
Este es un mito que es bastante común en el campo del hardware del servidor. En la práctica, las soluciones hiperconvergentes (cuando están todas juntas) necesitan mucho para qué. Históricamente, las primeras arquitecturas fueron desarrolladas por Amazon y Google para sus servicios. Entonces, la idea era hacer una granja informática de los mismos nodos, cada uno de los cuales tiene sus propios discos. Todo esto fue combinado por un software de formación de sistemas (hipervisor) y ya estaba dividido en máquinas virtuales. La tarea principal es un mínimo esfuerzo para mantener un nodo y un mínimo de problemas de escala: acabamos de comprar otros mil o dos de los mismos servidores y nos conectamos cerca. En la práctica, estos son casos aislados, y mucho más a menudo estamos hablando de un número menor de nodos y una arquitectura ligeramente diferente.
Pero la ventaja sigue siendo la misma: la increíble facilidad de escala y control. Menos: diferentes tareas consumen recursos de manera diferente, y en algún lugar habrá muchos discos locales, en algún lugar habrá poca RAM, y así sucesivamente, es decir, con diferentes tipos de tareas, la utilización de recursos disminuirá.
Resultó que pagas 10-15% más para facilitar la configuración. Esto causó el mito principal. Buscamos durante mucho tiempo dónde se aplicará la tecnología de manera óptima, y la encontramos. El hecho es que Tsiska no tenía sus propios sistemas de almacenamiento, pero querían un mercado completo de servidores. E hicieron Cisco Hyperflex, una solución de almacenamiento local en nodos.
Y esto de repente resultó ser una muy buena solución para los centros de datos de respaldo (recuperación ante desastres). Por qué y cómo, ahora lo diré. Y mostraré pruebas de clúster.
A donde
La hiperconvergencia es:
- Transfiera discos a nodos de cómputo.
- Integración completa del subsistema de almacenamiento con el subsistema de virtualización.
- Transferencia / integración con el subsistema de red.
Tal combinación le permite implementar muchas características de los sistemas de almacenamiento a nivel de virtualización y todo desde una ventana de control.
En nuestra empresa, los proyectos para diseñar centros de datos de respaldo tienen una gran demanda, y a menudo se elige la solución hiperconvergente debido a la gran cantidad de opciones de replicación (hasta el clúster de metro) listas para usar.
En el caso de los centros de datos de respaldo, generalmente se trata de una instalación remota en un sitio al otro lado de la ciudad o en otra ciudad en general. Le permite restaurar sistemas críticos en caso de una falla parcial o completa del centro de datos principal. Los datos de ventas se replican constantemente allí, y esta replicación puede ser a nivel de aplicación o a nivel de dispositivo de bloque (SHD).
Así que ahora hablaré sobre el dispositivo y las pruebas del sistema, y luego sobre un par de escenarios de la vida real con datos sobre ahorros.
Pruebas
Nuestra copia consta de cuatro servidores, cada uno de los cuales tiene 10 discos SSD por 960 GB. Hay un disco dedicado para almacenar en caché las operaciones de escritura y el almacenamiento de la máquina virtual de servicio. La solución en sí es la cuarta versión. El primero es francamente crudo (a juzgar por las revisiones), el segundo está húmedo, el tercero ya es bastante estable, y este puede llamarse un lanzamiento después del final de las pruebas beta para el público en general. Durante la prueba de los problemas que no vi, todo funciona como un reloj.
Cambios en v4Se corrigieron un montón de errores.
Inicialmente, la plataforma solo podía funcionar con el hipervisor VMware ESXi y admitía una pequeña cantidad de nodos. Además, el proceso de implementación no siempre finalizó con éxito, tuve que reiniciar algunos pasos, hubo problemas para actualizar desde versiones anteriores, los datos en la GUI no siempre se mostraban correctamente (aunque todavía no estoy contento con mostrar gráficos de rendimiento), a veces hubo problemas en la interfaz con la virtualización .
