Presentamos una exhaustiva hoja de trucos donde contamos en palabras simples lo que la inteligencia artificial "hace" y cómo funciona todo.
¿Cuál es la diferencia entre inteligencia artificial, aprendizaje automático y ciencia de datos?
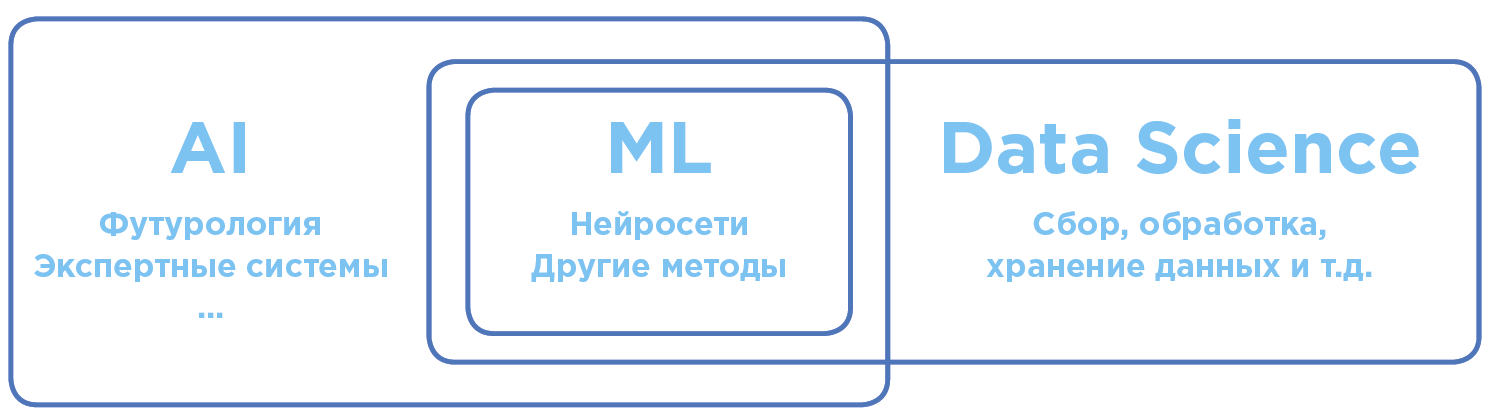 Diferenciación de conceptos en el campo de la inteligencia artificial y el análisis de datos.
Diferenciación de conceptos en el campo de la inteligencia artificial y el análisis de datos.Inteligencia Artificial - AI (Inteligencia Artificial)
En el sentido universal global, AI es el término lo más amplio posible. Incluye tanto teorías científicas como prácticas tecnológicas específicas para crear programas cercanos a la inteligencia humana.
Machine Learning - ML (Machine Learning)
Sección AI, aplicada activamente en la práctica. Hoy, cuando se trata de usar IA en los negocios o la fabricación, a menudo nos referimos a Machine Learning.
Los algoritmos de ML, como regla, funcionan según el principio de un modelo matemático de aprendizaje que realiza el análisis sobre la base de una gran cantidad de datos, mientras que las conclusiones se extraen sin seguir reglas rígidamente definidas.
El tipo de tarea más común en el aprendizaje automático es aprender con un maestro. Para resolver este tipo de problemas, la capacitación se utiliza en una serie de datos para los cuales se conoce de antemano la respuesta (ver más abajo).
Ciencia de datos - DS (Ciencia de datos)
La ciencia y la práctica de analizar grandes cantidades de datos utilizando todo tipo de métodos matemáticos, incluido el aprendizaje automático, así como la resolución de tareas relacionadas con la recopilación, el almacenamiento y el procesamiento de matrices de datos.
Los científicos de datos son expertos en datos, en particular, que analizan mediante el aprendizaje automático.

¿Cómo funciona el aprendizaje automático?
Considere el trabajo de ML sobre el ejemplo de la tarea de puntuación bancaria. El Banco tiene datos sobre clientes existentes. Él sabe si alguien tiene pagos de préstamos vencidos. La tarea es determinar si un nuevo cliente potencial realizará los pagos a tiempo. Para cada cliente, el banco tiene una combinación de ciertos rasgos / características: género, edad, ingresos mensuales, profesión, lugar de residencia, educación, etc. Entre las características pueden estar parámetros mal estructurados, como datos de redes sociales o historial de compras. Además, los datos pueden enriquecerse con información de fuentes externas: tipos de cambio, datos de oficinas de crédito, etc.
