
La tolerancia a fallas y la alta disponibilidad son temas importantes, por lo que RabbitMQ y Kafka dedicarán artículos separados. Este artículo es sobre RabbitMQ, y el siguiente es sobre Kafka, en comparación con RabbitMQ. El artículo es largo, así que ponte cómodo.
Considere las estrategias de tolerancia a fallas, consistencia y alta disponibilidad (HA), así como las compensaciones que cada estrategia tiene que hacer. RabbitMQ puede ejecutarse en un grupo de nodos, y luego se clasifica como un sistema distribuido. Cuando se trata de sistemas distribuidos, a menudo hablamos de consistencia y accesibilidad.
Estos conceptos describen cómo se comporta el sistema en caso de falla. Falla de conexión de red, falla del servidor, falla del disco duro, indisponibilidad temporal del servidor debido a recolección de basura, pérdida de paquetes o ralentización de la conexión de red. Todo esto puede conducir a la pérdida de datos o conflictos. Resulta que es casi imposible crear un sistema que sea simultáneamente completamente consistente (sin pérdida de datos, sin discrepancias de datos) y accesible (aceptará operaciones de lectura y escritura) para todo tipo de fallas.
Veremos que la coherencia y la accesibilidad se encuentran en diferentes extremos del espectro, y debe elegir qué forma optimizar. La buena noticia es que con RabbitMQ tal elección es posible. Tiene una especie de apalancamiento "Nerd" para cambiar el equilibrio hacia una mayor coherencia o mayor accesibilidad.
Prestaremos especial atención a qué configuraciones conducen a la pérdida de datos debido a registros confirmados. Existe una cadena de responsabilidad entre editores, corredores y consumidores. Después de que el mensaje se transmite al agente, es su trabajo no perder el mensaje. Cuando el corredor confirma al editor el recibo del mensaje, no esperamos que se pierda. Pero veremos que esto realmente puede suceder dependiendo de la configuración de su corredor y editor.
Las primitivas de estabilidad de un nodo
Colas sostenidas / enrutamiento
Hay dos tipos de colas en RabbitMQ: duraderas / no duraderas. Todas las colas se almacenan en la base de datos de Mnesia. Las colas persistentes se vuelven a declarar cuando el nodo se inicia y, por lo tanto, sobreviven a un reinicio, un bloqueo del sistema o un bloqueo del servidor (siempre que se guarden los datos). Esto significa que mientras declara el enrutamiento (intercambio) y la resistencia de la cola, la infraestructura de las colas / enrutamiento volverá a estar en línea.
Las colas volátiles y el enrutamiento se eliminan cuando se reinicia el host.
Publicaciones persistentes
El hecho de que la cola sea larga no significa que todos sus mensajes sobrevivirán al reinicio de un nodo. Solo se restaurarán los mensajes establecidos por el editor como persistentes. Los mensajes persistentes crean una carga adicional para el intermediario, pero si la pérdida de mensajes es inaceptable, entonces no hay otra manera.
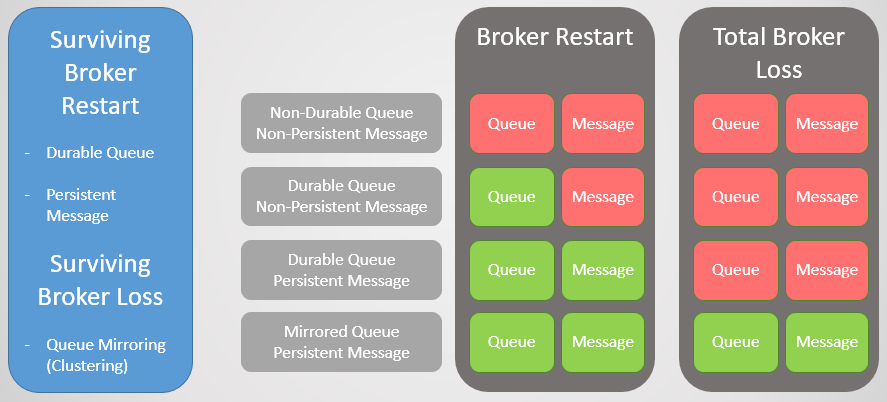 Fig. 1. Matriz de estabilidad
Fig. 1. Matriz de estabilidadAgrupación de clústeres de reflejo
Para sobrevivir a la pérdida de un corredor, necesitamos redundancia. Podemos combinar varios nodos RabbitMQ en un clúster y luego agregar redundancia adicional replicando las colas entre varios nodos. Por lo tanto, si un nodo cae, no perdemos datos y permanecemos disponibles.
