
Hola Habr! Continuamos publicando reseñas de artículos científicos de miembros de la comunidad Open Data Science del canal #article_essense. Si quieres recibirlos antes que los demás, ¡únete a la comunidad !
Artículos para hoy:
- Ecuaciones diferenciales ordinarias neuronales (Universidad de Toronto, 2018)
- Aprendizaje semi-no supervisado con modelos generativos profundos: agrupamiento y clasificación usando etiquetas ultra dispersas (Universidad de Oxford, The Alan Turing Institute, Londres, 2019)
- Descubriendo y mitigando el sesgo algorítmico a través de la estructura latente aprendida (Massachusetts Institute of Technology, Harvard University, 2019)
- Aprendizaje de refuerzo profundo de las preferencias humanas (OpenAI, DeepMind, 2017)
- Explorando redes neuronales cableadas al azar para el reconocimiento de imágenes (Facebook AI Research, 2019)
- Photofeeler-D3: una red neuronal con modelado de votantes para la calificación de fotos de citas (Photofeeler Inc., 2019)
- MixMatch: un enfoque holístico para el aprendizaje semi-supervisado (Google Reasearch, 2019)
- Divide y conquista el espacio de integración para el aprendizaje métrico (Universidad de Heidelberg, 2019)
Enlaces a colecciones pasadas de la serie: 1. Ecuaciones diferenciales ordinarias neurales
Autores: Ricky TQ Chen, Yulia Rubanova, Jesse Bettencourt, David Duvenaud (Universidad de Toronto, 2018)
→ Artículo original
El autor de la revisión: George Ignatov (en slack a2dy2n7okhtp)
Premio al mejor artículo de NIPS

Los autores del artículo señalaron que las redes tipo ResNet son muy similares al método de Euler para resolver ecuaciones diferenciales. Si es así, ¿por qué no llevar inmediatamente la idea al máximo? Imagine una red neuronal en forma de ecuación diferencial y obtenga
- Una red con un número arbitrario de capas, que se puede cambiar en cualquier momento durante el entrenamiento y la inferencia. Más capas -> más precisión y conversiones más suaves (y viceversa).
- Una cantidad mucho menor de parámetros, por lo tanto, reduce los costos de memoria.
NODO a través de analogías:
- - así es como se ve la definición de salida de la capa n en una red tipo red, parámetros W.
- - Esto se vería como una red de tipo NODE, siempre que n sea una cantidad discreta.
- , - El método de Euler.
- - ta-da! Red neuronal alimentada por ODE.
Lo resolvemos con cualquier ODEsolver de caja negra, arrojamos los gradientes usando el método de sensibilidad adjunto (Pontryagin et al., 1962). Debido a su completa diferenciabilidad, NODE se puede combinar con redes neuronales convencionales. Los autores publicaron el código en pytorch.
El artículo analiza 3 aplicaciones:
- Comparación con la arquitectura similar a ResNet (en MNIST). NODE casi no funciona peor, mientras usa 3 veces menos parámetros.
- Invalidar flujos normalizados a través de NODE: flujos normalizados continuos (conjunto de datos sintéticos). El nuevo modelo reduce los costos de computación de O (n_hidden_units ^ 3) a lineal.
- Modelado de eventos temporales con observaciones irregulares (conjunto de datos sintéticos). Se generó un conjunto de datos de trayectorias espirales a partir del cual los puntos muestreados aleatoriamente se rociaron con: sal: ruido gaussiano para la plausibilidad. Probó el RNN y el NODE habituales, y el segundo nuevamente demostró ser mejor.
En letra pequeña:
- El entrenamiento en minibatch causa algún tipo de sobrecarga computacional, pero los autores argumentan que en la práctica esto es casi invisible.
- Aparecen dos nuevos hiperparámetros: profundidad de red y tolerancia a errores al resolver ODE.
- Para que la solución ODE siga siendo única, la red debe tener pesos finitos y usar no linealidades de Lipshitz, como tanh o relu.
