
Introduccion
Hola, queridos Khabrovites!
Los últimos dos años de mi trabajo en
Synesis han estado estrechamente relacionados con el proceso de creación y desarrollo de
Synet , una biblioteca abierta para ejecutar redes neuronales convolucionales previamente capacitadas en la CPU. En el proceso de este trabajo, tuve que encontrar una serie de puntos interesantes relacionados con la optimización de algoritmos de propagación de señal directa en redes neuronales. Me parece que una descripción de estos puntos sería muy interesante para los lectores de Habrahabr. A lo que quiero dedicar una serie de mis artículos. La duración del ciclo dependerá de su interés en este tema y, por supuesto, de mi capacidad para superar la pereza. Quiero comenzar el ciclo con una descripción de la
bicicleta marco en sí. Las preguntas de los algoritmos que subyacen se revelarán en artículos posteriores:
- Capa de convolución: técnicas de optimización de multiplicación matricial
- Capa convolucional: convolución rápida según el método de Shmuel Vinograd
Respuestas a preguntas
Antes de comenzar una descripción detallada del marco, intentaré responder de inmediato una serie de preguntas que probablemente tendrán los lectores. La experiencia sugiere que es mejor hacerlo con anticipación, ya que muchos comienzan a escribir comentarios enojados de inmediato, sin haber leído hasta el final.
La primera pregunta que suele surgir en tales casos:
¿quién ejecuta redes en procesadores convencionales ahora, cuándo hay aceleradores gráficos y aceleradores de tensor (matriz)?Responderé que sí, realmente no es aconsejable llevar a cabo la capacitación de redes neuronales en la CPU, pero ejecutar redes neuronales listas para usar es una gran demanda, especialmente si la red es lo suficientemente pequeña. Las razones para esto pueden ser diferentes, pero las principales:
- Las CPU son más comunes. No todas las máquinas tienen una GPU, especialmente los servidores.
- En redes neuronales pequeñas, las ganancias del uso de la GPU son pequeñas y, a veces, completamente ausentes.
- La participación efectiva de la GPU para acelerar las redes neuronales generalmente requiere una estructura de aplicación significativamente más compleja.
La siguiente pregunta posible:
¿Por qué usar una solución especializada para iniciar cuando hay Tensorflow , Caffe o MXNet ?Puedes responder lo siguiente:
- Una variedad de marcos no siempre es buena, por lo que si hay varios modelos capacitados en diferentes marcos en un proyecto, entonces tendrá que integrarlos en una solución preparada, lo cual es muy inconveniente.
- Los marcos clásicos fueron diseñados para entrenar modelos de GPU, ¡y ciertamente son buenos para eso! Pero para ejecutar modelos entrenados en la CPU, su funcionalidad es redundante y no óptima.
- La confirmación de la necesidad de una solución especializada es la popularidad de OpenVINO , un marco de Intel que realiza la misma función.
Aquí inmediatamente surge una pregunta lógica sobre la invención de la bicicleta:
¿Por qué usar su oficio cuando hay una solución completamente profesional de un líder mundial reconocido?Mi respuesta es:
- Al comienzo del trabajo en Synet, OpenVINO todavía estaba en su infancia. Y en verdad, si en ese momento OpenVINO estaba en su estado actual, entonces con un alto grado de probabilidad no me involucraría en mi propio proyecto.
- Puede adaptar su propio marco a sus necesidades. Entonces, en mi caso, el requisito principal era el rendimiento máximo de un solo subproceso.
- Puede proporcionar soporte para una nueva funcionalidad lo más rápido posible si la necesita de repente (por ejemplo, agregue una nueva capa y elimine un error de rendimiento).
- Fácil de integrar en una solución llave en mano.
- El funcionamiento de la biblioteca en plataformas que no sean x86 / x86_64, por ejemplo, en ARM.
Es probable que los lectores tengan otras preguntas u objeciones, pero aún no puedo predecirlas y, por lo tanto, responderé en los comentarios al artículo. Mientras tanto, comencemos con una descripción directa de Synet.
Descripción breve de Synet
Synet está escrito en
C ++ y contiene solo
archivos de encabezado . Las optimizaciones
específicas de plataforma de bajo nivel se implementan en
Simd , otro proyecto de código abierto dedicado a acelerar el procesamiento de imágenes en una CPU. Y esta es la única dependencia externa de Synet (se eligió dicho esquema para facilitar la integración de la biblioteca en proyectos de terceros). Para lanzar redes neuronales, se utilizan modelos de su propio formato interno.