Espejo de cola:
- una cola principal (maestra), que recibe todos los comandos de escritura y lectura
- uno o más espejos que reciben todos los mensajes y metadatos de la cola principal. Estos espejos no existen para escalar, sino únicamente para redundancia.
 Fig. 2. Reflejando la cola
Fig. 2. Reflejando la colaLa duplicación se establece mediante la política adecuada. En él, puede elegir la tasa de replicación e incluso los nodos en los que se debe colocar la cola. Ejemplos:
ha-mode: all
ha-mode: exactly, ha-params: 2 (un maestro y un espejo)
ha-mode: nodes, ha-params: rabbit@node1, rabbit@node2
Confirmación al editor
Para lograr la grabación secuencial, Publisher Confirms debe confirmarse. Sin ellos, existe la posibilidad de perder mensajes. Se envía una confirmación al editor después de escribir el mensaje en el disco. RabbitMQ escribe mensajes en el disco no al recibirlos, sino periódicamente, en la región de varios cientos de milisegundos. Cuando la cola se refleja, la confirmación se envía solo después de que todas las réplicas también hayan escrito su copia del mensaje en el disco. Esto significa que el uso de reconocimientos aumenta la demora, pero si la seguridad de los datos es importante, entonces son necesarios.
Cola de conmutación por error
Cuando el intermediario se cierra o se bloquea, todas las colas principales (maestros) en este nodo se caen con él. El clúster luego selecciona el espejo más antiguo de cada maestro y lo promueve como un nuevo maestro.
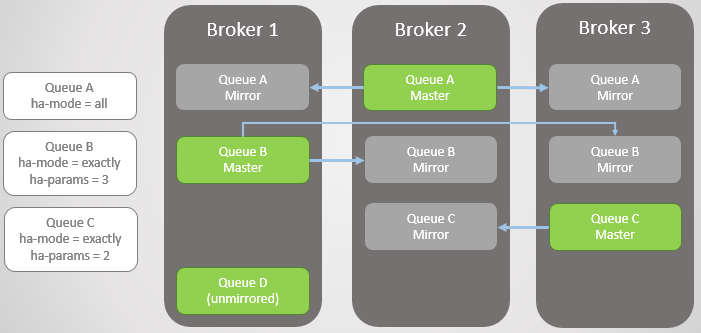 Fig. 3. Varias colas reflejadas y sus políticas.
Fig. 3. Varias colas reflejadas y sus políticas.Broker 3 gotas. Tenga en cuenta que el espejo de la cola C en Broker 2 se actualiza a maestro. También tenga en cuenta que se ha creado un nuevo espejo para la cola C en el corredor 1. RabbitMQ siempre intenta mantener la tasa de replicación especificada en sus políticas.
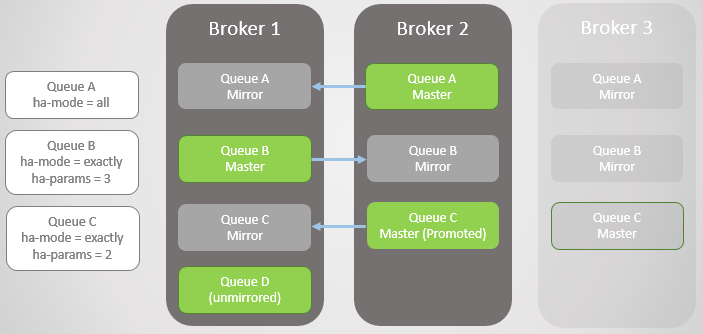 Fig. 4. El corredor 3 se cae, haciendo que la cola C falle
Fig. 4. El corredor 3 se cae, haciendo que la cola C falle¡El próximo Broker 1 está cayendo! Solo nos queda un corredor. El espejo de la Cola B se eleva hacia el maestro.