Enlace a una descripción más detallada sobre habr.
2. Aprendizaje semi-no supervisado con modelos generativos profundos: agrupamiento y clasificación usando etiquetas ultra dispersas
Autores del artículo: Matthew Willetts, Stephen Roberts y Christopher Holmes
(Universidad de Oxford, The Alan Turing Institute, Londres, 2019)
→ Artículo original
Autor de la revisión: Alex Chiron (en sliron shiron8bit)
Los autores consideran un caso semi-no supervisado para el problema de clasificación, cuando parte de las clases presentes en el marcado debido al sesgo de selección no se etiquetó en absoluto, y no muchos se etiquetaron de acuerdo con las clases de datos conocidas. Esto crea problemas adicionales, ya que la mayoría de los modelos generalmente funcionan en modo semi-supervisado / supervisado (clasificación) o en modo no supervisado (agrupamiento), y en este caso debemos considerar ambas opciones. Además, el uso de algoritmos semi-supervisados puede llevar al hecho de que los datos no asignados se asignarán de acuerdo con alguna métrica de proximidad a clases incorrectas. Un ejemplo hipotético de tales datos es un conjunto de exploraciones tumorales. Tomamos parte de los datos y marcamos todos los tipos de tumores presentes en esta parte, pero resultó que otros tipos de tumores estaban presentes en los datos restantes, y la variabilidad de las especies conocidas en el marcado no se reflejó completamente.
Los autores se inspiraron en modelos generativos profundos (el ejemplo más simple de un modelo de este tipo con una profundidad de capa única de variables ocultas es un codificador automático variacional, también conocido como VAE): en trabajos anteriores, dichos modelos hicieron frente con éxito tanto al caso semi-supervisado (M2, ADGM) como a la agrupación ( VaDE, GM-VAE).
¿Por qué no resolver 2 problemas al mismo tiempo (aprendizaje semi-supervisado en clases raramente marcadas y sin supervisión en clases no ubicadas), manteniendo el espacio de variables latentes aprendidas en común y combinando ideas de los modelos anteriores? Es esta idea la que subyace a los modelos GM-DGM / AGM-DGM propuestos en el artículo.
Considere el modelo M2 en un caso semi-supervisado. Se llama así, porque bajo M1, el creador implicó entrenamiento secuencial de VAE y algún clasificador (svm) para las representaciones latentes resultantes de z, pero M2 ya se obtiene de VAE al agregar a la capa de variables ocultas la variable y, que es responsable de la clase a veces observada.
,
donde ,
Aquí q es un codificador, p es un decodificador, parte - Clasificador directamente entrenado.
Para el caso no supervisado / semi-no supervisado, M2 no funciona: se produce un colapso posterior, la parte de clasificación q_phi (y | x) colapsa a la distribución a priori p (y). El autor de GM-VAE en su artículo también mostró la inoperancia de M2 en la práctica y señaló que a menudo al implementar M2, la primera capa del decodificador h1 es muy similar a una mezcla de gaussianos.
Con base en esta observación, GM-VAE utiliza una capa explícita de variables ocultas para agrupar una mezcla gaussiana para el agrupamiento, que también es repetida por los autores de este artículo. Por lo tanto, el modelo GM-DGM, que permite una operación exitosa en modo semi-sin supervisión, es una modificación VAE usando una mezcla de gaussianos en una capa oculta, dependiendo de una variable de clase y, con la función anterior de dos términos para contar y maximizar ELBO.
Los autores del artículo realizaron un experimento en una versión semi-no supervisada de Fashion-MNIST: eliminaron las etiquetas de las primeras 5 clases, las 5 clases restantes dejaron el 5% de las etiquetas, mientras que recibieron una precisión total del 77,2% frente al 53% para M2. También se mostró la posibilidad de usar el modelo para la agrupación (lo cual no es sorprendente, porque es casi GM-VAE).