Una máquina ve a cualquier cliente como una combinación de características:
. Donde por ejemplo
- edad
- ingresos, y
- la cantidad de fotos de compras caras por mes (en la práctica, como parte de una tarea similar, Data Scientist trabaja con más de cien funciones). Cada cliente tiene una variable más:
con dos resultados posibles: 1 (hay pagos atrasados) o 0 (sin pagos atrasados).
Totalidad de todos los datos.
y
- hay un conjunto de datos. Con estos datos, Data Scientist crea un modelo.
, seleccionando y modificando el algoritmo de aprendizaje automático.
En este caso, el modelo de análisis se ve así:
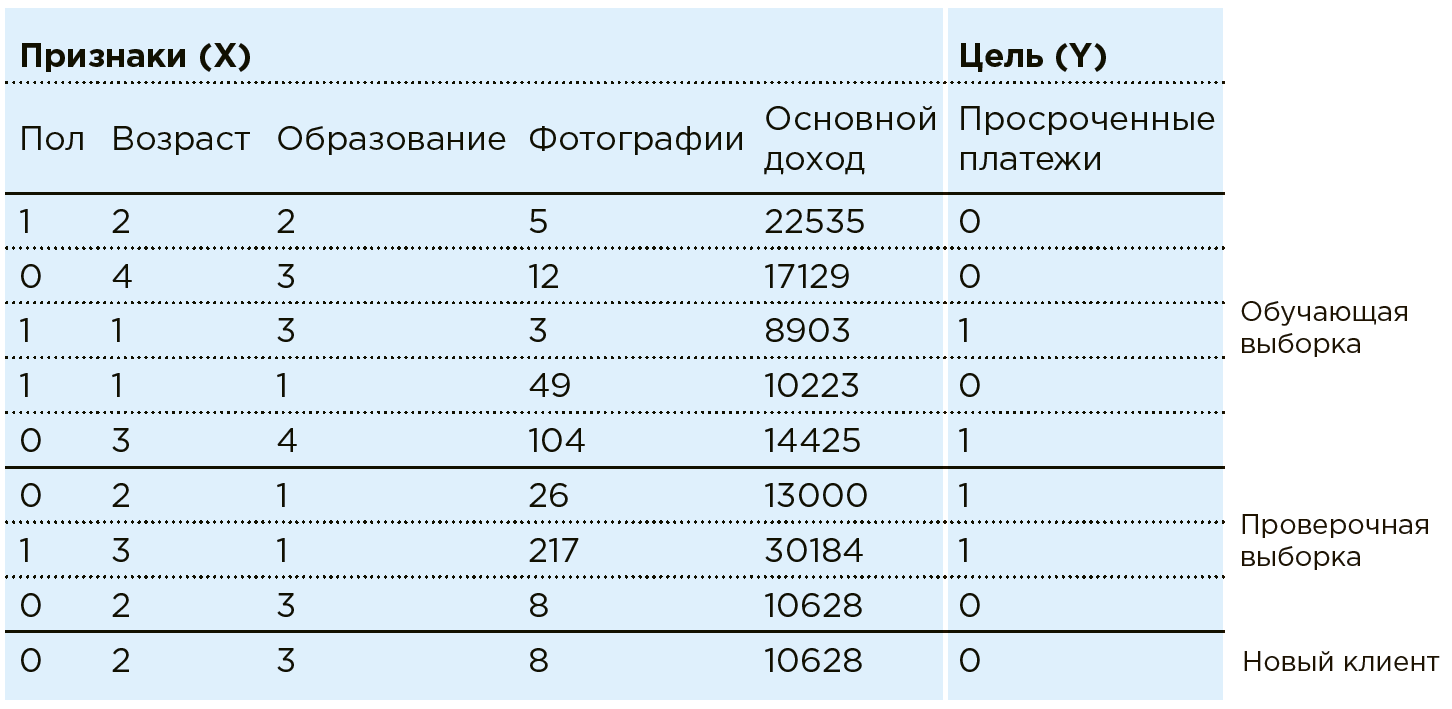
Los algoritmos de aprendizaje automático implican una aproximación por fases de las respuestas del modelo.
a las respuestas verdaderas (que se conocen de antemano en el Conjunto de datos de entrenamiento). Esto es entrenar con un maestro en una muestra particular.
En la práctica, con mayor frecuencia la máquina aprende solo en una parte de la matriz (80%), utilizando el resto (20%) para verificar la corrección del algoritmo seleccionado. Por ejemplo, un sistema se puede entrenar en una matriz de la que se excluyen los datos de un par de regiones, en el que se verifica la precisión del modelo después.
Ahora, cuando un nuevo cliente llega al banco, según el cual
el banco aún no se conoce, el sistema le dirá la confiabilidad del pagador en función de los datos conocidos sobre él
.
