Continuación de la traducción de un pequeño libro:
"Comprender los corredores de mensajes",
autor: Jakub Korab, editor: O'Reilly Media, Inc., fecha de publicación: junio de 2017, ISBN: 9781492049296.
Traducción completadaParte anterior:
Comprender los corredores de mensajes. Aprendiendo la mecánica de la mensajería a través de ActiveMQ y Kafka. Capítulo 1. IntroducciónCAPITULO 2
Activemq
ActiveMQ se describe mejor como un sistema de mensajería clásico. Fue escrito en 2004 para satisfacer la necesidad de un agente de mensajes de código abierto. En ese momento, si deseaba utilizar la mensajería en sus aplicaciones, la única opción eran los productos comerciales caros.
ActiveMQ se desarrolló como una implementación de la especificación Java Message Service (JMS). Esta decisión se tomó para cumplir con los requisitos para implementar la mensajería compatible con JMS en el proyecto Apache Geronimo, un servidor de aplicaciones J2EE de código abierto.
Un sistema de mensajería (o middleware orientado a mensajes, como a veces se le llama) que implementa la especificación JMS consta de los siguientes componentes:
CorredorUna pieza central de middleware que distribuye mensajes.
ClienteEl software que envía mensajes a través de un corredor. A su vez, consta de los siguientes artefactos:
- Código usando la API JMS.
- La API JMS es un conjunto de interfaces para interactuar con un agente de acuerdo con las garantías establecidas en la especificación JMS.
- La biblioteca del cliente del sistema que proporciona la implementación de la API e interactúa con el intermediario.
El cliente y el agente se comunican entre sí a través del protocolo de capa de aplicación, también conocido como
protocolo de interacción (Figura 2-1) . La especificación JMS dejó los detalles de este protocolo a implementaciones específicas.
 Figura 2-1. Revisión de JMS
Figura 2-1. Revisión de JMSJMS utiliza el término
proveedor para describir la implementación del proveedor del sistema de mensajería subyacente a la API de JMS, que incluye el intermediario, así como sus bibliotecas cliente.
La elección a favor de implementar JMS tuvo consecuencias de largo alcance para las decisiones de implementación tomadas por los autores de ActiveMQ. La especificación en sí misma proporciona una guía clara sobre las responsabilidades del cliente del sistema de mensajería y el agente con el que se comunica, dando preferencia a la obligación del agente de distribuir y entregar mensajes. La responsabilidad principal del cliente es interactuar con el destinatario (cola o tema) de los mensajes enviados por él. La especificación en sí está destinada a hacer que la interacción de la API con el intermediario sea relativamente simple.
Esta área, como veremos más adelante, tuvo un impacto significativo en el rendimiento de ActiveMQ. Además de las complejidades del corredor, el paquete de compatibilidad para la especificación proporcionada por Sun Microsystems tenía muchos matices, con su propio impacto en el rendimiento. Todos estos matices deberían haberse tenido en cuenta para que ActiveMQ se considere compatible con JMS.
Comunicación
Aunque la API y el comportamiento esperado estaban bien definidos en la especificación JMS, el protocolo de comunicación cliente-intermediario real se excluyó deliberadamente de la especificación para que los intermediarios existentes pudieran cumplir con JMS. Por lo tanto, ActiveMQ era libre de definir su propio protocolo de interacción, OpenWire. OpenWire es utilizado por la implementación de la biblioteca de cliente ActiveMQ JMS, así como sus contrapartes en .Net y C ++: NMS y CMS, que son subproyectos de ActiveMQ alojados por Apache Software Foundation.
Con el tiempo, se agregó soporte para otros protocolos de interacción a ActiveMQ, lo que aumentó la capacidad de interactuar con otros lenguajes y entornos:
AMQP 1.0El Protocolo avanzado de colas de mensajes (ISO / IEC 19464: 2014) no debe confundirse con su predecesor 0.X, que se implementa en otros sistemas de mensajería, en particular RabbitMQ, usando 0.9.1. AMQP 1.0 es un protocolo binario de propósito general para intercambiar mensajes entre dos nodos. No tiene ningún concepto de clientes o intermediarios e incluye funciones como control de flujo, transacciones y varias QoS (no más de una vez, al menos una vez y exactamente una vez).
PisarProtocolo de mensajería orientado a texto simple / continuo, un protocolo fácil de implementar que tiene docenas de implementaciones de clientes en diferentes idiomas.
XmppMensajería extensible y protocolo de presencia. (Protocolo extensible de mensajería y presencia). Anteriormente llamado Jabber, este protocolo basado en XML se desarrolló originalmente para sistemas de chat, pero se ha extendido más allá de sus casos de uso originales para incluir mensajes de publicación-suscripción.
MQTTEl protocolo ligero de publicación-suscripción (ISO / IEC 20922: 2016) utilizado para aplicaciones de máquina a máquina (M2M) e Internet de las cosas (IoT).
ActiveMQ también admite la imposición de los protocolos anteriores en WebSockets, que proporciona el intercambio de datos full-duplex entre aplicaciones en un navegador web y destinos en el intermediario.
Dado esto, ahora cuando hablamos de ActiveMQ, ya no nos referimos exclusivamente a la pila de interacción basada en las bibliotecas JMS / NMS / CMS y el protocolo OpenWire. La combinación y selección de idiomas, plataformas y bibliotecas externas que mejor se adaptan a esta aplicación se está volviendo cada vez más popular. Por ejemplo, es posible que una aplicación de JavaScript se ejecute en un navegador usando la biblioteca
Eclipse Paho MQTT para enviar mensajes a ActiveMQ a través de sockets web, y estos mensajes son leídos por un proceso de servidor C ++ que usa AMQP a través de la biblioteca
Apache Qpid Proton . Desde esta perspectiva, el panorama de los mensajes se está volviendo más diverso.
Mirando hacia el futuro, AMQP, en particular, tendrá muchas más oportunidades de las que tiene ahora, ya que los componentes que no son clientes ni corredores se están convirtiendo en una parte más familiar del panorama de la mensajería. Por ejemplo,
Apache Qpid Dispatch Router actúa como un enrutador de mensajes, al que los clientes se conectan directamente, permitiendo que diferentes destinos procesen diferentes direcciones, además de proporcionar la posibilidad de fragmentación (separación).
Cuando trabaje con bibliotecas de terceros y componentes externos, tenga en cuenta que tienen una calidad variable y pueden no ser compatibles con las funciones proporcionadas en ActiveMQ. Como un ejemplo muy simple: es imposible enviar mensajes a la cola a través de MQTT (sin configurar el enrutamiento en el intermediario). Por lo tanto, necesitará pasar algún tiempo trabajando con las opciones para determinar la pila del sistema de mensajería más adecuada para los requisitos de su aplicación.
El compromiso entre rendimiento y confiabilidad
Antes de profundizar en los detalles de cómo funciona la mensajería punto a punto en ActiveMQ, necesitamos hablar un poco sobre lo que enfrentan todos los sistemas con procesamiento de datos pesados: una compensación entre rendimiento y confiabilidad.
Cualquier sistema que acepte datos, ya sea un intermediario de mensajes o una base de datos, debe recibir instrucciones sobre cómo procesar estos datos en caso de falla. La falla puede tomar muchas formas, pero por simplicidad la reduciremos a una situación en la que el sistema pierde energía y se apaga inmediatamente. En esta situación, debemos especular sobre lo que sucederá con los datos que estaban en el sistema. Si los datos (en este caso, mensajes) estaban en la memoria o en la parte volátil del hierro, por ejemplo, en el caché, entonces estos datos se perderán. Sin embargo, si los datos se enviaron a un almacenamiento no volátil, por ejemplo, al disco, volverán a estar disponibles cuando el sistema vuelva a funcionar.