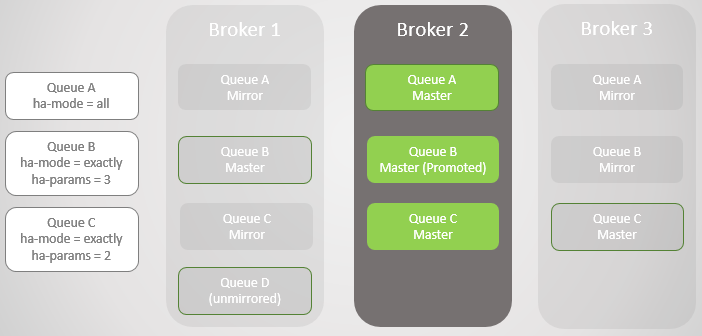 Fig. 5 5
Fig. 5 5Devolvimos el Broker 1. No importa cuán exitosamente sobrevivieron los datos a la pérdida y recuperación del broker, todos los mensajes de cola reflejados se descartan al reiniciar. Es importante tener en cuenta que habrá consecuencias. Pronto consideraremos estas consecuencias. Por lo tanto, el Broker 1 ahora es nuevamente miembro del clúster, y el clúster está tratando de cumplir con las políticas y, por lo tanto, crea espejos en el Broker 1.
En este caso, la pérdida del Broker 1 se completó, así como los datos, por lo que la Cola D sin duplicación se perdió por completo.
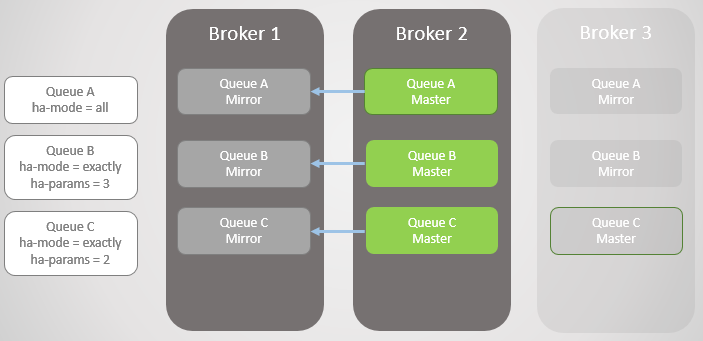 Fig. 6. El corredor 1 vuelve a estar en servicio
Fig. 6. El corredor 1 vuelve a estar en servicioBroker 3 vuelve a estar en línea, por lo que las líneas A y B vuelven a crear espejos para que se ajusten a sus políticas de HA. ¡Pero ahora todas las líneas principales están en un nodo! Esto no es ideal; una distribución uniforme entre nodos es mejor. Desafortunadamente, no hay opciones especiales para reequilibrar los maestros. Volveremos a este problema más tarde, ya que primero debemos considerar la sincronización de la cola.
 Fig. 7. El corredor 3 vuelve a estar en servicio. ¡Todas las colas principales en un nodo!
Fig. 7. El corredor 3 vuelve a estar en servicio. ¡Todas las colas principales en un nodo!Por lo tanto, ahora debe tener una idea de cómo los espejos proporcionan redundancia y tolerancia a fallas. Esto garantiza la disponibilidad en caso de falla de un solo nodo y protege contra la pérdida de datos. Pero aún no hemos terminado, porque en realidad todo es mucho más complicado.
Sincronización
Al crear un nuevo espejo, todos los mensajes nuevos siempre se replicarán en este espejo y en cualquier otro. En cuanto a los datos existentes en la cola principal, podemos replicarlos en un nuevo espejo, que se convierte en una copia completa del maestro. Tampoco podemos replicar los mensajes existentes y permitir que la cola principal y el nuevo espejo converjan a tiempo cuando lleguen mensajes nuevos a la cola y los mensajes existentes abandonen la cabecera de la cola principal.
Esta sincronización se realiza de forma automática o manual y se controla mediante una política de cola. Considera un ejemplo.
Tenemos dos líneas espejadas. La cola A se sincroniza automáticamente y la cola B manualmente. Ambas líneas tienen diez mensajes cada una.
 Fig. 8. Dos colas con diferentes modos de sincronización.
Fig. 8. Dos colas con diferentes modos de sincronización.Ahora estamos perdiendo Broker 3.
 Fig. 9. El corredor 3 cayó
Fig. 9. El corredor 3 cayóBroker 3 vuelve a estar en servicio. El clúster crea un espejo para cada cola en el nuevo nodo y sincroniza automáticamente la nueva Cola A con el maestro. Sin embargo, el espejo del nuevo Turno B permanece vacío. Por lo tanto, tenemos una redundancia completa de la cola A y solo un espejo para los mensajes existentes de la cola B.
