 Equipo de laboratorio de simulación híbrida. La foto muestra el panel de control SDS 9300, que, junto con varias computadoras analógicas, realizó simulaciones del módulo de comando y el módulo lunar.
Equipo de laboratorio de simulación híbrida. La foto muestra el panel de control SDS 9300, que, junto con varias computadoras analógicas, realizó simulaciones del módulo de comando y el módulo lunar.Años antes del Apolo 11, cuando se estaba desarrollando el sistema de control, pensaban que el software integrado era algo que podía hacerse en último lugar: "Hal lo hará", dijeron. De hecho, decenas de personas y cientos de personal de apoyo estaban haciendo esto, pero Hal Laning primero tuvo que descubrir cómo organizar las numerosas funciones de software para que pudieran realizarse casi simultáneamente en tiempo real en la computadora de a bordo de la nave espacial, que tiene un tamaño y una velocidad limitados. .
La arquitectura de Hal evitó las trampas de un sistema operativo en el que los cálculos deberían dividirse claramente entre períodos de tiempo. Tales sistemas son bastante difíciles de implementar, porque las tareas pueden cambiar arbitrariamente. Cuando se agregan o cambian tareas durante el proceso de desarrollo, puede ser necesario un cambio en la planificación de tareas. Lo peor es que el sistema operativo existente de la computadora de a bordo es muy frágil, en el sentido de que falla por completo si la tarea lleva más tiempo del asignado.
En cambio, Leining desarrolló un sistema en el que las funciones del programa se distribuyen en forma de "tareas", que pueden ser de cualquier tamaño que se requiera para realizar estas funciones. A cada tarea se le asigna una prioridad. El sistema operativo siempre realiza la tarea con la máxima prioridad. Si se realiza una tarea con prioridad baja y se asigna una tarea con prioridad alta en este momento, entonces la tarea con prioridad baja se suspenderá hasta que se complete la tarea con prioridad alta. Tal sistema nos da la ilusión de que las tareas se realizan simultáneamente, aunque en realidad, por supuesto, las tareas se realizan a su vez. Tal sistema no es determinista, pero sus funciones son comprensibles y pueden ser verificadas, y aumenta la confiabilidad, seguridad, flexibilidad de uso y, en particular, la facilidad de desarrollo.
Ejecutivo (
sistema operativo en tiempo real AGC y LGC. Aprox. Transl. ) Organizó la ejecución de tareas de tal manera que cada tarea retuvo su estado en forma de un conjunto de registros, y el estado se mantuvo mientras la tarea se realizaba con alta prioridad. LGC contiene una matriz de ocho conjuntos de 12 registros cada uno, 15 bits por registro. Un conjunto de registros de este tamaño es suficiente para realizar muchas tareas, pero las tareas que utilizan el intérprete (un
lenguaje de interpretación incorporado para tareas que operan con números de doble precisión. Transl. Aprox. ) Para realizar cálculos vectoriales y matriciales requieren más espacio. Para tales tareas, se asigna una matriz separada de 43 registros. LGC contiene cinco de estos arreglos (Vector Accumulator, VAC).
Con un conjunto tan limitado de matrices para mantener el contexto de las tareas, el inicio de tareas para la ejecución debe realizarse con mucho cuidado. Las funciones que se realizan secuencialmente una tras otra se combinaron en una tarea. La gran tarea de SERVICER estuvo activa durante toda la fase de aterrizaje y otras fases del vuelo con el motor encendido, e incluyó navegación usando acelerómetros, ecuaciones de movimiento, control del acelerador del motor, datos sobre la posición del barco, otros datos en la pantalla y cada uno. La función utilizaba la salida de las anteriores.
El número de matrices de registros disponibles y VAC limita el número de tareas que se pueden poner en cola para su ejecución en ocho, de las cuales hasta cinco pueden usar matrices de VAC. Durante el funcionamiento normal, el número de tareas en ejecución permanece constante, aunque las tareas iniciadas para una sola ejecución, o de forma asincrónica, pueden causar fluctuaciones en la carga del sistema.
Sin embargo, si el número de tareas iniciadas está más que completado, aumenta el número de matrices de registros y VAC utilizados. Si esta situación continúa durante un tiempo suficientemente largo, su número se agota y no se puede satisfacer la solicitud para iniciar la siguiente tarea.