Desde este punto de vista, tiene sentido que si no queremos perder mensajes en caso de falla de un corredor, necesitemos escribirlos en el almacenamiento permanente. El costo de esta solución en particular, desafortunadamente, es bastante alto.
Tenga en cuenta que la diferencia entre escribir un megabyte de datos en el disco es 100-1000 veces más lenta que escribir en la memoria. Por lo tanto, el desarrollador de la aplicación debe decidir si la confiabilidad del mensaje vale la pérdida de rendimiento. Decisiones como estas deben hacerse en función de un escenario de uso.
La compensación entre rendimiento y confiabilidad se basa en una gama de opciones. Cuanto mayor es la fiabilidad, menor es el rendimiento. Si decide hacer que el sistema sea menos confiable, por ejemplo, almacenando mensajes solo en la memoria, su productividad aumentará significativamente. De manera predeterminada, JMS está configurado para tener ActiveMQ listo para usar para confiabilidad. Existen muchos mecanismos que le permiten configurar el agente e interactuar con él en una posición en este espectro que sea más adecuada para escenarios específicos de uso del sistema de mensajería.
Este compromiso se aplica a nivel de corredores individuales. Sin embargo, al finalizar la configuración de un agente individual, es posible escalar el sistema de mensajería más allá de este punto examinando cuidadosamente los flujos de mensajes y compartiendo el tráfico entre varios agentes. Esto se puede lograr proporcionando a destinatarios específicos sus propios intermediarios o dividiendo el flujo general de mensajes a nivel de aplicación o utilizando un componente intermedio. Más adelante, consideraremos con más detalle cómo tener en cuenta las topologías de los corredores.
Guardar mensajes
ActiveMQ viene con una serie de estrategias de retención de mensajes conectables. Vienen en forma de adaptadores de persistencia (persistencia), que pueden considerarse motores de almacenamiento de mensajes. Estos incluyen soluciones basadas en disco como KahaDB y LevelDB, así como la capacidad de usar la base de datos a través de JDBC. Como los primeros se usan con mayor frecuencia, centraremos nuestra discusión en ellos.
Cuando un intermediario recibe mensajes persistentes, primero se escriben en el disco en un diario. Un diario es una estructura de datos en disco en la que solo puede agregar datos y que consta de varios archivos. El intermediario serializa los mensajes entrantes en una representación independiente del protocolo del objeto, y luego se ordena en forma binaria, que luego se escribe al final del registro. El registro contiene un registro de todos los mensajes entrantes, así como información sobre los mensajes que el cliente ha confirmado como leídos.
Los adaptadores de disco de persistencia admiten archivos de índice que rastrean dónde se encuentran los siguientes mensajes reenviados en el registro. Cuando se leen todos los mensajes del archivo de registro, el flujo de trabajo de fondo de ActiveMQ los eliminará o archivará. Si este registro se daña durante la falla del agente, ActiveMQ lo reconstruirá según la información en los archivos de registro.
Los mensajes de todas las colas se escriben en los mismos archivos de registro, lo que significa que si un mensaje no se lee, el archivo completo (generalmente el predeterminado es 32 MB o 100 MB, dependiendo del adaptador de persistencia) no se puede borrar. Esto puede causar problemas con poco espacio en disco con el tiempo.
Los corredores de mensajes clásicos no están diseñados para el almacenamiento a largo plazo: ¡lea sus mensajes!
Los registros son un mecanismo extremadamente eficiente para almacenar y recuperar mensajes, ya que el acceso al disco es secuencial para ambas operaciones. En los discos duros convencionales, esto minimiza el número de búsquedas de discos por cilindros, ya que las cabezas del disco simplemente continúan leyendo o escribiendo sectores en el sustrato giratorio del disco. Del mismo modo, en los SSD, el acceso secuencial es mucho más rápido que el acceso aleatorio, ya que el primero hace un mejor uso de las páginas de memoria del disco.
Factores de rendimiento del disco
Existen varios factores que determinan la velocidad a la que puede funcionar un disco. Para comprender esto, considere el método de escribir en un disco a través de un modelo mental simplificado de una tubería (
Figura 2-2 ).
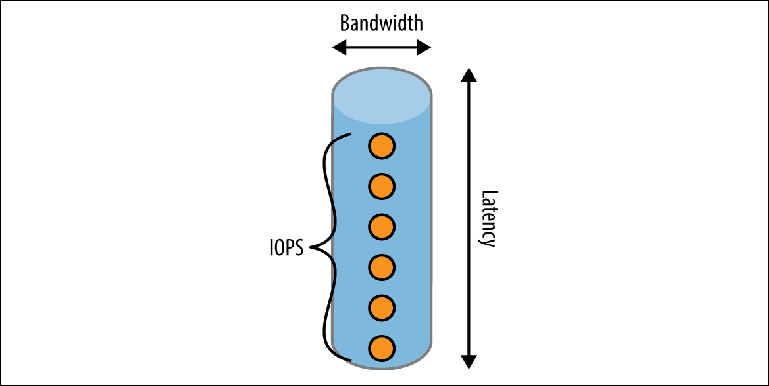 Figura 2-2. Modelo de tubo de rendimiento de disco
Figura 2-2. Modelo de tubo de rendimiento de discoUna tubería tiene tres dimensiones:
LongitudCorresponde a la
latencia esperada para completar una operación. Para la mayoría de las unidades locales, es bastante bueno, pero puede convertirse en un factor limitante importante en entornos de nube donde la unidad local está realmente en línea. Por ejemplo, al momento de escribir (abril de 2017), Amazon garantiza que la escritura en su almacenamiento EBS será "en menos de 2 ms". Si registramos secuencialmente, esto da un rendimiento máximo de 500 registros por segundo.
AnchoDetermina la
capacidad de carga o el ancho de banda de una sola operación. Los cachés del sistema de archivos utilizan esta propiedad combinando muchos registros pequeños en un conjunto más pequeño de operaciones de escritura más grandes realizadas en el disco.
Ancho de banda en el tiempoLa idea se presenta en forma de una serie de eventos que pueden estar en la tubería al mismo tiempo, expresados por una métrica llamada
IOPS (número de operaciones de E / S por segundo) . IOPS es comúnmente utilizado por los fabricantes de almacenamiento y los proveedores de la nube para medir el rendimiento. El disco duro tendrá diferentes valores de IOPS en diferentes contextos: si la carga de trabajo consiste principalmente en lectura, escritura o una combinación de ellos, y si estas operaciones son secuenciales, arbitrarias o mixtas. Las mediciones de IOPS que son más interesantes desde el punto de vista del corredor son operaciones de lectura y escritura secuenciales, ya que corresponden a la lectura y escritura de registros de un registro.
El rendimiento máximo de un intermediario de mensajes está determinado por el
logro de la primera de estas restricciones, y la configuración del intermediario depende en gran medida de la forma en que interactúa con los discos. Esto no es solo un factor de cómo, por ejemplo, se configura el corredor, sino que también depende de cómo los productores interactúan con el corredor. Al igual que con todo lo relacionado con el rendimiento, es necesario probar el intermediario en una carga de trabajo representativa (es decir, lo más cerca posible de mensajes reales) y en la configuración de almacenamiento real que se utilizará en PROM. Esto se hace para comprender cómo se comportará el sistema en realidad.