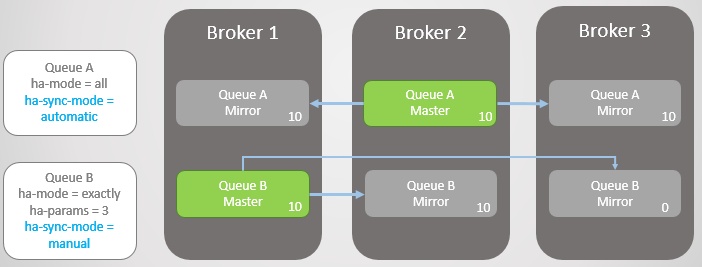 Fig. 10. El nuevo espejo de la Cola A recibe todos los mensajes existentes, pero el nuevo espejo de la Cola B no
Fig. 10. El nuevo espejo de la Cola A recibe todos los mensajes existentes, pero el nuevo espejo de la Cola B noAmbas líneas reciben diez mensajes más. Luego, el corredor 2 cae y la cola A regresa al espejo más antiguo, que se encuentra en el corredor 1. En caso de falla, no hay pérdida de datos. Hay veinte mensajes en la cola B del asistente y solo diez en el espejo, ya que esta cola nunca replicó los diez mensajes originales.
 Fig. 11. La línea A se revierte al corredor 1 sin perder mensajes
Fig. 11. La línea A se revierte al corredor 1 sin perder mensajesAmbas líneas reciben diez mensajes más. El agente 1 ahora se bloquea. La cola A cambia al espejo sin ningún problema sin perder mensajes. Sin embargo, la cola B tiene problemas. En este punto, podemos optimizar la accesibilidad o la coherencia.
Si queremos optimizar la accesibilidad, entonces la política de
promoción de fallas ha debe establecerse como
siempre . Este es el valor predeterminado, por lo que simplemente puede omitir la política. En este caso, de hecho, permitimos fallas en espejos no sincronizados. Esto provocará la pérdida de mensajes, pero la cola sigue siendo legible y grabable.
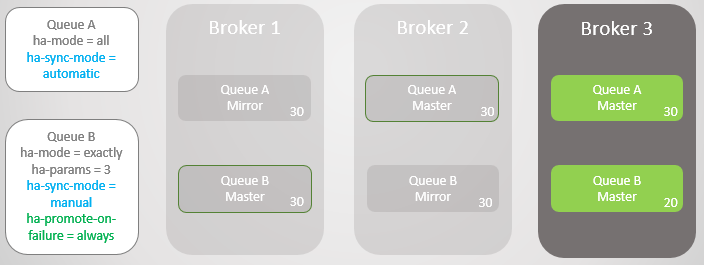 Fig. 12. La línea A se revierte al corredor 3 sin perder mensajes. La línea B regresa al corredor 3 con la pérdida de diez mensajes
Fig. 12. La línea A se revierte al corredor 3 sin perder mensajes. La línea B regresa al corredor 3 con la pérdida de diez mensajesTambién podemos configurar
ha-promote-on-failure para
when-synced . En este caso, en lugar de regresar al espejo, la cola esperará hasta que el Agente 1 con sus datos vuelva al modo en línea. Después de su regreso, la cola principal aparece nuevamente en el Broker 1 sin pérdida de datos. La accesibilidad se sacrifica por la seguridad de los datos. Pero este es un modo arriesgado, que incluso puede conducir a una pérdida completa de datos, que consideraremos en el futuro cercano.
 Fig. 13. La línea B no está disponible después de perder el corredor 1
Fig. 13. La línea B no está disponible después de perder el corredor 1Puede hacer una pregunta: "¿Quizás es mejor nunca usar la sincronización automática?". La respuesta es que la sincronización es una operación de bloqueo. ¡Durante la sincronización, la cola principal no puede realizar ninguna operación de lectura o escritura!
Considera un ejemplo. Ahora tenemos líneas muy largas. ¿Cómo pueden crecer a este tamaño? Por varias razones:
- Las colas no se usan activamente.
- Estas son líneas de alta velocidad, y en este momento los consumidores son lentos
- Estas son colas de alta velocidad, se produjo un error y los consumidores se están poniendo al día
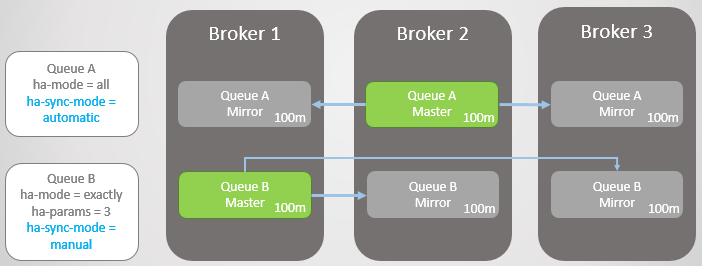 Fig. 14. Dos grandes colas con diferentes modos de sincronización.