Ahora que se han reparado todas las llagas de los niños, HyperFlex puede hacer ESXi y Hyper-V, y esto es posible:
- Crear un clúster extendido.
- Crear un clúster para oficinas sin usar Fabric Interconnect, de dos a cuatro nodos (solo compramos servidores).
- Capacidad para trabajar con almacenamiento externo.
- Soporte para contenedores y Kubernetes.
- Creación de zonas de accesibilidad.
- Integración con VMware SRM, si la funcionalidad incorporada no es adecuada.
La arquitectura no es muy diferente de las decisiones de los principales competidores, no crearon una bicicleta. Todo funciona en la plataforma de virtualización VMware o Hyper-V. Hardware alojado en servidores propietarios de Cisco UCS. Hay quienes odian la plataforma por la relativa complejidad de la configuración inicial, muchos botones, un sistema no trivial de plantillas y dependencias, pero también hay quienes aprendieron Zen, se inspiraron en la idea y ya no quieren trabajar con otros servidores.
Consideraremos la solución específicamente para VMware, ya que la solución se creó originalmente para él y tiene más funcionalidad, se agregó Hyper-V en el camino para mantenerse al día con los competidores y cumplir con las expectativas del mercado.
Hay un grupo de servidores llenos de discos. Hay discos para el almacenamiento de datos (SSD o HDD, a su gusto y necesidades), hay un disco SSD para el almacenamiento en caché. Cuando los datos se escriben en el almacén de datos, los datos se guardan en la capa de almacenamiento en caché (disco SSD dedicado y servicio de RAM de VM). Paralelamente, el bloque de datos se envía a los nodos en el clúster (el número de nodos depende del factor de replicación del clúster). Después de la confirmación de todos los nodos sobre la grabación exitosa, la confirmación de la grabación se envía al hipervisor y luego a la VM. Los datos grabados en segundo plano se deduplican, comprimen y escriben en discos de almacenamiento. Al mismo tiempo, siempre se escribe un bloque grande en los discos de almacenamiento y de forma secuencial, lo que reduce la carga en los discos de almacenamiento.
La deduplicación y la compresión siempre están activadas y no se pueden desactivar. Los datos se leen directamente desde discos de almacenamiento o desde la memoria caché de RAM. Si se usa una configuración híbrida, la lectura también se almacena en caché en el SSD.
Los datos no están vinculados a la ubicación actual de la máquina virtual y se distribuyen de manera uniforme entre los nodos. Este enfoque le permite cargar por igual todas las unidades e interfaces de red. La desventaja obvia es: no podemos minimizar el retraso de lectura, ya que no hay garantía de disponibilidad de datos a nivel local. Pero creo que este es un sacrificio insignificante en comparación con las ventajas recibidas. Además, los retrasos en la red han alcanzado tales valores que prácticamente no afectan el resultado general.
Para toda la lógica del subsistema de disco, es responsable una VM de servicio especial del controlador Cisco HyperFlex Data Platform, que se crea en cada nodo de almacenamiento. En nuestra configuración de VM de servicio, se asignaron ocho vCPU y 72 GB de RAM, que no es tan pequeño. Permítame recordarle que el host en sí tiene 28 núcleos físicos y 512 GB de RAM.
El servicio VM tiene acceso a discos físicos directamente al reenviar el controlador SAS a la VM. La comunicación con el hipervisor se produce a través de un módulo especial IOVisor, que intercepta las operaciones de E / S, y utiliza un agente que le permite transferir comandos a la API del hipervisor. El agente es responsable de trabajar con instantáneas y clones de HyperFlex.
En el hipervisor, los recursos de disco se montan como una bola NFS o SMB (dependiendo del tipo de hipervisor, adivine cuál). Y bajo el capó, este es un sistema de archivos distribuido que le permite agregar características de sistemas de almacenamiento completos para adultos: asignación de volumen delgado, compresión y deduplicación, instantáneas que utilizan la tecnología Redirect-on-Write, replicación síncrona / asíncrona.