3. Descubriendo y mitigando el sesgo algorítmico a través de la estructura latente aprendida
Autores: Alexander Amini, Ava Soleimany, Wilko Schwarting, Sangeeta N. Bhatia, Daniela Rus (Instituto de Tecnología de Massachusetts, Universidad de Harvard, 2019)
→ Artículo original
Autor de la revisión: Alex Chiron (en sliron shiron8bit)
Recientemente, cada vez más a menudo en los medios de comunicación puede encontrar noticias que tocan el tema del sesgo en los datos, especialmente con respecto a los algoritmos relacionados con las personas, con el crecimiento de su aplicabilidad, el riesgo de un fuerte impacto negativo en esas categorías y grupos de personas que son insuficientes (o excesivas) presentado en conjunto de datos. Uno de los últimos ejemplos es un estudio que mostró menos precisión en la detección de peatones con color de piel oscuro (en el contexto de la detección de objetos en los conjuntos de datos estándar BDD100K y MSCOCO, enlace ). Enfoques básicos para eliminar sesgos:
- Equilibrio de clases mediante remuestreo (requiere una comprensión a priori de la estructura de datos ocultos).
- Generación de datos imparciales (por ejemplo, el uso de GAN para generar individuos con una amplia variedad de tonos de piel ).
- Agrupación y posterior muestreo.
- Todavía puede esperar hasta que el conjunto de datos de IBM Diversity in Faces se presente a los académicos.
Los autores del artículo ofrecen una modificación de VAE y muestreo, teniendo en cuenta la distribución de la variable latente z, que puede reducir la influencia del sesgo en los datos en la etapa de entrenamiento.
Entonces, las ideas principales detrás de DB-VAE son:
- Considere un problema de clasificación en el que tenemos un conjunto de datos de entrenamiento {(x, y)}, x son características m-dimensionales, y son etiquetas d-dimensionales, y nuestra tarea es aproximar el mapeo X-> Y.
- Tomemos VAE, pero además del vector de variables ocultas z de dimensión 2k (recordamos, 2 aquí porque estamos tratando con medias y variaciones), también aprenderemos el codificador de dimensión d, que es responsable de las etiquetas mencionadas anteriormente. En este caso, el decodificador acepta solo el vector z como entrada. Por lo tanto, obtenemos una apariencia de aprendizaje semi-supervisado, donde se aprende parte del modelo para reconstruir la entrada, y parte es para resolver un problema específico (clasificación).
- Controlamos el entrenamiento del modelo debido a la pérdida combinada, combinando el estándar para la pérdida VAE (reconstrucción + divergencia KL) y la pérdida por un problema auxiliar (por ejemplo, entropía cruzada para el problema de clasificación binaria).
- Se presta especial atención al hecho de que necesita controlar la capacitación sobre los datos que no desea eliminar (es decir, no retroceder desde el decodificador).
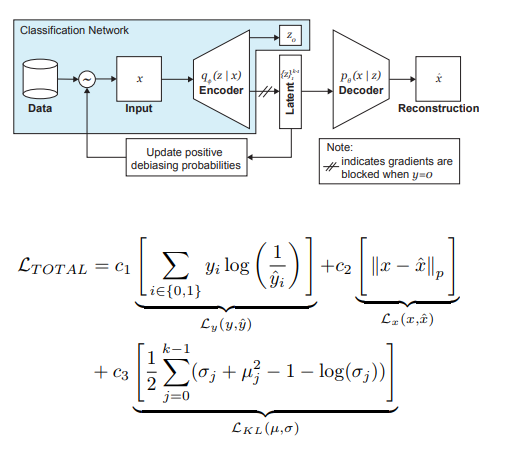
El papel más importante para eliminar el dolor de los negros es el muestreo adaptativo en la etapa de entrenamiento. Queremos elegir muestras raras (desde el punto de vista de algunos factores ocultos, no identificados explícitamente), por lo que recurrimos a los histogramas para cada dimensión del espacio de variables ocultas z, cuyo producto puede aproximarse a la distribución Q (z | X) de datos sobre todo el espacio Z. Al formar un nuevo lote, tendremos en cuenta la distribución 'inversa' a Q (z | X) W (z (x) | X), que determina la probabilidad de elegir un ejemplo en el lote (alfa es un hiperparámetro que determina el grado de desbarbado), actualizando Q (z | X) en cada época. Como puede ver, el desbarbado no está preseleccionado, sino que se basa en las variables latentes aprendidas.