Fig. 14. Dos grandes colas con diferentes modos de sincronización.Ahora Broker 3 se bloquea.
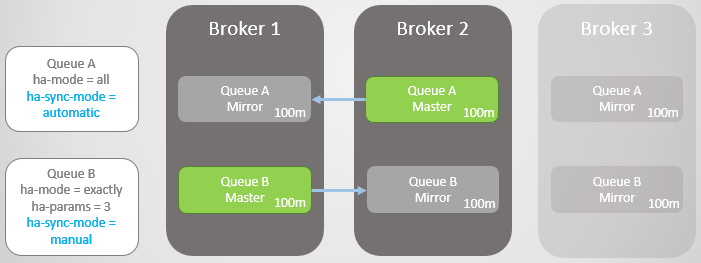 Fig. 15. El corredor 3 cae, dejando un maestro y un espejo en cada cola
Fig. 15. El corredor 3 cae, dejando un maestro y un espejo en cada colaBroker 3 regresa y se crean nuevos espejos. La cola principal A comienza a replicar los mensajes existentes en un nuevo espejo, y durante este tiempo, la cola A no está disponible. La replicación de datos requiere dos horas, lo que resulta en dos horas de tiempo de inactividad para esta cola.
Sin embargo, la Línea B permanece disponible durante todo el período. Ella sacrificó algo de redundancia en aras de la accesibilidad.
 Fig. 16. La cola no está disponible durante la sincronización
Fig. 16. La cola no está disponible durante la sincronizaciónDespués de dos horas, la Cola A también está disponible y puede comenzar nuevamente a aceptar operaciones de lectura y escritura.
Actualizaciones
Este comportamiento de bloqueo durante la sincronización dificulta la actualización de clústeres con colas muy grandes. En algún momento, el nodo con el asistente debe reiniciarse, lo que significa cambiar al espejo o apagar la cola durante la actualización del servidor. Si elegimos una transición, perderemos mensajes si los espejos no están sincronizados. De manera predeterminada, cuando un intermediario está deshabilitado, la transición a un espejo no sincronizado no se realiza. Esto significa que tan pronto como el corredor regrese, no perdamos ningún mensaje, el único daño fue solo una simple cola. La desactivación de los corredores se rige por la política de
ha-promote-on-shutdown . Puede establecer uno de dos valores:
always = habilitado para cambiar a espejos no sincronizados
when-synced = cambia solo al espejo sincronizado, de lo contrario la cola se vuelve inaccesible para leer y escribir. La cola vuelve tan pronto como regresa el corredor
De una forma u otra, con grandes colas, debe elegir entre pérdida de datos e inaccesibilidad.
Cuando la disponibilidad mejora la seguridad de los datos
Antes de tomar una decisión, se debe tener en cuenta una complicación más. Si bien la sincronización automática es mejor para la redundancia, ¿cómo afecta la seguridad de los datos? Por supuesto, gracias a una mejor redundancia, RabbitMQ tiene menos probabilidades de perder los mensajes existentes, pero ¿qué pasa con los nuevos mensajes de los editores?
Aquí debe considerar lo siguiente:
- ¿Puede un editor devolver un error y un servicio o usuario superior volverá a intentarlo más tarde?
- ¿Puede un editor guardar un mensaje localmente o en una base de datos para volver a intentarlo más tarde?
Si el editor solo puede soltar el mensaje, de hecho, mejorar la accesibilidad también aumenta la seguridad de los datos.
Por lo tanto, debe buscar un equilibrio, y la decisión depende de la situación específica.
Problemas con ha-promote-on-failure = cuando se sincroniza
La idea de
ha-promote-on-failure =
cuando se sincroniza es que evitamos cambiar a un espejo no sincronizado y, por lo tanto, evitamos la pérdida de datos. La cola permanece inaccesible para leer o escribir. En cambio, tratamos de devolver un corredor caído con datos no dañados para que reanude el trabajo como maestro sin pérdida de datos.