Service VM proporciona acceso a la interfaz WEB de la gestión del subsistema HyperFlex. Hay integración con vCenter, y la mayoría de las tareas diarias se pueden realizar desde él, pero los almacenes de datos, por ejemplo, son más convenientes para cortar desde una cámara web separada si ya ha cambiado a una interfaz HTML5 rápida, o usar un cliente Flash completo con integración completa. En la cámara web de servicio, puede ver el rendimiento y el estado detallado del sistema.
Hay otro tipo de nodo en un clúster: nodos computacionales. Pueden ser servidores rack o blade sin unidades integradas. En estos servidores, puede ejecutar máquinas virtuales cuyos datos se almacenan en servidores con discos. Desde el punto de vista del acceso a los datos, no hay diferencia entre los tipos de nodos, porque la arquitectura implica la abstracción de la ubicación física de los datos. La relación máxima de nodos de cálculo y nodos de almacenamiento es 2: 1.
El uso de nodos computacionales aumenta la flexibilidad al escalar los recursos del clúster: no tenemos que comprar nodos con discos si solo necesitamos CPU / RAM. Además, podemos agregar una canasta blade y ahorrar espacio en el servidor del rack.
Como resultado, tenemos una plataforma hiperconvergente con las siguientes características:
- Hasta 64 nodos en un clúster (hasta 32 nodos de almacenamiento).
- El número mínimo de nodos en un clúster es tres (dos para un clúster Edge).
- Mecanismo de redundancia de datos: duplicación con factor de replicación 2 y 3.
- Metro cluster.
- Replicación asíncrona de VM a otro clúster HyperFlex.
- Orquestación de cambio de máquinas virtuales a un centro de datos remoto.
- Instantáneas nativas utilizando la tecnología Redirect-on-Write.
- Hasta 1 PB de espacio utilizable con factor de replicación 3 y sin deduplicación. No tenemos en cuenta el factor de replicación 2, ya que esta no es una opción para ventas serias.
Otra gran ventaja es la facilidad de administración y despliegue. Todas las complejidades de la configuración de servidores UCS son manejadas por una VM especializada preparada por ingenieros de Cisco.
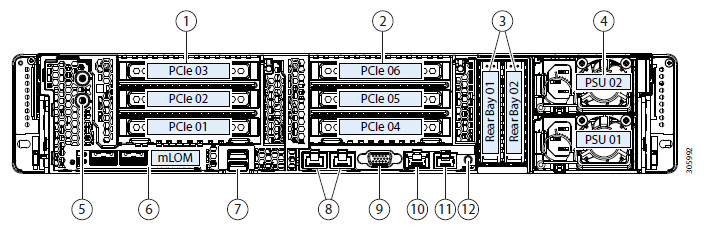
Configuración del banco de pruebas:
- 2 x Cisco UCS Fabric Interconnect 6248UP como un clúster de gestión y componentes de red (48 puertos que funcionan en modo Ethernet 10G / FC 16G).
- Cuatro servidores Cisco UCS HXAF240 M4.
Características del servidor:
Más opciones de configuraciónAdemás del hierro seleccionado, las siguientes opciones están actualmente disponibles:
- HXAF240c M5.
- Una o dos CPU que van desde Intel Silver 4110 hasta Intel Platinum I8260Y. La segunda generación está disponible.
- 24 ranuras de memoria, listones de 16 GB RDIMM 2600 a 128 GB LRDIMM 2933.
- De 6 a 23 discos para datos, un disco de almacenamiento en caché, un sistema y un disco de arranque.
Unidades de capacidad- HX-SD960G61X-EV 960GB 2.5 pulgadas Enterprise Value 6G SSD SATA (1X resistencia) SAS 960 GB.
- HX-SD38T61X-EV 3.8TB 2.5 pulgadas Enterprise Value 6G SATA SSD (1X resistencia) SAS 3.8 TB.