Regresaremos un año antes, antes del lanzamiento del Apolo 11, cuando nosotros, los ingenieros de software, pensamos que ya teníamos suficientes cosas, y se nos pidió que escribiéramos software para aterrizar en la Luna de tal manera que literalmente se pudiera apagar y volver a encender. sin interrumpir el proceso de aterrizaje y otras maniobras vitales! Esto se llamaba "reiniciar la protección". Además de la interferencia de energía, otros factores pueden hacer que el sistema se reinicie. El reinicio se produce si el hardware cree que el programa se bloqueó en un bucle infinito, o si se produjo un error de paridad al leer la ROM, o por varias otras razones.
La protección contra el reinicio se implementó mediante el registro de "puntos de referencia" en los puntos adecuados del programa, organizados de tal manera que regresar al último "punto de referencia" no causara un error, como se muestra en el siguiente ejemplo:
NEW_X = X + 1
X = NEW_XObviamente, sin registrar el waypoint, ejecutar este código por segunda vez hará que X se incremente nuevamente.
Después del reinicio, dicho programa reanuda su trabajo. Cada tarea comienza con el último waypoint registrado. Si varias copias de la misma tarea estaban en la cola, solo se reanuda la última. Algunas tareas no tienen un estado vital y no están protegidas contra el reinicio. Ellos simplemente desaparecen.
Reiniciar la protección funcionó muy bien. En el panel de control de nuestro simulador híbrido en Cambridge había un botón que provocó el reinicio de AGC. Al probar el software, a veces presionábamos este botón en momentos aleatorios, casi esperando que la falla nos llevara a otro error. Invariablemente, cada vez que se activaba la protección contra reinicio, y el trabajo continuaba sin detenerse.
(El simulador híbrido contenía una computadora digital SDS 9300 y una computadora analógica Beckmann, una computadora AGC real y modelos de cabina realistas para los módulos de comando y lunares).
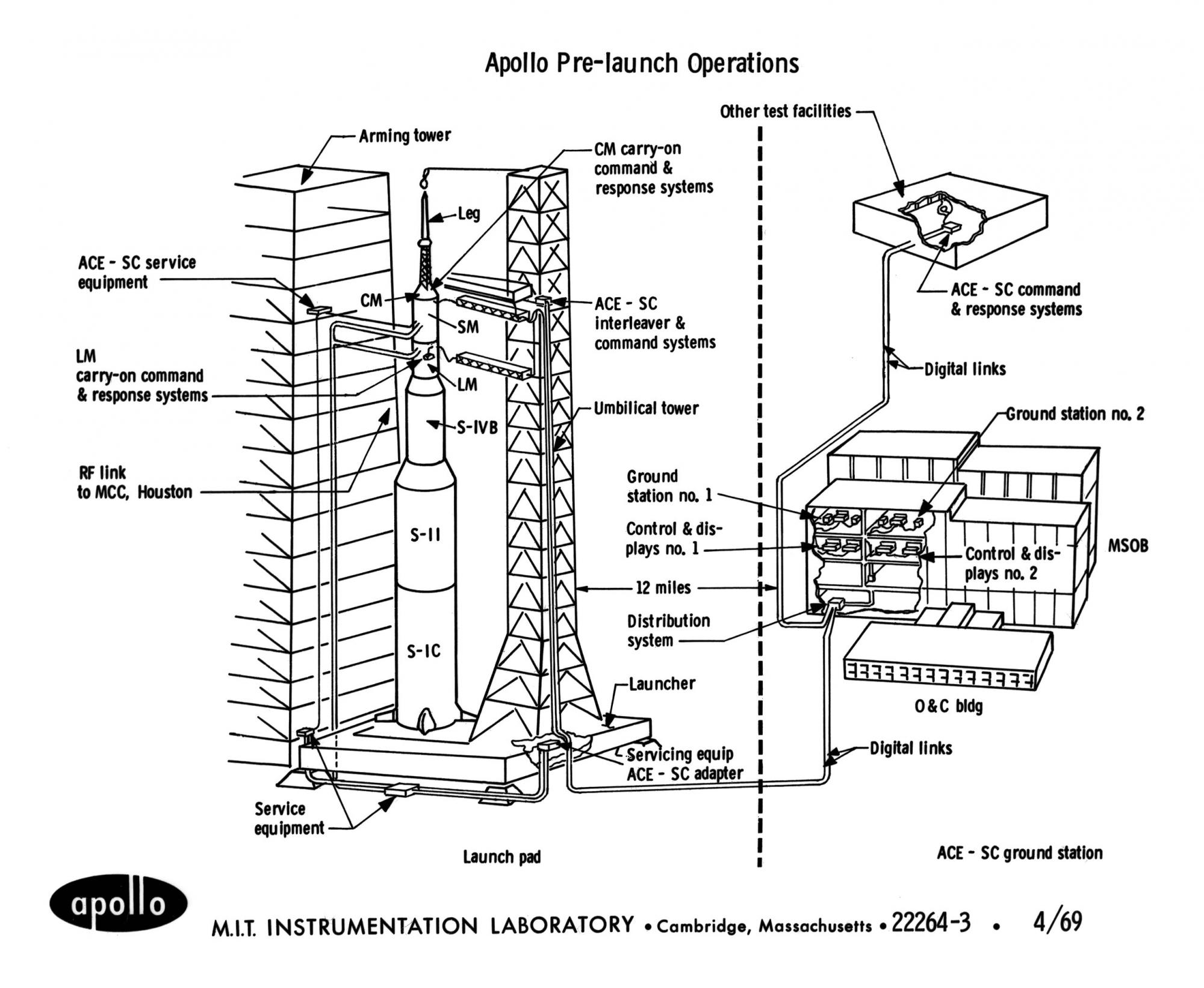 Preparación previa al lanzamiento de Apollo.