Pero (y esto es grande pero) si el corredor perdió sus datos, entonces tenemos un gran problema: ¡se pierde la cola! ¡Todos los datos se han ido! Incluso si tiene espejos que básicamente se ponen al día con la cola principal, estos espejos también se descartan.
Para volver a agregar un nodo con el mismo nombre, le decimos al clúster que olvide el nodo perdido (con el
comando rabbitmqctl forget_cluster_node ) e inicie un nuevo agente con el mismo nombre de host. Mientras el clúster recuerde el nodo perdido, recordará la cola anterior y los espejos no sincronizados. Cuando se le dice a un clúster que olvide un nodo perdido, esta cola también se olvida. Ahora necesita volver a declararlo. Perdimos todos los datos, aunque teníamos espejos con un conjunto de datos parcial. ¡Sería mejor cambiar a un espejo no sincronizado!
Por lo tanto, la sincronización manual (y la falla de sincronización) en combinación con
ha-promote-on-failure=when-synced , en mi opinión, es bastante arriesgado. Los documentos dicen que esta opción existe para la seguridad de los datos, pero es un cuchillo de doble filo.
Maestros reequilibrantes
Según lo prometido, volvemos al problema de la acumulación de todos los maestros en uno o más nodos. Esto puede suceder incluso como resultado de actualizaciones continuas del clúster. En un clúster con tres nodos, todas las colas principales se acumularán en uno o dos nodos.
El reequilibrio de los maestros puede ser problemático por dos razones:
- No hay buenas herramientas de reequilibrio
- Sincronización de cola
Para reequilibrar, hay un
complemento de terceros que no es oficialmente compatible. Con respecto a los complementos de terceros, el manual de RabbitMQ
dice : “El complemento proporciona algunas herramientas de configuración e informes adicionales, pero el equipo de RabbitMQ no lo admite y no lo prueba. Úselo bajo su propio riesgo.
Hay otro truco para mover la cola principal a través de las políticas de HA. El manual menciona un
guión para esto. Funciona de la siguiente manera:
- Elimina todos los espejos utilizando una política temporal con una prioridad más alta que la política HA existente.
- Cambia la política temporal de HA para usar el modo de nodos con el nodo al que se debe mover la cola principal.
- Sincroniza la cola para la migración forzada.
- Una vez completada la migración, elimina la política temporal. La política inicial de HA entra en vigor y se crea el número requerido de réplicas.
La desventaja es que este enfoque puede no funcionar si tiene grandes colas o estrictos requisitos de redundancia.
Ahora veamos cómo funcionan los clústeres RabbitMQ con particiones de red.
Interrupción de la conectividad
Los nodos de un sistema distribuido están conectados por enlaces de red, y los enlaces de red pueden y estarán desconectados. La frecuencia de las interrupciones depende de la infraestructura local o de la confiabilidad de la nube seleccionada. En cualquier caso, los sistemas distribuidos deberían poder manejarlos. Una vez más, tenemos que elegir entre accesibilidad y coherencia, y una vez más, la buena noticia es que RabbitMQ proporciona ambas (simplemente no al mismo tiempo).
Con RabbitMQ, tenemos dos opciones principales:
- Permitir la separación lógica (cerebro dividido). Esto proporciona accesibilidad, pero puede causar pérdida de datos.
- No permitir la separación lógica. Puede resultar en una pérdida de disponibilidad a corto plazo dependiendo de cómo los clientes se conectan al clúster. También puede conducir a la inaccesibilidad completa en un grupo de dos nodos.
Pero, ¿qué es la separación lógica? Esto es cuando un clúster se divide en dos debido a la pérdida de conexiones de red. En cada lado, los espejos se elevan hasta el maestro, por lo que al final, hay varios maestros en cada turno.
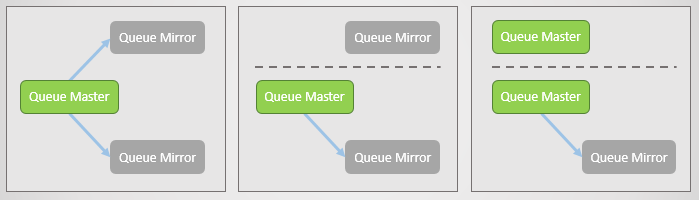 Fig. 17. La línea principal y dos espejos, cada uno en un nodo separado. Luego ocurre una falla en la red y se separa un espejo. El nodo separado ve que los otros dos se han caído y avanza sus espejos hacia el maestro. Ahora tenemos dos líneas principales, y ambas permiten escribir y leer.