API JMS
Antes de entrar en detalles sobre cómo ActiveMQ se comunica con los clientes, primero debemos aprender la API de JMS. La API define un conjunto de interfaces de programación utilizadas por el código del cliente:
ConnectionFactoryEsta es la interfaz de nivel superior que se utiliza para establecer conexiones con el intermediario. En una aplicación de mensajería típica, solo hay una instancia de esta interfaz. En ActiveMQ, este es un ActiveMQConnectionFactory. En el nivel superior, este diseño indica la ubicación del agente de mensajes, junto con detalles de bajo nivel sobre cómo interactuar con él. Como su nombre lo indica, ConnectionFactory es el mecanismo por el cual se crean los objetos Connection.
ConexiónEste es un objeto de larga duración que se asemeja más o menos a una conexión TCP: después de la creación, generalmente existe durante todo el ciclo de vida de la aplicación hasta que se cierra. La conexión es segura para subprocesos y puede funcionar con múltiples subprocesos simultáneamente. Los objetos de conexión le permiten crear objetos de sesión.
SesiónEste es un identificador de flujo cuando interactúa con un corredor. Los objetos de sesión no son seguros para subprocesos, lo que significa que varios subprocesos no pueden acceder a ellos al mismo tiempo. La sesión es el descriptor transaccional principal con el que el programador puede confirmar y revertir los mensajes de reversión si está en modo transaccional. Con este objeto, puede crear objetos Message, MessageConsumer y MessageProducer, y también obtener punteros (descriptores) para objetos de Tema y Cola.
MessageProducerEsta interfaz le permite enviar un mensaje al destinatario.
MensajeconsumidorEsta interfaz permite al desarrollador recibir mensajes. Hay dos mecanismos de recuperación de mensajes:
- Registrar MessageListener. Esta es la interfaz del manejador de mensajes que ha implementado, que procesará secuencialmente cualquier mensaje emitido por el intermediario utilizando una secuencia.
- Sondeo de mensajes utilizando el método de recepción ().
MensajeEsta es probablemente la estructura más importante ya que transfiere sus datos. Los mensajes en JMS constan de dos aspectos:
- Metadatos del mensaje. El mensaje contiene encabezados y propiedades. Tanto eso como eso pueden considerarse elementos de un mapa. Los encabezados son elementos bien conocidos definidos por la especificación JMS y disponibles directamente a través de la API, como JMSDestination y JMSTimestamp. Las propiedades son piezas arbitrarias de información de mensajes que se configuran para simplificar el procesamiento o el enrutamiento de mensajes sin tener que leer la carga útil del mensaje. Puede, por ejemplo, establecer el encabezado en AccountID o OrderType.
- Cuerpo del mensaje. Desde la sesión, se pueden crear varios tipos diferentes de mensajes dependiendo del tipo de contenido que se enviará en el cuerpo, los más comunes son TextMessage para cadenas y BytesMessage para datos binarios.
Cómo funcionan las colas: una historia de dos cerebros
Un modelo de trabajo útil, aunque inexacto, de ActiveMQ es un modelo de dos mitades del cerebro. Una parte es responsable de recibir mensajes del productor y la otra envía estos mensajes a los consumidores. Las relaciones son en realidad más complejas para fines de optimización del rendimiento, pero el modelo es suficiente para una comprensión básica.
Enviar mensajes a la cola
Veamos la interacción que ocurre al enviar un mensaje.
La Figura 2-3 nos muestra un modelo simplificado del proceso mediante el cual el intermediario recibe los mensajes. No corresponde totalmente al comportamiento en cada caso, pero es bastante adecuado para obtener una comprensión básica.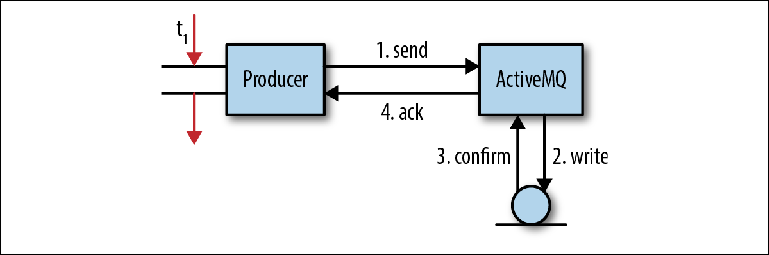 Figura 2-3. Envío de mensajes a JMSEn una aplicación cliente, un hilo recibe un puntero a un MessageProducer. Crea un mensaje con una carga útil estimada del mensaje y llama a MessageProducer.send ("pedidos", mensaje), con la cola como destino final del mensaje. Dado que el programador no quiere perder el mensaje si el intermediario se rompió, el encabezado del mensaje JMSDeliveryMode se configuró en PERSISTENT (comportamiento predeterminado).En este punto (1), la transmisión de envío llama a la biblioteca del cliente y ordena el mensaje en el formato OpenWire. Entonces el mensaje se envía al corredor.En el intermediario, la secuencia receptora elimina el mensaje de la línea y lo desmarca al objeto interno. Luego, el objeto del mensaje se transmite al adaptador de persistencia, que ordena el mensaje utilizando el formato de Google Protocol Buffers y lo escribe en el almacenamiento (2).Después de grabar el mensaje en el almacenamiento, el adaptador de persistencia debería recibir la confirmación de que el mensaje fue realmente grabado (3). Esta suele ser la parte más lenta de toda la interacción; Más sobre esto más adelante.Tan pronto como el agente se asegure de que el mensaje se haya guardado, enviará una respuesta de confirmación (4) al cliente. Después de eso, el hilo del cliente que originalmente llamó a la operación send () puede continuar su trabajo.Esta confirmación pendiente de mensajes persistentes es la base de la garantía proporcionada por la API de JMS: si desea que se guarde el mensaje, probablemente también sea importante para usted si el intermediario recibió el mensaje en primer lugar. Existen varias razones por las cuales esto puede no ser posible, por ejemplo, se ha alcanzado un límite de memoria o disco. En lugar de fallar, el intermediario suspende la operación de envío, obligando al productor a esperar hasta que aparezcan suficientes recursos del sistema para procesar el mensaje (un proceso llamado Control de flujo del productor), o enviará una confirmación negativa al productor, lanzando una excepción. El comportamiento exacto es personalizable para cada corredor.En esta operación simple, tiene lugar un número significativo de interacciones de E / S: dos operaciones de red entre el productor y el intermediario, una operación de guardar y un paso de confirmación. La operación de guardar puede ser una simple escritura en el disco u otra transición de red al servidor de almacenamiento.Esto plantea una pregunta importante sobre los corredores de mensajes: su trabajo está asociado con un flujo extremadamente intenso de operaciones de E / S y son muy sensibles a la infraestructura utilizada, especialmente a los discos.Echemos un vistazo más de cerca al paso de confirmación (3) en la interacción anterior. Si el adaptador de persistencia está basado en archivos, almacenar el mensaje implica escribir en el sistema de archivos. Si es así, ¿por qué debo confirmar que la operación de escritura se ha completado? ¿El hecho de completar una grabación realmente significa que ha ocurrido una grabación?
