
En 2017, ganamos la competencia para el desarrollo del núcleo de transacciones para el negocio de inversión de Alfa-Bank y comenzamos a trabajar de inmediato. (Vladimir Drynkin, líder del equipo de desarrollo de Investment Business Transaction Core de Alfa-Bank,
habló sobre el núcleo de negocios de inversión en HighLoad ++ 2018). Se suponía que este sistema debía agregar datos de transacciones en diferentes formatos de varias fuentes, unificar los datos, guardarlos y Proporcionar acceso a ella.
En el proceso de desarrollo, el sistema evolucionó y amplió sus funciones. En algún momento, nos dimos cuenta de que creamos algo mucho más que un simple software de aplicación diseñado para un alcance bien definido de tareas: creamos un sistema para construir aplicaciones distribuidas con almacenamiento persistente. Nuestra experiencia sirvió de base para el nuevo producto,
Tarantool Data Grid (TDG).
Quiero hablar sobre la arquitectura TDG y las soluciones que desarrollamos durante el desarrollo. Presentaré las funciones básicas y mostraré cómo nuestro producto podría convertirse en la base para construir soluciones llave en mano.
En términos de arquitectura, dividimos el sistema en
roles separados. Cada uno de ellos es responsable de una gama específica de tareas. Una instancia en ejecución de una aplicación implementa uno o más tipos de roles. Puede haber varios roles del mismo tipo en un clúster:
Conector
El conector es responsable de la comunicación con el mundo exterior; está diseñado para aceptar la solicitud, analizarla y, si tiene éxito, envía los datos para su procesamiento al procesador de entrada. Se admiten los siguientes formatos: HTTP, SOAP, Kafka, FIX. La arquitectura nos permite agregar soporte para nuevos formatos (el soporte de IBM MQ estará disponible próximamente). Si el análisis de solicitud falla, el conector devuelve un error. De lo contrario, responde que la solicitud se ha procesado correctamente, incluso si se produjo un error durante el procesamiento posterior. Esto se hace a propósito para trabajar con los sistemas que no saben cómo repetir solicitudes, o viceversa, hacerlo de manera demasiado agresiva. Para asegurarse de que no se pierdan datos, se utiliza la cola de reparación: el objeto se une a la cola y se elimina de ella solo después de un procesamiento exitoso. El administrador recibe notificaciones sobre los objetos que quedan en la cola de reparación y puede volver a intentar el procesamiento después de manejar un error de software o falla de hardware.
Procesador de entrada
El procesador de entrada clasifica los datos recibidos por características y llama a los controladores correspondientes. Los controladores son código Lua que se ejecuta en un entorno limitado, por lo que no pueden afectar el funcionamiento del sistema. En esta etapa, los datos se pueden transformar según sea necesario y, si es necesario, se puede ejecutar cualquier cantidad de tareas para implementar la lógica necesaria. Por ejemplo, al agregar un nuevo usuario en MDM (Master Data Management creado en base a Tarantool Data Grid), se crearía un registro dorado como una tarea separada para que el procesamiento de la solicitud no se ralentice. El entorno limitado admite solicitudes para leer, cambiar y agregar datos. También le permite llamar a alguna función para todos los roles del tipo de almacenamiento y agregar el resultado (mapear / reducir).
Los controladores se pueden describir en archivos:
sum.lua local x, y = unpack(...) return x + y
Luego declarado en la configuración:
functions: sum: { __file: sum.lua }
¿Por qué lua? Lua es un lenguaje sencillo. Según nuestra experiencia, las personas comienzan a escribir código que resolvería su problema solo un par de horas después de ver el idioma por primera vez. Y estos no son solo desarrolladores profesionales, sino, por ejemplo, analistas. Además, gracias al compilador JIT, Lua es veloz.