- Controladores de caché
- HX-NVMEXPB-I375 375GB 2.5 pulgadas Intel Optane Drive, Extreme Perf & Endurance.
- HX-NVMEHW-H1600 * 1.6TB 2.5 pulgadas Ent. Perf NVMe SSD (resistencia 3X) NVMe 1.6 TB.
- HX-SD400G12TX-EP 400GB 2.5 pulgadas Ent. Perf SSD SAS 12G (resistencia 10X) SAS 400 GB.
- HX-SD800GBENK9 ** 800GB 2.5 pulgadas Ent. Perf SSD SED SAS 12G (resistencia 10X) SAS 800 GB.
- HX-SD16T123X-EP 1.6TB 2.5 pulgadas Enterprise performance 12G SAS SSD (resistencia 3X).
Sistema / Log Drives- HX-SD240GM1X-EV 240GB SSD SATA Enterprise Value 6G de 2.5 pulgadas (Requiere actualización).
Controladores de arranque- HX-M2-240GB 240GB SATA M.2 SSD SATA 240 GB.
Conexión a una red en puertos Ethernet 40G, 25G o 10G.
Como FI puede ser HX-FI-6332 (40G), HX-FI-6332-16UP (40G), HX-FI-6454 (40G / 100G).
Probarse
Para probar el subsistema de disco, utilicé HCIBench 2.2.1. Esta es una utilidad gratuita que le permite automatizar la creación de carga desde múltiples máquinas virtuales. La carga en sí es generada por fio regular.
Nuestro clúster consta de cuatro nodos, factor de replicación 3, todas las unidades Flash.
Para las pruebas, creé cuatro almacenes de datos y ocho máquinas virtuales. Para las pruebas de escritura, se supone que el disco de almacenamiento en caché no está lleno.
Los resultados de la prueba son los siguientes:
Se indican valores en negrita, después de lo cual no hay aumento en la productividad, a veces incluso la degradación es visible. Debido al hecho de que descansamos en el rendimiento de la red / controladores / unidades.- Lectura secuencial de 4432 MB / s.
- Escritura secuencial de 804 MB / s.
- Si falla un controlador (máquina virtual o falla del host), la reducción del rendimiento se duplica.
- Si la unidad de almacenamiento falla, la reducción es 1/3. Rebild disk toma el 5% de los recursos de cada controlador.
En un bloque pequeño, nos encontramos con el rendimiento del controlador (máquina virtual), su CPU está cargada al 100%, al tiempo que aumenta el bloque que corremos en el ancho de banda del puerto. 10 Gbps no son suficientes para desbloquear el potencial del sistema AllFlash. Desafortunadamente, los parámetros del soporte de demostración proporcionado no permiten verificar el trabajo a 40 Gb / s.
En mi impresión de las pruebas y el estudio de la arquitectura, debido al algoritmo que coloca los datos entre todos los hosts, obtenemos un rendimiento predecible escalable, pero esto también es una limitación al leer, ya que sería posible exprimir más de los discos locales y más, aquí para guardar una red más productiva, por ejemplo, hay 40 Gbps FI disponibles.
Además, un disco para el almacenamiento en caché y la deduplicación puede ser una limitación; de hecho, en este soporte podemos escribir en cuatro discos SSD. Sería genial poder aumentar el número de discos en caché y ver la diferencia.
Uso real
Se pueden usar dos enfoques para organizar un centro de datos de respaldo (no consideramos colocar el respaldo en un sitio remoto):
- Pasivo activo Todas las aplicaciones están alojadas en el centro de datos principal. La replicación es síncrona o asíncrona. En caso de una caída en el centro de datos principal, debemos activar el de respaldo. Esto se puede hacer manualmente / scripts / aplicaciones de orquestación. Aquí obtenemos un RPO acorde con la frecuencia de replicación, y el RTO depende de la reacción y las habilidades del administrador y la calidad del desarrollo / depuración del plan de conmutación.