Figura 2-3. Envío de mensajes a JMSEn una aplicación cliente, un hilo recibe un puntero a un MessageProducer. Crea un mensaje con una carga útil estimada del mensaje y llama a MessageProducer.send ("pedidos", mensaje), con la cola como destino final del mensaje. Dado que el programador no quiere perder el mensaje si el intermediario se rompió, el encabezado del mensaje JMSDeliveryMode se configuró en PERSISTENT (comportamiento predeterminado).En este punto (1), la transmisión de envío llama a la biblioteca del cliente y ordena el mensaje en el formato OpenWire. Entonces el mensaje se envía al corredor.En el intermediario, la secuencia receptora elimina el mensaje de la línea y lo desmarca al objeto interno. Luego, el objeto del mensaje se transmite al adaptador de persistencia, que ordena el mensaje utilizando el formato de Google Protocol Buffers y lo escribe en el almacenamiento (2).Después de grabar el mensaje en el almacenamiento, el adaptador de persistencia debería recibir la confirmación de que el mensaje fue realmente grabado (3). Esta suele ser la parte más lenta de toda la interacción; Más sobre esto más adelante.Tan pronto como el agente se asegure de que el mensaje se haya guardado, enviará una respuesta de confirmación (4) al cliente. Después de eso, el hilo del cliente que originalmente llamó a la operación send () puede continuar su trabajo.Esta confirmación pendiente de mensajes persistentes es la base de la garantía proporcionada por la API de JMS: si desea que se guarde el mensaje, probablemente también sea importante para usted si el intermediario recibió el mensaje en primer lugar. Existen varias razones por las cuales esto puede no ser posible, por ejemplo, se ha alcanzado un límite de memoria o disco. En lugar de fallar, el intermediario suspende la operación de envío, obligando al productor a esperar hasta que aparezcan suficientes recursos del sistema para procesar el mensaje (un proceso llamado Control de flujo del productor), o enviará una confirmación negativa al productor, lanzando una excepción. El comportamiento exacto es personalizable para cada corredor.En esta operación simple, tiene lugar un número significativo de interacciones de E / S: dos operaciones de red entre el productor y el intermediario, una operación de guardar y un paso de confirmación. La operación de guardar puede ser una simple escritura en el disco u otra transición de red al servidor de almacenamiento.Esto plantea una pregunta importante sobre los corredores de mensajes: su trabajo está asociado con un flujo extremadamente intenso de operaciones de E / S y son muy sensibles a la infraestructura utilizada, especialmente a los discos.Echemos un vistazo más de cerca al paso de confirmación (3) en la interacción anterior. Si el adaptador de persistencia está basado en archivos, almacenar el mensaje implica escribir en el sistema de archivos. Si es así, ¿por qué debo confirmar que la operación de escritura se ha completado? ¿El hecho de completar una grabación realmente significa que ha ocurrido una grabación?En realidad no
Como suele suceder, cuanto más profundo estudias algo, más complejo resulta ser. En este caso particular, el almacenamiento en caché es el culpable .Cachés, cachés en todas partes
Cuando un proceso del sistema operativo, como un intermediario, escribe datos en el disco, interactúa con el sistema de archivos. Un sistema de archivos es un proceso que abstrae los detalles de la interacción con el medio de almacenamiento utilizado, proporcionando una API para operaciones de archivos como ABRIR, CERRAR, LEER y ESCRIBIR. Una de estas funciones es minimizar el número de operaciones de escritura almacenando los datos escritos por el sistema operativo en bloques que se pueden guardar en el disco de una manera. Las operaciones de escritura del sistema de archivos que parecen interactuar con discos se escriben realmente en esta memoria caché de búfer .Por cierto, es por eso que su computadora se queja cuando expulsa inseguramente una unidad USB: ¡los archivos que copió pueden no haberse escrito realmente!Tan pronto como los datos van más allá de la memoria caché del búfer, pasan al siguiente nivel de almacenamiento en caché, esta vez a nivel de hardware: la memoria caché del controlador de disco . Son especialmente importantes para los sistemas basados en RAID y realizan la misma función que el almacenamiento en caché a nivel del sistema operativo: minimizar el número de interacciones necesarias para las unidades en sí. Estas memorias caché se dividen en dos categorías: lasescrituras escritasse transfieren al disco inmediatamente después de la recepción.ReescrituraLa grabación se realiza en discos solo cuando el búfer está lleno y alcanza un cierto valor umbral.Los datos almacenados en estas memorias caché se pueden perder fácilmente durante un corte de energía, porque la memoria que usan generalmente es volátil (volátil) . Las tarjetas más caras tienen paquetes de baterías redundantes (BBU) que admiten energía de caché hasta que todo el sistema pueda restaurar la energía, después de lo cual los datos se escribirán en el disco.El último nivel de caché está en los discos mismos. Cachés de discoubicado en discos duros (tanto en discos duros estándar como en unidades de estado sólido) y puede ser de escritura o reescritura. La mayoría de las unidades comerciales utilizan cachés de reescritura y son volátiles, lo que nuevamente significa que los datos pueden perderse en caso de una falla de energía.Al volver al intermediario de mensajes, debe completar el paso de confirmación para asegurarse de que los datos realmente hayan llegado al disco. Desafortunadamente, la interacción con estos búferes de hardware depende del sistema de archivos, por lo que todo lo que puede hacer un proceso como ActiveMQ es enviar una señal al sistema de archivos de que desea sincronizar todos los búferes del sistema con el dispositivo en uso. Para hacer esto, el intermediario llama al método java.io.FileDescriptor.sync (), que, a su vez, inicia la operación POSIX fsync ().Este comportamiento de sincronización es un requisito del JMS para garantizar que todos los mensajes marcados como persistentes se guarden realmente en el disco y, por lo tanto, se ejecuten después de recibir cada mensaje o conjunto de mensajes relacionados en una transacción. Por lo tanto, la velocidad a la que un disco puede ejecutar sync () es crítica para el rendimiento del agente.Conflictos internos