Como experimento, los autores resolvieron el problema de la clasificación binaria (encontrar la cara en la foto). Para la capacitación, recopilamos un conjunto de datos, que consistía en 200 mil personas con CelebA y 200 mil no personas con Imagenet, redimensionamos las imágenes a 64x64. Como se mencionó anteriormente, durante el entrenamiento, se bloqueó la propagación hacia atrás desde el decodificador para fotos sin caras (y = 0). Después del entrenamiento, fueron validados en el Benchmark de Parlamentos Pilotos (PPB) (1270 fotos de personas de los parlamentos de Sudáfrica, Ruanda, Senegal, Suecia, Finlandia, Islandia): para todos los alfa> 0, la precisión de detección en las categorías hombre oscuro, mujer oscura, mujer ligera aumentó en comparación con opción sin debiasing.
4. Aprendizaje de refuerzo profundo de las preferencias humanas.
Autores: Paul Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, Dario Amodei (OpenAI, DeepMind, 2017)
→ Artículo original
Autor de la revisión: Dmitry Nikulin (en dniku slack)
Este artículo trata sobre cómo implementar la vieja idea en el contexto del aprendizaje de refuerzo profundo (RL). Idea: pidamos a una persona que evalúe el comportamiento de un agente, y en base a esto aprenderemos la función de recompensa. El problema es que el RL profundo es muy voraz y el tiempo humano es costoso. El artículo proporciona un conjunto de hacks que le permiten reducir las horas humanas a valores razonables.
La función de recompensa es una función en pares (observación, acción). Se establece promediando la predicción de un conjunto de redes neuronales. Los algoritmos RL utilizados (en el artículo A2C para Atari y TRPO para Mujoco) creen que este promedio es una verdadera recompensa, y están entrenados en ello. Por lo tanto, el artículo se centra en el tema de la formación de este conjunto.
El conjunto está capacitado en evaluaciones humanas. Cada calificación está estructurada de la siguiente manera. A una persona se le muestran dos videos de un agente de 1-2 segundos de duración. Puede calificar ese par de 4 maneras: izquierda es mejor / derecha es mejor / demasiado similar / incomparable. Si una persona dijo "incomparable", esa evaluación se descarta. De lo contrario, se recuerda el triple (σ¹, σ², μ), donde σⁱ es la trayectoria del agente en el video correspondiente (es decir, la lista de pares (obs, act)), y μ es el par (1, 0), (0, 1 ) o (½, ½). Además, se cree que la predicción de la recompensa por la trayectoria es igual a la suma de las predicciones para cada par (obs, acto). Finalmente, simplemente optimizamos softmax_cross_entropy_with_logits.
Se cree que una persona con una probabilidad del 10% selecciona una respuesta aleatoria, y esto se tiene en cuenta al construir una muestra de entrenamiento. La sección 2.2.3 del artículo ofrece algunos trucos más y escribe todas las fórmulas.
Los pares de clips para la demostración a una persona se seleccionan de la siguiente manera: se muestrea un gran número de clips, se considera la dispersión del conjunto en ellos y se muestran pares aleatorios de clips con alta dispersión a las personas. Los autores dicen que me gustaría elegir según el valor de la información, pero este es un trabajo futuro.
Los autores realizan pruebas en Atari y Mujoco, con calificaciones reales en humanos (contratistas contratados) y sintéticas (las calificaciones se generan de acuerdo con la verdadera función de recompensa), y al mismo tiempo se comparan con el RL habitual. Con un número de calificaciones aproximadamente igual, las pruebas sintéticas y reales funcionan de manera similar. Además, sorprendentemente, el RL regular (que ve la verdadera función de recompensa) no necesariamente funciona mejor.