Preparación previa al lanzamiento de Apollo.No solo el hierro podría provocar un reinicio, sino que se podría llamar mediante programación si el programa llegara a un punto en el que la computadora no supiera cómo continuar ejecutándolo. Esto sucedió al transferir el control bajo la etiqueta BAILOUT en el módulo de alarmas y abortos. La llamada fue acompañada por un código de error.
Estas acciones fueron realizadas por el sistema Ejecutivo si se agotaron los recursos. Si la tarea no se puede establecer debido al hecho de que no hay matrices libres para guardar registros, Executive llamó a BAILOUT con el código de error 1202. Si no había VAC libre, se llamó a BAILOUT con el código 1201.
No todas las funciones realizadas por LGC se realizaron como "tareas". Además de ellos, hubo interrupciones de hardware que podrían ocurrir en cualquier momento (si no se prohibieron explícitamente) que realizaban funciones de alta prioridad, se asignaron interrupciones a ciertos dispositivos, incluidos el piloto automático digital, el enlace ascendente y el enlace descendente (
dispositivo de transmisión y recepción datos en el canal de radio con la Tierra (aprox. transl. ) y el teclado.
Se podrían usar otras interrupciones para ejecutar fragmentos de código que deben ejecutarse en un momento específico. Dichas funciones se llamaron tareas y se programaron en una subrutina llamada WAITLIST. Se suponía que las "tareas" tenían un tiempo de entrega muy corto.
Mientras que las "tareas" se planificaron para su ejecución con una cierta prioridad, las "tareas" se planificaron para su lanzamiento en un momento determinado. Las tareas y tareas a menudo se compartían. La tarea podría iniciarse para leer las lecturas del sensor, que deberían leerse en un momento estrictamente definido, y la tarea, a su vez, inició una tarea con cierta prioridad para procesar estas lecturas.
Cuando Hal Lane diseñó Ejecutivo y Lista de espera a mediados de la década de 1960, hizo todo desde cero, sin depender de ningún ejemplo. Y sus principios son ciertos hoy. La distribución de funciones por un número limitado de procesos asincrónicos, bajo el control de un entorno ejecutivo con multitarea preventiva basada en intervalos de tiempo y prioridades, todo esto subyace en los sistemas informáticos modernos en tiempo real para aplicaciones espaciales.