El uso de un registro para todas las colas agrega complejidad adicional. En cualquier momento, puede haber varios productores enviando mensajes simultáneamente. El intermediario tiene varias transmisiones que reciben estos mensajes de los sockets entrantes. Cada hilo debe guardar su mensaje en el registro. Dado que varios hilos no pueden escribir en el mismo archivo al mismo tiempo, porque los registros entrarán en conflicto entre sí, luego los registros deben colocarse en cola utilizando el mecanismo de exclusión mutua. Llamamos a este hilo conflicto .Cada mensaje debe estar completamente grabado y sincronizado antes de procesar el siguiente mensaje. Esta restricción afecta a todas las colas en el intermediario al mismo tiempo. Por lo tanto, la velocidad de la rapidez con que se puede recibir un mensaje es el tiempo que lleva escribir en el disco, más cualquier tiempo de espera para que otras transmisiones terminen de grabar.ActiveMQ incluye un búfer de escritura, en el que las secuencias receptoras escriben sus mensajes, esperando la finalización de la grabación anterior. Luego, el búfer se escribe en una acción cuando el mensaje está disponible. Al finalizar, los hilos son notificados. Por lo tanto, el corredor maximiza el uso del ancho de banda de almacenamiento.Para minimizar el impacto del conflicto de subprocesos, a los conjuntos de colas se les pueden asignar sus propios registros utilizando el adaptador mKahaDB. Este enfoque reduce la latencia de escritura, ya que en cualquier momento los hilos probablemente escribirán en diferentes registros y no tendrán que competir entre sí para obtener acceso exclusivo a un archivo de registro.Transacciones
La ventaja de usar una sola revista para todas las colas es que, desde el punto de vista de los autores del corredor, es mucho más fácil implementar transacciones.Veamos un ejemplo en el que un productor envía varios mensajes a varias colas. El uso de una transacción significa que todo el conjunto de mensajes a enviar debe considerarse como una operación atómica. En esta interacción, la biblioteca del cliente ActiveMQ puede realizar algunas optimizaciones que aumentarán significativamente la velocidad de envío.En la operación que se muestra en la Figura 2-4, el productor envía tres mensajes, todos en diferentes colas. En lugar de la interacción habitual con el intermediario, cuando se confirma cada mensaje, el cliente envía los tres mensajes de forma asincrónica, es decir, sin esperar una respuesta. Estos mensajes se almacenan en la memoria del corredor. Tan pronto como se completa la operación, el productor informa a sus sesiones sobre la necesidad de comprometerse, lo que a su vez obliga al corredor a realizar un registro grande con una operación de sincronización.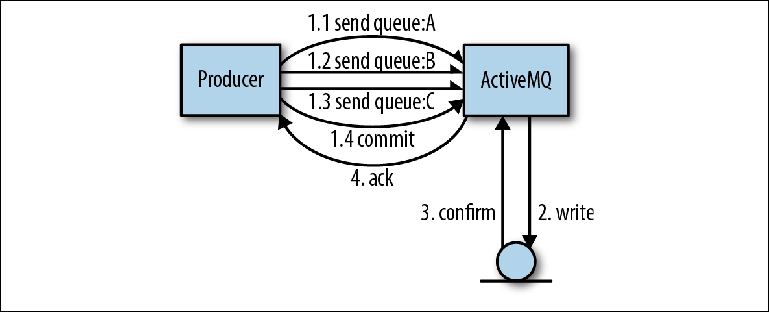 Figura 2-4. Envío de mensajes en transaccionesEn este tipo de operación, ActiveMQ utiliza dos optimizaciones para aumentar la velocidad:
Figura 2-4. Envío de mensajes en transaccionesEn este tipo de operación, ActiveMQ utiliza dos optimizaciones para aumentar la velocidad:- Eliminar el tiempo de espera antes de que sea posible el próximo envío del productor
- Combinando muchas operaciones de disco pequeño en una grande, esto le permite usar todo el ancho de banda del bus de disco
Si comparamos esto con la situación en la que cada cola se almacena en su propio registro, entonces el intermediario tendría que proporcionar algo como la coordinación de transacciones entre todos los registros.Restando mensajes de la cola
El proceso de lectura de mensajes comienza cuando el consumidor expresa su disposición a aceptarlos configurando un MessageListener para procesar los mensajes a medida que llegan o llamando al método MessageConsumer.receive () ( Figura 2-5 ).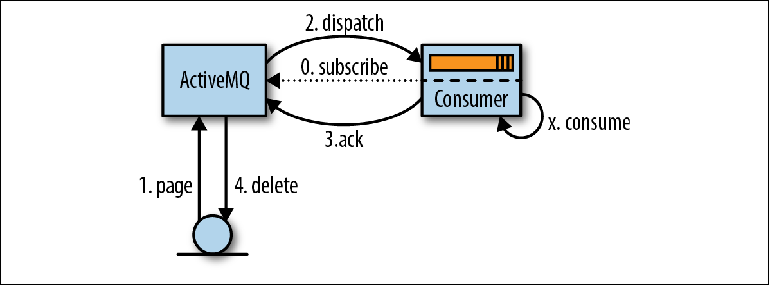 Figura 2-5. Lectura de mensajes a través de JMSCuando ActiveMQ se da cuenta de un consumidor, (ActiveMQ) lee (páginas) mensajes página por página desde el almacenamiento a la memoria de distribución (1). Luego, estos mensajes son redirigidos (enviados) al contador (2), a menudo en varias partes para reducir la cantidad de interacción de la red. El corredor realiza un seguimiento de qué mensajes se han redirigido y a qué consumidor.Los mensajes recibidos por el consumidor no son procesados inmediatamente por la aplicación, sino que se colocan en un área de memoria conocida comotampón de captación previa (tampón de captación previa) . El propósito de este búfer es agilizar el flujo de mensajes para que el agente pueda emitir mensajes al supervisor cuando estén disponibles para enviar, mientras que el consumidor puede recibirlos de manera ordenada, uno a la vez.En algún momento después de ingresar al búfer de captación previa, la lógica de la aplicación (X) lee los mensajes y la confirmación de la revisión se envía al intermediario (3). El tiempo transcurrido entre el procesamiento del mensaje y la confirmación se configura utilizando un parámetro de sesión JMS denominado modo de reconocimiento , que discutiremos más adelante.Tan pronto como el intermediario acepta la confirmación de entrega del mensaje, se elimina de la memoria y del almacén de mensajes (4). El término "eliminación" es algo engañoso, ya que en realidad se escribe un registro de confirmación en la revista y el índice en el índice aumenta. La eliminación real del archivo de registro que contiene el mensaje será realizada por el recolector de basura en el hilo de fondo basado en esta información.El comportamiento descrito anteriormente es una simplificación para facilitar la comprensión. De hecho, ActiveMQ no solo lee datos página por página del disco, sino que utiliza el mecanismo del cursor entre las partes receptoras y redireccionadoras del intermediario para minimizar la interacción con el repositorio del intermediario siempre que sea posible. La paginación, como se describió anteriormente, es uno de los modos utilizados en este mecanismo. Los cursores se pueden ver como un caché de nivel de aplicación que debe mantenerse sincronizado con el repositorio del intermediario. El protocolo de coherencia utilizado es una parte importante de lo que hace que el mecanismo de envío de ActiveMQ sea mucho más complejo que el mecanismo de Kafka que se describe en el próximo capítulo.