- Activo activo En este caso, solo está presente la replicación sincrónica, la disponibilidad de los centros de datos está determinada por un quórum / árbitro, ubicado estrictamente en la tercera plataforma. RPO = 0, y RTO puede alcanzar 0 (si la aplicación lo permite) o igual al tiempo de conmutación por error de un nodo en un clúster de virtualización. En el nivel de virtualización, se crea un clúster ampliado (Metro) que requiere almacenamiento activo-activo.
Por lo general, vemos con los clientes una arquitectura ya implementada con almacenamiento clásico en el centro de datos principal, por lo que diseñamos otra para la replicación. Como mencioné, Cisco HyperFlex ofrece replicación asincrónica y la creación de un clúster de virtualización extendido. Al mismo tiempo, no necesitamos un sistema de almacenamiento dedicado de rango medio o superior con las costosas funciones de replicación y acceso de datos activo-activo en dos sistemas de almacenamiento.
Escenario 1: Tenemos centros de datos primarios y de respaldo, una plataforma de virtualización en VMware vSphere. Todos los sistemas productivos se encuentran principalmente en el centro de datos, y la replicación de la máquina virtual se realiza a nivel de hipervisor, esto permitirá no mantener las máquinas virtuales encendidas en el centro de datos de respaldo. Replicamos bases de datos y aplicaciones especiales con herramientas integradas y mantenemos las máquinas virtuales encendidas. Si el centro de datos principal falla, iniciamos el sistema en el centro de datos de respaldo. Creemos que tenemos alrededor de 100 máquinas virtuales. Mientras el centro de datos principal esté funcionando, los entornos de prueba y otros sistemas se pueden iniciar en el centro de datos de respaldo, que se puede deshabilitar si se cambia el centro de datos principal. También es posible que usemos la replicación bidireccional. Desde el punto de vista del equipo, nada cambiará.
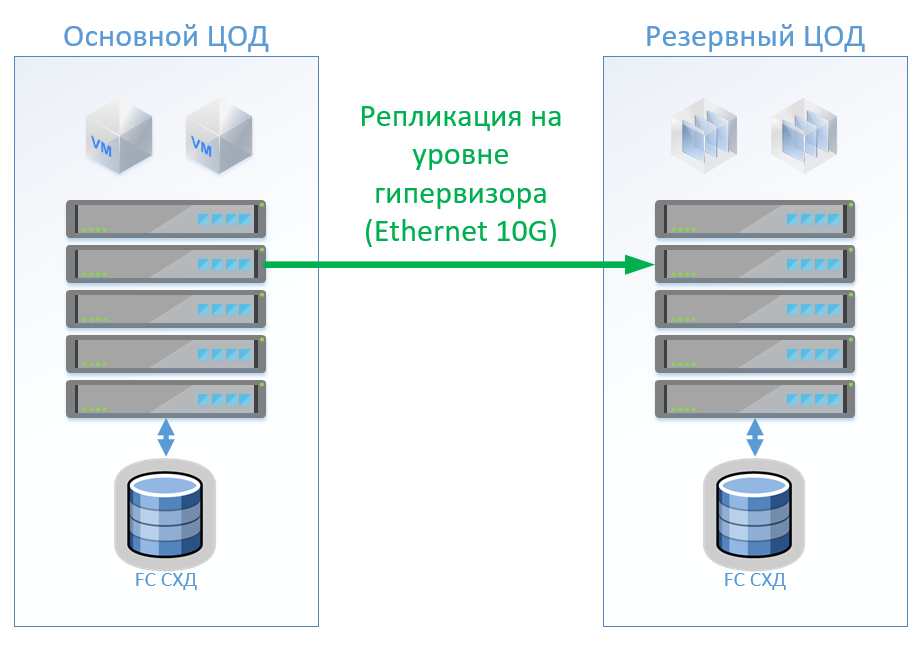
En el caso de la arquitectura clásica, colocaremos un sistema de almacenamiento híbrido en cada centro de datos con acceso a través de FibreChannel, desgarro, deduplicación y compresión (pero no en línea), 8 servidores por sitio, 2 conmutadores FibreChannel y Ethernet 10G. Para el control de replicación y conmutación en una arquitectura clásica, podemos usar herramientas VMware (Replication + SRM) o herramientas de terceros que serán un poco más baratas y, a veces, más convenientes.