Almacenamiento
El almacenamiento almacena datos persistentes. Antes de guardar, los datos se validan para cumplir con el esquema de datos. Para describir el esquema, utilizamos el formato extendido
Apache Avro . Ejemplo:
{ "name": "User", "type": "record", "logicalType": "Aggregate", "fields": [ { "name": "id", "type": "string" }, { "name": "first_name", "type": "string" }, { "name": "last_name", "type": "string" } ], "indexes": ["id"] }
En base a esta descripción, el DDL (Lenguaje de definición de datos) para el esquema DBMS de
Tarantool y el esquema
GraphQL para el acceso a los datos se generan automáticamente.
Se admite la replicación asincrónica de datos (también planeamos agregar replicación síncrona).
Procesador de salida
A veces es necesario notificar a los consumidores externos sobre los nuevos datos. Es por eso que tenemos el rol de Procesador de salida. Después de guardar los datos, podrían transferirse al controlador apropiado (por ejemplo, para transformarlos según lo requiera el consumidor) y luego transferirse al conector para su envío. La cola de reparación también se usa aquí: si nadie acepta el objeto, el administrador puede intentarlo más tarde.
Escalamiento
Las funciones de Conector, Procesador de entrada y Procesador de salida no tienen estado, lo que nos permite escalar el sistema horizontalmente simplemente agregando nuevas instancias de aplicación con la función habilitada necesaria. Para el escalado de almacenamiento horizontal, se organiza un clúster utilizando el
enfoque de cubos virtuales. Después de agregar un nuevo servidor, algunos depósitos de los servidores antiguos se mueven a un nuevo servidor en segundo plano. Este proceso es transparente para los usuarios y no afecta el funcionamiento de todo el sistema.
Propiedades de datos
Los objetos pueden ser enormes y contener otros objetos. Nos aseguramos de agregar y actualizar datos atómicamente y de guardar el objeto con todas las dependencias en un único depósito virtual. Esto se hace para evitar la llamada "mancha" del objeto en varios servidores físicos.
También se admite el control de versiones: cada actualización del objeto crea una nueva versión, y siempre podemos hacer un intervalo de tiempo para ver cómo se veía todo en ese momento. Para los datos que no necesitan un historial largo, podemos limitar el número de versiones o incluso almacenar solo la última, es decir, podemos desactivar el control de versiones para un tipo de datos específico. También podemos establecer los límites históricos: por ejemplo, eliminar todos los objetos de un tipo específico anterior a un año. El archivado también es compatible: podemos cargar objetos por encima de cierta edad para liberar el espacio del clúster.
Tareas
Las características interesantes que se deben tener en cuenta incluyen la capacidad de ejecutar tareas a tiempo, a solicitud del usuario o automáticamente desde el sandbox:
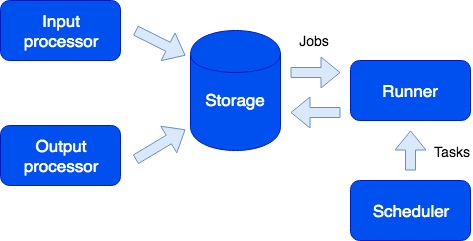
Aquí podemos ver otro rol llamado Runner. Este papel no tiene estado; si es necesario, se podrían agregar más instancias de aplicación con este rol al clúster. El corredor es responsable de completar las tareas. Como ya he mencionado, se pueden crear nuevas tareas desde el sandbox; se unen a la cola en el almacenamiento y luego se ejecutan en el corredor. Este tipo de tareas se llama trabajo. También tenemos un tipo de tarea llamada Tarea, es decir, una tarea definida por el usuario que se ejecutará a tiempo (utilizando la sintaxis cron) o bajo demanda. Para ejecutar y rastrear tales tareas, tenemos un conveniente administrador de tareas. El rol del planificador debe estar habilitado para usar esta función. Este rol tiene un estado, por lo que no escala lo que no es necesario de todos modos. Sin embargo, como cualquier otro rol, puede tener una réplica que comienza a funcionar si el maestro falla repentinamente.