Figura 2-5. Lectura de mensajes a través de JMSCuando ActiveMQ se da cuenta de un consumidor, (ActiveMQ) lee (páginas) mensajes página por página desde el almacenamiento a la memoria de distribución (1). Luego, estos mensajes son redirigidos (enviados) al contador (2), a menudo en varias partes para reducir la cantidad de interacción de la red. El corredor realiza un seguimiento de qué mensajes se han redirigido y a qué consumidor.Los mensajes recibidos por el consumidor no son procesados inmediatamente por la aplicación, sino que se colocan en un área de memoria conocida comotampón de captación previa (tampón de captación previa) . El propósito de este búfer es agilizar el flujo de mensajes para que el agente pueda emitir mensajes al supervisor cuando estén disponibles para enviar, mientras que el consumidor puede recibirlos de manera ordenada, uno a la vez.En algún momento después de ingresar al búfer de captación previa, la lógica de la aplicación (X) lee los mensajes y la confirmación de la revisión se envía al intermediario (3). El tiempo transcurrido entre el procesamiento del mensaje y la confirmación se configura utilizando un parámetro de sesión JMS denominado modo de reconocimiento , que discutiremos más adelante.Tan pronto como el intermediario acepta la confirmación de entrega del mensaje, se elimina de la memoria y del almacén de mensajes (4). El término "eliminación" es algo engañoso, ya que en realidad se escribe un registro de confirmación en la revista y el índice en el índice aumenta. La eliminación real del archivo de registro que contiene el mensaje será realizada por el recolector de basura en el hilo de fondo basado en esta información.El comportamiento descrito anteriormente es una simplificación para facilitar la comprensión. De hecho, ActiveMQ no solo lee datos página por página del disco, sino que utiliza el mecanismo del cursor entre las partes receptoras y redireccionadoras del intermediario para minimizar la interacción con el repositorio del intermediario siempre que sea posible. La paginación, como se describió anteriormente, es uno de los modos utilizados en este mecanismo. Los cursores se pueden ver como un caché de nivel de aplicación que debe mantenerse sincronizado con el repositorio del intermediario. El protocolo de coherencia utilizado es una parte importante de lo que hace que el mecanismo de envío de ActiveMQ sea mucho más complejo que el mecanismo de Kafka que se describe en el próximo capítulo.Modos de confirmación y transacción
Varios modos de confirmación, que determinan el orden entre la corrección de pruebas y la confirmación, tienen un impacto significativo en la lógica que debe implementarse en el cliente. Son los siguientes:AUTO_ACKNOWLEDGEEste es el modo más utilizado, posiblemente porque tiene la palabra AUTO. Este modo obliga a la biblioteca del cliente a reconocer el mensaje al mismo tiempo que el mensaje es leído por la llamada a reciben (). Esto significa que si la lógica empresarial iniciada por el mensaje arroja una excepción, entonces el mensaje se pierde porque ya se ha eliminado en el intermediario. Si el mensaje se lee a través del oyente, el mensaje se confirmará solo después de que el oyente haya completado con éxito el trabajo.CLIENT_ACKNOWLEDGESe enviará una confirmación solo cuando el código del consumidor llame explícitamente al método Message.acknowledge ().DUPS_OK_ACKNOWLEDGEAquí las confirmaciones serán almacenadas en el consumidor antes de enviarlas simultáneamente para reducir la cantidad de tráfico de red. Sin embargo, si el sistema del cliente se apaga, se perderán las confirmaciones y los mensajes se reenviarán y procesarán por segunda vez. Por lo tanto, el código debe considerar la probabilidad de mensajes duplicados.Los modos de confirmación se complementan con herramientas de lectura transaccional. Al crear una sesión, se puede marcar como transaccional. Esto significa que el programador debe llamar explícitamente a Session.commit () o Session.rollback (). En el lado del consumidor, las transacciones amplían el rango de interacciones que el código puede realizar como una operación atómica. Por ejemplo, puede leer y procesar múltiples mensajes como un todo, o restar un mensaje de una cola y luego enviarlo a otro usando el mismo objeto Session.Despacho y varios consumidores
Hasta ahora, hemos estado discutiendo el comportamiento de leer mensajes con un solo consumidor. Veamos ahora cómo este modelo es aplicable a varios consumidores.Cuando varios consumidores se suscriben a la cola, el comportamiento predeterminado del corredor es enviar mensajes de ida y vuelta a aquellos consumidores que tienen un lugar en los búferes de captación previa. Los mensajes se enviarán en el orden en que llegaron a la cola: esta es la única garantía FIFO proporcionada (primero en entrar, primero en salir; primero en entrar, primero en salir).Cuando el consumidor se apaga repentinamente, todos los mensajes que se le envíen, pero aún no confirmados, se reenviarán a otro cliente disponible.Esto plantea una pregunta importante: incluso cuando se utilizan transacciones de consumidores, no hay garantía de que el mensaje no se procesará varias veces.Considere la siguiente lógica de procesamiento dentro del consumidor:- El mensaje se resta de la cola. La transacción comienza.
- Se llama a un servicio web con el contenido del mensaje.
- La transacción está comprometida. Se envía una confirmación al corredor.
Si el cliente completa entre los pasos 2 y 3, entonces la revisión del mensaje ya ha afectado a algún otro sistema al llamar al servicio web. Las llamadas al servicio web son solicitudes HTTP y, como tales, no son transaccionales.
Este comportamiento es cierto para todos los sistemas de colas, incluso si son transaccionales, no pueden garantizar que no habrá efectos secundarios al procesar mensajes en ellos. Habiendo examinado el procesamiento de mensajes en detalle, podemos decir con confianza que:
No existe la entrega de mensajes solo una vez .Las colas proporcionan una garantía de entrega
al menos una vez, y las partes sensibles del código siempre deben considerar la posibilidad de recibir mensajes repetidos. Más adelante discutiremos cómo un cliente de mensajería puede usar la lectura idempotente para rastrear mensajes que ya han sido vistos y evitar duplicados.
Ordenar mensajes
Para un conjunto de mensajes que llegan en el orden de [A, B, C, D], y para dos consumidores C1 y C2, la distribución normal de los mensajes será la siguiente:
C1: [A, C]
C2: [B, D]Dado que el intermediario no controla el funcionamiento de los procesos de lectura y el orden de procesamiento es paralelo, no es determinista. Si C1 es más lento que C2, el conjunto inicial de mensajes puede procesarse como [B, D, A, C].
Este comportamiento puede sorprender a los principiantes que esperan que los mensajes se procesen en orden y, sobre esta base, están desarrollando su propia aplicación de mensajería. El requisito de que los mensajes enviados por el mismo remitente se procesen en orden uno con respecto al otro, también conocido como
ordenamiento causal , es bastante común.
Tomemos como ejemplo el siguiente caso de uso tomado de las apuestas en línea:
- La cuenta de usuario está configurada.
- El dinero se acredita en la cuenta.
- Se realiza una apuesta que retira dinero de la cuenta.
Aquí tiene sentido que los mensajes se procesen en el orden en que fueron enviados, de modo que se tenga en cuenta el estado general de la cuenta. Pueden suceder cosas extrañas si el sistema intenta eliminar dinero de una cuenta que no tiene fondos. Hay, por supuesto, formas de evitar esto.
El modelo de
cliente exclusivo incluye enviar todos los mensajes de la cola a un cliente. Con este enfoque, cuando se conectan varias instancias de aplicaciones o subprocesos a la cola, se firman utilizando un parámetro de destinatario especial:
my.queue?consumer.exclusive=true . Cuando conecta a un consumidor monopolista, él recibe todos los mensajes. Cuando el segundo consumidor está conectado, no recibirá ningún mensaje hasta que el primero se desconecte. Este segundo consumidor es en realidad una reserva activa, mientras que el primer consumidor ahora recibirá mensajes exactamente en el orden en que fueron registrados en el diario, en un orden causal.
La desventaja de este enfoque es que, aunque el procesamiento de mensajes es consistente, es un cuello de botella de rendimiento porque todos los mensajes deben ser procesados por un solo compilador.
Para comprender este caso de uso de manera más inteligente, debe reconsiderar el problema. ¿Todos los mensajes deben procesarse en orden? En el caso de las ofertas de procesamiento descritas anteriormente, es necesario procesar solo los mensajes relacionados con una cuenta secuencialmente. ActiveMQ proporciona un mecanismo para hacer frente a esta situación llamada
grupos de mensajes JMS .
Los grupos de mensajes son un tipo de mecanismo de partición que permite a los productores distribuir mensajes en grupos que se procesarán secuencialmente de acuerdo con una clave comercial. Esta clave comercial se establece en una propiedad de mensaje llamada
JMSXGroupID .
La clave natural en el caso de procesamiento de ofertas será el identificador de la cuenta.
Para ilustrar cómo funciona el envío, considere un conjunto de mensajes que llegan en el siguiente orden:
[(A, Group1), (B, Group1), (C, Group2), (D, Group3), (E, Group2)]
Cuando el mecanismo de despacho procesa un mensaje en ActiveMQ y ve un
JMSXGroupID que no existía antes, esta clave se asigna al consumidor de forma cíclica. De ahora en adelante, todos los mensajes con esta clave se enviarán a este contador.