Sin embargo, enseñar con un maestro no es la única clase de problemas que ML puede resolver.
Otra gama de tareas es la agrupación, que puede separar objetos de acuerdo con sus atributos, por ejemplo, para identificar diferentes categorías de clientes para que puedan hacer ofertas individuales.
Además, con la ayuda de algoritmos ML, se resuelven tareas como modelar la comunicación de un especialista de soporte o crear obras de arte indistinguibles de las creaciones humanas (por ejemplo, las redes neuronales pintan imágenes).
Una nueva y popular clase de tareas es el entrenamiento de refuerzo, que se lleva a cabo en un entorno limitado que evalúa las acciones de los agentes (por ejemplo, usando este algoritmo, se creó AlphaGo que derrotó a la persona en Go).

Red neuronal
Uno de los métodos de aprendizaje automático. Un algoritmo inspirado en la estructura del cerebro humano, que se basa en las neuronas y las conexiones entre ellas. En el proceso de aprendizaje, las conexiones entre las neuronas se ajustan de tal manera que se minimizan los errores de toda la red.
Una característica de las redes neuronales es la presencia de arquitecturas adecuadas para casi cualquier formato de datos: redes neuronales convolucionales para analizar imágenes, redes neuronales recurrentes para analizar textos y secuencias, codificadores automáticos para compresión de datos, redes neuronales generativas para crear nuevos objetos, etc.
Al mismo tiempo, casi todas las redes neuronales tienen una limitación significativa: para su entrenamiento, se necesita una gran cantidad de datos (órdenes de magnitud mayores que el número de conexiones entre neuronas en esta red). Debido al hecho de que recientemente los volúmenes de datos listos para el análisis han crecido significativamente, el alcance también está creciendo. Con la ayuda de las redes neuronales de hoy, por ejemplo, se resuelven las tareas de reconocimiento de imágenes, como determinar la edad y el género de una persona a partir de un video, o tener un casco en el trabajador.
Interpretación del resultado.
La sección Ciencia de datos, que permite comprender las razones para elegir una u otra solución según el modelo ML.
Hay dos áreas principales de investigación:
- Estudiar el modelo como una caja negra. Analizando los ejemplos cargados en él, el algoritmo compara las características de estos ejemplos y las conclusiones del algoritmo, sacando conclusiones sobre la prioridad de cualquiera de ellos. En el caso de las redes neuronales, generalmente se usa una caja negra.
- Estudiar las propiedades del modelo en sí. El estudio de las características que utiliza el modelo para determinar el grado de su importancia. La mayoría de las veces se aplica a algoritmos basados en el método del árbol de decisión.
Por ejemplo, al pronosticar defectos en la producción, signos de objetos
- Estos son los datos sobre la configuración de las máquinas, la composición química de las materias primas, los indicadores de los sensores, el video del transportador, etc. Y las respuestas
- Estas son las respuestas a la pregunta de si habrá un matrimonio o no.
Naturalmente, la producción está interesada no solo en el pronóstico del matrimonio en sí, sino también en la interpretación del resultado, es decir, las razones del matrimonio para su posterior eliminación. Esto puede ser una larga ausencia de mantenimiento de la máquina, la calidad de las materias primas o simplemente lecturas anormales de algunos sensores a los que el tecnólogo debe prestar atención.
Por lo tanto, en el marco del proyecto para el pronóstico del matrimonio en la producción, no solo se debe crear un modelo ML, sino que también se debe trabajar para interpretarlo, es decir, para identificar los factores que afectan el matrimonio.

¿Cuándo es efectivo el aprendizaje automático?
Cuando hay un gran conjunto de datos estadísticos, pero es imposible o muy laborioso encontrar dependencias utilizando métodos matemáticos clásicos o expertos. Entonces, si hay más de mil parámetros en la entrada (entre los cuales hay tanto numéricos como de texto, así como video, audio e imágenes), entonces es imposible encontrar la dependencia del resultado en ellos sin una máquina.
Por ejemplo, además de las sustancias mismas que entran en la interacción, una reacción química está influenciada por muchos parámetros: temperatura, humedad, material del recipiente en el que se produce, etc. Es difícil para un químico tener en cuenta todos estos signos para calcular con precisión el tiempo de reacción. Lo más probable es que tenga en cuenta varios parámetros clave y se basará en su experiencia. Al mismo tiempo, en función de los datos de las reacciones anteriores, el aprendizaje automático podrá tener en cuenta todas las señales y ofrecer un pronóstico más preciso.
¿Cómo se relacionan el Big Data y el aprendizaje automático?