La figura muestra un diagrama.
Si usa Cisco HyperFlex, obtiene la siguiente arquitectura:
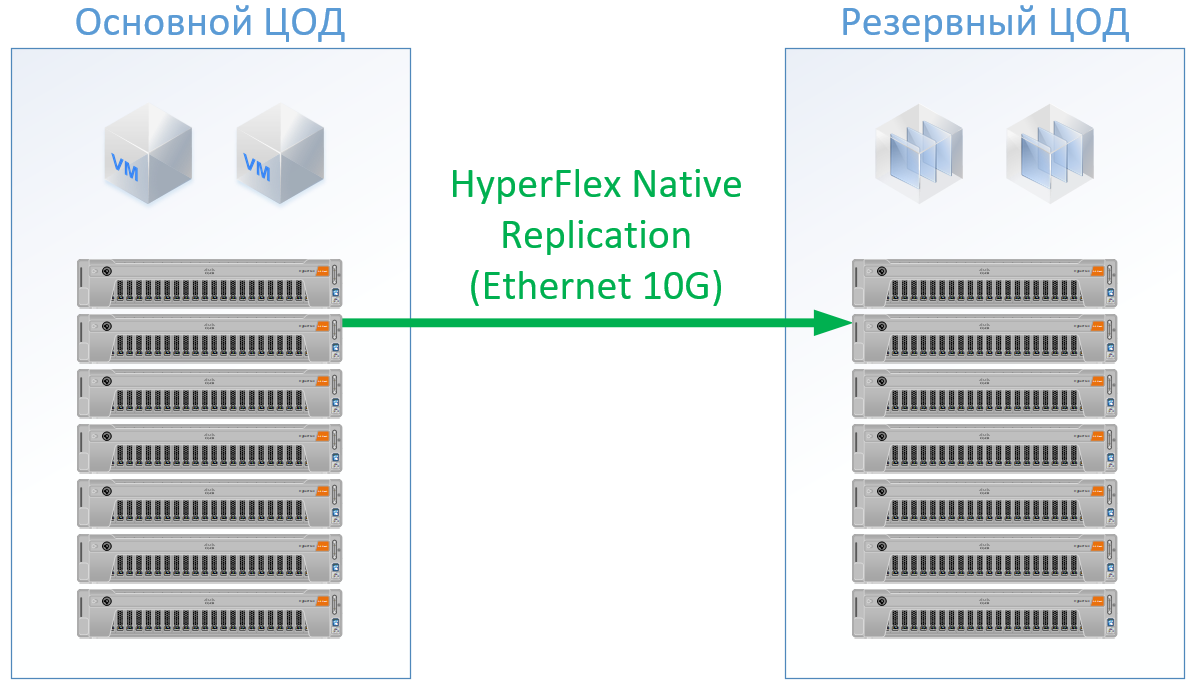
Para HyperFlex, utilicé servidores con grandes recursos de CPU / RAM, como parte de los recursos irán a la VM del controlador HyperFlex, incluso he recargado un poco la configuración de HyperFlex en la CPU y la memoria, para no jugar junto a Cisco y garantizar recursos para el resto de las VM. Pero podemos rechazar los conmutadores FibreChannel, y no necesitamos puertos Ethernet para cada servidor, el tráfico local se conmuta dentro de FI.
El resultado es la siguiente configuración para cada centro de datos:
Para Hyperflex, no prometí licencias de software de replicación, ya que está disponible de forma inmediata con nosotros.