Aquí los grupos se asignarán entre dos consumidores: C1 y C2, de la siguiente manera:
C1: [Group1, Group3] C2: [Group2]
Los mensajes serán redirigidos y procesados de la siguiente manera:
C2: [B, D] C2: [(C, Group2), (E, Group2)]
Si el consumidor se descompone, todos los grupos asignados a él serán redistribuidos entre el resto de los consumidores y cualquier mensaje no confirmado será redirigido nuevamente. Por lo tanto, aunque podemos garantizar que todos los mensajes relacionados se procesarán en orden, no podemos afirmar que serán procesados por el mismo consumidor.
Alta disponibilidad
ActiveMQ proporciona alta disponibilidad con un maestro-esclavo basado en almacenamiento compartido. En este esquema, dos o más corredores (aunque generalmente dos) se configuran en servidores separados, y sus mensajes se almacenan en un almacén de mensajes ubicado en una ubicación externa. Un almacén de mensajes no puede ser usado simultáneamente por varias instancias de un intermediario, por lo tanto, su función secundaria (almacén) es actuar como un mecanismo de bloqueo para determinar qué intermediario obtendrá acceso exclusivo (
Figura 2-6 ).
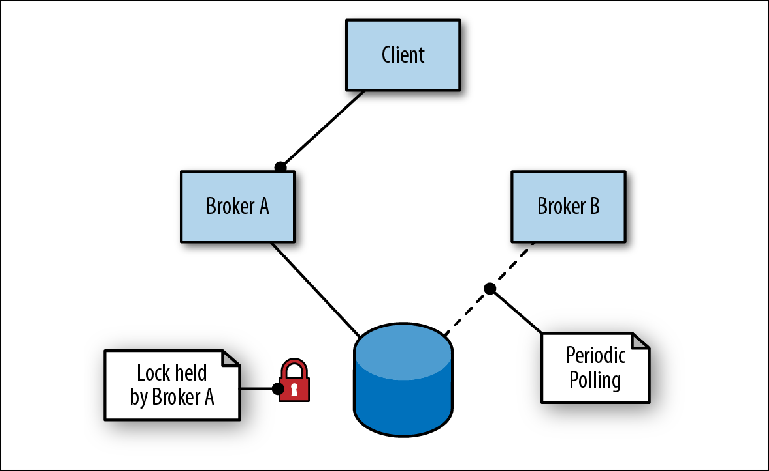 Figura 2-6. El corredor A es el líder; el corredor B está en espera como esclavo
Figura 2-6. El corredor A es el líder; el corredor B está en espera como esclavoPara conectarse al repositorio, el primer intermediario (Broker A) asume el rol de líder y abre sus puertos para el tráfico de mensajes. Cuando el segundo corredor (Broker B) se conecta al repositorio, intenta obtener un bloqueo y, dado que no tiene éxito, se detiene por un breve período antes de intentar volver a bloquearlo. Esto se llama contención impulsada.
Al mismo tiempo, el cliente alterna las direcciones de los dos intermediarios en un intento de conectarse al puerto de entrada, conocido como el conector de transporte. Tan pronto como el corredor principal esté disponible, el cliente se conecta a su puerto y puede enviar y leer mensajes.
Cuando el Agente A, que actúa como líder, falla debido a una falla del proceso (
Figura 2-7 ), ocurren los siguientes eventos:
- El cliente se desconecta e inmediatamente intenta reconectarse, alternando las direcciones de dos corredores.
- Se libera el bloqueo en el mensaje. El momento de esto depende de la implementación del almacenamiento.
- El corredor B, que estaba en modo esclavo, periódicamente tratando de obtener un bloqueo, finalmente tiene éxito y asume el papel de maestro, abriendo sus puertos.
- El cliente se conecta al Broker B y continúa su trabajo.
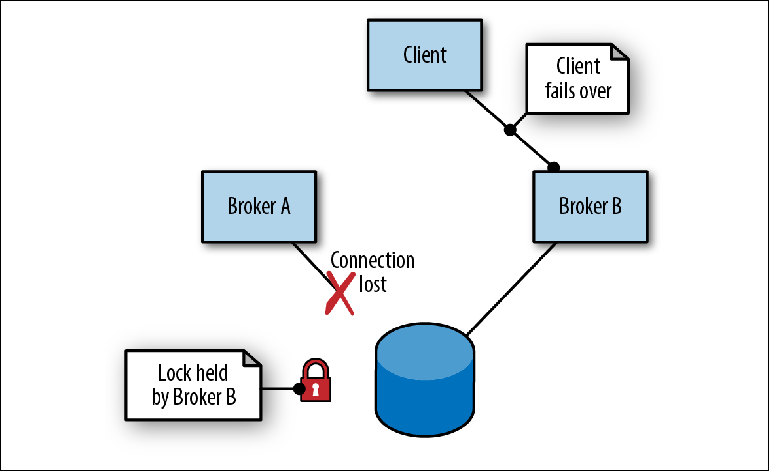 Figura 2-7. El intermediario A termina perdiendo la conexión al repositorio. El corredor B toma la delantera
Figura 2-7. El intermediario A termina perdiendo la conexión al repositorio. El corredor B toma la delanteraNo se garantiza que la lógica de alternancia entre varias direcciones de intermediario se incorpore a la biblioteca del cliente, como es el caso en las implementaciones de JMS / NMS / CMS. Si la biblioteca solo proporciona la reconexión a una sola dirección, es posible que deba colocar un par de intermediarios detrás de un equilibrador de carga, que también debería estar altamente disponible.
La principal desventaja de este enfoque es que para simplificar el trabajo de un intermediario lógico, se requieren varios servidores físicos. En este caso, uno de los dos servidores del corredor está inactivo, esperando la desconexión de su socio antes de que pueda comenzar a funcionar.
Este enfoque también tiene la complejidad adicional que el almacenamiento de intermediario utilizado, ya sea un sistema de archivos de red compartido o una base de datos, también debe ser altamente accesible. Esto conlleva costos adicionales para el equipo y la administración de la configuración del agente. En este escenario, es tentador reutilizar los repositorios de alta disponibilidad existentes utilizados por otras partes de la infraestructura, como una base de datos, pero esto es un error.
Es importante recordar que el disco es el principal limitador del rendimiento general del corredor. Si el disco mismo es utilizado simultáneamente por un proceso que no sea el intermediario de mensajes, entonces la interacción de este proceso con el disco probablemente ralentiza la grabación del intermediario y, por lo tanto, la velocidad a la que los mensajes pueden pasar por el sistema. Tales ralentizaciones son difíciles de diagnosticar y la única forma de evitarlas es separar los dos procesos en diferentes volúmenes de almacenamiento.
Para garantizar el funcionamiento estable del agente, se requiere un almacenamiento dedicado y exclusivo.
Escala vertical y horizontal
En algún momento de la vida del proyecto, puede encontrar una limitación de rendimiento en el intermediario de mensajes. Estas limitaciones generalmente se relacionan con los recursos, en particular las interacciones de ActiveMQ con el almacenamiento utilizado. Estos problemas generalmente surgen debido a conflictos de volumen de mensajes o ancho de banda entre los destinatarios, por ejemplo, cuando una cola desborda al intermediario durante los períodos pico.