Fig. 17. La línea principal y dos espejos, cada uno en un nodo separado. Luego ocurre una falla en la red y se separa un espejo. El nodo separado ve que los otros dos se han caído y avanza sus espejos hacia el maestro. Ahora tenemos dos líneas principales, y ambas permiten escribir y leer.Si los editores envían datos a ambos maestros, obtenemos dos copias divergentes de la cola.
Los diversos modos RabbitMQ proporcionan accesibilidad o consistencia.
Ignorar modo (predeterminado)
Este modo proporciona accesibilidad. Después de la pérdida de conectividad, se produce una separación lógica. Después de reconectarse, el administrador debe decidir qué partición prefiere. El lado perdedor se reiniciará y todos los datos acumulados de este lado se perderán.
 Fig. 18. Tres editores están asociados con tres corredores. Internamente, el clúster reenvía todas las solicitudes a la cola principal en Broker 2.
Fig. 18. Tres editores están asociados con tres corredores. Internamente, el clúster reenvía todas las solicitudes a la cola principal en Broker 2.Ahora estamos perdiendo al corredor 3. Él ve que otros corredores se han caído y mueve su espejo hacia el maestro. Esta es la separación lógica.
 Fig. 19. Separación lógica (cerebro dividido). Los registros van en dos líneas principales, y dos copias divergen.
Fig. 19. Separación lógica (cerebro dividido). Los registros van en dos líneas principales, y dos copias divergen.La conectividad se restaura, pero la separación lógica permanece. El administrador debe seleccionar manualmente el lado perdedor. En el siguiente caso, el administrador reinicia el Broker 3. Todos los mensajes que no logró transmitir se pierden.
 Fig. 20. El administrador deshabilita el Broker 3.
Fig. 20. El administrador deshabilita el Broker 3. Fig. 21. El administrador inicia el Broker 3, y se une al clúster, perdiendo todos los mensajes que permanecieron allí.
Fig. 21. El administrador inicia el Broker 3, y se une al clúster, perdiendo todos los mensajes que permanecieron allí.Durante la pérdida de conectividad y después de su restauración, el clúster y esta cola estaban disponibles para lectura y escritura.
Modo de curación automática
Funciona de manera similar al modo Ignorar, excepto que el clúster selecciona automáticamente el lado perdedor después de dividir y restaurar la conectividad. El lado perdedor regresa al clúster vacío, y la cola pierde todos los mensajes que se enviaron solo a ese lado.
Pausa en modo minoritario
Si no queremos permitir la separación lógica, entonces nuestra única opción es negarnos a leer y escribir en el lado más pequeño después de la partición del clúster. Cuando un corredor ve que está en el lado inferior, hace una pausa, es decir, cierra todas las conexiones existentes y rechaza las nuevas. Una vez por segundo, verifica la reconexión. Una vez que se restaura la conectividad, reanuda el trabajo y se une al clúster.
 Fig. 22. Tres editores están asociados con tres corredores. Internamente, el clúster reenvía todas las solicitudes a la cola principal en Broker 2.
Fig. 22. Tres editores están asociados con tres corredores. Internamente, el clúster reenvía todas las solicitudes a la cola principal en Broker 2.Luego, los corredores 1 y 2 se separan del corredor 3. En lugar de actualizar su espejo a maestro, el corredor 3 se detiene y queda inaccesible.
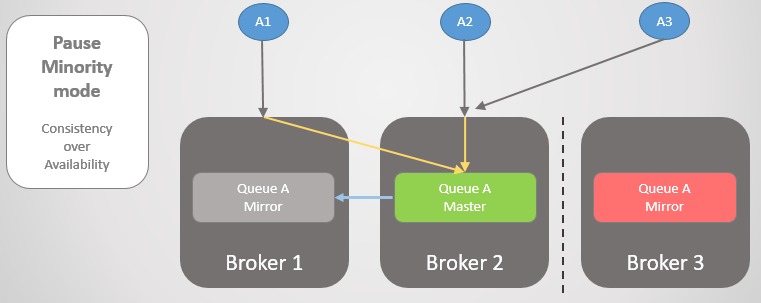 Fig. 23. Broker 3 hace una pausa, desconecta a todos los clientes y rechaza las solicitudes de conexión.