Registrador
Otro rol se llama Logger. Recopila registros de todos los miembros del clúster y proporciona una interfaz para cargarlos y verlos a través de la interfaz web.
Servicios
Vale la pena mencionar que el sistema facilita la creación de servicios. En el archivo de configuración, puede especificar qué solicitudes deben enviarse al controlador escrito por el usuario que se ejecuta en el entorno limitado. Tal controlador puede, por ejemplo, realizar algún tipo de solicitud analítica y devolver el resultado.
El servicio se describe en el archivo de configuración:
services: sum: doc: "adds two numbers" function: sum return_type: int args: x: int y: int
La API GraphQL se genera automáticamente y el servicio está disponible para llamadas:
query { sum(x: 1, y: 2) }
Esto llama al controlador de
sum que devuelve el resultado:
3
Solicitud de perfiles y métricas
Implementamos soporte para el protocolo OpenTracing para lograr una mejor comprensión de los mecanismos del sistema y solicitar perfiles. Bajo demanda, el sistema puede enviar información sobre cómo se ejecutó la solicitud a las herramientas que admiten este protocolo (por ejemplo, Zipkin):
No hace falta decir que el sistema proporciona métricas internas que se pueden recopilar con Prometheus y visualizar con Grafana.
Despliegue
Tarantool Data Grid se puede implementar desde paquetes o archivos RPM utilizando la utilidad incorporada o Ansible. Kubernetes también es compatible (
Tarantool Kubernetes Operator ).
Una aplicación que implementa lógica de negocios (configuración, controladores) se carga en el clúster de Tarantool Data Grid implementado en el archivo a través de la interfaz de usuario o como un script que utiliza la API proporcionada.
Aplicaciones de muestra
¿Qué aplicaciones puedes crear con Tarantool Data Grid? De hecho, la mayoría de las tareas comerciales están relacionadas de alguna manera con el procesamiento, el almacenamiento y el acceso a la secuencia de datos. Por lo tanto, si tiene grandes flujos de datos que requieren almacenamiento seguro y accesibilidad, entonces nuestro producto podría ahorrarle mucho tiempo en el desarrollo y ayudarlo a concentrarse en su lógica comercial.
Por ejemplo, le gustaría recopilar información sobre el mercado inmobiliario para mantenerse actualizado sobre las mejores ofertas en el futuro. En este caso, destacamos las siguientes tareas:
- Los robots que recopilan información de fuentes abiertas serían sus fuentes de datos. Puede resolver este problema utilizando soluciones preparadas o escribiendo código en cualquier idioma.
- A continuación, Tarantool Data Grid acepta y guarda los datos. Si el formato de datos de varias fuentes es diferente, entonces podría escribir código en Lua que convertiría todo a un solo formato. En la etapa de preprocesamiento, también podría, por ejemplo, filtrar ofertas recurrentes o actualizar más información de la base de datos sobre agentes que operan en el mercado.
- Ahora ya tiene una solución escalable en el clúster que podría rellenarse con datos y usarse para crear muestras de datos. Luego puede implementar nuevas funciones, por ejemplo, escribir un servicio que crearía una solicitud de datos y devolvería la oferta más ventajosa por día. Solo requeriría varias líneas en el archivo de configuración y algo de código Lua.
¿Qué sigue?
Para nosotros, una prioridad es aumentar la conveniencia de desarrollo con
Tarantool Data Grid . (Por ejemplo, este es un IDE con soporte para perfiles y depuradores que funcionan en el sandbox).
También prestamos mucha atención a los problemas de seguridad. En este momento, nuestro producto está siendo certificado por el FSTEC de Rusia (Servicio Federal de Tecnología y Control de Exportaciones) para reconocer el alto nivel de seguridad y cumplir con los requisitos de certificación para productos de software utilizados en sistemas de información de datos personales y sistemas de información federal.