Para la arquitectura clásica, tomé un vendedor que se estableció como un fabricante de calidad y económico. Para ambas opciones utilicé un estándar para un patín de solución específico, a la salida obtuve precios reales.
La solución en Cisco HyperFlex fue un 13% más barata.
Escenario 2: crear dos centros de datos activos. En este escenario, diseñamos un clúster extendido en VMware.
La arquitectura clásica consiste en servidores de virtualización, SAN (protocolo FC) y dos sistemas de almacenamiento que pueden leer y escribir en el que se extiende entre ellos. En cada SHD ponemos una capacidad útil para la cerradura.
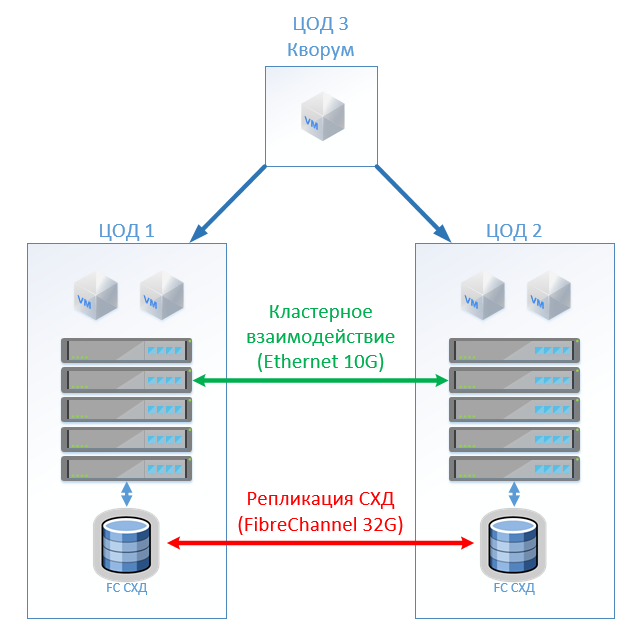
En HyperFlex, simplemente creamos un Stretch Cluster con el mismo número de nodos en ambos sitios. En este caso, se utiliza el factor de replicación 2 + 2.
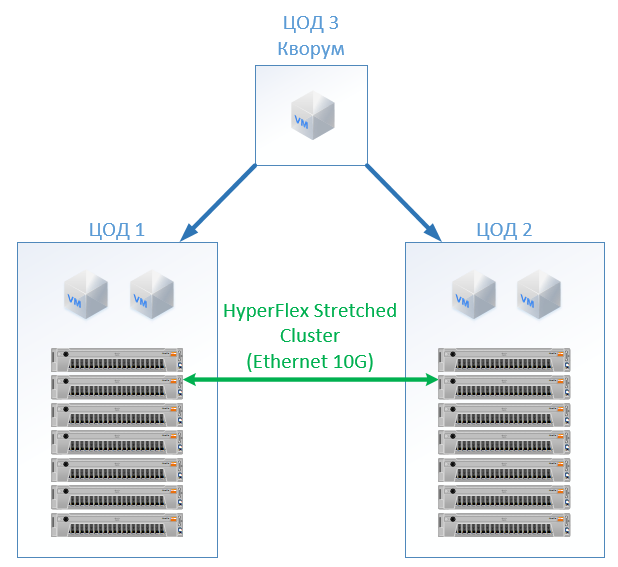
La siguiente configuración ha resultado:
En todos los cálculos, no tomé en cuenta la infraestructura de red, los costos del centro de datos, etc., serán los mismos para la arquitectura clásica y para la solución HyperFlex.
Al costo, HyperFlex resultó ser un 5% más caro. Vale la pena señalar aquí que para los recursos de CPU / RAM, obtuve un sesgo para Cisco, porque en la configuración llenaba los canales de los controladores de memoria de manera uniforme. , , , « », . , Cisco UCS .
SAN , - , (, , — ), ( ), .
, — Cisco. Cisco UCS, , HyperFlex , . , . : « , ?» « - , . !» — , : « » .
Referencias