considera lista para funcionar si todos sus contenedores están listos. Una aplicación de este mecanismo es controlar qué pods se usan como backends para los servicios de Kubernetes (y especialmente Ingress).
Las sondas de vida ayudan a Kubernetes a comprender cuándo es el momento de reiniciar el contenedor. Por ejemplo, tal verificación le permite interceptar el punto muerto cuando la aplicación está "atascada" en un lugar. Reiniciar el contenedor en este estado ayuda a mover la aplicación del suelo, a pesar de los errores, pero también puede provocar fallas en cascada (ver más abajo).
Si intenta implementar una actualización en una aplicación que no pasa las comprobaciones de estado / disponibilidad, su implementación se detendrá porque Kubernetes esperará el estado
Ready de todos los pods.
Ejemplo
Aquí hay una sonda de preparación de ejemplo que verifica la ruta
/health a través de HTTP con la configuración predeterminada (
intervalo : 10 segundos,
tiempo de espera : 1 segundo,
umbral de éxito : 1,
umbral de falla : 3):
# deployment'/ podTemplate: spec: containers: - name: my-container # ... readinessProbe: httpGet: path: /health port: 8080
Recomendaciones
- Para microservicios con un punto final HTTP (REST, etc.) siempre defina una sonda de preparación que verifique si la aplicación (pod) está lista para recibir tráfico.
- Asegúrese de que la sonda de preparación cubra la disponibilidad del puerto real del servidor web :
- Usando puertos para necesidades administrativas llamadas "admin" o "administración" (por ejemplo, 9090) para
readinessProbe , asegúrese de que el punto final regrese OK solo si el puerto HTTP principal (como 8080) está listo para aceptar tráfico *;
* Sé de al menos un caso en Zalando cuando esto no sucedió, es decir, readinessProbe verificó el puerto de "administración", pero el servidor en sí no se inició debido a problemas al cargar el caché. - colgar la sonda de preparación en un puerto separado puede llevar al hecho de que la congestión en el puerto principal no se reflejará en la comprobación de estado (es decir, el grupo de subprocesos en el servidor está lleno, pero la comprobación de estado aún muestra que todo está bien).
- Asegúrese de que la sonda de preparación permita la inicialización / migración de la base de datos ;
- la forma más fácil de lograr esto es acceder al servidor HTTP solo después de que se complete la inicialización (por ejemplo, migración de la base de datos desde Flyway , etc.); es decir, en lugar de cambiar el estado de la comprobación de estado, simplemente no inicie el servidor web hasta que se complete la migración de la base de datos *.
* También puede ejecutar migraciones de bases de datos desde contenedores init fuera del pod. Todavía soy un fanático de las aplicaciones autónomas, es decir, aquellas en las que el contenedor de la aplicación sin coordinación externa sabe cómo llevar la base de datos al estado deseado.
- Utilice
httpGet para las comprobaciones de preparación a través de los puntos finales típicos de las comprobaciones de estado (p /health Ej. /health ). successThreshold: 1 predeterminada ( interval: 10s , timeout: 1s , successThreshold: 1 , failureThreshold: 3 ):- los parámetros predeterminados significan que el pod no estará listo después de unos 30 segundos (3 comprobaciones de estado fallidas).
- Use un puerto separado para "admin" o "administración" si la pila de tecnología (por ejemplo, Java / Spring) permite que esto separe la administración del estado y las métricas del tráfico normal:
- pero no te olvides del párrafo 2.