Fig. 23. Broker 3 hace una pausa, desconecta a todos los clientes y rechaza las solicitudes de conexión.Una vez que se restablece la conectividad, vuelve al clúster.
Veamos otro ejemplo, donde la línea principal está en Broker 3.
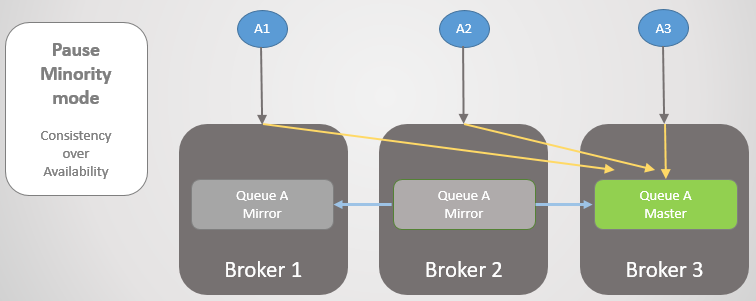 Fig. 24. La línea principal en Broker 3.
Fig. 24. La línea principal en Broker 3.Entonces se produce la misma pérdida de conectividad. El corredor 3 hace una pausa porque está en el lado más pequeño. Por otro lado, los nodos ven que el Broker 3 se ha caído, por lo que el espejo más antiguo de los Brokers 1 y 2 se eleva al maestro.
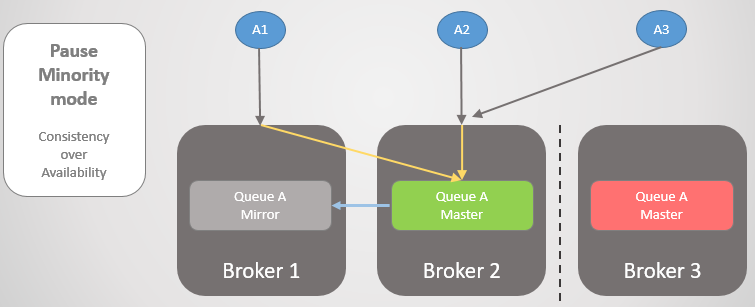 Fig. 25. Transición al corredor 2 si el corredor 3 no está disponible.
Fig. 25. Transición al corredor 2 si el corredor 3 no está disponible.Cuando se restablezca la conectividad, Broker 3 se unirá al clúster.
 Fig. 26. El clúster volvió a la operación normal.
Fig. 26. El clúster volvió a la operación normal.Es importante comprender que estamos obteniendo coherencia, pero también podemos obtener accesibilidad
si transferimos con éxito a los clientes a la mayor parte de la sección. Para la mayoría de las situaciones, personalmente elegiría el modo Pausa Minoritaria, pero realmente depende del caso particular.
Para garantizar la disponibilidad, es importante asegurarse de que los clientes se conecten con éxito al sitio. Considera nuestras opciones.
Conectividad del cliente
Tenemos varias opciones sobre cómo, después de perder la conectividad, enviar clientes a la parte principal del clúster o a los nodos de trabajo (después de una falla de un nodo). Primero, recordemos que una cola particular está alojada en un host particular, pero el enrutamiento y las políticas se replican en todos los hosts. Los clientes pueden conectarse a cualquier nodo, y el enrutamiento interno los dirigirá cuando sea necesario. Pero cuando se suspende un nodo, rechaza la conexión, por lo que los clientes deben conectarse a otro nodo. Si un nodo se cae, puede hacer poco.
Nuestras opciones:
- Se accede al clúster utilizando un equilibrador de carga, que simplemente recorre los nodos y los clientes hacen intentos repetidos de conectarse hasta que se completan con éxito. , , ( ). , .
- / , . , , .
- , . , , .
- / DNS. TTL.
Conclusiones
RabbitMQ . , :
. RabbitMQ , . , . RabbitMQ . RabbitMQ :
, :
ha-promote-on-failure=always
ha-sync-mode=manual
cluster_partition_handling=ignore ( autoheal )
- , , -
( ) :
- Publisher Confirms Manual Acknowledgements
ha-promote-on-failure=when-synced , ! =always .
ha-sync-mode=automatic ( ; , , )
- Pause Minority
; , (, ). Shovel.
- , , .
.
, RabbitMQ Docker Blockade, , .
:
№1 —
habr.com/ru/company/itsumma/blog/416629№2 —
habr.com/ru/company/itsumma/blog/418389№3 —
habr.com/ru/company/itsumma/blog/437446