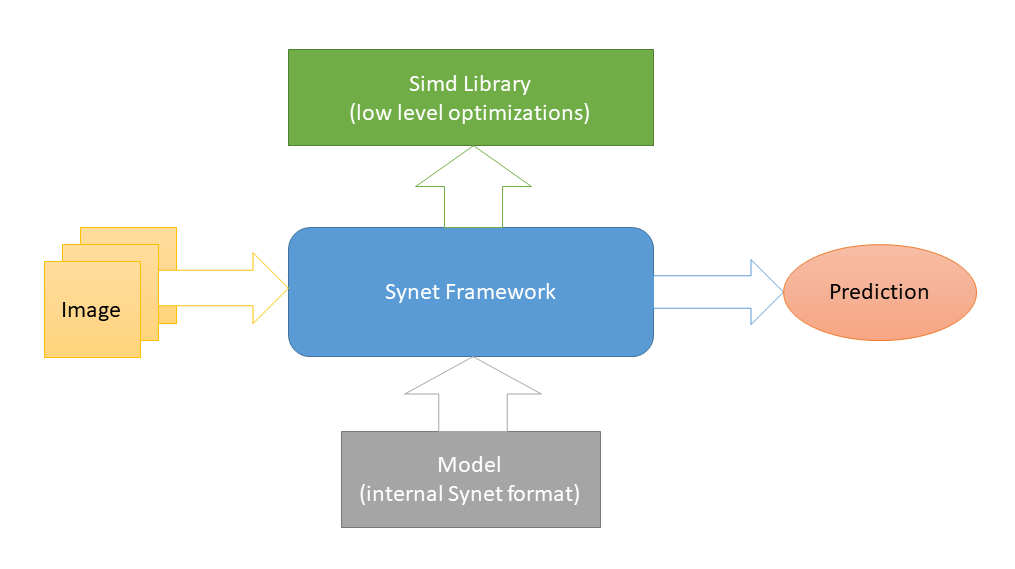
La conversión de modelos pre-entrenados al formato interno se lleva a cabo de acuerdo con un esquema de dos pasos: 1) Primero, convierta el modelo al formato del motor de inferencia (bueno
OpenVINO tiene todas las
herramientas necesarias para esto). 2) Luego, desde esta representación intermedia, convierta directamente al formato interno de Synet.

El modelo Synet contiene dos archivos: 1) * .XML: un archivo con una descripción de la estructura del modelo. 2) * .BIN: un archivo con pesas entrenadas.

Ejemplo de Synet
El siguiente es un ejemplo del uso de Synet para detectar caras.
Aquí se toma el modelo original del motor de inferencia.
#define SYNET_SIMD_LIBRARY_ENABLE #include "Synet/Network.h" #include "Synet/Converters/InferenceEngine.h" #include "Simd/SimdDrawing.hpp" typedef Synet::Network<float> Net; typedef Synet::View View; typedef Synet::Shape Shape; typedef Synet::Region<float> Region; typedef std::vector<Region> Regions; int main(int argc, char* argv[]) { Synet::ConvertInferenceEngineToSynet("ie_fd.xml", "ie_fd.bin", true, "synet.xml", "synet.bin"); Net net; net.Load("synet.xml", "synet.bin"); net.Reshape(256, 256, 1); Shape shape = net.NchwShape(); View original; original.Load("faces_0.ppm"); View resized(shape[3], shape[2], original.format); Simd::Resize(original, resized, ::SimdResizeMethodArea); net.SetInput(resized, 0.0f, 255.0f); net.Forward(); Regions faces = net.GetRegions(original.width, original.height, 0.5f, 0.5f); uint32_t white = 0xFFFFFFFF; for (size_t i = 0; i < faces.size(); ++i) { const Region & face = faces[i]; ptrdiff_t l = ptrdiff_t(face.x - face.w / 2); ptrdiff_t t = ptrdiff_t(face.y - face.h / 2); ptrdiff_t r = ptrdiff_t(face.x + face.w / 2); ptrdiff_t b = ptrdiff_t(face.y + face.h / 2); Simd::DrawRectangle(original, l, t, r, b, white); } original.Save("annotated_faces_0.ppm"); return 0; }
Como resultado del ejemplo, debería aparecer una imagen con caras anotadas:

Ahora tomemos un ejemplo de los pasos:
- Primero, el modelo se convierte del formato del motor de inferencia a Synet:
Synet::ConvertInferenceEngineToSynet("ie_fd.xml", "ie_fd.bin", true, "synet.xml", "synet.bin");
En realidad, este paso se realiza una vez, y luego el modelo ya convertido se usa en todas partes. - Descargar modelo convertido:
Net net; net.Load("synet.xml", "synet.bin");
- Un paso opcional para cambiar el tamaño de la imagen de entrada y el lote (naturalmente, el modelo debe admitir cambiar el tamaño de la imagen de entrada):
net.Reshape(256, 256, 1);
- Cargar una imagen y llevarla al tamaño de entrada del modelo:
View original; original.Load("faces_0.ppm"); View resized(net.NchwShape()[3], net.NchwShape()[2], original.format); Simd::Resize(original, resized, ::SimdResizeMethodArea);
- Cargando imagen en modelo:
net.SetInput(resized, 0.0f, 255.0f);
- Inicio de la propagación de señal directa en la red:
net.Forward();