Para construir modelos de aprendizaje automático, en diferentes casos, se requieren datos numéricos, textuales, fotográficos, de video, de audio y otros. Para almacenar y analizar esta información, hay toda un área de tecnología: Big Data. Para un análisis y almacenamiento de datos óptimos, crean "Data Lake": almacenamiento distribuido especial para grandes volúmenes de información mal estructurada basada en tecnologías de Big Data.
Doble digital como pasaporte electrónico
Un doble digital es una copia virtual de un objeto material real, proceso u organización, que le permite simular el comportamiento del objeto / proceso estudiado. Por ejemplo, puede ver preliminarmente los resultados de los cambios en la composición química en la fábrica después de los cambios en la configuración de las líneas de producción, los cambios en las ventas después de una campaña publicitaria con ciertas características, etc. incluidos los métodos de aprendizaje automático.
¿Qué se necesita para un aprendizaje automático de calidad?
Data Scientiest! Son ellos quienes crean el algoritmo de pronóstico: estudian los datos disponibles, presentan hipótesis, construyen modelos basados en el Conjunto de Datos. Deben tener tres grupos principales de habilidades: alfabetización en TI, conocimiento matemático y estadístico, y experiencia sustantiva en un campo particular.
El aprendizaje automático se basa en tres pilares.
Recuperación de datosSe pueden utilizar datos de sistemas relacionados: horario de trabajo, plan de ventas. Los datos también pueden enriquecerse con fuentes externas: tipos de cambio, clima, calendario de vacaciones, etc. Es necesario desarrollar una metodología para trabajar con cada tipo de datos y pensar a través de una tubería para convertirlos en un formato de modelo de aprendizaje automático (un conjunto de números).
CaracterizaciónSe lleva a cabo junto con expertos del campo requerido. Esto ayuda a calcular los datos que son adecuados para fines de pronóstico: estadísticas y cambios en el número de ventas durante el último mes para el pronóstico del mercado.
Modelo de aprendizaje automáticoEl científico de datos elige el método para resolver este problema comercial de forma independiente en función de su experiencia y las capacidades de varios modelos. Para cada tarea específica, debe elegir un algoritmo separado. La velocidad y la precisión del resultado del procesamiento de datos de origen dependen directamente del método seleccionado.
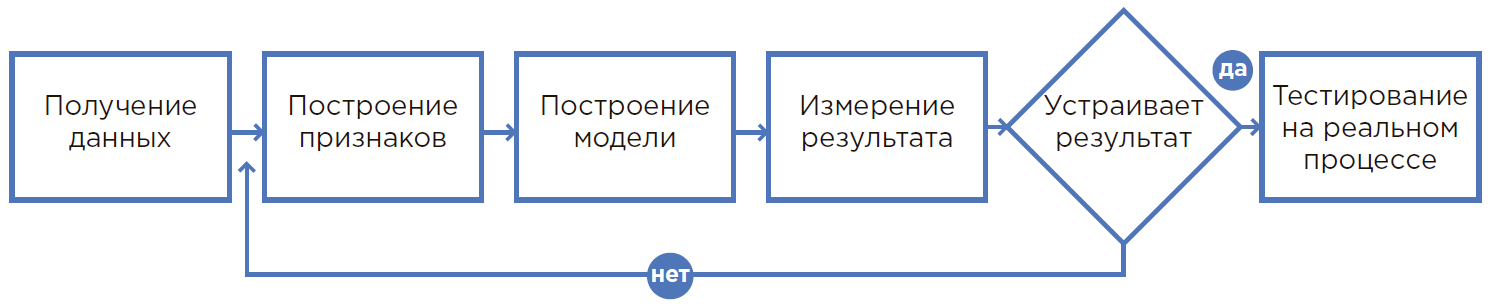 El proceso de crear un modelo de ML.
El proceso de crear un modelo de ML.De la hipótesis al resultado
1. Todo comienza con una hipótesis
Nace una hipótesis al analizar el proceso del problema, la experiencia de los empleados o con una nueva mirada a la producción. Por lo general, una hipótesis afecta un proceso en el que una persona es físicamente incapaz de tener en cuenta muchos factores y utiliza redondeos, suposiciones o simplemente hace lo que siempre hizo.
En este proceso, el uso del aprendizaje automático le permite utilizar significativamente más información al tomar decisiones, por lo tanto, es posible lograr resultados significativamente mejores. Además, la automatización de los procesos que utilizan ML y la reducción de la dependencia de una persona específica minimizan significativamente el factor humano (enfermedad, baja concentración, etc.).