Hay varias formas de obtener más rendimiento de la infraestructura del corredor:
- No use persistencia si no es necesario. Algunos escenarios de uso permiten la pérdida de mensajes durante bloqueos, especialmente cuando un sistema envía otro estado de instantánea completo al otro a través de la cola, ya sea periódicamente o bajo demanda.
- Ejecute el corredor en unidades más rápidas. En condiciones reales, se observaron diferencias significativas en el ancho de banda de grabación entre HDD estándar y alternativas basadas en memoria.
- Aproveche al máximo los tamaños de disco. Como se muestra en el modelo de interacción de canalización de disco descrito anteriormente, se puede lograr un mayor rendimiento mediante el uso de transacciones para enviar grupos de mensajes, combinando así varias operaciones de escritura en una más grande.
- Usar particiones de tráfico. Puede lograr un mayor rendimiento dividiendo los destinos de una de las siguientes maneras:
- Varios discos dentro de un intermediario, por ejemplo, utilizando el adaptador de persistencia mKahaDB para varios directorios, cada uno de los cuales está montado en un disco separado.
- Varios corredores, y la partición del tráfico se lleva a cabo manualmente por la aplicación cliente. ActiveMQ no proporciona ninguna función nativa para este propósito.
Una de las causas más comunes de los problemas de rendimiento del corredor es simplemente un intento de hacer demasiado con una instancia. Como regla, esto ocurre en situaciones en las que el intermediario se divide ingenuamente entre varias aplicaciones sin tener en cuenta la carga existente en el intermediario o sin comprender los volúmenes. Con el tiempo, un corredor se carga cada vez más hasta que deja de comportarse adecuadamente.
El problema a menudo surge durante la fase de diseño del sistema, cuando el arquitecto del sistema puede proponer un esquema como el de la
Figura 2-8 .
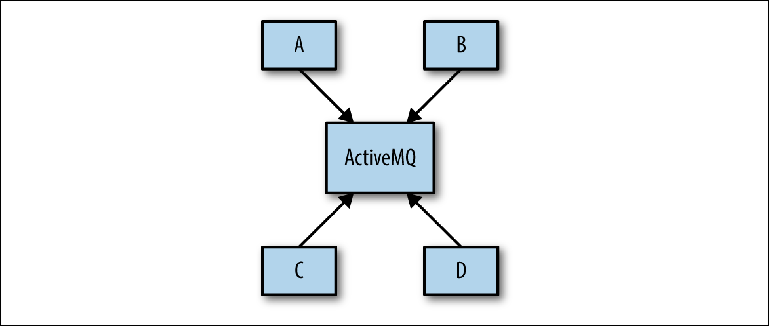 Figura 2-8. Vista conceptual de la infraestructura de mensajería
Figura 2-8. Vista conceptual de la infraestructura de mensajeríaEl objetivo es que varias aplicaciones se comuniquen entre sí de forma asincrónica a través de ActiveMQ. El objetivo ya no se especifica y luego el esquema determina la base de la configuración real del agente. Este enfoque se llama Universal Data Pipeline.
No tiene en cuenta el paso fundamental de análisis entre el diseño conceptual mencionado anteriormente y la implementación física. Antes de continuar con la construcción de una configuración específica, es necesario realizar un análisis, que luego se utilizará para justificar el proyecto físico. El primer paso en este proceso es determinar qué sistemas interactúan entre sí: un diagrama bastante simple con rectángulos y flechas (
Figura 2-9 ).
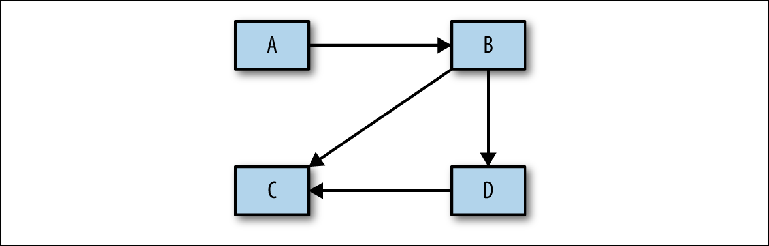 Figura 2-9. El mensaje de boceto fluye entre sistemas
Figura 2-9. El mensaje de boceto fluye entre sistemasDespués de su aprobación, puede ir a los detalles para responder las siguientes preguntas:
- ¿Cuántas colas y temas se usarán?
- ¿Qué volúmenes de mensajes se esperan para cada uno de ellos?
- ¿Qué tan grandes son los mensajes en cada destinatario? Los mensajes grandes pueden causar problemas en el proceso de paginación, lo que lleva a exceder los límites de memoria y bloquear el intermediario.
- ¿El flujo de mensajes será uniforme durante todo el día o habrá picos debido a los trabajos por lotes? Grandes lotes en una cola menos utilizada pueden interferir con las escrituras oportunas del disco para destinos de alto rendimiento.
- ¿Están los sistemas en el mismo centro de datos o en diferentes? La comunicación remota involucra algún tipo de intermediarios de red.
La idea es definir escenarios de mensajería separados que puedan ser combinados o divididos por corredores individuales (
Figura 2-10 ).
Después de dicho desglose, los escenarios de uso se pueden simular combinándose entre sí mediante el Módulo de rendimiento ActiveMQ para identificar cualquier problema.
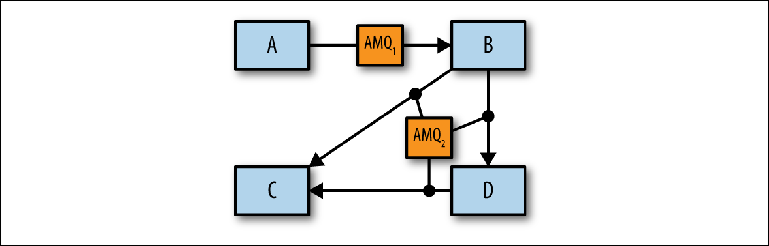 Figura 2-10. Identificación de corredores individuales.
Figura 2-10. Identificación de corredores individuales.Después de determinar el número apropiado de intermediarios lógicos, puede determinar cómo implementarlos a nivel físico utilizando configuraciones y redes de intermediarios altamente accesibles.
Resumen
En este capítulo, examinamos el mecanismo por el cual ActiveMQ recibe y distribuye mensajes. Discutimos las características que son compatibles con esta arquitectura, incluido el equilibrio de carga fijo de mensajes y transacciones relacionados. Al mismo tiempo, presentamos un conjunto de conceptos comunes a todos los sistemas de mensajería, incluidos protocolos de comunicación y revistas. También examinamos en detalle las dificultades involucradas en la escritura en disco y cómo los corredores pueden usar técnicas como la escritura de paquetes para mejorar el rendimiento. Finalmente, examinamos cómo ActiveMQ puede estar altamente disponible y cómo escalarlo más allá de las capacidades de un agente individual.
En el próximo capítulo, veremos Apache Kafka y cómo su arquitectura redefine la relación entre clientes y corredores para proporcionar una canalización de mensajes increíblemente robusta con un ancho de banda que es muchas veces mayor que un corredor de mensajes normal. Analizaremos la funcionalidad que utiliza para lograr este objetivo y consideraremos brevemente la arquitectura de las aplicaciones que proporcionan esta funcionalidad.
Siguiente parte:
Comprender los corredores de mensajes. Aprendiendo la mecánica de la mensajería a través de ActiveMQ y Kafka. Capítulo 3. KafkaTraducción completada: tele.gg/middle_java