Finalmente, además de tratar de entrenar al agente para obtener una gran recompensa en el sentido habitual, el artículo también da ejemplos de otras dos tareas: el Hopper en Mujoco hace un volteo hacia atrás, y la máquina en Atari Enduro no adelanta a otros autos, sino que viaja paralelamente a ellos. Resultó resolver ambos problemas.
En conclusión: el ejemplo describe un intento de reproducir este artículo. El intento fue exitoso, pero tomó 8 meses de trabajo en tiempo libre y 220 horas de tiempo puro, de los cuales la mitad fue a depurar la versión más simple.
5. Explorando redes neuronales cableadas al azar para el reconocimiento de imágenes
Autores: Saining Xie, Alexander Kirillov, Ross Girshick, Kaiming He (Facebook AI Research, 2019)
→ Artículo original
Autor de la revisión: Egor Panfilov (en slack tutk1ja)
Introducción
El trabajo plantea la cuestión de generar arquitectura de redes neuronales. Actualmente, se conocen muchos trucos arquitectónicos (LSTM, Inception, ResNet, DenseNet), que pueden mejorar la calidad de muchas tareas, pero también introducen una cierta arquitectura previa sólida en el modelo. En lugar de las soluciones mencionadas, Google está avanzando con su búsqueda de arquitectura neuronal (NAS), donde la búsqueda de arquitectura para una tarea específica se lleva a cabo desde módulos predefinidos a través de RL - NASNet, AmoebaNet.
Los autores argumentan que ambos enfoques donde el diseño está determinado por el hombre y NAS introducen demasiado estricto antes de la arquitectura. En un intento por reducirlo, intentan utilizar el enfoque generativo paramétrico de la red neuronal, donde el cableado (conexión) de los elementos se realiza de forma aleatoria. Resulta que los enfoques de cableado aleatorio han sido explorados desde la década de 1940 por científicos como A. Turing, M. Minsky, F. Rosenblatt. Como un argumento más, los autores recuerdan que en estudios neurocientíficos se reveló que la estructura de las conexiones neuronales en los organismos de una especie es diferente (hasta cierto nivel de detalle, por supuesto). Esto es cierto tanto para los gusanos como para los bebés humanos. En general, la idea de la generación procesal de redes neuronales suena interesante y prometedora, de eso se trata el trabajo.
Método:
Intentemos modularizar el proceso de generación de procedimientos de arquitectura de redes neuronales a través de un enfoque gráfico. Los pasos iniciales son los siguientes:
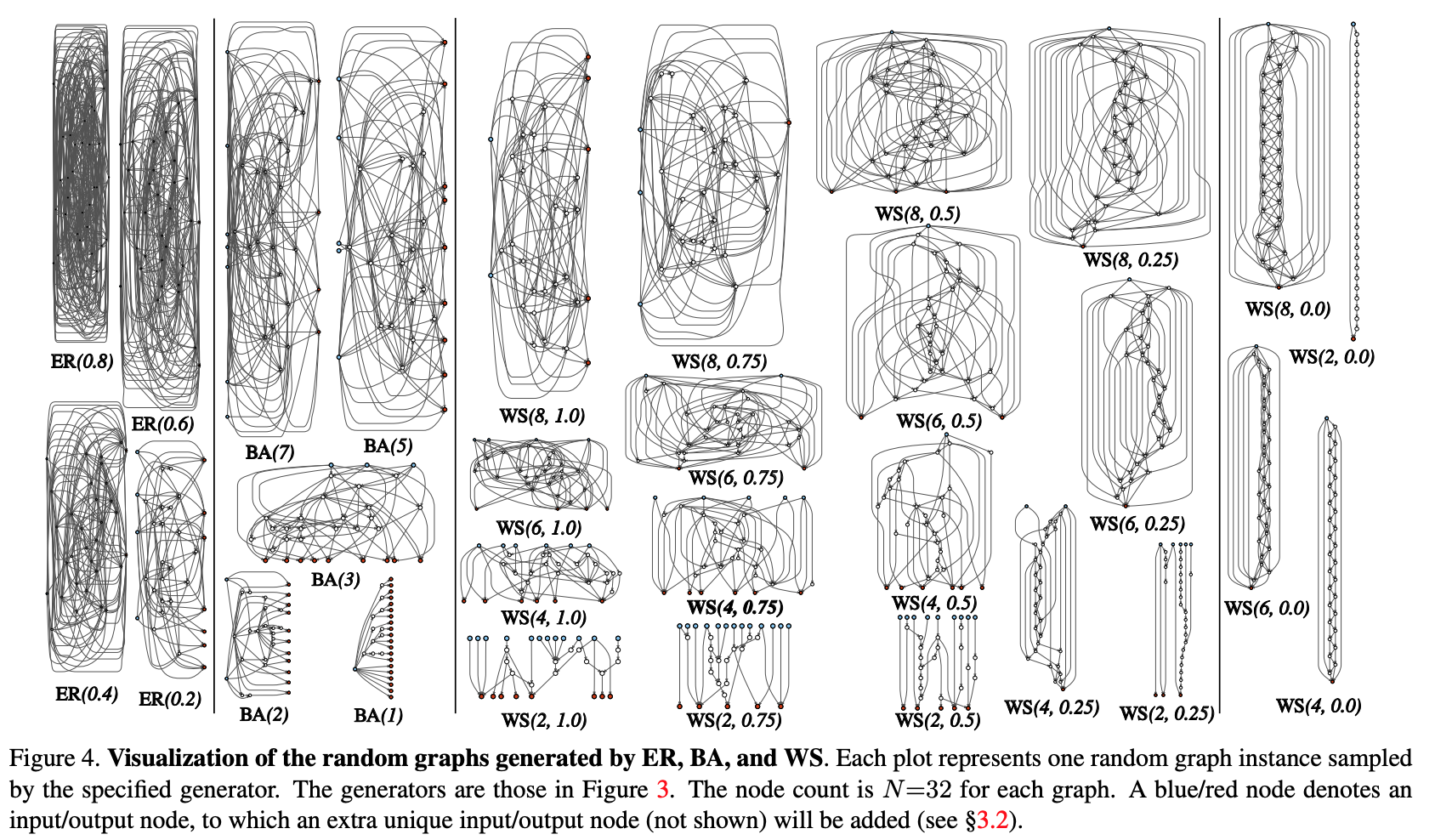
- Se genera un gráfico estocástico a partir de una familia parametrizada. Se utilizan métodos clásicos: Erdos-Renyi (ER), Barabasi-Albert (BA) y Watts-Strogatz (WS).
- El gráfico se convierte en una red neuronal:
- se supone que todos los bordes del gráfico son portadores dirigidos de tensores de datos;
- para cada vértice del gráfico, se determina el tipo de operación que realiza: (I) agregación sumando con los pesos entrenados, (II) transformación - ReLU + convolución + BN, (III) distribución - transferencia del tensor a lo largo de cada borde de salida;
- De acuerdo con los resultados de la subcláusula anterior, puede haber varios vértices de entrada y salida, pero quiero tener 1 punto de entrada en el gráfico y 1 punto de salida. Dichos nodos se crean por separado. La entrada simplemente extiende una copia del tensor a todos los vértices de entrada del gráfico, la salida considera el promedio no ponderado de todos los vértices de salida. Como resultado de los pasos 1 y 2, de hecho, no se crea una red completa, sino solo uno de los módulos (como conv_1, ... en popular codificadores convolucionales). Para obtener la red neuronal por completo:
- Se crean y conectan varios módulos en serie. Para reducir el número de parámetros de red, las transformaciones en todos los vértices de entrada de los módulos se realizan con un paso de 2x2. El número de canales en la transición al siguiente módulo aumenta en 2 veces. Para realizar experimentos en una tarea específica:
- En la salida de la red, se agrega un encabezado para la clasificación.
Resultados:
Las pruebas del método se llevaron a cabo en el problema de clasificación en ImageNet. La calidad de la red neuronal generada resultó estar a la par con las arquitecturas SotA, perdiendo un poco con respecto al reciente DeepBrain AmoebaNet de Google: (con un número comparable de parámetros).
Verificamos qué sucedería si eliminamos un vértice / borde aleatorio del gráfico resultante. Métrica: reducción de la calidad según el número adyacente de bordes de salida / vértices de entrada, respectivamente. En general, la calidad está disminuyendo, pero no es crítica.
Los autores también verificaron si el aprendizaje por transferencia funciona con esta arquitectura. En la tarea de detección de COCO, el backbone Faster R-CNN con FPN fue reemplazado por una red generada y pre-entrenada. Los resultados mostraron que la calidad del modelo no es peor que la de ResNeXt-50 / -101. Pero incluso el hecho de que el aprendizaje de transferencia está comenzando es bastante entretenido.
6. Photofeeler-D3: una red neuronal con modelado de votantes para la calificación de fotos de citas
Autores del artículo: Agastya Kalra y Ben Peterson (Photofeeler Inc., 2019)
→ Artículo original
Autor de la revisión: Alex Chiron (en sliron shiron8bit)
Los autores sugieren Photofeeler-D3: una arquitectura de red para evaluar fotos de sitios de citas en 3 direcciones / rasgos: cuán inteligente parece una persona, confiable y atractiva (¡descuide el efecto de halo!). La tarea surgió en base a una encuesta realizada por The Guardian, según la cual el 90% de las personas deciden una fecha futura únicamente sobre la base de evaluar fotos de un satélite potencial
Entonces, la red consta de los siguientes bloques:
- ( ) — (GAP ), 10 ( ) — temporary output.
- ( , voter model) - (voter), , temporary output , , 10 v_ij (( 10 [0;1]). v_ij [0.05, 0.15, 0.25...0.95].
- , 200 , .
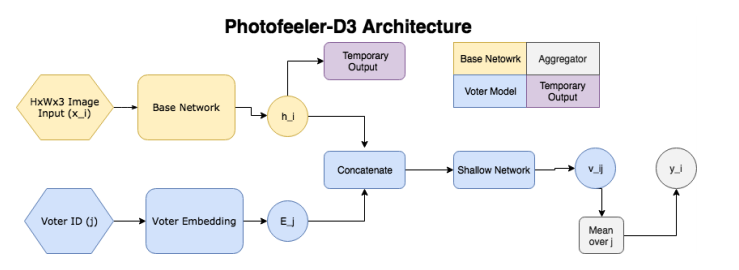
, , , , . Facial Beauty Prediction (FBP) SCUT-FBP Hot-Or-Not, , Photofeeler, . : +100k , 1.2 , (200 ) 200 (50 ). , 600px. 10000 8000 . , 0 3, [0,1] ( , ).
:
- (backbone , , etc) (20000 train, 3000 val, 2311 test), xception 600x600.
- , (temporary output) KL- ( , , 10 [0,1]).
- voter model one-hot .
- voter' , 2 .
- trait' 2 , .:
- ~80% , London Faces , prettyscale.com hotness.ai (81 53 52).
- FBP (SCUT-FBP Hot-Or-Not) , SOTA.
- , , 10
7. MixMatch: A Holistic Approach to Semi-Supervised Learning
: D. Berthelot, N. Carlini, IJ Goodfellow, N. Papernot, A. Oliver and Colin Raffel (Google Reasearch, 2019)
→
: ( JanRocketMan)
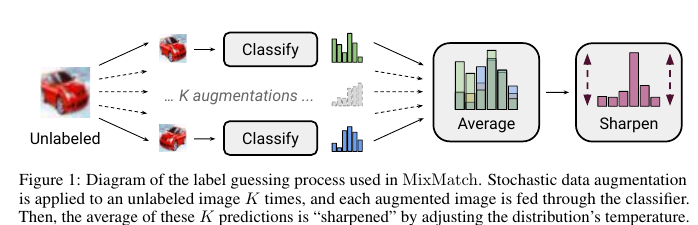
MeanTeacher Mixup- SOT- Semi-Supervised Learning (SSL) . , SSL consistency regularization. , ( ) "" , . Mean Teacher ( — c EMA ), — Mixup ( ). , . :
- unsupervised , .