- Obtención de un conjunto de regiones con caras encontradas:
Regions faces = net.GetRegions(original.width, original.height, 0.5f, 0.5f);
Comparación de rendimiento
Probablemente no sería del todo correcto comparar Synet con los marcos clásicos para el aprendizaje automático, por ejemplo, el motor de inferencia los
omite varias veces en varias pruebas .
Por lo tanto, el siguiente es un ejemplo de comparación del rendimiento de subproceso único del motor de inferencia (un producto de funcionalidad similar) y Synet en una muestra de un
conjunto de modelos abiertos :
Como se puede ver en la tabla, en estas pruebas en una máquina con soporte para AVX2 (i7-6700), el rendimiento de Synet generalmente corresponde al rendimiento del motor de inferencia (aunque varía mucho de un modelo a otro). En una máquina con soporte para el AVX-512 (i9-7900X), el rendimiento de Synet es en promedio un 25% más alto que el del motor de inferencia.
Todas las mediciones fueron realizadas por la aplicación de prueba, que se encuentra en Synet. Entonces, si lo desea, los lectores podrán reproducir las pruebas ellos mismos:
git clone -b master --recurse-submodules -v https://github.com/ermig1979/Synet.git synet cd synet ./build.sh inference_engine ./test.sh
Ventajas y desventajas.
Comenzaré con los profesionales:
- El proyecto es pequeño, se implementa fácilmente en proyectos de terceros.
- Muestra un alto rendimiento de subproceso único.
- Funciona en procesadores móviles (soporta ARM-NEON).
Bueno y contras, donde sin ellos:
- No hay soporte para GPU y otros aceleradores especiales.
- Poca paralelización de una tarea en CPU de varios núcleos.
- No hay soporte para INT8 (cuantización de pesos).
Conclusión
Synet se está utilizando actualmente como parte del proyecto
Kipod , una plataforma basada en la nube para análisis de video. Quizás tenga otros usuarios, pero eso no es seguro :). En el futuro, a medida que se desarrolle el proyecto, me gustaría agregarle lo siguiente:
- Soporte para nuevos modelos, capas, algoritmos.
- Soporte para cálculos enteros en formato INT8 (pesos cuantificados).
- Soporte informático GPU.
- Convierte del formato ONNX.
Esta lista está lejos de ser completa, y me gustaría complementarla teniendo en cuenta la opinión de la comunidad, por lo tanto, ¡espero sus comentarios! Para que la herramienta sea útil no solo para nuestra empresa, sino también para una amplia gama de usuarios. Además, el autor no rechazaría la asistencia de la comunidad en el proceso de desarrollo.
Al describir Synet, que hice en este artículo, deliberadamente no profundicé en los detalles de su implementación interna: hay muchos algoritmos sabrosos bajo el capó, pero me gustaría revelar los detalles de su implementación en los siguientes artículos de la serie:
- Capa de convolución: técnicas de optimización de multiplicación matricial
- Capa convolucional: convolución rápida según el método de Shmuel Vinograd