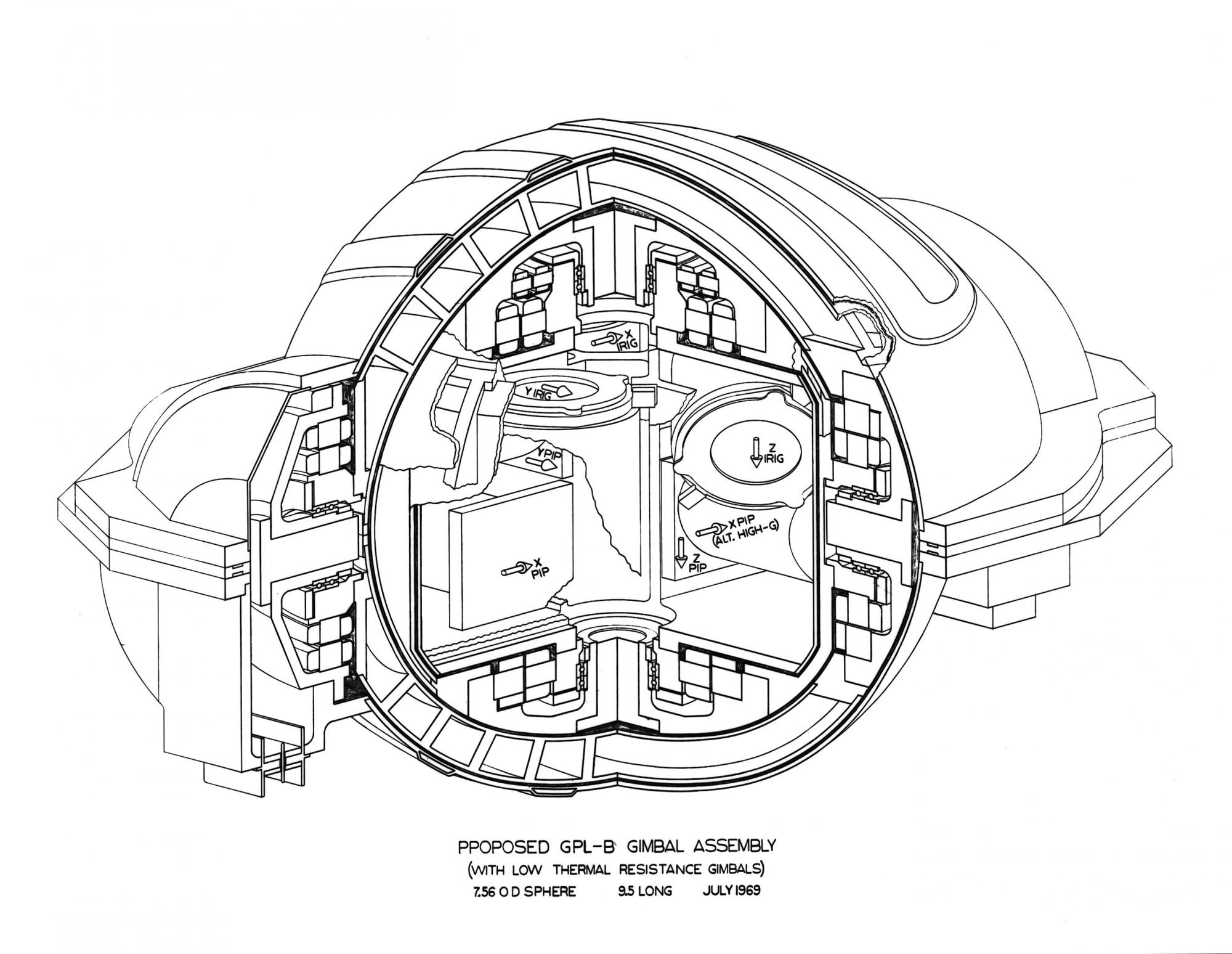 Montaje de giroscopios.
Montaje de giroscopios.* * *
Para comprender la causa raíz de las alarmas en el Apolo 11 durante el descenso, es necesario considerar el procedimiento de aproximación con el módulo de comando, que sigue después del ascenso del módulo lunar desde la superficie lunar a la órbita lunar. Así como usamos un radar de aterrizaje para medir la altitud y la velocidad en relación con la superficie lunar cuando aterrizamos en la luna, para acercarnos al módulo de comando en órbita lunar se requiere medir la distancia, la velocidad y la dirección en relación con la segunda nave que usa el radar de aproximación.