"" p. - "" , one-hot. : . T , , , ( ), .
- , . , SVHN, STL CIFAR10.
CIFAR10 90% accuracy 250 . — VAT, 60%. SVHN - 96% 250- , VAT Mean Teacher 90.
STL10 90% 1 , - CCGAN, 80. , :
- , ( );
- GridSearch- ;
c. SSL SVHN .
8. Divide and Conquer the Embedding Space for Metric Learning
: Artsiom Sanakoyeu, Vadim Tschernezki, Uta Buchler and Bjorn Ommer (Heidelberg University, 2019)
→
: ( Alexander Denisenko)
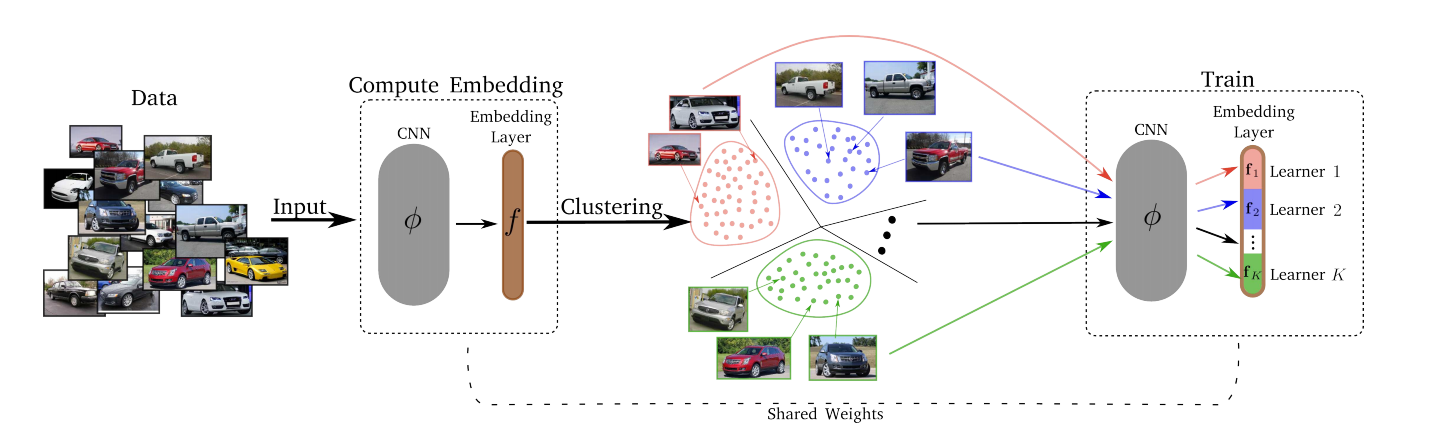
— , . , , – , , , ..
, :
- Divide.
- k-means. . . Embedding layer K . – . d/K (d – ). - Conquer.
Divide K K . , , , -, , . , T (Divide) . - Merjim: concatenamos todos los Lerners (cortes de la capa de incrustación). Luego entrenamos la capa de incrustación en todo el conjunto de datos para hacer que los Lerners sean amigos.
Resultados experimentales: todos ganaron en varios conjuntos de datos.
La pérdida puede ser cualquier cosa: pérdida de triplete, pérdida de margen, proxy-NCA, etc.
El número óptimo de K Lerners resultó ser 8 (la dimensión de todo el espacio de incrustación fue 128, de modo que cada Lerner resolvió su subtarea en un espacio de 16 dimensiones).
Un cambio en T de 1 a 10 no afectó significativamente nada, por lo que se utilizó T = 2.