2. Valoración de la hipótesis.
En base a la hipótesis formulada, se seleccionan los datos necesarios para el desarrollo de un modelo de aprendizaje automático. Se realiza una búsqueda de los datos relevantes y se determina una evaluación de su idoneidad para incorporar el modelo en los procesos actuales, quiénes serán sus usuarios y por qué se logra el efecto. Si es necesario, se realizan cambios organizativos y de cualquier otro tipo.
3. El cálculo del efecto económico y el retorno de la inversión (ROI)
La evaluación del efecto económico de la solución implementada es llevada a cabo por especialistas en conjunto con los departamentos relevantes: eficiencia, finanzas, etc. En esta etapa, debe comprender cuál es exactamente la métrica (número de clientes correctamente identificados / aumento en la producción / ahorro de consumibles, etc.) y articula claramente la meta medida.
4. La formulación matemática del problema.
Después de comprender el resultado del negocio, es necesario cambiarlo al plano matemático para definir métricas de medición y restricciones que no puedan ser violadas. Datos etapas datos
Un científico actúa en conjunto con un cliente comercial.
5. Recopilación y análisis de datos.
Es necesario recopilar datos en un solo lugar, analizarlos, considerar varias estadísticas, comprender la estructura y las relaciones ocultas de estos datos para formar signos.
6. Crear un prototipo
Es, de hecho, una prueba de hipótesis. Esta es una oportunidad para construir un modelo sobre los datos actuales e inicialmente verificar los resultados de su trabajo. Por lo general, se realiza un prototipo sobre los datos existentes sin desarrollar integraciones y trabajar con una transmisión en tiempo real.
La creación de prototipos es una forma rápida y económica de verificar si se está resolviendo un problema. Esto es muy útil cuando es imposible comprender de antemano si será posible lograr el efecto económico deseado. Además, el proceso de creación de un prototipo le permite evaluar mejor el alcance y los detalles del proyecto para implementar la solución, a fin de preparar una justificación económica para dicha implementación.
DevOps y DataOps
Durante el funcionamiento, puede aparecer un nuevo tipo de datos (por ejemplo, aparecerá otro sensor en la máquina o aparecerá un nuevo tipo de productos en el almacén) y luego el modelo debe ser entrenado. DevOps y DataOps son metodologías que ayudan a establecer la colaboración y los procesos integrales entre los equipos de Data Science, los ingenieros de preparación de datos, los servicios de desarrollo y operación de TI, y ayudan a que esas adiciones formen parte del proceso actual rápidamente, sin errores y sin resolver cada vez que sea único. problemas
7. Creando una solución
En ese momento, cuando los resultados del prototipo demuestran un logro seguro de los indicadores, se crea una solución completa donde el modelo de aprendizaje automático es solo un componente de los procesos estudiados. A continuación, integración, instalación del equipo necesario, capacitación del personal, cambios en los procesos de toma de decisiones, etc.
8. Operación piloto e industrial.
Durante la operación de prueba, el sistema funciona en el modo de asesoramiento, mientras que el especialista todavía repite las acciones habituales, cada vez que brinda comentarios sobre las mejoras necesarias para el sistema y aumenta la precisión de los pronósticos.
La parte final es la operación industrial, cuando los procesos establecidos cambian a un mantenimiento totalmente automático.
Puede descargar la hoja de trucos desde el
enlace .
Mañana en el foro sobre sistemas de inteligencia artificial
RAIF 2019 a las 09:30 - 10:45 habrá una mesa redonda: "IA para las personas: entendemos en palabras simples".
En esta sección, en un formato de debate, los oradores explicarán tecnologías complejas con palabras simples sobre ejemplos de la vida. Y también discuta sobre los siguientes temas:
- ¿Cuál es la diferencia entre inteligencia artificial, aprendizaje automático y ciencia de datos?
- ¿Cómo funciona el aprendizaje automático?
- ¿Cómo funcionan las redes neuronales?
- ¿Qué se necesita para un aprendizaje automático de calidad?
- ¿Qué es el marcado, el etiquetado de datos?
- ¿Qué es un doble digital y cómo trabajar con copias virtuales de objetos materiales reales?
- ¿Cuál es la esencia de la hipótesis? ¿Cómo pasar de la forma en que se plantea a la evaluación e interpretación del resultado?
A la discusión asisten:
Nikolay Marine, Director de Tecnología, IBM en Rusia y la CEI
Alexey Natekin, Fundador, Open Data Science x Data Souls
Alexey Hakhunov, CTO, Dbrain
Evgeny Kolesnikov, Director, Centro de Aprendizaje Automático, Jet Infosystems
Pavel Doronin, CEO, AI Today
La discusión estará disponible en
el canal de YouTube de Jet Infosystems a fines de octubre.