El radar de proximidad tiene varios modos de funcionamiento configurados por el interruptor de modo. Estos modos son los siguientes: SLEW, AUTO y LGC. En los modos SLEW y AUTO, el radar funciona bajo control de comando, independientemente de LGC. Este modo de operación podría usarse durante el despegue y la aproximación en caso de falla del sistema de navegación principal. En el modo SLEW, la antena del radar se guía manualmente, el resto del tiempo es estacionaria. Cuando la antena apunta al objetivo, puede cambiar el modo a AUTO (seguimiento automático) y rastreará el objetivo. El radar de proximidad mide la distancia y la velocidad, y los ángulos de rotación de los ejes a los que gira la antena se muestran en las pantallas de la cabina y en los indicadores en forma de escalas verticales. Además, los datos de distancia y velocidad ingresaron al sistema de guía de aborto (AGS), una computadora con solo 6144 palabras de memoria que duplicaban el sistema PGNS principal al aterrizar en la luna y despegar de la luna.
(Los nombres de los tres modos de funcionamiento del radar de acercamiento fueron una fuente de vergüenza para algunos comentaristas. A petición de la tripulación, las designaciones se cambiaron después de la misión LM-1 y antes de que la misión aterrizara en la luna. El modo que el Apolo 11 llamó LGC se llamaba anteriormente AUTO. El modo que se llamaba AUTO en Apollo 11, anteriormente llamado MANUAL. El nombre del modo SLEW permaneció sin cambios. Aunque esto de ninguna manera contribuyó al problema en Apollo 11, la documentación LUMINARIA interna en la sección relativa al canal discreto 33, en ese momento todavía se llamaba re Punto de referencia LGC con el radar de proximidad activado por RR AUTO-POWER ON.)
Si el sistema PGNS funcionaba (como realmente era), el LGC controlaba el radar, en cuyo caso el interruptor de modo de radar de proximidad estaba configurado en LGC. La electrónica de la interfaz del radar permitió que el software obtuviera datos sobre la distancia y la velocidad medidas por el radar, así como los ángulos del eje de rotación de la antena, desde donde se puede encontrar la dirección al objetivo. El programa LGC utilizó esta información para acercar al LGC al módulo de comando.
Resultó que el radar de aproximación también puede funcionar durante el descenso, y esto se hizo durante el descenso del Apolo 11. Las instrucciones de la tripulación requieren que el radar se encienda inmediatamente antes del inicio de la fase P63 y que permanezca en modo SLEW o AUTO durante toda la maniobra de aterrizaje.
Se dieron muchas explicaciones de por qué el radar se sintonizó de esta manera para aterrizar en la luna. Por ejemplo, algunas personas en Houston pueden haber considerado un elegante esquema de monitoreo de aterrizaje al comparar datos de radar con un gráfico de lecturas esperadas. Sin embargo, hay una explicación más simple: el radar se encendió antes de aterrizar solo para mantenerse caliente en caso de accidente durante la interrupción, y estaba en modo AUTO (si el módulo lunar estaba en una posición que le permite rastrear el módulo de comando) o SLEW (en otros momentos), solo para evitar movimientos inútiles de la antena.
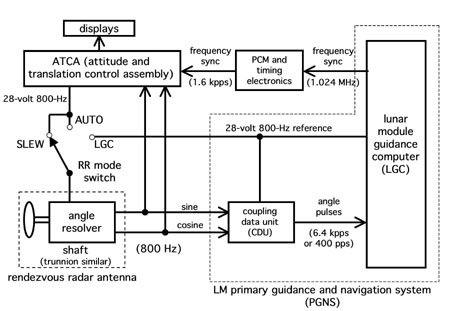
Figura 7.
Interfaces de radar PGNS, ATCA y de proximidadEste problema a menudo se atribuyó (incluido el autor anteriormente) simplemente como un error en la lista de verificación. Esta es una redacción inexacta, al igual que es incorrecto llamar a un apagado prematuro del monitor
El motor delta-V del módulo lunar es un "error de computadora", mientras que de hecho el error estaba en la documentación. De hecho, la posición del interruptor de radar de proximidad Apollo 11 no debería haber causado ningún problema. Pero desde aquí puede rastrear otro caso de errores en la documentación.
Años antes, la documentación estaba escrita en el documento de control de interfaz (ICD), que define la interfaz eléctrica entre el PGNS y la electrónica ATCA (conjunto de control de actitud y traducción), que fue suministrada por Grumman Aerospace, la compañía que construyó el módulo de aterrizaje. ICD determinó que los circuitos de suministro de energía de 28 V con una frecuencia de 800 Hz en dos sistemas deben estar alineados en frecuencia, pero no está escrito que se deben sincronizar en fase. De hecho, los dos sistemas estaban alineados en frecuencia con la señal de "sincronización de frecuencia" enviada por LGC. Tenían una relación de fase constante. Sin embargo, la fase entre los dos voltajes fue una variable completamente aleatoria, dependiendo del momento en que el LGC, que siempre funcionaba después de ACTA, comenzó a enviar una señal de sincronización. Estas interfaces se muestran en la fig. 7)
Se detectó un problema con la fase de 800 Hz al probar el módulo de aterrizaje LM-3 y se documenta, pero nunca se ha solucionado. Como resultado, cuando el interruptor de modo de radar estaba en la posición AUTO o SLEW, el mecanismo giratorio del radar fue excitado por una señal de 800 Hz del ATCA, que con alta probabilidad no coincide en fase con la señal de 800 Hz, que se utiliza como referencia en CDU que convierten señales de un mecanismo para convertir los datos en la computadora y disminuir (o disminuir) los contadores en la computadora que le indican al programa cómo gira la antena.
Sin embargo, en el Apolo 11, las CDU funcionaron de manera diferente. Como tomaron el voltaje generado por separado como señal de referencia, las señales del sensor de ángulo de antena recibidas por la CDU mostraron un ángulo desconocido. El error fue mayor si la diferencia de fase era cercana a 90 o 270 grados, y el Apolo 11, obviamente, alcanzó uno de estos puntos interesantes. En respuesta, la CDU comenzó a aumentar o disminuir los contadores LGC a una velocidad casi constante, aproximadamente 6400 pulsos por segundo para cada una de las esquinas. Esto sucedió cada vez que el interruptor estaba en modo SLEW o AUTO, independientemente de si el radar de proximidad estaba encendido.
Los contadores de CDU en LGC fueron incrementados o disminuidos por señales externas que fueron procesadas en la computadora. Esto llevó mucho tiempo, en este caso un ciclo de memoria de 11.7 µs cada uno. Si los contadores aumentaron a la velocidad máxima, tomó aproximadamente el 15% del tiempo total (este tiempo perdido se llama TLOSS). Actualmente estamos proporcionando una estimación conservadora del tiempo invertido del 13%, que es consistente con el comportamiento observado.
Después del vuelo del Apolo 11, los ingenieros de Grumman realizaron pruebas en un intento de reproducir el comportamiento de la computadora observado en vuelo. Confirmaron que incluso en el peor de los casos, las CDU no podían enviar pulsos a la velocidad máxima. Llegaron a la conclusión de que la carga máxima de la computadora con estos medidores (TLOSS) podría ser del 13.36%. Durante la simulación, se reprodujeron errores similares a los que ocurrieron en vuelo. Por lo tanto, el valor TLOSS citado es la mejor estimación documentada de la carga de la computadora Apollo 11. [Clint Tillman, "Simulando la interfaz RR-CDU cuando el RR está en el modo SLEW o AUTO (no LGC) en el Laboratorio FMES / FCI", 9 de agosto 1969]
Estoy en deuda con el experto en sistemas de guía del módulo lunar George Silver por su paciente explicación de la interfaz de radar de aproximación del módulo lunar. Jugó un papel central en la misión Apolo 11. En el momento del lanzamiento, se encontraba en Cabo Cañaveral, luego voló a Boston, a Cambridge, para vigilar el despegue desde la Luna. Vio la luna aterrizando en su casa por televisión el 20 de julio. Escuchó el sonido de las alarmas, supuso que algo estaba ocupando el tiempo de la computadora y recordó un caso que había visto al probar los sistemas LM-3, cuando el radar de proximidad causó una actividad frenética en los contadores. Después de un análisis adicional por parte del equipo de monitoreo de la misión de Cambridge, Silver finalmente contactó a representantes del MIT en Houston en la mañana del 21 de julio, menos de una hora antes del despegue de la luna.
 Fragmento de control manual
Fragmento de control manual* * *
Aterrizar en la luna fue la fase más intensa del vuelo. El sistema de control de aterrizaje tenía que lograr un objetivo con ciertas coordenadas, que tenía una cierta velocidad, aceleración, grado de sacudidas (grado de cambio / aceleración). Klumpp llamó a la tasa de cambio del “tirón” (“tirón”) “chasquido” (chasquido), y los siguientes dos derivados se llamaron “crujido” y “estallido” (estallido). En la fase de visibilidad (
es decir, cuando la superficie de la luna era visible en ojo de buey de la nave (aprox. transl. ) el programa permitió a la tripulación cambiar el lugar de aterrizaje. El acelerador se controló continuamente. La navegación incluyó mediciones utilizando el radar de aterrizaje. La figura 8. muestra un perfil de carga típico entre la elección de la fase P63 y tocar la superficie de la luna.

Fig. 8:
Carga durante el aterrizaje (datos del simulador)Incluso en estas condiciones, tratamos de hacer que nuestros programas sean lo suficientemente rápidos como para tener suficiente tiempo en caso de un TLOSS grande. La principal limitación fue el período de dos segundos, que se incorporó al programa "promedio-G" utilizado durante la fase de vuelo. , READACCS SERVICER, , , . , , .
Durante la fase de frenado, hasta que el radar de aterrizaje vio la superficie, el tiempo de reserva fue de al menos 15%. Una vez que se pone en funcionamiento el radar, comienzan los cálculos adicionales, asociados con la transferencia de coordenadas del sistema de referencia del radar al sistema de coordenadas para la navegación, lo que reduce el margen en un 13%. Cuando comienza la presentación (verbo 16, sustantivo 68), el margen disminuye a 10% o menos. Baz Aldrin fue perceptivo cuando dijo después de la señal 1202, "parece que apareció cuando entramos en 1668" [16].Cuando el margen es del 10% y se elimina el 13%, LGC no tiene suficiente tiempo de procesador para realizar todas las funciones requeridas. Debido a la flexibilidad del diseño Ejecutivo, y a diferencia de lo que sucedería con la arquitectura rígida, no hubo desastre.Tabla 1. Tareas activas al aterrizar en la luna. La Tabla 1 enumera las tareas que están activas al aterrizar el Apollo 11. SERVICER tiene la prioridad más baja y la más larga. Las tareas de alta prioridad pueden detener al SERVIDOR, pero tienen un tiempo de entrega relativamente corto.
La Tabla 1 enumera las tareas que están activas al aterrizar el Apollo 11. SERVICER tiene la prioridad más baja y la más larga. Las tareas de alta prioridad pueden detener al SERVIDOR, pero tienen un tiempo de entrega relativamente corto.SERVICER - , - . , SERVICER , READACCS, , SERVICER . SERVICER , VAC, READACCS FINDVAC, Executive VAC SERVICER. SERVICER . VAC . Executive , BAILOUT 1201 1202.
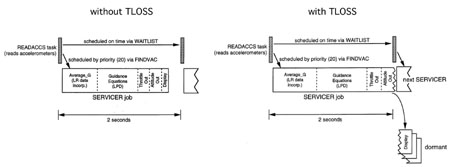
9:
SERVICER TLOSSFig.
La Figura 9 muestra cómo se comporta SERVICER con un TLOSS fuerte, y en la fig. La Figura 10 muestra una comparación de los registros y los conjuntos de VAC durante el funcionamiento normal y con TLOSS fuerte, durante el cual se produce el reinicio.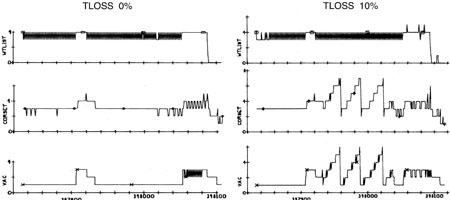
Fig. 10.
, TLOSS Executive Waitlist ( , P63 , [17].), P63, , . SERVICER, SERVICER. , , , , DELTAH ( 16, 68). , P63, « 68» « 63».
El sistema de protección de reinicio se desarrolló originalmente debido a posibles fallas de hardware y proporcionó una reducción en la carga computacional con un gran TLOSS. El sistema en tiempo real que desarrollamos resultó ser tolerante a fallas en ciertas condiciones.Durante la fase P64, la situación fue diferente. Además de las ecuaciones de movimiento habituales, se agregó un procesamiento adicional que incluía la capacidad de reasignar el sitio de aterrizaje. Las funciones de software adicionales dejan un margen de tiempo inferior al 10%. Las alarmas continuaron surgiendo. Tres alarmas de 1201 y 1202 ocurrieron en 40 segundos. Cada vez, el software se reiniciaba, borrando la cola de tareas, pero no podía reducir la carga.102:43:08, , AUTO ATT HOLD , , P66, . 2 20 P66, .