- Si es necesario, la sonda de preparación se puede usar para calentar / cargar el caché y devolver el código de estado 503 hasta que el contenedor se "caliente":
Advertencias
- No confíe en dependencias externas (como el almacenamiento de datos) al realizar pruebas de disponibilidad / vida; esto puede conducir a fallas en cascada:
- Como ejemplo, tomemos un servicio REST con estado con 10 pods dependiendo de una base de datos Postgres: cuando la verificación depende de una conexión de trabajo a la base de datos, los 10 pods pueden caerse si hay un retraso en la red / en el lado de la base de datos. generalmente todo termina peor de lo que podría;
- tenga en cuenta que Spring Data por defecto verifica la conexión a la base de datos *;
* Este es el comportamiento predeterminado de Spring Data Redis (al menos era como cuando lo comprobé la última vez), lo que condujo a una falla "catastrófica": cuando Redis no estuvo disponible por un corto tiempo, todos los pods "cayeron". - "Externo" en este sentido también puede significar otros pods de la misma aplicación, es decir, idealmente, la verificación no debe depender del estado de otros pods del mismo clúster para evitar bloqueos en cascada:
- los resultados pueden variar para aplicaciones de estado distribuido (por ejemplo, almacenamiento en caché en memoria en pods).
- No utilice la sonda de vida para las cápsulas (las excepciones son casos en los que son realmente necesarios y usted es plenamente consciente de los detalles y las consecuencias de su uso):
- la sonda de vida útil puede ayudar a recuperar contenedores "colgados", pero dado que usted tiene control total sobre su aplicación, lo ideal sería que no ocurrieran procesos y puntos muertos "colgados": la mejor alternativa es soltar la aplicación intencionalmente y devolverla a estado estacionario anterior;
- una sonda de vida fallida reiniciará el contenedor, lo que puede exacerbar las consecuencias de los errores de carga: reiniciar el contenedor provocará un tiempo de inactividad (al menos por el tiempo de inicio de la aplicación, por ejemplo, durante más de 30 segundos), causando nuevos errores, aumentando la carga en otros contenedores y aumentar la probabilidad de falla, etc.
- Los controles de vida combinados con una dependencia externa son las peores combinaciones posibles, lo que puede conducir a fallas en cascada: ¡un ligero retraso en el lado de la base de datos reiniciará todos sus contenedores!
- Los parámetros para las comprobaciones de vida y preparación deben ser diferentes :
- puede usar la sonda de vida con la misma comprobación de estado, pero un umbral más alto (umbral de
failureThreshold ), por ejemplo, asigne el estado no listo después de 3 intentos y suponga que la sonda de vida falló después de 10 intentos;
- No utilice controles de ejecución , ya que están asociados con problemas conocidos que conducen a la aparición de procesos zombies:
Resumen
- Use sondas de preparación para determinar cuándo un pod está listo para recibir tráfico.
- Use sondas de vitalidad solo cuando sean realmente necesarias.
- El uso incorrecto de las sondas de preparación / vida puede conducir a una disponibilidad reducida y fallas en cascada.

Materiales adicionales sobre el tema.
Actualización No1 de 2019-09-29
Acerca de los contenedores init para la migración de la base de datos : nota al pie agregada.
EJ me recordó a PDB: uno de los problemas de los controles de vida es la falta de coordinación entre las cápsulas. Kubernetes tiene
Presupuestos de interrupción de pod (PDB) para limitar el número de fallas concurrentes que puede experimentar una aplicación, pero las comprobaciones no tienen en cuenta los PDB. Idealmente, podemos ordenar los K8: "Reinicie un pod si falla su verificación, pero no los reinicie todos para no empeorarlo".
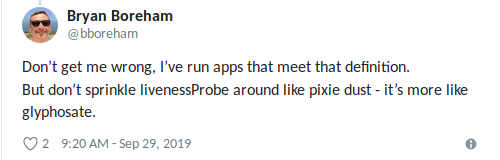
Bryan perfectamente formulado : "Utilice el sonido vivo cuando sepa con certeza que lo
mejor que puede hacer es" matar "la aplicación " (de nuevo, no se deje llevar).
Actualización n. ° 2 del 29/09/2019
Con respecto a la lectura de la documentación antes de su uso : creé una
solicitud de función para complementar la documentación sobre sondas de vida.
PD del traductor
Lea también en nuestro blog: